macOS 上的清理工具整理合集
最近 macOS 系统磁盘空间告急,之前就出现过因为磁盘空间不足导致系统卡顿还出现突然黑屏的状态,所以这次就看到还剩余几十个 GB 的时候就开始清理工作了。清理的同时顺便就整理一下常用的几个清理工具。
如何发现大文件
在清理之前首先要对本地磁盘文件做一个整体的了解,虽然 macOS 自带一个存储管理的查看面板,但是实在是太简陋,也只能提供非常简单地查找大文件的工具。
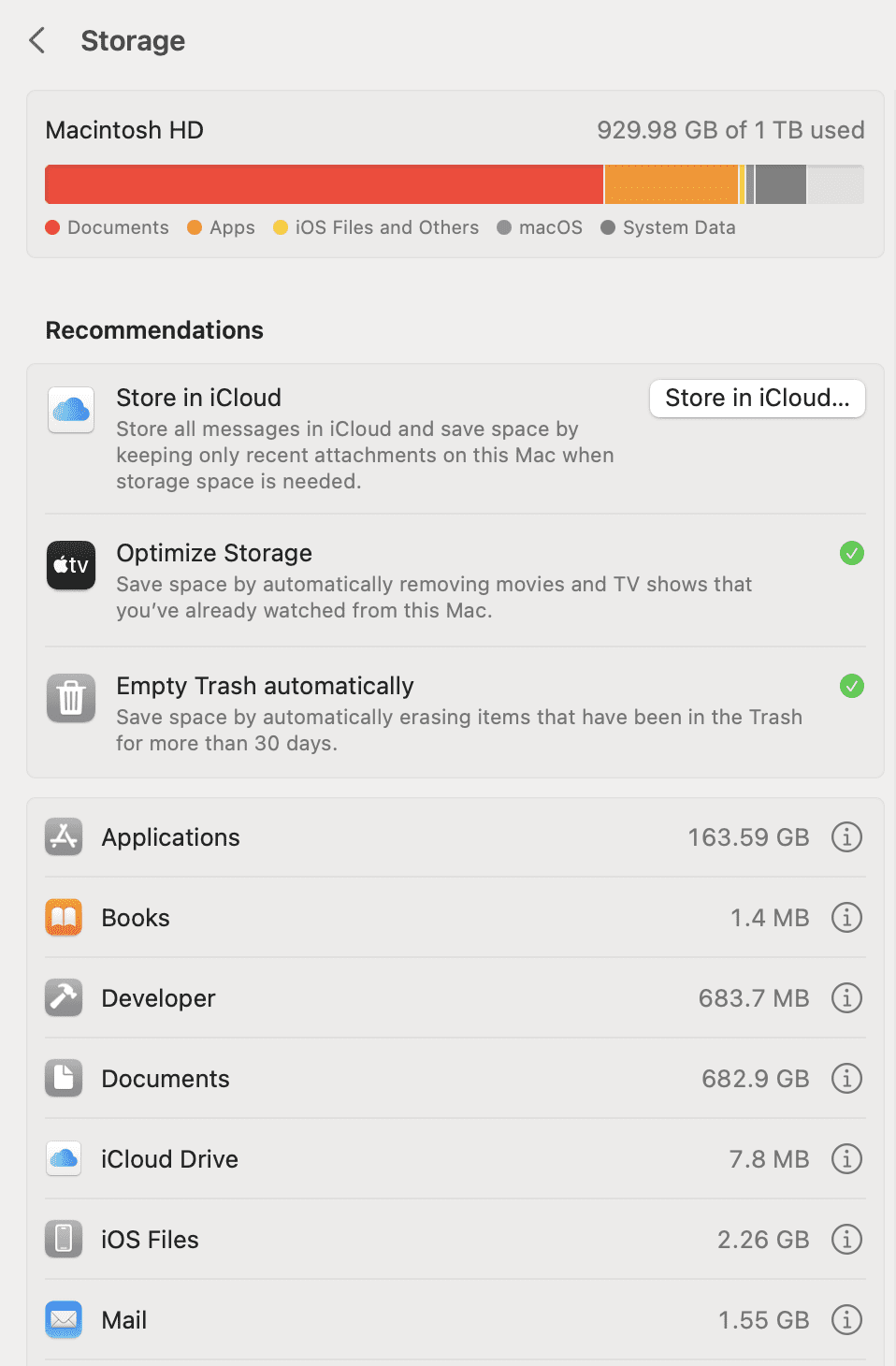
比如说从系统提供的 Storage 预览中能看到 Documents 占用的空间最多,可以点开后面的圆形 i 图标,可以看到其中占用空间很大的几个文件。
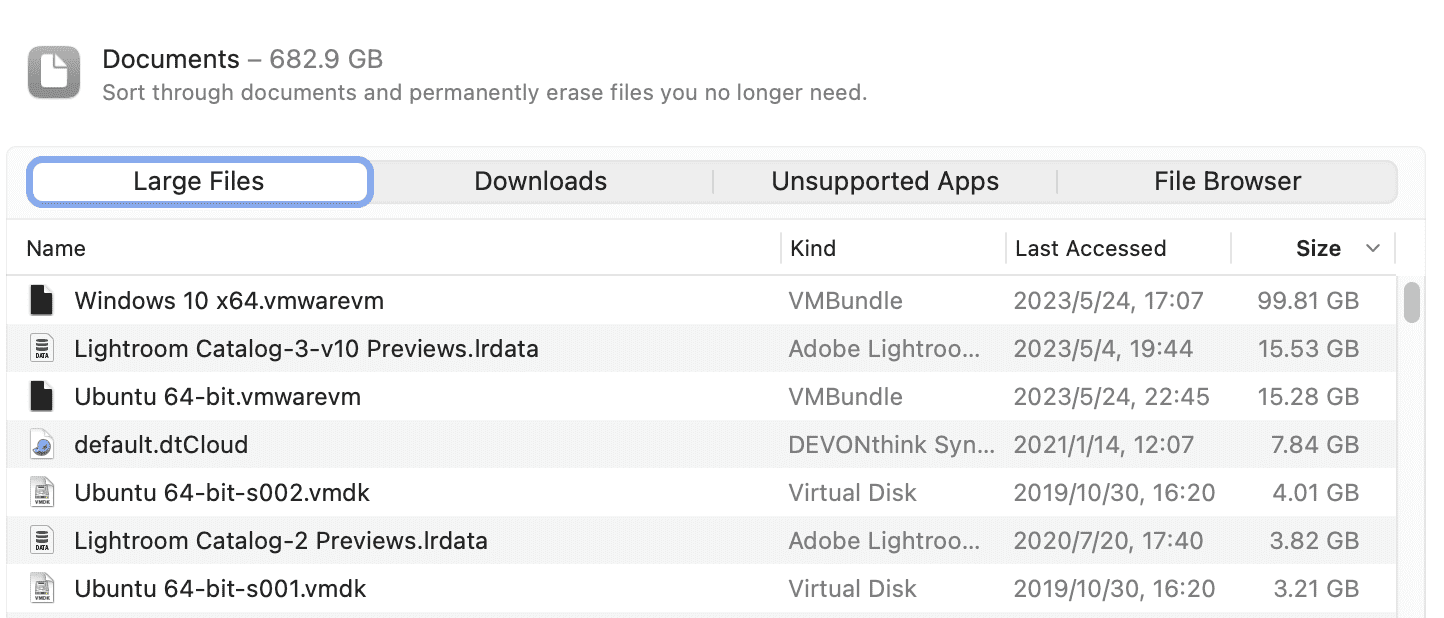
比如说对于我,就是我安装的两个虚拟机占用了比较多的空间,但这也是预想之内的。
gdu
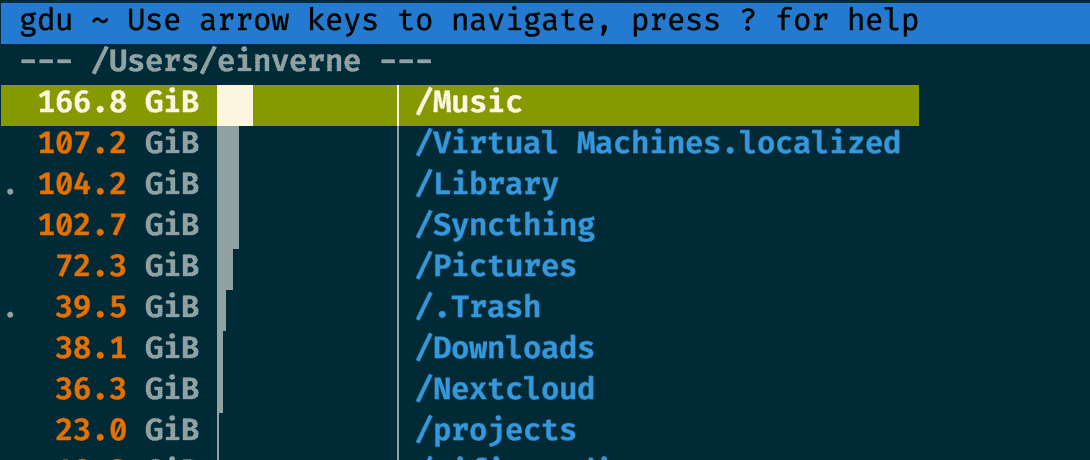
上面的方式只能找出来系统中的大文件所在,如果我想知道每一个文件夹所占用的空间大小,我之前的文章中介绍过gdu ,这个时候就派上了用场。
brew install gdu
然后直接对想要统计的目录运行 sudo gdu ~/
几款 macOS 上的清理工具
- [[Clean My Mac]] 收费软件
- [[Pretty Clean]] Pretty Clean 免费
- [[App Cleaner]] 免费,卸载应用
- [[Clean Me]] Clean Me 是一款开源的清理磁盘工具
Pretty Clean
PrettyClean 是一款 macOS 上的免费清理工具,界面非常简单。
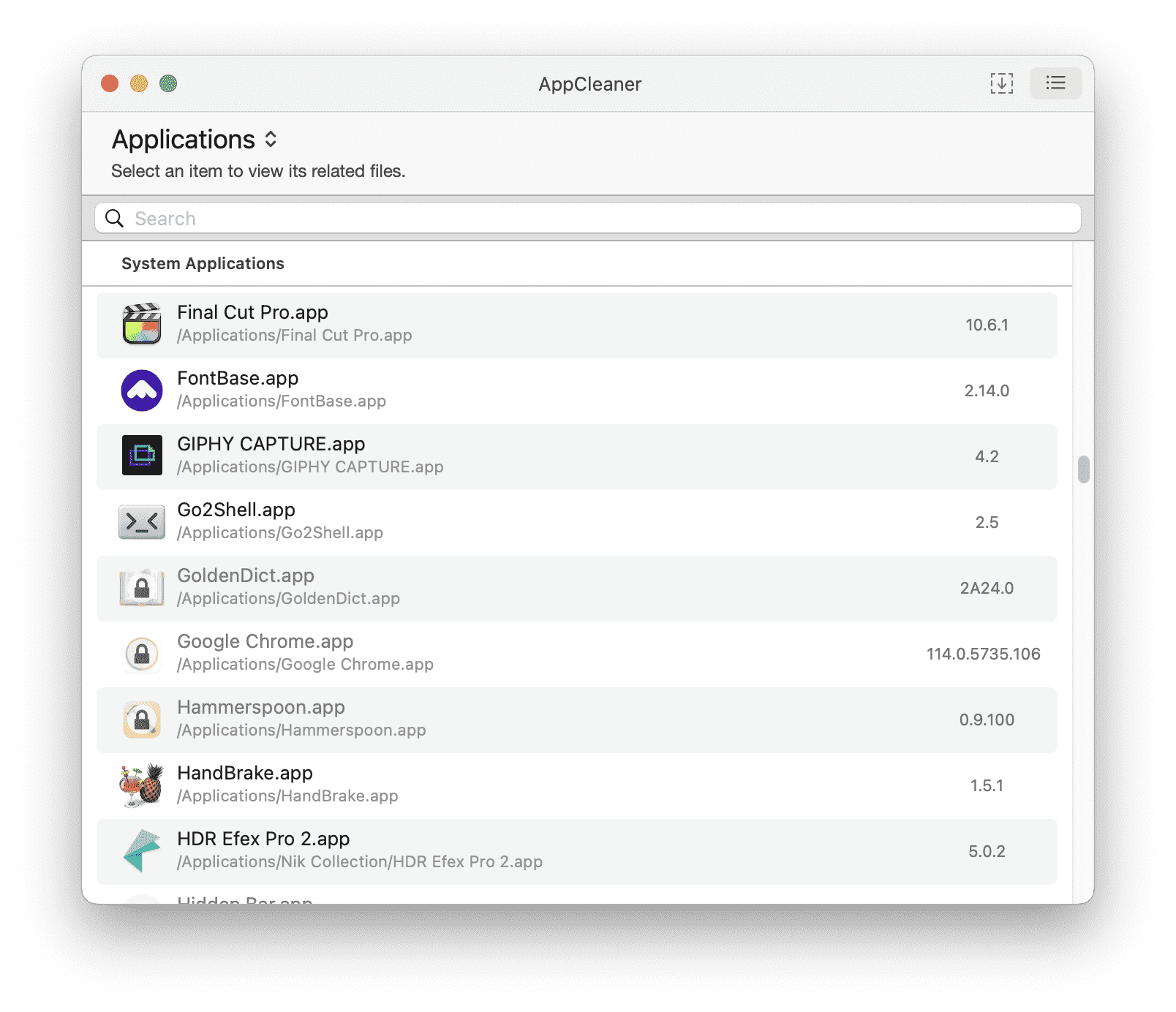
App Cleaner
App Cleaner 是一款可以用来快速卸载应用以及应用相关残留文件的应用,非常小巧,但是非常强大。
脚本
- mac-cleanup-py 是一个使用 Python 编写的 macOS 上的清理脚本。
使用 Listmonk 搭建自己的 Newsletter
listmonk 是一个开源的,使用 Go 语言编写的,自托管的邮件列表订阅应用。目前已经在 GitHub 收获了超过 10000 颗星星,listmon 速度非常快,功能丰富,并且可以直接打包成一个二进制文件,和 PostgreSQL 数据库一起使用。
借助 listmonk 可以非常快速的搭建属于自己的 Newsletter,Newsletter 是一种基于邮件的时事通讯,企业或组织可以通过邮箱给其成员,客户,员工或其他订阅者发送活动的新闻及广告营销的方式,但最近也逐渐成为个人出版、自媒体的流行订阅形式,相比 RSS,它更加自主,有更好的阅读体验,并且可以有更灵活的付费方式。
特性:
- 支持公共列表和私有列表
- 只依赖 [[PostgreSQL]]
- 拥有管理面板
- 基于 Go 的模板、支持 WYSIWYG 编辑器
- 多线程,多 SMTP 邮件队列,用于快速投递邮件
- HTTP,JSON API
- 点击和视图追踪
- 支持导入 [[MailChimp]] 和 [[Substack]] 的订阅用户
安装
具体的 docker-compose 可以看这里,listmonk 需要依赖一个配置文件,我一般习惯直接放在 HOME 目录中
git clone git@github.com:einverne/dockerfile.git
cd dockerfile/listmonk
cp env .env
# edit .env
# create config.toml
vi ~/listmonk/config.toml
然后填入一下内容。注意将配置文件中的内容填写,比如用户名和密码,数据库连接方式替换为自己的内容。
[app]
# Interface and port where the app will run its webserver.
address = "0.0.0.0:9000"
admin_username = "username"
admin_password = "password"
