MySQL Binary Log 清理
Binary Log 中包含了
- 数据库更改的事件,比如表创建或者数据更改
- 一条语句更新数据花费的时间
Binary log 的目的:
- For replication,在 replication 源服务器的 binary log 提供了数据更改的记录,这些记录会发送给 replicas。源服务器会将 binary log 发送给 replicas,然后在 replicas 服务器中重新执行事务,以做到和源服务器相同的数据更改。[[MySQL Replication 主从同步原理]]
- 特定的数据恢复操作需要依赖于 binary log。在备份恢复之后,在 binary log 中被记录的 events 可以从备份点开始被重新执行,这些修改会将数据库状态更新到最新
binary log 不会记录那些不修改数据的语句,比如 SELECT 或 SHOW 等等。如果要记录所有的语句,可以使用 [[MySQL General Query Log]]
清理 bin log
不要直接在操作系统删除 bin.log 文件,让 MySQL 自己处理这些文件。
清理 binlogs 的命令是:
PURGE BINARY LOGS TO 'mysql-bin.000223';
这一行命令会清理 mysql-bin.000223 之前的 binary logs.
PURGE BINARY LOGS BEFORE 'datetimestamp';
PURGE BINARY LOGS BEFORE DATE(NOW() - INTERVAL 3 DAY) + INTERVAL 0 SECOND;
这一行会清理 3 天前的 binary logs。
设置自动清理
如果只想要保留 3 天的 binary log ,那么可以修改配置文件 /etc/my.cnf:
[mysqld]
expire_logs_days=3
或者直接使用命令:
mysql> SET GLOBAL expire_logs_days=3;
Extend
- [[MySQL set the binary log format]]
reference
离线备份小鹅通反派影评以及节目列表
今天花了一点时间把小鹅通上的《反派影评》离线备份下来了,一直害怕哪天又突然没有了,反派影评几乎伴随着我渡过过去这几年的影视世界。早在更早之前就在《观影风向标》知道了波米,但是 6 年前因为这种原因节目停更了,随后波米就推出了《反派影评》之后几乎是每一期都会听,甚至有些节目会听上两遍以上。
但是疫情开始的着两年里,波米更新节目的频率越来越低,一方面也可能是能聊的电影也越来越少了,另外又刚在《随机波动》了解到波米因为眼睛才停更的,这里祝福一下波米早日恢复健康。作为一个影评人眼睛还是非常重要的。
离线备份小鹅通上的反派影评一直在我的待办事项上,今天终于有时间处理一下了。
Python 代码如下,注意将其中的 YOUR_COOKIE 替换成自己的 Cookie。
在浏览器访问 反派影评 的小鹅通主页,或者登录之后在我的中点击已购找到专辑。然后执行如下代码就可以下载专辑中的音频内容。
鉴于效愚和波米担心,这里将备份脚本删去了,反派影评的所有内容作者都有保存,即使哪一天平台倒闭了相信反派也会找到一个适合的地方分享这些音频。另外在和效愚的沟通中也发现了版权保护存在的问题,如果音频能够离线备份,那么就一定会造成购买者分享的问题。数字时代,分享几乎是无成本,但对于内容生产者而言就是损失。虽然我本人坚定的认为用户购买的数字内容,不管是音频,电子书,还是电影本就应该将其电子版所有权归属于购买者,购买者没有分发的权力,但购买者一定得掌握该数字资产的本体,不管以后平台倒闭,抑或是平台下架,都不应该影响用户的收听,收看。当我们在互联网还未诞生的年代,难道购买了一本书,作者就有禁止我把书借给朋友阅读的权力吗?显然任何人都是没有的。但是当我们进入数字时代之后,因为分享来的太过于容易,所以产生了盗版,虽然在目前的互联网上还没有一个很好的解决办法,但拭目以待吧,期待未来的互联网是否能给出一个答案。
因为我并没有把所有的专辑都购买,所以只把我有的内容备份下来了。
2022 年 11 月更新
这两天看到反派影评又重新更新了,但是小鹅通的店铺却突然被关闭了。很多朋友想要一份日常节目的备份,我更新到如下的地址,付费节目因为涉及版权问题,我就不分享了。
如果有朋友发现有缺失,或者想要一起讨论,欢迎加入 Telegram 群组。
下面是反派影评所有的节目列表。
.
├── 2020年日常节目(无需单独购买)
│ ├── ER284-评《急先锋》(4分,胶片).mp3
│ ├── ER285-评《我和我的家乡》(5.3分,洞姐&秦婉&阳磊&阿苏&波米).mp3
│ ├── ER286-评《一点就到家》(7.5分,海老鼠).mp3
│ ├── ER287-评《喜宝》(1.5分).mp3
│ ├── ER289-评《气球》(7分,海老鼠).mp3
│ ├── ER290-评《疯狂原始人2》(5.5分,阿苏).mp3
│ ├── ER291-评《棒!少年》(6分).mp3
│ ├── MA098-评“2020奥斯卡纪录长片单元”(陈玲珍_陆庆屹).mp3
│ ├── MA112:云电影节体验&金狮新片观感(思源_波米).mp3
│ ├── MA113-贾樟柯宣称退出平遥影展事件(何小沁_秦婉_波米).mp3
│ ├── MA115-韩国名导金基德去世专题(范小青_小猱_波米).mp3
│ ├── MA116-华纳拍网大&迪士尼拍网剧(波米).mp3
│ ├── NO.118-评《死灵魂》(7.5分,刘三解_汤博_波米).mp3
│ ├── NO.201-评《姜子牙》(6分,阳磊_鲁韵子_波米).mp3
│ ├── NO.202-评《芝加哥七君子审判》(约7.2分,杨超_雅琴_波米).mp3
│ ├── NO.203-评《金都》(约7.3分,清心_胶片).mp3
│ ├── NO.204-评《一秒钟》(约6.2分,萝贝贝_雷普利_波米).mp3
│ ├── NO.205-评《曼克》(约7.3分,田野_雷普利_波米).mp3
│ └── NO.206-评《神奇女侠1984》(约5.2分,鲁韵子_荡科长_海老鼠).mp3
├── 2021年日常节目(无需单独购买)
│ ├── ER292-评《送你一朵小红花》(5分).mp3
│ ├── ER293-评《唐人街探案3》(洞姐).mp3
│ ├── ER294-评《人潮汹涌》(海老鼠).mp3
│ ├── ER296-评《侍神令》(钱德勒).mp3
│ ├── ER297-评《刺杀小说家》(阿苏).mp3
│ ├── ER300-评《你好,李焕英》(弦子).mp3
│ ├── ER301-评《我的姐姐》(5分).mp3
│ ├── ER302-评《你的婚礼》(洞姐,5分).mp3
│ ├── ER304-评《白蛇传·情》(6.5分).mp3
│ ├── ER305-评《寂静之地2》(7分).mp3
│ ├── ER306-评《黑白魔女库伊拉》(阿苏,6.5分).mp3
│ ├── ER307-评《怒火·重案》(7分).mp3
│ ├── ER308-评《白蛇2:青蛇劫起》(6.5分).mp3
│ ├── ER309-评《盛夏未来》(6分).mp3
│ ├── ER310-评《硬汉枪神》(法兰西胶片,5.5分).mp3
│ ├── ER311-评《失控玩家》(微软晓晓,6分).mp3
│ ├── ER312-评《致命感应》(段练&波米,约5.8分).mp3
│ ├── ER313-评《007:无暇赴死》(5分).mp3
│ ├── ER314-评《扬名立万》(6分).mp3
│ ├── ER315-评《尚气》(5.5分).mp3
│ ├── MA117-《晴雅集》内地院线被禁映(波米).mp3
│ ├── MA123:评“2021年第93届奥斯卡颁奖礼”(洞姐_雷普利_波米).mp3
│ ├── MA124:评“2022年金球奖停办风波”.mp3
│ ├── MA127(下):云戛纳体验&影节盗版危机(胤祥_秦婉_波米).mp3
│ ├── MA129:豆瓣电影“一星运动”风波.mp3
│ ├── MA130:2021年第11届北京电影节前瞻(胤祥_秦婉_波米).mp3
│ ├── MA131:《长津湖》控制负面口碑事件.mp3
│ ├── NO.207-评《心灵奇旅》(6分,张扬_阿苏).mp3
│ ├── NO.208-评《拆弹专家2》(约7.3分,法兰西胶片_波米).mp3
│ ├── NO.209-评《亲爱的同志》(7.5分,杨超_刘三解_波米).mp3
│ ├── NO.210-评《扎克·施奈德版正义联盟》(约6.3分,鲁韵子_胶片_波米).mp3
│ ├── NO.211之《米纳里》(7分,荡科长_思源_波米).mp3
│ ├── NO.211之《金属之声》(约7.2分,荡科长_思源_波米).mp3
│ ├── NO.212-评《前程似锦的女孩》(6.5分,弦子_一舒).mp3
│ ├── NO.213-评《无依之地》(约6.7分,靳锦_隐形_波米).mp3
│ ├── NO.214-评《困在时间里的父亲》(约7.3分,靳锦_波米).mp3
│ ├── NO.215-评《黑寡妇》(约4.8分,法兰西胶片_海老鼠).mp3
│ ├── NO.216-评《X特遣队:全员集结》(约6.3分,鲁韵子_波米).mp3
│ ├── NO.217-评《安妮特》(约6.3分,顿河_披萨_波米).mp3
│ ├── NO.218-评《长津湖》(约5.3分,隐形_波米).mp3
│ ├── NO.219-评《沙丘》(约6.8分,雷普利_波米).mp3
│ ├── NO.220-评《兰心大剧院》(约6.7分,刘三解_靳锦_波米).mp3
│ ├── NO.221-评《梅艳芳》(5.5分,萝贝贝_阿苏_波米).mp3
│ ├── NO.222-评《钛》(约7.3分,弦子_胤祥_波米).mp3
│ └── NO.223-评《最后的决斗》(约6.7分,鲁韵子_海老鼠_波米).mp3
├── 江湖不会忘记
│ └── 《同呼吸》(约8.3分-反派最高分,弦子_胤祥_波米).mp3
├── 长节目全集(2016-2021)
│ ├── 023评《釜山行》(5.8分):神作?年度最大笑话!.mp3
│ ├── 034《你的名字》(6.5分):一剂治愈“日本地震”灾后创伤的良药.mp3
│ ├── 077《出租车司机》(韩版,7分):为了忘却的记念.mp3
│ ├── 111《三和人才市场》(7分):躺在起跑线的人.mp3
│ ├── NO.200-评《夺冠》(约5.8分,靳锦_波米).mp3
│ ├── NO.211之《犹大与黑弥赛亚》(约5.8分,荡科长_思源_波米).mp3
│ ├── NO.218-评《长津湖》(约5.3分,隐形_波米).mp3
│ ├── NO.219-评《沙丘》(约6.8分,雷普利_波米).mp3
│ ├── NO.220-评《兰心大剧院》(约6.7分,刘三解_靳锦_波米).mp3
│ ├── NO.221-评《梅艳芳》(5.5分,萝贝贝_阿苏_波米).mp3
│ ├── NO.222-评《钛》(约7.3分,弦子_胤祥_波米).mp3
│ ├── NO.223-评《最后的决斗》(约6.7分,鲁韵子_海老鼠_波米).mp3
│ ├── NO.224-评《黑客帝国4:矩阵重启》(约5.3分,田野_麦教授_波米).mp3
│ └── NO.225-评《国王理查德》(约5.8分,胡力涛_顿河).mp3
├── 长节目列表(2016-2021)
│ ├── 175-评《少年的你》(萝贝贝_熊阿姨_波米).mp3
│ ├── 176-评《天气之子》(张扬_法兰西胶片_波米).mp3
│ ├── 177-评《决战中途岛》(刘三解_波米).mp3
│ ├── 178上半场:评《小丑》(7.5分,鲁韵子_杨超_波米).mp3
│ ├── 178下半场:“小丑”形象及相关电影回顾.mp3
│ ├── 179上半场-评《别告诉她》(熊阿姨_一舒_波米).mp3
│ ├── 179下半场:“华裔女性三杰”风格概览.mp3
│ ├── 180-下半场:马丁·斯科塞斯黑帮片回顾.mp3
│ ├── 180-上半场:评《爱尔兰人》(荡科长_雷普利_波米).mp3
│ ├── 181下半场:刁亦男前作全回顾.mp3
│ ├── 181上半场:评《南方车站的聚会》(田野_隐形_波米).mp3
│ ├── 182-下半场:昆汀·塔伦蒂诺前作全回顾.mp3
│ ├── 182-上半场:评《好莱坞往事》(靳锦_法兰西胶片_波米).mp3
│ ├── 183-评《婚姻故事》(蒋方舟_萝贝贝_波米).mp3
│ ├── 184-评《灯塔》(K先生_雷普利_波米).mp3
│ ├── 185-评《金智英》(洞姐_熊阿姨_顿河).mp3
│ ├── 186-评《燃烧女子的肖像》(陈丹青_杨超_波米).mp3
│ ├── 187-评《阳光普照》及钟孟宏前作全回顾(雷普利_顿河_波米).mp3
│ ├── 188-评《乔乔的异想世界》(隐形_波米).mp3
│ ├── 189-评《原钻》(田野_雷普利_波米).mp3
│ ├── 190-评《极速车王》(石一瑛_田野_波米).mp3
│ ├── 191-评《我控诉》(雅琴_吴琦_波米).mp3
│ ├── 192-评《悲惨世界》(振宇_鲁韵子_波米).mp3
│ ├── 193-评《爆炸新闻》(弦子_一舒_波米).mp3
│ ├── 195-评《绅士们》(K先生_法兰西胶片_田野).mp3
│ ├── 196-评《誓血五人组》(海老鼠_吴琦_波米).mp3
│ ├── 197-评《灰猎犬号》(刘三解_波米).mp3
│ ├── 198-评《1917》(鲁韵子_法兰西胶片_波米).mp3
│ ├── 198-评《信条》(田野_法兰西胶片_波米).mp3
│ ├── 199-评《花木兰》(张扬_阿苏_波米).mp3
│ ├── NO.201-评《姜子牙》(6分,阳磊_鲁韵子_波米).mp3
│ ├── NO.202-评《芝加哥七君子审判》(约7.2分,杨超_雅琴_波米).mp3
│ ├── NO.203-评《金都》(约7.3分,清心_胶片).mp3
│ ├── NO.204-评《一秒钟》(约6.2分,萝贝贝_雷普利_波米).mp3
│ ├── NO.205-评《曼克》(约7.3分,田野_雷普利_波米).mp3
│ ├── NO.206-评《神奇女侠1984》(约5.2分,鲁韵子_荡科长_海老鼠).mp3
│ ├── NO.207-评《心灵奇旅》(6分,张扬_阿苏).mp3
│ ├── NO.208-评《拆弹专家2》(约7.3分,法兰西胶片_波米).mp3
│ ├── NO.209-评《亲爱的同志》(7.5分,杨超_刘三解_波米).mp3
│ ├── NO.210-评《扎克·施奈德版正义联盟》(约6.3分,鲁韵子_胶片_波米).mp3
│ ├── NO.211之《米纳里》(7分,荡科长_思源_波米).mp3
│ ├── NO.211之《金属之声》(约7.2分,荡科长_思源_波米).mp3
│ ├── NO.211之《犹大与黑弥赛亚》(约5.8分,荡科长_思源_波米).mp3
│ ├── NO.212-评《前程似锦的女孩》(6.5分,弦子_一舒).mp3
│ ├── NO.213-评《无依之地》(约6.7分,靳锦_隐形_波米).mp3
│ ├── NO.214-评《困在时间里的父亲》(约7.3分,靳锦_波米).mp3
│ ├── NO.215-评《黑寡妇》(约4.8分,法兰西胶片_海老鼠).mp3
