搭建自动化签到网站
很早以前就在用 binux 大佬的 qiandao.today,但后来不知道是用的人多了,还是大佬不怎么维护了,所以后来渐渐地就会登录不上,或者签到失败。干脆直接自己部署一个自己使用。
qiandao 项目是一个使用 Python 编写的自动化签到框架。最早由 Binux 开发,现在项目转到了组织中由 a76yyyy 维护。qiandao 是一个 HTTP 请求定时任务自动执行框架,基于 HAR 和 Tornado 服务。
Docker 部署
docker-compose 配置见 GitHub,克隆项目,直接 docker-compose up -d ,搭配 Nginx Proxy Manager 即可。
我自己搭建的服务如果有兴趣可以加入讨论群组 向我索要地址。
什么是 HAR
[[HAR]] 是 HTTP Archive format 的缩写,即 HTTP 存档格式,一种 JSON 格式的存档格式,用于记录浏览器和网站的交互过程。文件扩展名通常是 .har。签到项目提供了一个基于 Web 页面的 HAR 编辑器,可以通过浏览器录制,然后上传到网站中编辑的方式来快速制作符合自己需求的 HAR 文件。
HAR 文件包含有关网页或应用程序加载过程中所执行的 HTTP 请求和响应的信息。 HAR 文件通常是由浏览器开发工具或类似的工具生成的,可以在许多浏览器中使用。可以使用这些工具来查看网站或应用程序的加载情况,并分析其中的性能问题。
如何获取 HAR 文件
在 Google Chrome 中,可以打开开发人员工具(通常可以通过按 F12 键或在浏览器菜单中选择“更多工具”>“开发人员工具”来访问)。然后,在左侧的菜单中选择“网络”,然后在页面加载过程中会显示所有 HTTP 请求的列表。可以使用“导出为 HAR”按钮将这些请求保存到一个 HAR 文件中。
如何制作 HAR 签到模板
在制作模板时,需要将请求中的 Cookie 替换为双花括号,并且保存,那么通过这个模板创建签到时就会有 Cookie 字段定义。
如何处理 Cloudflare 拦截
api
| api | 地址 | 参数 | 参数是否必须 | 说明 | 用例 |
|---|---|---|---|---|---|
| 时间戳 | http://localhost/util/timestamp | ts | 否 | 默认返回当前时间戳和时间,如果参数带时间戳,返回所对应北京时间 | http://localhost/util/timestamp http://localhost/util/timestamp?ts=1586921249 |
| Unicode 转中文 | http://localhost/util/unicode | content | 是 | 要转码的内容 | http://localhost/util/unicode?content=今日签到:1\u5929\u5ef6\u4fdd |
| Url 转中文 | http://localhost/util/urldecode | content | 是 | 要转码的内容 | http://localhost/util/urldecode?content=签到成功!每日签到获得%2C |
| 正则表达式 | http://localhost/util/regex | data,p | 是 | data:原始数据 p:正则表达式 | http://localhost/util/regex?data=origin_data&p=regex |
| 字符串替换 | http://localhost/util/string/replace | p,s,t | 是 | p:正则表达式 s:要替换的字符串 t:要替换的内容 | http://localhost/util/string/replace?p=regex&t=text_to_replace&s=text |
其他工具
最后
我自己的新建的签到网站,虽然目前只有我一个人用,但是我自己也创建了不少好用的模板,尤其是 PT 站点签到的模板,如果有朋友有需要可以加入 Telegram Group ,然后大家在群里一起讨论怎么充分利用签到程序。
related
reference
使用 Remark42 替换博客的 Disqus 评论系统
前两天用隐身窗口打开自己的博客的时候突然发现 Disqus 评论框上一大片广告,没想到现在 Disqus 已经这样了,并且之前还暴露出过隐私问题。所以就想着什么时候替换掉它。
虽然之前也调研过静态博客的评论系统,但说实话那个时候还没有让我有替换掉 Disqus 的动力,毕竟有一些评论系统是基于 GitHub issue 的,也有一些现在来看比 Disqus 存活的时间都要短,连官网都不存在了。
问题
整理一下 Disqus 目前让我不舒服的一些地方:
- 在评论框上方插入了大片广告
- 正常留言被错误标记,我去 Disqus 后台看有不少正常的留言都被标记为了垃圾留言,而实际上完全没有问题,并且附加的链接也都是合理的,并且 Disqus 没有任何通知。所以也得对过去留了言没有得到回复的读者说声抱歉。
- Disqus 拖慢网页加载速度,用 GTmetrix 跑一下,可以看到一大半是因为 Disqus。

替换了 Disqus 至少可以提升一下访问速度,访客也不会被广告追踪。
Disqus 代替品
所以接下来就研究了一下 Disqus 的代替品,我大致把他们分成了一下几个部分:
- 类似于 Disqus 以中心化的云服务方式提供评论服务,并且兼顾用户隐私,所以基本上都按照访问量来收费,最少的也需要 5$ 一个月,这一类的服务有
- 第二类是以 GitHub issue 作为评论系统的后端,借助 GitHub 开放 API 的能力,使用 issue 来保存博客的评论,这一类评论系统必须要求用户有 GitHub 账户,并且我并不乐意「滥用」GitHub issue 的功能,我认为一个功能就有一个功能设计的目的和意义,GitHub issue 的功能是为项目上报问题或围绕项目展开的讨论而非针对内容本身所以这一类的也就不采用了。这一类的服务有:
- 另外剩下来的一大类是提供自建的方案,需要自己在云服务,Heroku,或者 VPS 上自建的,需要依赖 PostgreSQL 或 SQLite 这类数据库,这一类的评论系统往往实现了评论接口。
- 最后剩下一个比较特殊的,就是 Staticman 它将评论系统的评论部分拆成纯文本的数据,提交到静态博客的项目中,当用户发起评论后会自动提交一个 comment,或者发起一个 Pull Request 将内容保存下来。
综合比较下来因为已经排除了第一、二两类,在自建的服务中 Isso 和 Remark42 看着非常轻便,即使自建,使用 Docker 也非常快。并且 Remark42 更加强大一些,所以就选 Remark42 了。
Remark42 搭建
Remark42 是使用 Go 编写,并且提供了 Docker 部署方式,一个 docker-compose 文件搞定:
version: "3"
services:
remark42:
image: umputun/remark42:latest
container_name: "remark42"
restart: always
logging:
driver: json-file
options:
max-size: "10m"
max-file: "5"
environment:
- REMARK_URL=${URL}
- SITE=${SITE}
- SECRET=${SECRET}
- STORE_TYPE=bolt
- STORE_BOLT_PATH=/srv/var/db
- BACKUP_PATH=/srv/var/backup
- CACHE_TYPE=mem
- DEBUG=true
- AUTH_TELEGRAM=${AUTH_TELEGRAM}
- TELEGRAM_TOKEN=${TELEGRAM_TOKEN}
- AUTH_ANON=true
- ADMIN_PASSWD=${ADMIN_PASSWD}
- VIRTUAL_HOST=${YOUR_DOMAIN}
- VIRTUAL_PORT=8080
- LETSENCRYPT_HOST=${YOUR_DOMAIN}
- LETSENCRYPT_EMAIL=${YOUR_EMAIL}
volumes:
- ${STORAGE_PATH}:/srv/var
networks:
default:
external:
name: nginx-proxy
我使用 nginx-proxy 做域名转发,以及 SSL 证书自动生成。
导入 Disqus 数据
Disqus 提供导出评论到一个压缩包的工具,可以在 Disqus Admin > Setup > Export 找到 1。
docker exec -it remark42 import -p disqus -f /srv/var/xxxx-2021-10-08T12_57_49.488908-all.xml -s site_id
通过以上命令导入。
reference
club 域名宕机近 3 小时故障回顾
刚开始的时候收到了报警,说网站挂了,我的第一反应是 VPS 出问题了,赶紧 SSH 登录上去看,好像都正常。难道是 VPS 网络问题,于是看了看同一台机器上的其他服务,一切都没问题。
然后开始排查为什么登录不上,先看了一 DNS 解析,发现在我本地已经无法给出 DNS 解析的结果了,返回 SERVFAIL。
❯ nslookup www.techfm.club
Server: 192.168.2.1
Address: 192.168.2.1#53
** server can't find www.techfm.club: SERVFAIL
我下意识的还以为遭到 GFW DNS 污染了,用其他地区的 VPS nslookup 了一下发现是同样的错误。
于是我把怀疑点移到了 Cloudflare,但是登录 Cloudflare 发现其他域名都正常,并且查看 Cloudflare 的 status 页面也没有说有服务故障,然后就去 Help 里面想要联系一下客服寻求帮助一下,不过 Cloudflare 的页面做的很人性化,首先提供了自查故障的页面,所以自查了一下,Cloudflare 说:
The authoritative nameservers for techfm.club are set incorrectly. For Cloudflare to activate, your domain registrar must point to the two nameservers provided by Cloudflare as the authoritative servers. Set your authoritative nameservers in your registrar’s admin panel (contact your registrar for support). Review changing your nameservers.
