在 Mac M1 下使用 VMware Fusion 安装 Windows 11 跳过网络
今天遇到一个证书发行商提供的客户端 Windows only,无奈只能在想办法在 macOS 下安装一个 Windows,因为之前就使用过 VMware Fusion,个人使用是免费的,所以立即就上官网下载。
Windows 镜像
另外 Windows 镜像在 MSDN ITELLYOU 上下载,
安装
安装虚拟机的过程非常简单,将 ISO 拖入到安装界面,然后打开虚拟机就开始了自动安装,但是没想到的是在安装的过程中,遇到了如下的界面,始终无法跳过。
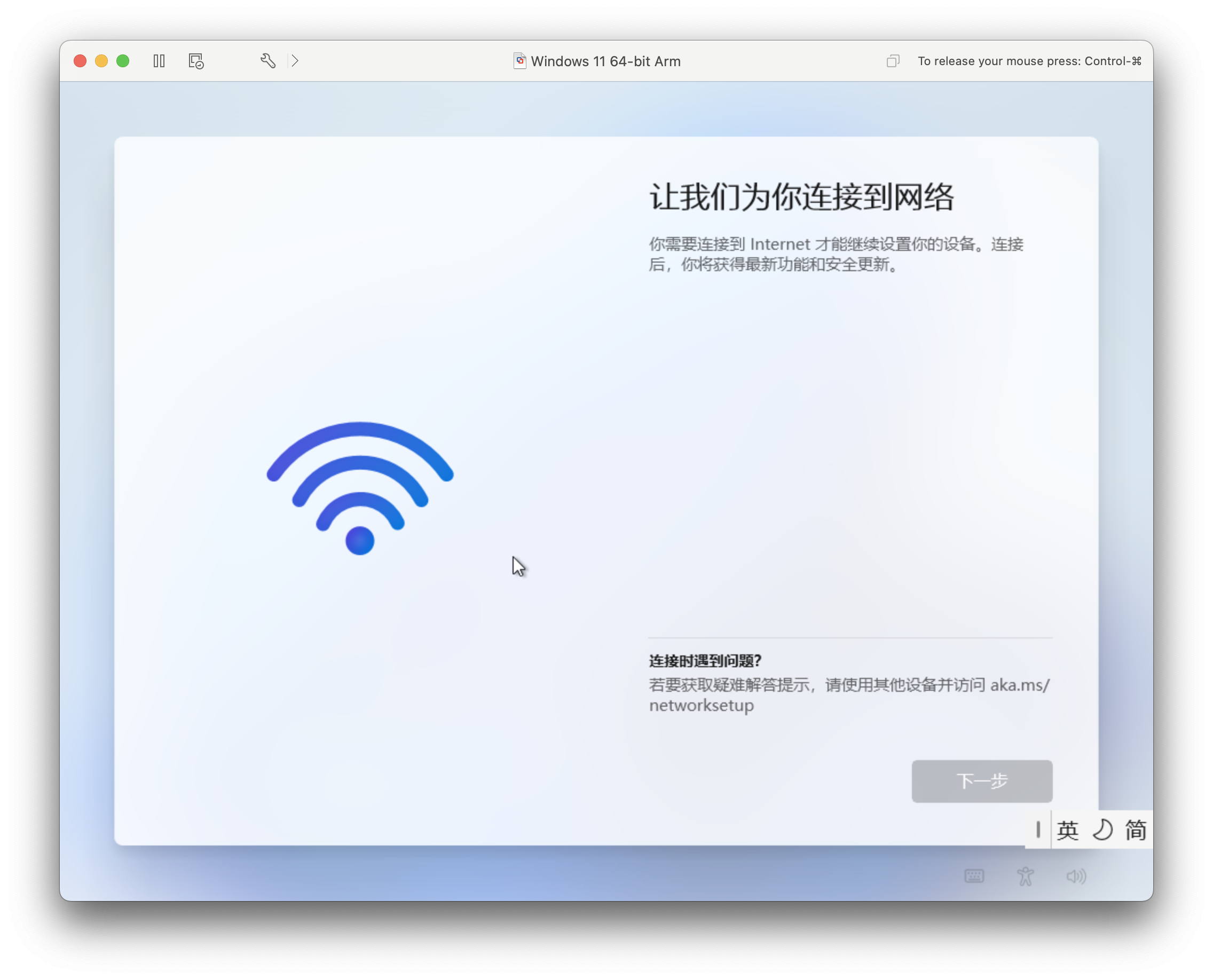
所以在这里记录一下如何在安装的过程中跳过联网。当到联网的画面之后,按下 Shift+F10 或者是 Fn+Shift+F10 快捷键调出命令提示符窗口。
在 cmd 界面中,通过 cd 命令切换到,C:\Windows\System32\oobe\ 目录,然后执行 BypassNRO.cmd,按 Enter 键。系统会自动重新启动,并提供在不联网的情况下完成首次开机设置的选项
Windows 11 设置联网
在使用上一步完成系统初始化之后,进入 Windows,依然无法联网。可以通过如下的步骤来使得虚拟机中的 Windows 能联网。
- 输入 cmd,打开终端,然后在终端中输入
powershell - 在 powershell 中执行
Set-ExecutionPolicy RemoteSigned - 然后在 VMware 菜单中找到 Install VMware Tools
- 此时虚拟机中会出现一个新的盘符,比如是 D 盘
- 那么在 Powershell 中输入
cd D:\ - 然后输入
./setup.ps1 - 等待安装完成
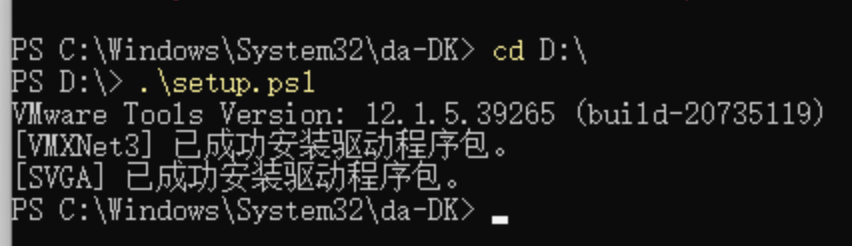
等待安装完成之后,就可以看到网络已经连接了。
reference
Music Tag Web 基于网页修改音乐的元数据
Music Tag Web 是一个基于网页的歌曲元数据编辑工具,支持编辑标题,专辑,艺术家,歌词,封面等信息。之前在 Windows 上用过一个叫做 [[mp3tag]] 的应用,后来在 macOS 上用的是 MusicBrainz Picard,后来发现一款非常不错的音乐播放器 [[Swinsian]],用了很久。我本地的所有音乐文件都会放在一个文件夹中然后使用 Syncthing 来同步。
正因为我的音乐库被同步到了 VPS 中,虽然本地也有一份备份,但是如果恰好电脑不在身边,那就不太好立即操作。
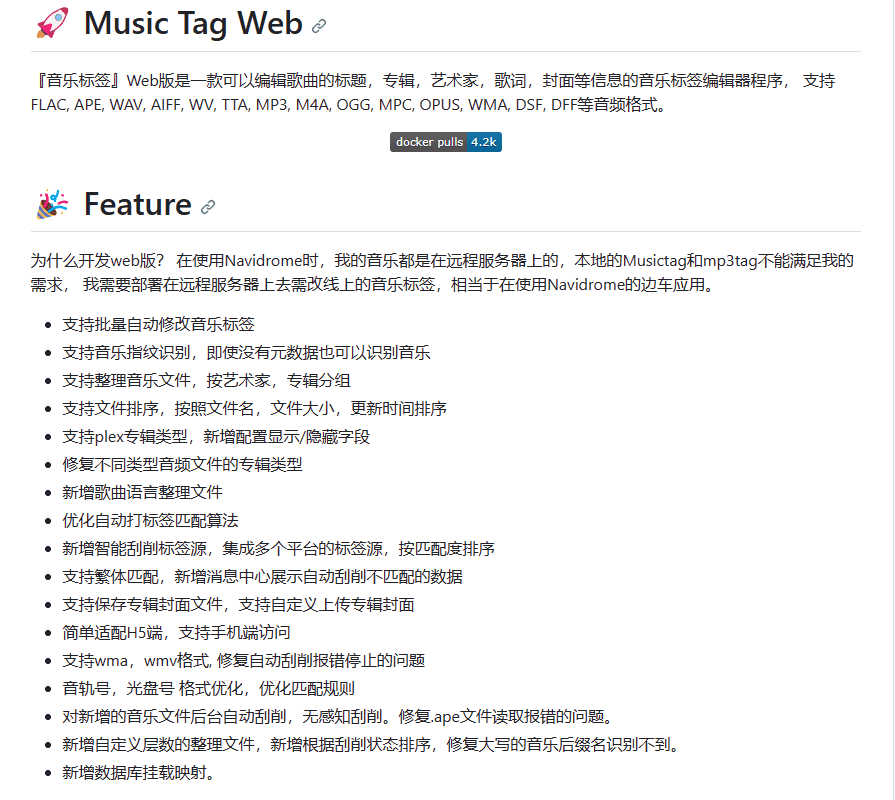
再回到今天的主题 Music Tag Web,它的特点是:
- 支持 FLAC,APE,WAV,AIFF,WV,TTA,MP3,M4A,OGG,MPC,OPUS,WMA,DSF,DFF 等音频格式。
- 支持音乐标签来源 网易云音乐,QQ 音乐,咪咕音乐, 酷狗音乐, 酷我音乐
- 支持批量自动修改音乐标签
什么是歌曲的元数据
如果有人想要研究一下什么歌曲的元数据,那就避不开 [[MP3 ID3]] 这样一个名次,对于 MP3 ID3 的格式,可以参考这篇文章。
安装
Music Tab Web 的安装非常简单,直接通过 Docker 启动即可。
直接使用命令启动(不推荐):
docker run -d -p 8001:8001 -v PATH_TO_MUSIC:/app/media -v PATH_TO_CONFIG:/app/data --restart=always xhongc/music_tag_web:latest
推荐使用 docker compose 启动,具体的配置可以参考我的仓库
version: '3'
services:
music-tag:
image: xhongc/music_tag_web:latest
container_name: music-tag-web
restart: always
ports:
- "8001:8001"
volumes:
- ${PATH_TO_MUSIC}:/app/media:rw
- ${CONFIG}:/app/data
command: /start
等待启动,使用 docker-compose logs -f 查看日志,没有出现问题即可,之后访问 IP + 端口 http://ip:8001 访问主页面,在路径后面加一个 admin 就可以看到管理界面,默认账号密码 admin/admin。
使用
Music Web Tag 的界面非常直观,支持手动修改,或者根据匹配的信息自动修改,也支持整理文件夹以及简体转繁体,繁体转简体等操作。
