Laravel 学习笔记:Blade Component
Blade 模板中的 Components 提供了和 section, layout 和 includes 相似的机制。都可以用来复用构造的 Blade 模板。
但 Component 更容易理解,提供了两种方式:
- class based components
- anonymous components
使用命令创建:
php artisan make:component Alert
创建的文件在 App\View\Components 目录。
make:component 命令会创建一个 template 在 resources/views/components 目录中。
也能在子目录中创建 Components:
php artisan make:component Forms/Input
如果传参 --view:
php artisan make:component forms.input --view
就不会创建 class,只会创建模板。
Laravel 学习笔记:部署到生产环境
在本地开发调试的时候使用了 Laravel 提供的 Sail 依赖本地的 Docker 环境,Sail 提供了 Nginx,MySQL,Redis,等等容器,还提供了一个用于测试的 SMTP mailhog,但是生产环境可以使用更加稳定的组件。
Requirements
Laravel 应用需要一些基础的系统依赖,需要确保Web 服务器有如下的最低要求:
- PHP >= 8.0
- BCMath PHP Extension
- Ctype PHP Extension
- cURL PHP Extension
- DOM PHP Extension
- Fileinfo PHP Extension
- JSON PHP Extension
- Mbstring PHP Extension
- OpenSSL PHP Extension
- PCRE PHP Extension
- PDO PHP Extension
- Tokenizer PHP Extension
- XML PHP Extension
Nginx
Web 服务器就用 Nginx。
记住 Web 服务器所有的请求都会先到 public/index.php 文件,千万不要将此文件放到项目的根目录,或者 Web 服务器的根目录,如果 Web 服务器可以访问项目根目录会造成带有敏感信息的配置文件泄漏。
server {
listen 80;
server_name example.com;
root /srv/example.com/public;
add_header X-Frame-Options "SAMEORIGIN";
add_header X-XSS-Protection "1; mode=block";
add_header X-Content-Type-Options "nosniff";
index index.php;
charset utf-8;
location / {
try_files $uri $uri/ /index.php?$query_string;
}
location = /favicon.ico { access_log off; log_not_found off; }
location = /robots.txt { access_log off; log_not_found off; }
error_page 404 /index.php;
location ~ \.php$ {
fastcgi_pass unix:/var/run/php/php7.4-fpm.sock;
fastcgi_param SCRIPT_FILENAME $realpath_root$fastcgi_script_name;
include fastcgi_params;
}
location ~ /\.(?!well-known).* {
deny all;
}
}
部署过程
这里使用 [[aapanel]] 来新建一个站点。
然后将代码 push 到 GitHub,然后到机器上 push 来下。
cp .env.example .env
根据自己的配置,修改数据库、Redis、SMTP 相关的配置。
执行:
sudo composer install
注意将站点的所有者修改为 www:
sudo chown -R www:www .
然后执行:
sudo php artisan key:generate
sudo php artisan migrate
禁用 php 方法:
proc_opensymlinkpcntl_signalpcntl_alarm
Composer
安装 Composer:
wget https://getcomposer.org/download/1.8.0/composer.phar
mv composer.phar /usr/local/bin/composer
chmod u+x /usr/local/bin/composer
composer -V
自动加载优化:
composer install --optimize-autoloader --no-dev
优化配置加载,将配置文件压缩到一个缓存中
php artisan config:cache
优化路由加载:
php artisan route:cache
优化视图加载
php artisan view:cache
问题
如果遇到如下问题:
PHP Fatal error: Uncaught Error: Call to undefined function Composer\XdebugHandler\putenv() in phar:///usr/local/bin/composer/vendor/composer/xdebug-handler/src/Process.php:101
Stack trace:
#0 phar:///usr/local/bin/composer/vendor/composer/xdebug-handler/src/Status.php(59): Composer\XdebugHandler\Process::setEnv()
#1 phar:///usr/local/bin/composer/vendor/composer/xdebug-handler/src/XdebugHandler.php(99): Composer\XdebugHandler\Status->__construct()
#2 phar:///usr/local/bin/composer/bin/composer(18): Composer\XdebugHandler\XdebugHandler->__construct()
#3 /usr/local/bin/composer(29): require('...')
#4 {main}
thrown in phar:///usr/local/bin/composer/vendor/composer/xdebug-handler/src/Process.php on line 101
Fatal error: Uncaught Error: Call to undefined function Composer\XdebugHandler\putenv() in phar:///usr/local/bin/composer/vendor/composer/xdebug-handler/src/Process.php:101
Stack trace:
#0 phar:///usr/local/bin/composer/vendor/composer/xdebug-handler/src/Status.php(59): Composer\XdebugHandler\Process::setEnv()
#1 phar:///usr/local/bin/composer/vendor/composer/xdebug-handler/src/XdebugHandler.php(99): Composer\XdebugHandler\Status->__construct()
#2 phar:///usr/local/bin/composer/bin/composer(18): Composer\XdebugHandler\XdebugHandler->__construct()
#3 /usr/local/bin/composer(29): require('...')