Name servers 服务器设置错误?我今天根本没有动过 Google Domains 的 NS 设置啊。不过还是按照帮助文档中的内容查询了一下域名的 NS,发现真的获取不到 NS 地址了。
einverne@sys ~ % dig techfm.club +trace @1.1.1.1
; <<>> DiG 9.16.1-Ubuntu <<>> techfm.club +trace @1.1.1.1
;; global options: +cmd
. 515539 IN NS a.root-servers.net.
. 515539 IN NS b.root-servers.net.
. 515539 IN NS c.root-servers.net.
. 515539 IN NS d.root-servers.net.
. 515539 IN NS e.root-servers.net.
. 515539 IN NS f.root-servers.net.
. 515539 IN NS g.root-servers.net.
. 515539 IN NS h.root-servers.net.
. 515539 IN NS i.root-servers.net.
. 515539 IN NS j.root-servers.net.
. 515539 IN NS k.root-servers.net.
. 515539 IN NS l.root-servers.net.
. 515539 IN NS m.root-servers.net.
. 515539 IN RRSIG NS 8 0 518400 20211020050000 20211007040000 14748 . Ivt+gf/MP9jMrhxG7kVEO6LfUeGvL6RaeaR4b19+hakqU2FplgG2DSMf ycLHYn2zaBPyyZysSh1AbgWO7L2nRZj5yMQB6A7IFR3ifp1ksCTDbtUf 4X0rzwzZcv2BVbJBsDAjVVdAFxVsnfX6siOx9JLxshe1/JECAaRoXo4X Fl5JTeEN+s+WBZdOShKmvkILGRt9UkMeFton3dIP47ZBvnlgmMGkv9Jw VZHQmzdufQSfta0HtjPwN+/mzlH6nnGs4beqlhsIAttzQALgzcspCjP+ NenqtiXTxg7jvtP8Dy/JkTYbecQX+mcL19ySGDoBkGov2RSfJURdXgrN PN7QZA==
;; Received 1097 bytes from 1.1.1.1#53(1.1.1.1) in 4 ms
club. 172800 IN NS ns1.dns.nic.club.
club. 172800 IN NS ns2.dns.nic.club.
club. 172800 IN NS ns3.dns.nic.club.
club. 172800 IN NS ns4.dns.nic.club.
club. 172800 IN NS ns6.dns.nic.club.
club. 172800 IN NS ns5.dns.nic.club.
club. 86400 IN DS 29815 8 2 3B67F899B57454E924DD1EFAE729B8741D61BA9BC8D76CD888919E5C 0950CA23
club. 86400 IN DS 29815 8 1 7F2B8E1D8B715BB382111A84F4552A599462017A
club. 86400 IN RRSIG DS 8 1 86400 20211020050000 20211007040000 14748 . AQaz5Kne3pWNMUOyrCJ67y3q8mN0fe2cukuTY0oiyMJNi/OuL7eGxqiq 3RlfRL+Y9+50jOkEdw6170xKqeU/XAdyYRI9R6xQYTCZE2y+YSnHW81k PGrFVb4N8RfmD8/AX0RckRMzu4DqokMXnfYd2WFGqrNJtvWMGxDkdkxU PfJv0jHHBzV0s1YyS/UuFC9joaYGeZ8L81HVeQV0aZn7pz3+u794OQgf 0SpqbiiSuYJDGXvldA7ZkXA9Nd+pQAzd+DjJK8F4b68cuNrlmS3W923D iVUqFfPXXqx03pNuUfJPp7XAZNGsGrfrMEQSSl0LI01ct7FM2YilJkUx fF+thg==
couldn't get address for 'ns1.dns.nic.club': failure
couldn't get address for 'ns2.dns.nic.club': failure
couldn't get address for 'ns3.dns.nic.club': failure
couldn't get address for 'ns4.dns.nic.club': failure
couldn't get address for 'ns6.dns.nic.club': failure
couldn't get address for 'ns5.dns.nic.club': failure
dig: couldn't get address for 'ns1.dns.nic.club': no more
einverne@sys ~ % dig techfm.club +trace @1.1.1.1
; <<>> DiG 9.16.1-Ubuntu <<>> techfm.club +trace @1.1.1.1
;; global options: +cmd
. 511583 IN NS a.root-servers.net.
. 511583 IN NS b.root-servers.net.
. 511583 IN NS c.root-servers.net.
. 511583 IN NS d.root-servers.net.
. 511583 IN NS e.root-servers.net.
. 511583 IN NS f.root-servers.net.
. 511583 IN NS g.root-servers.net.
. 511583 IN NS h.root-servers.net.
. 511583 IN NS i.root-servers.net.
. 511583 IN NS j.root-servers.net.
. 511583 IN NS k.root-servers.net.
. 511583 IN NS l.root-servers.net.
. 511583 IN NS m.root-servers.net.
. 511583 IN RRSIG NS 8 0 518400 20211020050000 20211007040000 14748 . Ivt+gf/MP9jMrhxG7kVEO6LfUeGvL6RaeaR4b19+hakqU2FplgG2DSMf ycLHYn2zaBPyyZysSh1AbgWO7L2nRZj5yMQB6A7IFR3ifp1ksCTDbtUf 4X0rzwzZcv2BVbJBsDAjVVdAFxVsnfX6siOx9JLxshe1/JECAaRoXo4X Fl5JTeEN+s+WBZdOShKmvkILGRt9UkMeFton3dIP47ZBvnlgmMGkv9Jw VZHQmzdufQSfta0HtjPwN+/mzlH6nnGs4beqlhsIAttzQALgzcspCjP+ NenqtiXTxg7jvtP8Dy/JkTYbecQX+mcL19ySGDoBkGov2RSfJURdXgrN PN7QZA==
;; Received 1097 bytes from 1.1.1.1#53(1.1.1.1) in 4 ms
club. 172800 IN NS ns5.dns.nic.club.
club. 172800 IN NS ns6.dns.nic.club.
club. 172800 IN NS ns3.dns.nic.club.
club. 172800 IN NS ns1.dns.nic.club.
club. 172800 IN NS ns2.dns.nic.club.
club. 172800 IN NS ns4.dns.nic.club.
club. 86400 IN DS 29815 8 2 3B67F899B57454E924DD1EFAE729B8741D61BA9BC8D76CD888919E5C 0950CA23
club. 86400 IN DS 29815 8 1 7F2B8E1D8B715BB382111A84F4552A599462017A
club. 86400 IN RRSIG DS 8 1 86400 20211020050000 20211007040000 14748 . AQaz5Kne3pWNMUOyrCJ67y3q8mN0fe2cukuTY0oiyMJNi/OuL7eGxqiq 3RlfRL+Y9+50jOkEdw6170xKqeU/XAdyYRI9R6xQYTCZE2y+YSnHW81k PGrFVb4N8RfmD8/AX0RckRMzu4DqokMXnfYd2WFGqrNJtvWMGxDkdkxU PfJv0jHHBzV0s1YyS/UuFC9joaYGeZ8L81HVeQV0aZn7pz3+u794OQgf 0SpqbiiSuYJDGXvldA7ZkXA9Nd+pQAzd+DjJK8F4b68cuNrlmS3W923D iVUqFfPXXqx03pNuUfJPp7XAZNGsGrfrMEQSSl0LI01ct7FM2YilJkUx fF+thg==
couldn't get address for 'ns5.dns.nic.club': failure
couldn't get address for 'ns6.dns.nic.club': failure
couldn't get address for 'ns3.dns.nic.club': failure
couldn't get address for 'ns1.dns.nic.club': failure
couldn't get address for 'ns2.dns.nic.club': failure
couldn't get address for 'ns4.dns.nic.club': failure
dig: couldn't get address for 'ns5.dns.nic.club': no more
并且 club 默认的 6 台 NS 全部都返回 failure。而正常的域名会返回默认配置的 NS:
einverne@sys ~ % dig gtk.pw +trace @1.1.1.1
; <<>> DiG 9.16.1-Ubuntu <<>> gtk.pw +trace @1.1.1.1
;; global options: +cmd
. 518159 IN NS a.root-servers.net.
