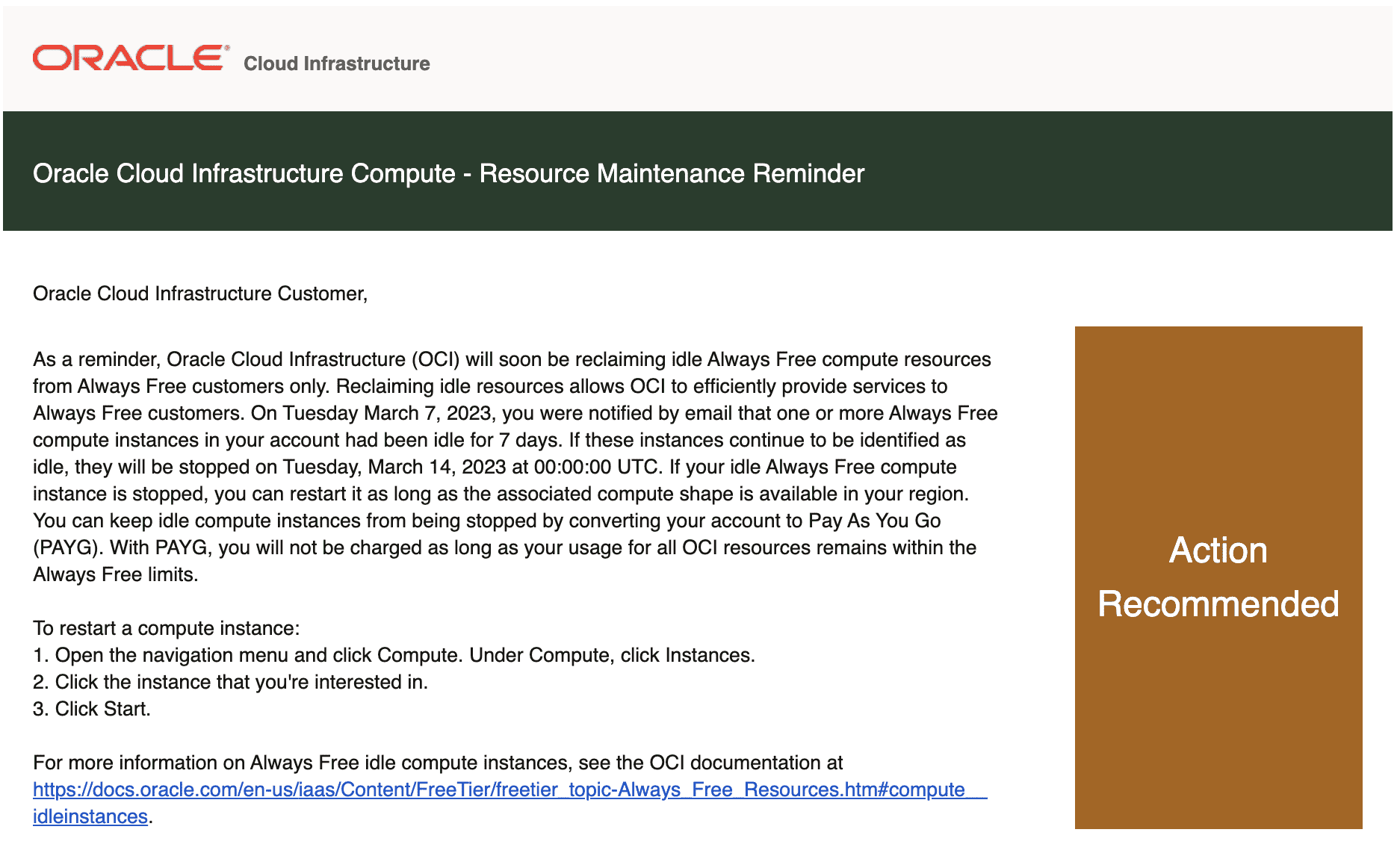
最近收到 Oracle(甲骨文) 一封名为「Oracle Cloud Infrastructure Compute - Resource Maintenance Reminder」 的邮件,大致意思就是如果 Oracle Always Free 的机器使用率比较低的话,Oracle 就会判定 Compute Instances 处于 Idle (闲置)状态,Oracle 将保留回收实例的权力。
如何判定机器是处于闲置状态呢,在 Oracle 给出的官方文档 是这样描述的:
• CPU utilization for the 95th percentile is less than 10% ,95% 时间 CPU 利用率低于 10% • Network utilization is less than 10% ,网络利用率低于 10% •Memory utilization is less than 10% (applies to A1 shapes only),内存利用率低于 10%(仅适用于 A1 类型的 ARM 实例)
Oracle 给出的描述非常清晰,就目前我的理解,应该是只要上述三个条件中的一个满足了就会触发 Oracle 的回收机制,首先 Oracle 会发送一封警告邮件 Action Recommended,标题就是上面的。然后会告知用户,7 天之内如果没有满足上述标准就会回收实例。
Oracle Cloud Infrastructure Customer,
Oracle Cloud Infrastructure (OCI) will be reclaiming idle Always Free compute resources from Always Free customers. Reclaiming idle resources allows OCI to efficiently provide services to Always Free customers. Your account has been identified as having one or more compute instances that have been idle for the past 7 days. These idle instances will be stopped one week from today, January 30,2023. If your idle Always Free compute instance is stopped, you can restart it as long as the associated compute shape is available in your region. You can keep idle compute instances from being stopped by converting your account to Pay As You Go (PAYG). With PAYG, you will not be charged as long as your usage for all OCI resources remains within the Always Free limits.
