Prometheus: 监控系统和时序数据库
Prometheus 是一个用 Go 写的监控系统,最早由 SoundCloud 开发并开源,Prometheus 内置一个时序数据库。Prometheus 受到 Google borgmon 监控系统启发,2012 年起源于 SoundCloud 内部,后来成为第二个加入 Cloud Native Computing Foundation 的项目。
It collects metrics from configured targets at given intervals, evaluates rule expressions, displays the results, and can trigger alerts if some condition is observed to be true.
Prometheus 以固定的频率从配置的目标采集监控指标信息,经过计算,显示结果,并且观察到某些条件成真时发出告警。
Prometheus 区别于其他监控系统的地方在于:
-
一个多维的数据模型(Dimensional data model 通过指标名字定义的时序以及键值的组合)
- 时序数据通过 metric 和 key-value 区分
- metric 可以设置任意维度标签
- 双精度浮点,Unicode 标签
- 灵活强大的查询语言 ([[PromQL]]),可以轻易的利用其多维信息
- Prometheus 服务是一个单独的二进制文件,可以直接在本地工作
- 无需依赖分布式存储;单服务器节点是自治的 (single server nodes are autonomous)
- 高效:每个采样点只有 3.5 bytes 占用,单一服务每秒可以处理百万级别 metrics
- 通过在 HTTP 上的 pull 模型实现采集
- pushing timeseries 通过中间网关支持
- 监控目标可以通过服务发现 (service discovery) 或者静态配置 (static configuration) 实现
- 多种图形和仪表板支持,结合 Grafana 可以实现更丰富的展示
- 支持分层和水平的联合 (federation)
SoundCloud 在其官方博客 Prometheus: Monitoring at SoundCloud 中提到设计这套监控系统的目标:
A multi-dimensional data model, so that data can be sliced and diced at will, along dimensions like instance, service, endpoint, and method.
Operational simplicity, so that you can spin up a monitoring server where and when you want, even on your local workstation, without setting up a distributed storage backend or reconfiguring the world.
Scalable data collection and decentralized architecture, so that you can reliably monitor the many instances of your services, and independent teams can set up independent monitoring servers.
Finally, a powerful query language that leverages the data model for meaningful alerting (including easy silencing) and graphing (for dashboards and for ad-hoc exploration).
除了上面提到的 Prometheus 特性,在后来的发展中,Prometheus 不断的新增特性,比如 服务发现,外部存储,告警规则和多种通知方式。
Prometheus 目前已经支持 Kubernetes, etcd, Consul 等多种服务发现机制。
为了扩展 Prometheus 的采集能力和存储能力,Prometheus 引入了”联邦”的概念。多个 Prometheus 组成两层联邦,上层定时从下层 Prometheus 节点获取数据并汇总,部署多个联邦节点实现高可用。下层节点分别负责不同区域的数据采集,下层 Prometheus 节点可以被部署到单独的机房充当代理。
Prometheus 组成
Prometheus 有很多可选组件:
- Prometheus Server: 收集存储时间序列,并对外提供 API,提供 PromQL 查询语言
- Client:为需要监控的服务生成相应的 metrics 并暴露给 Prometheus Server,Server pull 时直接返回实时状态
- Push Gateway:用户可以主动向其中 push 数据,用于短期 job
- Exporters: 暴露已有的第三方服务 metrics,等待 server 拉取
- Alertmanager: 从 Prometheus server 接收到 alerts 后,进行数据处理,发出报警,报警方式有:邮件,Slack,pagerduty, OpsGenie, webhook 等
大致工作流:
- Prometheus Server 定期从配置的目标 (Target) 或者 exporters 中 pull 拉取 metrics,或者接收来自 Pushgateway 发送的 metrics
- Prometheus 在本地存储 metrics 数据,并通过一定规则清洗整理数据,把得到的结果记录到时间序列
- 得到数据后,根据制定的报警规则,计算报警指标
- Alertmanager 根据配置,对接收到的报警进行处理
- 在图形界面中可视化采集的数据
从上面的介绍能比较清晰的看到 Prometheus 定时从被监控的组件中获取监控数据,而任意的组件只要提供对应的 exporter (Prometheus 这里使用 HTTP 协议) 就可以快速接入监控。这种模式就特别适合微服务,或者容器。而目前常见的组件,Prometheus 都提供了对应的 exporter,比如 Haproxy, Nginx, MySQL, Linux 系统信息等等。
相关概念
数据模型
时间序列由 metric 名和一组 key-value 标签组成。
- metric 名:语义的名字,一般用来表示 metric 功能,比如: http_requests_total, http 总请求数。metric 名由 ASCII 字符,数字,下划线,冒号组成,必须满足
[a-zA-Z_:][a-zA-Z0-9_:]*1 - 标签:一个标签就是一个维度,
http_requests_total{method="Get"}表示所有 http 请求中 Get 请求,method 就是一个标签,标签需要满足[a-zA-Z_:][a-zA-Z0-9_:]*1 - 样本:实际时间序列,每个序列包括 float64 值和一个毫秒级时间戳
组合样式:
<metric name>{<label name>=<label value>, ...}
举例:
http_requests_total{method="POST",endpoint="/api/tracks"}
metric 类型
Client 提供如下 metric 类型:2
- Counter: 累加 metric,只增不减的计数器,默认值为 0,典型应用场景:请求个数,错误次数,执行任务次数