. 518159 IN NS b.root-servers.net.
. 518159 IN NS c.root-servers.net.
. 518159 IN NS d.root-servers.net.
. 518159 IN NS e.root-servers.net.
. 518159 IN NS f.root-servers.net.
. 518159 IN NS g.root-servers.net.
. 518159 IN NS h.root-servers.net.
. 518159 IN NS i.root-servers.net.
. 518159 IN NS j.root-servers.net.
. 518159 IN NS k.root-servers.net.
. 518159 IN NS l.root-servers.net.
. 518159 IN NS m.root-servers.net.
. 518159 IN RRSIG NS 8 0 518400 20211020050000 20211007040000 14748 . Ivt+gf/MP9jMrhxG7kVEO6LfUeGvL6RaeaR4b19+hakqU2FplgG2DSMf ycLHYn2zaBPyyZysSh1AbgWO7L2nRZj5yMQB6A7IFR3ifp1ksCTDbtUf 4X0rzwzZcv2BVbJBsDAjVVdAFxVsnfX6siOx9JLxshe1/JECAaRoXo4X Fl5JTeEN+s+WBZdOShKmvkILGRt9UkMeFton3dIP47ZBvnlgmMGkv9Jw VZHQmzdufQSfta0HtjPwN+/mzlH6nnGs4beqlhsIAttzQALgzcspCjP+ NenqtiXTxg7jvtP8Dy/JkTYbecQX+mcL19ySGDoBkGov2RSfJURdXgrN PN7QZA==
;; Received 1097 bytes from 1.1.1.1#53(1.1.1.1) in 0 ms
pw. 172800 IN NS ns1.nic.pw.
pw. 172800 IN NS ns6.nic.pw.
pw. 172800 IN NS ns2.nic.pw.
pw. 172800 IN NS ns5.nic.pw.
pw. 86400 IN DS 26645 7 2 7EF397EDF4D7CA228C0F5111F5E1696CDBF279C0B6AFA48FC7E71A12 E07E5880
pw. 86400 IN DS 26645 7 1 58EE332D303E2A64B7449C43AB770DAA1CA74C40
pw. 86400 IN RRSIG DS 8 1 86400 20211020050000 20211007040000 14748 . ZKSbdDYOAuZYYX7LFUI6fZn6GtHJHrA04nENEPp6oGcGIh7IliGFyJai MkV6OfwYhyk6npWLaSNkYaU2Kv9mif6Bu1RBPbGbVaQphhFeqxmFRtf8 5B/Q+V6dYZJ8cnMZEMeuqlvfBzT6m+Dv6zsgvJ3dZ2Yly9ehkd9i2pXT F9Hv4mj+35B4r6H0/e1hlD8a0AmMITFPIAZ+ZQLkGaCf+d8jAP9oMIEG 2uezoE4PLybmCsovtT/zFcyrIXv0CLphN1Ky6yCkwu1nDMvWi3eoyunK ANPojlC6i3OCa7zmBuR+4qJWQeb9o5mqz+QXHkrPY/LEK8Vs9+t+xuzG ZzRc6Q==
;; Received 686 bytes from 192.5.5.241#53(f.root-servers.net) in 288 ms
gtk.pw. 3600 IN NS vera.ns.cloudflare.com.
gtk.pw. 3600 IN NS phil.ns.cloudflare.com.
5njihdv29htfqesp4s66h5ia7mau40g2.pw. 3600 IN NSEC3 1 1 1 - 5NJN8B0GFH3C6U7E54SIUSFMKRA3164C NS SOA RRSIG DNSKEY NSEC3PARAM
5njihdv29htfqesp4s66h5ia7mau40g2.pw. 3600 IN RRSIG NSEC3 7 2 3600 20211014233500 20210914093758 20159 pw. cGysLwA8FKKv9t+B0ywJA1yUNvytR6vINedx6Lz4ZPwsdBX0DTkn0OUM xR97Mxo58SoGCzTImM8JFsXJGid6j6txWh5KYN0NsmOd52sAOYXTz6uz m/fTDFMIXdLp8XJeRP8hGGAsdd7W7dhQTo8r4V1Rsc1JT3n33AEX7CAq Z5g=
vum0mlvs55o2lfpa00pfb93sl2dc98de.pw. 3600 IN NSEC3 1 1 1 - VUMSNHHGG0TDGRB3VN24B7GKEAA1IVGG TXT RRSIG
vum0mlvs55o2lfpa00pfb93sl2dc98de.pw. 3600 IN RRSIG NSEC3 7 2 3600 20211018221437 20210918161358 20159 pw. BPjMNyd1u4ci+m+FkCaVI+nW6gA+MPNPtNHdSJWwmCJN0GqYVgFNvj97 qTI1Jc/TiorDmURxE7zORU5IaI4K6XJG2ckpiq6xw+khy850dvAs2WVE ZI+uDc+nX4yFj7pvDJBiiNZR+Z9yAtDdvm1EomB0E91KBnGdZbBhYOsd qJk=
;; Received 601 bytes from 212.18.249.12#53(ns6.nic.pw) in 16 ms
gtk.pw. 300 IN A 104.21.51.157
gtk.pw. 300 IN A 172.67.182.127
;; Received 67 bytes from 2606:4700:50::adf5:3a93#53(vera.ns.cloudflare.com) in 0 ms
立马登录 Google Domains 查看 NS 设置,页面上还是 Cloudflare 提供的两个 NS 服务器地址,看着也没有问题,所以又联系了 Google Domains 的 Help,Google Domains 的帮助人员还是非常快的就能联系上,帮忙查询了一下 NS 设置,用 https://www.whatsmydns.net/#NS/ 查询了一下了全球的 NS,全部失败:
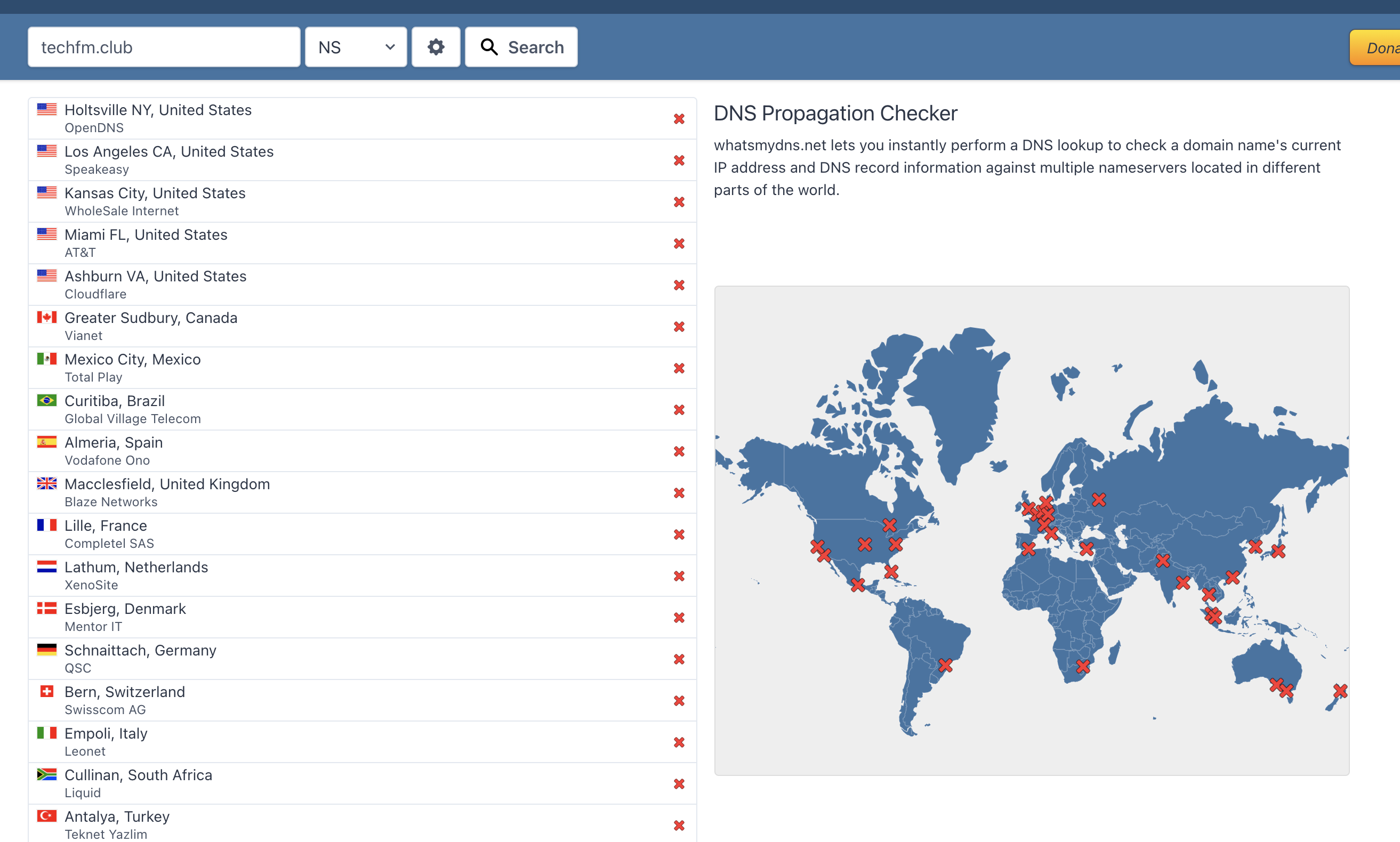
客服解释说需要时间等待配置传播生效,但问题在于我没有更改过任何配置。这个时候我就有看到相关的消息出来(source1, source2,source3),这才发现不是我一个人的问题。无奈好像我也无法解决,只能等上游解决了。
终于从 10月7号下午 6:52 开始,到 9:23 分为止,宕机了近 3 小时。

原因分析
.club 通用顶级域名(gTLD) 的 name server 无响应,所有 6 台官方的服务器 get.club 都无响应,所以下游的 DNS 服务器都无法解析。
This morning there was a DNS service disruption impacting .Club websites. The issue has now been resolved. We apologize for any inconvenience this may have caused.