解决方案
因为我之前申请的两台 AMD 和一台 24 G 内存的 ARM,都不敢将生产的东西放在上面,怕得就是 Oracle 突然变卦,所以上面跑的程序都比较少,现在看起来 Oracle 至少在变卦之前还是会发出声明的,可以将一些 Docker 迁移到机器上跑跑了。
解决方案其实也比较简单,一个就是按照官网所提供的方式升级成付费账号,用多少支付多少(Pay As You Go (PAYG));另外一个方案就是真实地把机器利用起来,跑一些程序,或者将起作为 [[K3s]] 节点加入集群跑起来,看看满足其使用的最低要求。
说实话,网上有一些教程让用户禁用 oracle cloud agent(root 模式下执行 snap remove oracle-cloud-agent),禁止 Oracle 监控实例的运行状况。因为可以猜测的就是 Oracle 会在 VM 实例中跑监控程序,然后批量地监控用户机器的使用情况,包括 CPU,内存,网络等等,如果把这个 agent 卸载掉了是否 Oracle 就检测不到了。说实话我是不推荐这个方法的,因为 VM 运行在 Oracle 的机房,要检测还是能通过其他手段来检测到的。
所以个人还是推荐将 VM 好好利用起来,个人在过去尝试过的 Self-hosted 应用,非常不错的都在这里 管理了起来,也可以在 GitHub Awesome Self hosted 项目里面找找自己感兴趣的利用起来。
利用 lookbusy 生成虚拟负载
lookbusy 是一个可以虚拟产生 CPU、内存、磁盘等负载的工具。
lookbusy 常用的一些使用方法。
CPU 使用
-c: 每个 cpu 的期望利用率,以百分比为单位(默认 50 )。若选择 curve 使用模式,则应给出 MIN-MAX 形式的范围。-n:保持忙碌的 CPU 数量(默认值:自动检测出的全部核心数)-r: 第一种模式:fixed,保持指定百分比的 CPU 利用率,第二种模式:curve,CPU 利用率随给定区间上下浮动。-p: 曲线内峰值利用率的偏移量,默认单位是秒,可以添加 m、h、d 作为其他单位-P: 曲线内峰值利用率的偏移量,可以添加 m、h、d 作为其他单位
内存使用
-m: 以字节为单位,后面是 KB、MB 或 GB(其他单位)-M: 单位为毫秒(默认值为 1000)
磁盘使用
-d:用于磁盘流失的文件大小(以字节为单位,后跟 KB、MB、GB 或 TB(其他单位))-b:用于 I/O 的块大小(以字节为单位,后跟 KB、MB 或 GB)-D:迭代之间的休眠时间,以毫秒为单位(默认值为 100)-f: 要用作缓冲区的文件 / 目录的路径(默认 /tmp)
使用举例:
lookbusy -c 50 # 占用所有 CPU 核心各 50%
lookbusy -c 50 -n 2 # 占用两个 CPU 核心各 50%
lookbusy -c 50-80 -r curve # 占用所有 CPU 核心在 50%-80% 左右浮动
lookbusy -m 128MB -M 1000 # 每 1000 毫秒,循环释放并分配 128MB 内存
lookbusy -d 1GB -b 1MB -D 10 # 每 10 毫秒,循环进行 1MB 磁盘写入,临时文件不超过 1GB
nohup lookbusy -c 50 -D 10 > /dev/null 2>&1 & #占用所有 CPU 核心各 50%,且后台运行,不记录日志
在 Oracle ARM 机器上可以直接使用 docker-compose 启动。