从 Buffer 消费图学习 CCPM 项目管理方法
CCPM(Critical Chain Project Management)中文叫做关键链项目管理方法,是 Eliyahu M. Goldratt 在其著作 Critical Chain 中踢出来的项目管理方法,它侧重于项目执行所需要的资源,通过识别和管理项目关键链的方法来有效的监控项目工期,以及提高项目交付率。
CCPM 对于需要持续交付项目同时优化可用资源的团队来说是一个不错的选择。这个方法最初出现在 20 世纪 90 年代末,被宝洁,NASA 和德州仪器等公司所采用。
什么是 CCPM
CCPM 全称 Critical Chain Project Management,使用关键链方法的项目
- 在规划时概述项目依赖和资源限制
- 构建理想的项目工作流
- 如果有需要向项目添加额外资源
完成操作之后,项目经理就可以根据可用资源是否已经得到利用来跟踪项目进度。
CCPM buffer 管理法是 CCPM 中的一种关键概念,它基于关键路径和资源约束来管理项目的时间和资源。在 CCPM 中,项目的关键路径是指项目中的最长路径,它决定了项目的总体交付时间。资源约束是指在项目执行过程中可能会出现的资源瓶颈或限制,例如关键资源的有限可用性。
CCPM 基于三个主要的原则
- 打破对每项任务完成日期进行不健康承诺
- 考虑资源的真实情况来规划项目
- 将管理重点放在关键的事情上
然后最终决定任务完成日期。
为什么要有 CCPM
- CCPM 首先要解决的一个问题就是对不确定性的恐惧,项目工具固定任务所需要花费的时间来估算,但是在现实中,每个人都知道任务的消耗世间可能是不明确的,有可能 5 天就能完成,但是也可能延迟到 10 天,但大部分的情况下可以给出一个大概的估算,比如 90% 的可能在 8 天时间内完成
- 传统的项目管理无法充分利用提前完成的任务,而那些花费了比预计更长事件的任务会对后续的任务产生一系列连锁反应
- 当很多任务并行时,下游任务可以在计划日期开始的可能性非常低
- 大多数计划只考虑逻辑依赖,并假设资源立即可用,这通常会导致资源超载,延迟,多任务有压力。
- 多任务并行处理通常受到追捧,但是却有一定程度会对项目完成产生灾难性影响
- 越早开始做,就可以越早完成,当只有一件事情的时候,通常确实如此,但是如果同时处理很多事情时,可能现实情况恰恰相反
关键链(critical chain)和关键路径(critical path)的区别
关键路径法
- 注重于基本项目任务的单一序列
- 允许项目团队确定理想的工作流程,确保项目在预计时间内成功完成
- 优先级列表中删除不包含在关键路径上的任何任务
而在关键链方法中
- 最重要的是完成项目所需要的资源
- 多余的资源包含在项目中,充当资源缓冲区
- 如果团队没有利用任何额外的资源或资源缓冲区,则被认为正在成功前进
关键路径侧重于项目调度,而关键链更关注完成项目所需要的资源。
CCPM 的重点
关键
- 将项目拆分为更小的任务,确定两种任务,对项目至关重要的项目,一种是需要很长时间完成的任务
- 确定完成任务所需时间,传统项目管理中,通常强调每项小任务必需遵守计划制定的日期,但是在 CCPM 中为了补偿不确定性并兑现承诺,每个参与者都通过增加安全 Buffer 来增加每项任务的持续时间。
- 考虑项目中的任何资源限制,减少工作延误和中断
- 每一项任务都被拆分为专注期(Focus Duration)以及 Margin,这两部份共同组成 Task duration
- 团队中的每个人都专注于个人任务
- 禁止个人多任务切换
- 避免浪费时间,只计划完成任务所需要时间的 50%,如果需要更多的时间,可以使用缓冲区完成剩余工作,通过这种方法,团队可以提高工作效率
- 创建资源缓冲区,当任务需要更多时间才能完成时,资源缓冲区就会发挥作用。
在 CCPM 中,个别项目的延迟并不会影响到整个项目的工期,只是消耗掉一些缓冲而已,在剩余缓冲足够的情况下不需要采取任何措施。
什么是 Buffer
在 CCPM 中,buffer(缓冲, バッファー 消費)被用于管理项目中的不确定性和资源约束。
