过去一年我在看 [[Agent]] 产品的时候,一个感受越来越强烈:真正难的往往不是“让模型会调用工具”,而是把一套能长期跑、能恢复、能接企业系统、还能管住权限的 agent 基础设施搭起来。很多团队一开始做 demo 很快,给 [[Claude]] 或别的模型加几个 tool,跑通一个 happy path 并不难;但一旦任务变成长时间执行、要操作代码、要调用外部服务、要给不同用户隔离凭据、要把中间状态可靠地保存下来,问题马上就从 Prompt 设计变成了系统设计。
所以我第一次看到 [[Anthropic]] 推出 Claude Managed Agents 的时候,注意力根本不在“又多了一个 agent API”,而是在它背后的判断:Anthropic 不想只给你一组低层原语,而是开始把 agent runtime 本身也做成托管服务。换句话说,它不是只让你“调用 Claude”,而是让你“托管一个会工作的 Claude agent”。如果你已经用过 [[Claude Code]]、自己手搓过 Tool Use,或者看过 [[Anthropic]] 之前那几篇关于 harness 和 long-running agent 的工程文章,这个方向其实非常顺。
这篇文章我想把 Claude Managed Agents 讲清楚:它到底是什么,和普通的 Tool Use 或 [[Agent SDK]] 有什么区别,核心能力在哪里,适合什么场景,以及如果你今天就想试一试,应该怎么上手。
Claude Managed Agents 是什么
用官方文档的话说,Claude Managed Agents 是 Claude Platform 上一套用来运行 long-horizon agents 的托管服务。这个定义里最关键的词其实不是 agent,而是 managed。因为它意味着你不再只是在 API 层拿到一个“会调用工具的模型”,而是拿到了一整套由 Anthropic 托管的 agent 运行时。
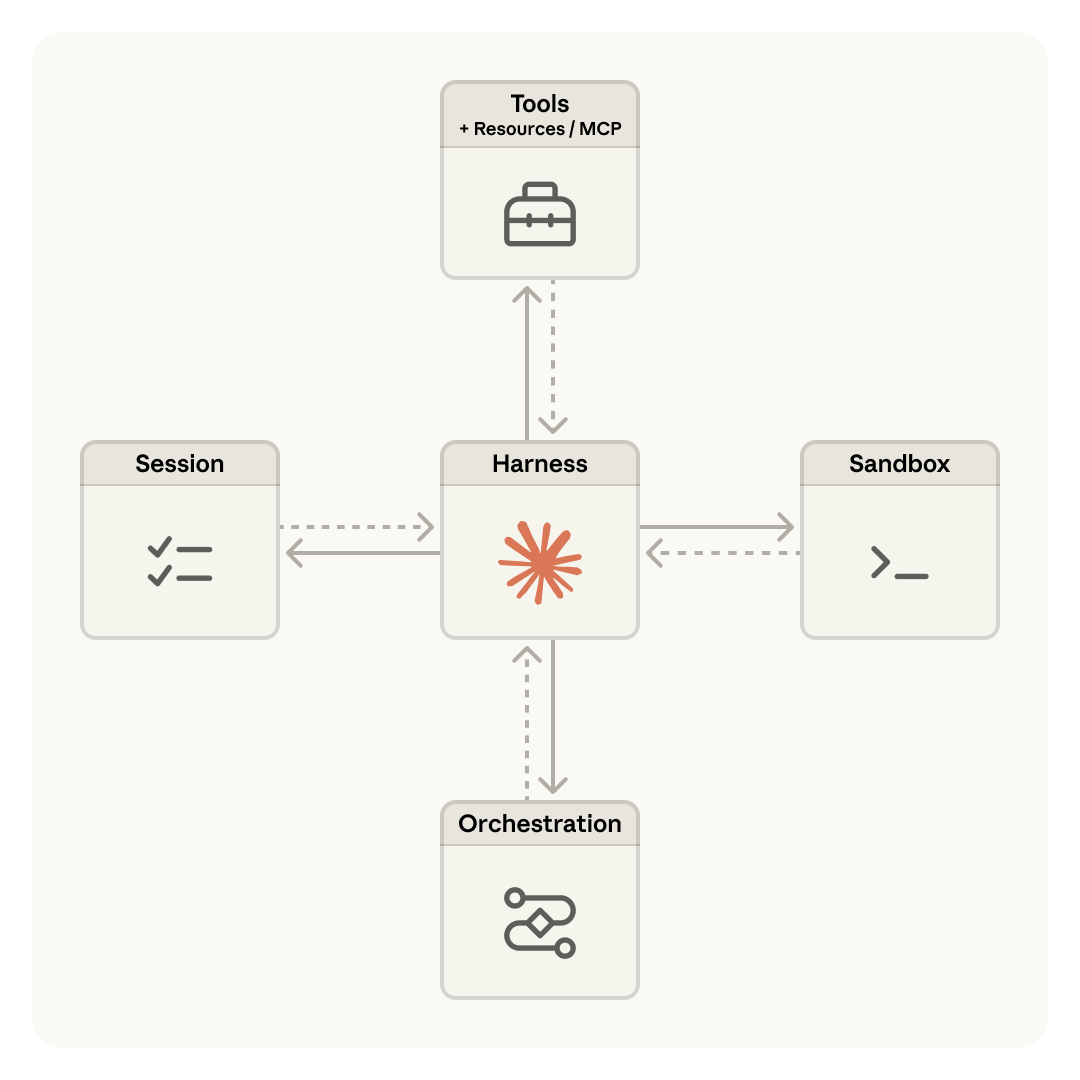
在官方 quickstart 里,Claude Managed Agents 把整套系统拆成四个核心概念。Agent 是配置本身,里面放模型、system prompt、工具、MCP servers 和 skills;Environment 是运行环境,也就是容器模板、依赖和网络配置;Session 是某个 agent 在特定 environment 里的实际运行实例;Events 则是你和 agent 之间流动的消息,包括用户输入、工具调用、状态变化和最终输出。这个拆分我觉得很重要,因为它把“配置”“环境”“运行”“事件流”分成了四层,而不是像很多简单 demo 那样全都糊在一段代码里。
如果你以前用的是普通的 Messages API tool use,你大概会很快理解两者的差别。普通 Tool Use 更像是给模型一组函数,剩下的 agent loop、上下文管理、工具执行、重试、状态持久化、容器生命周期这些事情,都还是你自己负责。Claude Managed Agents 则把这整层运行机制托管了起来。你定义 agent,创建 environment,启动 session,然后通过事件流和它交互。对我来说,这就是它最核心的产品定位。
它和 Tool Use、Agent SDK、Claude Code 分别是什么关系
我觉得理解 Claude Managed Agents,最容易卡住的点不是 API 怎么调,而是它到底处在 Anthropic 哪一层产品栈里。因为如果这个位置没想明白,后面你很容易把它误解成“Claude Code 的 API 版”,或者“只是 Tool Use 套了个壳”。
我的理解是这样的。最底层仍然是 [[Claude API]] 和 Tool Use,这一层给你模型和工具调用原语,灵活度最高,但基础设施也最靠自己。再往上是 [[Agent SDK]],它把本地 agent loop、权限、工具、流式输出这些事情封装得更顺手一些,适合代码优先、自己掌控运行时的开发方式。Claude Managed Agents 再往上一层,它不是只给库,而是直接托管 runtime,帮你管理 agent、environment、session、event stream、memory、vaults 这些运行组件。至于 [[Claude Code]],它更像 Anthropic 自己面向终端用户交付的一种现成 harness,工程博客里甚至明确写到,Claude Code 本身就是 Managed Agents 可以承载的一种优秀 harness。