— .CLUB Domains (@getDotClub) October 7, 2021
GoDaddy Registry tweeted:
This morning there was a DNS service disruption impacting .club websites. The issue has now been resolved. We apologize for any inconvenience this may have caused.
— GoDaddy Registry (@GoDaddyRegistry) October 7, 2021
在 JetBrains IntelliJ IDEA 中使用 GitHub Copilot
虽然之前早早的就把 GitHub Copilot 在 Visual Studio Code 上用了起来,但是平时使用的 IDE 还是 IntelliJ IDEA 比较多,今天刷 Twitter 看到有人分享说在 IntelliJ IDEA 上可以通过添加 preview 的 plugin 源来添加 GitHub Copilot 插件支持,搜了一下果然可以。
具体的教程可以参考GitHub。
主要的步骤就是通过在插件管理里面添加 Plugin repository:
https://plugins.jetbrains.com/plugins/super-early-bird/list
然后重启之后搜索 github copilot 安装启用。不过需要注意的是该插件只有在 IDEA 2021.2 及以上版本中才能安装。
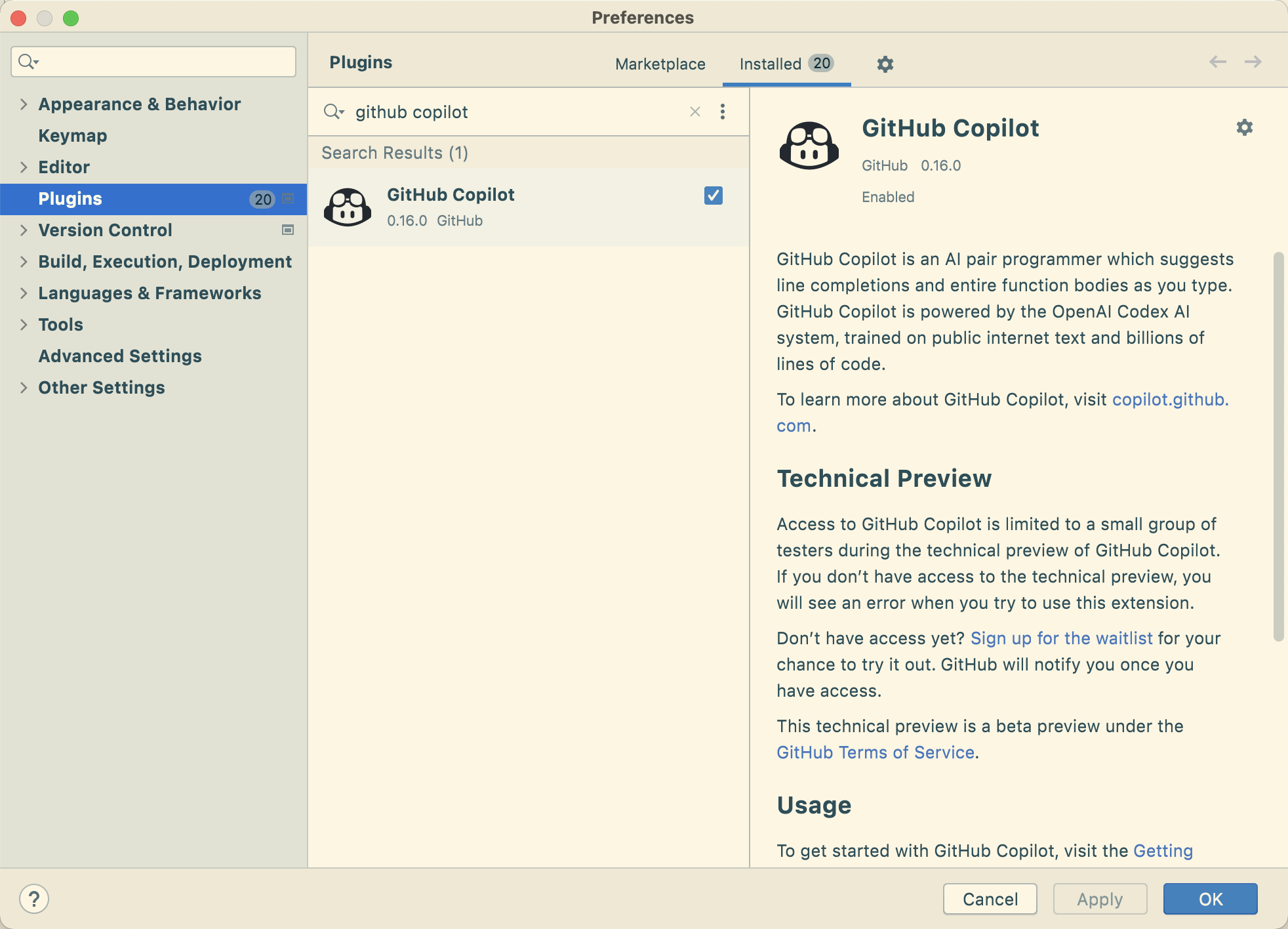
安装之后在 Tools -> GitHub Copilot 中登录,启用。
快捷键
记录整理一些常用的快捷键。在默认情况下,Tab 就是选中默认的。Esc 是取消建议。
- Option(macOS)/Alt(Windows/Linux) +
[或]可以选择上一条或下一条建议 - Option(macOS)/Alt(Windows/Linux) + Enter 可以查看更多的建议
- Trigger inline suggestion: Alt +
\or Option +\。
Rime 输入法中的快捷键
今天在整理 Rime 插件使用的时候,想起来整理一下 Rime 输入法的快捷键。
在之前整理 Rime 基础配置 的时候稍微带到一下。
通过配合这些快捷键可以在输入很长一段句子的时候提升体验。
ctrl+grave(grave) tab 键上面,1 左边的那个键用来切换 Rime 输入方案shift+delete删除选中的候选词,一般用来调整不希望在候选词前的词ctrl+ n/p上下翻页选择候选词Ctrl+b/f类似于左箭头,右箭头,可以快速调整输入,在输入很长一段后调整之前的输入时非常有效Ctrl+a/e贯标快速跳转到句首或者句末Ctrl+d删除光标后内容Ctrl+h回退,删除光标前内容Ctrl+g清空输入Ctrl+k删词,等效于 Shift + delete(macOS 上可以使用 ⌘+k)-/+或者tab来翻页
更多的快捷键可以在 default.yaml 配置中看到。
key_binder:
bindings:
- {accept: "Control+p", send: Up, when: composing}
- {accept: "Control+n", send: Down, when: composing}
- {accept: "Control+b", send: Left, when: composing}
- {accept: "Control+f", send: Right, when: composing}
- {accept: "Control+a", send: Home, when: composing}
- {accept: "Control+e", send: End, when: composing}
- {accept: "Control+d", send: Delete, when: composing}
- {accept: "Control+k", send: "Shift+Delete", when: composing}
- {accept: "Control+h", send: BackSpace, when: composing}
- {accept: "Control+g", send: Escape, when: composing}
- {accept: "Control+bracketleft", send: Escape, when: composing}
- {accept: "Alt+v", send: Page_Up, when: composing}
- {accept: "Control+v", send: Page_Down, when: composing}
- {accept: ISO_Left_Tab, send: Page_Up, when: composing}
- {accept: "Shift+Tab", send: Page_Up, when: composing}
- {accept: Tab, send: Page_Down, when: composing}
- {accept: minus, send: Page_Up, when: has_menu}
- {accept: equal, send: Page_Down, when: has_menu}
- {accept: comma, send: Page_Up, when: paging}
- {accept: period, send: Page_Down, when: has_menu}
- {accept: "Control+Shift+1", select: .next, when: always}
- {accept: "Control+Shift+2", toggle: ascii_mode, when: always}
- {accept: "Control+Shift+3", toggle: full_shape, when: always}
- {accept: "Control+Shift+4", toggle: simplification, when: always}
- {accept: "Control+Shift+5", toggle: extended_charset, when: always}
- {accept: "Control+Shift+exclam", select: .next, when: always}
- {accept: "Control+Shift+at", toggle: ascii_mode, when: always}
- {accept: "Control+Shift+numbersign", toggle: full_shape, when: always}
- {accept: "Control+Shift+dollar", toggle: simplification, when: always}
- {accept: "Control+Shift+percent", toggle: extended_charset, when: always}
- {accept: "Shift+space", toggle: full_shape, when: always}
- {accept: "Control+period", toggle: ascii_punct, when: always}
自定义快捷键
在上面的配置中可以看到 Rime 默认就定义了非常多的快捷键绑定,并且这些快捷键都可以通过配置改变。
这里做一个例子,比如平时用 Vim 较多,想要更换成更加舒服的 Vim 绑定,可以在 Rime 配置根目录中 vi default.custom.yaml 中配置:
# default.custom.yaml
patch:
