从零搭建一台 NAS:软件篇
之前总结过一篇 NAS 硬件 介绍了自组 NAS 可能遇到的一些名词和概念,这里再总结一下相关的软件。
Operating System
首先就是操作系统的选择,这里 也简单总结过 FreeNAS,OpenMediaVault 和 [[unRAID]] 的优缺。
软件的选择
MergerFS
MergerFS 提供了一种简单的,类似于存储池的概念,可以让我们通过简单的方式来访问多块硬盘,和 unRAID, Synology, Qnap 提供的方式类似。总结一下就是 MergerFS 允许我们混合合并多个数据卷到一个挂载点下。
mergerfs is a union filesystem geared towards simplifying storage and management of files across numerous commodity storage devices. It is similar to mhddfs, unionfs, and aufs.
特性:
- 组合多块磁盘成存储池
- 支持多块不同格式,不同大小的硬盘
- 支持增量升级硬盘,可以不用一下子购入一组硬盘来扩充容量
- 将多个硬盘驱动器组合在一个挂载点进行读取和写入
- 为每个驱动器提供一个单独可读的文件系统,所以假如想要拆下一块硬盘,那么这块硬盘也可以挂载到其他系统中使用
- 只运行当前有读写任务的硬盘
官网:
安装
直接从源安装:
apt install mergerfs fuse
或者用 deb 安装:
wget https://github.com/trapexit/mergerfs/releases/download/*/mergerfs_*.debian-stretch_amd64.deb && dpkg -i mergerfs*.deb
Docker
Docker 官方的教程已经足够清晰:
apt install curl
curl -sSL https://get.docker.com | sh
为了管理方便,可以将自己的用户名加入到 Docker 用户组:
usermod -aG docker your-name
Test Docker:
docker run --rm hello-world
snapRAID
snapRAID 是一个备份应用,他可以在一组硬盘中计算 parity,然后通过 parity 来恢复磁盘故障可能带来的数据丢失。snapRAID 是 ‘snapshot’ RAID 的缩写,它不是和 mdadm, ZFS 或者 uRAID 那样实时备份,它需要定时运行 sync 来同步。
snapRAID 支持不同大小的硬盘,但是 partiy 磁盘必须要大于或等于最大的数据盘的容量。
- snapRAID 支持最多 6 块 parity 磁盘(基于奇偶校验保护),这就使得 snapRAID 可以提供远超过 ZFS 和 BTRFS RAID 的错误容忍。
- snapRAID 的数据完整性校验使用 128 bit 校验和,类似于 ZFS 的 256bit 校验和,snapRAID 可以自动修复这些错误。
- 此外,上次同步以后更改的任何文件都可以逐个文件还原,从而在文件级别提供了非常完善的备份解决方案。要知道 RAID 并不是备份。
- snapRAID 还可以在已经有数据的磁盘中使用,这想比如传统的 RAID,又是一个巨大的进步。
- 再者,它只会让正在使用的磁盘运转,不像 RAID 即使获取一个文件,也需要所有磁盘运转。
SnapRAID is a backup program for disk arrays. It stores parity information of your data and it recovers from up to six disk failures.
SnapRAID 是为一组不经常修改的文件而设计的,一个常见的用例就是媒体或家用服务器。假设你拥有 2TB 的影片,2TB 的剧集,你多长时间更改他们一次?并不是很经常吧。那么你需要对这些文件进行实时的奇偶校验计算,还是在每天固定时间安静地执行一次?我的想法就是每天一次同步就已经足够保证数据的安全。
再举一个简单的例子,假如你下载了一个文件,并保存为 “WorstMovieEver.mkv”,这个文件立即可以访问到,但直到下一次奇偶校验(或者奇偶校验快照)执行,这个文件都是没有被保护的。这就意味着在下载完成后到执行奇偶校验这个过程中,如果你遇到了磁盘故障,那么这个文件就无法恢复了。值得注意的是,如果文件足够重要,那么手工执行一次 snapraid sync 也是非常简单的。
snapRAID 在 GPL v3 开源许可下开源,snapRAID 支持大量的操作系统,包括但不限于 Linux, OS X, Windows, BSD, Solaris 等等。
官网:
经过上面的一大番解释,相信你已经了解 snapRAID 的运作方式了,在使用 snapRAID 之前请先审视一下自己的使用场景。snapRAID 非常不适用于频繁修改的应用程序,例如数据库或其他类似的应用程序,如果你的使用场景是类似这种,那么请优先考虑实时奇偶校验的解决方案。如果你能够容忍可能造成数据丢失的时间窗口,并且有一批静态的大文件,SnapRAID 就是为你准备的。
安装
@IronicBadger 提供了一键编译脚本:
apt install git
git clone https://github.com/IronicBadger/docker-snapraid.git
cd docker-snapraid/
chmod +x build.sh
./build.sh
cd build/
dpkg -i snapraid*.deb
snapraid -V
# snapraid v11.1 by Andrea Mazzoleni, http://www.snapraid.it
使用
SnapRAID 有详尽的文档.