#4 {main}
thrown in phar:///usr/local/bin/composer/vendor/composer/xdebug-handler/src/Process.php on line 101
需要禁用 php 的 putenv 方法。
Laravel 学习笔记:本地化
通过 Laravel 的样例项目也应该能看到 Laravel 对本地化多语言的支持代码了。
观察一下项目的目录结构就能猜出来语言文件在 resources/lang 中。目录结构需要按照 ISO 15897 标准来命令,简体中文 zh_CN
/resources
/lang
/en
messages.php
/es
messages.php
可以看到所有的语言文件都是返回一个 key-value 结构。
JSON 文件
Laravel 还可以定义 JSON 文件,存放在 resources/lang 下,如果是中文则是 resources/lang/zh_CN.json 文件:
{
"welcome": "欢迎来到 EV 的 Blog"
}
配置 Locale
在 config/app.php 中可以配置网站语言。
使用翻译
可以使用 __ 辅助函数来从语言文件中获取翻译。
echo __('welcome')
在 Blade 模板引擎中,可以直接在 `` 中使用:
如果翻译字符不存在,则直接返回字符串。
翻译占位符
如果翻译字符串中有需要变动的变量,可以使用 : 来将其定义为占位符:
'welcome' => 'Welcome, :name',
然后在获取的时候传入一个数组用于替换:
echo __('welcome', ['name' => 'laravel']);
利用 Cloudflare 和 Gmail 配置域名邮箱的收发
早在 2022 年年初的时候 Cloudflare 就推出了 Email Routing 的服务,在第一时间就从 Google Domains 中迁移到了 Cloudflare,中间好像也没有遇到什么问题,正常的收到域名邮箱的邮件,转发到 Gmail。
Cloudflare Email Routing (beta) is designed to simplify the way you create and manage email addresses, without needing to keep an eye on additional mailboxes. With Email Routing, you can create any number of custom email addresses that you can use in situations where you do not want to share your primary email address, such as when you subscribe to a new service or newsletter. Emails are then routed to your preferred email inbox, without you ever having to expose your primary email address.
Email Routing is free and private by design. Cloudflare will not store or access the emails routed to your inbox.
Prerequisites
- 首先需要将域名添加到 Cloudflare
- Cloudflare 已经开通 Email Routing 功能
- 一个可以接收 Email Routing 的 Gmail 邮箱
接收邮件
Cloudflare 接收邮件的设置非常简单,在页面中可以创建自定义地址的域名邮箱,然后自动转发至指定的首选邮箱。也可以设置 Catch-all 将所有发送至域名邮箱的邮件,即使没有定义前缀也全部转发到指定邮箱。
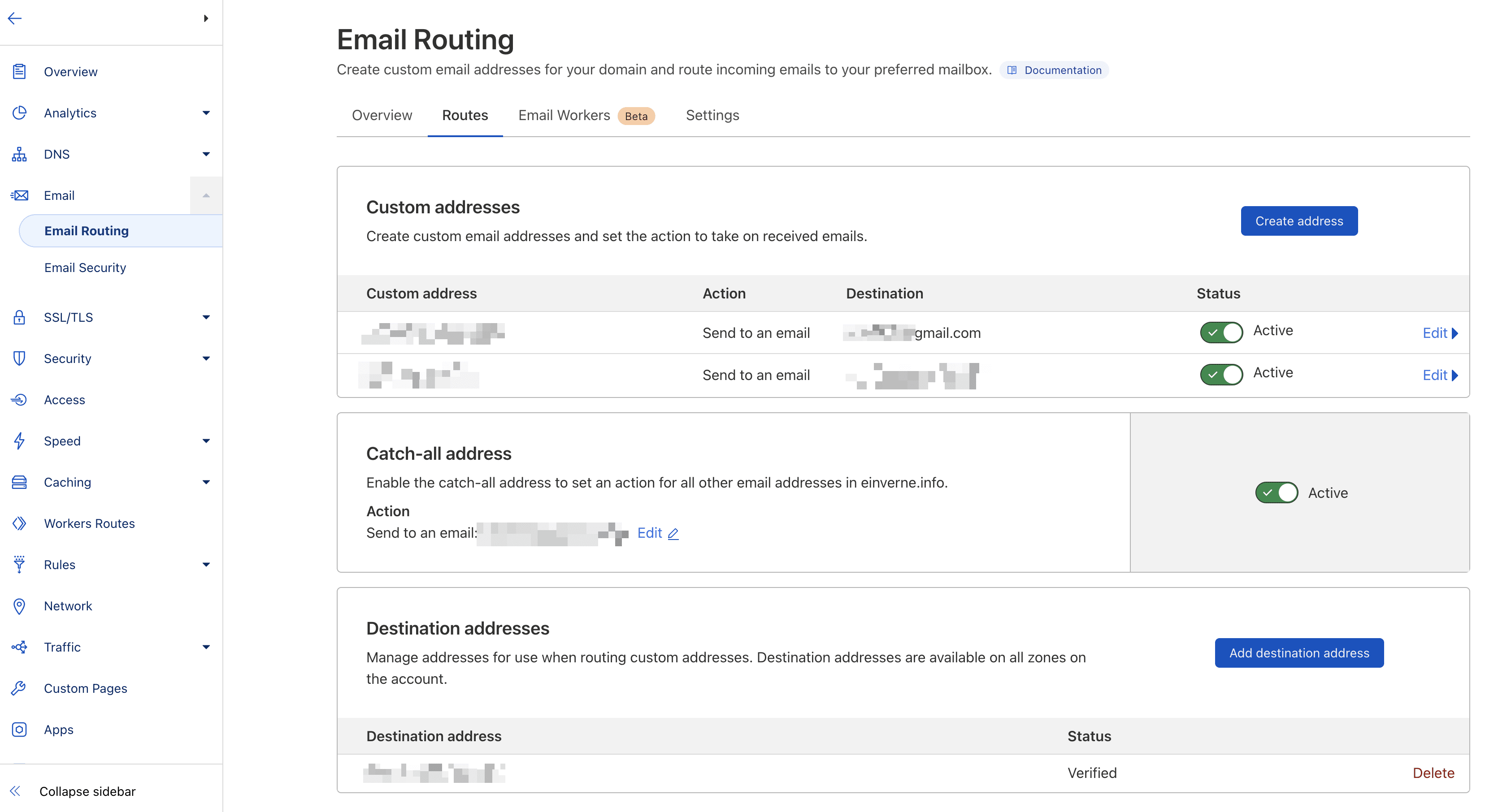
具体步骤:
- 点击电子邮件 -> 开始使用
- 创建自定义邮件地址
- 会收到一封验证电子邮件路由地址邮件,点击验证电子邮箱地址,验证成功后会提示启用电子邮件路由,点击添加记录并启用
- Cloudflare 会自动设置 DNS 记录
随后发往该域名邮箱的所有邮件都会通过 Cloudflare 转发到指定的 Gmail 中。
发送邮件