- Gauge: 计量器,与时间无关的瞬时值,值可增可减,比如:当前温度,CPU 负载,运行的 goroutines 个数,数值可以任意加减,node_memory_MemFree 主机当前空闲大小,node_memory_MemAvailable 可用内存
- Histogram:柱状图,直方图,表示一段时间内的资料信息,用于请求时间,响应大小,可以对结果进行采样,分组和统计
- Summary: 类似 Histogram,但提供了 quantiles 功能,昆虫安装百分比划分结果,比如 quantile 为 0.99,表示取采样数据中的 95 数据。
Installation & Usage
Prometheus Server
Prometheus Server 可以有很多安装方式,Docker,Ansible,Chef,Puppet,SaltStack 等等,具体可以参考官网。
通过 Docker 安装:
docker run --name prometheus -d \
-p 9090:9090 \
-v ~/docker/prometheus:/etc/prometheus \
prom/prometheus
如果把 Prometheus 的配置映射到了本地,可以直接去 ~/docker/prometheus/ 下查看配置。
或者使用 Docker compose:
version: '2'
services:
prometheus:
image: prom/prometheus
volumes:
- ./prometheus.yml:/etc/prometheus/prometheus.yml
command:
- '--config.file=/etc/prometheus/prometheus.yml'
ports:
- '9090:9090'
Node exporter
Prometheus 主要用于监控 Web 服务,如果要监控物理机,则需要在机器上安装 node exporter, exporter 会暴露 metrics 给 Prometheus,包括 CPU 负载,内存使用,磁盘 IO,网络等等。[^exporter]
[^exporter](https://github.com/prometheus/node_exporter#enabled-by-default)
node exporter 安装步骤:3
在官网 获取最新的 node exporter 地址:
curl -LO https://github.com/prometheus/node_exporter/releases/download/v0.18.1/node_exporter-0.18.1.linux-amd64.tar.gz
解压
tar -xzvf node_exporter-0.18.1.linux-amd64.tar.gz
移动到 /usr/local/bin 目录
sudo mv node_exporter-0.18.1.linux-amd64/node_exporter /usr/local/bin/
创建 node exporter service,首先创建用户,然后添加服务
sudo useradd -rs /bin/false node_exporter
sudo vi /etc/systemd/system/node_exporter.service
保存如下内容:
[Unit]
Description=Node Exporter
After=network.target
[Service]
User=node_exporter
Group=node_exporter
Type=simple
ExecStart=/usr/local/bin/node_exporter
[Install]
WantedBy=multi-user.target
重新加载 system daemon,启动服务:
sudo systemctl daemon-reload
sudo systemctl start node_exporter
sudo systemctl status node_exporter
开机启动:
sudo systemctl enable node_exporter
服务启动后会监听 9100 端口,使用如下命令验证:
curl http://localhost:9100/metrics
或者查看 9100 端口是否起来 netstat -anp | grep 9100.
配置这台服务器作为 Prometheus Server 的 Target 监控目标。
sudo vi /etc/prometheus/prometheus.yml
在 scrape 配置下,记得 IP 换成自己的
- job_name: 'node_exporter_metrics'
scrape_interval: 5s
static_configs:
- targets: ['10.10.0.1:9100']
重启 Prometheus 服务,如果是 Docker 起的,则需要重启容器
sudo systemctl restart prometheus
到 Prometheus 后台 Targes 下验证是否添加成功。
简单查询验证:
node_memory_MemFree_bytes
node_cpu_seconds_total
node_filesystem_avail_bytes
rate(node_cpu_seconds_total{mode="system"}[1m])
rate(node_network_receive_bytes_total[1m])
Alert Manger
Alert Manger 也可以通过 Docker 来安装使用:
docker run -d -p 9093:9093 \
-v /path/to/alertmanager/config.yml:/etc/alertmanager/config.yml \
--name alertmanager \
prom/alertmanager
push gateway
Prometheus 默认的数据采集方式是通过 pull 模型,在配置中能看到 5 秒的配置,但是如果有些数据不适合使用这样的方式来监控,那么就需要使用 Push Gateway 将数据 Push 给 Prometheus 。
docker run -d -p 9091:9091 --name pushgateway prom/pushgateway
通过浏览器访问 9091 端口,Prometheus 提供了多个语言的 SDK 用来想 Push Gateway 发送数据,为了测试可以使用 shell 命令:
echo "cqh_metric 100" | curl --data-binary @- http://ip:9091/metrics/job/cqh
推送多个指标:
cat <<EOF | curl --data-binary @- http://ip:9091/metrics/job/cqh/instance/test
muscle_metric{label="gym"} 8800
bench_press 100
dead_lift 160
deep_squal 160
EOF
Grafana
通过 Docker compose 安装:
grafana:
image: grafana/grafana
volumes:
- grafana_data:/var/lib/grafana
environment:
- GF_SECURITY_ADMIN_PASSWORD=pass
depends_on:
- prometheus
ports:
- '3000:3000'
Prometheus config
在安装好 Prometheus 会有 yaml 格式的配置文件。主要分为这几个部分:
global: 全局配置scrape_configs: 定义 Prometheus 需要 pull 的目标alerting: Alertmanager 配置rule_files: 告警规则
更多参数的解释可以参考官网.