buffer 消费图包括了危险,警告,安全三个部分,分别是下图中的红色,黄色,绿色部分。
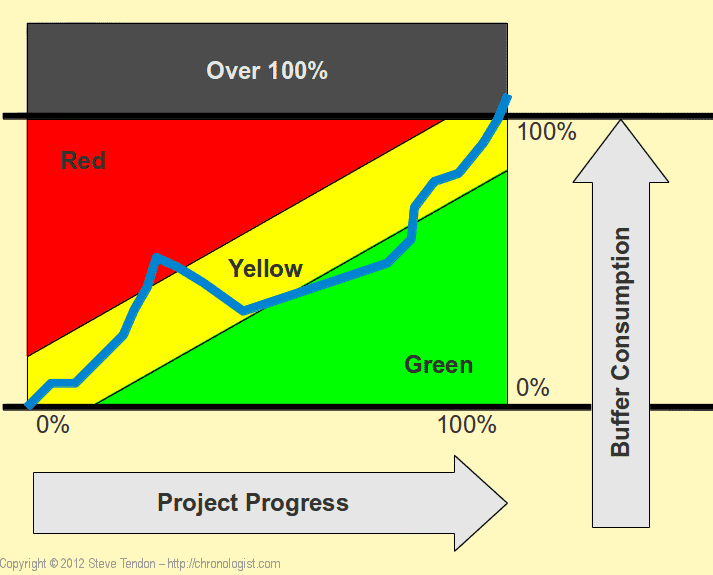
CCPM buffer 主要包括以下几个步骤:
- 确定关键路径:通过分析项目的任务依赖关系和持续时间,确定项目的关键路径。
- 识别资源约束:识别项目中可能出现的资源约束或瓶颈,例如某个关键资源的有限可用性。
- 创建 buffer:在关键路径上确定项目的关键链,然后为其创建 buffer。Buffer 可以分为两种类型:project buffer(项目缓冲)和 feeding buffer(供给缓冲)。
- Project buffer:位于项目的最后一个关键链任务之后,用于保护整个项目的交付时间。Project buffer 的目的是处理不可预测的任务延误或其他项目风险。
- Feeding buffer:位于关键链上的每个任务之前,用于保护任务的执行时间,以应对可能的资源约束或其他不确定性。
- 监控和管理 buffer:在项目执行过程中,通过监控关键链任务的进度和 buffer 的消耗情况,及时识别和处理潜在的风险和问题。如果 buffer 的消耗超过预期,项目团队需要采取相应的措施来恢复或调整项目进度。
CCPM buffer 管理法的核心思想是将 buffer 安排在项目的关键路径上,以平衡资源约束和不确定性,从而提高项目的交付时间和效率。通过有效地管理 buffer,可以更好地应对项目风险和不确定性,提高项目交付成功的可能性。
AI Shell 让 AI 在命令行下提供 Shell 命令
AI Shell 是一款在命令行下的 AI 自动补全工具,当你想要实现一个功能,敲一大段命令又记不住的时候,使用自然语言让 AI 给你生成一个可执行的命令,然后确认之后执行。
之前介绍过 GitHub Copilot CLI,这个作者受到此启发,做了一个开源版本的命令行工具。
安装
安装
npm install -g @builder.io/ai-shell
设置 API KEY
ai config set OPENAI_KEY=<your token>
会创建一个 .ai-shell 文件在 home 根目录。
用法
用法就非常简单
ai <prompt>
或者开启对话模式
ai chat
最棒的 Navidrome 音乐客户端 Sonixd(Feishin)
Sonixd 是一款跨平台的音乐播放器,可以使用 [[Subsonic API]],兼容 Jellyfin,[[Navidrome]],Airsonic,Airsonic-Advanced,Gonic,Astiga 等等服务端。 Sonixd 是一款跨平台的音乐播放器,可以使用 [[Subsonic API]],兼容 Jellyfin,[[Navidrome]],Airsonic,Airsonic-Advanced,Gonic,Astiga 等等服务端。
Sonixd 是一款非常优秀的云端音乐播放器软件,播放在云端储存的音乐。支持各种格式音乐文件,支持 Windows、MacOS、Linux 系统。打造自己的网易云音乐 PC 客户端,不再为付费及版权所困扰。
Sonixd 作者将 Sonixd 重写,并且重命名为 Feishin。
问题
安装的时候,如果遇到如下的问题,解决方案如下。
Sonixd.app is damaged and can’t be opened.
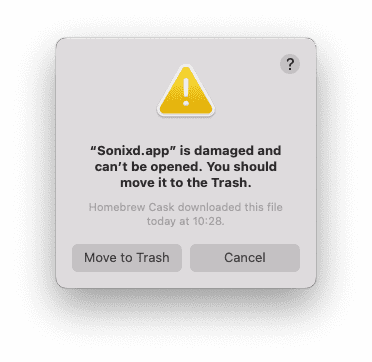
在终端执行
xattr -cr /Applications/Sonixd.app
然后重新打开即可。
Sonixd 是一款非常优秀的云端音乐播放器软件,播放在云端储存的音乐。支持各种格式音乐文件,支持 Windows、MacOS、Linux 系统。打造自己的网易云音乐 PC 客户端,不再为付费及版权所困扰。
Sonixd 作者将 Sonixd 重写,并且重命名为 Feishin。
问题
安装的时候,如果遇到如下的问题,解决方案如下。
Sonixd.app is damaged and can’t be opened.