和软件的本地版差距不大,除了界面上有所变化功能上并没有变化太大,能够根据平台来索引歌曲文件,可以进行手动的歌曲信息修改,包括了歌手、专辑、风格以及歌词等等信息都可以修改。支持的文件夹整理是一大亮点,可以针对专辑或者歌手,将其歌曲放在一个文件夹中。
自动修改完成之后就可以看到文件的信息被修改,同时也能在操作记录中看到是否有失败项。而针对自动修改错误的,也可以直接在界面进行手动修改。
related
- [[MusicBrainz]]
- [[mp3tag]]
- [[Music Tag]]
《小而美》读书笔记
怎么知道的这一本书
在很多地方看到过这一本书的书评,Twitter 上关注的人当中也不乏推荐者。
在阅读这本书之前,很早就听过《疯投圈》的播客提到过这个名词,这个世界上有两类公司,一种是小而美的公司,一种是大而全的公司。小而美的公司追求简洁、高效和精益,专注于核心业务,避免过多的复杂性和浪费。而大而全的公司则追求规模、多样性和全面性,拥有庞大的组织架构和复杂的业务流程。我想,很多的大公司都是经历过小而美的阶段,比如说只有一个搜索栏的 Google;比如说只提供照片分享的社交网站 Instagram;比如说专注于影视作品打分的豆瓣。很多小而美的公司会找到自己的盈利模式,比如 Google 的竞价广告,进而变成一家庞大的公司;又或者像 Instagram 这样被大公司收购,进而成为一家主流的图片社交网站;很少一部分会像豆瓣一样,既没有发展成为一家庞大的公司,也没有被另外一家大企业收购进而得到进一步的发展。更有很多的公司,可能因为没有跟上时代的发展,而被淹没在历史里面。
但这一本《小而美》吸引我的点在于,作者提倡去长期经营一家小而美的公司,「刻意」的维持公司的规模不要过大,并且要长期在发展中保持专注高效,为现有客户提供长期的价值。
通过目录,可以看出来这是一本非常实用主义的书,作者的很多建议非常贴近现实,甚至很多都可以直接套用。从创建社区,提出问题,构建想法,提出解决方案,到假设验证,冷启动,营销,运营,作者通过自己创建 Gumroad 的经历给读者编写了一本创业说明书。在很流行 [[独立开发者]] 的当下,这本书受到热捧也是可以理解的。
关于作者
《小而美》的作者叫做 萨希尔·拉文吉亚(Sahil Lavingia),我是第一次听说这位作者,但是直到我看书,才知道原来他是 Gumroad 的创始人,这本书也是记录他尝试将这个创作者平台做大,却不成之后的思考。他同时也是一个作家,投资人。
几句话总结书的内容
《小而美:持续盈利的经营法则》原始的书名是 《The Minimalist Entrepreneur: How Great Founders Do More with Less》,直译过来其实有一些些差别,极简创业者、伟大的创业者如何使用最小的成本来实现更多,但中文书的翻译正恰好说明了本书的全部重点,作者不是教人创建一家大型企业,而是让读者明白如何创建一个可持续盈利的项目。作者自称自己是极简主义创业,那什么是极简主义创业者呢,在解释这个词之前,可以先了解一下前几年非常流行的一个词,叫做「独角兽」,被称为独角兽的企业,是指那些估值超过 10 亿美元的企业,Uber,Dropbox,Evernote 等等,这一些项目有非常成功的,上市的,也有像 Evernote 一样「失败」 的。而回到本文的主题 —- 极简主义,就是那些成为不了独角兽的公司,但是却有其存在的价值,可以通过少量的人力和资源即可维护的项目,能给客户不断提供服务和价值。极简主义创业者不是为了攫取利润,而是为客户和社区创造价值。这也是这一本书的核心。作者倡导创业者通过减少复杂性和浪费,利用自动化,不断优化流程的方式来打造一个企业。
- 盈利第一
- 从社区入手
- 越少越好
- 瞄准前 100 个客户
- 营销
- 寻求自我成长和企业成长
- 建造自己想住的房子
先是创作者,再是创业者
- 理想客户是谁,缩小范围
- 明确要解决的痛点是什么,付费意愿
- 制订计划表,设计方案,收取费用
-
不断重复这个过程,直到找到一个可行的产品,然后扩大经营
- 第二章 社区很重要
- 提前创建社区,在社区中发现问题,从问题引到产品,产品带来生意
- 选择合适的问题去解决,确认他人也面临相同的问题
- 产生疑虑时回到社区,帮助你继续前行
- 第三章 Less is more
- 在创建最小化可行产品之前,先完善有价值的人工流程
- 应该创建什么
- 产品化就是将一个流程发展成为可以出售的东西
- 起名
- 网站,邮件
- 创建社交媒体
- 付款
- 尽早交付,经常交付
- 在创建最小化可行产品之前,先完善有价值的人工流程
- 第四章 瞄准前 100 个客户
- 第五章 通过做自己来营销
- 营销不是为了制造头条新闻,而是为了制造粉丝
- 从教学开始,再去激励、娱乐