reference
使用 tinyMediaManager 整理影视资源
tinyMediaManager (后文简写成 tmm) 可以用来批量处理本地的影视资源,处理后就可以非常漂亮用海报墙的方式展示出来。
下载安装
tinyMediaManager 是 Java 编写的,所以天然的具有跨平台的属性,三大桌面平台全都支持,并且还是开源的。
Mac 下可以使用:
brew install --cask tinymediamanager
功能
特色功能 1:
- 支持从 themoviedb.org, imdb.com, ofdb.de, moviemeter.nl 等等站点抓取电影元信息,海报,图片等等
- 支持从 opensubtitles.org 自动获取字幕,当然这个站中文的比较少
- 支持批量重命名
使用
使用过程是比较简单的,添加媒体库,然后 tmm 就能通过文件名在左侧边栏展示出来,然后指定元数据从 themoviedb.org 获取,如果媒体文件命名足够清晰的话,可以直接一键自动匹配所有的影片。
媒体文件的管理
绝大部分影片用 bt 下载后可能的文件名是这样的:
利刃出鞘(中英双字幕).Knives.Out.2019.WEB-1080p.X264.AAC.CHS.ENG-UUMp4.mp4
对于这样的文件名本身就已经告诉了我们很多信息,比如中文片名,英文片名,发行日期,文件格式,编码格式,音频编码格式,中英文字幕情况,以及出处,如果想要在 [[Kodi]],Emby,[[Plex]], 或者 Jellyfin 这些媒体播放器中展示出海报,剧情介绍,演员表等等 metadata,还缺少两样东西:
- xxx-poster.jpg
- xxx.nfo
poster.jpg 顾名思义就是电影的海报,而 nfo 文件就是存放该媒体文件 metadata 信息的地方,用 less 或者直接用 vi 查看的话就一目了然了。其中包含着这部电影需要展示的完整的信息,有了这两个文件,不管在那个媒体管理软件中打开存放的目录就能比较漂亮的显示媒体海报墙了。
Extended
安装 tinymediamanager 过程中发现 themoviedb 这个非常棒的网站,不仅完美的代替了豆瓣,界面美观,而且还提供了 API 接口,豆瓣恶心的把 API 关闭后,又频繁删贴,早有点看不下去了。
自建 RSS Reader
Stringer
[[stringer]] 是一个可以自行搭建的 RSS Reader,Ruby 编写。Stringer 没有任何社交媒体分享,没有机器学习算法。但有一套快捷键。非常适合构建一个个人的在线阅读体验。
Tiny Tiny RSS
Php 5.6, Postgresql or MySQL
Docker 安装,虽然 ttrss 官方给了自己的解决方案,但似乎刚刚起步,而 linuxserver/tt-rss 的镜像因为拿不到 tt-rss tarball 所以也停止更新了。所以最后折中的方案就是用了 这个镜像
QNAP 下的 PostgreSQL
App store 中可以直接安装,但实际上 QNAP 只是帮用户默认用 docker-compose 安装好了,不过也还行了,连 phpPgAdmin 也安装了。
查看下文件内容:
version: '3'
services:
db:
image: postgres:11.4
restart: on-failure
ports:
- 5432:5432
volumes:
- ./data:/var/lib/postgresql/data
environment:
- POSTGRES_PASSWORD=postgres
web:
image: edhongcy/phppgadmin:latest
restart: on-failure
ports:
- 7070:80
- 7443:443
depends_on:
- db
environment:
- PHP_PG_ADMIN_SERVER_DESC=PostgreSQL
- PHP_PG_ADMIN_SERVER_HOST=db
- PHP_PG_ADMIN_SERVER_PORT=5432
- PHP_PG_ADMIN_SERVER_SSL_MODE=allow
- PHP_PG_ADMIN_SERVER_DEFAULT_DB=template1
- PHP_PG_ADMIN_SERVER_PG_DUMP_PATH=/usr/bin/pg_dump
- PHP_PG_ADMIN_SERVER_PG_DUMPALL_PATH=/usr/bin/pg_dumpall
- PHP_PG_ADMIN_DEFAULT_LANG=auto
- PHP_PG_ADMIN_AUTO_COMPLETE=default on
- PHP_PG_ADMIN_EXTRA_LOGIN_SECURITY=false
- PHP_PG_ADMIN_OWNED_ONLY=false
- PHP_PG_ADMIN_SHOW_COMMENTS=true
- PHP_PG_ADMIN_SHOW_ADVANCED=false
- PHP_PG_ADMIN_SHOW_SYSTEM=false
- PHP_PG_ADMIN_MIN_PASSWORD_LENGTH=1
- PHP_PG_ADMIN_LEFT_WIDTH=200