# 其他配置...
key_binder:
bindings:
- { when: has_menu, accept: "Control+k", send: Page_Up }
- { when: has_menu, accept: "Control+j", send: Page_Down }
- { when: has_menu, accept: "Control+h", send: Left }
- { when: has_menu, accept: "Control+l", send: Right }
这样就可以使用 Ctrl+j/k 来上下翻页,而使用 Ctrl+h/l 来左右切换候选词。不过我个人还是还是习惯默认设置的快捷键。
配置说明
在上面的例子中可以看到 bindings 配置中有三个配置选项。每一条 binding 下面可以包含:
- accept,实际接受的按键
- send,输出效果
- toggle,切换开关
- when,作用范围
toggle 的候选项有:
ascii_mode
ascii_punct
full_shape 全角字符
simplification 繁简
extended_charset
when 可以接受的选项有:
paging 翻页
has_menu 操作候选项用
composing 操作输入码用
always 全域
accept 和 send 可用字段除 A-Za-z0-9 外,还可以包含键盘上实际的所有按键:
BackSpace 退格
Tab 水平定位符
Linefeed 换行
Clear 清除
Return 回車
Pause 暫停
Sys_Req 印屏
Escape 退出
Delete 刪除
Home 原位
Left 左箭頭
Up 上箭頭
Right 右箭頭
Down 下箭頭
Prior、Page_Up 上翻
Next、Page_Down 下翻
End 末位
Begin 始位
Shift_L 左Shift
Shift_R 右Shift
Control_L 左Ctrl
Control_R 右Ctrl
Meta_L 左Meta
Meta_R 右Meta
Alt_L 左Alt
Alt_R 右Alt
Super_L 左Super
Super_R 右Super
Hyper_L 左Hyper
Hyper_R 右Hyper
Caps_Lock 大寫鎖
Shift_Lock 上檔鎖
Scroll_Lock 滾動鎖
Num_Lock 小鍵板鎖
Select 選定
Print 列印
Execute 執行
Insert 插入
Undo 還原
Redo 重做
Menu 菜單
Find 蒐尋
Cancel 取消
Help 幫助
Break 中斷
space
exclam !
quotedbl "
numbersign #
dollar $
percent %
ampersand &
apostrophe '
parenleft (
parenright )
asterisk *
plus +
comma ,
minus -
period .
slash /
colon :
semicolon ;
less <
equal =
greater >
question ?
at @
bracketleft [
backslash
bracketright ]
asciicircum ^
underscore _
grave `
braceleft {
bar |
braceright }
asciitilde ~
KP_Space 小鍵板空格
KP_Tab 小鍵板水平定位符
KP_Enter 小鍵板回車
KP_Delete 小鍵板刪除
KP_Home 小鍵板原位
KP_Left 小鍵板左箭頭
KP_Up 小鍵板上箭頭
KP_Right 小鍵板右箭頭
KP_Down 小鍵板下箭頭
KP_Prior、KP_Page_Up 小鍵板上翻
KP_Next、KP_Page_Down 小鍵板下翻
KP_End 小鍵板末位
KP_Begin 小鍵板始位
KP_Insert 小鍵板插入
KP_Equal 小鍵板等於
KP_Multiply 小鍵板乘號
KP_Add 小鍵板加號
KP_Subtract 小鍵板減號
KP_Divide 小鍵板除號
KP_Decimal 小鍵板小數點
KP_0 小鍵板0
KP_1 小鍵板1
KP_2 小鍵板2
KP_3 小鍵板3
KP_4 小鍵板4
KP_5 小鍵板5
KP_6 小鍵板6
KP_7 小鍵板7
KP_8 小鍵板8
KP_9 小鍵板9
通过上面的组合就可以实现非常多自定义的功能,比如有人喜欢将 ; 绑定到第二个候选词:
{ when: has_menu, accept: ";", send: 2 }
这样当候选词出现在第二位时,直接按下 ; 就可以输入。
reference
用 Gatsby 写了一个券商推荐注册列表
放假在家,刚好刷 Twitter 的时候看到有人写了一个券商注册的页面,一个简单的列表,挂上了目前常用的美港股做新人推荐,顺便就看了一下源码,发现使用 [[Gatsby]] 和 [[TailwindCSS]] 写的,于是就抱着学习的态度,上手了一下 Gatsby,简单的了解了一下 Gatsby 也是一个静态网页生成器,用来 React 和 [[GraphQL]]。而 [[TailwindCSS]] 是一个 CSS 框架,通过简单的 class 就能实现不错的界面效果。
从了解一个新的技术,到上手的过程就不多说了,官网的新手教程非常详细。这里就想记录一下中间遇到的一些问题,以及解决的过程。以及结合之前看过的 [[费曼学习法]] 聊一聊学习的过程。
费曼学习法
首先先说一下什么叫做费曼学习法,如果用简单的话来说就是将复杂的知识简单化,用最通俗的语言去解释。
费曼学习法的具体内容很细致,但如果将学习划分几个步骤来的话,可以简化成这样几部:
- 确定学习目标
- 理解学习对象
- 以输出代替输入
- 回顾
- 简化学习内容,再吸收
套用我了解学习 Gatsby 的过程,首先我的目标非常明确,就是制作一个简单的页面可以展示列表。
理解学习对象,在我看来就是通过查看其官网,文档,以及简单的 Wiki 了解 Gatsby 是什么,可以做什么。我这里要了解的内容有两部分,一个便是静态网站生成器 Gatsby,另一个是 CSS 框架 [[TailwindCSS]]。
静态网站生成器和 CSS 框架两个概念都不是很陌生,类似的技术也都非常多,当前的这个博客就是 Ruby 下的 Jekyll 生成的静态页面,而这个博客用的就是 Bootstrap CSS 框架。所以使用类比就能大致的对其有一定的了解。
第三步,用输出代替输入,这就是实践的部分。当然也是个人认为最重要的一步,再以前我往往就是忽视了这一步。所以直接根据官网的教程,先实现一遍新手任务,然后根据我的需要,先从官网初始化了一个最基本的项目,然后在本地跑起来,引入 Tailwind CSS,然后尝试对页面进行修改,先构建了一个基本的样式,将图中的一个样式实现,研究如何获取数据,如何实现循环。
最后定下的方案就是通过 YAML 文件 ,将页面中需要显示的内容配置在其中,因为 Gatsby 通过插件的方式可以非常方便的引入不同类型的数据源,所以看一下插件的介绍。在实践中花了最多时间的就是将图片动态的显示出来,直接使用 StaticImage 只能将固定的图片显示出来。所以继续阅读官网的文档。以 image 为关键字把所有搜出来的结果都看了,还是一头雾水,并且昨天状态也不太好就直接先睡了。今天起来从原理上简单的了解了一下 Gatsby 的插件,然后逐渐就有了一个思路。
在 Gatsby 中有三类插件:
- 数据源插件,一般名字中会带 source,数据源插件负责从外部数据获取,然后将数据放在数据层中,方便应用通过 GraphQL 来获取使用
- 数据转化插件, 名字中带 transformer,转换特定的格式,比如将 markdown 文件内容转换为对象
- 功能插件,一般就叫做某某 plugin
我已经通过 gatsby-transformer-yaml 将 YAML 文件内容可以在界面中读取,剩下的就是将 YAML 配置中配置的文件路径在界面中展示出来,Gatsby 这一块做过一些 API 的调整,需要通过 GraphQL 查询出来之后再使用 GatsbyImage 来展示。
整个上面的过程完成之后就大致做了一个类似的列表页。
回到费曼学习法的第四步,回顾,这一步也是正是我当前正在做的事情。
第五步,简化学到的内容,如果让我现在再去回忆我学到了什么,我脑海里首先会蹦出几个关键字,不是 Gatsby,也不是 [[TailwindCSS]],而是 React,GraphQL,基础的 CSS 长宽模型。我之前没有接触过 React,但是在使用的过程中大概的了解了其模块化的设计,并且界面和数据分离,通过 GraphQL 做数据绑定和交互整个这个过程就形成了 Gatsby 这个技术。而在使用 Tailwind CSS 的过程中最费我时间的就是调整页面中元素的位置。如果之前学习基础 CSS 的时候能够对 margin,padding 有更多的了解就好了。
