C++ 解析JSON
因项目需求,需要使用 C++ 解析 JSON。
RapidJSON
第一种方法,使用 RapidJSON 可以方便的用来生成或者解析 JSON。
项目地址:https://github.com/miloyip/rapidjson
RapidJSON 是只有头文件的 C++ 库。使用时只需要把 include/rapidjson 复制到项目目录中即可。
类似如下的JSON,其中包括Object,包括Array,掌握解析该JSON,基本 RapidJSON 解析可掌握:
{
"ret": "101",
"error": [
{
"errortype": "A0001",
"errorstroke": {
"0": "0.2",
"1": "0.3"
}
},
{
"errortype": "A0021",
"errorstroke": {
"0": "0.2",
"1": "0.3"
}
}
]
}
代码如下:
#include <iostream>
#include <vector>
#include <string>
#include "rapidjson/document.h"
#include "rapidjson/writer.h"
#include "rapidjson/stringbuffer.h"
using namespace rapidjson;
using namespace std;
int main() {
string ret =
"{\"ret\":\"101\",\"error\":[{\"errortype\":\"A0001\",\"errorstroke\":{\"0\":\"0.2\",\"1\":\"0.3\"}},{\"errortype\":\"A0021\",\"errorstroke\":{\"0\":\"0.2\",\"1\":\"0.3\"}}]}";
rapidjson::Document doc;
doc.Parse<kParseDefaultFlags>(ret.c_str());
if (doc.HasMember("ret")) {
string retjson = doc["ret"].GetString();
for (unsigned i = 0; i < retjson.length(); ++i) {
cout << retjson.at(i) << " ";
}
}
cout << endl;
if (doc.HasMember("error")) {
const Value & errorjson = doc["error"];
for (SizeType i = 0; i < errorjson.Size(); ++i) {
// 或者这里可以换用一种遍历使用 Value::ConstValueIterator
// http://rapidjson.org/md_doc_tutorial.html#QueryArray
if (errorjson[i].HasMember("errortype")) {
string errortype = errorjson[i]["errortype"].GetString();
cout << "errortype: " << errortype << endl;
}
if (errorjson[i].HasMember("errorstroke")) {
const Value & errorstroke = errorjson[i]["errorstroke"];
cout << "errorstroke" << endl;
for (Value::ConstMemberIterator iter = errorstroke.MemberBegin();iter != errorstroke.MemberEnd(); ++iter) {
cout << iter->name.GetString() << ": " << iter->value.GetString() << endl;
}
}
}
}
return 0;
}
关于 RapidJSON 的更多内容可以参考官网。
boost property_tree
使用 boost 库中的 property_tree 解析如下:
/*
first config your project to include /usr/local/include
second link lib /usr/local/lib
*/
#include <iostream>
#include <boost/property_tree/ptree.hpp>
#include <boost/property_tree/json_parser.hpp>
#include <boost/foreach.hpp>
#include <string>
using namespace boost::property_tree;
int main(int argc, const char * argv[]) {
std::string str_json = "{\"ret\":\"101\",\"error\":[{\"errortype\":\"A0001\",\"errorstroke\":{\"0\":\"0.2\",\"1\":\"0.3\"}},{\"errortype\":\"A0021\",\"errorstroke\":{\"0\":\"0.2\",\"1\":\"0.3\"}}]}";
ptree pt; //define property_tree object
std::stringstream ss(str_json);
try {
read_json(ss, pt); //parse json
} catch (ptree_error & e) {
return 1;
}
std::cout << pt.get<std::string>("ret") << std::endl;
ptree errortype = pt.get_child("error"); // get_child to get errors
// first way
for (boost::property_tree::ptree::iterator it = errortype.begin(); it != errortype.end(); ++it) {
std::cout << it->first;
std::cout << it->second.get<std::string>("errortype") << std::endl;
ptree errorstroke = it->second.get_child("errorstroke");
for (ptree::iterator iter = errorstroke.begin(); iter != errorstroke.end(); ++iter) {
std::string key = iter->first;
std::cout << iter->first << std::endl;
std::cout << iter->second.data() << std::endl;
}
}
// second way: using boost foreach feature
// BOOST_FOREACH(ptree::value_type &v, errortype){
// ptree& childparse = v.second;
// std::cout << childparse.get<std::string>("errortype") << std::endl;