│ ├── NO.216-评《X特遣队:全员集结》(约6.3分,鲁韵子_波米).mp3
│ └── NO.217-评《安妮特》(约6.3分,顿河_披萨_波米).mp3
├── 长节目全集(2016-2022)
│ ├── NO.226-评《蜘蛛侠3:英雄无归》(7分,鲁韵子_波米).mp3
│ ├── NO.227-评《新蝙蝠侠》(约6.7分,阿苏_鲁韵子_波米).mp3
│ └── NO.228-评《不要抬头》(约7.3分,杨超_波米).mp3
├── 长节目列表(2016至今)
│ ├── 001《垫底辣妹》(6.8分)世界上最大谎言是春药式励志.mp3
│ ├── 002《踏血寻梅》(7.3分 NC-17级):凶手是最大的受害者.mp3
│ ├── 003《牯岭街少年杀人事件》CC修复版专题:一个明朗的夏日.mp3
│ ├── 004《百鸟朝凤》(7分 R级):人生航标今何在 百鸟朝凤一曲终.mp3
│ ├── 005《美国队长3》(7.2分 PG-13):复仇者击败复仇者联盟.mp3
│ ├── 006《希特勒回来了》(6.8分 PG-13级):欧洲的右转·意志的胜利.mp3
│ ├── 007"第69届戛纳电影节专题".mp3
│ ├── 008《X战警:天启》(5.5分 PG-13):特效堆砌·狗尾续貂.mp3
│ ├── 009《魔兽》(5.9分):你们的青春·我们的槽点.mp3
│ ├── 010《海底总动员2:多莉去哪儿》(5分):皮克斯从海底捞出的一碗冷饭.mp3
│ ├── 011《三人行》(7分):一个字头·二十周年·三人拍案.mp3
│ ├── 012《哭声》(7分):子不语怪力乱神.mp3
│ ├── 013《寒战2》(6.5分):宫斗也要按照基本法嘛!.mp3
│ ├── 014《路边野餐》(8.3分):她说她要寻找小贝壳.mp3
│ ├── 015《天空之眼》(8.0分):当肯尼亚的泪水决堤于伦敦的会议室.mp3
│ ├── 016《树大招风》.mp3
│ ├── 017《遇见你之前》(6.2分):我生于忧患,你死于安乐.mp3
│ ├── 018《小姐》(6.8分):一只章鱼哥·两双剪刀脚.mp3
│ ├── 019《完美陌生人》(6.8分):当马蓉宋喆灵魂附体.mp3
│ ├── 020《谍影重重5》(7.5分):再次踏上无尽之路,去往生疏未知的远方.mp3
│ ├── 021《星际迷航:超越星辰》(7分):生生不息·繁荣昌盛.mp3
│ ├── 022《长江图》(8分):落木萧萧下·海潮至此回.mp3
│ ├── 024《招魂2》(6.5分):善恶终有报·天道好轮回.mp3
│ ├── 025《湄公河行动》(5.8分):和《毒战》差了一百个《警察故事3》.mp3
│ ├── 026《咖啡公社》(7.3分):得不到的永远在骚动.mp3
│ ├── 027《黑处有什么》(6.8分):马车同学,你危险啦!.mp3
│ ├── 028《她》(7.5分):总有一群低等生物需要被处决.mp3
│ ├── 029《驴得水》(5.8分):批判已被认定的批判.mp3
│ ├── 030《奇异博士》(6.3分):来,给范厨师包上.mp3
│ ├── 031《屏住呼吸》(6.3分):东西街南北走·出门看见人咬狗.mp3
│ ├── 032《比利·林恩的中场战事》(6.2分):父辈的旗帜·血染的风采.mp3
│ ├── 033《我不是潘金莲》(7分):朗朗乾坤·遍地贱人.mp3
│ ├── 035《血战钢锯岭》(7.5分):我是道路·真理·生命.mp3
│ ├── 036《萨利机长》(7分):从麦迪逊桥到哈德逊河.mp3
│ ├── 037《罗曼蒂克消亡史》(7.5分):孤岛生死场.mp3
│ ├── 038《夜行动物》(7分):只是汤姆·福特的另一款化妆品.mp3
│ ├── 039《星战外传:侠盗一号》(完整版,7.5分).mp3
│ ├── 040《魔弦传说》(4分):别再扯什么匠人精神了.mp3
│ ├── 041《降临》(6.8分):两个七筒一桌麻将.mp3
│ ├── 042《比海更深》(7.7分):然而台风.mp3
│ ├── 043《月光男孩》(6.5分):蓝色是最不温暖的颜色.mp3
│ ├── 044《爱乐之城》(7.3分):想唱就唱,要唱的响亮.mp3
│ ├── 045《海边的曼彻斯特》(7.7分):对不起,没有和解.mp3
│ ├── 046《隐藏人物》(6.8分):弗吉尼亚在燃烧.mp3
│ ├── 047《乐高蝙蝠侠大电影》(6.8分):小丑别开枪是我.mp3
│ ├── 048下半场:法律纪实题材漫谈.mp3
│ ├── 048上半场《辛普森:美国制造》(7.3分):放不下的黑权,带不上的黑手套.mp3
│ ├── 049《八月》(6.5分):八月流火·昙花一现.mp3
│ ├── 050《金刚:骷髅岛》(6.5分):景甜和她的怪兽宇宙.mp3
│ ├── 051《推销员》(7.3分).mp3
│ ├── 052《攻壳机动队真人版》(4分):生死去来·棚头傀儡.mp3
│ ├── 053《速度与激情8》(5分):票房有多高片子就有多烂.mp3
│ ├── 054《沉默》(7.5分):受难的三种境界.mp3
│ ├── 055《爱国者之日》(7分):关于”热点事件“的改编边界.mp3
│ ├── 056《银河护卫队2》(6分):好个屁!.mp3
│ ├── 057《分裂》(6.7分):请注意,本期仅有一位主播!.mp3
│ ├── 058《杰出公民》(7.3分):伪君子大战真小人.mp3
│ ├── 059《金刚狼3》(7分):最后的大兵.mp3
│ ├── 060“赵家少年与黄家少年”.mp3
│ ├── 061《猜火车2》(7分):乡音无改鬓毛衰.mp3
│ ├── 062《疾速追杀2》(6.8分):社会我威哥·人狠话不多.mp3
│ ├── 063《变形金刚5》(4.3分):电影已死.mp3
│ ├── 064《明月几时有》(6.5分):客途秋恨·归去来兮.mp3
│ ├── 065下半场:印度电影概况.mp3
│ ├── 065上半场《摔跤吧!爸爸》(7分).mp3
│ ├── 066《迷失Z城》(7.8分):“夺宝奇兵”的另一种诠释.mp3
│ ├── 067《绣春刀2》.mp3
│ ├── 068《战狼2》(5.8分):特效和主题皆五毛.mp3
│ ├── 069《玉子》(7.2分):好大一口猪.mp3
│ ├── 070《在这世界的角落》(7分):大江大海1945.mp3
│ ├── 071上半场《异形:契约》(6.8分):众神进入英灵殿.mp3
│ ├── 071下半场:《异形》系列前作回顾.mp3
│ ├── 072《极盗车神》(7.5分).mp3
│ ├── 073《敦刻尔克》(7分):一次概念先行的实景演出.mp3
│ ├── 074《蜘蛛侠:英雄归来》(6.8分):他还只是个孩子啊!.mp3
│ ├── 075《猩球崛起3:终极之战》(5.5分):影院无佳片·猴子称大王.mp3
│ ├── 076《皮绳上的魂》(6.8分):在冈仁波齐的山脚下.mp3
│ ├── 078《生存家族》(6.8分):消失的万家灯火.mp3
│ ├── 079《天才枪手》(6.8分):愿你打完小抄时·有侠客收剑入鞘的骄傲.mp3
│ ├── 080《猎凶风河谷》(7.2分):恶土之上·踏雪寻仇.mp3
│ ├── 081《银翼杀手2049》(7.5分):即使变成甲壳虫卡夫卡还是进不去城堡.mp3
│ ├── 082《相爱相亲》(6.8分):我指着大海的方向.mp3
│ ├── 083《一个柬埔寨女儿的回忆录》(6.2分):朱莉妈妈的比心大行动.mp3
│ ├── 084《嘉年华》(7.8分):在梦露的裙摆下.mp3
│ ├── 085《王牌特工2》(6分)即兴尬聊.mp3
│ ├── 086《至暗时刻》(7.2分):毕竟他贡献了史上最俗的拍照手势.mp3
│ ├── 087《底特律》(6.8分):这是最后的斗争.mp3
│ ├── 088《芳华》(6分):一颗流弹打中我胸膛.mp3
│ ├── 089《母亲!》(6.5分):这是部带有宗教色彩的环保电影?.mp3
│ ├── 090《小丑回魂》(6.8分).mp3
│ ├── 091《不成问题的问题》(6.8分):一次属于重庆的失败实验.mp3
│ ├── 092《请以你的名字呼唤我》(7.2分):于是大喊“安红俺想你!”.mp3
│ ├── 093《灾难艺术家》(6分):一部烂片的诞生.mp3
│ ├── 094《性别之战》(6.8分):这真的是一期网球节目.mp3
│ ├── 095《水形物语》(6.5分):给我一杯忘形水.mp3
│ ├── 096《我,花样女王》(7.5分):给你一个三周半大反转!.mp3
│ ├── 097《华盛顿邮报》(6.5分):搞个大新闻.mp3
│ ├── 098《三块广告牌》(7.5分):仇恨呼叫转移.mp3
│ ├── 099《大佛普拉斯》(8.2分):一张票·一世情.mp3
│ ├── 100《湮灭》(6.7分):到灯塔去.mp3
│ ├── 101《1987:黎明到来的那一天》:不要太难过·就像这世界.mp3
│ ├── 102《头号玩家》:游戏的胜利.mp3
│ ├── 103《暴裂无声》(5.5分):羔羊为何沉默?.mp3
│ ├── 104《魅影缝匠》(7.2分):小蝌蚪找妈妈.mp3
│ ├── 105《犬之岛》(6.7分):民主为何被流放?.mp3
│ ├── 106《血观音》(6.5分):一条青花瓷的大腿.mp3
│ ├── 107《羞辱》(7.3分):记住历史还是记住仇恨?.mp3
│ ├── 108《复联3》(6.2分):计生委书记大战妇联主任.mp3
│ ├── 109《寂静之地》(5.5分):沉静如海.mp3
│ ├── 110《游侠索罗》(5.3分).mp3
│ ├── 112《燃烧》.mp3
│ ├── 113《侏罗纪世界2》(5.8分):恐龙电影和恐龙一样过时了.mp3
│ ├── 114《超人总动员2》.mp3
│ ├── 115《动物世界》.mp3
│ ├── 116《我不是药神》:伪现实·真印囧.mp3
│ ├── 117《邪不压正》.mp3
│ ├── 119下半场:徐克代表作回顾.mp3
│ ├── 119上半场《狄仁杰之四大天王》.mp3
│ ├── 120《小偷家族》(7.5分).mp3
│ ├── 121《死侍2》(5.3分):人至贱则无敌.mp3
│ ├── 122《快把我哥带走》(5.8分).mp3
│ ├── 123《遗传厄运》(7.5分):傀儡的主人.mp3
│ ├── 124上半场《碟中谍6:全面瓦解》(7分):点燃引线!.mp3
│ ├── 124下半场:《碟中谍》前作回顾.mp3
│ ├── 125《美国动物》(7分):没有比追求不凡更平凡的追求了.mp3
│ ├── 126《曼蒂》(6分):凯奇翻了一个前滚翻.mp3
│ ├── 127上半场:《江湖儿女》.mp3
│ ├── 127下半场:贾樟柯前作全回顾.mp3
│ ├── 128上半场:《影》.mp3
│ ├── 128下半场:张艺谋代表作回顾.mp3
│ ├── 129《找到你》(5.8分):民粹时代的“现实主义”.mp3
│ ├── 130《幸福的拉扎罗》(7.5分):神说,要有光.mp3
│ ├── 131上半场:《7月22日》.mp3
│ ├── 131下半场:保罗·格林格拉斯代表作回顾.mp3
│ ├── 132上半场:《网络迷踪》.mp3
│ ├── 132下半场:桌面电影总结与展望.mp3
│ ├── 133《沉默的教室》.mp3
│ ├── 134上半场:《摘金奇缘》.mp3
│ ├── 134下半场:华裔三杰风格简述.mp3
│ ├── 135《大象席地而坐》.mp3
│ ├── 136《冷战》.mp3
│ ├── 137上半场:《巴斯特的歌谣》.mp3
│ ├── 137下半场:科恩兄弟代表作回顾.mp3
│ ├── 138《狗十三》(7.2分):赛先生之死.mp3
│ ├── 139下半场:阿方索·卡隆前作全回顾.mp3
│ ├── 139上半场:《罗马》.mp3
│ ├── 140《蜘蛛侠:平行宇宙》.mp3
│ ├── 141《地球最后的夜晚》(7分):长夜漫漫路迢迢.mp3
│ ├── 142《登月第一人》.mp3
│ ├── 143《野梨树》及锡兰前作回顾.mp3
│ ├── 144《一个明星的诞生》.mp3
│ ├── 145下半场:音乐人传记片漫谈.mp3
│ ├── 145上半场:《波西米亚狂想曲》.mp3
│ ├── 146《流浪地球》.mp3
│ ├── 147下半场:斯派克·李代表作回顾.mp3
│ ├── 147上半场:《黑色党徒》.mp3
│ ├── 148《宠儿》及导演兰斯莫斯代表作回顾.mp3
│ ├── 149《阿丽塔:战斗天使》:逃出恐怖谷.mp3
│ ├── 150《绿皮书》(6.5分):大型开封菜宣传片.mp3
│ ├── 151下半场:拉斯·冯·提尔代表作回顾.mp3
│ ├── 151上半场:《此房是我造》.mp3
│ ├── 152《谁先爱上他的》.mp3
│ ├── 153《地久天长》.mp3
│ ├── 154《开战》及史蒂芬·布塞前作全回顾.mp3
│ ├── 155《骡子》.mp3
│ ├── 155下半场:伊斯特伍德导演代表作回顾.mp3
│ ├── 156《无主之作》:我不在那儿.mp3
│ ├── 157《复仇者联盟4:终局之战》:你和银幕对暗号.mp3
│ ├── 158《风中有朵雨做的云》及娄烨前作全回顾.mp3
│ ├── 159《玻璃先生》:打响反超英电影第一枪!.mp3
│ ├── 160《柔情史》:世上只有妈妈好?.mp3
│ ├── 161《我们》:手拉手·心连心.mp3
│ ├── 162《哥斯拉2:怪兽之王》:没有剧情何来剧透?.mp3
│ ├── 163《何以为家》:所以穷人没有生育期喽?.mp3
│ ├── 164《狮子王》:精致的临摹.mp3
│ ├── 165《银河补习班》.mp3
│ ├── 166《哪吒之魔童降世》.mp3
│ ├── 167上半场:《痛苦与荣耀》.mp3
│ ├── 167下半场:阿莫多瓦代表作回顾.mp3
│ ├── 168《寄生虫》:我命由天不由我.mp3
│ ├── 169《感谢上帝》:以恩宠之名.mp3
│ ├── 170《美国工厂》:世界一片透明.mp3
│ ├── 171《同义词》.mp3
│ ├── 172鸡肋三连之《攀登者》.mp3
│ ├── 172鸡肋三连之《中国机长》.mp3
│ ├── 172鸡肋三连之《我和我的祖国》.mp3
│ ├── 173《仲夏夜惊魂》.mp3
│ ├── 174下半场:李安前作全回顾.mp3
│ ├── 175上半场:《双子杀手》.mp3
│ └── NO.118-评《死灵魂》(7.5分,刘三解_汤博_波米).mp3
├── “江湖不会忘记”
│ ├── 《迷航》(约6.8分,振宇_段炼_波米).mp3
│ └── 《登楼叹》(约6.2分,刘三解_熊阿姨_波米).mp3
├── 《黑客帝国》专题
│ ├── NO.224-评《黑客帝国4:矩阵重启》(约5.3分,田野_麦教授_波米).mp3
│ ├── 沃卓斯基其它前作回顾.mp3
│ ├── 彩蛋:《黑客帝国》动作场面回顾(胶片_波米).mp3
│ ├── “红色药丸版”黑客回顾(上):科幻?杰克苏B级动作片!(胶片&波米).mp3
│ ├── “蓝色药丸版”黑客回顾:从洞穴寓言到拟物与影像(杨超_波米).mp3