在终端执行
xattr -cr /Applications/Sonixd.app
然后重新打开即可。
中心化加密货币交易所 Gate 注册以及认证
Gate.io 是一个中心化的加密货币交易所。Gate 中文通常被称为「芝麻开门」,Gate 创立于 2013 年,前身是比特儿,是一家致力于安全、稳定的数字货币交易所,支持超过 1600 种数字货币的交易,提供超过 2700 个交易对。
优势
- Gate 交易所支持的加密货币种类多
- 为用户提供上百种合约交易
- 提供永续合约,交割合约,期权和牛熊证
- Gate 提供 API 支持超过 300 种加密货币交易
- 支持 WebSocket 订阅
- SDK 支持包括 Python,Java,PHP,C#,NodeJS,Go,JavaScript 等
历史安全事故
- 2015 年 2 月,Gate 前身比特儿被黑客入侵,约 7170 枚 BTC 被盗
- 2019 年 1 月,ETC 区块链遭受 51% 攻击,被盗取 54200 ETC,此次攻击并非交易所责任,而是由于 ETC 网络算力不足造成,Gate 仍然承诺承担用户损失
Gate 在 2020 年推出 100% 保证金审计,以保护用户资产安全。
为什么我要开通 Gate
- Gate 提供的交易币种比较丰富,当然也可以说是山寨币比较多
- 在 Gate 参与空投的项目方比较多
- Gate 提供的 SDK 比较丰富,之后有时间可以进行探索
- 交易机器人跟投(新手不建议合约以及开大杠杆)
虽然之前已经注册过 Binance ,但是有一些小众的币种没有上线币安,另外币安的缺乏自动跟单系统。
注册条件
- 海外邮箱
- 海外 IP 地址
- 身份证
- 一台可以安装 Gate 应用的手机,需要用来人脸验证
注册流程
点击链接 进行,使用我的 链接 您可以获得 10% 的手续费折扣。
在官网输入邮箱和密码,完成邮箱注册之后,会收到一封官方的邮件,带有一个 6 位的验证码。输入验证码,然后完成注册。
完成身份认证
完成账号注册之后,需要完成 [[KYC]],在网站后台完成身份认证,个人信息只会作为平台的身份认证使用。
在网页「安全设置」,「身份认证」中,点击身份证,然后按提示输入居住地,然后身份证号码,然后上传身份证的正反面,提交之后等待审核完成(一般在几小时内,个人提交后几分钟就完成了)
在提交完身份证之后,可以根据自己的需求完成「地址认证」。
为了确保账号的安全,建议根据后台的提示完成 Gate 账号的二步验证,设定交易密码,完成手机账号绑定。
自此之后就可以开始欢乐地交易之旅了。
如何购币和充值
使用手机账号登录 Gate 之后,在首页就可以明显的看到两个按钮「快捷买币」以及「充值」。可以通过 P2P 的购买,或者直接通过链上转账完成向 Gate 的充值。
不重启的情况下重新加载 rTorrent 配置文件
因为我在 Screen 下使用 rTorrent,最近经常调试修改 rtorrent.rc 配置文件,所以想要找一个方法可以在不重启 rTorrent 的情况重新加载配置文件,网上调查了一下之后发现原来挺简单的。
首先因为我是在 screen 下使用,所以先
screen -ls
screen -r session_id
重新 attach 上,然后就进入了 rTorrent。