- 第六章 有意识地和企业一起成长
- 追求「盈利自信」无限的跑道会最大限度提高创造力、清晰度和控制力
- 少花钱,少折腾
- 如果要筹资,从社区进行
启发或想法
这本书非常具有实践意义,并且也给了我很多启发。作者描述的每一个过程都是可以被实施的,如果非要说的话,这一本书可以说是极简主义创业说明书,作者连需要做什么,做几步,怎么做都写得非常清楚,从建立社区,发现问题,解决问题,营销,等等方面都进行了探讨。但个人对这一本书的观感不佳的一个原因是作者每一步实施都浅浅的略过,点到为止,如果说创业者可以按这个说明书操作倒也不错,但这本书更多的是给读者一个思路,一个思考的方向,原来还可以这样做。
谁应该看这本书
- 想要做一款独立产品的开发者
- 已经在运营产品的人员
- 初创企业的老板
印象深刻的句子
- 不应先学习,再开始,应先开始,再学习
- 极简主义创业者关注如何「尽一切力量盈利」,而不是「不计一切成本扩张」。
- 生意,是你为所关心的人群解决问题的方式,你也会因此赚钱
- 先成为一个创作者,再成为一个创业者。
- 通过赚钱,来赚取时间
Omnivore 一款开源的稍后阅读服务
Omnivore 是一个开源的,稍后阅读应用,查看起官方的页面,支持非常多的客户端,包括了 iOS, macOS, Chrome,等等 Android 还在测试中。
在之前的自行架设的服务 中有推荐过 [[Wallabag]],但是 Wallabag 界面稍微有一些古早,但是使用起来完全没有任何问题,我自己也搭建用了很久。而非开源的,比如 [[Pocket]],[[Instapaper]],也都是过去非常不错的稍后阅读服务。
Omnivore 吸引我的一点是可以和外部的其他应用同步,比如可以和 Obisidian 同步,还可以接收 Newsletter。 另外还有一个吸引我的点就是,很多宣称可以代替 [[Readwise]] 阅读器,这也是一款我关注了很久,但是还没有深入使用的在线阅读器。 所以这篇文章就来介绍一下它。
功能
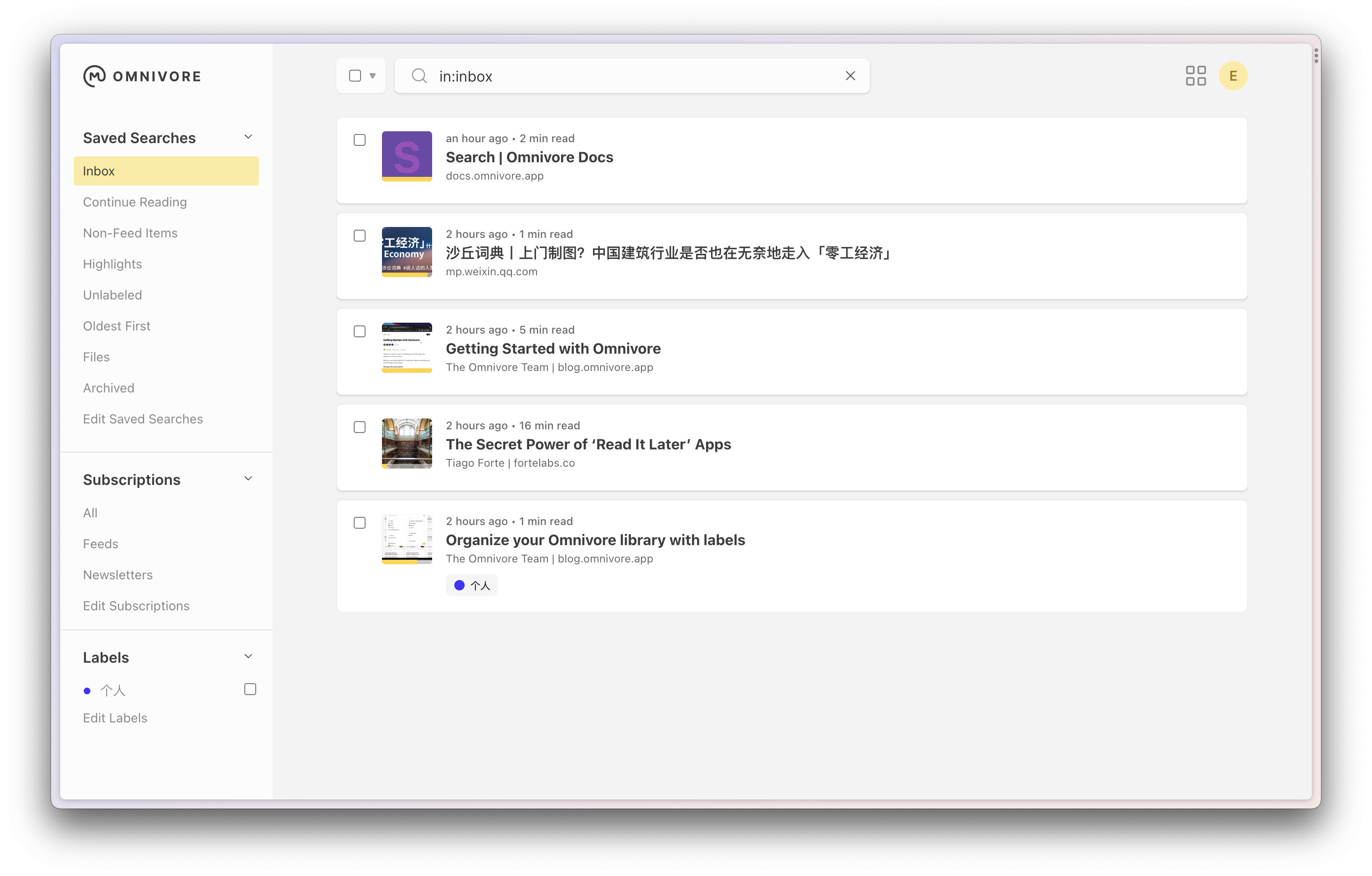
功能:
- 稍后阅读
- 集中所有的 Newsletters,会生成一个
username-123abc@inbox.omnivore.app的邮箱地址,在订阅的时候使用该地址,所有发送到该邮箱的订阅内容都会自动存在 Omnivore - 所有平台同步阅读进度
- 分类分组功能
- 支持和 [[Logseq]] 和 [[Obsidian]] 同步
- Text-to-speech,支持文章转音频
添加内容方式
Omnivore 可以通过很多方式来添加阅读源
- 通过官方提供的浏览器插件添加网页,包括 Chrome,Edge,Firefox,Safari
- 通过 macOS 客户端,或者其他手机客户端(iOS,Android),直接添加链接
- 更赞的是 Omnivore 还可以抓取微信公众号的内容。
- macOS 客户端还支持导入 PDF
- 通过类似 RSS 阅读器一样的 RSS 订阅链接,添加 Feed
- 通过电子邮件
整理
Omnivore 提供了如下几个方式了帮助整理
- Archiving 归档
- Lables 标签
- Search 搜索,通过关键字来搜索所有保存的内容,也可以通过一些高级的检索技巧来实现更加细粒度,准确的搜索
- 根据标签过滤,
label:Newsletter- 有标签一或标签二,
label:Cooking,Fitness - 过滤同时有多个标签的内容
label:Newsletter label:Surfing - 有标签一,但是没有标签二
label:Coding -label:News
- 有标签一或标签二,
- 根据是否存档过滤
- 在收件箱
in:inbox - 在归档中
in:archive - 所有的
in:all
- 在收件箱
- 根据阅读状态来过滤
- 读过
is:read - 未读
is:unread
- 读过
- 根据类型过滤
type:articeltype:filetype:pdftype:highlights
- 查询有 highlights 的内容
has:highlights - 排序
sort:saved依据保存日期排序sort:updated根据更新时间排序sort:score根据相关度- 可以通过
-asc或者-des来调整升降序 sort:saved-ascsort:updated-des
- 根据标签过滤,
- Filters 过滤器,默认情况下提供了内置的过滤器
- Read Later,所有的未归档的内容,除了 Newsletters
- Highlights,高亮的
- Today,今日保存的内容
- Newsletters,通过邮件订阅的内容