alert rules
告警配置样例。
# Alert for any instance that is unreachable for >5 minutes.
ALERT InstanceDown # alert 名字
IF up == 0 # 判断条件
FOR 5m # 条件保持 5m 才会发出 alert
LABELS { severity = "critical" } # 设置 alert 的标签
ANNOTATIONS { # alert 的其他标签,但不用于标识 alert
summary = "Instance down",
description = " of job has been down for more than 5 minutes.",
}
使用 Prometheus 监控 Flask 应用
我在最初寻找监控系统的时候就是为了给 Flask 应用使用。而 Prometheus 在各个方面都超出了我的预期,不过再回到原始的初衷。
Flask 中使用 Prometheus 需要引入 prometheus_client , Prometheus 的 Python 客户端。
import prometheus_client
from prometheus_client import Counter
from flask import Response, Flask, jsonify
app = Flask(__name__)
total_requests = Counter('request_count', 'Total webapp request count')
@app.route('/metrics')
def requests_count():
total_requests.inc()
return Response(prometheus_client.generate_latest(total_requests), mimetype='text/plain')
@app.route('/')
def index():
total_requests.inc()
return jsonify({
'status': 'ok'
})
if __name__ == '__main__':
app.run(host='0.0.0.0', port=5000)
修改 prometheus.yml 配置文件。
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']
- job_name: 'api_monitor'
scrape_interval: 5s
static_configs:
- targets: ['web:5000']
PromQL
Prometheus 内置了数据查询语言 PromQL,它提供对时间序列数据丰富的查询,聚合以及逻辑运算的能力。同时也可以利用 PromQL 做告警和数据可视化。利用 Prometheus 可以轻易的回答这些问题:4
- 访问量前 10 的 HTTP 地址
topk(10, http_requests_total) - 计算 CPU 温度在两个小时内的差异
delta(cpu_temp_celsius{host="zeus"}[2h]) - 预测系统磁盘空间在 4 个小时之后的剩余情况
predict_linear(node_filesystem_free{job="node"}[1h], 4 * 3600) - 过去 5 分钟占用 CPU 最高的应用服务
PromQL 是 Prometheus 中非常重要的概念。最简单的使用方式就是输入指标名称,比如
up
指定 label 查询:
up{job="prometheus"}
或者使用 Instant vector selectors:
up{job!="prometheus"}
up{job=~"server|mysql"}
up{job=~"10\.10\.0\.1.+"}
=~ 正则匹配,使用 RE2 语法
选择一段时间内所有数据,Range vector selectors,比如查询 5 分钟内所有的 HTTP 请求数:
http_requests_total[5m]
Range vector selectors 返回的数据类型是 Range vector,一般需要和 rate() 或 irate() 函数一起使用。
# 计算的是每秒的平均值,适用于变化很慢的 counter
# per-second average rate of increase, for slow-moving counters
rate(http_requests_total[5m])
# 计算的是每秒瞬时增加速率,适用于变化很快的 counter
# per-second instant rate of increase, for volatile and fast-moving counters
irate(http_requests_total[5m])
PromQL 还支持 count, sum, min, max, avg, stddev(标准差),topk(前 k 条), quantile(分布统计), 等聚合操作,支持 rate, abs, ceil, floor 等内置函数,更多例子见官网.
和其他监控系统对比
Prometheus 值得注意的点
上面这么多文字可以看到 Prometheus 是一个很强大的监控系统,同时部署也非常方便,但 Prometheus 也并非 Silver Bullet,它并不能用来解决一切问题。可以注意到的是 Prometheus 非常适合微服务架构,利用服务发现可以轻松的将监控目标扩展到成千成万。
数据非 100% 可靠
Prometheus 采集的数据可能有丢失,不适用于对采集数据要求 100% 精确的场景。Prometheus 只针对可用性及性能进行监控,不具备日志监控等功能。
存储有限
Prometheus 只认为最近的监控数据有查询需求,Prometheus 在设计之初将数据保存在本地就并非为大量数据存储。如果需要对历史数据进行分析,可以使用 Prometheus 提供的远端存储 OpenTSDB, M3db 等等。
无权限系统
Prometheus 没有任何权限管理的功能,它只专注于做好一件事情,那就是监控及告警,Prometheus 认为权限管理应该属于上层管理系统去维护,所以 Prometheus 在设计时没有考虑任何权限管理问题。
reference
- https://github.com/prometheus/prometheus/
- https://www.ibm.com/developerworks/cn/cloud/library/cl-lo-prometheus-getting-started-and-practice/index.html
- https://youtu.be/PDxcEzu62jk
- https://www.aneasystone.com/archives/2018/11/prometheus-in-action.html
- https://www.infoq.cn/article/275NDkYNZRpcTIL2R8Ms
使用 asdf-vm 管理编程语言多个版本
之前浏览文章的时候偶然看到了 asdf 这个项目,然后惊讶的发现它整合了我之前经常使用的 pyenv 还有不太常用的 jenv, nvm, rvm,通过这一个命令就可以实现,所以立马在机器上试了一下。
Install
安装的过程具体可以参考官网,这里不多展开,Mac 下可以使用 Homebrew, 不过个人还是偏好使用 git clone 安装:
git clone https://github.com/asdf-vm/asdf.git ~/.asdf
然后在 ~/.zshrc 中添加:
. $HOME/.asdf/asdf.sh
Plugin
asdf 通过插件的形式可以添加不同语言的支持。支持的所用插件可以在这里 看到。
asdf plugin add python
安装具体版本:
asdf list all python
asdf install python latest
asdf install python 3.6.1
设置版本
asdf global python 3.6.1
asdf shell python 3.6.1
asdf local python 3.6.1
在 sudo 中使用 asdf
使用 asdf 安装的环境都在用户目录下, 如果要在 sudo 中使用,则会报错 sudo: xxx command not found,因为 sudo 默认不会将用户的环境变量传递过去。如果要在 sudo 中使用,则需要手动指定 PATH:
sudo -E env "PATH=$PATH" [command] [options]
可以设置一个 alias:
$ alias mysudo='sudo -E env "PATH=$PATH"'
reference
Linux 内存管理初识
DMA 内存区域,0~16MB 内存。
NORMAL 内存区域,16MB~896MB
HIGHMEM,高端内存区域。
用户空间
用户进程访问的内存空间,每个进程有自己的独立用户空间,虚拟地址从
0x00000000 到 0xBFFFFFFF
总容量 3G.