按下快捷键 ctrl + x,进入 command 模式
然后输入
import=~/.rtorrent.rc
回车
最后离开 screen
ctrl a+d
reference
Go 语言编写的网络穿透工具 chisel
chisel 是一个在 HTTP 协议上的 TCP/UDP 隧道,使用 Go 语言编写,10.9 K 星星。
工具采用 HTTP 进行数据传输,将 TCP 和 UDP 封装在 HTTP 隧道中。可以用来做 [[内网穿透工具]]。
chisel 只有一个二进制可执行文件,客户端和服务端都包含在内。
在之前的文章中,介绍过不少内网穿透的工具,比如 [[frp]],[[nps]],还有一些已经非常成熟的商业化工具 [[Tailscale]] ,[[ZeroTier]] 等等,感兴趣可以查看历史的文章。
作用
chisel 这一类的工具可以有很多种用途,比如常见的端口转发,内网穿透等。
- 也可以用来绕过防火墙,比如通常防火墙会禁用掉一些非常用的 TCP 协议,通过 chisel over HTTP 的特性就可以绕过此防火墙
安装
直接通过 GitHub release 获取二进制
或者通过 Docker
docker run --rm -it jpillora/chisel --help
或者 Go
go install github.com/jpillora/chisel@latest
macOS 下也可以
brew install chisel
端口转发
比如一台内网的服务器 10.0.0.1 上有一个本地端口 8000 的服务,目前没有暴露给外部访问。如果要在另外一台机器上能访问该服务。可以执行如下的操作。
在这一台服务器上执行 chisel 服务端,暴露 12000 端口
./chisel server -p 12000
在另外一台服务器 10.0.0.2 上,保证可以访问 10.0.0.1,然后执行
./chisel client 10.0.0.1:12000 28000:127.0.0.1:8000
这样就将 10.0.0.1 的本地 8000 端口,转发到了 10.0.0.2 机器的 28000 端口,此事在 10.0.0.2 机器上到 28000 的访问,就会通过 chisel 转发到 10.0.0.1 机器的 8000 端口。
比如可以用 Python 直接起一个测试的服务 python3 -m http.server --bind 127.0.0.1 8000
反向连接
刚刚上面的操作是通过在 10.0.0.2 机器作为 chisel 的 client。
同样也可以将 10.0.0.2 作为 chisel 的 server,比如在 10.0.0.2 服务器上
./chisel server -p 12000 --reverse
开启 reverse 之后,表示服务器端使用反向模式,流量转发到哪一个端口由 client 端指定。
然后在 10.0.0.1 服务器上执行
./chisel client 10.0.0.2:12000 R:28000:127.0.0.1:8000
此时 10.0.0.2 机器上也可以通过 28000 端口来访问 10.0.0.1 的 8000 端口。
socks 代理
除了直接转发 HTTP ,chisel 也可以设置 socks 代理。