所以如果要一句话区分:
- Tool Use 是原语
- Agent SDK 是本地开发框架
- Managed Agents 是托管运行平台
- Claude Code 是已经做好的成品交互层
我自己会把 Claude Managed Agents 理解成“Anthropic 开始把 agent 基础设施产品化”的标志。它不只是为了少写几行代码,而是为了让你不用自己养那一整套容易出问题的 harness。
Claude Managed Agents 解决的其实是哪些难题
Anthropic 官方工程博客有一篇很值得看的文章,题目叫《Scaling Managed Agents: Decoupling the brain from the hands》。这篇文章对我帮助很大,因为它没有把 Managed Agents 写成营销功能表,而是直接讲他们在做长时间运行 agent 时踩到的基础设施问题。
其中一个很重要的观点是,很多 harness 都在编码“模型现在做不到什么”。比如为了防止上下文太长而提前收尾,旧的 harness 可能会强行做 context reset;但随着模型变强,这些假设会过时,之前那些补丁式设计反而变成负担。于是 Anthropic 想做的是一组能比具体 harness 活得更久的稳定接口,而不是一套写死在某个时代模型能力上的脚手架。
他们最后抽象出的几个核心部件是 session、harness 和 sandbox。session 是 append-only 的事件日志,负责可靠存储发生过什么;harness 是调用 Claude、接工具、组织上下文的那一层大脑运行逻辑;sandbox 则是执行代码、编辑文件、跑命令的“手”。这三层解耦之后,容器挂了不等于 session 丢了,harness 崩了也可以从 session log 里恢复,工具和执行环境也不必和 Claude 的“脑子”绑死在一个容器里。
这一点听起来很底层,但其实非常影响上层产品体验。比如 Anthropic 在工程博客里提到,brain 和 hands 解耦之后,只有真正需要的时候才去 provision container,不再让每个 session 都先付出完整的容器启动成本。结果是 p50 的 TTFT 大约下降了 60%,p95 下降超过 90%。这类数据不是用户每天都会盯着看的指标,但它决定了你做出来的 agent 产品是“感觉很灵”,还是“每次都像在等服务器起床”。
我觉得它最有价值的核心能力
如果只看功能名,Claude Managed Agents 当然也有大家熟悉的那些词:tools、memory、skills、vaults、MCP、streaming、console。但是我觉得它真正的价值不在于“列了很多能力”,而在于这些能力被放进了一套统一的托管运行时里。
第一块是预置 agent toolset。官方 quickstart 里直接用 agent_toolset_20260401 打开完整的内建工具集,至少包括 bash、文件操作、网页搜索等能力。这意味着你可以比较快地把 Claude 变成一个真的会读文件、会写文件、会运行命令、会查网页的 agent,而不是只会吐文字的聊天模型。对很多 coding、research、ops automation 场景来说,这一步其实就已经够用了。
第二块是 environment。Managed Agents 不是简单地“帮你跑个函数”,而是让 agent 在一个有明确容器配置和网络策略的 environment 里运行。你可以先创建环境,再把不同 session 指向它。这个设计特别适合企业内部产品,因为依赖、网络、执行边界终于被当成一等公民,而不是写死在某台机器或某段 CI 脚本里。
第三块是 events 和 streaming。Managed Agents 的交互模型不是一次请求一次响应,而是围绕 event stream 来组织。你可以先发 user.message,再通过 SSE 持续接收 agent.message、agent.tool_use,最后等到 session.status_idle。这对我来说非常重要,因为它意味着你做产品时可以把 agent 的中间过程真正暴露给用户,而不是等几十秒后只给一个最终结果。只要做过 agent UI,你就会知道“过程可见”对信任感有多关键。