集成
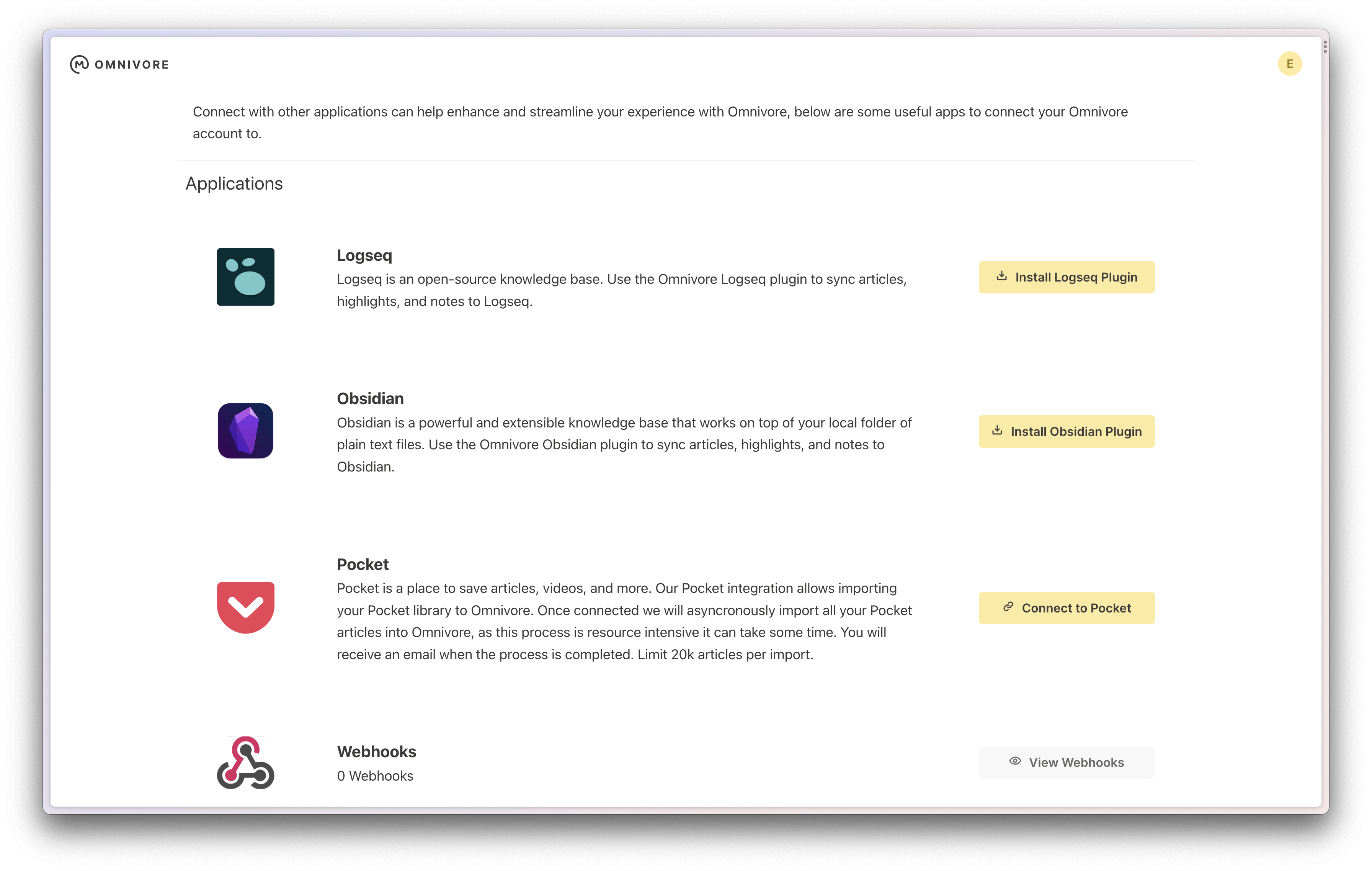
将数据发送到其他应用,比如 Logseq,Obsidian,或者通过 API,或者 Webhooks 的方式和其他系统进行集成。
- Logseq
- Obsidian
- Pocket 支持关联之后,导入数据,限制 20k 条
- Webhook
- [[Readwise]],将高亮从 Omnivore 同步到 Readwise
和 Obsidian 集成
Webhook
目前 Omnivore 支持四种类型的事件
- 页面创建
- 页面更新
- 创建高亮
- 添加标签
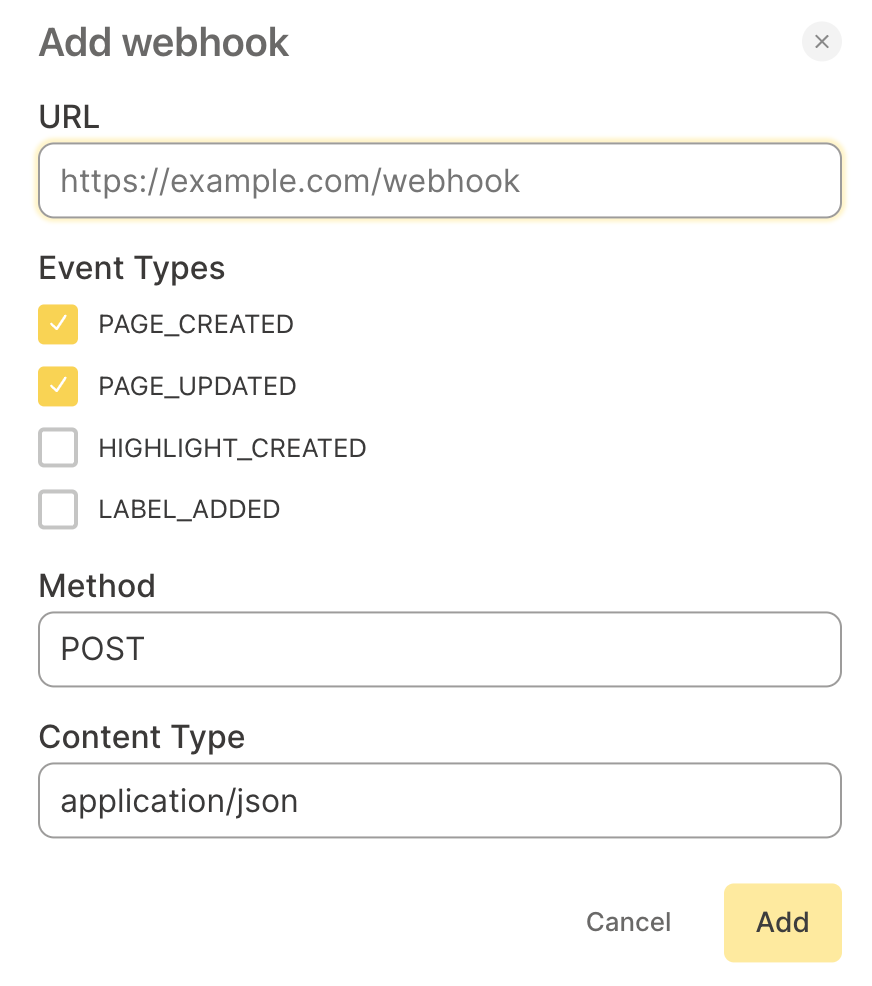
如果有外部的系统集成,可以根据这四个事件类型去触发。
我买了一块 1TB 的便携移动硬盘 三星 T7
笔记本电脑用了 3 年多,各种媒体材料,尤其是音乐我喜欢放在本地,以及各种应用程序基本上已经把磁盘自带的空间占满了,这两天刚好看到日亚有促销活动,可能是看我之前搜索过 SanDisk E61,E81 ,所以推荐里面直接推送了一个三星的 T7,看了一下价格只要 10600 JPY,用 Keepa 对比了一下历史价格,以及京东上的价格,感觉还挺合适的,就下了单。
外观
我原本预想就很小,但是到手发现是真的小,和信用卡比了一下,正好是一张信用卡大小,感觉是产品设计的时候特意的,因为和信用卡放在一起也几乎看不出来。
 外观
外观
 几乎只有 1/3 的硬币直径。
几乎只有 1/3 的硬币直径。

可以看到 T7 的厚度几乎和 iPhone 13 一致。
 和 iPhone 相比,大小也非常小。
和 iPhone 相比,大小也非常小。

 手持大小。
手持大小。
说明
直接看网上的 电子说明书
T7 默认情况下已经格式化成 exFAT 格式,兼容 Windows,macOS,Android 系统。用户也可以根据自己的常用系统自行格式化。
| 文件格式 | Windows 系统 | macOS |
|---|---|---|
| exFAT | 读取和写入 | 读取和写入 |
| NTFS | 读取和写入 | 仅读取 |
| HFS/HFS+/APFS | 无法读取 | 读取和写入 |
Samsung T7 可以用自带的软件实现磁盘加密。
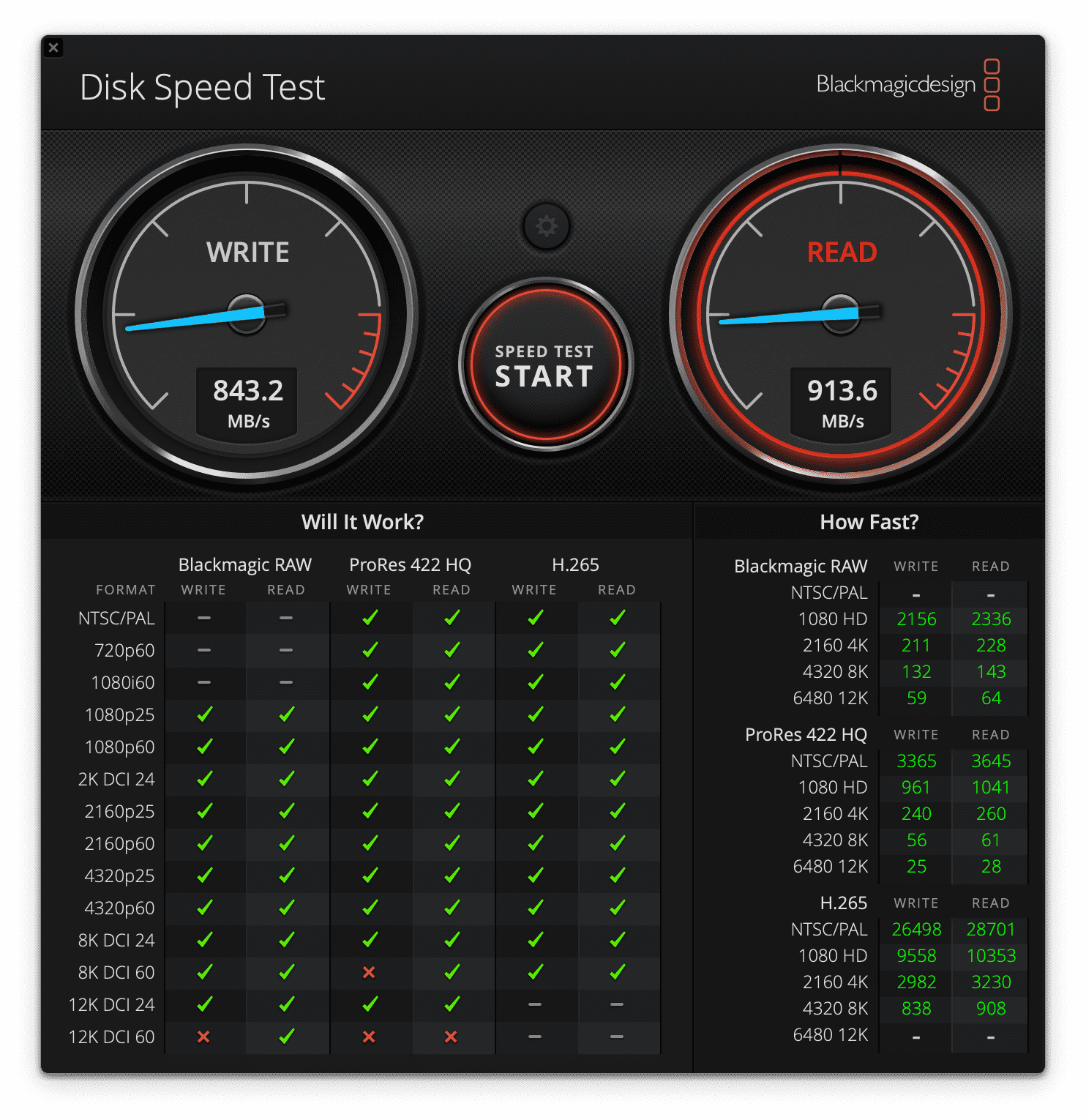
测速
使用 Disk Speed Test 在 macOS 下测试速度,虽然没有达到理论速度 1050 MB/s ,但日常使用也够了。
总结
买这一块 1T 的固态也只是用来做一下应急处理,主要是家里的 NAS 没有带在身边,而使用普通的硬盘处理 Lightroom 中的照片也略慢,所以临时用这一块固态硬盘来应急一下。如果是存储重要的资料,我个人还是会用类似 Duplicacy 等增量备份工具多地备份一下的。更具体的可以参考之前的备份方案。
对象存储服务提供商提供的免费存储容量
[[对象存储]] 的英文是 Object-based Storage System,是一种将数据以对象的形式存储在分布式系统中的服务,而不是传统的文件系统或者块存储。
对象存储服务提供商通常提供以下功能和服务:
- 可扩展性:它们能够处理大规模的数据,并自动扩展以适应数据量的增长。
- 冗余备份:它们使用分布式系统来复制和备份数据,以确保数据的安全性和可靠性。
- 数据访问控制:它们提供各种访问控制机制,以确保只有经过授权的用户才能访问和修改数据。
- 数据管理:它们提供各种管理工具,使用户能够有效地管理和组织他们的数据。
- 数据传输:它们通常提供高速的网络传输机制,以便用户可以快速地上传和下载他们的数据。
一些知名的对象存储服务提供商包括亚马逊 S3(Amazon S3)、微软 Azure Blob Storage、谷歌云存储(Google Cloud Storage)等。这些服务可以根据用户的需求来选择,并根据使用量进行付费。
那么除了上面提到的这些云服务商,还有哪些服务商提供免费的对象存储服务呢。
Oracle Cloud
Oracle Cloud Object Storage 包含了 20 GB 的免费存储空间。
Backblaze B2 Cloud Storage
[[Backblaze]] 是一个云存储解决方案提供商,其提供了类似 [[AWS S3]] 的在线块存储服务。 Backblaze B2 价格要便宜一些。并且前 10GB 存储是完全免费的。和 AWS S3 一样,需要为带宽付费,但是通过 Bandwidth Alliance,在 Backblaze 和 Cloudflare 之间的带宽是完全免费的,这也就意味这如果通过 Cloudflare ,那么使用 Backblaze 也就不再需要考虑流量的问题。