# Database.
[db]
host = "host"
port = 5432
user = "listmonk"
password = "pass"
database = "listmonk"
ssl_mode = "disable"
max_open = 25
max_idle = 25
max_lifetime = "300s"
当添加完配置文件之后,就可以使用 docker-compose up -d db 来启动数据库了,但是 listmonk 应用不回初始化数据库 Schema,所以还需要进行初始化数据库操作。
docker-compose run --rm app ./listmonk --install
等初始化数据操作完成,可以通过进入 PostgreSQL 容器查看表结构来验证。
docker exec -it listmonk_db /bin/bash
psql -d listmonk -U listmonk -W
\dt
最后就可以启动应用 docker-compose up -d
自定义静态模板文件
这部分内容已经在我上面提及的 docker-compose.yml 文件中存在。
app:
<<: *app-defaults
container_name: listmonk_app
depends_on:
- db
command: "./listmonk --static-dir=/listmonk/static"
volumes:
- "${LISTMONK_CONFIG}/config.toml:/listmonk/config.toml"
- "./static:/listmonk/static"
导入外部订阅用户
加入已经在 [[MailChimp]] 或者 [[Substack]] 上有一定的订阅用户,那么可以通过后台工具导入 csv 文件。但需要注意的是,导入的用户默认状态是 Unconfirmed,所以需要进入数据库手动更新用户的状态。
docker exec -it listmonk_db /bin/bash
psql -d listmonk -U listmonk -W
输入密码登录数据库,然后执行 \dt 查看表。然后查看表内容
SELECT * from subscriber_lists;
然后更新所有人
UPDATE subscriber_lists SET status='confirmed' WHERE list_id=4;
设置 SSL
默认情况下 listmonk 运行在 HTTP,不提供 SSL,我们可以借助 Nginx 和 Let’s Encrypt 来生成证书提供更安全的访问。
有很多种方式可以完成
- 在服务器上安装 Nginx,然后使用 certbot 生成 SSL 证书并自动续期
- 也可以利用 Nginx Proxy Manager 来管理 Docker 中的服务,自动暴露 Docker 端口,然后提供 SSL 访问
- 或者如果不想有一个 Web UI 管理界面,也可以利用 Nginx Proxy 自动管理 Docker 中的服务,生成证书
- 在这边因为我已经安装了 HestiaCP 控制面板 就直接借助其自带的 Nginx
之前好几篇文章也介绍过 HestiaCP 面板中的模板文件,所以这里就简单再总结一下。
首先与进入 root 账户 sudo su -
然后进入如下的目录
cd /usr/local/hestia/data/templates/web/nginx/php-fpm/
这个目录中包含了 HestiaCP 默认的 Nginx 模板。
cp default.tpl listmonk.tpl
cp default.stpl listmonk.stpl
然后分别修改这两个新生成的 listmonk 配置文件。
将其中 location 部分修改
location / {
proxy_pass http://localhost:9001;
proxy_set_header Host $http_host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
}