使用 Cloudflare 的域名邮箱发送邮件则需要用到 Gmail 中的设定。Cloudflare Email Routing 自身是不支持发送邮件的。但可以通过如下方法实现域名邮箱的发送:
- Gmail SMTP
- [[sendinblue]] 等等第三方邮件发送服务提供商
- [[AWS SES]] 邮件发送服务
首先要生成应用专用密码,主要用来代替密码来登录 Gmail,如下图,记住生成的密码。
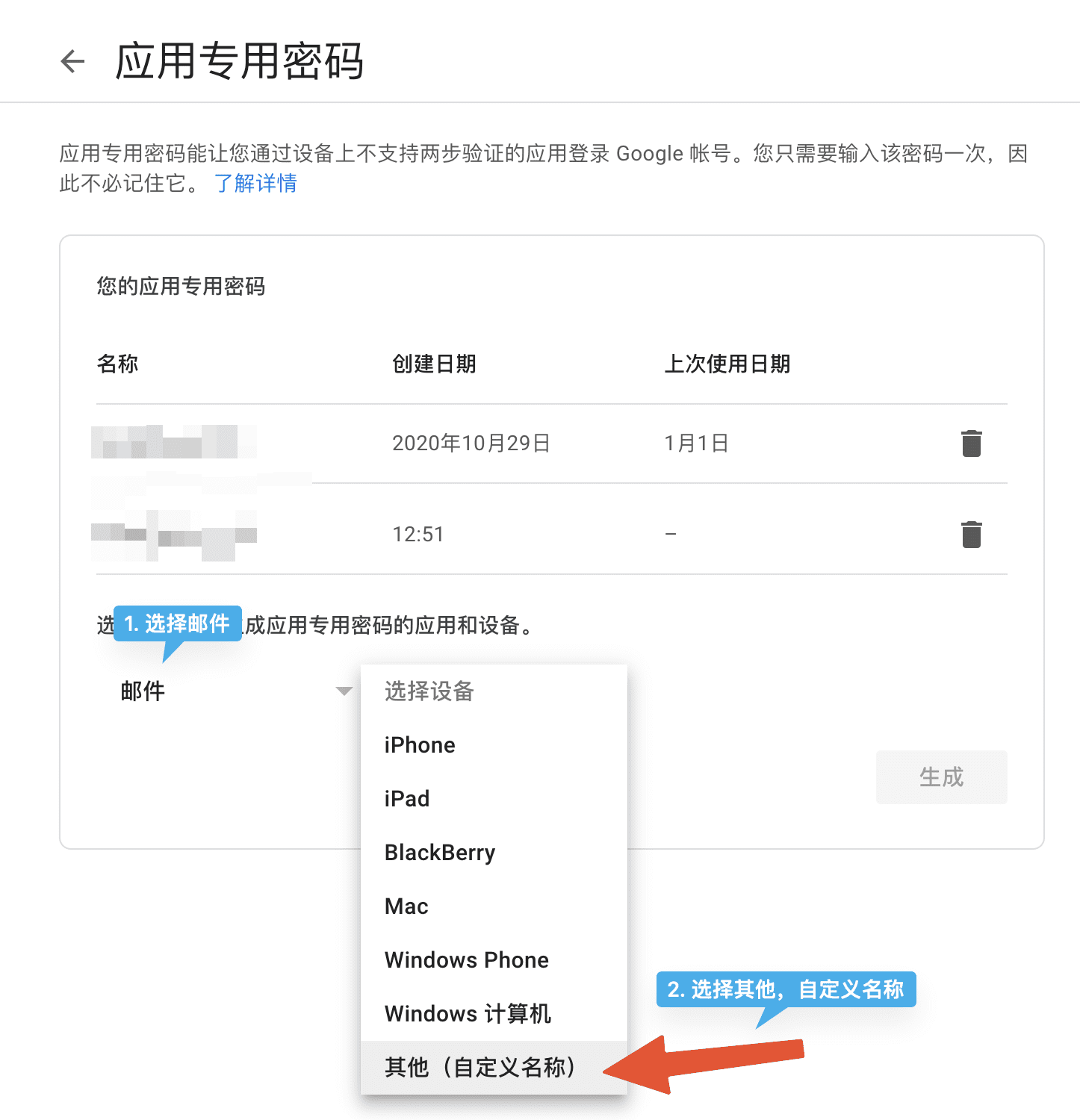
然后打开 Gmail,点击「Settings」,在所有的设置中,找到 「Accounts and Import」,在「Send mail as」中,点击「Add another email address」。
在弹出的对话框中设置「Name」和 「Email address」:
- 邮箱名字用于发送邮件的默认名,会显示在邮件上
- 域名邮箱地址填写 Cloudflare 中配置的邮箱,确保可以接收邮件
然后进入下一步:
- SMTP 填写
smtp.gmail.com - port 端口默认
- username 填写 Gmail 账号
- password 填写之前获取的专属应用密码
填写成功之后,需要填入验证码,域名邮箱会收到一份邮件,包含验证码,在页面上填入即可。
完成配置之后,在发送邮件的时候就可以选择自定义的邮箱了。
不过需要注意的是,通过 Gmail 代发的邮件在 QQ 邮箱,163 邮箱等邮箱中会显示代发邮箱本身,并且会出现「此地址未验证,请注意识别」等等字样。如果介意这一点,可能还是需要找一家正规的域名邮箱服务提供商比较合适。我也在提供付费的域名邮箱服务,如果感兴趣可以点击这里。
使用 ed25519 SSH Key 代替 RSA 密钥
什么是 ed25519
ed25519 是一个相对较新的加密算法,实现了 Edwards-curve Digital Signature Algorithm(EdDSA)。但实际上 ed25519 早已经在 5 年前就被 OpenSSH 实现,并不算什么前沿科技。但很多人,即使是每天都使用 SSH/SCP 的人可能并不清楚这个新类型 key。
不过要注意的是并不是所有的软件目前都实现了 ed25519,但是大多数最近的操作系统 SSH 都已经支持了。
ed25519 的好处
- 相较于 RSA key,最明显的一个好处就是 ed25519 key 非常短,这就非常方便存储以及传输 key
- 另外就是产生和校验更快
- collision resilience,这意味着可以有效的避免 hash 碰撞攻击
生成 ed25519 SSH key
ssh-keygen -t ed25519 -C "your@gmail.com"
可以检查 ~/.ssh 目录下的 key,会发现 ed25519 的公钥只有简短的一行:
ssh-ed25519 AAAACxxxx your@gmail.com
Laravel 学习笔记:Model Factoris 批量创建假数据
在开发环节要测试的时候,如果想要在数据库中批量插入一些假数据,这个时候就可以使用 model factories。
在 database/factories/ 目录下面默认定义了一个 UserFactory.php
namespace Database\Factories;
use Illuminate\Database\Eloquent\Factories\Factory;
use Illuminate\Support\Str;
class UserFactory extends Factory
{
/**
* Define the model's default state.
*
* @return array
*/
public function definition()
{
return [
'name' => $this->faker->name(),
'email' => $this->faker->unique()->safeEmail(),
'email_verified_at' => now(),
'password' => '$2y$10$92IXUNpkjO0rOQ5byMi.Ye4oKoEa3Ro9llC/.og/at2.uheWG/igi', // password
'remember_token' => Str::random(10),
];
}
}
可以看到在这个类中给 User 的每一个字段都设置了一个 faker 方法。