// ptree errorstroke = childparse.get_child("errorstroke");
// BOOST_FOREACH(ptree::value_type& w, errorstroke){
// std::cout << w.first << std::endl;
// std::cout << w.second.data() << std::endl;
// }
// }
/*
101
A0001
0
0.2
1
0.3
A0021
0
0.2
1
0.3
*/
return 0;
}
中国科技馆一日游
早上去的时候一大群熊孩子在外面排队吓得我差点想要放弃,其实后来才发现到的时候没有开馆,排了一会儿队就进去了,还是很快的。其实这个地方还只适合亲子去游玩,如果真的高中都毕业了,真的看到没有意思了,涉及到的一些物理,化学小道具都是课本上曾经存在过的实验。如果有机会未来带小孩来玩一玩还是挺不错的。
进门就能看到这只巨大的恐龙化石。

去的时候直接从顶层往下逛的,馆中走道还有不少奥运的雕塑。


在上几层物理展馆中还是有不少有趣的玩意儿的,没拍多少照片,让我驻足的有如下的傅科摆,曾经屋里课本上学单摆的时候有看到过。当然傅科摆也间接地证明了地球的自转。物理那块区域的电生磁,磁生电,光等等区都是挺有趣的。

古代计时工具—-日晷。


最后走的时候在一层见到了很多中国古代天文,地理,木工等等的仪器和小工具,给我印象深刻的就是这个鲁班锁,用6块切割好的木块能够拼接成如图的形状。

Goodbye Picasa
Google Photos 官网:http://googlephotos.blogspot.com/
Picasa Resources : https://sites.google.com/site/picasaresources/Home/Picasa-FAQ
这个网站整理了 Google Picasa Help Forum 中的很多问题,也解决了困惑我很久的问题,比如 新 Google Photos 中相册的排序问题,比如 Google Photos 中分享出去照片自定义大小的问题,比如 Picasa Web Album 关闭之后的问题。
总之有关从 Picasa 平稳迁移到 Google Photos 的很多问题基本都能找到解决方案。
还有一个 Top Contributor 自己的网站 : http://picasageeks.com/ 也是很棒,总结了各种经验。
虽然 Google 关闭 Picasa 来看,对长期使用 Picasa 的老用户来说是件悲痛的事情,就像当时 Google 关闭 Google Reader 一样。但是多少年过去了,可能新用户根本不知道曾经有一个 Google Reader 存在过。从公司的角度看 关闭 Picasa 一心 Google Photos 当然也无口厚非,集中一心把一款产品打造好。只是从 Picasa 到 Google Photos 走得太快,以至于 Picasa Web Album 很多很实际的功能 Google Photos 一个都没有。而 Google Photos 一直在宣传的功能 Picasa 却很早就就拥有。这里本不想多说却还是依然写了这么多。
转到 Google Photos 本身这个产品,如果是新用户并且是移动设备使用时长较多的话,它本身是一款非常棒的产品: 1. 全备份(日期排序) 2. 简单修图工具 3. 相册以及好用的分享工具。 单就这三点已经完全满足一个相册应该具备的功能了。而反过来真是因为在移动设备上的简单,以及没有对老用户的照顾,Google Photos 中的时间线,相册管理远远不及 Picasa。但是细想原本这两款产品针对的用户就是不一样的。
-
Picasa 这一款产品是一款云端相册,用来提供给用户分享照片,因此重在 Web ,以及相册管理
-
Google Photos 私人相册,云端相册,重在移动,重在备份,虽然也有分享功能却很弱。上面 Picasa Geeks 网站上有篇文章写得好,列举了 Google Photos 没有的功能。在 Web 上,缺乏排序功能,分享设置只有 Private 和 Public 两个选项,而 Picasa Web Album 有 Public,Limited(Anyone with link), Limited(Listed People), Private 四个选项,而这4个选项和 Google Drive 文件分享类似。希望 Google Photos 之后会把这些功能都添加上吧。
总之事情已经这样,结局无法改变,现在提前去适应一下 Google Photos 也好,不至于到时候慌乱。我关注的事情如下:
图片分享及直链
在之前的文章中我都是使用的 Picasa Web Album 分享出来的图片链接,Picasa 提供的免费无限图床真是赞到家,不仅没有流量限制,还能自定义大小。
比如下面两张照片,通过修改 s144-Ic42 参数就能够变换图片的大小,当然具体参数可以从这里 查到。最常用的可能就是改 s0 获得原图了吧。
{kind=link}
{kind=link}
在 Picasa 关闭之后获取直链成为一个问题,我在 StackOverflow 上面的提问也没有任何实质性的解决。不过在后来的使用过程中发现,将照片分享到 Google+ ,这时 Google 会产生一个直接的图片 URL,点击看图片,并右击复制图片链接,就可以获取和 Picasa 分享类似的链接。
相册及分享
这要从很久很久以前说起,我原先的照片管理一直依照相册来管理,比如今天可能拍了很多照片,我会以 日期-活动 ,例如 160311-Event 来命令相册然后通过合适的分享途径分享出去,如果我想使用某张照片到博客中,获取直链并添加到博客配图即可。可是在 Google+ Photos 时代,Google 就彻底搞乱了我的相册管理方法。Picasa 中被莫名其妙的添加了很多的相册。自此之后相册管理体系彻底崩溃,没有了清晰的相册管理,现在我已经不管相册了,按照 Google Photos 给我的时间流排布照片,适当的时候将图片添加到相册中。其他时候基本上放任 Google Photos 自己备份。
在 Google Photos App 中即使我想分享一个相册我首选的也是讲照片内容传到 Google+ ,并不会优先使用 Google Photos 的分享功能,所以至今为止,我的 Share 相册中也只有当时测试使用过的一个相册。
测试帖如上
关于容量
可能让我唯一开心一点的就是 Picasa 到 Google+ Photos 到 Google Photos 的容量变成了无限大。其实听到这个消息的时候,我的相册容量已经到到了10G,当时正愁怎么办呢。随之后面的改变就已经很吸引人了,从 Google+ 时代的 2048*2048 像素以下不算空间,到现在 Google Photos 的16MP 下不算空间,几乎已经是无限容量的节奏了,我手机最高像素也没这么大。。
最后的吐槽,真的不想管这个了,改来改去太累了。
排序算法
排序算法复习,插入排序,选择排序,冒泡排序,希尔排序,[[归并排序]],堆排序,快排。
关于排序算法的 stable 稳定性,排序保存原始数据顺序则稳定,否则不稳定。
关于原址排序,算法需要额外的空间计算或者保存数据, in-place sorting ,归并排序为非原址排序 not-in-place sorting。
关于时间复杂度,归并排序,堆排序,快排有相对较快的速度 O(n*log(n))
稳定性
排序前后两个相等的数的相对位置不变。
有一些排序算法天然是稳定的,比如 Insertion Sort, Merge Sort, Bubble Sort。
为什么需要有稳定性?