- PHP_PG_ADMIN_THEME=default
- PHP_PG_ADMIN_SHOW_OIDS=false
- PHP_PG_ADMIN_MAX_ROWS=30
- PHP_PG_ADMIN_MAX_CHARS=50
- PHP_PG_ADMIN_USE_XHTML_STRICT=false
- PHP_PG_ADMIN_HELP_BASE=http://www.postgresql.org/docs/%s/interactive/
- PHP_PG_ADMIN_AJAX_REFRESH=3
看到了默认密码了吧,QNAP 官方的页面都不写一下,让别人一键安装的去哪里找,还不如直接贴这个让用户自己到 Container 里面自己建呢。
如果安装后发现用默认的用户名:postgres 和默认密码:postgres 登录不了,尝试重启一下服务,然后 netstat -tupln 看看服务 5432 端口有没有启动。
/etc/init.d/postgresql.sh restart
然后就开始安装 ttrss:
docker run -d --name ttrss --restart=unless-stopped \
-e SELF_URL_PATH=http://<your-nas-ip>:181 \
-e DB_HOST=<your-nas-postgresql-host> \
-e DB_PORT=5432 \
-e DB_NAME=ttrss \
-p 181:80 \
wangqiru/ttrss
安装的时候有个坑,启用时遇到如下错误:
PHP Fatal error: Uncaught PDOException: SQLSTATE[42P01]: Undefined table: 7 ERROR: relation "ttrss_version" does not exist LINE 1
我一般习惯 MySQL 的做法,先到数据库中新建了一个 DB,新建一个用户,然后再用 -e DB_USER=user -e DB_PASS=password 来创建 Docker 容器,没想到遇到了 Bug,首次初始化的时候脚本里有着判断,如果 db 已经存在了就不初始化 sql 了,所以到数据库中把新建的数据库删掉,然后再来一次就好了。
其他说明:
--restart参数可以换成--restart=always,这样系统重启容器也能重启SELF_URL_PATH这里需要和启动时的 URL 配置完全一致,否则 ttrss 启动时会出错
其他插件安装可以参考这里,比如全文输出,主题之类,我只想用 ttrss 来订阅几个我日常关注的博主,其他的订阅源还是 InoReader 所以也就不折腾全文不全文了,不全文输出的也就没有订阅的必要了。不过如果你想要实现全文输出也还是有办法的。
Mercury Parser api
docker run -d --name=mercury-parser-api \
--restart=unless-stopped \
-p 3000:3000 -d wangqiru/mercury-parser-api
FreshRSS
FreshRSS 也是 PHP 编写,基本依赖也就是 PHP 和数据库,MySQL 5.5.3+ MariaDb, SQLite, PostgreSQL 9.5+. 界面也比较简洁大方。
用 Docker 安装也比较方便,可以参考这里
安装
docker run -d \
--name=freshrss \
-e PUID=1000 \
-e PGID=100 \
-e TZ=Asia/Shanghai \
-p 6080:80 \
-v /share/Container/freshrss:/config \
--restart unless-stopped \
linuxserver/freshrss
NewsBlur
Python, Django, Celery etc
NewsBlur 的在线预览可以点击这里,界面也还是很不错的。
Selfoss
另一款 PHP 编写的 RSS 阅读器,Selfoss 比较简单,依赖也比较简单,PHP,WebServer,Database(sqlite, mysql, PostgreSQL) 就可以,所以安装起来也比较简单,甚至有环境的基础下,下载 zip, 解压,然后修改一下配置即可。
需要注意的是,config.ini 配置文件中的 password 字段,需要访问 http://ip-selfoss-service/password,然后输入密码生成一个 hashcode,然后将该密码 hash 配置到 config.ini 文件中。
然后访问 http://ip-selfoss-service/opml,可以导入 opml 文件。
Android Reader
总结
Selfoss 相对比较简单,定时抓取也要手工 crontab 来触发,但功能一点也不弱,日常用完全没有问题,并且依赖非常少。
排错
在我配置使用 SQLite 作为数据库时,Selfoss 没出现问题,但是当我配置 MySQL 作为数据库时,在日志中给我报了:
[2020-02-10 16:04:21] selfoss.ERROR: PDOStatement: You do not have the SUPER privilege and binary logging