产生 Factories
通过命令:
php artisan make:factory UserFactory
这个时候在 database/factories 下面就会有一个 UserFactory,你需要按照 faker 的方式给 Model 每一个自定义的字段都加上 fake 方式。
tinker
然后执行 tinker:
php artisan tinker
进入交互式命令行之后:
use App\Models\User;
User::factory(10)->create();
执行完成之后就会往数据库中插入 10 条假数据。
Laravel 学习笔记:分页
Laravel 的分页实现集成了 Query Builder 和 Eloquent ORM,提供了一种非常方便的分页接口。
基础使用
最简单的方式就是使用 query builder 和 Eloquent query 的 paginate 方法,这个方法会自动处理请求的 limit 和 offset 参数。
默认情况下,当前页面的参数使用 page 表示。
所以在 Controller 中直接指定一页请求的条数即可:
<?php
namespace App\Http\Controllers;
use App\Http\Controllers\Controller;
use Illuminate\Support\Facades\DB;
class UserController extends Controller
{
/**
* Show all application users.
*
* @return \Illuminate\Http\Response
*/
public function index()
{
return view('user.index', [
'users' => DB::table('users')->paginate(15)
]);
}
}
默认情况下 paginate 方法会统计总条数,如果不需要,可以使用
$users = DB::table('users')->simplePaginate(15);
如果使用 Eloquent,可以直接在 Model 上调用:
$users = User::paginate(15);
排序
如果要倒序来分页,有两种写法,一种是直接使用 DB:
$ondata = DB::table('official_news')->orderBy('created_date', 'desc')->paginate(10);
另外一种就是使用 Model:
$posts = Post::orderBy('id', 'desc')->paginate(10);
Cursor 分页
除了使用 offset 方式分页,还可以使用游标:
$users = DB::table('users')->orderBy('id')->cursorPaginate(15);
这样每一次请求,会在分页请求中带上 cursor 参数:
http://localhost/users?cursor=eyJpZCI6MTUsIl9wb2ludHNUb05leHRJdGVtcyI6dHJ1ZX0
表示了下一页的开始。
- 对于大数据表,游标分页可以提供更好的性能,在使用
order by,并且有索引的情况下 - 如果数据表经常写,offset 分页可能会跳过记录或者出现重复条数,如果有记录被频繁的增加,或删除的话
分页的一些问题和局限:
simplePaginate只能显示Next和Previous链接,无法支持展示页码- 需要排序的列是唯一的,包含 null 的列无法支持排序
自定义分页 URLs
默认情况下,分页器产生的链接会匹配请求的 URI。withPath 方法允许自定义 URL。
如果想要产生的链接是 http://example.com/admin/users?page=N 需要传入 /admin/users
use App\Models\User;
Route::get('/users', function () {
$users = User::paginate(15);
$users->withPath('/admin/users');
//
});
展示分页结果
当调用 paginate 方法时,会获得一个 Illuminate\Pagination\LengthAwarePaginator 实例,当调用 simplePaginate 方法时,会获得 Illuminate\Pagination\Paginator.