│ └── “红色药丸版”黑客回顾(下):千年虫和杀毒软件过时了(胶片_波米).mp3
├── 反派马后炮全集(2016-2021)
│ ├── MA000:伊朗名导阿巴斯·基亚罗斯塔米去世(嘉宾:海老鼠、隐形).mp3
│ ├── MA001:赵薇导演作品《没有别的爱》遭抵制(嘉宾:海老鼠、隐形).mp3
│ ├── MA002:2016年第10届FIRST青年影展(上)(嘉宾:段炼、隐形).mp3
│ ├── MA003:2016年第10届FIRST青年影展(下)(嘉宾:段炼、隐形).mp3
│ ├── MA004:导演蔡明亮频繁举报盗版网站(嘉宾:“时代映画社”社长、荡科长).mp3
│ ├── MA005 从《谍影重重5》看“特供3D”为何屡骂不止(嘉宾:海老鼠、隐形).mp3
│ ├── MA006:谈第53届台湾电影金马奖提名名单(嘉宾:玉年、隐形).mp3
│ ├── MA007:2016年11月进口片批量上映为哪般(嘉宾:顿河、隐形).mp3
│ ├── MA008:因“叶宁跳槽”致冯小刚炮轰万达(嘉宾:顿河、海老鼠).mp3
│ ├── MA009:2016年内地院线“引进片十佳”节目(嘉宾:田野、法兰西胶片).mp3
│ ├── MA010:官媒炮轰豆瓣等评分网站(田野_蜉蝣_波米).mp3
│ ├── MA011:2016年内地院线“华语片十佳”节目(雷普利_隐形_波米).mp3
│ ├── MA012:2017年引进片展望(嘉宾:田野、法兰西胶片).mp3
│ ├── MA013 2017年第74届美国金球奖颁奖礼(嘉宾:荡科长、海老鼠).mp3
│ ├── MA014 2017年华语片展望(嘉宾:雷普利、隐形).mp3
│ ├── MA015:2016年“院线外十佳片”节目(蜉蝣_海老鼠_波米).mp3
│ ├── MA016 2017年第89届奥斯卡提名名单(嘉宾:荡科长、玉年).mp3
│ ├── MA017 2017年第36届香港金像奖提名名单(嘉宾:秦婉、田野).mp3
│ ├── MA018 2017年第89届奥斯卡女演员提名(嘉宾:秦婉、顿河).mp3
│ ├── MA019 2017年第89届奥斯卡男演员提名(嘉宾:小猱、柏小莲).mp3
│ ├── MA020 2017年第89届奥斯卡外语与纪录长片提名(嘉宾:隐形、海老鼠).mp3
│ ├── MA021 2017年第89届奥斯卡颁奖礼综述(嘉宾:荡科长、隐形).mp3
│ ├── MA022 引进片删减问题为何层出不穷(嘉宾:法兰西胶片、隐形).mp3
│ ├── MA023 2017年第7届北京国际电影节前瞻(嘉宾:蜉蝣、隐形).mp3
│ ├── MA024 《我爱我家》开拍大电影(嘉宾:雷普利、隐形).mp3
│ ├── MA025 2017年第36届香港电影金像奖颁奖典礼(嘉宾:秦婉、法兰西胶片).mp3
│ ├── MA026 《大话西游》内地单方面重映引争议(嘉宾:钱德勒、法兰西胶片).mp3
│ ├── MA027 徐浩峰放弃《刀背藏身》导演署名(嘉宾:海老鼠、隐形).mp3
│ ├── MA028 《沉默的羔羊》导演乔纳森·戴米去世(嘉宾:海老鼠、隐形).mp3
│ ├── MA029 2017年第70届戛纳国际电影节(嘉宾:秦婉、柳莺).mp3
│ ├── MA030 2017年第20届“上海国际电影节”前瞻(嘉宾:秦婉、玉年).mp3
│ ├── MA031 2017年上半年国产片小结(嘉宾:法兰西胶片、隐形).mp3
│ ├── MA032 2017年上半年进口片小结(嘉宾:法兰西胶片、隐形).mp3
│ ├── MA033 2017年第11届FIRST青年影展(嘉宾:法兰西胶片、钱德勒).mp3
│ ├── MA034 《三生三世》粉丝大规模“锁场”事件(嘉宾:隐形、荡科长).mp3
│ ├── MA035 《战狼2》票房破50亿(嘉宾:隐形、秦婉).mp3
│ ├── MA036 2017年第74届威尼斯国际电影节(嘉宾:秦婉、海老鼠).mp3
│ ├── MA037 《芳华》删减争议与撤出2017年“十一档”风波(嘉宾:隐形、胶片).mp3
│ ├── MA038 凯文·史派西因性侵嫌疑被删光戏份(嘉宾:隐形、胶片).mp3
│ ├── MA039 2017年第54届台湾电影金马奖颁奖典礼(嘉宾:秦婉、翠萍).mp3
│ ├── MA040 迪士尼收购21世纪福斯(嘉宾:荡科长、法兰西胶片).mp3
│ ├── MA041:2017年引进片十佳(嘉宾:荡科长、雷普利).mp3
│ ├── MA042:2017年华语片十佳(嘉宾:秦婉、法兰西胶片).mp3
│ ├── MA043:2018年引进片展望(嘉宾:荡科长、雷普利).mp3
│ ├── MA044:2018年华语片展望(嘉宾:秦婉、法兰西胶片).mp3
│ ├── MA045:第90届奥斯卡提名名单(嘉宾:耿先生、荡科长).mp3
│ ├── MA046上半场:2018奥斯卡女主提名点评(嘉宾:田野、小猱).mp3
│ ├── MA046下半场:2018奥斯卡女配提名点评(嘉宾:田野、小猱).mp3
│ ├── MA047:2018年第90届奥斯卡纪录长片提名点评(嘉宾:海老鼠、雷普利).mp3
│ ├── MA048:2018奥斯卡外语片提名点评(嘉宾:海老鼠、雷普利).mp3
│ ├── MA049上半场:2018年第90届奥斯卡男主角提名点评(嘉宾:柏小莲、秦婉).mp3
│ ├── MA049下半场:2018年第90届奥斯卡男配角提名点评(嘉宾:柏小莲、秦婉).mp3
│ ├── MA050:2018年第90届奥斯卡颁奖礼综述(嘉宾:法兰西胶片、荡科长).mp3
│ ├── MA051:中宣部接手监管内地电影业(嘉宾:杨超、隐形).mp3
│ ├── MA052:日本动画导演高畑勋去世(嘉宾:法兰西胶片、蜉蝣).mp3
│ ├── MA053:2017年第37届香港电影金像奖颁奖礼综述(嘉宾:雷普利、翠萍).mp3
│ ├── MA054:捷克名导米洛斯·福尔曼去世(嘉宾:田野、雷普利).mp3
│ ├── MA055:第8届北影节事故频发&漫威10周年庆典争议(嘉宾:耿先生、隐形).mp3
│ ├── MA056:《后来的我们》退票争议事件(嘉宾:水怪、潇潇).mp3
│ ├── MA057:崔永元频爆电影行业内幕(嘉宾:玉年、秦婉).mp3
│ ├── MA058:2018年第12届FIRST青年影展(嘉宾:雷普利、段炼).mp3
│ ├── MA060:《江湖儿女》冯小刚戏份遭删减(嘉宾:水怪、靳锦).mp3
│ ├── MA061 内地影院“线上票补”被逐步取消(嘉宾:徐元、隐形).mp3
│ ├── MA062 金庸&邹文怀&蓝洁瑛相继去世(嘉宾:鲁韵子、法兰西胶片).mp3
│ ├── MA063 “漫威之父”斯坦·李去世(嘉宾:鲁韵子、阳磊).mp3
│ ├── MA064 2018年第55届台湾电影金马奖颁奖典礼(嘉宾:秦婉、雷普利).mp3
│ ├── MA065 意大利名导贝托鲁奇去世(嘉宾:海老鼠、隐形).mp3
│ ├── MA066:香港名导林岭东去世(嘉宾:隐形;客串:鲁韵子、法兰西胶片).mp3
│ ├── MA067:2018年内地院线“引进片十佳”节目(嘉宾:靳锦、顿河).mp3
│ ├── MA068:《地球最后的夜晚》片方“错位营销”事件(嘉宾:隐形、靳锦).mp3
│ ├── MA069:2019年外语片展望(嘉宾:靳锦、顿河).mp3
│ ├── MA070:2018年内地院线“华语片十佳”节目(嘉宾:鲁韵子、张瑞).mp3
│ ├── MA071:2019年华语片展望(嘉宾:鲁韵子、张瑞).mp3
│ ├── MA072:2019年第91届奥斯卡提名名单(嘉宾:思源、蜉蝣).mp3
│ ├── MA073:2019年第91届奥斯卡男配角提名点评(嘉宾:顿河、陆姝).mp3
│ ├── MA074:2019年第91届奥斯卡女配角奖提名点评(嘉宾:李梦、秦婉).mp3
│ ├── MA075:2019年第91届奥斯卡影帝提名点评(嘉宾:顿河、陆姝).mp3
│ ├── MA076:2019年第91届奥斯卡影后提名点评(嘉宾:李梦、秦婉).mp3
│ ├── MA077:2019年第91届奥斯卡纪录片提名点评(嘉宾:熊阿姨、一舒).mp3
│ ├── MA078:2019年第91届奥斯卡颁奖礼综述(嘉宾:荡科长、靳锦).mp3
│ ├── MA079:法国名导阿涅斯·瓦尔达去世专题(嘉宾;杨超、雷普利).mp3
│ ├── MA080:原上影节开幕片《八佰》由于“技术原因”被撤下.mp3
│ ├── MA081:2019上半年中国内地影市漫谈(嘉宾:杨超、法兰西胶片).mp3
│ ├── MA082:《小美人鱼》等迪士尼真人改编电影争议频出(嘉宾:张扬、荡科长).mp3
│ ├── MA083:从此暂停大陆影片影人参加金马影展.mp3
│ ├── MA084:《黑客4》开拍&漫威索尼一度分手(嘉宾:杨超、法兰西胶片).mp3
│ ├── MA085上半场:2019年威尼斯电影节前方特别节目(思源_波米).mp3
│ ├── MA085下半场:2019年威尼斯电影节上半程漫谈(嘉宾:陀螺凡达可、何小沁).mp3
│ ├── MA086:2019年威尼斯电影节综述.mp3
│ ├── MA087:马丁·斯科塞斯炮轰漫威事件.mp3
│ ├── MA088:《好莱坞往事》因所谓“辱华”内地遭撤档(嘉宾:靳锦、何小沁).mp3
│ ├── MA089:2019年金马奖颁奖礼综述(嘉宾:麦若愚、翠萍).mp3
│ ├── MA090:2020年美国金球奖颁奖礼综述.mp3
│ ├── MA091:2019年内地院线“引进十佳”节目(嘉宾:蜉蝣、秦婉).mp3
│ ├── MA092:2020年第92届奥斯卡提名点评(嘉宾:靳锦、海老鼠).mp3
│ ├── MA093:2020年引进片展望(嘉宾:蜉蝣、秦婉).mp3
│ ├── MA094:2019年内地院线“华语十佳”节目(嘉宾:柏小莲、萝贝贝).mp3
│ ├── MA095:2020年华语展望(嘉宾:柏小莲、萝贝贝).mp3
│ ├── MA096:徐峥《囧妈》移动端首播争议(嘉宾:隐形、靳锦).mp3
│ ├── MA097:2020年第92届奥斯卡女演员提名点评(嘉宾:柏小莲、靳锦).mp3
│ ├── MA098:2020年奥斯卡纪录长片提名点评(嘉宾:陈玲珍、陆庆屹).mp3
│ ├── MA099:2020年奥斯卡男演员提名点评(嘉宾:杨超、钱德勒).mp3
│ ├── MA100:2020年奥斯卡颁奖礼综述(嘉宾:荡科长、阿苏).mp3
│ ├── MA101:波兰斯基的凯撒奖获奖风波.mp3
│ ├── MA102:2020年香港金像奖获奖名单简评(主播:鲁韵子).mp3
│ ├── MA103:2020年内地影院停工数月(嘉宾:杨超、法兰西胶片).mp3
│ ├── MA104:2020年戛纳电影节停办&线上公布片单(嘉宾:靳锦、秦婉).mp3
│ ├── MA105:内地影院是否复工陷争议.mp3
│ ├── MA106:华纳流媒体频道HBO一度下架《乱世佳人》.mp3
│ ├── MA107:意大利作曲家埃尼奥·莫里康内去世.mp3
│ ├── MA108:J·K罗琳及哈利·贝瑞言论风波(嘉宾:杨超、阿苏).mp3
│ ├── MA109:2020年西宁FIRST影展综述(嘉宾:法兰西胶片、荡科长、海老鼠).mp3
│ ├── MA110:英国名导艾伦·帕克去世(嘉宾:高旗、杨超).mp3
│ ├── MA111-评《八佰》被小粉红炮轰事件.mp3
│ ├── MA112:云电影节体验&金狮新片观感(思源_波米).mp3
│ ├── MA113-贾樟柯宣称退出平遥影展事件(何小沁_秦婉_波米).mp3
│ ├── MA114-大量发生③:杭州台湾影展&第57届金马颁奖礼.mp3
│ ├── MA114-大量发生②:《金刚川》过10亿.mp3
│ ├── MA114-大量发生①:英国演员肖恩·康纳利去世.mp3
│ ├── MA115-韩国名导金基德去世专题(范小青_小猱_波米).mp3
│ ├── MA116-华纳拍网大&迪士尼拍网剧(波米).mp3
│ ├── MA117-《晴雅集》内地院线被禁映(波米).mp3
│ ├── MA118-2020年“内地院线片五佳”特别节目(吴琦_徐元_波米).mp3
│ ├── MA119:人人影视字幕组被封.mp3
│ ├── MA120:评“2021年第93届奥斯卡提名”.mp3
│ ├── MA121:评“2021年第93届纪录长片提名”(麦教授_波米).mp3
│ ├── MA122:评“2021年第93届国际影片提名”(秦婉_波米).mp3
│ ├── MA123:评“2021年第93届奥斯卡颁奖礼”(洞姐_雷普利_波米).mp3
│ ├── MA124:评“2022年金球奖停办风波”.mp3
│ ├── MA125:评“互联网巨头VS传统电影业”(徐元_安洳誼_波米).mp3
│ ├── MA126:2021年上半年内地影市小结.mp3
│ ├── MA127(上):2021年戛纳概览&香港纪录片风波(胤祥_秦婉_波米).mp3
│ ├── MA127(下):云戛纳体验&影节盗版危机(胤祥_秦婉_波米).mp3
│ ├── MA128:评“2021年第15届FIRST青年电影展”(靳锦_胤祥_海老鼠).mp3
│ ├── MA129:豆瓣电影“一星运动”风波.mp3
│ ├── MA130:2021年第11届北京电影节前瞻(胤祥_秦婉_波米).mp3
│ ├── MA131:《长津湖》控制负面口碑事件.mp3
│ ├── MA131:《搏击会》内地版修改结局事件.mp3
│ ├── MA132:2022年第94届奥斯卡提名名单综述.mp3
│ ├── MA133:2022年第40届香港金像奖提名名单综述.mp3
│ ├── MA134:2022年柏林&《隐入尘烟》撤档.mp3
│ └── ma059:《银护》导演古恩因不当言论一度被迪士尼开除之风波(嘉宾:王自健、荡科长).mp3
├── 电影耳旁风全集(2016-2021)
│ ├── ER001:《大唐玄奘》.mp3
│ ├── ER007:《独立日2》.mp3
│ ├── ER013:《星际迷航13:超越星辰》.mp3
│ ├── ER029:《健忘村》.mp3
│ ├── ER030:《西游伏妖篇》.mp3
│ ├── ER031:《乘风破浪》.mp3
│ ├── ER032:《功夫瑜伽》.mp3
│ ├── ER033:《大闹天竺》.mp3
│ ├── ER034:《了不起的菲丽西》.mp3
│ ├── ER035:《极限特工3》.mp3
│ ├── ER036:《决战食神》.mp3
│ ├── ER037:《合约男女》.mp3
│ ├── ER038:《欢乐好声音》.mp3
│ ├── ER039:《刺客信条》.mp3
│ ├── ER041:《最终幻想15》.mp3
│ ├── ER043:《美女与野兽》.mp3
│ ├── ER045:《嫌疑人X的献身》(国版).mp3
│ ├── ER046:《非凡任务》.mp3
│ ├── ER047:《一念无明》.mp3
│ ├── ER048:《蓝精灵3》.mp3
│ ├── ER049:《盲·道》.mp3
│ ├── ER050:《记忆大师》.mp3
│ ├── ER051:《喜欢你》.mp3
│ ├── ER052:《春娇救志明》.mp3