加入有一组英文名,包括 First Name 和 Last Name,要求先按照 Last Name(姓) 排序,然后按照 First Name (名) 排序,这个时候可以先排序 First Name (稳定或非稳定),然后按照稳定的排序算法排序 Last Name,这样就可以保证排序完成之后,就是最终的结果。
插入排序
每次取一个元素插入正确的位置,适合少量元素。对于未排序的数据,从已排序的序列中从后向前扫描,找到相应的位置插入,实现上通常使用 in-place 排序,只需要使用额外 O(1) 空间,但是因为插入正确的位置之后,需要反复移动已经排序的序列,为新元素提供插入空间,因而比较费时。
一般来说,插入排序都采用 in-place 在数组上实现。具体算法描述如下:
- 从第一个元素开始,该元素可以认为已经被排序
- 取出下一个元素,在已经排序的元素序列中从后向前扫描
- 如果该元素(已排序)大于新元素,将该元素移到下一位置
- 重复步骤 3,直到找到已排序的元素小于或者等于新元素的位置
- 将新元素插入到该位置后
- 重复步骤 2~5
Algorithm
for i = 2:n,
for (k = i; k > 1 and a[k] < a[k-1]; k--)
swap a[k,k-1]
→ invariant: a[1..i] is sorted
end
Java 版本:
static void insert_sort(int[] array) {
for(int i = 1; i < array.length; ++i) {
int cur = array[i];
for(int j = i - 1; j >= 0 && array[j] > cur; j--) {
array[j + 1] = array[j];
array[j] = cur;
}
}
}
Properties
- Stable
- O(1) extra space
- O(n^2^) comparisons and swaps
- Adaptive: O(n) time when nearly sorted
- Very low overhead
Example
list = [4,6,2,5,1,3,0,4,8,1,5,3,6]
# 升序
# 从第二个元素开始,每次循环将前 i 个元素排序
for i in range(1,len(list)):
value = list[i]
j = i-1
# 将第 i 个元素的位置腾出
while j >= 0 and list[j]>value:
list[j+1] = list[j]
j=j-1
# 在排完序的 list[0...i] 中将值插入合适位置
list[j+1]=value
# 降序
list = [4,6,2,5,1,3,0,4,8,1,5,3,6]
for i in range(len(list)-1, -1, -1):
value = list[i]
j=i+1
while j<len(list) and value < list[j]:
list[j-1] = list[j]
j=j+1
list[j-1]=value
print(list)
选择排序
每次选取数组中最小(或者最大)的元素,并将其与未排序数组中首元素交换,依次进行。
选择排序拥有最小的交换次数,适合交换元素开销比较大的情况。选择排序其他情况都比较低效。
Algorithm
for i = 1:n,
k = i
for j = i+1:n, if a[j] < a[k], k = j
→ invariant: a[k] smallest of a[i..n]
swap a[i,k]
→ invariant: a[1..i] in final position
end
Properties
- Not stable
- O(1) extra space
- Θ(n^2^) comparisons
- Θ(n) swaps
- Not adaptive
Example
list = [4,6,2,5,1,3,0,4,8,1,5,3,6]
for i in range(0,len(list)):
k = i
for k in range(i+1, len(list)):
# 没有完全按照定义写,不过这样交换的开销更大。
if list[k] < list[i]:
list[i], list[k] = list[k], list[i]
print(list)
Java 版:
static void selection_sort(int[] array) {
if(array.length <= 1) return;
for(int i = 0; i < array.length; i++) {
int smallest = i;
for(int j = i + 1; j < array.length; j++) {
if (array[j] < array[smallest]) {
smallest = j;
}
}
int temp = array[i];
array[i] = array[smallest];
array[smallest] = temp;
}
}
冒泡排序
[[冒泡排序]] 反复交换相邻未按次序排列的元素,一次循环之后最大的元素到数组最后。
Algorithm
for i = 1:n,
swapped = false
for j = n:i+1,
if a[j] < a[j-1],
swap a[j,j-1]
swapped = true
→ invariant: a[1..i] in final position
break if not swapped
end
Properties
- Stable
- O(1) extra space
- O(n^2^) comparisons and swaps
- Adaptive: O(n) when nearly sorted
Example
def bubble_sort_1(list):
for i in range(0, len(list)):
for j in range(1, len(list)-i):
if list[j-1] > list[j]:
list[j-1], list[j] = list[j], list[j-1]
def bubble_sort_2(list):
for i in range(0, len(list)):
swap = False
for j in range(len(list)-1, i, -1):
if list[j-1] > list[j]:
list[j-1], list[j] = list[j], list[j-1]
swap = True
if swap is False:
break
相较于第一种直接冒泡,设定标志优化冒泡。
Java 版
static void bubble_sort(int[] arr) {
int i, j, temp, len = arr.length;
for (i = 0; i < len - 1; i++)
for (j = 0; j < len - 1 - i; j++)
if (arr[j] > arr[j + 1]) {
temp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = temp;
}
}
希尔排序
分组插入排序,将数组拆分成若干子序列,由增量决定,分别进行直接插入排序,然后缩减增量,减少子序列,最后对全体元素进行插入排序。插入排序在基本有序的情况下效率最高。
Algorithm
h = 1
while h < n, h = 3*h + 1
while h > 0,