is enabled (you *might* want to use the less safe log_bin_trust_function_creators variable)
网上一查似乎是 MySQL 权限问题,但想想我已经给了 Selfoss 的用户整个 selfoss 数据库的权限了,后来一查看到有人和我相同的情况 1,定位到应该就是 MySQL 中创建 Tigger 的权限不足导致。
[2020-02-10 16:09:03] selfoss.ERROR: PDOStatement: Trigger does not exist
结合这个错误,所以我的解决方法就是在安装时临时给 selfoss 这个数据库用户超级权限,安装好后把权限取消。
- Selfoss 安装好后会在 phpMyAdmin 中能看到 Selfoss 创建了两个 Trigger,
insert_updatetime_trigger和update_updatetime_trigger, 备份时记得备份,mysqldump --triggers --no-create-info --no-data --no-create-db --skip-opt selfoss > selfoss.trigger - 删除 triggers from the selfoss database: drop trigger insert_updatetime_trigger; and drop trigger update_updatetime_trigger;
- replaced the selfoss user in the exported selfoss.trigger file with root (DEFINER=
root@localhost) - 导入
mysql selfoss < selfoss.trigger
miniflux
Go 编写,依赖 PostgreSQL。
stringer
Ruby 编写
Leed
Php/MySQL
更多自建的 RSS 可以参考这里 大概还有几十种,不同语言,不同实现。
Feedbin
Ruby & Postgres & Redis & Memcached & Elasticsearch
reference
- https://www.reddit.com/r/selfhosted/comments/6yqmdo/rss_freshrss_vs_tiny_tiny_rss_vs_selfoss/
- https://sleele.com/2019/06/16/tiny-tiny-rss-%E9%83%A8%E7%BD%B2%E6%B5%81%E7%A8%8B/
-
https://selfoss.aditu.de/forum/index.php?mode=thread&id=895 ↩
威联通折腾篇二十一:Virtualiztion Station 安装 Windows10
平时不会想起用 Windows,因为没有要用的场景,但有的时候不得不用到,所以安装一个以防万一。
导入虚拟机
支持导入的虚拟机格式有:
- ova
- ovf
- vmx
- qvm
全新安装虚拟机
如果选择新建虚拟机可以用镜像全新安装。
VNC 链接
安装后可以设置 VNC 连接,设置端口 5900,然后就可以通过客户端连接了。
Linux 下可以使用 Remmina:
自建邮件服务器可选项
整理一些可以自行搭建邮件服务器的项目。
Postal
[[postal]] 是一个使用 Rust 编写的邮件服务器,可以发送和接收邮件。这是一个可以代替 [[SendGrid]]、[[Mailgun]] 或者 Postmark 的开源工具,可以在自己的服务器上假设。
GitHub 地址:https://github.com/postalserver/postal
Mail-in-a-Box
mailu
Mailu.io 是一款免费开源且性能强大、功能丰富的域名邮箱服务。它基于Docker, 具有部署简单,可移植性高,备份方便等多种优势。
搭建介绍:
-
[[2021-07-30-email-server-mailu]]
mailcow
Open source email server
mailcow 使用介绍:
搭建视频教程:
Poste
Poste 是一个可以自己搭建的邮件服务器程序,提供了后台管理,可以实现邮件收发,容量控制,邮件过滤等等工具。还提供了统计分析,SSL,邮件转发,邮件别名,通过 ClamAV 支持邮件病毒扫描等等功能。
Poste 运行需要 800MB 左右空间,只支持 64 位操作系统。
Poste 可以支持 Docker 安装,但是提供了 Free、Pro 和 Pro+ 版本,都需要按年订阅。
docker-mailserver
文档不是很全
salmon
一个 Python 写的 smtp 服务
inbucket
Disposable webmail server (similar to Mailinator) with built in SMTP, POP3, RESTful servers; no DB required.
A great tool for email testing.