cursorPaginate 会获得 Illuminate\Pagination\CursorPaginator。
这些对象都提供了一些方法来获取结果集。
<div class="container">
@foreach ($users as $user)
@endforeach
</div>
Laravel 学习笔记:Model 之间关系
Laravel 使用的 Eloquent ORM 中的 Model 可以用一种非常易读的方式去定义 Model 和 Model 之间的关系。
1 对 1 关系
比如 User 和 Phone 都是一个 Model,要去表示用户和 Phone 的关系,可以:
<?php
namespace App\Models;
use Illuminate\Database\Eloquent\Model;
class User extends Model
{
/**
* Get the phone associated with the user.
*/
public function phone()
{
return $this->hasOne(Phone::class);
}
}
在 User Model 中定义 phone() 方法,然后使用 Illuminate\Database\Eloquent\Model 中定义的 hasOne() 方法。
hasOne() 方法的第一个参数是 Model 的类名。一旦定义了就可以动态的直接通过用户 Model 去访问 Phone
$phone = User::find(1)->phone;
上面的方式默认 Phone 这个 Model 中有一个 user_id 的外键。如果定义了其他名字,可以将外键名字传入第二个参数:
return $this->hasOne(Phone::class, 'foreign_key');
定义一对一逆向关系
比如 Phone 属于用户:
<?php
namespace App\Models;
use Illuminate\Database\Eloquent\Model;
class Phone extends Model
{
/**
* Get the user that owns the phone.
*/
public function user()
{
return $this->belongsTo(User::class);
}
}
Eloquent 会按照约定,假设 Phone model 中含有一个 user_id 列。
一对多关系
一对多关系通常用来定义一个 Model 是其他 Model 的父节点。比如一篇文章可嗯有无数的评论。
<?php
namespace App\Models;
use Illuminate\Database\Eloquent\Model;
class Post extends Model
{
/**
* Get the comments for the blog post.
*/
public function comments()
{
return $this->hasMany(Comment::class);
}
}
注意 Eloquent 会自动决定外键的列名,按约定,Eloquent 会自动使用 parent model 的 snake case 名字然后加上 _id 作为外键。所以上面的例子中,Eloquent 会自动认为 Comment model 中有一个 post_id 的外键。
一旦定义了关系,就可以动态的获取:
use App\Models\Post;
$comments = Post::find(1)->comments;
foreach ($comments as $comment) {
//
}
逆向一对多关系
使用 belongsTo 方法:
<?php
namespace App\Models;
use Illuminate\Database\Eloquent\Model;
class Comment extends Model
{
/**
* Get the post that owns the comment.
*/
public function post()
{
return $this->belongsTo(Post::class);
}
}
获取:
use App\Models\Comment;
$comment = Comment::find(1);
return $comment->post->title;
多对多关系
最常见的多对多关系就是,用户-角色,用户可能有多重角色,同一个角色也会有不同的用户。另外一个比较常见的场景就是标签系统,一本书会有标签1,2,3,标签1也会包含多本书。
class User extends Model
{
public function roles() {
return $this->belongsToMany(
Role:class,
// pivot table
'role_user',
'user_id',
'role_id'
)
}
}
Role 定义:
class Role extends Model {
public function users() {
return $this->belongsToMany(
User:class,
'role_user',
'role_id',
'user_id'
)
}
}
远程一对一
三个 Model 之间都是一对一关系,那么就可以建立远程一对一关系。
Laravel 学习笔记:事件
Laravel Event 提供了一个最简单的观察者模式实现,可以订阅监听应用中发生的事件。事件通常放在 app/Events 目录,监听器放在 app/Listeners。
事件是应用功能模块之间解耦的有效方法。单个事件可以有多个监听器,监听器之间相互没有影响。
比如说每次有订单产生时,发送给用户一个 Slack 通知,通过事件,可以将处理订单的代码和 Slack 通知代码解耦,只需要发起一个事件,监听器监听订单产生事件,然后触发响应的动作即可。
注册事件/监听器
可以使用如下的命令创建 Event
php artisan event:generate
或者分别单独创建 Event 和 Listener:
php artisan make:event PodcastProcessed
php artisan make:listener SendPodcastNotification --event=PodcastProcessed
然后需要手动添加到 EventServiceProvider 的 boot 方法中。
EventServiceProvider 中的 $listen 数组配置了监听器:
protected $listen = [
Registered::class => [
SendEmailVerificationNotification::class,
],
];
Defining Event
Event class 是一个包含了 Event 信息的数据容器。
<?php
namespace App\Events;
use App\Models\Subscribe;
use Illuminate\Broadcasting\Channel;
use Illuminate\Broadcasting\InteractsWithSockets;
use Illuminate\Broadcasting\PresenceChannel;
use Illuminate\Broadcasting\PrivateChannel;
use Illuminate\Contracts\Broadcasting\ShouldBroadcast;
use Illuminate\Foundation\Events\Dispatchable;
use Illuminate\Queue\SerializesModels;
class SubscribeEvent
{
use Dispatchable, InteractsWithSockets, SerializesModels;
public $subscribe;
/**
* Create a new event instance.