h = h / 3
for k = 1:h, insertion sort a[k:h:n]
→ invariant: each h-sub-array is sorted
end
Properties
- Not stable
- O(1) extra space
- O(n^3/2^) time as shown (see below)
- Adaptive: O(n·lg(n)) time when nearly sorted
Example
list = [4,6,2,5,1,3,0,4,8,1,5,3,6]
def insertion_sort(k,h,n):
"""
:param k: group count
:param h: step length
:param n: total
:return:
"""
for i in range(k+h, n, h):
value = list[i]
j = i-h
while j >= 0 and list[j]>value:
list[j+h] = list[j]
j=j-h
list[j+h]=value
h = 1 # step length
while h < len(list):
h = 3*h +1
while h > 0:
h = int(h / 3)
for k in range(0, h): # devide into k groups
insertion_sort(k, h, len(list))
print(list)
归并排序
[[归并排序]] 是一个典型的分治算法,将数组分成两个子数组,在子数组中继续拆分,当小组只有一个数据时可认为有序,之后合并,所以重点就到了合并有序数组。
Algorithm
# split in half
m = n / 2
# recursive sorts
sort a[1..m]
sort a[m+1..n]
# merge sorted sub-arrays using temp array
b = copy of a[1..m]
i = 1, j = m+1, k = 1
while i <= m and j <= n,
a[k++] = (a[j] < b[i]) ? a[j++] : b[i++]
→ invariant: a[1..k] in final position
while i <= m,
a[k++] = b[i++]
→ invariant: a[1..k] in final position
Properties
- Stable
- Θ(n) extra space for arrays (as shown)
- Θ(lg(n)) extra space for linked lists
- Θ(n·lg(n)) time
- Not adaptive
- Does not require random access to data
Example
From wiki
from collections import deque
def merge_sort(lst):
if len(lst) <= 1:
return lst
def merge(left, right):
merged,left,right = deque(),deque(left),deque(right)
while left and right:
merged.append(left.popleft() if left[0] <= right[0] else right.popleft()) # deque popleft is also O(1)
merged.extend(right if right else left)
return list(merged)
middle = int(len(lst) // 2)
left = merge_sort(lst[:middle])
right = merge_sort(lst[middle:])
return merge(left, right)
堆排序
利用最大堆的性质,堆性质,子结点的值小于父节点的值。每次将根节点最大值取出,剩下元素进行最大堆调整,依次进行。
Algorithm
# heapify
for i = n/2:1, sink(a,i,n)
→ invariant: a[1,n] in heap order
# sortdown
for i = 1:n,
swap a[1,n-i+1]
sink(a,1,n-i)
→ invariant: a[n-i+1,n] in final position
end
# sink from i in a[1..n]
function sink(a,i,n):
# {lc,rc,mc} = {left,right,max} child index
lc = 2*i
if lc > n, return # no children
rc = lc + 1
mc = (rc > n) ? lc : (a[lc] > a[rc]) ? lc : rc
if a[i] >= a[mc], return # heap ordered
swap a[i,mc]
sink(a,mc,n)
Properties
- Not stable
- O(1) extra space (see discussion)
- O(n·lg(n)) time
- Not really adaptive
Example
def max_heapify(lst, i):
"""
下标为 i 的根节点调整为最大堆
:param lst:
:param i:
:return:
"""
l = 2 * i + 1
r = 2 * (i + 1)
if l < len(lst) and lst[l] > lst[i]:
largest = l
else:
largest = i
if r < len(lst) and lst[r] > lst[largest]:
largest = r
if largest != i:
lst[i], lst[largest] = lst[largest], lst[i]
max_heapify(lst, largest)
def build_max_heap(lst):
"""
建立最大堆
"""
for i in range((len(lst)-1)/2, 0, -1):
max_heapify(lst, i)
def heap_sort(lst):
build_max_heap(lst)
ret = []
for i in range(len(lst)-1, -1, -1):
ret.append(lst[0])
lst.remove(lst[0])
max_heapify(lst, 0)
return ret
L = [16, 4, 10, 14, 7, 9, 3, 2, 8, 1]
R = heap_sort(L)
print(R)
快排
从数列中挑出元素,将比挑出元素小的摆放到前面,大的放到后面,分区操作。然后递归地将小于挑出值的子数列和大于的子数列排序。
Algorithm
# choose pivot
swap a[1,rand(1,n)]
# 2-way partition
k = 1
for i = 2:n, if a[i] < a[1], swap a[++k,i]
swap a[1,k]
→ invariant: a[1..k-1] < a[k] <= a[k+1..n]
# recursive sorts
sort a[1..k-1]
sort a[k+1,n]
Properties
- Not stable
- O(lg(n)) extra space (see discussion)