reference
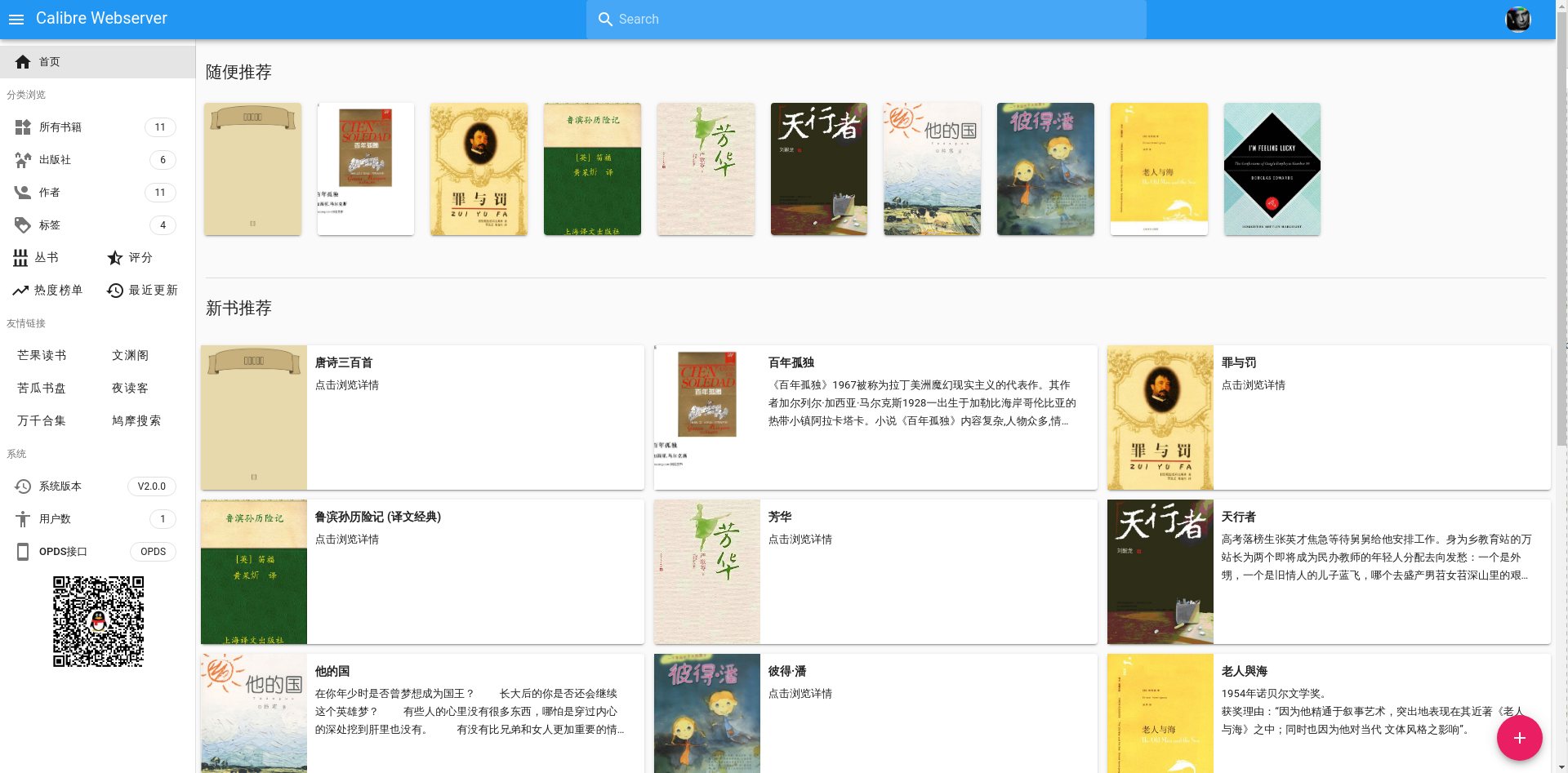
威联通折腾篇十九:Calibre-web
借助 QNAP(威联通)的 Container Station 功能,可以展开无限想象,之前也已经分享 过很多的使用 Docker 镜像来安装的教程了。所以今天不展开讲,主要就是来分享一下,最近安装的 calibre-web。因为之前七零八落的收集了很多电子书,文件分散在磁盘的各个地方,一直没有好好整理,正好趁着这个机会把所有的文件都放到一个地方了。
docker
主要是用的镜像是 technosoft2000 制作的 calibre-web:
我尝试了 linuxserver 发布的 calibre-web,也不错,不过缺少了在线预览功能。然后还看到有几个中文的镜像,还没来得及尝试。
源码主要在 https://github.com/janeczku/calibre-web 这里。
docker create --name=calibre-web --restart=always \
-v <your Calibre books folder>:/books \
[-v <your Calibre Web application folder>:/calibre-web/app] \
[-v <your Calibre Web kindlegen folder>:/calibre-web/kindlegen`]
[-v <your Calibre Web config folder>:/calibre-web/config \]
[-e USE_CONFIG_DIR=true \]
[-e APP_REPO=https://github.com/janeczku/calibre-web.git \]
[-e APP_BRANCH=master \]
[-e SET_CONTAINER_TIMEZONE=true \]
[-e CONTAINER_TIMEZONE=<container timezone value> \]
[-e PGID=<group ID (gid)> -e PUID=<user ID (uid)> \]
-p <HTTP PORT>:8083 \
technosoft2000/calibre-web
批量导入书籍
注意下方命令中的 --library-path 需要指定 Calibre 库的位置。
calibredb add --library-path=/books -r /path/to/your/book_dir_you_want_to_add
使用该方法添加的书籍会在原始位置,而 metainfo 则会添加到 Calibre 库中,也就是上面一行的 /books 目录中。
更多关于 calibredb 命令的使用可以参考官网
Goodreads API
获取 Goodreads API
批量导入 Calibre
在 Calibre 界面中可以快速的导入一个目录,但是在 Web UI 里面暂时不能做到,所以借用 Bash 命令 1:
if [ "$(ls -A /[autoaddfolder])" ]; then
calibredb add -r "/[autoaddfolder]" --library-path="/[calibrelibraryfolder]"
fi
Others
talebook
亮点是支持从豆瓣获取数据,不过我使用的 technosoft2000 的镜像也是支持的。
gshang2017
豆瓣 API
在最早使用 Calibre-web 的时候还自带豆瓣图书的数据源,可以一键将图书的 metadata 信息补充完整,但后来豆瓣把 API 关闭了,所以可以借助如下的项目来将此部份模块替换,使用 Python 爬取豆瓣的数据。
延伸
- Komga 另一个可以自行搭建的图书管理
-
https://github.com/janeczku/calibre-web/issues/412 ↩
威联通折腾篇二十:自带 Apache Web 服务器及 SSL 配置
折腾一下威联通自带的 Web 服务器。
vhost
在界面上修改虚拟主机配置,比如 Create New Virtual Host:
- Host name: blog.nas.com
- folder: /share/Web/wp
- protocol: HTTP
- port number: 80
对应的修改会保存到如下文件:
/etc/config/apache/extra/httpd-vhosts-user.conf
点击应用,QNAP 会应用修改,然后因为我是局域网用,所以修改了我本地 /etc/hosts,把域名 blog.nas.com 指到 QNAP 的局域网地址。