比如在服务器中执行
./chisel server -p 12000
客户端可以
./chisel client server_ip:12000 socks
这个时候就默认开启了一个 1080 端口的 socks 代理,当然这个端口可以自己设置,结合 Socks 代理工具,或者 Proxychains 等工具就可以直接利用这个 socks。
经过上面的说明,既然 chisel 可以作为 Socks5 代理,那么其实用来作为穿透 GFW 的工具也是可以的
在公网的服务器上
chisel server -p 3000 --socks5
然后在本地执行
chisel client server_ip:3000 socks
使用 Bunny CDN 加速你的网站
前两天看到 Twitter 上有人发帖说求推荐 CDN,突然发现很多人其实不知道 Bunny CDN,虽然这一家 CDN 成立时间比较早了,但是很多人还是只知道大名鼎鼎的 Cloudflare。这里就简单的介绍一下这个 CDN 吧。
Bunny 是一家成立于 2014 年的 CDN 加速服务商,提供快速、强大且价格实惠的 CDN 加速服务,总计 80Tbps+网络,连接 3000 多家 ISP 和 14 家一级传输提供商,采用顶级 AMD CPU 和 NVMe+ SSD 服务器,平均 24 毫秒延迟,并提供最先进的 DDoS 缓解安全措施,帮你的网站抵御任何攻击。
Bunny 的域名 DNS 解析服务除了基本功能还具有负载均衡、地理/延迟智能解析,还可使用编写脚本的 DNS 记录简化部署、做出智能路由决策。另外,bunny.net 还提供对象存储、网站压缩优化、在线视频存储播放等服务。
Bunny CDN 提供节点非常地多,其中亚太节点在二十多个,包括日本东京、韩国首尔、中国香港等,这些节点都是连接速度快节点。
简单注册个 Bunny.net 账号就可以获得 14 天 1TB 流量免费试用,并且还可以使用优惠码免费充值 5 美元额度!按照最低 0.01 美元/GB 的定价这 10 美元免费额度可以用 1TB CDN 流量,当然也可以用于使用 Bunny 的域名 DNS 解析、对象存储、网站压缩优化、在线视频存储播放等服务。
功能
- 支持一键设置 SSL
- 提供 Smart Cache 功能,当站点离线也可以访问到 Bunny 节点上缓存的内容
- 兼容 S3
- 自定义访问规则,可以配置一键屏蔽某个地区
- Bunny 还提供了 WordPress 插件,
如果你也想尝试一下 Bunny 可以点击这里 访问。
注册账号之后,记得在站内兑换优惠码,价值 5 刀,BUNNYFIVER,如果兑换码出现问题,欢迎加入讨论群一起讨论。
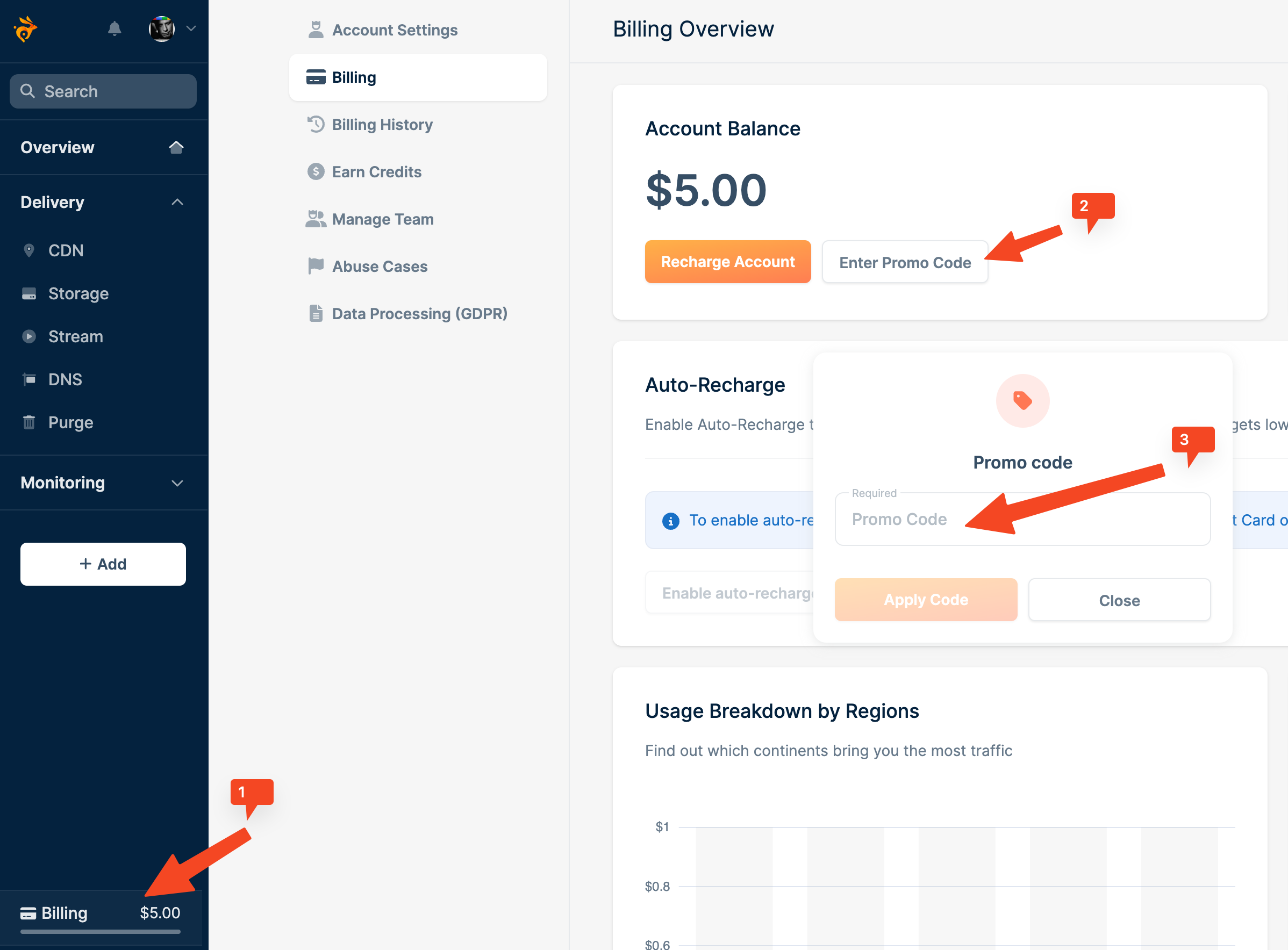
设置
和大多数 CDN 的设置一样,当注册完成账号之后,可以点击页面中的 「Add Pull Zone」 创建 CDN。
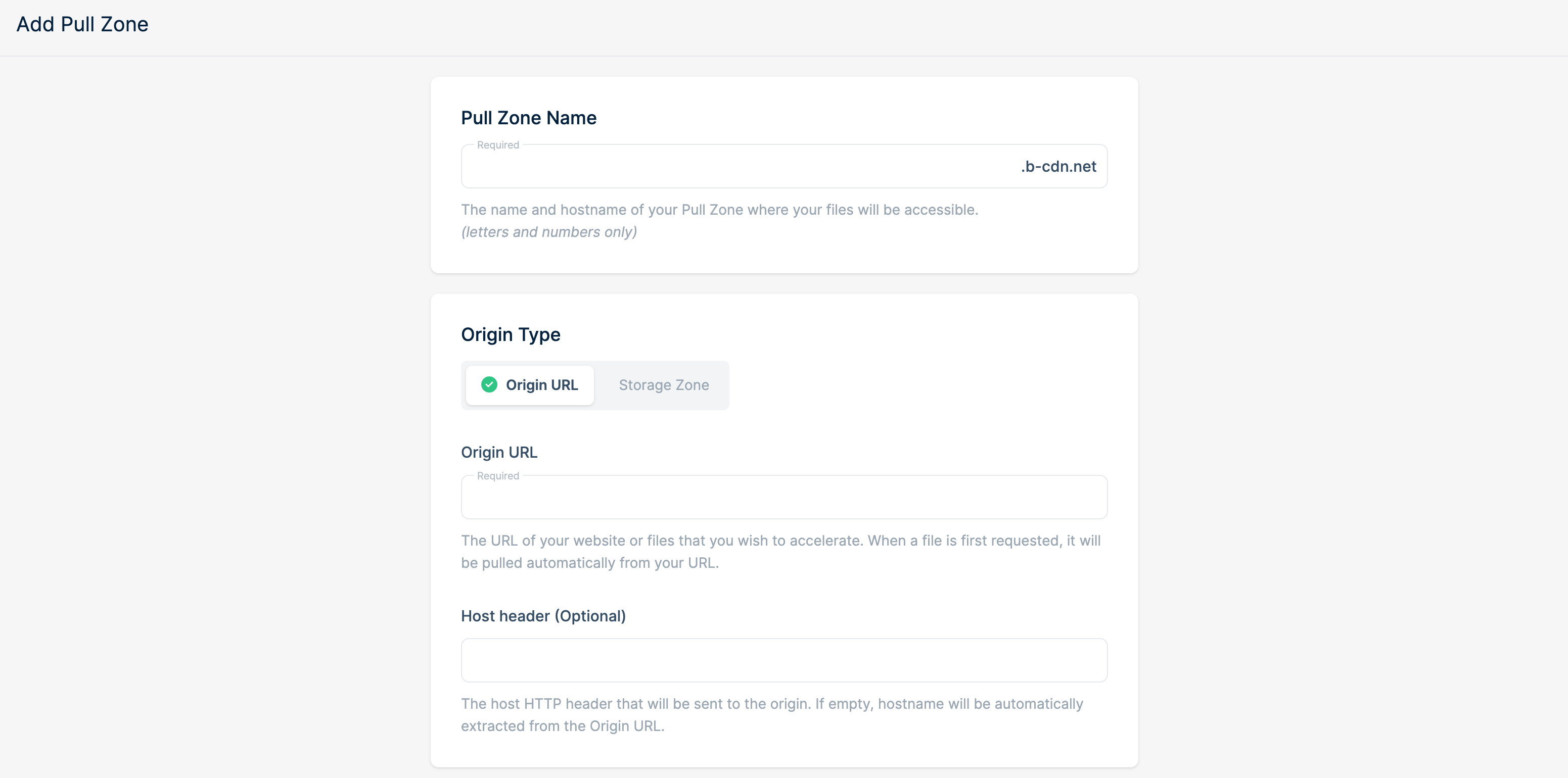
填入自定义的 Pull Zone Name,然后在 Origin URL 中填入需要加速的网站地址。接下来根据自己的需求选择 CDN 地区,页面上也会表明不同地区的价格。