│ ├── ER053:《拆弹·专家1》(客串:海老鼠).mp3
│ ├── ER054:《提着心吊着胆》.mp3
│ ├── ER056:《当怪物来敲门》.mp3
│ ├── ER057:麻烦家族.mp3
│ ├── ER058:《亚瑟王:斗兽争霸》.mp3
│ ├── ER059:《超凡战队》.mp3
│ ├── ER060:《毒。诫》.mp3
│ ├── ER061:《异星觉醒》.mp3
│ ├── ER062:《加勒比海盗5》.mp3
│ ├── ER063:荡寇风云.mp3
│ ├── ER064:《神奇女侠》(客串:隐形).mp3
│ ├── ER065:《哆啦A梦:大雄的南极冰冰凉大冒险》.mp3
│ ├── ER066:《29+1》.mp3
│ ├── ER067:我心雀跃.mp3
│ ├── ER068:新木乃伊.mp3
│ ├── ER069:《52赫兹,我爱你》.mp3
│ ├── ER070:冈仁波齐.mp3
│ ├── ER071:生吃.mp3
│ ├── ER072:《原谅他77次》.mp3
│ ├── ER076:绝世高手.mp3
│ ├── ER078:京城81号2.mp3
│ ├── ER079:大护法.mp3
│ ├── ER081:深夜食堂2.mp3
│ ├── ER082:闪光少女.mp3
│ ├── ER083:《父子雄兵》.mp3
│ ├── ER084:建军大业.mp3
│ ├── ER085:我是马布里.mp3
│ ├── ER086:《三生三世十里桃花》(0分,主播:小猱).mp3
│ ├── ER087:心理罪.mp3
│ ├── ER088:《侠盗联盟》.mp3
│ ├── ER089:《破·局》.mp3
│ ├── ER090:《杀破狼·贪狼》.mp3
│ ├── ER091:《十万个冷笑话2》.mp3
│ ├── ER094:《赛车总动员3:极限挑战》.mp3
│ ├── ER096:失眠.mp3
│ ├── ER097:《惊天解密》.mp3
│ ├── ER098:《鬼魅浮生》.mp3
│ ├── ER099:《军舰岛》.mp3
│ ├── ER100:《缝纫机乐队》.mp3
│ ├── ER105:《雷神3:诸神黄昏》.mp3
│ ├── ER106:《东方快车谋杀案》(2017版).mp3
│ ├── ER110:《追捕》(2017版).mp3
│ ├── ER112:《帕丁顿熊2》(主播:法兰西胶片).mp3
│ ├── ER113:《至爱梵高·星空之谜》.mp3
│ ├── ER126:《伯德小姐》(客串:田野、小猱).mp3
│ ├── ER129:捉妖记2.mp3
│ ├── ER130:《唐人街探案2》.mp3
│ ├── ER131:爱在记忆消逝前.mp3
│ ├── ER132:黑豹.mp3
│ ├── ER133:恋爱回旋.mp3
│ ├── ER134:大坏狐狸的故事.mp3
│ ├── ER135:古墓丽影:源起之战.mp3
│ ├── ER136:《环太平洋2:雷霆再起》.mp3
│ ├── ER137:第三度嫌疑人.mp3
│ ├── ER138:《通勤营救》(客串:法兰西胶片).mp3
│ ├── ER139:起跑线.mp3
│ ├── ER140:狂暴巨兽.mp3
│ ├── ER141:脱单告急.mp3
│ ├── ER142:后来的我们.mp3
│ ├── ER143:幕后玩家.mp3
│ ├── ER144:《昼颜》.mp3
│ ├── ER145:《路过未来》.mp3
│ ├── ER146:《超时空同居》.mp3
│ ├── ER147:《命运速递》.mp3
│ ├── ER148:《西小河的夏天》.mp3
│ ├── ER149:《哆啦A梦:大雄的金银岛》.mp3
│ ├── ER150:《厕所英雄》.mp3
│ ├── ER151:《猛龙怪客》(虎胆追凶)&《深海越狱》.mp3
│ ├── ER152:《泄密者》.mp3
│ ├── ER153:《金蝉脱壳2:冥府》.mp3
│ ├── ER154:《摩天营救》.mp3
│ ├── ER155:《毒战》(韩版).mp3
│ ├── ER156:《西虹市首富》.mp3
│ ├── ER157:《妈妈咪呀2》.mp3
│ ├── ER158:《风语咒》.mp3
│ ├── ER159:《一出好戏》.mp3
│ ├── ER160:《巨齿鲨》.mp3
│ ├── ER161:《精灵旅社3:疯狂假期》.mp3
│ ├── ER162:《欧洲攻略》.mp3
│ ├── ER163:《大三儿》&《最后的棒棒》.mp3
│ ├── ER164:《升级》.mp3
│ ├── ER165:《天才之击》(客串:胡力涛).mp3
│ ├── ER166:《蚁人2:黄蜂女现身》.mp3
│ ├── ER167:《瞒天过海美人计》.mp3
│ ├── ER168:《阿尔法:狼伴归途》.mp3
│ ├── ER169:《传奇的诞生》.mp3
│ ├── ER170:《边境杀手2:边境战士》.mp3
│ ├── ER171:《未择之路》.mp3
│ ├── ER172:《悲伤逆流成河》.mp3
│ ├── ER173:《黄金兄弟》.mp3
│ ├── ER174:《无双》.mp3
│ ├── ER175:《嗝嗝老师》.mp3
│ ├── ER176:《帝企鹅日记2:召唤》.mp3
│ ├── ER178:《跨越8年的新娘》.mp3
│ ├── ER179:《宝贝儿》.mp3
│ ├── ER180:《我的间谍前男友》.mp3
│ ├── ER181:《无敌原始人》.mp3
│ ├── ER182:《铁血战士》(2018版).mp3
│ ├── ER183:《阿拉姜色》.mp3
│ ├── ER184:《飓风奇劫》.mp3
│ ├── ER185:《流浪猫鲍勃》.mp3
│ ├── ER186:《大轰炸》.mp3
│ ├── ER187:《你好,之华》.mp3
│ ├── ER188:《毒液》.mp3
│ ├── ER189《神奇动物在哪里2:格林德沃之罪》(主播:效愚).mp3
│ ├── ER190:《无名之辈》.mp3
│ ├── ER191:《无敌破坏王2》.mp3
│ ├── ER192:《憨豆特工3》.mp3
│ ├── ER193:《海王》(客串:鲁韵子).mp3
│ ├── ER194:《绿毛怪格林奇》.mp3
│ ├── ER195:《冥王星时刻》.mp3
│ ├── ER196:《叶问外传:张天志》.mp3
│ ├── ER197:《来电狂响》.mp3
│ ├── ER198:《大黄蜂》.mp3
│ ├── ER199:《四个春天》.mp3
│ ├── ER200:《“大”人物》.mp3
│ ├── ER201:《白蛇:缘起》.mp3
│ ├── ER202:《养家之人》.mp3
│ ├── ER203:《疯狂外星人》.mp3
│ ├── ER204:《小猪佩奇过大年》.mp3
│ ├── ER205:《新喜剧之王》.mp3
│ ├── ER206:《飞驰人生》.mp3
│ ├── ER207:《廉政风云》.mp3
│ ├── ER208:《神探蒲松龄》.mp3
│ ├── ER209:《一吻定情》.mp3
│ ├── ER210:《惊奇队长》.mp3
│ ├── ER211:《过春天》.mp3
│ ├── ER212:《比悲伤更悲伤的故事》.mp3
│ ├── ER213:《老师·好》.mp3
│ ├── ER215:《海市蜃楼》.mp3
│ ├── ER216:《小飞象》.mp3
│ ├── ER217:《调音师》.mp3
│ ├── ER218:《雷霆沙赞!》.mp3
│ ├── ER219:《撞死了一只羊》(雷普利).mp3
│ ├── ER220:《雪暴》(海老鼠).mp3
│ ├── ER221:《海蒂和爷爷》(雷普利).mp3
│ ├── ER222:《一条狗的使命2》(胶片).mp3
│ ├── ER223:《过昭关》(靳锦).mp3
│ ├── ER224:《龙珠超:布罗利》(法兰西胶片).mp3
│ ├── ER225:《阿拉丁》(隐形).mp3
│ ├── ER226:《哆啦A梦:月球》(阳磊).mp3
│ ├── ER227:《X战警:黑凤凰》(荡科长).mp3
│ ├── ER228:《妈阁是座城》(秦婉).mp3
│ ├── ER229:《黑衣人外传:全球追缉》(隐形).mp3
│ ├── ER230:《大河唱》(熊阿姨).mp3
│ ├── ER231:《监护风云》(靳锦).mp3
│ ├── ER232:《玩具总动员4》(蜉蝣).mp3
│ ├── ER233:《孟买酒店》(雷普利).mp3
│ ├── ER234:《蜘蛛侠2:英雄远征》(鲁韵子).mp3
│ ├── ER235:《逆流大叔》(秦婉).mp3
│ ├── ER236:《扫毒2天地对决》(胶片).mp3
│ ├── ER237:《高达NT》(胶片).mp3
│ ├── ER238:《送我上青云》(海老鼠).mp3
│ ├── ER239:《上海堡垒》.mp3
│ ├── ER240:合辑《昨日奇迹》《愤怒的小鸟2》《沉默的证人》《使徒行者2》《烈火英雄》.mp3
│ ├── ER241:《速度与激情外传:特别行动》.mp3
│ ├── ER242:《昆虫总动员2-来自远方的后援军》.mp3
│ ├── ER243:《保持沉默》(秦婉).mp3
│ ├── ER244:《深夜食堂》(国版,主播:海老鼠).mp3
│ ├── ER245:《小丑》(威尼斯前方无剧透版).mp3
│ ├── ER246:《罗小黑战记》(雷普利).mp3
│ ├── ER247:《小小的愿望》(萝贝贝).mp3
│ ├── ER248:《决胜时刻》(法兰西胶片).mp3
│ ├── ER249:《犯罪现场》.mp3
│ ├── ER250:《安娜》(靳锦).mp3
│ ├── ER251:《终结者:黑暗命运》(主播:法兰西胶片).mp3
│ ├── ER252:《我的拳王男友》.mp3
│ ├── ER253:《受益人》.mp3
│ ├── ER254:《他们已不再变老》(刘三解).mp3
│ ├── ER255:《大约在冬季》(萝贝贝).mp3
│ ├── ER256:《冰雪奇缘2》(张扬).mp3
│ ├── ER257:《利刃出鞘》.mp3
│ ├── ER258:《星际探索》(雷普利).mp3
│ ├── ER259:《星球大战9:天行者崛起》.mp3
│ ├── ER260:《叶问4:完结篇》.mp3
│ ├── ER261:《半部喜剧》(萝贝贝).mp3
│ ├── ER262:《理查德·朱维尔的哀歌》.mp3
│ ├── ER263:《囧妈》.mp3
│ ├── ER264:《教宗的承继》(主播:杨超).mp3
│ ├── ER265:《隐形人》(主播:隐形).mp3
│ ├── ER266:《二分之一魔法》(张扬).mp3
│ ├── ER267:《南山的部长们》(刘三解).mp3
│ ├── ER268:《猛禽小队和哈莉·奎茵》(鲁韵子).mp3
│ ├── ER269:《从不,很少,有时,总是》(雷普利).mp3
│ ├── ER270:《饥饿站台》(海老鼠).mp3
│ ├── ER271:《矿民,马夫,尘肺病》(雷普利).mp3
│ ├── ER272:《狩猎》(田野).mp3
│ ├── ER273:《狩猎的时间》(洞姐).mp3
│ ├── ER274:《卡彭》(雷普利).mp3
│ ├── ER275:《列夫·朗道:娜塔莎》(海老鼠).mp3
│ ├── ER276:《春潮》(雷普利).mp3
│ ├── ER277:《多力特的奇幻冒险》(荡科长).mp3
│ ├── ER278:《喋血战士》(胶片).mp3
│ ├── ER279:《妙先生》(阿苏).mp3
│ ├── ER280:《#活着》(洞姐).mp3
│ ├── ER281:《小妇人》(鲁韵子).mp3
│ ├── ER282:《麦路人》.mp3
│ ├── ER283:评《我想结束这一切》(雷普利).mp3
│ ├── ER284-评《急先锋》(4分,胶片).mp3
│ ├── ER285-评《我和我的家乡》(5.3分,洞姐&秦婉&阳磊&阿苏&波米).mp3
│ ├── ER286-评《一点就到家》(7.5分,海老鼠).mp3
│ ├── ER287-评《喜宝》(1.5分).mp3
│ ├── ER288-评《掬水月在手》(熊阿姨).mp3
│ ├── ER289-评《气球》(7分,海老鼠).mp3
│ ├── ER290-评《疯狂原始人2》(5.5分,阿苏).mp3
│ ├── ER291-评《棒!少年》.mp3
│ ├── ER292-评《送你一朵小红花》(5分).mp3
│ ├── ER293-评《唐人街探案3》(洞姐).mp3
│ ├── ER294-评《人潮汹涌》(海老鼠).mp3
│ ├── ER295-付费摘录:评《消失的情人节》(蜉蝣&雷普利&波米).mp3
│ ├── ER296-评《侍神令》(钱德勒).mp3
│ ├── ER297-评《刺杀小说家》(阿苏).mp3
│ ├── ER298-付费摘录:评《无声(台)》(雷普利).mp3
│ ├── ER299-付费摘录:评《孤味》(雷普利).mp3
│ ├── ER300-评《你好,李焕英》(弦子).mp3
│ ├── ER301-评《我的姐姐》(5分).mp3
│ ├── ER302-评《你的婚礼》(洞姐,5分).mp3
│ ├── ER303-评《悬崖之上》(5分).mp3
│ ├── ER304-评《白蛇传·情》(6.5分).mp3
│ ├── ER305-评《寂静之地2》(7分).mp3
│ ├── ER306-评《黑白魔女库伊拉》(阿苏,6.5分).mp3
│ ├── ER307-评《怒火·重案》(7分).mp3
│ ├── ER308-评《白蛇2:青蛇劫起》(6.5分).mp3
│ ├── ER309-评《盛夏未来》(6分).mp3
│ ├── ER310-评《硬汉枪神》(法兰西胶片,5.5分).mp3
│ ├── ER311-评《失控玩家》(微软晓晓,6分).mp3
│ ├── ER312-评《致命感应》(段练&波米,约5.8分).mp3
│ ├── ER313-评《007:无暇赴死》(5分).mp3
│ ├── ER314-评《扬名立万》(6分).mp3
│ ├── ER315-评《尚气》(5.5分).mp3
│ ├── ER316-付费摘录:评《瀑布》(秦婉_胤祥_波米).mp3
│ ├── er002:幻体.mp3
│ ├── er003:超脑48小时.mp3
│ ├── er004:X战警:天启.mp3
│ ├── er005:钢刀.mp3
│ ├── er006:惊天魔盗团2.mp3
│ ├── er008:《寒战2》.mp3
│ ├── er009:忍者神龟2.mp3
│ ├── er010:《大鱼海棠》.mp3
│ ├── er011:《绝地逃亡》.mp3
│ ├── er012:我们诞生在中国.mp3
│ ├── er014:谍影重重5.mp3
│ ├── er015:七月与安生.mp3
│ ├── er016:神奇动物在哪里.mp3
│ ├── er017:《海洋奇缘》.mp3
│ ├── er018:间谍同盟.mp3
│ ├── er019:佩小姐的奇幻城堡.mp3
│ ├── er020:塔洛耳旁风.mp3
│ ├── er021:我在故宫修文物.mp3
│ ├── er022:生门.mp3
│ ├── er023:摆渡人.mp3