*
* @return void
*/
public function __construct(Subscribe $subscribe)
{
$this->$subscribe = $subscribe;
}
/**
* Get the channels the event should broadcast on.
*
* @return \Illuminate\Broadcasting\Channel|array
*/
public function broadcastOn()
{
return new PrivateChannel('channel-name');
}
}
可以看到 Event 中几乎没有什么逻辑,只是保存了一个 Subscribe Model。
Defining Listeners
Event listeners 会在 handle 方法中被触发。也 handle 方法中可以执行对应的事件响应。
<?php
namespace App\Listeners;
use App\Events\SubscribeEvent;
use Illuminate\Contracts\Queue\ShouldQueue;
use Illuminate\Queue\InteractsWithQueue;
class SubscribeListener
{
/**
* Create the event listener.
*
* @return void
*/
public function __construct()
{
//
}
/**
* Handle the event.
*
* @param object $event
* @return void
*/
public function handle(SubscribeEvent $event)
{
//
}
}
handle 方法会接受一个 Event 参数,这个参数就是定义的 Event。
定义好 Event 和 Listener 之后,在 EventServiceProvider 注册,就可以通过
event(new \App\Events\SubscribeEvent($subscribe));
来触发事件。
Queued Event Listener
如果你要在 Listener 中执行一些繁重的操作,那么可以使用 Queued Event Listener:
在 Listener 上指定实现 ShouldQueue,然后记得配置好队列。
<?php
namespace App\Listeners;
use App\Events\OrderShipped;
use Illuminate\Contracts\Queue\ShouldQueue;
class SendShipmentNotification implements ShouldQueue
{
//
}
这样,当一个事件发生后,Listener 会自动被添加到队列中。
Dispatching Events
可以调用 Events 的 dispatch() 方法。
Event Subscribers
Laravel 学习笔记:队列
当需要构建一个网络应用的时候,可能有一些任务,比如解析、存储、传输 CSV 文件等等,可能需要花费较长的时间。Laravel 提供了一个非常简单的队列 API,可以让这些操作可以在后台进行。让这些繁重的任务在后台执行可以有效的提高应用的响应速度,提升用户使用体验。
Laravel 队列提供了一个统一的 API 访问入口,可以支持不同的队列:
- [[Amazon SQS]]
- [[Redis]]
- [[Beanstalk]]
- 甚至关系型数据库
Laravel 队列的配置在 config/queue.php 中。
Laravel 还提供了一个 Redis 队列的 Dashboard 叫做 Horizon。但是这一篇文章不会涉及到 Horizon 相关内容。
Connection Vs. Queues
Laravel 队列的相关配置都在 config/queue.php 配置文件,其中有一个 connections 配置数组。这个选项用来定义和后端队列服务(比如 Amazon SQS,Beanstalk,Redis) 的连接。
每一个 connection 配置,都有一个 queue 属性。如果没有指定队列,那么就会放到 default
use App\Jobs\ProcessPodcast;
// This job is sent to the default connection's default queue...
ProcessPodcast::dispatch();
// This job is sent to the default connection's "emails" queue...
ProcessPodcast::dispatch()->onQueue('emails');
Laravel 队列允许用户指定队列的优先级:
php artisan queue:work --queue=high,default
Driver Notes & Prerequisites
Database
如果使用数据库作为队列驱动,那么需要创建一张表来存储队列任务。运行 queue:table 来创建表:
php artisan queue:table
php artisan migrate
最后不要忘了给应用配置 database 驱动:
QUEUE_CONNECTION=database
Redis
如果消息队列使用 Redis Cluster,队列的子必须包含 key hash tag ,为了确保所有的 Redis keys 都在同一个 hash slot:
'redis' => [
'driver' => 'redis',
'connection' => 'default',
'queue' => '{default}',
'retry_after' => 90,
'block_for' => 5,
],
在使用 Redis Queue 的时候,可以使用 block_for 配置,用来指定驱动应该等待多久才 Redis 中拉取数据。
如果要使用其他队列,需要安装其他依赖:
- Amazon SQS:
aws/aws-sdk-php ~3.0 - Beanstalkd:
pda/pheanstalk ~4.0 - Redis:
predis/predis ~1.0or phpredis PHP extension
Creating Jobs
默认所有的队列任务存放在 app/Jobs 目录中,如果目录不存在可以用 artisan 命令生成:
php artisan make:job ProcessPodcast
产生的类会实现 Illuminate\Contracts\Queue\ShouldQueue 接口,告诉 Laravel 这个任务应该被放到队列中异步执行。
Job 类非常简单,包含一个 handle 方法,会被队列调用。
<?php
namespace App\Jobs;
use App\Models\Podcast;
use App\Services\AudioProcessor;
use Illuminate\Bus\Queueable;
use Illuminate\Contracts\Queue\ShouldQueue;
use Illuminate\Foundation\Bus\Dispatchable;
use Illuminate\Queue\InteractsWithQueue;
use Illuminate\Queue\SerializesModels;
class ProcessPodcast implements ShouldQueue
{
use Dispatchable, InteractsWithQueue, Queueable, SerializesModels;
/**
* The podcast instance.
*
* @var \App\Models\Podcast
*/
protected $podcast;
/**
* Create a new job instance.
*
* @param App\Models\Podcast $podcast
* @return void
*/
public function __construct(Podcast $podcast)
{
$this->podcast = $podcast;
}
/**
* Execute the job.
