RETE 算法是卡内基梅隆大学的 [[Charles L.Forgy]] 博士在 1974 年发表的论文中实现的算法,是一种[[模式匹配算法]]。简易版本的论文发表于 1982 年 (http://citeseer.ist.psu.edu/context/505087/0)。拉丁语的 rete 表示 ”net” 和 “network”。
这个算法设计的目的是为了在大量的规则,Objects(或者说 Facts)中寻找匹配的规则。其核心思想是通过分离的匹配项,根据内容动态的构造匹配树,缓存中间结果,以空间换取时间,降低计算量。
RETE 算法主要可以分成两个部分:
- 规则编译 rule compilation,构建 RETE 网络,一个有向无环图。
- 规则执行 runtime execution
- 找出符合 LHS 部分的集合
- 选择一个条件被满足的规则
- 执行 RHS 内容
RETE 算法通过规则条件生成了一个网络,每个规则条件是网络中的一个节点。
大量模式集合和大量对象集合间比较的高效方法,通过网络筛选的方法找出所有匹配各个模式的对象和规则。
在 Dr. Forgy 1982 年的论文中,他定义了 4 种基本节点:
- root
- 1-input
- 2-input
- terminal
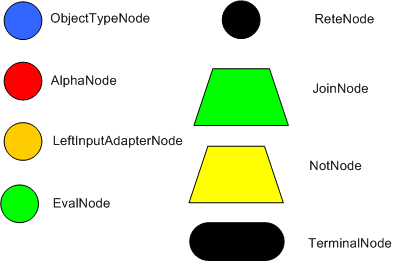
RETE 网络中的节点,除了根节点之外,每一个节点都对应一个 Pattern,对应规则的条件部分模式。从根节点到叶子节点定义了完整的 left-hand-side 的条件。每一个节点都保存满足这个 Pattern 的部分内存。
当一个新的 Fact 被插入或被修改时,会沿着网络传播,当满足 Pattern 时,标记节点。当一个 Fact 或者一组 Facts 满足所有 Patterns 是,就达到了叶子节点,对应的规则就被触发了。
RETE 算法设计用内存来换取执行时间。
规则
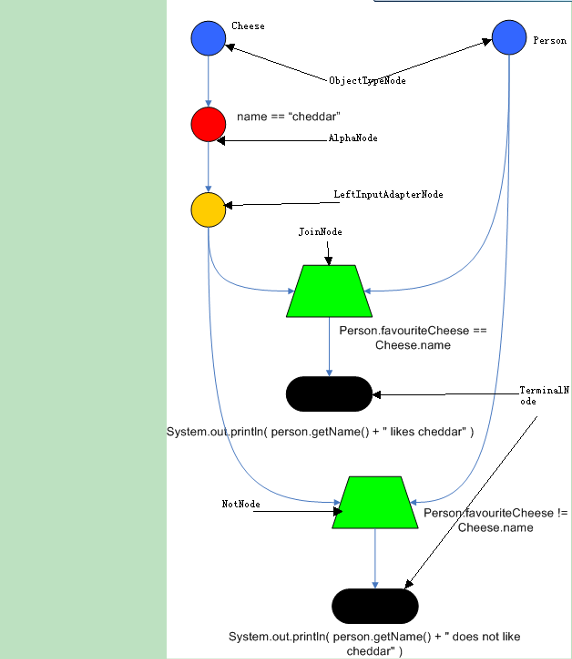
首先来看一下 Drools 的最简单的一条规则:
rule
when
Cheese( $chedddar : name == "cheddar" )
$person : Person( favouriteCheese == $cheddar )
then
System.out.println( $person.getName() + " likes cheddar" );
end
规则中可以看到 when-then 的结构,当满足 when 中的条件时,则执行 then 语句。
可以看到条件中有两个 Fact,分别是 Cheese 和 Person。
假设有两个 Fact,Person 和 Cheese。
相关概念
- Fact 事实,通常是一个 Object,通常一个 Fact 会有很多对象的属性
- Rule 规则:条件和结果的推理语句,条件部分叫做 LHS(Left-hand-side),结果部分为 RHS(right-hand-side)。
- Pattern 模式:规则的条件部分
- RETE 网络:Drools 会根据规则在编译阶段构建一个 RETE 网络
Alpha Network
Alpha 网络形成一个 discrimination network,负责根据条件选择每一个独立的 WMEs。
在 discrimination network 中每一个 AlphaNode ( 1-input node)分支,
用非专业的术语来描述 discrimination network 就是一种当数据在其中传播的时候过滤数据的网络。在网络顶层的节点会有很多的匹配,当随着网络传播,会越来越少匹配。在网络的底部是 Terminal Nodes(结束节点),当走到这个节点意味着之前所有的 Pattern 都需要满足。