- 存储每 GB 每个月 $0.005
- 流量,每 GB 下载 $0.01
Storj
Storj 提供的分布式存储可以创建三个项目,每个项目都有 50GB 存储,以及 50GB 流量可以免费使用。 也就是达到了免费的 150G 存储。1
1:https://docs.storj.io/dcs/pricing
免费的对象存储,特点:
免费 150 G 永久25 GB- 去中心化储存
- 可免费创建三个 project
- 流量和储存一样都免费配额
- 可选 AP(亚太)/US(美国)/EU(欧洲)三个地区
- 多终端客户端/支持 S3 协议/可使用 rclone 传输挂载
缺点
Storj 目前只有 AP/US/EU 三个地区有服务器,访问速度可能会受到一定影响。并且目前 Storj 在初创时期,其商业模式是否能为继续也是需要继续考量的。
Contabo Object Storage
Contabo 发布的 Object Storage 对象存储,起步价 250GB,2.99$ (2.49 欧元)一个月。不限流,提供 DDOS 防护,兼容 S3 。
目前有欧洲,美国和亚洲三个地理位置。
在刚推出该项目的时候还提供了 20% 的额外优惠,只需要 1.99 欧元(2.49 美元)。1
Scaleway
注册 Scaleway 帐号之后可以获得 75 GB 的免费存储空间。
反查一个域名的所有子域名
前段时间看到一篇文章说因为 Nginx 的一个「特性」,在直接访问 IP ,并且没有配置默认证书的情况下 Nginx 就会返回一个 SSL 证书从而倒置域名的泄露,进而泄露了网站的源 IP,使得一些扫描网站,比如 [[censys]] 可以直接查询到域名背后的网站 IP,从而导致网站即使用了 CDN 也会遭受到攻击。在这个契机下,我又开始了衍生,因为在 censys,[[fofa]],[[Shodan]] 等等网站上你只需要输入一个域名就可以获得所有这个站点相关的信息,那么有没有办法可以在只知道一个网站域名的情况下知道所有的二级域名呢。
于是抱着这个新想法,进行了一番调查,果然还是有办法可以知道的。我最最朴素的想法就是写一个遍历,直接通过随机的字符串,[a-z0-9\-] 等等字符的组合,然后进行这些域名检查,ping,dig 的结果,如果有返回,可以认为这个子域名被启用了。但是很显然这个想法的效率太低了,并且遍历这么多无效的域名前缀很显然没有办法最快的找到所有的。
然后我就找到了 [[MassDNS]],一款使用 C 语言编写的高性能子域名扫描工具。它通过使用自定义的 DNS 解析器和并发查询来加快子域名的发现速度。MassDNS 支持使用字典文件进行子域名爆破,并提供了丰富的配置选项来优化扫描过程。 MassDNS 还支持自定义的 DNS 服务器,并可以通过设置最大查询时间和最大重试次数等参数来控制扫描过程中的超时和重试行为。此外,它还提供了多种输出格式,包括文本、JSON 和 CSV,以便用户根据需要对扫描结果进行分析和处理。 使用 MassDNS 进行子域名扫描非常简单,只需指定目标域名和字典文件即可开始扫描。它还提供了多线程支持,可以根据系统资源情况调整并发线程数量,以实现更快的扫描速度。
然后我又循着脉络找到了 OneForAll 这样一个开源的工具,它是一个功能强大的子域名收集工具,集成了非常多的工具,从它的官方介绍上也可以看出来它收集子域名的思路和方法。
- 利用成熟第三方的情报收集
- 利用证书收集子域名情报,比如通过
censys_api,certspotter,crtsh等等 - 常规检查收集子域
- 域传送漏洞利用
axfr - 检查跨域策略文件
cdx - 检查 HTTPS 证书
cert - 检查内容安全策略
csp - 检查 robots 文件
robots - 检查 sitemap 文件
sitemap - 利用 NSEC 记录遍历 DNS 域
dnssec - NSEC3 记录
- 域传送漏洞利用
- 网络爬虫存档记录,
archivecrawl,commoncrawl - 通过第三方 DNS 数据集收集子域
- 直接通过 DNS 查询收集,SRV记录,MX,NS,SOA,TXT记录
- 利用威胁情报平台数据收集子域
- 搜索引擎发现子域
- 利用证书收集子域名情报,比如通过
- 通过字典,或者遍历来查询子域名
- 通过 [[MassDNS]] 来多线程查询子域名
OneForAll 使用
首先获取 OneForAll 的代码
git clone git@github.com:shmilylty/OneForAll.git
通过 pyenv 或者其他熟悉的工具,安装 Python 依赖,然后执行
python3 oneforall.py --target douban.com run