- O(n^2^) time, but typically O(n·lg(n)) time
- Not adaptive
Example
list_demo = [2,8,7,1,3,5,6,4]
def partition(lst, p, r):
"""
划分
:param lst: 待排序数组
:param p: 起始下标,子数组第一个元素
:param r: 终止下标,子数组最后一个元素 r < len(lst)
:return: 划分结果下标
"""
if r >= len(lst) or p < 0:
return
x = lst[r]
i = p - 1
for j in range(p, r):
if lst[j] <= x:
i += 1
lst[i], lst[j] = lst[j], lst[i]
lst[i+1], lst[r] = lst[r], lst[i+1]
return i + 1
def quick_sort(lst, p, r):
if p < r:
q = partition(lst, p, r)
quick_sort(lst, p, q-1)
quick_sort(lst, q+1, r)
quick_sort(list_demo, 0, len(list_demo)-1)
print(list_demo)
分配排序
箱排序
箱排序也称桶排序 (Bucket Sort),其基本思想是:设置若干个箱子,依次扫描待排序的记录 R[0],R[1],…,R[n-1],把关键字等于 k 的记录全都装入到第 k 个箱子里(分配),然后按序号依次将各非空的箱子首尾连接起来(收集)。对于有限取值范围的数组来说非常有效,时间复杂度可以可达 O(n). 例如给人年龄排序,人的年龄只能在 0~100 多之间,不可能有人超过 200, 适用桶排序。
-
箱排序中,箱子的个数取决于关键字的取值范围。 若 R[0..n-1] 中关键字的取值范围是 0 到 m-1 的整数,则必须设置 m 个箱子。因此箱排序要求关键字的类型是有限类型,否则可能要无限个箱子。
-
箱子的类型应设计成链表为宜 一般情况下每个箱子中存放多少个关键字相同的记录是无法预料的,故箱子的类型应设计成链表为宜。
-
为保证排序是稳定的,分配过程中装箱及收集过程中的连接必须按先进先出原则进行。
桶排序的平均时间复杂度是线性的,O(n), 但是最坏的情况可能是 O(n^2)
基数排序
基数排序是非比较排序算法,算法的时间复杂度是 O(n). 相比于快速排序的 O(nlgn), 从表面上看具有不小的优势。但事实上可能有些出入,因为基数排序的 n 可能具有比较大的系数 K. 因此在具体的应用中,应首先对这个排序函数的效率进行评估。
基数排序的主要思路是,将所有待比较数值(注意,必须是正整数)统一为同样的数位长度,数位较短的数前面补零. 然后,从最低位开始,依次进行一次稳定排序。这样从最低位排序一直到最高位排序完成以后,数列就变成一个有序序列。
这个算法的难度在于分离数位,将分离出的数位代表原元素的代表,用作计数排序。但是分离数位不能脱离原来的数字,计数排序的结果,还是要移动原元素。
注意计数排序的元素数值与位置的联系,引申到基数排序的从元素得到中间值然后与位置的联系。
枚举排序
通常也被叫做秩排序 (Rank Sort) ,算法基本思想是:对每一个要排序的元素,统计小于它的所有元素的个数,从而得到该元素在整个序列中的位置,时间复杂度为 O(n^2)
reference
每天学习一个命令:nslookup 查询调试 DNS
最近配置路由器 pdnsd,经常需要调试 DNS 信息,就离不开调试工具了。 nslookup 用来查询 DNS 记录,查看域名解析是否正常,经常被用来在网络故障时诊断网络问题。
命令
在 Ubuntu 下可以使用如下命令安装:
sudo apt install dnsutils
格式:
nslookup [-option] [name | -] [server]
使用
nslookup 是一个查询 Internet domain name server 的工具,nslookup 有两种模式:
- interactive 交互模式
- non-interactive 非交互模式
交互模式
进入交互模式,总共有两种方法。
第一种方法,直接输入 nslookup 命令,不加任何参数,则直接进入交互模式,此时 nslookup 会连接到默认的域名服务器(即 /etc/resolv.conf 的第一个 dns 地址)。
第二种方法,是支持选定不同域名服务器的。需要设置第一个参数为“-”,然后第二个参数是设置要连接的域名服务器主机名或 IP 地址。
如果你直接在 nslookup 命令后加上所要查询的 IP 或主机名,那么就进入了非交互模式。当然,这个时候你也可以在第二个参数位置设置所要连接的域名服务器。
例子
交互模式下查询域名
nslookup
> www.douban.com
Server: 127.0.1.1 // 连接的 DNS 服务器
Address: 127.0.1.1#53 // DNS 服务器 IP 地址与端口
Non-authoritative answer: // 非权威答案,从连接的 DNS 服务器本地缓存中读取,非实际查询得到
Name: www.douban.com
Address: 115.182.201.6 // IP 地址
Name: www.douban.com
Address: 115.182.201.7
Name: www.douban.com
Address: 115.182.201.8
交互模式下更改 DNS
进入交互模式之后,使用 server dns-server 来改变上连 DNS 服务器地址
查询域名 IP 地址
nslookup www.douban.com [dns-server]
如果没有指定 dns-server,使用系统默认的 DNS 服务器。
中国美术馆一日游
本来打算去的自然博物馆,可无奈去官网看的时候已经没有预订票,于是就去了中国美术馆。北京来了快6年而似乎该去的博物馆都尚未能去,想接下来的时间里能不能用自己的脚都走遍,用自己的眼睛都看遍。借用网友的一句话,“不能也不敢说自己懂艺术,只是单纯的喜欢,喜欢美,喜欢不同的表达,喜欢安静的可以欣赏思想与灵感的地方”。上一次画画还要追溯到初中,近十年时间没有接触任何艺术,也没有接受任何艺术形式的熏陶。在最初进入的时候确实是一头雾水,幸而我们这一次去的时候正好是中华民族大团结全国美术作品展,至少还有一个主题让我们可以想象。虽然进门看到如此主旋律的主题有点失望,然而从一个展厅进到另一个展厅,除了进门见到的习大大有点恶心之外,渐渐就开始敬佩起这些画家。
喜欢画画的人可以经常上美术馆的官网看看,不定期的会举办一些展览。
下面是三幅震撼到我的画:

这原本是一副很大的画,这里的两位只是画的一小部分,记得画的左边还有一位在回眸,右边也还有两位。

远看真的像是一副照片,细节部分也是栩栩如生,近看脸部的文理,光影的处理着实让我震惊了。

被萌到的小狗,哈士奇?不认识。
其他令我印象深刻的画作:
塔吉克新娘 官网
美术馆馆藏作品链接
很遗憾,写这篇文章的时候中途忘记保存了,漏掉了一些内容,现在凭感觉补了一些,却再也找不到当时的感觉,虽然只仅仅相隔一天。由此可见随时保存的重要性了。
几道 C++ 问题
Question 6
Method overriding is key to the concept of Polymorphism. 覆盖是多态的核心 True
多态可以概括成“一个接口,多个方法”,运行时决定调用函数。C++ 多态利用虚函数实现,虚函数允许子类重新定义方法,子类重新定义方法的做法称为“覆盖”,或者重写。(直接覆盖成员函数和覆盖虚函数,只有重写了虚函数的才能算作是体现了C++ 多态性)