然后最好把 stpl 文件中的 proxy_hide_header Upgrade; 删除。
再进入 HestiaCP 管理后台,创建用户,然后创建网站,填入域名。创建域名进入高级管理,在 Web Template(Nginx)中选择刚刚创建的 listmonk,保存。然后在高级设置中,配置 SSL,等待获取证书,保存之后就能通过域名来访问 listmonk 了。
Upgrade
如果使用 Docker 安装,那么升级非常简单,更新镜像,更新数据库,重启即可。
docker compose pull
docker compose run --rm app ./listmonk --upgrade
docker compose up app db
related
- [[SendPortal]]
- [[Mautic]]
.box 区块链上的 TLD
今天在 Twiter 上看到 .box 这个顶级域名开始开放 Early Access,然后就突然想起来之前突然某一天 Twitter 大家都换上了 .eth 的昵称。突然很多陌生的名词出现了,比如什么是 ENS,什么是 DID。
什么是 eth
.eth 是 ENS(Ethereum Name Service)域名服务提供的一种以太坊地址命名方式。它是一种去中心化的域名系统,将难以记忆的以太坊地址转换为更容易记忆的名称。.eth 域名可以被认为是一种以太坊上的虚拟资产,可以购买、出售、转让和租赁。与传统的域名系统不同,.eth 域名是在以太坊区块链上注册的,所有权也是通过智能合约进行管理和转移。
什么是 ENS
ENS 全称为 Ethereum Name Service,是以太坊上的一种域名服务,类似于互联网上的 DNS。它通过将以太坊地址映射到易于记忆的名称,使用户能够更轻松地发送和接收加密货币。通过 ENS,用户可以使用类似于“myname.eth”这样的名称来代替其以太坊地址。ENS 名称可以用于接收以太币和其他以太坊资产,还可以用于智能合约和去中心化应用程序(DApps)。
什么是 DID
DID 全称为 Decentralized Identifier,是一种去中心化身份标识符。与传统身份验证方式不同的是,DID 是基于分布式账本技术建立的,它使得用户可以在不泄露自己身份信息的情况下进行认证和授权。每个 DID 都是唯一的,且由该 DID 的所有者完全控制。DID 可以与加密货币钱包等数字身份验证系统相结合,为用户提供更安全、更私密的身份验证方式。
什么是 DAO
DAO 是“去中心化自治组织”的缩写,是一种基于区块链技术的组织形式。DAO 的核心思想是将组织的管理权和所有权分散到所有的成员手中,实现去中心化的组织管理。
DAO 是由一组智能合约和区块链技术构成的自动化组织,它们的运行是由算法和代码决定的,而不是由人类中央管理。成员可以通过投票决定组织的战略、预算、分配和其他重要事项。
DAO 的主要优点是去除了传统组织中的中心化、层级化结构,使组织更加透明、公正和开放。此外,DAO 还可以通过智能合约的执行自动化流程,以降低运营成本和提高效率。但是,DAO 也存在一些风险和挑战,例如智能合约的漏洞、成员之间的信任问题等。
什么是 DApps
DApps 全称为 Decentralized Applications,即去中心化应用程序。与传统的应用程序不同,DApps 是基于区块链技术构建的应用程序,其数据和运行代码存储在区块链网络中,而不是集中式服务器上。DApps 使用智能合约来实现代码逻辑,保证了应用程序的去中心化和安全性,同时也去除了中间商的干预。DApps 可以用于各种场景,如数字货币钱包、去中心化交易所、投票系统、游戏等。
.box
再回到本文的主角 .box 身上,box 是一个基于 Web 3.0 的顶级域名,但是 .box 兼容 Web 2.0 可以直接被访问到。我们知道在加密货币区块链的领域,每个人的帐号都是一大串几乎不能被记忆的地址。Ethereum Name Service (ENS) 就是想要扮演 Web 3.0 的 DNS 系统,让所有的地址都可以通过一次「解析」而被访问到。
box 域名可以作为 :
- DID Profile 或者钱包
- 去中心化的网站
- Web 2 的电子邮件