进程与内存
按照”访问属性” 划分五个不同的内存区域。
代码段
存放可执行文件的操作指令,可执行程序在内存中的镜像。
只读,不可写
数据段
可执行文件中已初始化全局变量,静态分配的变量和全局变量。
BSS
未初始化的全局变量
heap
heap 用来存放进程运行时被动态分配的内存段,大小不固定。
malloc 新内存加到 heap,free 时从 heap 释放。
stack
- 临时的局部变量,函数中定义的变量(不包括 static)
- 函数被调用时,参数也会被压入发起调用的进程栈中,调用结束时,返回值也会被存放到栈
可以使用 size 命令来查看编译后的程序在各个内存区域的大小,比如查看 sshd 进程:
which sshd
sudo size /usr/sbin/sshd
现金流桌游
今天和几个小伙伴体验了一下“现金流”这款桌游,其实在很早之前看过《穷爸爸,富爸爸》之后就了解到了这款游戏,但一直没有机会去尝试。很多人把这款桌游“吹”的很神,就像是玩过就能[[财富自由]]一样,虽然实际生活并不会像游戏一样,但多少能从中体验到一些心得。
规则
现金流的规则可以说是非常简单的了,玩过大富翁吗?把大富翁地图上的各种地标换成各种人生事件,领工资,各种机会,生孩子,失业等等,那就是游戏的开始。当然如果要跳出无穷无尽的轮回则需要思考自己手上资产负债表中的各项数字。从“老鼠圈”跳转到人生的快车道。
具体细节的规则网上也有很多,这里就不展开。直接贴一个视频吧。
基本设置:
- 身份卡,填写资产损益表
- 掷骰子
- 银行结算日
-
机会卡,小生意,大买卖
- 房产
- 股票
- 基金
- 额外支出卡
- 慈善事业,总收入 10%,下三次掷骰子两颗
- 失业,支付总支出,停两轮
- 小孩,增加小孩,增加支出
-
银行贷款
- 现金方式贷款,千的整数倍,最多月现金流的十倍
- 负债增加银行贷款
- 支出一栏增加银行贷款
- 总支出增加银行贷款
- 月现金流减去银行贷款支出
Balance Sheet & Income Statement
在游戏之前,或者说在我叙述下文心得之前,有必要先来熟悉这张表格。

图片来自于 richdad,这张图片早在 1998 年就申请了专利。
{kind=link}
这张表格上半部分是叫做 Income Statement,中文又称为[[资产损益表]]。下部分叫做 Balance Sheet , 中文一般翻译成资产负债表。
个人觉得在完这个桌游之前一定要先了解 Accounting 相关的概念,当然这只是个人的看法,这个游戏其实并没有要求这个,但我觉得如果能提前知道一些记账的概念会对整个游戏有更加深刻的理解。
看到上面的这张图,在游戏中是一张非常重要的图。从上到下基本可以划分成这样几块:
- Income
- Expenses
- Passive Income & Total Expenses & Monthly Cash Flow
- Assets
- Liabilities
Income(收入) 和 Expenses(支出) 就不再多说,Passive Income 是非工作收入,Total Expenses 总支出,Monthly Cash Flow 是月现金流。
可以得到一个简单的公式:Income + Passive Income - Total Expenses = Monthly Cash Flow.
这是一个非常显而易见的事情。而对一般人而言比较陌生的是下面两项,也就是 Assets 和 Liabilities,分别是资产和负债。增加资产能够一定程度上带来非工资收入,而这里的资产又包括了现实生活中的很多种,包括股票,基金,存单,房产,公司等等。而负债则包括住房抵押贷款,信用卡,房地产抵押贷款,名下企业的负债等等。
用简单的话总结,假如你拥有一处房产,每个月能带来 1000 元的房租收入,那么这个房产就是 Assets 资产;而相反如果该房产每个月需要花费 1000 维护成本,那么这个房产就是 Liabilities 负债。用《富爸爸,穷爸爸》书中更加直白的话就是,放钱到口袋的就是资产,从口袋拿钱走的叫做负债。
关于资产和负债更详细的讨论可以参考之前写的复式记账.
记账这件事
我一直对记账这件事情如鲠在喉,很早 就在寻找合适的记账应用,也陆陆续续用了一些,以前我对记账这件事情是想要做到事事巨细,无论大额小额都记下来。但今天结束游戏时,我才发现我曾经做的,只是资产损益表中的一个数字,叫做总支出。大部分情况下我并不关心这部分支出是信用卡消费,还是其他贷款。而我做的事情其实只是资产损益表中绝大部分时间不会变化的事情,就像游戏中每个角色的固定支出一样。而表格剩下的大部分,其实在我做的记账中并没有显示出来。所以这里也不得不提到复式记账的应用 beancount 了,玩过游戏后才对真正对复式记账有更深刻的了解。
非工资收入
在游戏的过程中,我是真的花费了很长很长的时间才从“老鼠圈”中跳脱出来,这不仅是因为是第一次玩需要熟悉各种设定及规则,也更是因为需要在游戏的设定中找到真正的 Assets。跳出老鼠圈的关键点是,非工资收入大于总支出,而非工资收入怎么来,游戏中可以包括利息,股息,房地产投资,企业现金流等等,而和现实生活一样,往往很多人在最开始的时候并没有那么多现金来购买这些 Assets,游戏过程中一半我才意识到现金的重要性,这也怪不得那么多公司一到经济不景气的时候就开始大量屯积现金,手中有现金的时候,才不会在机会来临的时候错失,也不会因为现金不足而陷入失业等等困境,甚至在拥有孩子的时候也可以从容的应对。
但如果从游戏的世界跳脱出来,在现实世界中如果要去寻找非工资收入的 Assets 呢?有这么样几个,我觉得可以供参考。
- 稳定企业的股票
- [[债券]]或银行存单,享受虽不高但稳定的利息
- 能够产生收入的房产
- 版权,知识产权
除开投资企业以及房产,我看到在介绍 Business 的一段话深入我心。
The purpose of a business is to solve a problem.