第四块是 skills、memory 和 vaults。skills 让 agent 可以加载 Anthropic 预置或你自己写的可复用能力,官方文档目前说每个 session 最多支持 20 个 skills;memory 则是把长期上下文从一次性 prompt 里抽出来,作为 memory store 通过 resources[] 挂到 session 上,还支持 read_only 和 read_write 这样的访问模式;vaults 则解决更现实的问题,就是用户凭据和第三方认证。Anthropic 把 vault 设计成 session 级引用的认证原语,你不必每次请求都把 token 重传一遍,也不用自己再糊一层 secret store 才能让 agent 代表用户操作第三方系统。
安全设计是我特别在意的一点
现在很多 agent demo 看起来很惊艳,但我越来越警惕一个问题:模型写出来的代码和真实凭据,到底隔没隔开。Anthropic 这次在工程博客里写得很直接,之前如果把 Claude、harness 和 sandbox 都塞进同一个容器里,那么 prompt injection 一旦诱导模型去读环境变量,事情会变得非常糟糕,因为凭据可能和执行环境放在一起。
Managed Agents 的设计里,一个核心修正就是让凭据不要直接暴露给 sandbox。比如 Git 仓库的访问 token 可以在 sandbox 初始化时用于 clone 和配置 remote,但 agent 本身不需要直接拿到 token;自定义工具则通过 MCP proxy 调用,proxy 再去 secure vault 里取出相应凭据。这样即便 Claude 在 sandbox 里执行了不可信代码,至少也不是一伸手就能摸到整套认证信息。
我觉得这点特别值得单独记住,因为很多人讨论 agent 时只盯着“能不能做更多事”,但真正上线时,权限模型和密钥隔离才是最先把你拦住的东西。Claude Managed Agents 至少说明 Anthropic 已经不再把这件事当成“用户自己想办法”的外围问题,而是把它纳入了平台设计本身。
Session 不等于上下文窗口,这个设计非常聪明
工程博客里还有一个我很喜欢的标题,叫 “The session is not Claude’s context window”。这句话几乎把 long-running agents 的一个根本问题点破了。很多 agent 系统一旦上下文变长,就只能做摘要、裁剪、压缩,但这些步骤本质上都是不可逆的。你现在觉得无关的信息,可能下一轮突然就变成关键线索。
Managed Agents 的做法是把 session 作为独立于上下文窗口之外的持久事件对象来保存。Claude 当前看到的上下文,当然还是需要做组织和管理,但完整的事件流可以被 session log 持久化保存,harness 再按需要去读、切片、回溯、重组。这个设计的好处是,你可以在不把所有历史都塞回模型上下文的前提下,依然保留“以后再回头查”的能力。
如果你自己写过 agent loop,就会明白这件事有多省心。因为一旦 session 和 context window 被混成同一个概念,后面所有长任务都会变得非常脆弱。Anthropic 这次把两者明确拆开,我觉得是一个非常对的系统边界。
具体怎么开始用
如果你今天就想试 Claude Managed Agents,我会推荐两条路:一条是先在 Console 里原型验证,另一条是直接走 CLI 或 API。
官方有一个 “Prototype in Console” 页面,做得很务实。你可以在 Console 里直接配置模型和 system prompt,添加 MCP servers,勾选 tools,挂上 skills,然后在页面里直接启动 session runner,看 event stream 和行为是否符合预期。更重要的是,它会把对应的 /v1/agents 和 /v1/sessions 请求结构展示出来。对我这种喜欢先看 UI 行为、再落代码的人来说,这个路径效率很高。