/etc/init.d/Qthttpd.sh reload
然后在自己机器上就能通过域名 (blog.nas.com) 访问 NAS 中 /share/Web/wp 目录。
vhost 配置解析
在 QNAP 上查看 vhost 配置文件 /etc/config/apache/extra/httpd-vhosts-user.conf,可以看到:
NameVirtualHost *:80
<VirtualHost _default_:80>
DocumentRoot "/share/Web"
</VirtualHost>
<VirtualHost *:80>
<Directory "/share/Web/wp">
Options FollowSymLinks MultiViews
AllowOverride All
Require all granted
</Directory>
ServerName blog.nas.com
DocumentRoot "/share/Web/wp"
</VirtualHost>
解释:
DocumentRoot配置了服务器根目录OptionsMultiViews 使用”MultiViews”搜索,即服务器执行一个隐含的文件名模式匹配,并在其结果中选择。ServerName主机名字
SSL 配置
reference
NextCloud 和 Joplin 完美合作
今天不经意打开了 NextCloud 管理后台,然后看提示有 App 更新就顺手进去看了一下,然后就发现了宝藏,这一年多来不过把 NextCloud 作为 Dropbox 代替品,做为文件同步工具,没想到后台已经发展出各种“玩法”,安装插件可以在 NextCloud 中启用 Calendar,Contacts,甚至还有视频通话插件,然后通过插件可以将 NextCloud 扩展成 RSS 阅读器,可以变成看板,可以变成电子书阅读器等等。不过让我眼前一亮的是其中有个插件叫做 Joplin Web API。不过该插件目前并不完善,还在 beta 阶段,不过不妨展开想象,如果未来可以借助 NextCloud,那么分享 Joplin 中的笔记,甚至对同一个笔记展开协同合作也不是不可能的。
WebDAV
NextCloud 默认已经启用了 WebDAV, 所以可以在 Joplin 设置,同步设置中直接配:
http://[ip]:[port]/remote.php/dav/files/USERNAME/Joplin
记得 Joplin 文件夹要创建好。
二步验证
开启二步验证后需要在后台生成一个密码,而不能用自己的用户名和密码来同步。
reference
在线目录列表程序
最简单的 index 就是开启 Apache,或者 Nginx 的 Directory Index Listing。
location /somedirectory/ {
autoindex on;
}
不过有些简陋而已。
ZFile
[[ZFile]] 是一款基于 Java 的在线网盘程序,支持对接 S3,OneDrive,SharePoint,又拍云,本地存储,FTP 等等,支持在线浏览图片、播放音视频、文本文件等等。
docker run -d --name=zfile --restart=always \
-p 8080:8080 \
-v /root/zfile/db:/root/.zfile/db \
-v /root/zfile/logs:/root/.zfile/logs \
zhaojun1998/zfile
或者参考我的 docker-compose。
FileBrowser Enhanced
Nginx docker
Nginx index 套了一层皮肤
PanIndex
[[PanIndex]] 是一个使用 JavaScript 实现的网盘目录列表,支持天翼云、teambition, 阿里云盘,OneDrive 等等
演示:
![[screenshot-area-2021-10-28-111720.png]]
OLAINDEX
[[OLAINDEX]] 是一个可以将 OneDrive 中的内容展示出来的目录列表程序。基于 PHP 框架 Laravel ,界面也不错。
OneDrive directory listing application
从 DockerHub 拉取Docker镜像:
docker run -d --init --name olaindex -p 80:8000 xczh/olaindex:6.0
现在,访问http://YOUR_SERVER_IP/,可以看到你的OLAINDEX应用了。
当然你也可以选择从 Dockerfile 自行编译Docker镜像,切换到项目根目录执行:
docker build -t xczh/olaindex:dev .