Ethereum Name Service (ENS) 将会在今年 9 月份发布 .box 域名,注册使用 .box 域名会和 .eth 域名一样,都是通过区块链完成。
.box vs .eth
Ethereum Name Service (ENS)是一种区块链原生的域名系统,为用户在 Web3 和加密平台上提供身份认证。 它与传统域名系统有着相同的基本概念,只是使用了基于以太坊区块链的分布式技术。 ENS 的主要功能是将机器可读的标识符(如加密货币地址)转换为人类可读的域名。ENS 地址或 URL 以.eth 结尾,用简单的域名如”James.eth”取代了加密地址中的长串数字。
每个.eth 域名是用于识别以太坊地址、哈希、元数据和其他基于区块链的地址的标识符。即将推出的.box 命名系统与.eth 类似,主要区别在于.box 域名将通过 ENS 和 Web 浏览器访问,而不使用传统的 Web DNS。通过新的.box 域名,用户可以在当前使用的 Web 浏览器上访问他们的区块链地址。
使用 Atuin 同步 Shell 历史
Atuin 是一个可以同步,备份 Shell 命令历史的服务。借助 Atuin 可以在多台设备之前同步 Shell 命令历史,所有的命令都在数据库(SQLite)中加密存储。
相关命令
安装 Atuin 命令行工具
brew install atuin
安装完成之后配置 ZSH
echo 'eval "$(atuin init zsh)"' >> ~/.zshrc
配置服务器地址,首先创建一个配置文件
vi ~/.config/atuin/config.toml
sync_address = "https://atuin.xxx.com"
注册帐号
atuin register -u username -e email@gmail.com -p password
登录
atuin login -u username -p password
同步
atuin sync
我买了一个 Ledger Nano S Plus
今天我购买了一个 Ledger Nano S Plus,是一个入门款的[[硬件钱包]](冷钱包),借此契机也正好从头开始学习和整理一下[[加密货币]]相关知识。
什么是助记词
之前已经写过一篇文章系统的讲述了什么是助记词,以及为什么可以通过助记词来回复加密货币钱包。简单来说就是助记词就是一连串特定单词组成的字符串,一般是 12 个,或 24 个单词,可以用来备份或恢复钱包的私钥。
什么是硬件钱包(冷钱包)
[[硬件钱包]] (也被称为冷钱包)是一种物理的电子设备,使用随机数生成器(RNG)生成公钥以及私钥。生成的密钥随后存入设备内,设备不会接入互联网,所以比较安全。
Ledger 拿到手之后必须要做的几个事情
照着官方的手册和在线的说明流程,下载 Ledger Live,然后用 USB 数据线连接电脑。设置 4 到 8 位 PIN 码,然后用笔在赠送的纸上写下 24 个助记词(千万记住助记词是不能接触互联网的,不管是记录到电脑中,还是拍照都是不可以的),完成设置之后,可以用 Ledger Live 下载对应的 App 到 Nano S Plus 中之后,就可以创建钱包,生成地址了。
手动恢复钱包 确认助记词
但是为了为了更安全,更熟悉地使用使用硬件钱包,我故意输错了 3 次 PIN 码,让 Ledger 重置,然后再用刚刚记下来的 24 个单词恢复钱包。这一步的目的就是为了确保我记录下来的助记词是完全正确并且可以恢复的。否则如果遇到硬件钱包丢失,或者损毁都可以不再担心,只需要保管好助记词就可以了。
充值少量的 BNB
在恢复完成之后,我又从 [[Binance]] 转出了少量的 BNB 到 Ledger 钱包中,为了确保 Ledger 钱包是完全可以正常工作的。至此初始化的过程就做完了,之后就可以正常的利用起来。
另外一个小技巧就是当只有一个 Ledger 的时候,也可以通过故意输错 PIN 的方式,让设备重置,然后重新生成一个新的助记词,那么原来的钱包还是存在的,也可以定期往其中转入加密货币,但是这个钱包就没有任何设备可以管理。于是就可以通过一个 Ledger 来生成多个钱包的目的。