│ ├── er024:铁道飞虎.mp3
│ ├── er025:情圣.mp3
│ ├── er026:你好,疯子!.mp3
│ ├── er027:少年巴比伦.mp3
│ ├── er028:太空旅客.mp3
│ ├── er040:一条狗的使命.mp3
│ ├── er042:天才捕手.mp3
│ ├── er044:生化危机6:终章.mp3
│ ├── er055:逃出绝命镇.mp3
│ ├── er073:奇幻人生.mp3
│ ├── er074:逆时营救.mp3
│ ├── er075:与君相恋100次.mp3
│ ├── er077:神偷奶爸3.mp3
│ ├── er080:悟空传.mp3
│ ├── er092:目击者之追凶.mp3
│ ├── er093:星际特工:千星之城.mp3
│ ├── er095:看不见客人.mp3
│ ├── er101:空天猎.mp3
│ ├── er102:英伦对决.mp3
│ ├── er103:追龙.mp3
│ ├── er104:羞羞的铁拳.mp3
│ ├── er107:家族之苦2.mp3
│ ├── er108:正义联盟.mp3
│ ├── er109:暴雪将至.mp3
│ ├── er111:寻梦环游记.mp3
│ ├── er114:妖猫传.mp3
│ ├── er115:心理罪之城市之光.mp3
│ ├── er116:前任3:再见前任.mp3
│ ├── er117:妖铃铃.mp3
│ ├── er118:二代妖精.mp3
│ ├── er119:解忧杂货店.mp3
│ ├── er120:神秘巨星.mp3
│ ├── er121:移动迷宫3.mp3
│ ├── er122:奇迹男孩.mp3
│ ├── er123:马戏之王.mp3
│ ├── er124:南极之恋.mp3
│ ├── er125:忌日快乐.mp3
│ ├── er127:西游记女儿国.mp3
│ ├── er128:红海行动.mp3
│ ├── er177:《超能泰坦》.mp3
│ └── er214:《乐高大电影2》.mp3
├── 反派马后炮全集(2016-2022)
│ ├── MA135:2022年第94届奥斯卡颁奖礼综述.mp3
│ └── MA136:俄乌战争背景下的文化制裁.mp3
├── 电影耳旁风全集(2016-2022)
│ ├── ER317-评《神奇动物3:邓布利多之谜》(6.5分,阿苏).mp3
│ └── ER318-评《哭悲》(7.5分,杨超).mp3
├── 日常节目优先播放专辑
│ └── MA132:特区修改“香港电影检查条例”.mp3
├── 日常节目优先收听专辑
│ ├── 2021年11月节目单(会员音频版).mp3
│ ├── 2021年12月节目单(会员音频版).mp3
│ ├── 2022年1月节目单(会员音频版).mp3
│ ├── ER316-付费摘录:评《瀑布》(秦婉_胤祥_波米).mp3
│ ├── HUI01-评《圣母》(约6.8分,杨超_波米).mp3
│ ├── MA131:《搏击会》内地版修改结局事件.mp3
│ ├── MA133:第58届台湾金马奖综述(秦婉_胤祥_波米).mp3
│ └── NO.221-评《梅艳芳》(5.5分,萝贝贝_阿苏_波米).mp3
├── 反派文集与其它音频(2016-2020)
│ ├── 2018年4月音频节目单(含广告,荡科长_蜉蝣_波米).mp3
│ ├── 2018年7月音频节目单(海老鼠_鬓鬓_波米).mp3
│ ├── 2020年3月音频节目单&十年专题介绍&声援剩余价值(隐形_波米).mp3
│ ├── MA098原初版:2020年奥斯卡纪录长片提名点评(陆庆屹_陈玲珍_波米).mp3
│ └── 一周年特别节目:《招魂2》闹鬼原址探访(音频).mp3
├── 大江东去——奥斯卡十年专题
│ ├── 奥斯卡十年③导演&表演.mp3
│ ├── 奥斯卡十年①关键词.mp3
│ ├── 奥斯卡十年②名场面.mp3
│ ├── 奥斯卡十年④小奖大作.mp3
│ ├── 奥斯卡十年⑦未来展望.mp3
│ ├── 奥斯卡十年⑤十佳片(上).mp3
│ └── 奥斯卡十年⑥十佳片(下).mp3
├── 狂沙十万里——《沙丘》专题
│ ├── 4、原著设定-水利专制统治(鲁韵子&麦教授&波米).mp3
│ ├── 5、原著人物-英雄十二阶段(鲁韵子&麦教授&波米).mp3
│ ├── 6、对比《基地》:不是原著基地,是拉登的基地.mp3
│ ├── 7、从沙丘到三体:科幻事关“未来定义权”.mp3
│ ├── 8、《沙丘》随片评论(杨超_波米).mp3
│ ├── 8、《沙丘》评论(无空隙版,杨超_波米).mp3
│ ├── 8、《沙丘》随片评论(开头倒数版,杨超_波米).mp3
│ └── NO.219-评《沙丘》(约6.8分,雷普利_波米).mp3
├── 去日苦多——香港电影十年专题
│ ├── 港片十年①合拍片:千言万语.mp3
│ ├── 港片十年②合拍片:粤语残片.mp3
│ ├── 港片十年③合拍片:伶官传序.mp3
│ └── 港片十年⑨十佳片:风中风中.mp3
├── 登堂入室——韩国电影十年专题
│ ├── 十年电影观⑧佳片榜:“东方有个肯·洛奇”.mp3
│ ├── 赠品:反派影评“韩影十年”线上交流-全程回放音频.mp4
│ ├── 十年文化观③观相社会:“下女的阶梯”.mp3
│ ├── 十年文化观①热点惊回首:“那天,大海”.mp3
│ ├── 十年电影观⑨五大过誉片:“辩护人已死”.mp3
│ ├── 十年电影观⑩三大杰作:“耶稣为何东渡?”.mp3
│ ├── 十年行业观⑦为我所用:“中韩电影差几年”.mp3
│ ├── 十年行业观⑤国民偶像沉浮录:“翁主与屌丝”.mp3
│ ├── 十年文化观②半岛与萨德危机:“北风!北风!”.mp3
│ ├── 十年行业观⑥全能类型片:“老家伙的全盛时代”.mp3
│ └── 十年行业观④大师与学徒:“不是任何人女儿的导演”.mp3
├── 《沙丘》专题——“狂沙十万里”
│ ├── 1、电影外延-大师的坟场(靳锦&田野&波米).mp3
│ ├── 2、美剧外延-时代的眼泪(靳锦&田野&波米).mp3
│ └── 3、游戏外延-即时战略消亡史(麦教授&波米).mp3
├── 他们已在变老——《指环王》专题
│ └── 碟2(无倒数):《指环王3》随片讲解(杨超&波米).mp3
├── 再见语言——戛纳电影节十年专题
│ ├── 戛纳十年②作者论“华山论剑”.mp3
│ ├── 戛纳十年①作者论“失宠与过誉”.mp3
│ ├── 戛纳十年③行业观“搞个大新闻”.mp3
│ ├── 戛纳十年④行业观“影响的焦虑”.mp3
│ ├── 戛纳十年⑤十佳片“潮起又潮落”.mp3
│ └── 戛纳十年⑥十佳片“我们的故事”.mp3
├── 娱乐至死——好莱坞类型片十年专题
│ ├── 十年娱乐场③"一声NO,一曲Let It Go.".mp3
│ ├── 彩蛋:“动改真&动画片”十年概览.mp3
│ ├── 十年拉片室⑧“AI·丧尸·造物主”.mp3
│ ├── 十年拉片室⑦“怪兽·屌丝·克苏鲁”.mp3
│ ├── 十年热搜榜⑤“表姐·寡姐·劳模姐”.mp3
│ ├── 十年热搜榜⑥“斗士·骑士·传教士”.mp3
│ ├── 本期介绍与片段试听(波米).mp3
│ ├── 十年娱乐场①“漫威大法一时爽”.mp3
│ ├── 十年娱乐场②“相扑大赛火葬场”.mp3
│ ├── 十年水晶球⑨“雕栏玉砌应犹在”.mp3
│ └── 十年热搜榜④“惊天动地抢头条”.mp3
├── 《指环王》专题——“他们已在变老”
│ ├── 1、《指环王3》随片讲解(杨超&波米).mp3
│ ├── 2、《霍比特人》及“魔戒”相关作品(麦教授&波米).mp3
│ ├── 3、导演彼得·杰克逊前作回顾(麦教授&波米).mp3
│ ├── 4、事件讨论:《指环王》死于短视频时代?(杨超&法兰西胶片&波米).mp3
│ ├── 碟2(有倒数):《指环王3》随片讲解(杨超&波米).mp3
│ └── 《指环王3》随片讲解(开头倒数版,杨超&波米).mp3
└── (连载中)去日苦多——香港电影十年专题
├── 港片十年④港产片:恐惧本身.mp3
├── 港片十年⑤港产片:作茧成蝶.mp3
├── 港片十年⑥港产片:前仆后继.mp3
├── 港片十年⑦十佳片:落日余晖.mp3
└── 港片十年⑧十佳片:未来昔日.mp3
26 directories, 867 files
附录
观影风向标全集,下载地址
.
├── 000《北京遇上西雅图2》(5.2分 PG13)——无耻的IP 糟糕的续集.m4a
├── 001 成全自己,恶心别人的《私人定制》.m4a
├── 002 还有谁可以拯救《警察故事2013》.m4a
├── 003 银河系装逼指南:《等风来》.m4a
├── 004 除了片名什么都好——《救火英雄》.m4a
├── 005 结尾的反转你猜到了吗?—《安德的游戏》.m4a
├── 006 萌到极致就卑鄙了——《神偷奶爸2》.m4a
├── 007 闲聊86届奥斯卡提名名单.m4a
├── 008 俄罗斯怎么招你了?——《一触即发》.m4a
├── 009《僵尸》—20年来最好看的华语恐怖片,即使有之一.m4a
├── 010 《大闹天宫》— 别再拿大圣开玩闹了!.m4a
├── 011《爸爸去哪》 - 电影院看电视.mp3
├── 012 情人节快餐——《北爱》(6.6分).m4a
├── 013 十四个矮人整恶龙—《霍比特人2》(7.3分).m4a
├── 014 世界工厂与中国3D——《新机械战警》(8.0分).m4a
├── 015《天注定》(7.5分)——面对暴力你需要擦亮眼睛.m4a
├── 016 《极品飞车》(6.5分)——老的游戏新的激情.m4a
├── 017《雪国列车》(6.8分)——论世界末日和狗熊掰棒子.m4a
├── 018 《白日焰火》(6.0分)—严重高估与严重删改.m4a
├── 019《天才眼镜狗》(6.3分)——大人看太幼稚,小孩看太费劲.m4a
├── 020《盟军夺宝队》(5.0分)——美国“主旋律烂片”的绝佳范本.m4a
├── 021《美国队长2》(6.8)——美国主旋律+谍影重重+跑酷高手.m4a
├── 022《里约大冒险2》(7.3分)——Happy Wife,Happy Life.m4a
├── 023《催眠大师》(7.1分)——独家揭秘剧本原有的反转剧情.m4a
├── 024《超凡蜘蛛侠2》(7.5分)——最亲民的超级英雄.m4a
├── 025 《人间小团圆》(5.6分) - 无关杜汶泽,就是不好看.mp3
├── 026《归来》(6.8分)——张艺谋的“老清新”与“初恋50次”.m4a
├── 027《X战警——逆转未来》(6.5分)——管它合不合理,反正我给你都弄活了!.m4a
├── 028《窃听风云3》(6.2分)——窃听越来越像鸡蛋壳了,一敲就碎!.m4a
├── 029 波米戛纳归来有感——下里巴人与风花雪月只差一层楼而已.m4a
├── 030《明日边缘》(7.6分)——异类穿越引发的烧脑大猜想.m4a
├── 031《哥斯拉2014》(6.6分)——大大大大大大怪兽!.m4a
├── 032《摩纳哥王妃》(6.4)——好莱坞明星的欧洲皇室攻略.m4a
├── 033《沉睡魔咒》(6.1)——接力《冰雪奇缘》宣示女权复兴.m4a
├── 034《变形金刚4》(6.2)——喜欢围观看打架的人有福了!!.m4a
├── 035《分手大师》(5.5分)——犯贱无底线,搞笑没尊严,我们不推荐.m4a
├── 036《突袭2》(7.0分)——令香港武指汗颜的印尼神片.m4a
├── 037《笔仙3》(5.5分)——恐怖吗?!.mp3
├── 038《老男孩之猛龙过江》(5.6分)——屌丝做完屌丝梦发现自己还是屌丝的屌丝故事!.m4a
├── 039《小时代3》(5.0分)——中国的粉丝电影最大特点就是你看不懂!.m4a
├── 040《京城81号》(5.4分)——传说和现实是有差距的!!.m4a
├── 041《后会无期》(6.3分)——一路向西的西游记.m4a
├── 042《绣春刀》(6.6分)——以故鉴今的明朝那些事儿.m4a
├── 043《龙之谷——破晓奇兵》(7.1分)——国产3D动画的自我救赎.m4a
├── 044《驯龙高手2》(7.2分)——为什么第二部永远不如1?.m4a
├── 045《猩球崛起2》(7.2分)——细说猩球全系列!!.m4a
├── 046《敢死队3》(6.2分)——长征路上的敢死队还能走多久?.m4a
├── 047《挑战者联盟》(7.5分)——今年最不该错过的3D动画片!.m4a
├── 048《心花路放》(6.2分)——别抱太高期望就还挺逗的…….m4a
├── 049 波米多伦多电影节归来专访.m4a
├── 050 《亲爱的》(7.6分)——这不止是一部电影!.m4a
├── 051《黄金时代》(6.0分)——一部被朗读出来的电影.m4a
├── 052《痞子英雄:黎明升起》(5.6)——好一锅东北乱炖!!!.m4a
├── 053 《银河护卫队》(7.3分)——废柴联盟闹翻二手科幻.m4a
├── 054《蓝色骨头》(6.4分)——新长征路上的电影.m4a
├── 055《移动迷宫》(6.0分)——心慌方+大逃杀+林中小屋.m4a
├── 056《宙斯之子》(6.7分)——论宣传工作在革命战线的重要性!.m4a
├── 057《超体》(6.7分)——一线之隔的扯淡与真理.m4a
├── 058《忍者神龟》(6.6分)——定义什么是爆米花电影.m4a
├── 059《星际穿越》(8.3分)——2014太空漫游.m4a
├── 060《马达加斯加的企鹅》(6.2分)——萌吗?贱吗?好看吗?.m4a
├── 061《星际穿越》互动问答版:讨论无止境 电影价更高.m4a
├── 062《狂怒》(6.8分)——世界的主旋律,美国的狼牙山.m4a
├── 063《推拿》(6.8分)——黑暗中的情与欲.m4a
├── 064《太平轮(上)》(5.2分)——沉没在岸边的《太平轮》!.m4a
├── 065《鸣梁海战》(6.1分)——棒子和鬼子不得不说的故事.m4a
├── 066《一步之遥》(5.5分)——步子迈大了容易扯着蛋!.m4a
├── 067《智取威虎山》(6.0分)——“一个字”就能结束2014?.m4a
├── 067《博物馆奇妙夜3》(6分)——即将关张的博物馆与音容宛在的罗宾威廉斯.m4a
├── 069 观影风向标2014年内地市场五佳片评选之引进片.m4a
├── 070观影风向标2014年内地市场五佳片评选之国产片.m4a
├── 071观影风向标2014年海外市场不容错过的电影.m4a
├── 072《重返20岁》(6分)——出色的创意,不同的演绎.m4a
├── 073《前目的地》(7.3分)——超强剧透,不喜误入!.m4a
├── 074《霍比特人:五军之战》(6.3分)——再见中土世界!.m4a
├── 075《坚不可摧》(5.8分)——缺少维他命的人物传记电影.m4a
├── 076《狼图腾》(7分)——丢掉了残忍,狼就变成狗了.m4a
├── 077《天将雄师》(6分)——漏洞百出的故事,狗血的个人英雄主义.mp3.m4a
├── 078《超能陆战队》(7.3分)——超萌陆战队!.m4a
├── 079 波米专访——柏林电影节见闻录.m4a
├── 080《失孤》(5.7分)——角度不同结果不同的凭心而论.m4a