真正值得投资的是那些解决社会问题的商业模式。发现一个问题,并用自己的方式解决这个问题,这个过程很难,也非常漫长,但是现在成熟的市场可以容下试错的成本,Uber 从一个小城市开到全世界,Airbnb 让全世界一起共享客房,Facebook 从校园走向社会,Netflix 从租赁服务转型到线上流媒体,这个世界上有着这种用自己的方式发现问题并尝试解决问题的人。如果能成为那样的人必然已经逃离了“老鼠圈”,而如果没有成为那样的人,如果能发现并支持他们,自然也能够逃离“老鼠圈”。
关于失业
今天的游戏,可以说我是逃避不了“失业”,几乎每一次都准确的停留到了失业一格,但问题的关键也是,我手中并没有那么多的现金,导致我在很长一段时间内都几乎在原地踏步。四个多小时,还在转圈,但最最关键的也是,在计算好手中的现金后,一定要择时机购入优质的资产,我用 1 美元购买的股票,升值到 40 元,虽然买的不多,但那足以成为人生的第一桶金,于是在后面我用其购入房产,购入高现金流的资产,再长达五个小时后终于跳出了“老鼠圈”,所以人生不要失望,祸兮福之所倚,谁知道未来会发生什么呢。
游戏心得
这款游戏在初期会有很长一段时间在“老鼠圈”不断的轮回,经常会有这些跳不出“老鼠圈”的理由。
机会不好,运气差
在今天下午的游戏中便是这样的情况,我 5 次失业,几乎每次都近乎破产,更甚至第一轮扔骰子就到了“额外支出”,只有 400 存款的我,需要支付 600,直接出局。虽然这可能是游戏设定的 Bug 啊,但下午真的运气太差,刚买的房产,经济不景气银行就回收了。刚购入股票,就失业了,只能半价抵押给银行。
但遇到这样的情况游戏中怎么办呢,只能默默的积攒机会,攒够足够的现金,并进行合理的投资。充分利用向其他玩家甩卖机会卡的方式,积攒现金。
失业生孩子太多次
另外一桌有一个玩家就是生了三个孩子,本来作为卡车司机的他收入并不高,而生孩子带来的巨大生活开支,直接击垮了后面的游戏乐趣。这种情况下,在真实生活中就应该做好规划。而游戏中只能检视现金,资产负债表,并且积攒足够的现金,慢慢的积累财富。
买不起房子
由于我们是第一次玩,并没有了解到向银行贷款的规则,所以在前期几乎都是白白的错失了眼前的机会。在遇到好的 Assets 时,可以果断的向银行进行贷款。当然这都是需要建立在一个好的月现金流的基础之上的。否则银行也不会贷款给资产差的人。
买了太多房子
游戏中还真的遇到了这样的玩家,作为医生的他,依靠前期大量的月现金流积累了早期资产,但是一直没有遇到能够增加现金流的优质房产,虽然依靠股票和房产赚得了很多的现金,但这些现金在手中一直没有花出去。而遇到这种情况就需要用卖出股票或转卖房地产,先获取第一桶金,然后再购买高现金流的资产。
缺点
当然这款游戏也有其固有的“缺点”,那就是在对资产负债表的结算,当然其实这也是这个桌游最最精华的部分,那就是通过对自己资产负债表的结算,加深自己对资产的认识。而也正是这一个过程,使用纸质的负债表实在会拖慢游戏的进度。经常的情况便是需要花费近乎一半的时间来对资产负债表结算。
现金流桌游中能快速变化的数字是,非工资收入, 股票 / 基金 / 存单,地产,投资 等等。个人的总收入和总支出并不能改变,我觉得这是这个游戏并不合理的地方,假如让我改进这个游戏,我会让每一个人有一个技能点数,如果有机会走到一些可以改变技能的地方,可以改变自己的总收入。或者设计一种模式来减少自己的贷款,减少总支出。
最后
虽然花了一个下午的时间来熟悉这个游戏,最终也没人真正的达到游戏胜利的条件,但是其实不应该忘记的是,这个游戏胜利的条件并不是你多有钱,而是实现你的梦想,每个人在开始的时候都选择了一个梦想。不管在游戏中还是在现实生活中,钱永远也不应该成为人生的目标,而是应该找到自己的梦想,用一生去追求。
每天学习一个命令:qmv 在文本编辑器中对文件及目录进行编辑
在给 tldr review 提交时,有一个命令引起了我的兴趣,那就是 qmv,当时简单的尝试了一下,浏览了一下 man page。没有仔细的深入,但昨天突然遇到一个需求,我要批量修改一个目录下文件的大小写,需要将大写部分修改成小写,一下子就想起了这个命令。虽然这个命令是作为移动来介绍的,但它也可以作为重命名来使用,毕竟重命名也算是移动的一种嘛。
命令的使用特别简单,直接使用 qmv 后面接目录名即可,然后会打开默认的文本编辑器, 比如vi,然后在其中能看到两列,左边是原始名字,后面是目标名,如果要批量修改重命名那就直接对后面一列进行编辑即可。最后保存退出,那么 qmv 会自动把所作的修改应用到文件中。

延展
qmv 是属于renameutils 这个包,这个包中还有 qcp 和 qcmd,看名字应该比较好猜,cp 和 cmd,复制和执行。
通过如下方式安装:
sudo apt install renameutils
macOS 下:
brew install renameutils
reference
Github Actions 使用
GitHub Actions 是 GitHub 推出的 CI/CD 工具,通过简单的语法可以做一些 build, deploy 等等的事情。
Workflow
放在仓库根目录 .github/workflows 文件夹下。yaml 格式。语法规则见:
寻找 Actions
官方的 Actions 都放在 https://github.com/actions 仓库中。
- 官方的市场 https://github.com/marketplace?type=actions
- Awesome actions https://github.com/sdras/awesome-actions
在命令行下给 socks 或者 http 代理测速
在国内不可避免的要用到代理,这些年陆陆续续从 GAE 上的代理,到自己购买 VPS 搭建,从 Shadowsocks 到 V2ray,自己花费了不少的时间,而现在虽然手上也有两台 VPS,但是已经不拿他们作为主要的代理了,我一台 Directspace 的 VPS,线路没有优化过,到国内的延迟略高,而另一台 AWS 的 EC2,虽然地理位置在韩国,也只勉强到能用的阶段。所以这两年陆陆续续不再自己维护代理服务,之前有购买过因为 Ingress 结缘的 Shadowsocks 服务,一直用到现在,虽然有些情况下会发生断流,倒也一直没有放在心上。直到尝试了一周的 V2ray 服务提供商,我想是回不去 SS 了。
那么有什么方法来对一个代理服务的提供商的速度进行测试呢?这就是这篇文章的最主要的内容。
YouTube
我知道很多的人拿 YouTube,右击查看 Stats for nerds.