另外一个需要注意的是,Ledger 生成的助记词是可以恢复到任何厂家的硬件钱包上的,但是需要查看该硬件钱包是否支持全部的币种,如果有不支持的币种,就没有办法管理了。但是不需要荒,加密货币还是在的,只需要将助记词恢复到支持的设备上即可开始管理。另外一个需要注意的是,冷钱包生成的助记词也是可以被恢复到热钱包中的,但是一旦恢复到热钱包中,那么这个钱包就不再「安全」。
最后
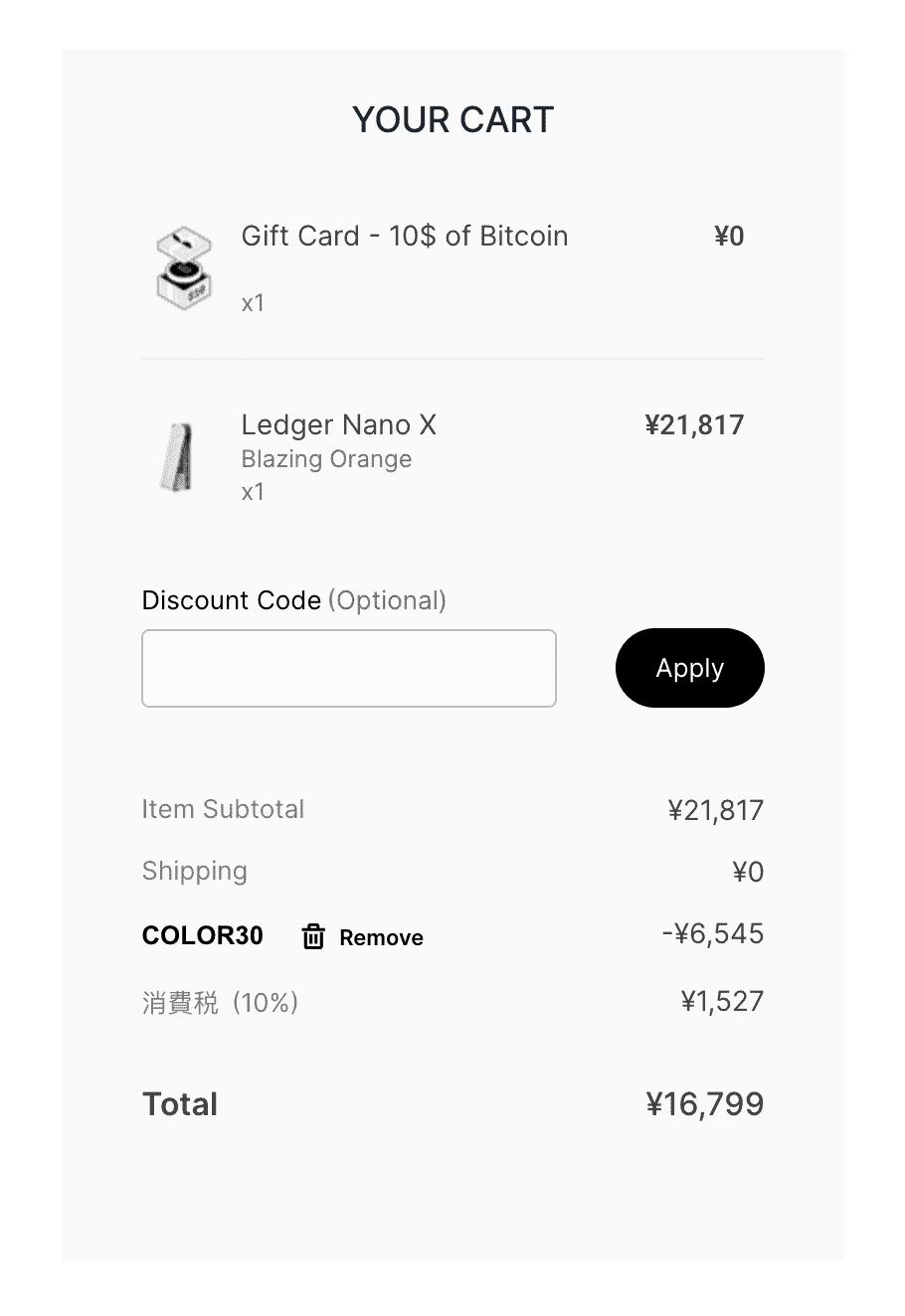
目前 Ledger 官方正在对彩色版本的 Ledger 进行打折销售,提供了 30% 的优惠力度,你可以通过我的邀请链接去购买,你我都可以得到价值 $10 的 BTC 返现,在选购彩色版本时,享受总价 7 折优惠,Nano X 只需要 16799 日元,Nano S Plus 只需要 8749 日元。
macOS 上好用的 ChatGPT 客户端整理
介绍几款在 macOS 上能使用的 ChatGPT 客户端。
- [[ChatX]]
- [[MacGPT]]
- [[AMA]]
- [[Chatbox]]
- [[OpenCat]]
ChatX
ChatX 是我目前个人在使用的客户端,界面简洁,提供了内置的 [[prompt]]。
MacGPT
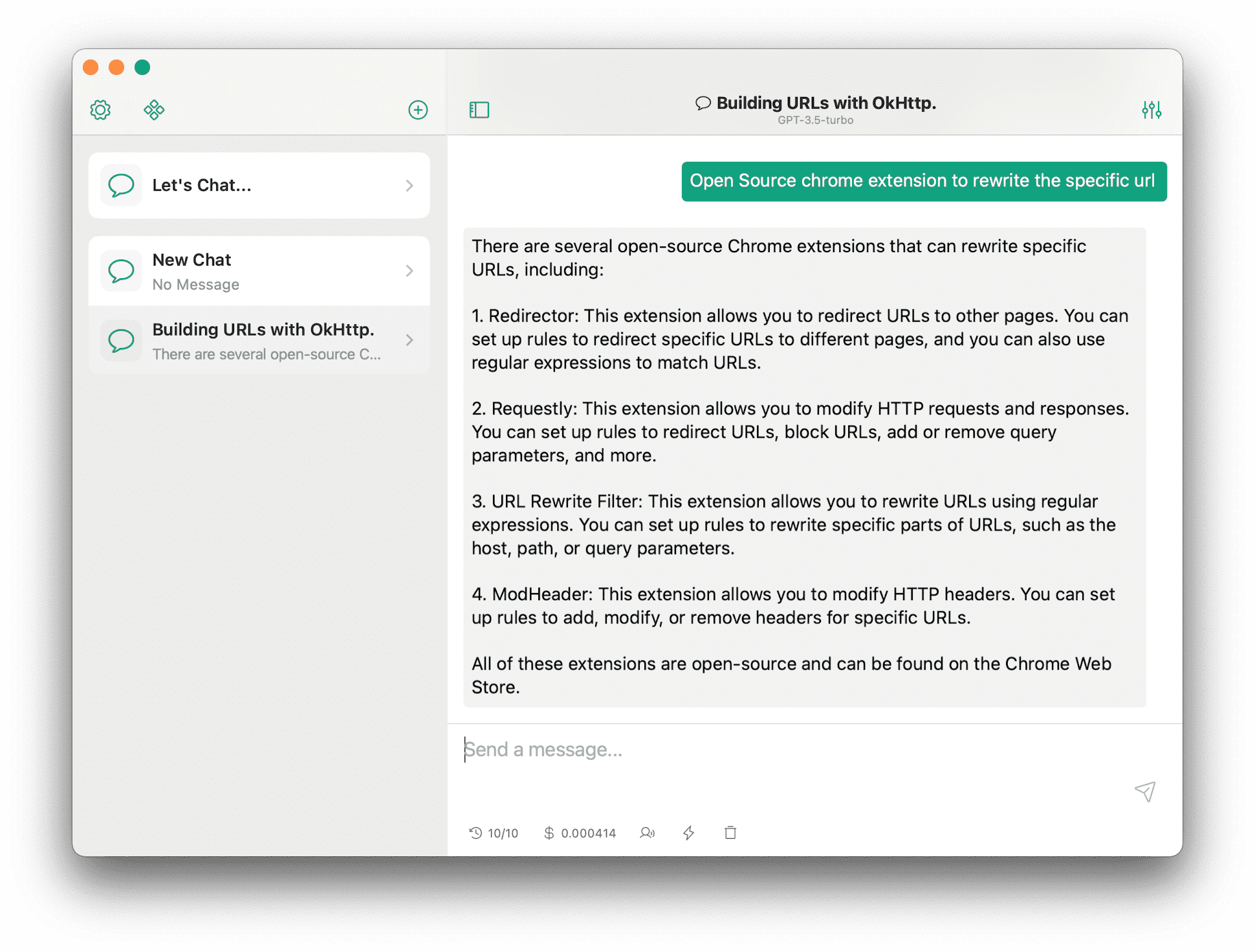
MacGPT 是一个 macOS 下的 ChatGPT 客户端,提供了 Native 和 Web 两种方式可以访问 ChatGPT。
MacGPT 提供的特色功能就是可以使用关键字来在任何应用中触发 ChatGPT。比如说在设置中设定了 +gpt ,那么在任何编辑器中,只要输入 +gpt questions 加上问题,然后回车,MacGPT 就可以在聊天窗口中直接进行回答,非常方便。
MacGPT 另外一个功能就是提供了一个全局的快捷键,可以一键呼出全局对话框,可以在这个全局对话框中和 ChatGPT 交互。
AMA
AMA (Ask Me Anything)是一个由 @gaodengming 开发的跨平台的 ChatGPT 客户端 ,我在 iOS 下面就使用这个客户端。

Chatbox
Chatbox 是一款开源的 macOS 上的 ChatGPT 客户端,使用 TypeScript 开发打包。
OpenCat
OpenCat 是 @waylybaye 开发的一款 ChatGPT 客户端
利用 Jakarta 来验证 Java Bean 数据合法性
Bean Validation 为 JavaBean 和方法验证定义了一组元数据模型和 API 规范,常用于后端数据的声明式校验。
2017 年 11 月,Oracle 将 Java EE 移交给 Eclipse 基金会。 2018 年 3 月 5 日,Eclipse 基金会宣布 Java EE (Enterprise Edition) 被更名为 Jakarta EE。因此 Bean Validation 规范经历了从 JavaEE Bean Validation 到 Jakarta Bean Validation 的两个阶段:
- JSR 303 (Bean Validation 1.0) Java EE 6
- JSR 349 (Bean Validation 1.1) Java EE 7
- JSR 380 (Bean Validation 2.0) Java EE 8
- Jakarta Bean Validation 2.0
- Jakarta Bean Validation 3.0
特性
- 通过使用注解的方式在对象模型上表达约束
- 以扩展的方式编写自定义约束
- 提供了用于验证对象和对象图的 API
- 提供了用于验证方法和构造方法的参数和返回值的 API
- 报告违反约定的集合
Maven
添加依赖
<!-- Validation -->
<dependency>
<groupId>org.hibernate.validator</groupId>
<artifactId>hibernate-validator</artifactId>