Alpha 网络,用来过滤 Fact,通过模式匹配找出事实集中所有符合模式的集合,Alpha 网络中包含 - ObjectTypeNode,类型节点,根节点的直接子节点,对象的类型 - Alpha Node,条件节点
Beta Network
Beta 网络则执行不同 WMEs 之间的 joins。这个网络中包含 2-input nodes(两个输入的节点)。每一个 Beta Node 都会将结果发送给 Beta Memory。
- Beta 网络,用于匹配规则,通过连接操作将模式集组合成匹配集,最终将匹配集转化为规则结果并执行,包含两类节点
- BetaNode 连接节点,接受条件节点的输入,将规则中关联的条件节点组合起来
- Terminal Node 终端节点,规则的 THEN 部分
RETE 网络中的节点
RETE 网络中的节点:
- RootNode,根节点,所有对象通过 RootNode 进入网络,虚拟节点,然后对象会立即进入 ObjectTypeNode
- ObjectTypeNode,对象类型节点,保证对应类型的对象才会进入,比如两个对象 Cheese 和 Person。为了保证效率,引擎只会将对象传递到符合对象类型的节点。ObjectTypeNode 会继续传播到 AlphaNode, LeftInputAdapterNodes, BetaNodes。
- AlphaNode 用来计算 Literal conditions,规则的条件部分的一个模式,一个对象只有和本节点匹配成功后,才能继续向下传播。在 1982 年的论文中,只提到了相等条件,当很多 RETE 实现了更多的操作。比如 Account.name == “Mr Trout”。
- 当一个单一对象有多个 literal conditions 条件的时候,会连接到一起,这意味着当插入一个对象 Account 时,必须先满足第一个条件,然后才会继续到第二个 AlphaNode。
- BetaNode 节点用于比较两个对象和它们的字段,两个对象可能是相同或不同的类型。我们将这两个输入称为左和右。BetaNode 的左输入通常是一组对象的数组。BetaNode 具有记忆功能。左边的输入被称为 Beta Memory,会记住所有到达过的语义。右边的输入成为 Alpha Memory,会记住所有到达过的对象。
- JoinNode,用作 join 节点, 相当于 and,属于 BetaNode 类型的节点。
- NotNode,exists 检查
- LeftInputAdapterNodes,当个对象转换和数组
- Terminal Nodes,表明一条规则已经匹配了它的所有条件
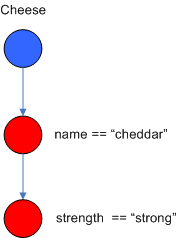
比如如下的 Alpha_Nodes 就表明是 Cheese( name =="cheddar", strength == "strong" )
构建 RETE 网络
编译的结果是规则集对应的 RETE 网络,一个 Fact 可以流动的图。
- 创建根节点
- 加入一条规则 Account(name=”abc”, age>10)
- a. 取出规则中的一个模式,模式就是规则中最小的匹配项,比如 age > 10, age < 20 就是两个基本的模式,如果是新类型,加入一个 ObjectTypeNode 节点
- b. 检查模式对应的 AlphaNode 节点是否存在,如果存在则记录下节点位置,如果没有则将模式作为 Alpha 节点加入到网络,同时根据 Alpha 节点的模式建立 Alpha 内存表
- 重复 b 直到所有的模式处理完毕
- d. 组合 Beta 节点,按照: Beta 左输入节点为 Alpha(1),右输入节点为 Alpha(2),Beta(i)节点左输入节点为 Beta(i-1),右输入节点为 Alpha(i) ,并将两个父节点的内存表内联成自己的内存表
- e. 重复 d 直到所有的 Beta 节点处理完毕;
- f. 将动作 Then 部分,封装成叶节点(Action 节点)作为 Beta(n)的输出节点;