docker run -d --init --name olaindex -p 80:8000 xczh/olaindex:dev
或者也可以使用这个镜像:
OneDrive 的目录程序还有 PyOne,OneIndex, [[OneList]]
h5ai
h5ai 是一个 PHP 实现的简单在线列表程序,将源码放到目录下,使用 PHP 就能打开列表,不过源码已经很久没有更新了。
zdir
依赖:
- PHP
特色功能:
- 文件搜索
- Office 文件在线预览
-
文件二维码
- https://github.com/helloxz/zdir
- 帮助文档:https://doc.xiaoz.me/#/zdir/
GoIndex
[[GoIndex]] 是一个使用了 Cloudflare Workers 的 Google Drive 列表程序。在不需要自己的服务器的情况下就可以使用 GoIndex 来展示 Google Drive 中的内容。
onedrive-vercel-index
Snap2HTML
Snap2HTML 是一个生成一个静态 HTML 页面展示文件列表的程序。
filestash
[[filestash]]
alist
[[AList]]
DirectoryLister
[[DirectoryLister]] 是一个简洁的文件目录程序,需要依赖 PHP,Nginx。
其他网盘程序
-
[[2018-04-08-nextcloud NextCloud]] - [[CloudReve]]
- [[SeaFile]]
- [[KODExplorer]]
- [[OwnCloud]]
关于 .git 目录你需要知道的一切
之前也总结过不少的关于 git 使用的文章,但都很少提及 .git 目录,都知道在 git init 之后,git 会在目录下创建一个 .git 目录,该目录中保存着 git 的一切。昨天在 Twitter 上正好有人分享了三篇文章,今天就顺便学习一下。
通过.git 目录学习 git
— Hao Chen (@haoel) February 5, 2020
- https://t.co/pBe2jE7QXM
- https://t.co/w8kV4oAocV
- https://t.co/GqnF5FnkY2
初识 git 目录
展开 git 目录,大致是这样的:
├── HEAD
├── branches
├── config
├── description
├── hooks
│ ├── pre-commit.sample
│ ├── pre-push.sample
│ └── ...
├── info
│ └── exclude
├── objects
│ ├── info
│ └── pack
└── refs
├── heads
└── tags
其中的每一个文件和目录都是有意义的,下面就一个一个看看。首先是 HEAD 文件,这个不陌生吧,git 中一个非常重要的概念,后面展开。
conf
conf 文件中包含着 repository 的配置,包括 remote 的地址,提交时的 email, username, 等等,所有通过 git config .. 来设置的内容都在这里保存着。如果熟悉甚至可以直接修改该文件。
description
被 gitweb(github 之前) 用来描述 repository 内容。
hooks
hooks,国内通常被翻译成钩子,git 中一个比较有趣的功能。可以编写一些脚本让 git 在各个阶段自动执行。这些脚本被称为 hooks, 脚本可以在 commit/rebase/pull 等等环节前后被执行。脚本的名字暗示了脚本被执行的时刻。一个比较常见的使用场景就是在 pre-push 阶段检查本地提交是否遵循了 remote 仓库的代码风格。
info exclude
该文件中定义的文件不会被 git 追踪,和 .gitignore 作用相同。大部分情况下 .gitignore 就足够了,但知道 info/exclude 文件的存在也是可以的。
commit 中有什么?