什么是好的学习
在费曼学习法这本书中对学习的解释,让我对[[教育]]有了更加深刻的理解。上周末在吃饭的时候,朋友顺口聊起了什么是你认为的「好的教育」,在去探讨什么是「好的教育」之前,什么是学习,在过去的时间里,我常常认为记得比别人多,学的比人快就是好的学习。但学习,不是去比拼知识的储备,也不是去竞争学位的高低,而是思维方式的培养。学习不是为了记住什么,而是通过学习建立自己行之有效的思维方式,然后将知识应用到实际生活中去解决问题。那么回到我认为的「好的教育」,学习如果是主动发起的,那么往往会收获不错的结果。那么好的教育就是要让人激发出学习的兴趣。
在没有了解 Gatsby 之前我对静态网站的印象就停留在了 markdown 文件的渲染,但是我在了解的过程中发现 Gatsby 使用了一套不一样的实现思路,通过 GraphQL 的帮助,Gatsby 让 markdown 成为了其可以选择的一个数据源,只要做一层数据转换,那么其内容可以从任何的数据源中获取,比如从 WordPress 的数据库,从其他任何 CMS 的数据源。这样就使得 Gatsby 拥有了其他静态网站不一样的能力。
最后
代码在 https://github.com/einverne/broker 界面在 https://broker.einverne.info。
推荐几个 Rime 插件
切换到 Rime 输入法也好多年了,陆陆续续积累了不少的配置和词库,不过最近看到有朋友在 GitHub 上 star 了一个 Rime 的配置,点进去了一下,让我眼前一亮的是 Rime 通过插件的方式实现了一些非常不错的特性,虽然之前也陆陆续续的配置过 lua 扩展,但是这次看到还能让 Rime 加载预先训练的统计语言模型,所以就再次激起了我的兴趣。
之前的几篇文章,如果感兴趣也可以去看看:
- Linux 和 macOS 下配置 Rime
- 利用 imewlconverter 制作 Rime 词库
- 配置 Rime 输入法输入韩语
- 配置 Rime 在 Vim 下退出编辑模式时自动切换成英文输入法
- 手工编译安装 macOS 下的 Rime(鼠须管)
接下来就整理一下目前我用到的三个 Rime 插件。
librime-lua
librime-lua 是我发现的第一个插件,之前看到有人提的一个 Feature Request 说到,能不能通过输入 date 或 「rq」这样的短语自动在候选词中出现当前的日期,后来发现果然可以。librime-lua 就是用来实现这样的功能的。
librime-lua 通过 Lua 扩展了 Rime 的能力,使得用户可以编写一定的 Lua 脚本来更改 Rime 候选词的结果。最常见的使用方式,比如当输入 date 的时候,在候选词中直接显示出当前的日期。
插件地址:https://github.com/hchunhui/librime-lua
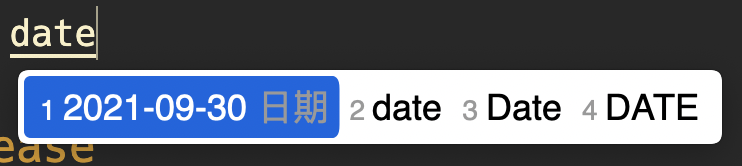
安装 librime-octagram 插件
librime-octagram 可以让 Rime 使用训练好的统计语言模型。
插件地址: https://github.com/lotem/librime-octagram
安装过程也比较简单,把插件以及模型放到 Rime 的配置文件夹中,然后在输入法配置方案,比如小鹤双拼 double_pinyin_flypy.custom.yaml 中加入:
patch:
__include: grammar:/hant
如果之前有别的 patch,直接加入 __include 那一行即可。然后重新部署 Rime 输入法。
可以通过如下的方式验证是否安装成功,直接一次性输入下面的句子:
- 各個國家有各個國家的國歌
- 充滿希望的跋涉比到達目的地更能給人樂趣

BlindingDark/rime-lua-select-character
这一个以词定字的插件是在这一次再学习的过程中发现的,在某些特定的时候,往往是通过组词去输入某个单字的,因为汉语中同音字还是很多的,如果只用拼音输入一个字的话可能会需要翻页很多次才能找到对的那个字,但是如果这个字出现在词语里面可能可以一次性命中,这个插件就是为了解决这个问题的。
以词定字插件可以让你在输入一个词组后,选取这个词组的开头或结尾的一个字直接上屏,比如想要打“嫉”这个字,可以先打“嫉妒”再按 [ 键选择第一个字,如果要输入词语的第二个字,可以在词语出现之后按下 ]。
插件地址:https://github.com/BlindingDark/rime-lua-select-character
在这个模式下,当候选词出现在第二个的时候,我就使用 Tab 来将候选词位置挪到第二位,然后使用 [ 或 ] 选择。不过默认情况下 Tab 绑定的快捷键是翻页:
- {accept: Tab, send: Page_Down, when: composing}
所以需要在 default.custom.yaml 中做一下调整:
patch:
key_binder:
bindings:
- {accept: "Control+p", send: Up, when: composing}
- {accept: "Control+n", send: Down, when: composing}
- {accept: "Control+b", send: Left, when: composing}
- {accept: "Control+f", send: Right, when: composing}
- {accept: "Control+a", send: Home, when: composing}
- {accept: "Control+e", send: End, when: composing}
- {accept: "Control+d", send: Delete, when: composing}
- {accept: "Control+k", send: "Shift+Delete", when: composing}
- {accept: "Control+h", send: BackSpace, when: composing}
- {accept: "Control+g", send: Escape, when: composing}
- {accept: "Control+bracketleft", send: Escape, when: composing}
- {accept: "Alt+v", send: Page_Up, when: composing}
- {accept: "Control+v", send: Page_Down, when: composing}
- {accept: ISO_Left_Tab, send: Page_Up, when: composing}
- {accept: "Shift+Tab", send: Page_Up, when: composing}
- {accept: Tab, send: Page_Down, when: composing}
- {accept: Tab, send: Right, when: has_menu}
- {accept: minus, send: Page_Up, when: has_menu}
- {accept: equal, send: Page_Down, when: has_menu}
- {accept: comma, send: Page_Up, when: paging}
- {accept: period, send: Page_Down, when: has_menu}
- {accept: "Control+Shift+1", select: .next, when: always}
- {accept: "Control+Shift+2", toggle: ascii_mode, when: always}
- {accept: "Control+Shift+4", toggle: simplification, when: always}
- {accept: "Control+Shift+5", toggle: extended_charset, when: always}
- {accept: "Control+Shift+exclam", select: .next, when: always}
- {accept: "Control+Shift+at", toggle: ascii_mode, when: always}
- {accept: "Control+Shift+numbersign", toggle: full_shape, when: always}
- {accept: "Control+Shift+dollar", toggle: simplification, when: always}