*
* @param App\Services\AudioProcessor $processor
* @return void
*/
public function handle(AudioProcessor $processor)
{
// Process uploaded podcast...
}
}
在这个例子中,传入了一个 Eloquent model,因为 Job 使用了 SerializesModels,Eloquent models 会自动序列化和反序列化。
二进制数据,比如图片内容,应该通过 base64_encode 方法,然后再传入队列。否则任务可能无法序列化成 JSON,然后放到队列中。
可能 model 的关系也会被序列化,这可能会很大,所以为了避免 model 关系被序列化,可以调用 withoutRelations
public function __construct(Podcast $podcast)
{
$this->podcast = $podcast->withoutRelations();
}
Unique Jobs
有些时候期望只有一个实例任务会被放到队列中,可以实现 ShouldBeUnique:
<?php
use Illuminate\Contracts\Queue\ShouldQueue;
use Illuminate\Contracts\Queue\ShouldBeUnique;
class UpdateSearchIndex implements ShouldQueue, ShouldBeUnique
{
...
}
上面的例子中,UpdateSearchIndex 任务是唯一的,这就保证了如果队列中的任务没有完成,就不会有新的任务被加入进去。
可以通过 uniqueId 和 uniqueFor 属性来特别指定想要的主键:
<?php
use App\Product;
use Illuminate\Contracts\Queue\ShouldQueue;
use Illuminate\Contracts\Queue\ShouldBeUnique;
class UpdateSearchIndex implements ShouldQueue, ShouldBeUnique
{
/**
* The product instance.
*
* @var \App\Product
*/
public $product;
/**
* The number of seconds after which the job's unique lock will be released.
*
* @var int
*/
public $uniqueFor = 3600;
/**
* The unique ID of the job.
*
* @return string
*/
public function uniqueId()
{
return $this->product->id;
}
}
保持任务唯一,直到开始处理,可以实现 ShouldBeUniqueUntilProcessing 。
Job Middleware
速率限制 限流
需要在 AppServiceProvider 类的 boot 方法中定义一个 RateLimiter
use Illuminate\Cache\RateLimiting\Limit;
use Illuminate\Support\Facades\RateLimiter;
/**
* Bootstrap any application services.
*
* @return void
*/
public function boot()
{
RateLimiter::for('backups', function ($job) {
return $job->user->vipCustomer()
? Limit::none()
: Limit::perHour(1)->by($job->user->id);
});
}
防止任务重叠
避免一个任务在修改资源的时候,另一个任务也在修改。
Throttling Exceptions
当和一个不稳定的外部接口通信时,一旦抛出异常,可以制定 Throttling Exceptions 机制,定义一个重试时间。
通常情况下如果一个任务抛出了异常,任务会马上重试。
Dispatching Jobs
一旦写好了任务类,就可以使用 dispatch 方法来分发。
可以在 Controller 中手动分发任务。
<?php
namespace App\Http\Controllers;
use App\Http\Controllers\Controller;
use App\Jobs\ProcessPodcast;
use App\Models\Podcast;
use Illuminate\Http\Request;
class PodcastController extends Controller
{
/**
* Store a new podcast.
*
* @param \Illuminate\Http\Request $request
* @return \Illuminate\Http\Response
*/
public function store(Request $request)
{
$podcast = Podcast::create(...);
// ...
ProcessPodcast::dispatch($podcast);
}
}
如果想要有条件分发任务可以使用 dispatchIf 或者 dispatchUnless。
延迟分发
可以使用 delay 方法来延迟分发任务:
<?php
namespace App\Http\Controllers;
use App\Http\Controllers\Controller;
use App\Jobs\ProcessPodcast;
use App\Models\Podcast;
use Illuminate\Http\Request;
class PodcastController extends Controller
{
/**
* Store a new podcast.
*
* @param \Illuminate\Http\Request $request
* @return \Illuminate\Http\Response
*/
public function store(Request $request)
{
$podcast = Podcast::create(...);
// ...
ProcessPodcast::dispatch($podcast)
->delay(now()->addMinutes(10));
}
}
在返回浏览器请求后分发
use App\Jobs\SendNotification;
SendNotification::dispatchAfterResponse();
Job Chaining
Job chaining 允许你指定一组任务,这些任务应该按照顺序依次执行,如果一个任务失败了,接下来的任务就不会执行。
use App\Jobs\OptimizePodcast;
use App\Jobs\ProcessPodcast;
use App\Jobs\ReleasePodcast;
use Illuminate\Support\Facades\Bus;
Bus::chain([
new ProcessPodcast,
new OptimizePodcast,
new ReleasePodcast,
])->dispatch();
或者:
Bus::chain([
new ProcessPodcast,
new OptimizePodcast,
function () {
Podcast::update(...);
},
])->dispatch();
自定义 Queue 和 Connection
向特定队列分发任务。
<?php
namespace App\Http\Controllers;
use App\Http\Controllers\Controller;
use App\Jobs\ProcessPodcast;
use App\Models\Podcast;
use Illuminate\Http\Request;
class PodcastController extends Controller
{
/**
* Store a new podcast.
*
* @param \Illuminate\Http\Request $request
* @return \Illuminate\Http\Response
*/
public function store(Request $request)
{
$podcast = Podcast::create(...);
// Create podcast...
ProcessPodcast::dispatch($podcast)->onQueue('processing');
}
}
或者直接在任务的构造方法中定义:
<?php
namespace App\Jobs;
use Illuminate\Bus\Queueable;
use Illuminate\Contracts\Queue\ShouldQueue;
use Illuminate\Foundation\Bus\Dispatchable;
use Illuminate\Queue\InteractsWithQueue;
use Illuminate\Queue\SerializesModels;
class ProcessPodcast implements ShouldQueue
{
use Dispatchable, InteractsWithQueue, Queueable, SerializesModels;
/**
* Create a new job instance.