├── 081《王牌特工》(7.7分)——在那烟花盛开的地方.m4a
├── 082《一万年以后》(6.2分)——奇葩电影映射出的奇葩现象.m4a
├── 083《速度与激情7》(6.5分)——永别保罗 再见激情!.m4a
├── 084《万物生长》(6.0分)——直男癌的三段春梦.m4a
├── 085《闯入者》(7.4分)——闯入者与红色失忆症.mp3.m4a
├── 086《赤道》(6.8分)——你真的读懂了《赤道》的含义吗?.m4a
├── 087《超能查派》(7.5分)——人性最后的希望,并不来自人类本身.m4a
├── 088《复》《明》《哆》《末》——短评大集合.m4a
├── 089《侏罗纪世界》(7分)——怀旧,最强的致幻剂.m4a
├── 090 专访波米68界戛纳电影节见闻.m4a
├── 091《少年班》(6.5分)——被糟蹋了的电影好题材.m4a
├── 092《道士下山》(3.8分)——太极与八卦.m4a
├── 093《我是路人甲》(6.6分)——中国影视圈最底层群落的冰山一角.m4a
├── 094《西游记之大圣归来》(7.3分)——一部合格的国产动画片.m4a
├── 095《捉妖记》(7.3分)——关于政策与一碗水端平.m4a
├── 096《煎饼侠》(6.2分)——屌丝!.m4a
├── 097《模仿游戏》(7.4分)——绝不沉闷的人物传记电影.m4a
├── 098《破风》(7.3分)——两只轮子的速度与激情.m4a
├── 099《滚蛋吧!肿瘤君》(6.4分)——正能量与催泪弹.m4a
├── 100 观影100期,是“终结”,还是“创世纪”——《终结者 创世纪》(6.0分).m4a
├── 101《烈日灼心》(7.0 分)——法外之徒.mp3
├── 102《刺客聂隐娘》(6.8分)——聂隐娘观影贴士.m4a
├── 103《碟中谍 5》(7.4分) PG-13——围观50岁开外“老人家”上天入地.m4a
├── 104 72届威尼斯电影节——波米专访.m4a
├── 105《港囧》(5.9分 PG 15)——囧!!!.m4a
├── 106《九层妖塔》(5.2分 PG13)——雷!!.m4a
├── 107《解救吾先生》(7.5分 PG15)——有气场的绑匪与有根基的城市.m4a
├── 108《头脑特工队》(6.7分 PG)——是皮克斯的翻身仗还是炒冷饭?.m4a
├── 109《心迷宫》(6.6分 PG13)——诚意之作·独立之光.m4a
├── 110《小王子》(7分 PG)——又一部神作还是又一次过誉?.m4a
├── 111《蚁人》(6.6分 PG13)——蚁力神!谁看谁知道!.m4a
├── 112《他在身后》(6.5分 PG18)——这是4个月前录好的节目.m4a
├── 113《山河故人》(5.8分 PG13)——山河依旧 故人不在.m4a
├── 114《军中乐园》(7分 R)——乡愁是一湾浅浅的海峡.m4a
├── 115《007:幽灵党》(5.9分 PG13)——007系列从革命之路走向毁灭之路.m4a
├── 116《一个勺子》(7.2分 PG13)——从勺子到后脑勺子.m4a
├── 117《火星救援》(7.2分 PG13)—荒岛求生+Apollo13.m4a
├── 118《师父》(7.3分 PG13)——刀背藏身·坐看重围.m4a
├── 119《寻龙诀》(6.8分 PG13).m4a
├── 120 《老炮儿》(7.3分 R级)-问谁主沉浮?姆们姆们姆们!.m4a
├── 121 观影风向标2015年内地市场十强佳片评选之引进片.m4a
├── 122 观影风向标2015年内地市场十强佳片评选之国产片.m4a
├── 123《蝙蝠侠大战超人》(5.5分 PG13) ——英雄归来 不再守望!.m4a
├── 124 《火锅英雄》(6.8分 R级)——一锅致敬梗与类型混搭的九宫格.m4a
├── 125《伦敦陷落》(5.3分 PG-13)——伦敦,不设防的城市.m4a
├── 126《聚焦》(8分 R级)——现实里没有超级英雄,只有恪尽职守.m4a
└── 127《疯狂动物城》(7.7分 PG)——乌托邦的绝对政治正确.m4a
0 directories, 128 files
《也许你该找个人聊聊》读书笔记
怎么知道的这一本书
我已经忘记最初是怎么知道的这一本书了,好像是订阅的某人的 Newsletter,又或许是在豆瓣看到了别人的书评。但这本书已经被标记为待看了,就拿出来读了一下。
虽然看到豆瓣的上的评价已经排上了豆瓣 Top 250 中的 117 名,但阅读之前确实没有抱有很大的期待,但当我看了一半之后我才发了这一本书魅力。尤其是当哪位身患癌症为时不多的大学女教授,当她发现自己更喜欢超市收银员时义无反顾的去做时,我甚至是眼泛泪光的。还有看到那个送了多年的快递小哥受到作者感召决定会学校读书,最终成为一个建筑承包商的时候,我是感动的。这种力量是无形的,来自于生活最真实的鼓励。
关于作者
作者叫做洛莉·戈特利布(Lori Gottlieb),我原本对作者也并不是非常了解,但阅读的过程中也能在书中略微感受到一些,作者是一位心理治疗师。并且带着一位小孩,而这位小孩并不是作者结婚之后所生,而是通过购买精子而得。在书中的开篇也能读到作者自己因为和一位「仇童男」分手而陷入痛苦并找另一位心理治疗师治疗的过程。
几句话总结书的内容
这是一本心理治疗师写的回忆录,回顾几位来访者的故事,包括:
- 一个沉迷于手机短信,防卫心较重的四十岁男人约翰,电视剧编剧和制片,事业成功,但自以为是。
- 母亲因为救学生而被汽车撞倒,父亲是一位立志要成为作家的英语文学教授。
- 一位 30 多岁,刚刚新婚被诊断出绝症的大学女教授。
- 在她发现自己的生命只剩下一年的时候,依然决定去当超时收银员。
- 二十四岁的女孩夏洛特,有着原生家庭创伤和酗酒问题,在爱情问题中频频受挫
- 一位六十九岁的孤独老太太,离过三次婚,对生活缺少目标而且充满遗憾,声称如果生活不好转,将会在 70 岁生日的时候自杀
这一本书的组织架构并没有将这几个人的故事一一整理到一起,而是以时间序,穿插讲述,在一开始月阅读的时候还有一些不适,但是当我习惯了作者的叙事逻辑之后,发现非常易读。作者的文笔也非常细腻,生动,往往一件非常小的事情通过作者的叙述就能够在脑海里面构建出一副画面。
启发或想法
在阅读这一本书的时候,我不经回想起一部没有那么知名的韩剧 —- [[灵魂修缮工]],[[申河均]] 饰演的心理医生和 [[郑素敏]] 饰演的患有 BPD 边缘型人格障碍的患者,两人偶然相遇发生的各种故事。
申河均扮演的心理医生正是这本书中作者提到了那一类长期和病患一起生活并观察病患给出治疗方案的医生。而这样的医生也正是现代医疗体系做排斥的,医院需要医生 15 分钟完成一位患者的诊断,流水线的完成任务。这一部韩剧也是我看过的少数几部以心理医生为主角的「医疗剧」。都说现代人或多或少有一些心理疾病,但却鲜有剧集去表现。而这一本书,这一部剧的观看过程就是非常疗愈的过程。
《精神疾病诊断与统计手册》罗列了十种人格障碍。
- A 群,具有古怪、奇异、反常的人格特质,偏执型人格障碍,分裂型人格障碍
- B 群(具有戏剧化、不稳定的人格特质) 反社会型人格障碍,边缘型人格障碍,表演型人格障碍,自恋型人格障碍
- C 群(具有焦虑、恐惧的人格特质)回避型人格障碍,依赖型人格障碍,强迫型人格障碍
[[荣格]] 创造了「集体无意识」这个词,指的是大脑中保存祖先记忆或全人类共有经验的部分。 [[弗洛伊德]] 才客观层面分析了梦境,即梦境的内容如何与做梦者的实际生活关联(包括人物的角色、特定的情境),而荣格心理学则是从主观层面解析梦境,去解释梦境如何与我们集体无意识中的共有主题相关联。
我们如何改变?
- 答案藏在「与他人的相处中」。
谁应该看这本书
- 我想这本书所有人都可以看,在任何时候,任何地点。
Obsidian 中使用 Vim 模式并配置 Vimrc
一直在 [[Obsidian]] 中使用 Vim 模式,之前也安装了 Obsidian Vimrc 的插件,但一直没有好好研究,只简单的配置了几行。最近总想要实现在 Visual Mode 下给选中的内容两边加上 Grave(也被称为 backtick,就是键盘上 1 左边的按键,在 markdown 下通常用来作为 code) ,或者双引号,一直没有找到很好的办法,所以想来研究一下很否通过 Vimrc 来实现。
本文就记录一下在 Obsidian 下使用 Vim 键盘操作,以及在 Obsidian 下配置 Vimrc。
Prerequisite
- 需要开启 Obsidian 的 Vim 支持
- 安装 Obsidian Vimrc Support Plugin
文档内移动
基础移动
j/k/h/lgg移动光标到首行G移动到最后一行w移动到下一个 word 第一个字母e移动到 word 尾,ge移动到上一个单词 word 尾b移动到上一个 word 第一个字母0移动到行第一个字符$移动到行尾^移动到行第一个非空白字符%跳转到匹配的()[]{},比如光标在(那么%可以跳转到匹配的)
垂直移动
上面提到过 j/k 可以跨行移动。
{移动到上一个 paragraph}移动到下一个 paragraphCtrl+u/d向上/下滚动窗口
搜索
/{pattern}向后搜索,输入搜索词 Enter,然后使用n跳转下一个匹配,N跳转上一个匹配?{pattern}向前搜索
笔记间跳转
Ctrl-oObsidian 默认, open quick switcherAlt-[(在 macOS 下为cmd+[) navigate back 跳转到前一个笔记Alt-](在 macOS 下为cmd+]) navigate forward 后一个笔记
这里推荐一个插件 Obsidian Better Command Palette ,安装完成之后映射到 Ctrl+p,然后就可以呼出 Palette:
/{search_keywords}来搜索文档名#{tag}来搜索标签,然后在标签中搜索文档
我觉得 Better Command Palette 比默认的 Switcher 好的一点在于在搜索框中会显示文档的名字,原始名字和标签,而默认的只会显示文档名,而我的很多文档都是使用 alias 重命名过的,一般文档名都是英文名,而 alias 会起一个中文名。
切分 Panel
Ctrl+\垂直切分窗口,这个可以在设置中搜索Split Vertically设置Ctrl+-水平切分窗口,Split Horizontally
vimrc
vimrc 文件是 Vim 的配置文件,在 Obsidian 中可以通过 Obsidian Vimrc Support Plugin 来支持 vimrc。
可以在笔记库(vault) 根目录创建 .obsidian.vimrc,然后在其中配置。
特性:
exmap [commandName] [command ...]用来映射 Ex commands 的命令。obcommand执行 Obsidian 命令cmcommand执行 CodeMirror 命令surround在 Visual 模式中给选择的文本添加内容,或者在 normal 模式中使用pasteinto粘贴板jscommand和jsfile
在添加命令到 Vimrc 文件之前,应该现在 Obsidian 的命令模式下尝试一下(在 Normal mode 下输入 : )。
" semicolon as colon
nmap ; :
" Have j and k navigate visual lines rather than logical ones
nmap j gj
nmap k gk
" I like using H and L for beginning/end of line
nmap H ^
nmap L $
这里举几个简单的例子:
- 第一个配置,就是在 normal 模式下,将
;映射成:,这样进入 Vim 命令模式的时候就可以按相同的按键而不用按下 Shift 了 - 第二个配置将
j映射成gj,k映射成gk,可以让j/k移动的时候按照视觉上的行数,而不是文本真实的换行,尤其是在笔记中可能有大量的段落的情况下非常有用 - 第三个配置,将
H映射成跳转到行首,L映射成跳转到行尾
Obsidian Commands
安装 Vimrc 支持插件之后作者定义了一个 Ex command 叫做 obcommand 来执行不同的 Obsidian 命令。
在 Obsidian 中执行 : obcommand [commandName] 可以执行命令:
obcommand app: go-backobcommand editor: insert-linkobcommand editor: toggle-commentobcommand workspace: split-vertical
作者在 GitHub 上说在编辑器中执行 : obcommand 会展示出当前支持的 obcommand 命令列表,但我尝试之后并没有作用,把 Obsidian 升级到最新的 0.15.9 也不管用。
并且尝试使用 surround ,目前好像也有 BUG。
附录
目前支持的 obcommand 列表:
app:delete-file Delete current file –
app:go-back Navigate back Ctrl+Alt+ArrowLeft
app:go-forward Navigate forward Ctrl+Alt+ArrowRight
app:open-help Open help F1
app:open-settings Open settings Ctrl+,
app:open-vault Open another vault –
app:reload Reload app without saving –
app:show-debug-info Show debug info –
app:toggle-default-new?pane-mode Toggle default new pane mode –
app:toggle-left-sidebar Toggle left sidebar –
app:toggle-right-sidebar Toggle right sidebar –
backlink:open Backlinks: Show backlinks pane –
backlink:open-backlinks Backlinks: Open backlinks for the current file –
backlink:toggle-backlinks-in?document Backlinks: Toggle backlinks in document –
command-palette:open Command palette: Open command palette Ctrl+P
dataview:dataview-drop?cache Dataview: Drop All Cached File Metadata –
dataview:dataview-force?refresh-views Dataview: Force Refresh All Views and Blocks –
editor:attach-file Insert attachment –
editor:context-menu Show context menu under cursor –