然后绑定自定义域名,因为 Bunny 默认的域名是 xxx.b-cdn.net ,你可以根据自己的需求比如将静态资源全部设置为 asset.your-domain.com 这样,那么直接在 Add Custom Hostname 中添加自己的域名即可。
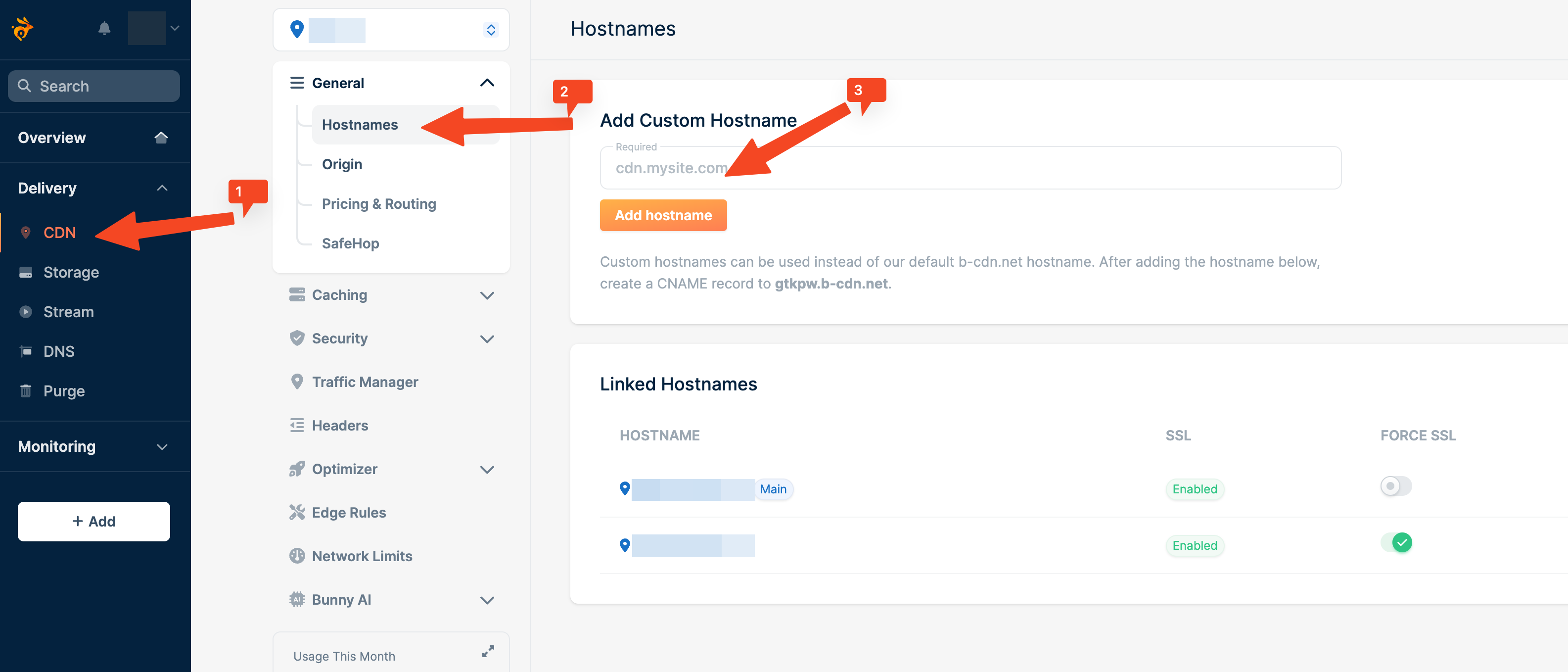
添加完成之后需要配置 DNS 的 CNAME 记录,比如将 asset.your-domain.com 指向 Bunny 给出的 Hostname。等待 DNS 解析完成即可使用自己的域名来访问 CDN。
Bunny 也提供免费的 SSL 证书,到页面上一键申请即可。其他 CDN 的设置根据自己的需求进行设置即可。
related
- [[Cloudflare]]
- [[Fastly]]
绕过付费墙
今天早上看到一篇 WSJ 的分享,但是点进去发现竟然只能看个开头,所以兴起整理一下这篇文章。
bypass-paywalls
之前我就知道一个叫做 bypass-paywalls 的插件,但是因为因为更换电脑 所以 Chrome 上没有配置,所以立即设置起来。
git clone git@github.com:iamadamdev/bypass-paywalls-chrome.git
cd bypass-paywalls-chrome
cd build && sh build.sh
然后将此文件夹拖拽到 chrome://extensions。
但当我安装完成之后发现,WSJ 可能检测到了该插件,查看 Chrome 的请求,直接返回 401,感觉应该就是检测并且屏蔽了该插件。
Bypass Paywalls Chrome Clean
于是我就又找了一个插件 Bypass Paywalls Chrome Clean,这个插件在原来的插件基础上,增加了一个非常独特的功能,那就是当发现内容已经被 archive.is 等内容缓存的时候,就直接将网页内容替换为缓存的内容,间接实现了绕过付费墙的目的。
Bypass Paywalls Chrome Clean 的安装也非常简单,直接 clone 项目,然后拖拽到 Chrome 即可。
related
最后再补充一个网站,把链接直接输入进去,可以查看原文
基于表格的无代码数据库 Teable 介绍
Teable 是一个非常快,实时,专业,开发者友好的 No Code 数据库。Teable 构建在 PostgreSQL 之上,使用一个简介的,表格类似界面,可以基于此构建复杂的企业级别的数据库应用。
功能
Spreadsheet-like 界面
- 单元格编辑,每一个单元格都可以编辑
- 公式支持,支持直接在单元格进行公式计算
- 数据排序和过滤,基于列或者多列的排序过滤
- Aggregation Function,聚合方法,根据列,计算,统计 sum, average,count,max,min 等
- 数据格式化,格式化数字,日期等
- 分组,行组织成组
- 固定列,固定表格左侧的列,滚动时可见
- 导入导出 csv xlsx 格式
- 行样式和条件格式
- 图表和可视化工具,从表格数据创建图标,比如条形图,饼图,折线图等(即将推出)
- 数据验证,限制或验证单元格中的数据(即将推出)
- 撤销和重做(即将推出)
- 评论和注释(即将推出)
- 替换查找(即将推出)
多视图