每一次创建一些文件,提交,git 都会压缩并将其保存到自己的数据结构中。压缩的内容会拥有一个唯一的名字,一个 hash 值,该 hash 值会保存到 object 目录中。
在浏览 object 目录之前我们要问自己一个问题,什么是一次提交 (commit)?一次提交是当前工作目录的一个快照,但又不止于此。
事实上,当使用 git 提交时,git 为了创建工作区的快照,只做了两件事:
- 如果文件没有改变,git 将压缩的文件名 (the hash) 保存到快照
- 如果文件改变了, git 会压缩该文件,然后将压缩的文件保存到 object 目录,最后将 hash 保存到快照
一旦快照被创建,压缩的内容和名字都会到 object 目录中:
├── 4c
│ └── f44f1e3fe4fb7f8aa42138c324f63f5ac85828 // hash
├── 86
│ └── 550c31847e518e1927f95991c949fc14efc711 // hash
├── e6
│ └── 9de29bb2d1d6434b8b29ae775ad8c2e48c5391 // hash
├── info // let's ignore that
└── pack // let's ignore that too
上面的内容是新建了一个空文件 file__1.txt 并提交后 object 目录的结构。需要注意的是,如果 hash 是 4cf44f1e...,那么 git 会将内容保存到 4c 子目录中,然后将文件命名为 f44f1...。这样就使得 object 目录缩小了,最多只会有 00-ff 这些目录。
commit 由四部份组成:
- 工作区快照名 hash
- comment
- 提交者信息
- hash 的父 commit
如果解压一个 commit 文件,可以查看到这些内容。
// by looking at the history you can easily find your commit hash
// you also don't have to paste the whole hash, only enough
// characters to make the hash unique
git cat-file -p 4cf44f1e3fe4fb7f8aa42138c324f63f5ac85828
可以看到:
tree 86550c31847e518e1927f95991c949fc14efc711
author Pierre De Wulf <test[@gmail.com](mailto:pie@gmail.com)> 1455775173 -0500
committer Pierre De Wulf <[test@gmail.com](mailto:pie@gmail.com)> 1455775173 -0500
commit A
两个重要的内容:
- 快照 hash
86550同样是一个 object, 可以在 object 目录中找到 - 因为是第一个提交,所以没有 parent
查看具体的快照内容:
git cat-file -p 86550c31847e518e1927f95991c949fc14efc711
100644 blob e69de29bb2d1d6434b8b29ae775ad8c2e48c5391 file_1.txt
这里就找到了上面提到的三个 object 中的另外一个,这个 object 是 blob, 后文在展开。
branch, tags, HEAD 他们都一样
到目前为止你已经知道了 git 中的一切都可以通过正确的 hash 来获取。现在然我们来看看 HEAD.
cat HEAD
ref: refs/heads/master
然而,HEAD 不是一个 hash, 那也 OK,之前的文章在介绍 HEAD 时都将 HEAD 比喻成一个指针,指向当前工作的分支。让我们来看看 refs/heads/master
cat refs/heads/master
4cf44f1e3fe4fb7f8aa42138c324f63f5ac85828
熟悉吧,这就是第一次提交的 hash. 这就显示了 branchs, tags, 都是指向 commit 的指针。这也就意味着你可以删除所有的分支,所有的 tags,但所有的提交依然还在。如果还想了解更多,可以查看 git book
reference
文章分类
最近文章
- Dinox 又一款 AI 语音实时转录工具 前两天介绍过 [[Voicenotes]],也是一款 AI 转录文字的笔记软件,之前在调查 Voicenotes 的时候就留意到了 Dinox,因为是在小红书留意到的,所以猜测应该是国内的某位独立开发者的作品,整个应用使用起来也比较舒服,但相较于 Voicenotes,Dinox 更偏向于一个手机端的笔记软件,因为他整体的设计中没有将语音作为首选,用户也可以添加文字的笔记,反而在 Voicenotes 中,语音作为了所有笔记的首选,当然 Voicenotes 也可以自己编辑笔记,但是语音是它的核心。
- 音流:一款支持 Navidrom 兼容 Subsonic 的跨平台音乐播放器 之前一篇文章介绍了Navidrome,搭建了一个自己在线音乐流媒体库,把我本地通过 [[Syncthing]] 同步的 80 G 音乐导入了。自己也尝试了 Navidrome 官网列出的 Subsonic 兼容客户端 [[substreamer]],以及 macOS 上面的 [[Sonixd]],体验都还不错。但是在了解的过程中又发现了一款中文名叫做「音流」(英文 Stream Music)的应用,初步体验了一下感觉还不错,所以分享出来。
- 泰国 DTV 数字游民签证 泰国一直是 [[Digital Nomad]] 数字游民青睐的选择地,尤其是清迈以其优美的自然环境、低廉的生活成本和友好的社区氛围而闻名。许多数字游民选择在泰国清迈定居,可以在清迈租用廉价的公寓或民宿,享受美食和文化,并与其他数字游民分享经验和资源。
- VoceChat 一款可以自托管的在线聊天室 VoceChat 是一款使用 Rust(后端),React(前端),Flutter(移动端)开发的,开源,支持独立部署的在线聊天服务。VoceChat 非常轻量,后端服务只有 15MB 的大小,打包的 Docker 镜像文件也只有 61 MB,VoceChat 可部署在任何的服务器上。
- 结合了 Google 和 AI 的对话搜索引擎:Perplexity AI 在日本,因为 SoftBank 和 Perplexity AI 开展了合作 ,所以最近大量的使用 Perplexity ,这一篇文章就总结一下 Perplexity 的优势和使用技巧。