如果你更偏工程化,官方 quickstart 的最小路径也很清楚。第一步先装 Anthropic 的 CLI:
brew install anthropics/tap/ant
ant --version
然后创建一个 agent:
ant beta:agents create \
--name "Coding Assistant" \
--model claude-sonnet-4-6 \
--system "You are a helpful coding assistant. Write clean, well-documented code." \
--tool '{type: agent_toolset_20260401}'
接着创建 environment:
ant beta:environments create \
--name "quickstart-env" \
--config '{type: cloud, networking: {type: unrestricted}}'
然后通过 API 创建 session。这里有一个当前必须记住的细节:截至 2026 年 4 月,Managed Agents 相关请求需要带上 anthropic-beta: managed-agents-2026-04-01 这个 beta header。官方文档也明确写了,SDK 会自动帮你带上,但如果你自己写 HTTP 请求,别漏掉它。
curl https://api.anthropic.com/v1/sessions \
-H "x-api-key: $ANTHROPIC_API_KEY" \
-H "anthropic-version: 2023-06-01" \
-H "anthropic-beta: managed-agents-2026-04-01" \
-H "content-type: application/json" \
-d '{
"agent": "agent_xxx",
"environment_id": "env_xxx",
"title": "Quickstart session"
}'
有了 session 之后,再发事件给它:
curl "https://api.anthropic.com/v1/sessions/$SESSION_ID/events" \
-H "x-api-key: $ANTHROPIC_API_KEY" \
-H "anthropic-version: 2023-06-01" \
-H "anthropic-beta: managed-agents-2026-04-01" \
-H "content-type: application/json" \
-d '{
"events": [
{
"type": "user.message",
"content": [
{
"type": "text",
"text": "Create a Python script that generates the first 20 Fibonacci numbers and saves them to fibonacci.txt"
}
]
}
]
}'
最后通过 SSE 看它边做边回:
curl -N "https://api.anthropic.com/v1/sessions/$SESSION_ID/stream" \
-H "x-api-key: $ANTHROPIC_API_KEY" \
-H "anthropic-version: 2023-06-01" \
-H "anthropic-beta: managed-agents-2026-04-01" \
-H "Accept: text/event-stream"
这套流程跑通之后,你对 Managed Agents 的理解会一下子清楚很多,因为你会直接看到它不是一问一答,而是“定义 agent -> 准备环境 -> 启动 session -> 发事件 -> 订阅流 -> 等待 idle”这样一整条运行链路。
我会怎么设计第一版产品接入
如果是我自己要在产品里接 Claude Managed Agents,我不会一上来就追求特别复杂的多工具大一统系统。我会先挑一个长任务、低耦合、对过程可见性要求高的场景,比如代码库分析、内部文档整理、日报生成、知识库问答后续执行这类任务。因为这些场景既能体现 event stream 和 tools 的价值,又不会让你第一天就被权限和副作用炸到。