以特定的方式显示数据
- Grid View,网格视图,默认,电子表格形式展示
- Form View,表单格式,用于输入数据
- Kanban View,看板显示(即将推出)
- Calendar View,日历视图 (即将推出)
- Gallery View,图库视图(即将推出)
- Gantt View,甘特图,项目进度(即将推出)
- Timeline View,时间线视图(即将推出)
速度快
- 支持数百万数据
- 自动索引
- 批量操作
SQL 支持
- 可以与 BI 工具,比如 [[Metabase]],[[PowerBi]] 等工具集成
- 和 [[Appsmith]] 这样的 No code 工具集成
- 支持原生 SQL 直接检索数据
Privacy First
- 支持自己托管数据
实时协作
- 为团队涉及,支持数据实时更新
- 支持团队协作,成员邀请和管理
- 完全的权限机制,支持表和列级别
扩展性
- 基于 React 的无后端编程能力
- 极低成本定制自己的应用程序
- 扩展脚本
Automation 自动化
- 使用 AI 或者可视化编程设计工作流
Copilot (即将推出)
- 通过聊天创建项目表格
- 澄城条形图分析
- 查看日程安排
- 等等
关键词说明:
- Space,Teable 中所有的内容都通过 Space 来管理,每一个 Space 都是独立的空间,可以邀请协作者单独管理 base
- base,是 Database 的缩略语,是存储数据的地方,workflow 也依赖于此
- table,用来管理不同的数据集
- view,用户可以创建 Grid,Form views,Gallery,Kanban,Calendar views 等等
总结
在 GitHub Trending 上看到这个项目就点开来看了一下,直接拉下来代码,看到当前项目的完成度还不错,直接在服务器上就跑起来了,但看到官方的说明,项目还在构建当中,还有很多功能在慢慢推进,我自己的话还没有来得及每个功能都尝试一遍,但以当前的完成度,还是果断关注一下,这个项目的想象空间还是挺大的,毕竟有了灵活的数据库可视化,很多服务都可以被代替掉。
related
- [[PostgreSQL]]
- [[Airtable]]
聊一聊 Devin 第一个完全自主的 AI 工程师
Devin 是 Cognition 发布的一款完全自助的 AI 软件工程师。1
Fully Autonomous AI Software Engineer Devin 完全自主人工智能软件工程师 Devin
Devin 主打的就是通过 prompt 自主的学习,编写,调试,甚至可以进行部署。在 Cognition 发布的视频来看,Devin 至少能够
- 进行网页浏览,比如查看并理解 GitHub Issue
- 自主学习 API 文档
- 进行编码,根据 Upwork 上的实际问题来编码
- 调试
- 修复错误
和传统的 AI 对话框不一样,Devin 自带了命令行,编辑器,甚至还自带了一个浏览器。
DHH
伴随着 Devin 的发布 DHH 也发布了一篇博文《Developers are on edge》,讲述了 AI 可能对程序员造成的影响,他说到现在软件开发行业遭受着双重打击,一方面科技行业一直在裁员,而另一方面还要面临 AI 带来的巨大威胁。