*
* @return void
*/
public function __construct()
{
$this->onQueue('processing');
}
}
分发到指定 Connection
如果应用和多个队列 connection 交互,可以使用 onConnection 来指定:
<?php
namespace App\Http\Controllers;
use App\Http\Controllers\Controller;
use App\Jobs\ProcessPodcast;
use App\Models\Podcast;
use Illuminate\Http\Request;
class PodcastController extends Controller
{
/**
* Store a new podcast.
*
* @param \Illuminate\Http\Request $request
* @return \Illuminate\Http\Response
*/
public function store(Request $request)
{
$podcast = Podcast::create(...);
// Create podcast...
ProcessPodcast::dispatch($podcast)->onConnection('sqs');
}
}
同样的是,也可以在构造方法中指定:
public function __construct()
{
$this->onConnection('sqs');
}
Running The Queue Worker
Laravel 包括了一个 Artisan 命令可以用来开始一个队列的 worker,开始处理新的任务。
可以使用 queue:work 命令:
php artisan queue:work
为了使得 queue:work 命令常驻后台,可以使用进程管理器 Supervisor。
注意,queue workers 会将应用保存到内存中。这也就意味着代码的改动不会立即生效。在开发的过程中,注意重启 queue workers。
或者可以执行 queue:listen 命令
php artisan queue:listen
该命令只建议在开发过程中使用。
Supervisor 配置
安装 Supervisor
sudo apt install supervisor
Supervisor 的配置在 /etc/supervisor/conf.d 目录中。可以创建 laravel-worker.conf 文件:
[program:laravel-worker]
process_name=%(program_name)s_%(process_num)02d
command=php /home/einverne/app.com/artisan queue:work sqs --sleep=3 --tries=3 --max-time=3600
autostart=true
autorestart=true
stopasgroup=true
killasgroup=true
user=forge
numprocs=8
redirect_stderr=true
stdout_logfile=/home/einverne/app.com/worker.log
stopwaitsecs=3600
然后启动 Supervisor
sudo supervisorctl reread
sudo supervisorctl update
sudo supervisorctl start laravel-worker:*
处理失败的任务
Laravel 提供了很多方式了定义任务可以重试的次数,一旦次数达到,任务就会被放到失败队列。
Cleaning Up After Failed Jobs
当一个任务失败时,你可能希望执行一些操作,比如发送通知,或者更新一些数据,这个时候可以定义 failed 方法。
public function failed(Throwable $exception)
{
// Send user notification of failure, etc...
}
发送邮件时使用队列
上一篇文章讲到了发送邮件,而发送邮件对于应用的响应时间有直接负面影响,生产环境最好的方式就是将发送邮件的过程放入队列中,在后台进行操作。
Laravel 有一个内置的队列,在发送邮件的时候直接使用 queue 方法:
Mail::to($request->user())
->cc($moreUsers)
->bcc($evenMoreUsers)
->queue(new OrderShipped($order));
在使用 queue 之前需要配置队列。
文章分类
最近文章
- Dinox 又一款 AI 语音实时转录工具 前两天介绍过 [[Voicenotes]],也是一款 AI 转录文字的笔记软件,之前在调查 Voicenotes 的时候就留意到了 Dinox,因为是在小红书留意到的,所以猜测应该是国内的某位独立开发者的作品,整个应用使用起来也比较舒服,但相较于 Voicenotes,Dinox 更偏向于一个手机端的笔记软件,因为他整体的设计中没有将语音作为首选,用户也可以添加文字的笔记,反而在 Voicenotes 中,语音作为了所有笔记的首选,当然 Voicenotes 也可以自己编辑笔记,但是语音是它的核心。
- 音流:一款支持 Navidrom 兼容 Subsonic 的跨平台音乐播放器 之前一篇文章介绍了Navidrome,搭建了一个自己在线音乐流媒体库,把我本地通过 [[Syncthing]] 同步的 80 G 音乐导入了。自己也尝试了 Navidrome 官网列出的 Subsonic 兼容客户端 [[substreamer]],以及 macOS 上面的 [[Sonixd]],体验都还不错。但是在了解的过程中又发现了一款中文名叫做「音流」(英文 Stream Music)的应用,初步体验了一下感觉还不错,所以分享出来。
- 泰国 DTV 数字游民签证 泰国一直是 [[Digital Nomad]] 数字游民青睐的选择地,尤其是清迈以其优美的自然环境、低廉的生活成本和友好的社区氛围而闻名。许多数字游民选择在泰国清迈定居,可以在清迈租用廉价的公寓或民宿,享受美食和文化,并与其他数字游民分享经验和资源。
- VoceChat 一款可以自托管的在线聊天室 VoceChat 是一款使用 Rust(后端),React(前端),Flutter(移动端)开发的,开源,支持独立部署的在线聊天服务。VoceChat 非常轻量,后端服务只有 15MB 的大小,打包的 Docker 镜像文件也只有 61 MB,VoceChat 可部署在任何的服务器上。
- 结合了 Google 和 AI 的对话搜索引擎:Perplexity AI 在日本,因为 SoftBank 和 Perplexity AI 开展了合作 ,所以最近大量的使用 Perplexity ,这一篇文章就总结一下 Perplexity 的优势和使用技巧。