可以看到其中有一条 Connection Speed,这个图片中的速度大概在 15~18Mbps,转换一下大概在 2~3MB/s 的速度,这个速度看个 1080p,大概是可以了,如果要追求更高的画质那么还需要更高的比特率,不过对于我来说,这已经足够了,毕竟我的 MSI 显示屏也只有 1080p 而已。
speedtest-cli
但 YouTube 毕竟只是一种方式,如果想要更加精确的测速,有一个网站叫做 speedtest,一般我用来测试都用这个,或者还有一个 Netflix 提供的 fast.com.
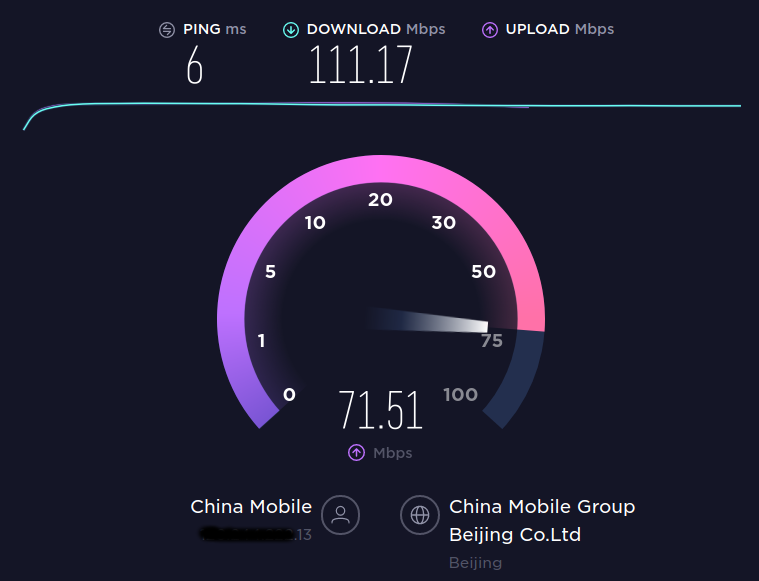
结果:
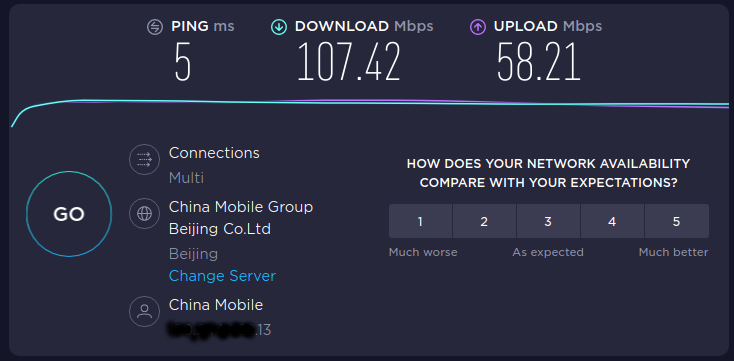
但其实 speedtest 可以在命令行下进行。
首先要先安装 pip, 然后在安装:
pip install speedtest-cli
运行:
➜ speedtest-cli
Retrieving speedtest.net configuration...
Testing from China Mobile Guangdong (xxx.xxx.xxx.13)...
Retrieving speedtest.net server list...
Selecting best server based on ping...
Hosted by Beijing Broadband Network (Beijing) [1.67 km]: 11.141 ms
Testing download speed................................................................................
Download: 124.99 Mbit/s
Testing upload speed......................................................................................................
Upload: 4.17 Mbit/s
speedtest 的测速的时候会根据位置选择不同的节点,不同的节点会对结果有一定的影响。
对代理进行测试
既然有了上面的基础 speedtest-cli 命令,那么在 Linux 下,HTTP 代理也好,socks 代理也好都可以通过 speedtest-cli 来直接在终端下进行测试。
首先要知道本地的 socks 代理地址,Shadowsocks 一般的本地 socks 地址是:
socks://127.0.0.1:1080
对 socks 代理进行测速
要对 socks 代理进行测试则先要安装 proxychains,然后通过
sudo apt install proxychains4
proxychains4 curl ip.gs
来验证已经走了代理。再通过如下命令进行测速:
proxychains4 speedtest-cli
在输出的一大堆日志中可以查看到下载和上传的速度:
Download: 18.65 Mbit/s
Upload: 4.01 Mbit/s
对 HTTP 代理进行测速
对 HTTP 代理的测试相对要简单一些。开启 V2ray 代理,我用的 Linux 下 V2rayL 的客户端,在配置中可以看到 HTTP 的代理端口是 1081.