封装可以使得代码模块化,继承可以扩展已存在的代码,而多态的目的则是为了接口重用。也就是说,不论传递过来的究竟是那个类的对象,函数都能够通过同一个接口调用到适应各自对象的实现方法。
最常见的用法就是声明基类的指针,利用该指针指向任意一个子类对象,调用相应的虚函数,可以根据指向的子类的不同而实现不同的方法。如果没有使用虚函数的话,即没有利用C++多态性,则利用基类指针调用相应的函数的时候,将总被限制在基类函数本身,而无法调用到子类中被重写过的函数。因为没有多态性,函数调用的地址将是一定的,而固定的地址将始终调用到同一个函数,这就无法实现一个接口,多种方法的目的了。
#include <iostream>
using namespace std;
class A
{
public:
void foo()
{
printf("1\n");
}
virtual void fun()
{
printf("2\n");
}
};
class B : public A
{
public:
void foo()
{
printf("3\n");
}
void fun()
{
printf("4\n");
}
};
int main(void)
{
A a;
B b;
A *p = &a;
p->foo();
p->fun();
p = &b;
p->foo();
p->fun();
return 0;
}
输出
1 2
1 4
基类指针指向基类对象,调用基类函数;基类指针指向子类对象, p->foo() 指针是个基类指针,指向是一个固定偏移量的函数,因此此时指向的就只能是基类的foo()函数的代码了,因此输出的结果还是1。而p->fun() 指针是基类指针,指向的fun是一个虚函数,由于每个虚函数都有一个虚函数列表,此时p调用fun()并不是直接调用函数,而是通过虚函数列表找到相应的函数的地址,因此根据指向的对象不同,函数地址也将不同,这里将找到对应的子类的fun()函数的地址,因此输出的结果也会是子类的结果4。
上面例子,还有一种问法
B *ptr = (B *)&a; ptr->foo(); ptr->fun();
输出
3 2
从原理上来解释,由于B是子类指针,虽然被赋予了基类对象地址,但是ptr->foo()在调用的时候,由于地址偏移量固定,偏移量是子类对象的偏移量,于是即使在指向了一个基类对象的情况下,还是调用到了子类的函数,虽然可能从始到终都没有子类对象的实例化出现。而ptr->fun()的调用,可能还是因为C++多态性的原因,由于指向的是一个基类对象,通过虚函数列表的引用,找到了基类中fun()函数的地址,因此调用了基类的函数。由此可见多态性的强大,可以适应各种变化,不论指针是基类的还是子类的,都能找到正确的实现方法。
“隐藏”是指派生类的函数屏蔽了与其同名的基类函数,规则如下: (1)如果派生类的函数与基类的函数同名,但是参数不同。此时,不论有无virtual 关键字,基类的函数将被隐藏(注意别与重载混淆)。 (2)如果派生类的函数与基类的函数同名,并且参数也相同,但是基类函数没有virtual 关键字。此时,基类的函数被隐藏(注意别与覆盖混淆)。
纯虚函数,virtual ReturnType Function()= 0;
C++支持两种多态性:编译时多态性,运行时多态性。
- 编译时多态性:通过重载函数实现
- 运行时多态性:通过虚函数实现。
虚函数是在基类中被声明为virtual,并在派生类中重新定义的成员函数,可实现成员函数的动态覆盖(Override) 包含纯虚函数的类称为抽象类。由于抽象类包含了没有定义的纯虚函数,所以不能定义抽象类的对象。
Q16
Which objected oriented design concept is key to the factory design pattern?
Inheritance
Q23
Which of the following describe the C++ programming language?
Compiled Declarative
Q25
The friend keyword is used to grant access to private class members. True
- 友元函数:普通函数对一个访问某个类中的私有或保护成员。
- 友元类:类A中的成员函数访问类B中的私有或保护成员。
友元函数
friend <类型><友元函数名>(<参数表>);
友元函数只是一个普通函数,并不是该类的类成员函数,它可以在任何地方调用,友元函数中通过对象名来访问该类的私有或保护成员
#include <iostream>
using namespace std;
class Base{
public:
Base(int _data):data(_data){};
friend int getData(Base& _base);
private:
int data;
};
int getData(Base& _base){
return _base.data;
}
int main() {
Base b(2);
std::cout << getData(b) << endl;
return 0;
}
友元类
friend class <友元类名>;
友元类的声明在该类的声明中,而实现在该类外。
#include <iostream>
using namespace std;
class Base{
public:
Base(int _data):data(_data){};
friend class FClass;
private:
int data;
};
class FClass{
public:
int getData(Base _base){
return _base.data; // call friend class private data
}
};
int main() {
Base b(2);
FClass c;
cout << c.getData(b) << endl;
return 0;
}
Q38
Choose word or words to describe UML language.
- Picture
- Relational
- Interpreted
- Abstract
- None of the answers are correct.
只有 Picture 正确
The Unified Modeling Language (UML) is a general-purpose, developmental, modeling language in the field of software engineering, that is intended to provide a standard way to visualize the design of a system.
为啥没有 Relation 有点神奇~ UML 图能够看出类与类的关系的啊
Q40
Generalization is used by UML to describe Inheritance and the deriving of one class from another.
Generaliztion 是从属关系,可以表示继承,或者派生
http://www.uml-diagrams.org/generalization.html
Q44
#include <iostream>
void f0(int& sum){
sum = 3+2*7;
}
int main() {
int *p, sum = 0;