<version>8.0.0.Final</version>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>jakarta.validation</groupId>
<artifactId>jakarta.validation-api</artifactId>
<version>3.0.2</version>
</dependency>
<dependency>
<groupId>org.glassfish.expressly</groupId>
<artifactId>expressly</artifactId>
<version>5.0.0</version>
<scope>runtime</scope>
</dependency>
自定义校验注解
默认 Jakarta 已经定义了非常常用的一些校验,比如 @NotBlank, @Min, @Max 等等,但如果它提供的注解无法满足我们的需求时就需要通过自定义的方式来实现。
自定义的步骤主要分为
- 创建一个
validator来,实现jakarta.validation.ConstraintValidator接口 - 创建一个 constraint annotation 并且添加
jakarta.validation.Constraint注解
首先来看看注解定义
@Target({ElementType.FIELD, ElementType.METHOD, ElementType.PARAMETER,
ElementType.ANNOTATION_TYPE})
@Retention(RetentionPolicy.RUNTIME)
@Constraint(validatedBy = LanguageValidator.class)
@Documented
public @interface Language {
String message() default "must be a valid language display name.";
Class<?>[] groups() default {};
Class<? extends Payload>[] payload() default {};
}
注意这里的 @Constraint 注解需要指定 Validator。
Constraints
Constraints 约束是 Bean Validation 规范的核心。通过约束注解和约束验证的实现组合完成。
《美国大萧条》读书笔记
怎么知道的这一本书
在微信上关注了先知书店店长荐书,某一天的公众号文章中推荐了 [[罗斯巴德]] 这位经济学家的几部著作,这一本《美国大萧条》一下子就抓住了我的眼球,他的另外一部作品 [[人,经济与国家]] 也在我的待看清单上。
关于作者
[[罗斯巴德]] (Murray Newton Rothbard) 是一位美国犹太裔经济学家,历史学家,自然法理论家,政治理论家,是[[奥地利学派]]著名的学者。他的著作大量的介绍了 [[米塞斯]] 的工作,对现代的自由意志主义,和无政府资本主义理论的发展和传播有着极大的贡献。
这一本《美国大萧条》是罗斯巴德对 1929 年美国大萧条原因的分析和梳理,他提出了一个和主流观点截然不同的视角去剖析大萧条的成因。
几句话总结书的内容
简单的说这本书罗斯巴德根据[[商业周期理论]] 分析大萧条的原因是政府对市场的干预太多(低利率和信贷扩张)。
主流的观点(国内教科书上流行的观点)通常将 1929 年的经济危机归结于自由市场经济的失灵,但罗斯巴德认为与其说是市场的失败,不如说是政府货币政策的失败。虽然为了解决大萧条许多政府逢兴[[凯恩斯主义]],但是过去近百年,再回望就能知道凯恩斯主义已经不再行得通。
[[奥地利学派]] 通过 [[商业周期理论]] 尽管没有指出准确的时间,但是预测到了世界性的经济大萧条。奥地利学派认为政府的扩张性货币政策,利率非常低,信贷规模膨胀,因为利率过低扭曲了资源配置信号,使得市场自我调节失灵,一旦信贷收缩,萧条就发生了。
与米塞斯和哈耶克不同的是,凯恩斯认为,大萧条是由于需求不足导致,有效需求不足的原因是居民储蓄太多,而企业对未来太悲观,不愿意投资。大危机造就了凯恩斯主义经济学,大危机过后的 30 年代,凯恩斯主义获得了主流地位,一直到 80 年代才开始被人质疑。凯恩斯主义为政府干预经济提供了很好的理论依据,需求不足,市场失灵,解决的办法就是政府介入市场,增加需求。