editor:cycle-list-checklist Cycle bullet/checkbox –
editor:delete-paragraph Delete paragraph Ctrl+D
editor:focus Focus on last note –
editor:focus-bottom Focus on pane below –
editor:focus-left Focus on pane to the left –
editor:focus-right Focus on pane to the right –
editor:focus-top Focus on pane above –
editor:fold-all Fold all headings and lists –
editor:follow-link Follow link under cursor Alt+Enter
editor:insert-callout Insert callout –
editor:insert-embed Add embed –
editor:insert-link Insert Markdown link Ctrl+K
editor:insert-tag Add tag –
editor:insert-wikilink Add internal link –
editor:open-link-in-new-leaf Open link under cursor in new pane Ctrl+Alt+Enter
editor:open-search Search current file Ctrl+F
editor:open-search-replace Search & replace in current file Ctrl+H
editor:rename-heading Rename this heading... –
editor:save-file Save current file Ctrl+S
editor:set-heading Toggle heading –
editor:swap-line-down Move line down –
editor:swap-line-up Move line up –
editor:toggle-blockquote Toggle blockquote –
editor:toggle-bold Toggle bold Ctrl+B
editor:toggle-bullet-list Toggle bullet list –
editor:toggle-checklist?status Toggle checkbox status Ctrl+Enter
editor:toggle-code Toggle code –
editor:toggle-comments Toggle comment Ctrl+/
editor:toggle-fold Toggle fold on the current line –
editor:toggle-highlight Toggle highlight –
editor:toggle-italics Toggle italics Ctrl+I
editor:toggle-numbered-list Toggle numbered list –
editor:toggle-source Toggle Live Preview/Source mode –
editor:toggle-spellcheck Toggle spellcheck –
editor:toggle-strikethrough Toggle strikethrough –
editor:unfold-all Unfold all headings and lists –
file-explorer:move-file File explorer: Move file to another folder –
file-explorer:new-file Create new note Ctrl+N
file-explorer:new-file-in-new?pane Create note in new pane Ctrl+Shift+N
file-explorer:open File explorer: Show file explorer –
file-explorer:reveal-active- file
File explorer: Reveal active file in navigation
file-recovery:open File recovery: Open saved snapshots –
global-search:open Search: Search in all files Ctrl+Shift+F
graph:animate Graph view: Start graph timelapse animation
graph:open Graph view: Open graph view Ctrl+G
graph:open-local Graph view: Open local graph –
markdown-importer:open Format converter: Open format converter
markdown:toggle-preview Toggle reading view Ctrl+E
note-composer:extract?heading Note composer: Extract this heading... –
note-composer:merge-file Note composer: Merge current file with another file... –
note-composer:split-file Note composer: Extract current selection... –
open-with-default-app:open Open in default app –
open-with-default-app:show Show in system explorer –
outgoing-links:open Outgoing Links: Show outgoing links pane
outgoing-links:open-for?current Outgoing Links: Open outgoing links for the current file –
switcher:open Quick switcher: Open quick switcher Ctrl+O
theme:use-dark Use dark mode –
theme:use-light Use light mode –
window:toggle-always-on?top Toggle window always on top –
workspace:close Close active pane Ctrl+W
workspace:close-others Close all other panes –
workspace:copy-path Copy file path –
workspace:copy-url Copy Obsidian URL –
workspace:edit-file-title Edit file title F2
workspace:export-pdf Export to PDF –
workspace:move-to-new?window Move current pane to new window –
workspace:open-in-new?window Open current pane in new window –
workspace:split-horizontal Split horizontally –
workspace:split-vertical Split vertically –
workspace:toggle-pin Toggle pin –
workspace:undo-close-pane Undo close pane Ctrl+Shift+T
记一次 iPhone 13 初始化设置 时隔 6 年我又转向了 iOS
大概 6,7 年前入手了 iPhone 7 ,当时第一次接触 iOS,当时的 iPhone 还有圆圆的 Home 键,还有指纹解锁。但如今的 iPhone 长了刘海,去掉了指纹解锁,增加了面容解锁,一样的 iOS 但确实有了一些变化。时隔 6 年之后,我又一次用回了 iOS,上个月 618 的时候买了一个最低配的 iPhone 13。在 iPhone 7 之后,我一直使用 OnePlus 7 Pro 至今,OnePlus 7 Pro 至今为止依然非常好的可以满足日常的工作生活,除了电池耐用性下降了之外。因为 OnePlus 7 Pro 还可以日常使用,所以重担不会落到 iPhone 13 上,128G 也够用了。
为何放弃了 OnePlus
OnePlus 的没落,自从卖身给了 OPPO,以及宣布了 Oxygen OS 和 OPPO 系统的合并,就断去了我再购买 OnePlus 的欲望,虽然这两年里面一加 7 Pro 的系统还在更新,日常的修复补丁还是会在推送,但一个不再维护的系统实在无法让人安心地继续使用下去。在 YouTube 也已经非常多人开始质疑 OnePlus,包括 MKBHD , Linus ,虽然我没有遇到 Linus 视频中那么诡异的 BUG,但这么多年的使用中确实还是遇到过几次系统无响应的时候(有一次甚至是因为对 SD 卡读写频繁,而导致整个系统卡死的情况,因为使用 Syncthing 在局域网同步,直接以最高速度写 SD 卡导致)
Android 阵营的其他厂商,要么是在大陆水土不服的 Pixel,要么就是定价策略异常诡异的三星,而国内的华为,小米,OPPO,这些非常本地化的 OS,如果连浏览器关键字都要审查的系统,我是不敢用的。所以要不就是买小米刷欧版系统,要么就是直接用 Oxgyen OS。而 MIUI 系统,虽然用起来也能用,但就是在某些细节方面总会遇到一些不明不白的问题,就我周围人的使用经验来看,出现过相册选择不按照更新倒序排列,以至于发一个最新的照片需要翻页很久的情况;再比如系统粘贴板在某些应用中就是会失效,比如在微信中复制的内容,在淘宝中无法粘贴;再比如这个 下拉通知栏 中的音乐播放器,
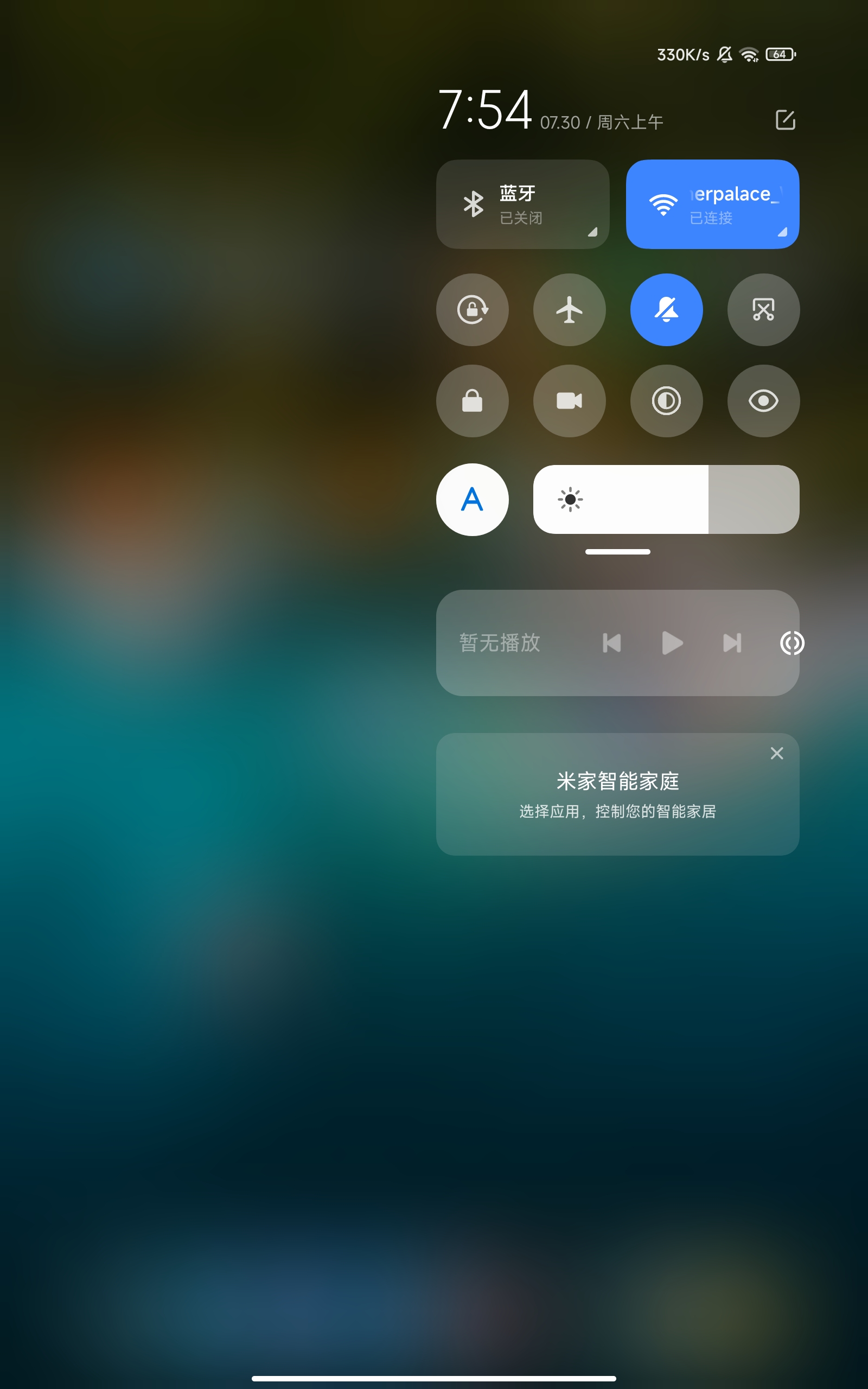
这个这么明显的设计问题,让我这个强迫症患者始终无法接受。
MIUI 这些问题虽然都不大吧,但总是会让我不开心。而我对国内厂商那种堆砌硬件而完全不顾外观设计的行为也非常不满意,为了画质上一点点的提升,而让整个后备突出一大块的摄像头设计,是完全看不下去的。

不过还好,每年出的机型层出不穷,至少还有一些没有那么激进。小米 12 就还可以。

原本这一节的标题起的是「为何离开 Android 阵营」,但我想一想其实我是选择了放弃 OnePlus,Android 目前还是无法离开的,即使选择了 iPhone,但还是会很长一段时间内还依然在这个地方用到 Android,电子墨水屏的 Boox Note 2 就还是 Android 系统。
为何切换到了 iOS
过去几年里面,我已经把我产生的数据和特定的操作系统隔离了,我可以非常快速地迁移到另外一个平台而不用担心数据安全的问题。而这些年的发展又使得两个系统的操作习惯越来越贴近,我使用的大部分的应用,如果去掉状态栏和底部导航,几乎是没有办法区分是运行在 Android 还是 iOS 的。所以我还是可以无痛的切换到 iOS,登录系统账号,然后在 Mail 中登录 Google 账号,通讯录,邮件等等都回来了。装上 Bitwarden,装上应用登录账号,基本上立马就能上手使用。
原本我是想在这里提一下 iOS 的稳定性和易用性的,然而我想起了我当时为什么弃用 iPhone 7,就是因为更新系统之后不知为何应用总是会 闪退 ,重置系统,删除账号等等很多方法都试过无果。故放弃。我对 iOS 的态度一直是观望态度,所以如果是日常使用的机器,我只会升级稳定版本。并且会在推送更新很久一段时间之后再升级。
应用选择心路历程
今天早上翻看当时 那篇记录 ,很有趣的是,里面提到了应用的迁移,到 2022 年,我几乎把当时用的应用全部都替换了一遍:
除了 Google Photos 还继续在使用,但也仅作为备份中的一份存在,原始文档还是会备份到 NAS 中。
设置
下面按照 Settings 中的顺序记录一下设置。
Notifications Scheduled Summary
设定通知摘要,现在的应用有些时候会发送大量无效的通知,当然这个时候我就会选择关闭通知,但是也有一些应用通知介于非常有用和不需要那么即时去处理的,那么就可以使用 iOS 这个 Scheduled Summary (定时推送通知摘要)功能,打开这个功能之后 iOS 会收纳非紧急通知,在方便的时候以摘要形式接收。
Turn on Headphone Safety
在 Sounds & Haptics -> Headphone Safety 中打开耳机通知和降低高音量。在嘈杂的环境中降低声音的分贝保护听力。
Turn off background App refresh
在 General -> Backgroud App Refresh 中根据应用关闭后台刷新,节省电量。
Turn off Tracking
在 Privacy -> Tracking ,关闭请求跟踪。
App 无法跟踪使用痕迹。
Turn off Apple Advertising
在 Privacy -> Apple Advertising 关闭 Apple 个性化广告。这个只是减少了 Apple 推送和用户相关的广告,但是 Apple 在能推送广告的时候还是会推送的。
Back Tap
在 Settings-> Accessibility -> Touch -> Back Tap 中可以设置双击或三击 iPhone 后备执行的动作。这里面有丰富的动作可以设置,比如打开通知栏,打开相机,截图,设置静音,锁定屏幕。
我个人的设定
- 双击:通知栏
- 三击:打开相机
设置小鹤双拼
在输入法中选择双拼方案,小鹤双拼
Bitwarden
安装的第一个应用,密码管理器。有了他才能在之后的应用登录的时候非常顺畅。
法国大革命前夕的舆论与谣言 读书笔记
怎么知道的这一本书
在疫情的初期,我非常厌恶一个词「辟谣」,原本这是一个非常正面的词语,用「正确」的事实来反驳谣言。而事实是,大量使用这个词的行政机构,把「辟谣」作为了一个收束话语权的工具,造成了社会只有一家之言。而这一家之言在大部分的情况下,也并不是事实。这就造成了社会上大量民众认知的失调。
至今为止,当我听到上面的这一段播报的时候也还是会不寒而栗。
当我不断被「谣言」,「辟谣」这些词汇轰炸的时候,在豆瓣上刚好看到了这一本叫做《法国大革命前夕的舆论与谣言》的书,很少有书能够在名字上如此贴近现实,就把他加入了待看列表。
什么是谣言
什么是谣言?英文是 rumour,牛津词典的解释是:
a piece of information, or a story, that people talk about, but that may not be true.