第一版我会这么配:用 Console 把 system prompt 和工具范围打磨好,再导出成固定 agent 配置;environment 单独建一个最小可用版本,把依赖和网络先收紧,不要默认全开;如果需要连内部系统,就优先走 [[MCP]],并用 vaults 管用户凭据;用户偏好、项目背景、历史结论则用 memory store 挂到 session 上,而不是一遍遍重新塞进 prompt;前端界面则直接消费 event stream,把 agent.tool_use 和 session.status_idle 这些事件展示出来。
这样做的好处是,你不会把所有复杂度都压在 prompt 上,而是开始按平台提供的边界去组织系统。说白了,Managed Agents 最值得用的地方,就是它已经替你定义了一套比较靠谱的 agent 运行边界。如果你还把它当作“只是一个更贵一点的聊天 API”,那很多价值就浪费掉了。
什么场景特别适合,什么场景反而没必要
我觉得 Claude Managed Agents 最适合三类事情。第一类是长时间执行而且需要过程反馈的任务,比如代码修改、批量文件处理、研究整理、自动化运维步骤。第二类是需要真正访问环境和工具的任务,也就是光靠模型文字回答没法完成的事。第三类是需要把认证、上下文、环境和事件流都纳入一个统一产品接口的场景,尤其是面向真实用户交付的企业应用。
但反过来说,如果你只是做一个非常轻量的问答型功能,或者工具调用极少、上下文也不需要跨轮持久化,那 Claude Managed Agents 可能就有点重了。这种情况下普通 Messages API 或者本地 [[Agent SDK]] 反而更直接。Managed Agents 的价值在于它替你托管了一大块复杂度,但如果你的问题本来就不复杂,那这块托管层未必是刚需。
还有一点我会特别提醒,就是不要因为它叫 managed agents,就误以为“所有 agent 问题都自动解决了”。系统 prompt 怎么写,工具边界怎么划,哪些动作能自动放权,哪些动作必须回到用户确认,memory 里该放什么不该放什么,这些产品设计问题仍然是你自己的责任。Managed Agents 帮你托管的是运行时,不是替你做所有判断。
最后
如果让我用一句最简洁的话来概括 Claude Managed Agents,我会说它是 [[Anthropic]] 把 agent 从“模型会调工具”推进到“平台负责托管 agent runtime”的一个重要信号。它真正有价值的地方,不只是 bash、web search、memory、vaults 这些单点能力,而是 Anthropic 开始把 session、harness、sandbox、credential isolation、event streaming 这些以前需要团队自己硬扛的基础设施,打包成一套可复用的平台接口。
这也是为什么我觉得它很值得关注。很多人现在谈 agent,还是停留在 prompt 和 workflow 这一层,但一旦你真的要把 agent 做进产品,最先暴露出来的问题几乎全是运行时问题。Claude Managed Agents 并没有让这些问题消失,但它至少把这些问题从“每家公司自己发明一遍”变成了“平台给你一套统一做法”。这件事本身,就已经很有含金量了。
如果你本来就在用 [[Claude Code]]、[[MCP]] 或 [[Anthropic API]],那我很建议你抽一点时间把 Managed Agents 的 quickstart 和工程博客读完。它未必是你今天所有项目的答案,但它很可能代表了未来几年 agent 平台会长成什么样。
相关链接
- Anthropic 工程博客:Scaling Managed Agents
- Claude Managed Agents Quickstart
- Prototype in Console
- Managed Agents Skills
- Managed Agents Memory
- Managed Agents Vaults
相关笔记
- [[Claude Code 编程助手使用总结]]
- [[Anthropic MCP Model Context Protocol]]
- [[Claude Code Agent Teams 是什么,如何使用]]