很快就能获得一个 CSV 的结果。
Other
- [[Findomain]]
使用 Dokku 构建属于你自己的 PaaS
Dokku 是一个开源的 PaaS,用户可以非常轻松地构建自己的 PaaS 云平台。
什么是 PaaS
在深入了解 Dokku 之前,先来了解一下什么是 [[PaaS]],PaaS 的全称是 Platform as a Service,平台即服务。典型的产品有 [[Heroku]],[[Vercel]] 等等。
PaaS 作为一个平台提供给了开发者构建,部署,管理应用的能力,开发者不再需要关系复杂的基础设施,比如操作系统,网络,硬件等等。PaaS 提供商通常提供开发工具,运行时环境,应用管理后台等等。除了上面提到的 [[Heroku]] 之外,AWS Elastic Beanstalk,Google Apple Engine,Microsoft Azure App Service。
与之对应的概念还有
- [[IaaS]],Infrastructure as a Service,基础设施即服务,通过虚拟化技术,提供了操作系统级别的服务,允许用户租用虚拟服务器,包括计算资源,存储,内存,网络等等。典型的 IaaS 提供商是 Amazon AWS(Amazon Web Services),Microsoft Azure,Google Cloud Platform,[[Oracle Cloud]],阿里云等等
- [[BaaS]],Backend-as-a-Service,一种托管的后端服务,比如提供托管的数据库,后端代码的运行时环境,通常也会提供能让开发者轻松构建移动应用或 Web 应用的后台服务,开发者无需自己维护后端数据库及应用程序运行时。BaaS 通常会提供数据存储,用户管理,文件存储,通知推送,第三方 API 集成等。借助 BaaS 开发者可以不用关心数据,只专注于前端,用户界面的体验。常见的提供商有 Google [[Firebase]],Facebook Parse,AWS Amplify,[[Supabase]] 等等。开源的代替也有我之前介绍过的 Appwrite。
- [[SaaS]],Software-as-a-Service,软件即服务,通过互联网提供给用户软件产品。用户通过网络访问使用这些服务而不需要自己安装,配置和维护这些软件。
- [[FaaS]],Function-as-a-Service,函数即服务,开发者专注于编写函数(片段的代码),配置触发器来指定函数何时触发。函数被触发时,自动分配计算资源,执行用户代码,并返回结果。开发者不用再关心除函数以外的其他资源。FaaS 提供商包括 AWS Lambda,Google Cloud Functions,Azure Functions。
传统的 IT 基础设施需要运维人员从下到上管理
- 应用程序
- 数据
- 运行时
- 中间件
- 操作系统
- 虚拟化
- 服务器
- 存储
- 网络
而上面提到的概念则是将不同的部分组合,一步一步简化了开发程序的过程。开发者关系的细节越来越少,与此同时可以在此基础上构建出丰富多彩的应用程序(SaaS)。
什么是 Dokku
Dokku 是一个使用 Go 语言编写的,开源的,最小化的 PaaS 平台。
如何安装 Dokku
环境要求:
- 全新安装的 Ubuntu 16.04 x64, Ubuntu 14.04 x64, Debian 8.2 x64
- 至少 1GB 内存
Dokku 官网文档上有很多的安装方式。推荐的安装方式是直接用一台全新的 VPS,直接安装。我尝试使用 Docker Compose 来安装,发现端口映射以及 SSH Key 配置要麻烦很多。
数据库支持
Dokku 自身不支持数据库,但是可以通过插件的形式来支持。从传统的 MariaDB,[[PostgreSQL]],到 [[CouchDB]],[[Elasticsearch]] 等等,都可以从这个链接 查看。
如何部署应用程序
因为 Dokku 是一个 Heroku 的最小化实现,所以 Heroku 在 GitHub 仓库中的所有例子都可以在 Dokku 这里使用。
- python: python-django-sample
- java:java-sample
- spring:java-spring-sample
- scala:scala-sample
- php:php-getting-started
- go-kafaka:heroku-kafka-demo-go
如果安装好 Dokku,之后部署应用的步骤基本上也就是分成两部分,在本地完成代码,然后添加 Dokku 为远程,直接将代码推送到远程。
mkdir my-app
cd my-app
npx create-react-app .