export http_proxy=http://127.0.0.1:1081
curl ip.gs
# 确保自己的 IP 已经变成代理的 IP,然后运行
speedtest-cli
老版本的 speedtest-cli 中对 http_proxy 支持可能有问题,确保自己的的是最新的版本:
➜ speedtest-cli --version
speedtest-cli 2.1.2
推广时刻
这里提供我测试用的一个是我以前用的 SSR 服务,一个便是新的 V2ray 的服务:
当然拿两者对比速度是没有意义的,服务器不同,协议也不同,只是提供一个方法让大家的选择服务商的时候能够对自己所用的服务有一个基本的了解。对于我的情况新的 wujievpn 几乎提供了我翻了一倍的下行速度。Download 从 18.65 Mbit/s 提高到了 34.5 Mbit/s。所以还是值得一提的。
如果有人想要尝试,欢迎使用我的邀请链接:
reference
- 感谢 @sivel 提供这么好用的命令行测速工具 speedtest-cli
OpenWrt 学习笔记
硬件
CPU
- Atheros/QualCom 高通 (QCA)
- BroadCom 博通 (BCM)
- MediaTek 联科发 (MTK)
- RealTek 瑞昱
RAM
- SDRAM
- DDR, DDR2, DDR3
ROM(Flash)
- SPI Flash
- NOR Flash
- NAND Flash
WiFi 芯片接口
- USB(速度相对较慢)
- PCI-e
软件
BootLoader
Wiki
CPU, 网卡数据库 Wiki:
reference
- 《跟着佐大学 OpenWrt 开发入门》
小米路由器 3G 刷机及固件
记录一下小米路由器 3G 的刷机历程,过程步骤是比较简单,但就是配置过程有点心酸,理论上是应该直接就能工作的,但是我的情况比较特殊,想用 OpenWrt 的无线中继来着,但是用别人的固件,和我自己编译的固件都无法在小米路由器 3G 上实现无线中继。
OpenWrt 固件
我的另一台 WNDR 3800 直接配置就可以无线中继,但是小米的配置后就各种问题。
无线未开启或未关联
最一开始就是,开启无线中继后 5G 信号显示,“无线未开启或未关联”。
网上查到解决方法是需要将国家修改为美国,2.4G 信道设置为 11, 5G 信道设置为 149(如果是无线中继,那么和主路由保持一致即可),然后重启路由器。
重启路由器后确实看到一块网卡已经可以,但总是有一块还是报错。
查看内核日志
[ 246.611715] wlan1: deauthenticated from fc:7c:01:dd:5b:7a (Reason: 15=4WAY_HANDSHAKE_TIMEOUT)
去查看这个日志也找不到原因。故放弃转下载了 Padavan 的固件。
Padavan
Padavan 是俄罗斯开发者在华硕的路由器系统中延伸而来。Padavan 针对 mtk 芯片,梅林固件是针对博通芯片。功能相似。
在 Padavan 的固件中,直接 5G,设置无线桥接
- 无线 AP 工作模式: AP-Client + AP
- 无线 AP-Client 角色:这里我选 LAN Bridge(因为我想要我这台接入的设备 IP 和主路由 IP 在同一个网段),而如果你想要 Padavan 连接的设备有一个新的 IP 段,这里可以选择 WAN(Wireless ISP)
- 然后选择上级 SSID,自动获取信道,授权方式,密码,应用
到这里就完成了 Padavan 中设置无线中继。另外我还去 LAN 设置中把 LAN 的 DHCP 关了。
然后再在 LAN 设置中将 LAN IP 地址,也就是 Padavan 的管理后台设置一个在主路由中的静态 IP,我的主路由网关是 192.168.2.1 所以我给 Padavan 设定了一个 192.168.2.2。
另外要注意的是 Padavan 固件中有一个路由器运行模式,如果像我一样作为无线中继使用,也别尝试接入点模式 (AP) 模式,除非你一定要把路由器当成交换机使用。
接入点模式的介绍:
MI-R3G 连接到外部有线 / 无线路由器并且提供无线网络共享。 该模式下 NAT、防火墙、UPnP、DHCP 服务不可用,并且 WAN 端口直接连接到 LAN 端口。
在该模式下 WAN 口的作用也和 LAN 口一样。那么假如安装我上面的配置,Padavan 就无法进入管理后台了,因为 Padavan 只作为一个无线交换机在发挥功能。所以如果要使用该模式,一定把 LAN 口地址改成和无线中继的网段不一样的网段,这样了解网线,然后使用静态 IP 地址连接电脑还能上管理后台,否则就只能恢复出厂设置了。
Padavan 的默认 WiFi 名是 PDCN(PDCN_5G),默认的密码是 1234567890,后台管理管理页面是 192.168.123.1 ,默认的用户名和密码是 admin/admin.