但是奥地利学派认为,萧条是市场自身调整的必然过程,有助于释放经济中已经存在的问题,政府干预只能使得问题更糟糕。书中更是花了大量的笔墨描写胡佛政府的干预(扩大公共投资,限制工资下调,贸易保护主义法律等),使得这次危机持续很长时间。
商业周期理论(Business Cycle Theory)
区分商业周期和普通商业波动。
商业变动,通过普遍的交易媒介—-货币进行传播。货币把经济活动串联起来,货币供给量上升,货币的需求保持不变,那么每一美元所体现的购买力会下降,价格会普遍上升。
金本位制度的废弃使得美联储可以无限制扩大纸币供应量和银行的美元数量,致使价格上升,经济陷入混乱,收入因为通货膨胀而下降。
奥地利学派的理论揭示了通货膨胀并非政府扩大货币和信贷供给量的唯一恶果,这种扩张扭曲了投资和生产的结构,使得资本品行业对不良项目投资过度。
避免萧条的最好的方法就是,禁止美联储利用权力扩大货币和信贷。如果陷入了萧条,那么合理的措施是避免政府对萧条进行干预,使萧条的过程能尽快自行完成,然后重建一套健康和繁荣的经济体系。
通货膨胀的产生
- 货币供给膨胀(1921-1929)
- 准备金标准(银行信贷扩张)
- 准备金率降低
- 准备金总额的增加
- 最小法定准备金超出部分耗尽
- 准备金总量上升,造成 20 世纪 20 年代通货膨胀
- 货币性黄金存量
- 联储购买的财产
- 联储贴现的票据
- 其他联储信贷
- 银行外流通领域中的货币
- 代偿付的国库通货
- 国库库存现金
- 联储的国库存款
- 联储的非成员银行存款
- 联储的未花费资本基金
大萧条
大萧条的错误并不在于自由市场经济,而应该归咎于政客、官僚。
- 干预失业问题
- 干预劳工关系
- 胡佛新政
- 扩张信贷
- 公共建设
- 斯姆特-霍利关税
启发或想法
《美国大萧条》一书让我重新更换了一个视角去看待 1929 年发生的大萧条,也通过作者补充的大量胡佛的新政,和当时政府社会上大量具体的经济数据,来再次回到了那个动荡的时代。就像书中说的那样,从完全不相信市场经济的马克思主义经济学,到到摇摆的[[凯恩斯主义]],到适度干预的 [[芝加哥学派]],再到完全信任市场的[[奥地利学派]],对于同样的一件灾难,有不同的解释和叙事。站在我们这个时间点上,我还无法判断出来究竟是哪一种学说能真正根治大萧条的产生。虽然我已经感觉到大萧条在疫情的催化作用中,已经渐渐显露出了头角,但我还是从心底中希望不要发生,毕竟没有人一生之中有 10 年的时间可以虚度,已经被疫情浪费的三年时间也尽量想挽回一些。
谁应该看这本书
每一个人,我在看书的过程中无时不刻联想到当今的现实,虽然这本书距离出版已经过去了 60 年,但其中的理论无一不是当今现实的写照,疫情的三年美国因为救济向社会发放了大量的美元,导致市场美元增多,信贷扩张,而从去年开始的加息,缩表,导致如今的萧条,虽然程度上可能并不及当年但这依然可以说是过去几十年里面很罕见的了。
印象深刻的句子
给 macOS 编写的纯键盘操作流 Shortcat
Shortcat 是一个 macOS 上的效率工具,可以利用键盘了操作 UI 界面上的一切,而不需要使用到触摸板或鼠标。理念有一些类似于 Chrome 上的 [[vimium]] 插件,利用快捷键在界面上的每一个可以点击的区域加上快捷按键,通过按键来操作界面的内容。
安装
可以直接通过 brew 安装
brew install shortcat
使用
打开
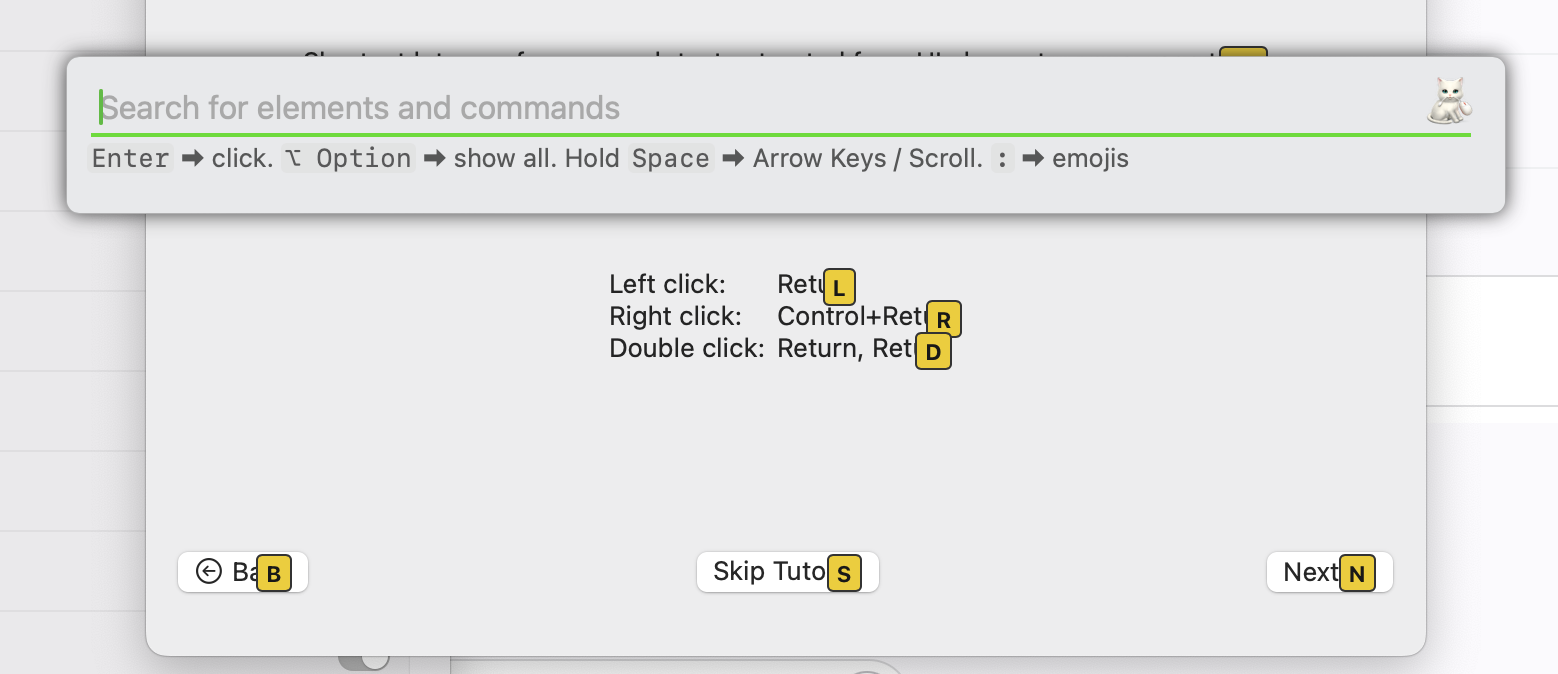
 然后可以使用默认的快捷键 Shift+Cmd+Space 来调用出来 Shortcat,然后界面每个可以点击的地方都可以直接看到一个黄色的标签,通过这个搜索框就可以直接进行检索然后,按下
然后可以使用默认的快捷键 Shift+Cmd+Space 来调用出来 Shortcat,然后界面每个可以点击的地方都可以直接看到一个黄色的标签,通过这个搜索框就可以直接进行检索然后,按下
- Return 点击
- Control + Return 右击