git remote add dokku dokku@example.com:my-app
git push dokku master
更具体的部署操作可以查看这里。
Dokku 默认会使用 Heroku Buildpack 方式部署应用。Buildpack 由一系列脚本组成,会自动完成检测、构建、编译、发布等工作。
目前已支持 Ruby, Node.js, Java, Python, PHP, Go 等众多类型的应用。
常用的命令
创建应用
dokku apps:create $APP_NAME
总结
借助 Dokku 可以让你不在受限于 Firebase,Amazon Elastic Beanstalk,或者 Heroku 的平台,并且 Dokku 和这些服务相比丝毫不差。但于此同时,你需要自己维护 Dokku,并自己管理 Dokku 扩容以及 Dokku 运行的环境。
zlibrary 使用技巧
之前 zlibrary 的域名被取缔也曾经是一度的热门,但是 zlibrary 并没有就此消失。这篇文章就介绍几个继续使用 zlibraray 的小技巧。


如何访问 zlibrary
zlibrary 的很多域名都被 sized 了,包括
- https://z-lib.org/ 曾经的站点
- https://singlelogin.me/ 入口登录网站
但是 zlibrary 似乎搜集了很多不同顶级域名,虽然一直在被取缔,但是还一直有可访问的网址。我之前的文章 其实一直再更新。这里就放两个,如果还有更新我一般会更新到之前的文章里面。
- https://singlelogin.re/
- https://singlelogin.se
- 或者使用 Tor 地址
- 下载客户端 https://go-to-zlibrary.se/
Telegram Bot
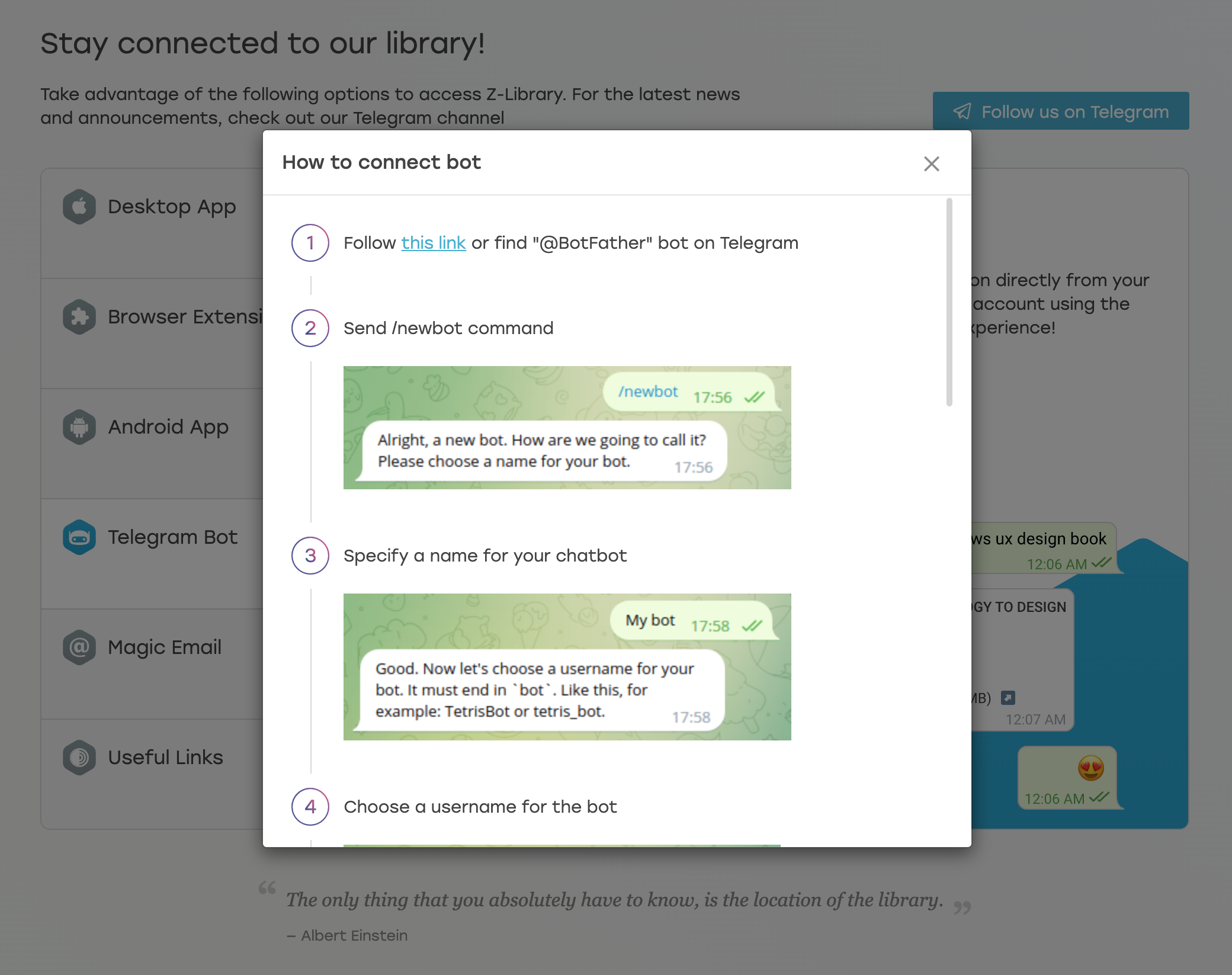
在使用自己的账号登录 zlibrary 之后,在我的页面中,可以找到绑定 Telegram Bot 的地方,
登录 zlibrary 之后,点击右上角

找到这个 Telegram Bot ,根据这个提示,在 Telegram 中创建 Bot,然后获取 Bot 的 API 。将这个 API 粘贴到网页上。
或者直接编辑个人页面,找到页面下方的 Personal Telegram bot

kindle bot
在绑定了 zlib Telegram bot 之后,只要发送书名,就可以返回搜索的书,然后可以将书转发到我写的 KindlePush bot 中,发到 Kindle
初次使用 KindlePush Bot 需要设置一下邮箱和帐户名密码。
私人访问链接
使用账号登录 zlibrary 登录之后可以获得两个私人的访问地址,可以保存到收藏夹然后就可以通过这个私人地址去访问了。
userscript
也可以使用如下的脚本
- https://greasyfork.org/zh-CN/scripts/428894-downloadbookfromipfs
会在界面中添加一个按钮用来在 [[IPFS]] 网络中下载。
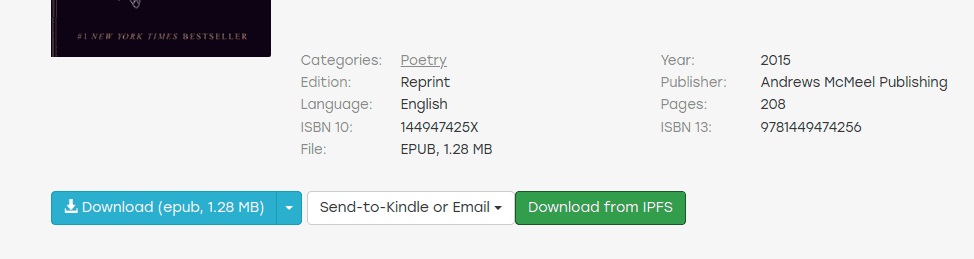
通过 IPFS 下载可以不占用 Zlibrary 的配额。
reference
《日本的细节》读书笔记
怎么知道的这一本书
很早之前整理有关日本的书籍的时候就看到过,但是最近拿起来这本书还是因为在公司的书架上看到了,然后就借回家读了读。
关于作者
蒋丰,对其人不太熟悉,看了一下书封面上的介绍,是 《日本新华侨报》的总编,在日本已经呆了 30 多年了,所以也就有了观察描写日本的资格。
之前在总结日本文化相关的书籍的时候,我自己做了一个分类,比如说有美国人旁观者身份去写的《菊与刀》,英国人写的《剑桥日本史》,有日本人自己写的《战后日本经济史》,还有中国人的观察笔记《静观日本》,对于日本这样一个主题能找到非常多的视角。而这一本《日本的细节》就是从一个现代中国人的视角重新去看日本生活中的细节。
几句话总结书的内容
作者通过如下的几个方面,对日本生活的方方面面细节进行了描绘。
- 城市建设
- 工业制造
- 公共服务
- 居住环境
- 教育
- 新农村
这本书抛开了所有宏伟的历史叙事,而仅仅是将当下,现实的日本生活中的细节,一一展现在读者面前。
启发或想法
日本的变化
这本书给我的最大收获就是让我看到了,日本社会的变化,正如书名《日本的细节》作者截取的当下日本生活的截面,但是放到历史的纵向,让我看到了为什么会变成这样。
- 交通安全,乱闯红灯
- 1980 年代,大家还是喜欢闯红灯,北野武还经常拿「大家一起闯红灯就不需要怕」来打趣。但是日本政府听取了各方意见之后,搞清楚了,没有人会拿自己的生命开玩笑。于是确立了「人高于车」的交通规则,行人优先的原则被体现到了交通管理的方方面面,《机动车损害赔偿保护法》最大限度保障行人安全、《交通无障碍法》确保步行者安全。
- 保障行人的等待红灯极限 90 秒,设置「步行者按钮」,路口修建天桥,控制小区内行车速度。日本逐渐构造起了为行人着想的交通体系,这种情况下还有必要闯红灯,谁还好意思闯红灯。
- 食品安全上
- 20 世纪 50 年代,日本也发生过森永毒奶粉事件,造成了 23 名儿童死亡,1463 名儿童。但是日本随后就大幅修改了《食品卫生法》,1960 年公布了《食品添加物法定书》,1968 年出台了《消费者保护基本法》,建立了食品安全出现问题首先是政府的责任。
- 医疗方面
- 我知道当前[[日本医药分离]]的制度,但是我不知道的是日本用了将近百年的时间才实现医药分离的改革。从明治 1874 年首次写入《医制》的医药分野,到平成 2007 年医药分业率达到 59.7%。为什么这个改革这么难实施,就是因为牵扯的利益太过于复杂和庞大。来看看日本政府做了那些改革
- 上调医生诊疗报酬,初诊为例,1960 年报酬为 18 点,1990 年之后,调整成了 210 点,增加了 12 倍
- 药价调查每两年实施一次,根据数据制定标准药价,保持药品市场的活力,又控制药价飞涨
- 防止医生和医疗机构过多用药和用错药,推广「固定药店」做法,鼓励患者尽量在一家点购买药品,药店专业的药剂师会为每一位患者建立用药档案,并在配药时询问患者病情,详细记载开药医生的名字和开药时间。一旦发现用药异常,就会询问患者的检查数据和原因。实现了对用药的系统管理,也对医生和医疗机构进行了一种监督。读到这里的时候我不经想起了日剧 [[重启人生]] 中主角因为是药剂师,看到外公吃两种不同的药会造成身体上的问题,于是就去药店询问药剂师,才发现是外公在两家药店分别拿药,导致药剂师不清楚用药情况而没有做出提醒,而主角通过自己的药剂知识延长了外公的生命。在另外一部石原里美演的电视剧 [[灰姑娘药剂师]] 里面也能对药剂师是一个什么样的职业有一个初步的了解