(*p)++;
sum = sum * 3;
f0(sum);
std::cout << sum << ",";
return 0;
}
(*p)++ 一行有问题
具体问题内容请看这里
切换 Linux 内核版本
Linux 内核是开源类 Unix 系统宏内核。仅仅一个内核并不是一套完整的操作系统。有一套基于 Linux 内核的完整操作系统叫作 Linux 操作系统。Kernel 是 Linux 系统的核心,主要负责硬件的支持。
Linux 内核提供了安全补丁, bugfix 和新特性。
Linux 内核在 GNU 通用公共许可证第 2 版之下发布。
Linux 的 Kernel 主要提供以下五个基本的功能 1:
- 硬件管理以及硬件的抽象
- 进程和线程的管理,以及之间的通信
- 内存的管理,包括虚拟内存管理以及内存空间的包含
- I/O 设备,包括文件系统,网络接口,串行接口 (Serial interfaces) 等等
- 设备基本功能,包括开启启动,关闭,计时器,多任务管理等等
修改启动内核版本需要谨慎,每一步在确认知道自己在做什么的情况下再操作。Linux 内核版本变更可能导致网络访问异常,声音异常,甚至是桌面环境无法启动。在安装和移除内核时,确保已经已经阅读过相关帮助,确保自己知道如何选择不同版本的内核,如何恢复之前的版本,以及如何检查 DKMS 状态。
Linux 内核版本号的意义
Linux 内核版本号由 3 组数字组成:第一个组数字。第二组数字。第三组数字
- 第一个组数字:目前发布的内核主版本。
- 第二个组数字:偶数表示稳定版本;奇数表示开发中版本。
- 第三个组数字:错误修补的次数。
查看内核版本
在 Linux 机器上执行如下命令查看当前正在使用的内核版本
uname -r
使用如下命令查看当前系统安装的内核版本
dpkg -l | grep linux-image
如果使用的是 Linux Mint 那么在 Update Manager 中,选择 View -> Linux Kernels 可以查看当前安装的版本和正在使用的版本,或者选择安装新的版本切换。
安装和卸载内核版本
sudo apt search linux-image
sudo apt install xxx
sudo apt-get purge xxx
选择内核版本
一个系统可以同时安装多个内核,但是运行时只能选择一个,当启动电脑时,在显示 GRUB 菜单时可以选择加载哪一个内核。(当只有一个系统安装时,GRUB 菜单可能被跳过,强制显示 GRUB 菜单可以在启动电脑时一直按住 Shift 按键)
在 Advanced options 选项中,可以选择系统上安装的内核版本,在启动时选择一个即可。
DKMS
DKMS 全称是 Dynamic Kernel Module Support,它可以帮我们维护内核外的这些驱动程序,在内核版本变动之后可以自动重新生成新的模块。
sudo apt-get install dkms
内核包含了所有的开源驱动,一般都可以正常工作,私有的驱动(DVIDIA,AMD,Broadcom… 等等)不包含在其中。这些私有驱动(proprietary drivers)需要在安装时手动编译到每一个内核中。这个操作可以用 dkms 来完成。如果私有驱动无法正常编译到内核中,可能导致启动异常,所以需要提前检查
dkms status
reference
-
《UNIX AND LINUX SYSTEM ADMINISTRATION HANDBOOK》第十一章 ↩
Nexus 6 刷机及电信 3G/4G 破解
adb and fastboot
从 Android 开发官网下载 Android SDK,从事过 Android 开发的应该知道 adb 和 fastboot 工具,在完整 SDK 中这两个工具在 platform-tools 文件夹下。如果想要方便的使用这两个工具,可以将文件路径加入到系统环境变量中,这样以后就可以在任何目录使用 adb 和 fastboot 命令。
flash factory image
救砖,或者在 recovery 下没有备份又无法开机的情况下只能刷回原厂镜像救砖机。因此折腾需谨慎,刷机前请一定使用 recovery 备份系统及数据。可以从 Google 官网下载镜像。
下载镜像
https://developers.google.com/android/nexus/images#shamu
解压之后应该会有如下文件
bootloader-shamu-moto-apq8084-71.15.img 2016/01/06 07:19 10,636,288
flash-all.bat 2016/01/06 07:19 985
flash-all.sh 2016/01/06 07:19 856
flash-base.sh 2016/01/06 07:19 814
image-shamu-mmb29q.zip 2016/01/06 07:19 1,009,825,337
radio-shamu-d4.01-9625-05.32+fsg-9625-02.109.img 2016/01/06 07:19 118,272,512
解锁bootloader
解锁 bootloader 会抹去手机一切内容,需谨慎,总之只需要一句命令
fastboot oem unlock
然后利用音量键及电源键来确认解锁 bootloader, 之后运行
fastboot reboot
重启手机。
刷镜像
- 关机并进入 fastboot 也就是 bootloader模式,在关机状态下,同时按住“电源键”+“音量下”
- 数据线连接手机与电脑,在驱动安装正确之后
- 执行 flash-all.bat (Windows 下) 或者 flash-all.sh (MAC或者 Linux 下)
- 等待执行完毕,手机恢复成出厂镜像
root
root 工具及教程来自 @Chainfire ,在此由衷的感谢他。
- 下载ZIP工具
- 解压文件,并将手机进入 bootloader/fastboot 模式
- 连接数据线,并运行 root-windows.bat (Windows 下)或者 chmod +x root-linux.sh 并运行 root-linux.sh (Linux下) Mac下同Linux
Recovery
第三方的 Recovery 有以下的功能:
- Wipe your phone’s data (Factory reset) and cache
- Make, restore and manage backups of your phone’s operating system and software
- Mount, unmount and format your phone’s internal as well as external storage partitions
- Install a custom ROM or application from a zip file to your phone
- Wipe Dalvik cache and battery statistics
- Make logs for error reporting and debugging
刷入 recovery
- 从官网 下载 Nexus 6 TWRP 的 recovery 文件
- 进入 bootloader/fastboot 模式
-
执行以下命令
fastboot flash recovery recovery.imgrecovery.img 即下载的 Recovery 镜像。
- 利用音量键选择 recovery ,点击电源键选择,可以进入 “Recovery Mode”.