- {accept: "Control+Shift+percent", toggle: extended_charset, when: always}
- {accept: "Control+period", toggle: ascii_punct, when: always}
注意其中的
- {accept: Tab, send: Right, when: has_menu}
这样就可以使用 Tab 来切换候选词了。更多的快捷键自定义可以查看这篇文章。
总结
使用这些插件请保证:
- 鼠须管在 0.12.0 及以上版本
- Linux 需根据需要自行编译安装 librime
- Windows 没有在用,管不了了
Traefik 入门使用
Traefik 是什么
Traefik (音同 traffic),是一个 Cloud Native 的 HTTP reverse proxy(反向代理) 和 load balancer(负载均衡),反向代理服务器就是可以拦截流量并根据规则把流量导到特定的服务上。
在没有 [[Traefik]] 之前,如果在 orchestrator (比如 Swarm 或 Kubernetes) 或 service registry(比如 etcd 或 consul)下开发了一系列的微服务,并要让用户可以访问这些服务,你可能需要手动配置一个反向代理。传统的反向代理服务器(比如 Nginx)需要为每一个子域名到微服务服务进行配置。在一个每一天需要进行很多次增加,移除,升级,扩容的微服务环境下,传统的配置方式(基于配置文件)会变得非常繁琐。
Traefik 可以很好的和现存的基础架构结合到一起,包括 Docker, Swarm mode, Kubernetes, Marathon, Consul, Etcd, Rancher, Amazon ECS 等等
Traefik 会监听 service registry/orchestrator API 并且立即产生一个路由规则,这样微服务可以直接连接到外部的世界,不再需要额外的干预。
Kubernetes 负责把 Pod 容器自动分配到 Node 节点处理。
功能:
- 持续的更新配置,无需重启 Traefik 即可更新配置
- 自动的服务发现与负载均衡
- 支持多样的负载均衡算法
- 完美支持
docker基于label配置 - 借助 Let’s Encrypt 实现 HTTPS
- Circuit breakers, retry
- 通过网页界面查看路由
Websocket,HTTP/2,GRPCready- metrics 的支持,支持对
prometheus和k8s集成 - 提供监控指标(Rest, Prometheus, Datadog, Statsd, InfluxDB)
- 访问日志(JSON, CLF)
- 提供 Rest API
- 单一的二进制文件(Go 编写),提供官方的 docker 镜像
- Dashboard 界面
概念
在进一步学习 Traefik 之前有几个在 Traefik 中的概念需要提前了解一下。
- Providers 是 Traefik 的服务提供方,可以是 orchestrators 也可以是容器引擎,cloud prividers 或者 key-values 存储。Traefik 需要依赖这些服务的 APIs 来自动发现服务和路由,然后动态的更新路由。
- Entrypoints 监听传入的流量,接口请求的端口
- Routers 分析请求,将请求连接到对应的服务
- Services,将请求转发给应用(load balancing),配置如何将流量最终传入这些 Services
- Middlewares ,中间件,用来修改请求或根据请求来做判断(authentication,rate limiting,headers),Middlewares 附加在路由上,在请求发送到服务之前(或者在服务响应发送到客户端之前)对请求进行调整
Traefik 是如何发现服务的?
Traefik 能够通过 cluster API 自动发现服务,在 Traefik 的配置中,被称为 provider。比如 provider 配置了 Docker,那么 Traefik 会自动根据 Docker 提供的 API 来获取发现服务,并自动根据配置更新路由策略。
在 Docker 环境下使用 docker-compose 安装使用
为了了解最基本的使用,最好的方法就是实践自己启动一下。
version: '3'
services:
traefik:
container_name: traefik
image: traefik:latest
restart: always
command: --api.insecure=true --providers.docker
ports:
- "80:80"
- "443:443"
- "8080:8080"
volumes:
- /var/run/docker.sock:/var/run/docker.sock:ro
- ./ssl/:/data/ssl/:ro
- ./traefik.yml:/etc/traefik.yml:ro
- ./config/:/etc/traefik/config/:ro
# 先创建外部网卡
# docker network create traefik
networks:
traefik:
external: true
启动之后可以访问
- http://localhost:8080/api/rawdata 检查 Traefik 暴露的 API rawdata
上面的方式开启了 Traefik 的 Dashboard,可以直接访问 8080 端口。
然后使用 whoami 镜像做一下验证,该镜像会将请求的 header 信息输出在请求结果中。
version: '3'
services:
whoami:
# A container that exposes an API to show its IP address
image: traefik/whoami
labels:
- "traefik.enable=true"
# 设置Host 为 whoami.docker.localhost 进行域名访问
- "traefik.http.routers.whoami.rule=Host(`whoami.docker.localhost`)"
# 使用已存在的 traefik 的 network
networks:
default:
external:
name: traefik
当 whoami 的服务启动之后 Traefik 会自动根据 label 的配置,然后将 whoami.docker.localhost 的请求自动转发到 whoami 这个服务中。
然后修改一下本地的 /etc/hosts 文件,增加
127.0.0.1 whoami.docker.localhost
然后用浏览器访问 http://whoami.docker.localhost 就可以看到 whoami 这个服务的返回。
或者直接使用 curl 请求:
❯ curl http://whoami.docker.localhost/
Hostname: 20f1d26a6db0
IP: 127.0.0.1
IP: 172.30.0.3
RemoteAddr: 172.30.0.2:49750
GET / HTTP/1.1
Host: whoami.docker.localhost
User-Agent: curl/7.58.0
Accept: */*
Accept-Encoding: gzip
X-Forwarded-For: 172.30.0.1
X-Forwarded-Host: whoami.docker.localhost
X-Forwarded-Port: 80
X-Forwarded-Proto: http
X-Forwarded-Server: ab231307712a
X-Real-Ip: 172.30.0.1
Configuration
[[traefik-configuration]] 有两种配置方式:
- 完全动态的配置 (dynamic configuration)
- 静态初始配置(static configuration)
自动重定向到 https
所有到 80 端口的流量都会被重定向到 443 端口。
--entrypoints.web.address=:80
--entrypoints.web.http.redirections.entryPoint.to=websecure
--entrypoints.web.http.redirections.entryPoint.scheme=https
--entrypoints.web.http.redirections.entrypoint.permanent=true
--entrypoints.websecure.address=:443
部署举例
- [[Traefik 部署 n8n]]