从这些变化上面也能看到,日本从来就不是那个遵守规则,文明开化的社会,但是能看到的是每一次社会出现问题,就立马会进行调整,纠错。这两天在 Twitter 上也看到了有人来日本旅游,高赞生活中遇见的一切,温热的马桶座垫,拥有不会缺纸的公共卫生间,干净的街道等等。但是我想说的是,每个国家都有每个国家的优点,每个国家也有每个国家的缺点,日本不是一个完美的国家,这个世界上也不存在一个完美的国家,但是这个世界上存在会进步(纠错)的国家,存在保守固执的国家。
日本的交通问题,食品安全问题,医药分离问题都是非常大的问题,甚至森永奶粉受害者们成立的自治受害者协会花了 10 年的时间才让森永低头认罪。这一下子就让我想到了 [[托克维尔]] 在 [[论美国的民主]] 中他观察到美国的[[公民自治]],观察到的自治团体在社会中产生的作用。而日本显然是有这样的自治团体出现的土壤的,人们会为了同一个信念而构成小团体,进而去纠正这个社会的错误。
一些小细节
- 透明雨伞
- 来东京之后,一直不知道为什么这边商店这么多卖透明雨伞的,并且在下雨的路上也能看到非常多的人使用透明的雨伞。直到我看到书中讲到,因为日本皇室使用 White Rose 生产的透明胶伞,并且使用透明伞,当在路上因为要避让行人的时候,会将伞稍微往低一些以防止发生碰撞,如果是透明的伞就不会遮挡住视线,及时把伞挡在身体前,也还是能看清道路上的状况。
- 日本的公交车会倾斜,让车距离站台更近
- 日本的酸奶盖不会粘到酸奶,这个小细节我是看到了书才意识到,我线下买过几次酸奶,打开塑料的盖子的时候,我甚至没有意识到,知道看到了书中的描绘回想才更感受「震惊」
一些书之外的东西
我过来日本这边也过去了半年,本来在过来一个月的时候就想写一篇总结,但因为拖延症,所以一拖再拖。但是读完这一本书又让我想起了,当时我想写没有写出的「细节」。
- 温暖的座便垫,因为过来的时候是冬天,那时候天还有点冷,但是我无论走到哪里的公共厕所的马桶坐垫都是温热的,这是让我第一次在异国他乡感受到的真正的「温暖」。并且在公共卫生间,几乎不用考虑卫生纸的问题,并且如果细心注意的话,大部分的卫生间是有两个卷纸槽的,我几乎没遇到过没有卷纸的卫生间
- 房屋入住指南,我从来没有想到过租房之后还会给我一本将近一厘米厚的说明书,因为我住在江东区,这本手册中不仅包含了屋内所有电器,开关的说明,还包含了防灾指南,包括地震,火灾,水灾。更让我惊讶的是这本手册中将历史上可能发生的水患用地图的方式标注出来了,非常直观,并且这一本厚厚的手册立即就让我对周围的设施有了一个初步的了解。
- 开关上的夜明灯,说实话我很久都没有注意到这个小小的夜明指示,因为很少夜起,直到很久之后我才在全黑的夜里发现了开关上的一点点绿色亮光,这一点亮光让我一下子就找到了开关的位置。这一点点小小的光,说不上是什么特别新奇的发明,但是却让我想起了之前在家里,在漆黑的晚上怎么都摸不到开关的窘境。
- 日本的空调温控,现在已经 9 月份,经过了 7 月,8 月的酷蜀,让我对我家里的空调有了全新的认识,因为入住的时候很偶然地别人送给了我一个带温度测量的时钟,我因为每一次都将空调放到 26 度,而我的时钟上则稳稳地显示室内的温度是 25.5 到 26 度。因为我曾经被北京的空调折磨地不行,同样的开 26 度,不是太冷就是太热,每一次都是热的时候调整成 24 甚至 20 度,冷的时候就得往上调整一下。而在这边,我开始的时候也以为这样所以每次都开到 24 度,但当我发现这边的空调温度控制能做到这么精确的时候就再没有调整过温度,一直都是 26 度,然后度过了一个夏天。
- 在读了上面这么多细节之后,另外一个我知道之后非常惊叹的是,日本超市中所有售卖的盒装饮料中,盒装牛乳的盒子上面有一道缺口,而其他的饮料,比如果汁,或者加工牛奶上面是平整的。


谁应该看这本书
对日本这个社会,国家比较感兴趣的人。
印象深刻的句子
- 一个民族,一旦敢于下定决心不惜付出生命的代价去学习异族的强势文化的时候,它的学习态度一定是恭敬虔诚的,它的学习精神一定是耐劳刻苦的,它的学习态度一定是精益求精的。
- 细节上下功夫,细节上取胜。
文章分类
最近文章
- 从 Buffer 消费图学习 CCPM 项目管理方法 CCPM(Critical Chain Project Management)中文叫做关键链项目管理方法,是 Eliyahu M. Goldratt 在其著作 Critical Chain 中踢出来的项目管理方法,它侧重于项目执行所需要的资源,通过识别和管理项目关键链的方法来有效的监控项目工期,以及提高项目交付率。
- AI Shell 让 AI 在命令行下提供 Shell 命令 AI Shell 是一款在命令行下的 AI 自动补全工具,当你想要实现一个功能,敲一大段命令又记不住的时候,使用自然语言让 AI 给你生成一个可执行的命令,然后确认之后执行。
- 最棒的 Navidrome 音乐客户端 Sonixd(Feishin) Sonixd 是一款跨平台的音乐播放器,可以使用 [[Subsonic API]],兼容 Jellyfin,[[Navidrome]],Airsonic,Airsonic-Advanced,Gonic,Astiga 等等服务端。 Sonixd 是一款跨平台的音乐播放器,可以使用 [[Subsonic API]],兼容 Jellyfin,[[Navidrome]],Airsonic,Airsonic-Advanced,Gonic,Astiga 等等服务端。
- 中心化加密货币交易所 Gate 注册以及认证 Gate.io 是一个中心化的加密货币交易所。Gate 中文通常被称为「芝麻开门」,Gate 创立于 2013 年,前身是比特儿,是一家致力于安全、稳定的数字货币交易所,支持超过 1600 种数字货币的交易,提供超过 2700 个交易对。
- 不重启的情况下重新加载 rTorrent 配置文件 因为我在 Screen 下使用 rTorrent,最近经常调试修改 rtorrent.rc 配置文件,所以想要找一个方法可以在不重启 rTorrent 的情况重新加载配置文件,网上调查了一下之后发现原来挺简单的。