安装完 recovery 之后就能够快速的备份系统,恢复出厂设置,恢复备份数据,刷入新ROM,刷入ZIP
kernel
一张图解释什么是 kernel
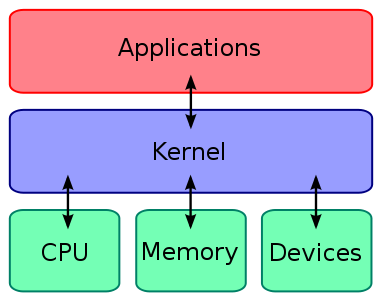
Nexus 6 第三方的 kernel 有很多选择 比如 franco.kernel,这里推荐 ElementalX,有如下功能
- Easy installation and setup with Aroma installer
- overclock/underclock CPU
- user voltage control
- Advance color control
- MultiROM support
- optional USB fastcharge
- optional sweep2wake and doubletap2wake
- optional sweep2sleep
- sound control
- init.d support
- NTFS r/w and exFAT support
- option to disable fsync
- adjustable vibration
- does not force encryption
安装 ElementalX kernel
- 从ElementalX 官网下载,并保存到手机
- 进入 Recovery Mode
- 刷入 ZIP ,选择下载的文件,安装
Nexus 6 破解电信3G/4G
6.0.1 (MMB29Q) 有效
下载文件,教程中需要用的软件及文件 https://yunpan.cn/cxCaHyqkKPwg9 提取码 db02
- DFS
- QPST
还有这里
- moto x qc diag interface - 64bit.zip
- carrier_policy.xml
具体步骤参考nexus6破解电信教程
简单来说破解4G步骤:
- 用QPTS工具里面的EFS Explorer, 添加/policyman/carrier_policy.xml,nexus6 默认没有这个文件
- 进入BP TOOLS模式,安装好后,必须确认好你的设备管理器 端口(COM和LPT)中BP驱动的端口号
- 从开始菜单中,打开QPST configuration
- 先点Ports标签,然后点Add New Prot 输入你的设备端口号
- 点StartClient菜单中的EFS Explorer选项
- 连接上手机后,在EFS 根目录创建policyman目录
- 把carrier_policy.xml(见附件)拖进policyman目录中
- 完成后重启手机
破解完成后请在手机拨号面板那输入 *#*#4636#*#* 看下首选网络是不是LTE/GSM/CDMA auto(prl)
参考
- http://forum.xda-developers.com/nexus-6/general/guide-flash-factory-images-nexus-6shamu-t2954008
- http://forum.xda-developers.com/showpost.php?p=56938530&postcount=1
- http://bbs.gfan.com/android-7828699-1-1.html
- http://m.anruan.com/view_7100.html
- http://bbs.gfan.com/forum.php?mod=viewthread&tid=7795111
- http://bbs.gfan.com/android-8085647-1-1.html
Linux 常用命令合集
部分内容为 《Linux 命令速查手册》读书记录。
系统
uname -a # 查看内核 / 操作系统 /CPU 信息
head -n 1 /etc/issue # 查看操作系统版本
cat /proc/cpuinfo # 查看 CPU 信息
hostname # 查看计算机名
lspci -tv # 列出所有 PCI 设备
lsusb -tv # 列出所有 USB 设备
lsmod # 列出加载的内核模块
env # 查看环境变量
资源
监视系统资源,包括跟踪正在运行的程序 (ps,top)终止进程(kill),列出打开的文件(lsof),报告系统内存占用(free),磁盘空间占用(df,du)等等。
ps aux # 查看系统正在运行的进程
ps -ef # 查看所有进程
ps f # 查看进程树
top # 实时显示进程状态
kill -9 PID # 终止正在运行的进程 -9 强制中断, -15 正常中止
lsof # 列出打开的文件
free -m # 查看内存使用量和交换区使用量
df -h # 查看各分区使用情况
du -sh 《目录名》 # 查看指定目录的大小
grep MemTotal /proc/meminfo # 查看内存总量
grep MemFree /proc/meminfo # 查看空闲内存量
uptime # 查看系统运行时间、用户数、负载
cat /proc/loadavg # 查看系统负载
磁盘和分区
mount | column -t # 查看挂接的分区状态
fdisk -l # 查看所有分区
swapon -s # 查看所有交换分区
hdparm -i /dev/hda # 查看磁盘参数(仅适用于 IDE 设备)
dmesg | grep IDE # 查看启动时 IDE 设备检测状况
网络
这里列举了常用和网络相关的命令,包括查看本地 IP(ifconfig),判断网络连通性(ping,traceroute) 等等。其中 ifconfig, iwconfig ,route 等等命令都有双重用途,不仅能够查看网络连接属性,也能够进行配置。
ifconfig # 查看所有网络接口的属性
ifup eth0 # 开启网络
ifdown eth0 # 关闭 eth0 网卡
iwconfig # 查看无线接口属性
iptables -L # 查看防火墙设置
ping # 网络连通性
route -n # 查看路由表
netstat -lntp # 查看所有监听端口
netstat -antp # 查看所有已经建立的连接
netstat -s # 查看网络统计信息
traceroute https://google.com # 显示数据包从计算机路由到指定的主机经过的每一步
mtr # traceroute 更好的代替
host # 查看网站 DNS 结果
dhclient -r eth0 # 使用 DHCP 获得新网络地址
mtr 使用介绍
用户
w # 查看活动用户
id 《用户名》 # 查看指定用户信息
last # 查看用户登录日志
cut -d: -f1 /etc/passwd # 查看系统所有用户
cut -d: -f1 /etc/group # 查看系统所有组
crontab -l # 查看当前用户的计划任务
服务
chkconfig --list # 列出所有系统服务
chkconfig --list | grep on # 列出所有启动的系统服务
文章分类
最近文章
- Glance 个人自定义 Dashboard Glance 是一个可以自行架设的个人 Dashboard 以及 RSS 订阅信息面板。
- Fileball 一款 iOS tvOS 上的媒体播放器及文件管理器 Fileball 是一款 iOS,tvOS 上的本地文件管理器,本地音乐播放器,本地视频播放器,以及文本编辑器,Fileball 可以在 iPhone,iPad,Apple TV 上使用。Fileball 可以连接网络共享,支持 SMB,FTP,SFTP,Synology,NFS,WebDAV 等,支持 Emby,Jellyfin 等,还可以连接百度网盘,Box,Dropbox,Google Drive,OneDrive,pCloud 等,可以作为 [[Infuse]] ,[[VidHub]] 等播放器的平替,高级版本价格也比较合适。Fileball 也支持 [[IPTV]]。
- 在日本申请入台证材料及在线提交注意事项 本文记录入台证办理的材料及提交手续,以及在使用线上提交系统的时候需要注意的点。入台证是中华民国台湾地区出入境许可证的俗称,所有进入台湾的人都需要申请此许可证。
- 从 Buffer 消费图学习 CCPM 项目管理方法 CCPM(Critical Chain Project Management)中文叫做关键链项目管理方法,是 Eliyahu M. Goldratt 在其著作 Critical Chain 中踢出来的项目管理方法,它侧重于项目执行所需要的资源,通过识别和管理项目关键链的方法来有效的监控项目工期,以及提高项目交付率。
- AI Shell 让 AI 在命令行下提供 Shell 命令 AI Shell 是一款在命令行下的 AI 自动补全工具,当你想要实现一个功能,敲一大段命令又记不住的时候,使用自然语言让 AI 给你生成一个可执行的命令,然后确认之后执行。