- [[Traefik 部署 miniflux]]
reference
在两个 DataGrip 之间同步数据库配置以及一些使用笔记
DataGrip 是 JetBrains 出品的一款数据库管理工具。
同步
从 2021.1 版本开始,可以在 Data Source 上按下 Ctrl/Cmd+C 复制,然后在其他的 IDE 中使用 Ctrl/Cmd+V 来粘贴。
粘贴板会包含 Data Source 的 XML 配置。
但使用 Cmd+C 的同步方式,粘贴板并不会粘贴密码内容,所以粘贴之后也还需要输入数据库密码进行验证。
同步表结构
虽然这种情况我自己很少操作,但是看了一下还是有很多有这样的需求,这里就记录一下,比如有两个环境,本地开发环境和线上环境,如果本地已经完成表结构的变更,想要将这个表结构的更新同步到线上的数据库中,可以直接利用 DataGrip 的同步表结构。
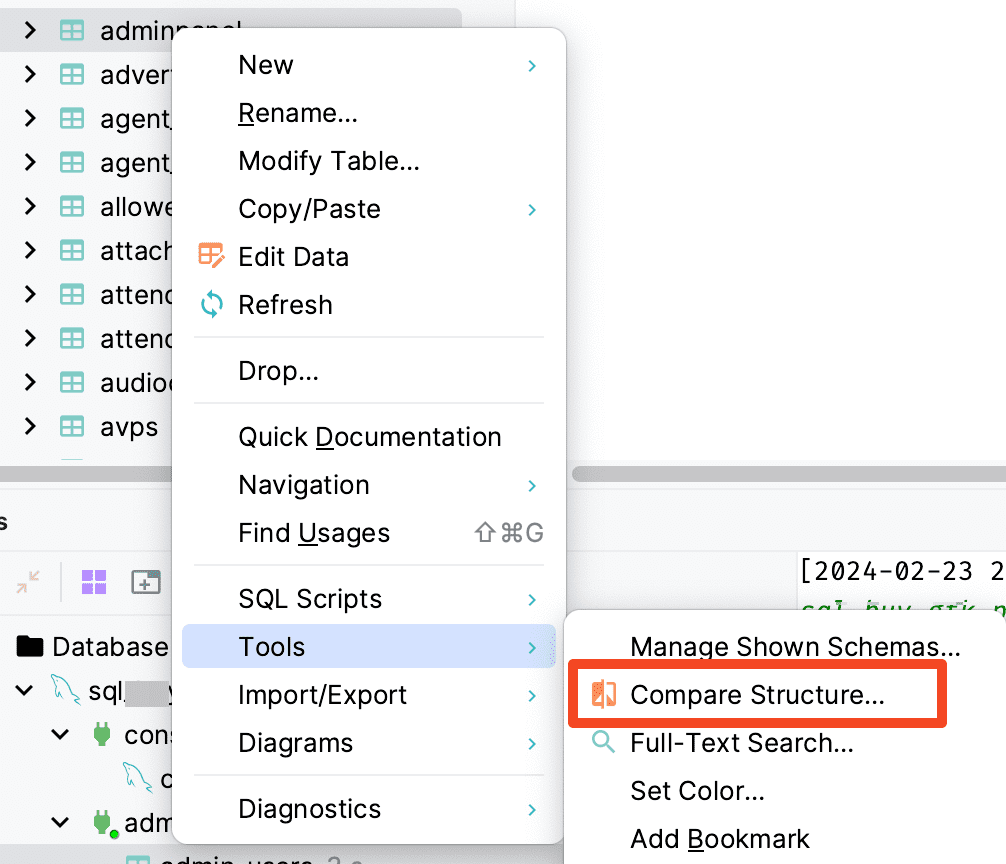
当然我个人推荐的做法是通过将 SQL 放入版本控制做好 Migration,或者使用自动化的 SQL 版本,比如 Python 下的 [[Alembic]] 来管理数据库表结构的版本,实现可以自动升级,降级等。
espanso:Rust 编写的跨平台开源文本扩展工具
今天在 review tldr 提交的新命令的时候发现了一个新的工具 espanso,查看其官网发现是一个文本扩展的工具([[TextExpander]])。在之前 macOS 上短暂的体验过 [[Keyboard Maestro]] 但因为其是 macOS 独占,所以之后再回到 Ubuntu 下的时候就渐渐不用了,并且其授权还挺贵的。然后就一直使用 RIME 配置自定义的短语来作为短语的快捷输入,比如输入 date 的时候自动在候选词中添加日期。但这样的问题便在于每一次更改 RIME 的配置文件都需要经历 RIME 部署这样一个漫长的过程。并且可扩展性也不强。于是想来体验一下 espanso 。
[[Espanso]] 是一个使用 Rust 实现的跨屏平台的 Text Expander,可以在任何编辑器中扩展短语。可以完美代替 [[Keyboard Maestro]] 的 Text Expand 功能。
官网地址:
特性:
- 扩展功能强,可以通过 package 扩展
- 响应速度快,我下载体验后没有任何卡顿
- 支持 form 和 regex
- 文档完善
- 完成度高
- 定义光标位置
- 支持剪贴板
- 可以自动填充图像
- 支持扩展外部脚本(任何语言)
- 用于特定程序匹配
安装
在 macOS 上:
brew tap federico-terzi/espanso
brew install espanso
espanso --version
然后使用 espanso register 启用。
在 Linux 上:
sudo snap install espanso --classic
安装完成后执行:
espanso start
启动后台任务。这样在任何编辑器中输入 :espanso 会自动转变成 Hi there!。
更多安装方式可以参考官网。
使用
其官网有一个非常生动形象的 GIF,当输入:
:greet自动变成hello world:date自动产生日期:llo变成一串 Emoji:ip变成真实的 IP 地址
执行 espanso edit 会自动使用默认的编辑器创建一个默认的配置文件到 ~/.config/espanso/default.yml 文件:
matches:
# Simple text replacement
- trigger: ":espanso"
replace: "Hi there!"
# Dates
- trigger: ":date"
replace: ""
vars:
- name: mydate
type: date
params:
format: "%m/%d/%Y"
# Shell commands
- trigger: ":shell"
replace: ""
vars:
- name: output
type: shell
params:
cmd: "echo Hello from your shell"
Configuration
espanso 基于文本的配置文件对软件的行为进行设定,在不同操作系统上的路径:
- Linux:
~/.config/espanso - macOS:
/Users/einverne/Library/Preferences/espanso - Windows:
C:\Users\user\AppData\Roaming\espanso
可以通过 espanso path 来快速获知路径。
default.yml 文件是 espanso 的主要配置文件,使用 YAML 语法。
更加详细的配置文件可以参考官方文档。
自定义光标位置
在 espanso 的配置 replace 中可以使用 $|$ 作为占位符,表示光标。
比如想要输入 :div 的时候自动展开成为 <div></div> 然后将光标停留到中间,就可以使用:
- trigger: ":div"
replace: "<div>$|$</div>"
Package
Espanso 更加强大的地方在与其扩展性,通过安装其他包可以将 espanso 的能力扩展。比如从 espanso hub 安装 Basic Emojis :
espanso install basic-emojis
然后重启服务:
espanso restart
然后输入 :ok 就可看到文本被替换成了 Emoji。
![[Pasted image 20211013182143.png]]
更多的 package 可以看 espansohub。
快捷键
一些非常有用的快捷键。
Toggle Key
可以通过连续按两次 ALT(macOS 下为 Option) 按键来临时禁用 espanso。可以看到通知 Espanso disabled。 再按两次可以开启。可以通过配置文件修改 Toggle Key
Backspace Undo
有些时候可能无意识中触发了 expansion,但又不想要这个结果,那么可以按一下 BACKSPACE 撤销这一次修改。
同步配置文件
可以使用软链接的方式将配置文件放在同步文件夹,或 git 仓库中保存管理。
Linux 下
ln -s "/home/user/Dropbox/espanso" "/home/user/.config/espanso"
macOS 下,见脚本。
我个人直接将配方放到 dotfiles 中管理。
配置
reference
- [[Rust 开源项目]]
文章分类
最近文章
- Dinox 又一款 AI 语音实时转录工具 前两天介绍过 [[Voicenotes]],也是一款 AI 转录文字的笔记软件,之前在调查 Voicenotes 的时候就留意到了 Dinox,因为是在小红书留意到的,所以猜测应该是国内的某位独立开发者的作品,整个应用使用起来也比较舒服,但相较于 Voicenotes,Dinox 更偏向于一个手机端的笔记软件,因为他整体的设计中没有将语音作为首选,用户也可以添加文字的笔记,反而在 Voicenotes 中,语音作为了所有笔记的首选,当然 Voicenotes 也可以自己编辑笔记,但是语音是它的核心。
- 音流:一款支持 Navidrom 兼容 Subsonic 的跨平台音乐播放器 之前一篇文章介绍了Navidrome,搭建了一个自己在线音乐流媒体库,把我本地通过 [[Syncthing]] 同步的 80 G 音乐导入了。自己也尝试了 Navidrome 官网列出的 Subsonic 兼容客户端 [[substreamer]],以及 macOS 上面的 [[Sonixd]],体验都还不错。但是在了解的过程中又发现了一款中文名叫做「音流」(英文 Stream Music)的应用,初步体验了一下感觉还不错,所以分享出来。
- 泰国 DTV 数字游民签证 泰国一直是 [[Digital Nomad]] 数字游民青睐的选择地,尤其是清迈以其优美的自然环境、低廉的生活成本和友好的社区氛围而闻名。许多数字游民选择在泰国清迈定居,可以在清迈租用廉价的公寓或民宿,享受美食和文化,并与其他数字游民分享经验和资源。
- VoceChat 一款可以自托管的在线聊天室 VoceChat 是一款使用 Rust(后端),React(前端),Flutter(移动端)开发的,开源,支持独立部署的在线聊天服务。VoceChat 非常轻量,后端服务只有 15MB 的大小,打包的 Docker 镜像文件也只有 61 MB,VoceChat 可部署在任何的服务器上。
- 结合了 Google 和 AI 的对话搜索引擎:Perplexity AI 在日本,因为 SoftBank 和 Perplexity AI 开展了合作 ,所以最近大量的使用 Perplexity ,这一篇文章就总结一下 Perplexity 的优势和使用技巧。