这里可以看到 may not be true,当然谣言是没有事实依据的传闻,但谣言之所以是谣言,是人们并没有足够的事实来佐证自己,只能道听途说,这其中必然可能产生错误,但禁止谣言,甚至禁止民众出声,那便是不对的。
[[密尔]] 在 [[论自由]] 中对压制思想和言论自由有如下的探讨,大致可以分成三种情况:
- 被压制的言论可能是一个正确的意见,那么人类就失去了一个获得真理的机会
- 被压制的可能是一个完全错误、荒谬的意见,如此,人类也可能失去一个机会,即从真理和错误冲突中产生出对于真理的更加清楚的认识和印象
- 大部分情况下,被压制的言论可能部分是真理,部分是谬误,压制者所持有的观点也部分真理,部分错误,如此,压制自由就会导致既丧失获得真理的机会,又失去在错误冲突中完善真理的机会
法国学者让·诺埃尔•卡普费雷对谣言的论述可以帮助我们思考谣言的根本性质。
- 由于害怕谣言而控制言论,正是产生谣言的重要根源之一;
- 你可能不会相信谣言,但谣言会使你产生怀疑;
- “虚假”的谣言是有根据的谣言必须付出的代价;
- 谣言是不受控制的,因而意味着有可能接近秘密和找到被掩盖的事实;
在《谣言:世界最古老的传媒》一书中,作者提出,只有不受监控、约束和强迫的信息交流才是真实的交流,哪怕其可靠性会受到影响。1
关于书名
在看到澎湃的这一篇 文章 ,我才知道我被这个中文书名翻译给误导了。原名是「Dire et mal dire: L’opinion Publique au XVIIIe Siècle」,翻译成 18 世纪的舆论是比较准确。澎湃进一步补充了,这一本书不是一本揭示舆论和谣言造成法国大革命的书,二者之间并不是简单的因果关系。
关于作者
阿莱特·法尔热从事法国社会史研究,关注 18 世纪法国民众身份,两性关系和历史书写等问题。
几句话总结书的内容
作者通过法国革命前(18 实际)的大量舆论资料(编年史、报刊、回忆录、警方笔录、大量的手写新闻,还有巴士底狱的档案),为我们勾画了革命前夕法国的舆论背景,为我们了解法国大革命的起源具有重大参考价值。
整本书分为三个部分,第一部分整理了日记、报纸和警方记录;第二部分分析了谣言的形式和动机;第三部分则是梳理了在 1661 年到 1775 年之前反对国王的言论和巴士底狱的相关档案。
作者通过翔实的资料发现在 18 世纪中叶,巴黎民众在舆论和谣言的环境中逐渐发展起对公共政治的关心,以及对表达意见和观点的权力的渴望。
启发或想法
疫情一晃已经三年过去了,当前国内的舆论环境只能说比疫情前更糟糕,每当有「大事」发生再听不到从各个角度发出的声音,徐州八孩被铁链所在家中的悲剧从发生到消沉,很难相信竟然只有官方的通告,竟然没有一家媒体去报道她的近况;唐山被打女孩,那家火锅店主,竟然连谣言都已经不存在。在 18 世纪人们尚能通过手抄新闻的方式来传播信息,而如今自诩为信息时代的我们,甚至连关键字都无法发出。
就像作者在书中所写的那样,在「在这些舆论和谣言中,人民开始有了一种意识,了解政治的要求是合法的,对政治的知情权和批判权是必要的(284 页)」,尤其在涉及到公共事务时,人们不断地提出诉求,他们认为说话不仅仅是他们的能力,更应该是一项亟待确立的合法权利。
谁应该看这本书
- 所有人
-
卡普费雷《谣言:世界最古老的传媒》,郑若麟译,上海人民出版社,2008 年 12 月 ↩
使用 glab 提交 Merge Request
glab 是一款使用 Go 语言实现的和 GitLab 实例交互的命令行工具。
之前是在 GitHub 上开发,但在 2022 年 11 月 22 之后,被 GitLab 官方采用,变成了官方支持的 cli 工具。
Installation
macOS & Linux 使用 Homebrew:
brew install glab
config
配置文件的地址在本地 ~/.config/glab-cli/。
❯ cat .config/glab-cli/config.yml
# What protocol to use when performing git operations. Supported values: ssh, https
git_protocol: https
# What editor glab should run when creating issues, merge requests, etc. This is a global config that cannot be overridden by hostname.
editor:
# What browser glab should run when opening links. This is a global config that cannot be overridden by hostname.
browser:
# Set your desired markdown renderer style. Available options are [dark, light, notty] or set a custom style. Refer to https://github.com/charmbracelet/glamour#styles
glamour_style: dark
# Allow glab to automatically check for updates and notify you when there are new updates
check_update: false
# Whether or not to display hyperlink escapes when listing things like issues or MRs
display_hyperlinks: false
# configuration specific for gitlab instances
hosts:
gitlab.com:
# What protocol to use to access the api endpoint. Supported values: http, https
api_protocol: https
# Configure host for api endpoint, defaults to the host itself
api_host: gitlab.com
# Your GitLab access token. Get an access token at https://gitlab.com/-/profile/personal_access_tokens
token:
# Default GitLab hostname to use
gitlab_host:
token: glpxxx
apt_host: gitlab_host
git_protocol: https
api_protocol: https
user: gitlab_username
host: gitlab.com
附加填充里面的 token 等信息即可。
环境变量
GITLAB_URL=
# or GITLAB_HOST=
GITLAB_TOKEN=
zsh completion
glab completion -s zsh > /path/to/zsh/completion
可以通过 echo $FPATH 来查看本机 Zsh 的 completion 文件路径。
merge requests
创建 Merge Request:
glab mr create -a username -t "fix something"
glab mr create --autofill --labels bugfix
glab mr create --squash-before-merge --remove-source-branch -a username -t "feat: message"
合并
glab mr merge 123
glab mr note -m "needs to do before it can be merged" branch-foo
同意:
glab mr approve {id | branch} [flags]
glab mr approve 234
glab mr approve 234 456
glab mr approve branch-1
glab mr approve branch-1 branch-2
reference
[[2019-06-20-gitlab-cli-merge-request]]
Netdata outbound_packets_dropped_ratio 告警
一直使用 Netdata 来作为 VPS 的监控,配合 Netdata Cloud 来作为监控面板体验一直都不错。不过最近有一台机器经常发送邮件告警:
outbound_packets_dropped_ratio
看这个告警一头雾水,虽然每个词都懂,但就是不知道表示的什么含义。所以搜罗各种资料学习一下。
什么是 outbound packets dropped ratio
详细的解释 Netdata 也给了出来:
Details: ratio of outbound dropped packets for the network interface venet0 over the last 10 minutes
过去 10 分钟内网卡 venet0 出站的流量丢包率。
那具体什么是 dropped packets 呢?在 Linux 下有很多原因会出现丢包,有可能是网络不稳提,或者网络拥堵,或者应用无法处理负载。
Linux 下显示网络接口的 dropped packet
❯ sudo netstat -i
Kernel Interface table
Iface MTU RX-OK RX-ERR RX-DRP RX-OVR TX-OK TX-ERR TX-DRP TX-OVR Flg
br-c834d 1500 7024713 0 0 0 5439423 0 0 0 BMU
br-f28aa 1500 446015 0 0 0 7656772 0 0 0 BMRU
br-f50ea 1500 5779300 0 0 0 6093954 0 0 0 BMRU
docker0 1500 0 0 0 0 0 0 0 0 BMU
lo 65536 38808638 0 0 0 38808638 0 0 0 LRU
venet0 1500 78213871 0 0 0 114697804 0 25737 0 BOPRU
venet0:0 1500 - no statistics available - BOPRU
vethd37c 1500 151555 0 0 0 209478 0 0 0 BMRU
vethe8b7 1500 8254 0 0 0 134561 0 0 0 BMRU
可以看到图中 venet0 这块网卡在 TX-DRP 上确实是有一定的丢包。
显示网卡的统计信息:
netstat -s
# 显示 tcp
netstat -s -t
# 显示 udp
netstat -s -u
netstat -s 的结果
Ip:
Forwarding: 1 //开启转发
31 total packets received //总收包数
0 forwarded //转发包数
0 incoming packets discarded //接收丢包数
25 incoming packets delivered //接收的数据包数
15 requests sent out //发出的数据包数
Icmp:
0 ICMP messages received //收到的ICMP包数
0 input ICMP message failed //收到ICMP失败数
ICMP input histogram:
0 ICMP messages sent //ICMP发送数
0 ICMP messages failed //ICMP失败数
ICMP output histogram:
Tcp:
0 active connection openings //主动连接数
0 passive connection openings //被动连接数
11 failed connection attempts //失败连接尝试数
0 connection resets received //接收的连接重置数
0 connections established //建立连接数
25 segments received //已接收报文数
21 segments sent out //已发送报文数
4 segments retransmitted //重传报文数
0 bad segments received //错误报文数
0 resets sent //发出的连接重置数
Udp:
0 packets received
...
TcpExt:
11 resets received for embryonic SYN_RECV sockets //半连接重置数
0 packet headers predicted
TCPTimeouts: 7 //超时数
TCPSynRetrans: 4 //SYN重传数
或者可以使用 ip 命令:
❯ ip -s link show venet0
2: venet0: <BROADCAST,POINTOPOINT,NOARP,UP,LOWER_UP> mtu 1500 qdisc noqueue state UNKNOWN mode DEFAULT group default
link/void
RX: bytes packets errors dropped overrun mcast
30619319736 78217051 0 0 0 0
TX: bytes packets errors dropped carrier collsns
32292008558 114701118 0 25738 0 0
Why does linux drop packets?
为了找出 Linux 服务器为什么 drop packets 可以借助 dropwatch。这个工具可以用来诊断 Linux networking stack 的问题,主要是查看协议栈丢包问题。
dropwatch
安装必要的工具:
sudo apt-get install libpcap-dev libnl-3-dev libnl-genl-3-dev binutils-dev libreadline6-dev autoconf libtool pkg-config build-essential
安装完之后执行 libtoolize,这会拷贝,连接必要的脚本,包括 ltmain.sh 。
然后手动编译:
git clone https://github.com/nhorman/dropwatch
cd dropwatch
./autogen.sh
./configure
make
make install
如何修改告警策略
因为我是用 docker 安装,所以需要进入 netdata 容器:
docker exec -it netdata /bin/sh
然后执行:
/etc/netdata/edit-config health.d/net.conf
其中的第 107 行即可。
reference
工程代码挑战网站 CodeWars 使用体验
CodeWars 是一个面向工程的代码挑战网站。不同于 [[LeetCode]] 侧重于考察算法,CodeWars 更注重与工程代码,提供了基础的单元测试,以及不同语言的实现。
相较于 LeetCode CodeWars 上面的问题相对比较直接,有些甚至可以用来学习一些编程语言的特性。和 LeetCode 一样带有讨论版,可以通过讨论版来学习。
适合的场景
- 学习新一门新语言,通过完成题目来熟悉基础的语法
- 想通过解题来了解语言的特性,比如 Java 中 stream
CodeWars 中也包含一些基础的算法,随着 Rank 越来越高也会有比较难的题目。
不同的模式
在注册进入 CodeWars 之后,会让用户选择不同的模式。
- Fundamentals
- Rank Up
- Practice and Repeat
- Beta
- Random
基础,升级,练习,Beta,随机。可以根据自己的需求选择。
总结
如果看完上面的介绍你觉得 CodeWars 不错的话,可以点击 这里 来注册。如果你觉得又可以分享的解题思路,也可以点个 关注 一起来讨论。
Eu.org 免费域名申请
eu.org 是欧盟组织下面的域名,EU 代表欧盟,Paul Mockapetris 在 1996 年的 9-10 月份创建了这个域名的 DNS 服务器。现在对个人和组织是免费注册的。
“EU.org, free domain names since 1996”。
eu.org 是 Google 认可的顶级域名。
优点:
- 历史悠久;
- 支持 NS 记录,意味着支持所有域名记录;
- 稳定,可长期使用;
- 没有任何限制
缺点:
eu.org 在国内使用 http 会被被强行重置,配合 HTTPS 才可正常访问。
注册账号
申请页面 https://nic.eu.org/arf/ 注册账号,验证邮箱。
申请域名
点击 New Domain 申请域名。
- 输入想要注册的域名,包括后缀
- 填写地址
- 需要提前添加 DNS 服务器,需要把准备申请的域名添加
在申请域名的时候需要提前填写 DNS 信息,但是 Cloudflare 不能提前添加未注册的域名,所以不能用 Cloudflare。
这里可以使用:
- https://dns.he.net/
- dns.com
- dnspod
Hurricane Electric Hosted DNS(HE) NS Records:
- ns1.he.net
- ns2.he.net
- ns3.he.net
- ns4.he.net
- ns5.he.net
DNSPOD 的 NS Record 一般都是 XXX.dnspod.com
之后 EU.org 会开始验证 NS 记录。如果没有问题最后的日志会是 done。
---- Servers and domain names check
Getting IP for PHIL.NS.CLOUDFLARE.COM: 108.162.193.137 172.64.33.137 173.245.59.137
Getting IP for PHIL.NS.CLOUDFLARE.COM: 2803:f800:50::6ca2:c189 2606:4700:58::adf5:3b89 2a06:98c1:50::ac40:2189
Getting IP for VERA.NS.CLOUDFLARE.COM: 172.64.32.147 108.162.192.147 173.245.58.147
Getting IP for VERA.NS.CLOUDFLARE.COM: 2803:f800:50::6ca2:c093 2a06:98c1:50::ac40:2093 2606:4700:50::adf5:3a93
No error, storing for validation...
Saved as request 202303xxxxxxxx-arf-3xxxx
Done
这个过程的时间不确定,可能会是 1 天,也可能好几个星期,最后注册邮箱中会收到 EU.org 发过来的邮件,标题一般是 request [20210906172103-arf-xxxx] (domain test.EU.ORG) accepted,这表示域名注册成功了。
中途遇到的问题
Eu.org 在验证 NS 的过程中可能会出现如下错误:
SOA from NS1.HE.NET at 216.218.130.2: Error: Answer not authoritative (148.835 ms)
这个时候注意在前面选项 Name Servers 中选择 server names 单选项。
将 eu.org 域名添加到 Cloudflare
当 eu.org 域名申请完毕,可以将域名添加到 Cloudflare 管理。
首先需要在 eu.org 管理后台中修改域名的 nameservers 修改成 Cloudflare 的 NS 地址。
通常是:
- phil.ns.cloudflare.com
- vera.ns.cloudflare.com
这两个地址可以在 Cloudflare 后台添加域名之后获得。
在 Cloudflare 添加新申请的域名,如果添加的时候提示:
eu.org is not a registered domain
或者提示这个域名没有注册,就等待一下 EU.org 刷新 WHOIS,然后等待一会儿再尝试添加。
文章分类
最近文章
- 从 Buffer 消费图学习 CCPM 项目管理方法 CCPM(Critical Chain Project Management)中文叫做关键链项目管理方法,是 Eliyahu M. Goldratt 在其著作 Critical Chain 中踢出来的项目管理方法,它侧重于项目执行所需要的资源,通过识别和管理项目关键链的方法来有效的监控项目工期,以及提高项目交付率。
- AI Shell 让 AI 在命令行下提供 Shell 命令 AI Shell 是一款在命令行下的 AI 自动补全工具,当你想要实现一个功能,敲一大段命令又记不住的时候,使用自然语言让 AI 给你生成一个可执行的命令,然后确认之后执行。
- 最棒的 Navidrome 音乐客户端 Sonixd(Feishin) Sonixd 是一款跨平台的音乐播放器,可以使用 [[Subsonic API]],兼容 Jellyfin,[[Navidrome]],Airsonic,Airsonic-Advanced,Gonic,Astiga 等等服务端。 Sonixd 是一款跨平台的音乐播放器,可以使用 [[Subsonic API]],兼容 Jellyfin,[[Navidrome]],Airsonic,Airsonic-Advanced,Gonic,Astiga 等等服务端。
- 中心化加密货币交易所 Gate 注册以及认证 Gate.io 是一个中心化的加密货币交易所。Gate 中文通常被称为「芝麻开门」,Gate 创立于 2013 年,前身是比特儿,是一家致力于安全、稳定的数字货币交易所,支持超过 1600 种数字货币的交易,提供超过 2700 个交易对。
- 不重启的情况下重新加载 rTorrent 配置文件 因为我在 Screen 下使用 rTorrent,最近经常调试修改 rtorrent.rc 配置文件,所以想要找一个方法可以在不重启 rTorrent 的情况重新加载配置文件,网上调查了一下之后发现原来挺简单的。