我之前的文章简单的介绍过Scrapy,pyspider 等等 Python 下的爬虫框架,但这些都是上古时期的爬虫工具,依赖于开发者手工解析 HTML,清洗页面中的数据,而在如今大部分网站都是动态渲染的时代,很多框架都已经落后,而今天想要介绍的这一款 FireCrawl 正是顺应了当今 AI 时代的潮流,成为了网络爬虫和数据提取的绝好工具。
FireCrawl
FireCrawl 是 Mendable.ai 开发的一款开源的专业网络爬虫和数据提取工具,可以高效地抓取任何网页,并将其转化成结构化数据或者 Markdown 格式。在如今的 AI 时代,大语言模型可以完全理解用户输入的 Markdown,同样通过 FireCrawl 抓取的内容也可以很好的作为 LLM 的输入给用户提供更精确的返回。
FireCrawl 也可以抓取 JavaScript 动态渲染的内容,FireCrawl 还提供了一个易于调用的 API,开发者也可以通过 API 调用实现内容的爬取和转换。
核心功能
- FireCrawler 可以从指定的 URL 开始然后遍历整个网站内容,抓取所有的子页面,如果网站存在站点地图,FireCrawler 也会充分利用。
- 单页面抓取,指定 URL,可以快速提取눌,并转换为多种格式,包括 Markdown,HTML 或结构化数据
使用
Python 下可以安装
pip install firecrawl-py
下面给出一个简单的示例
from firecrawl.firecrawl import FirecrawlApp
# 初始化FirecrawlApp实例
app = FirecrawlApp(api_key="fc-YOUR_API_KEY")
# 抓取单个网页
scrape_status = app.scrape_url(
'https://firecrawl.dev',
params={'formats': ['markdown', 'html']}
)
print(scrape_status)
# 爬取整个网站
crawl_status = app.crawl_url(
'https://firecrawl.dev',
params={
'limit': 100,
'scrapeOptions': {'formats': ['markdown', 'html']}
},
poll_interval=30
)
print(crawl_status)
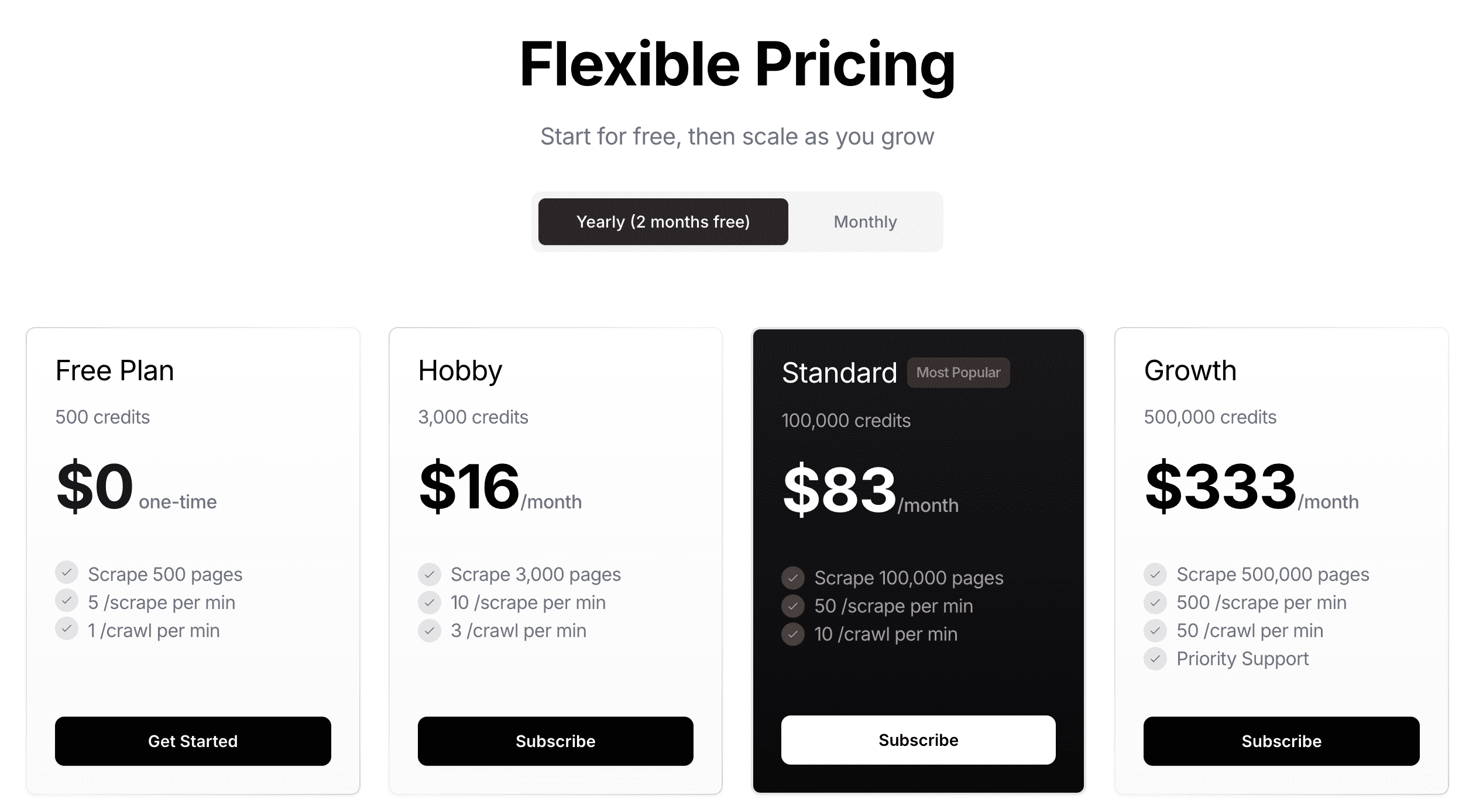
价格
免费账户拥有 500 credits,之后需要按需付费,每个月 16 USD 可以获得 3000 credits。
集成
FireCrawl 可以轻松和其他工具平台集成,比如说 Trigger.dev,通过 Trigger 来触发调用 FireCrawl。
import FirecrawlApp from "@mendable/firecrawl-js";
import { task } from "@trigger.dev/sdk/v3";
// 初始化FirecrawlApp实例
const firecrawlClient = new FirecrawlApp({
apiKey: process.env.FIRECRAWL_API_KEY,
});
export const firecrawlCrawl = task({
id: "firecrawl-crawl",
run: async (payload: { url: string }) => {
const { url } = payload;
// 爬取网站
const crawlResult = await firecrawlClient.crawlUrl(url, {
limit: 100,
scrapeOptions: {
formats: ["markdown", "html"],
},
});
if (!crawlResult.success) {
throw new Error(`Failed to crawl: ${crawlResult.error}`);
}
return {
data: crawlResult,
};
},
});
不过在抓取数据的时候,一定要遵守网站的使用条款和协议,另外也要设置合理的爬取速度,避免对目标网站产生过大的负担。