- Return,Return 双击
总结
不过我个人在尝试了一下之后,发现在 macOS 上触摸板相对来说更加便捷,并且 Shortcat 虽然可以让用户扔掉鼠标,但是由于操作系统可操作的区域非常多,所以导致搜索出现的选项非常多,而这个检索的过程,使用触摸板早就已经操作完成了。
macOS 自定义系统设置记录
因为电脑空间告警,所以用 Clean Me 这个应用对系统进行了一次清理,没想到的是,可能在我误操作的情况下把我系统的设置和全部软件的设置都给清空了。我所有的系统配置都恢复了初始的状态,让我使用起来非常变扭,我在之前有写过一篇 MacBook 初始化和应用安装 的文章,但是那篇文章写的比较啰嗦,索性就重新整理一下。
下面的内容会按照常用的功能来划分。
Keyboard
首先在 Input Sources 中添加 Rime 输入法。
Touch Bar 设置成默认 Fn 键
Touch Bar shows -> F1, F2, etc. Keys
在 Shortcut 中将 Spotlight 的快捷键取消,因为我使用 [[Raycast]]。
Desktop & Dock
- Reduce size
- Automatically hide and show the Dock
在设置 Desktop & Dock 设置的时候看到了一个新的设置 Stage Manager,查了一下是 macOS 最早在 iPad 上引入的多窗口管理方式。
Stage Manager 基本是一个单窗口模式,点击一个应用就会集中到该窗口上,其他的应用会被移动到左边。用户可以将应用拖入到当前的工作区中,然后形成多个应用窗口的组合。
说实话我不知道 Apple 在 macOS 桌面版引入这样的窗口管理模式的目的,只是为了配合 iPad 触摸屏的操作方式?虽然我承认 macOS 上的窗口切换本来就有很多问题,我是通过
文章分类
最近文章
- Dinox 又一款 AI 语音实时转录工具 前两天介绍过 [[Voicenotes]],也是一款 AI 转录文字的笔记软件,之前在调查 Voicenotes 的时候就留意到了 Dinox,因为是在小红书留意到的,所以猜测应该是国内的某位独立开发者的作品,整个应用使用起来也比较舒服,但相较于 Voicenotes,Dinox 更偏向于一个手机端的笔记软件,因为他整体的设计中没有将语音作为首选,用户也可以添加文字的笔记,反而在 Voicenotes 中,语音作为了所有笔记的首选,当然 Voicenotes 也可以自己编辑笔记,但是语音是它的核心。
- 音流:一款支持 Navidrom 兼容 Subsonic 的跨平台音乐播放器 之前一篇文章介绍了Navidrome,搭建了一个自己在线音乐流媒体库,把我本地通过 [[Syncthing]] 同步的 80 G 音乐导入了。自己也尝试了 Navidrome 官网列出的 Subsonic 兼容客户端 [[substreamer]],以及 macOS 上面的 [[Sonixd]],体验都还不错。但是在了解的过程中又发现了一款中文名叫做「音流」(英文 Stream Music)的应用,初步体验了一下感觉还不错,所以分享出来。
- 泰国 DTV 数字游民签证 泰国一直是 [[Digital Nomad]] 数字游民青睐的选择地,尤其是清迈以其优美的自然环境、低廉的生活成本和友好的社区氛围而闻名。许多数字游民选择在泰国清迈定居,可以在清迈租用廉价的公寓或民宿,享受美食和文化,并与其他数字游民分享经验和资源。
- VoceChat 一款可以自托管的在线聊天室 VoceChat 是一款使用 Rust(后端),React(前端),Flutter(移动端)开发的,开源,支持独立部署的在线聊天服务。VoceChat 非常轻量,后端服务只有 15MB 的大小,打包的 Docker 镜像文件也只有 61 MB,VoceChat 可部署在任何的服务器上。
- 结合了 Google 和 AI 的对话搜索引擎:Perplexity AI 在日本,因为 SoftBank 和 Perplexity AI 开展了合作 ,所以最近大量的使用 Perplexity ,这一篇文章就总结一下 Perplexity 的优势和使用技巧。