如何进入 Breed
Breed 下载地址:https://breed.hackpascal.net/
刷入 Breed 的方法就不说了,网上太多了。这里记录一下怎么进入 Breed,因为我总是忘记。
- 断电
- 按住 reset
- 通电
- 指示灯先黄色闪烁,然后蓝色闪烁
- 用网线连接 LAN,和电脑
- 进入
192.168.1.1
几大路由器固件的历史
思科发布 wrt54 路由后未遵循开源协议被告,之后迫于压力发遵循 GPL 发布了 wrt,再之后 wrt 延伸出社区版的 openwrt、HyperWRT 等,华硕也发布了 asuswrt(GPL 开源协议)。在华硕开源 asuswrt 后,开发者们基于此开发了梅林和 Padavan (老毛子)。
而开源社区这边,openwrt 又衍生出 dd-wrt、石像鬼、lede 等。其实现在用 arm 架构的路由器基本上全是 wrt 系统,包括 newifi, 极路由等等。
个人的局域网网络设置整理
最近因为想要调查我屋里网络带宽的瓶颈,把整个家里的网络环境整理了一番,也把本来乱七八糟的各种 IP 也梳理了一下。纯粹整理,如果不关心的可以跳过。
现在我有两台路由器,准确来说是三台,一台主路由基本不动,负责接入互联网,稳定为主,千兆。一台房间的副路由,无线中继主路由,IP 由主路由分配,还有一台本来做了无线桥接,有一个新的网段,现在想逐渐弃用,转移到同一个网段,便于管理。
路由器设置 DHCP
主路由和副路由的网络设置,就不赘述,主路由没有什么设置,主要是副路由需要设置无线中继 +AP,我这里没有用主路由的 SSID,新产出了一个新的 SSID,如果在个人家中其实用同一个 SSID 即可,可以无缝切换。
QNAP static ip
QNAP 设置静态地址
网络与虚拟环境中,找到之前设定的对应的接口,QNAP 中叫做虚拟交换机,直接通过 UI 界面修改即可。
Proxmox static ip
Proxmox 的网络接口配置在 /etc/network/interfaces 文件中。
类似这样:
auto lo
iface lo inet loopback
iface enp3s0 inet manual
auto vmbr0
iface vmbr0 inet static
address 192.168.2.100
netmask 255.255.255.0
gateway 192.168.2.1
bridge_ports enp3s0
bridge_stp off
bridge_fd 0
修改其中的 address, netmask, gateway 即可。修改保存后重启,或者 systemctl restart networking.service
Raspberry Pi static ip
树莓派是网线接入,所以需要设置 eth0 的静态地址。
如果是用网线,eth0 端口,编辑 /etc/dhcpcd.conf:
interface eth0
static ip_address=192.168.2.4/24
static routers=192.168.2.1
static domain_name_servers=192.168.2.1 8.8.8.8
重启:
sudo reboot
如果使用的是无线网卡,那么需要设置 wlan0 网卡:
# 查看当前配置
ifconfig -a
# 查看 wifi 配置
less /etc/wpa_supplicant/wpa_supplicant.conf
# 修改配置
sudo vi /etc/dhcpcd.conf
修改内容,和上面类似,注意把 IP 替换成对应内网的地址,别直接复制使用:
interface wlan0
static ip_address=192.168.2.4/24
static routers=192.168.2.1
static domain_name_servers=192.168.2.1 8.8.8.8
注意配置 Raspberry Pi 网卡地址的时候千万要小心,否则一旦配置错误,如果又是作为服务器使用的话,可能造成无法获取局域网地址从而无法连接,那么就可能需要键盘和显示器来登录重新配置,所以谨慎。
Other devices
其他的 Linux PC 可以选择 DHCP,也可以配一个静态的 IP,因为不需要连接所以不知道自动获取的 IP 也关系不大。
为什么路由器的设置地址都是 192.168 开头
IPv4 地址协议中预留了 3 个 IP 段,作为保留地址给专有网络使用。
- A 类地址:10.0.0.0–10.255.255.255
- B 类地址:172.16.0.0–172.31.255.255
- C 类地址:192.168.0.0–192.168.255.255
那么回到这个问题上,为什么家用的路由器默认分配的地址都是 192.168.1.x 或者 192.168.2.x 等等,举一个简单的例子,假如路由器使用 192.168.1.1/24 网段,那么在这个网络中可以容纳的机器数是 192.168.1.2-255 共 254 多个可用的 IP,一般家庭的设备连接足够。当然能够带动这么多设备的路由器性能也需要足够好了。
而假如你的局域网中可预期将会有几千几万太设备那么必然 192.168.1.x 的网段是不能用的,必须用到
172.16.0.0/12可容纳 1048576 个地址10.0.0.0/8可容纳 16777216 个地址
下面两个地址自然个人是用不这么多的。
reference
文章分类
最近文章
- 从 Buffer 消费图学习 CCPM 项目管理方法 CCPM(Critical Chain Project Management)中文叫做关键链项目管理方法,是 Eliyahu M. Goldratt 在其著作 Critical Chain 中踢出来的项目管理方法,它侧重于项目执行所需要的资源,通过识别和管理项目关键链的方法来有效的监控项目工期,以及提高项目交付率。
- AI Shell 让 AI 在命令行下提供 Shell 命令 AI Shell 是一款在命令行下的 AI 自动补全工具,当你想要实现一个功能,敲一大段命令又记不住的时候,使用自然语言让 AI 给你生成一个可执行的命令,然后确认之后执行。
- 最棒的 Navidrome 音乐客户端 Sonixd(Feishin) Sonixd 是一款跨平台的音乐播放器,可以使用 [[Subsonic API]],兼容 Jellyfin,[[Navidrome]],Airsonic,Airsonic-Advanced,Gonic,Astiga 等等服务端。 Sonixd 是一款跨平台的音乐播放器,可以使用 [[Subsonic API]],兼容 Jellyfin,[[Navidrome]],Airsonic,Airsonic-Advanced,Gonic,Astiga 等等服务端。
- 中心化加密货币交易所 Gate 注册以及认证 Gate.io 是一个中心化的加密货币交易所。Gate 中文通常被称为「芝麻开门」,Gate 创立于 2013 年,前身是比特儿,是一家致力于安全、稳定的数字货币交易所,支持超过 1600 种数字货币的交易,提供超过 2700 个交易对。
- 不重启的情况下重新加载 rTorrent 配置文件 因为我在 Screen 下使用 rTorrent,最近经常调试修改 rtorrent.rc 配置文件,所以想要找一个方法可以在不重启 rTorrent 的情况重新加载配置文件,网上调查了一下之后发现原来挺简单的。