- 重复上面的步骤,添加规则,直到所有的规则处理完毕。
运行时执行
Working Memory Element,简称 WME,用于和非根节点代表的模式进行匹配的元素
当 facts 被插入到 Working Memory,引擎会为每一个 Fact 创建 Working memory elements(WMEs)。Facts 是一个 n 位元祖。
当 WME 从根节点进入 到 RETE 网络之后,根节点会将 WME 传到子节点中,然后每一个 WME 会通过网络传播下去,直到达到 Terminal Node。
1)如果 WME 的类型和根节点的后继结点 TypeNode(alpha 节点的一种)所指定的类型相同,则会将该事实保存在该 TypeNode 结点对应的 alpha 存储区中,该 WME 被传到后继结点继续匹配,否则会放弃该 WME 的后续匹配; 2)如果 WME 被传递到 alpha 节点,则会检测 WME 是否和该结点对应的模式相匹配,若匹配,则会将该事实保存在该 alpha 结点对应的存储区中,该 WME 被传递到后继结点继续匹配,否则会放弃该 WME 的后续匹配: 3)如果 WME 被传递到 beta 节点的右端,则会加入到该 beta 结点的 right 存储区,并和 left 存储区中的 Token 进行匹配(匹配动作根据 beta 结点的类型进行,例如:join,projection,selection),匹配成功,则会将该 WME 加入到 Token 中,然后将 Token 传递到下一个结点,否则会放弃该 WME 的后续匹配: 4)如果 Token 被传递到 beta 结点的左端,则会加入到该 beta 结点的 left 存储区,并和 right 存储区中的 WME 进行匹配(匹配动作根据 beta 结点的类型进行,例如:join,projection,selection),匹配成功,则该 Token 会封装匹配到的 WME 形成新的 Token,传递到下一个结点,否则会放弃该 Token 的后续匹配; 5)如果 WME 被传递到 beta 结点的左端,将 WME 封装成仅有一个 WME 元素的 WME 列表做为 Token,然后按照 4) 所示的方法进行匹配: 6)如果 Token 传递到 Terminal,则和该根结点对应的规则被激活,建立相应的 Activation,并存储到 Agenda 当中,等待激发。 7)如果 WME 被传递到 Terminal Node,将 WME 封装成仅有一个 WME 元素的 WME 列表做为 Token,然后按照 6) 所示的方法进行匹配;
特点和不足
特点:
- 启发式算法,不同规则间共享相同的模式,如果 BetaNode 被多个规则共享,会提高 N 倍
- 当事实集合变化不大时,保存在 Alpha 和 Beta 节点的状态不需要太多变化,避免了大量的重复计算,提高了匹配效率。
- RETE 匹配速度与规则数目无关,只有 Fact 满足本节点才会继续向下沿网络传递
不足:
- RETE 算法使用存储区存储已计算的中间结果,牺牲空间换取时间,加速系统的速度,存储区根据规则和事实成指数级增长,当规则和事实很多的时候,会耗尽系统资源。
建议:
- 容易变化的规则尽量后置,减少规则的变化带来的规则库变化
- 约束性通用或较强的模式尽量前置,避免不必要的匹配
- 针对 Rete 算法内存开销大和事实增加删除影响效率的问题,技术上应该在 alpha 内存和 beata 内存中,只存储指向内存的指针,并对指针建索引(可用 hash 表或者非平衡二叉树)。 d. Rete 算法 JoinNode 可以扩展为 AndJoinNode 和 OrJoinNode,两种节点可以再进行组合
一个 Python 实现的 RETE 算法
reference
- 《一种基于共享度模型的改进 Rete 算法》 孙新, 严西敏, 尚煜茗, 欧阳童, 董阔