That’s the trouble with The Future. It’s awfully difficult to predict when it’ll actually arrive. All we’re doing is making bets and taking guesses.
文中 DHH 做了一个非常形象的比喻,过去农业需要全球 97% 的人参与其中,而今天只需要 2% 的人口。尽管农业生产总价值上升了很多,但是从事农间生产的人却少了很多很多。归咎其原因就是因为科技发展所带来的自动化进程,使得从事农业生产的人只需要动一动手指就可以管理大面积的农田。
那未来程序员的职业何尝不可能发展成这样呢?或许 AI 的发展会使得软件开发行业面临前所未有的变化,当软件行业不再需要那么多程序员进行手动编程的事后,这一个行业可能就已经达到了顶峰,但 DHH 也说了这并不意味着这个行业的小时,而更可能会让 AI 在社会生活中被更广泛的使用和融合,软件行业可能不需要那么多的手工编码程序员,但是他所产生的价值却还是会给社会带来巨大的福利。长期来看,没有任何职业可以成功抵御因为技术进步所带来的自动化而遭淘汰的命运,积极地拥抱变化,看向未来才是当下我们所能做的最后一件事情。
文章分类
最近文章
- 从 Buffer 消费图学习 CCPM 项目管理方法 CCPM(Critical Chain Project Management)中文叫做关键链项目管理方法,是 Eliyahu M. Goldratt 在其著作 Critical Chain 中踢出来的项目管理方法,它侧重于项目执行所需要的资源,通过识别和管理项目关键链的方法来有效的监控项目工期,以及提高项目交付率。
- AI Shell 让 AI 在命令行下提供 Shell 命令 AI Shell 是一款在命令行下的 AI 自动补全工具,当你想要实现一个功能,敲一大段命令又记不住的时候,使用自然语言让 AI 给你生成一个可执行的命令,然后确认之后执行。
- 最棒的 Navidrome 音乐客户端 Sonixd(Feishin) Sonixd 是一款跨平台的音乐播放器,可以使用 [[Subsonic API]],兼容 Jellyfin,[[Navidrome]],Airsonic,Airsonic-Advanced,Gonic,Astiga 等等服务端。 Sonixd 是一款跨平台的音乐播放器,可以使用 [[Subsonic API]],兼容 Jellyfin,[[Navidrome]],Airsonic,Airsonic-Advanced,Gonic,Astiga 等等服务端。
- 中心化加密货币交易所 Gate 注册以及认证 Gate.io 是一个中心化的加密货币交易所。Gate 中文通常被称为「芝麻开门」,Gate 创立于 2013 年,前身是比特儿,是一家致力于安全、稳定的数字货币交易所,支持超过 1600 种数字货币的交易,提供超过 2700 个交易对。
- 不重启的情况下重新加载 rTorrent 配置文件 因为我在 Screen 下使用 rTorrent,最近经常调试修改 rtorrent.rc 配置文件,所以想要找一个方法可以在不重启 rTorrent 的情况重新加载配置文件,网上调查了一下之后发现原来挺简单的。