zinit 作者删库事件以及后续代替方案
前两天在新机器上使用我的 dotfiles 配置的时候,本来会自动安装 zinit,并进行一些初始化配置,但突然发现卡在了 zinit 配置拉取的过程中,还以为 GitHub 权限配置的问题,但仔细看了一下发现作者把整个仓库,以及个人页面都给删除了。 https://github.com/zdharma/zinit 这个仓库显示 404,我还以为产生了错觉,因为刚刚从 Google 点击跳转过来,Google 的结果还在,但自己一搜就发现原来真的是作者本人把仓库删除了。
所以也没有办法,除了我本地的一份缓存,最近一次提交还是 6 月份,所以只能搜索一下看看还有没有人有最新的备份,然后就看到了 GitHub 上之前贡献者新建的社区维护的仓库。把我 dotfiles 中的地址替换成该仓库目前暂时没有遇到任何问题。
另外要注意如果用到了如下的插件也要响应地替换:
zdharma/zinit -> zdharma-continuum/zinit
zdharma/fast-syntax-highlighting -> zdharma-continuum/fast-syntax-highlighting
zdharma/history-search-multi-word -> zdharma-continuum/history-search-multi-word
我个人也备份了一份代码 https://github.com/einverne/zinit 有兴趣可以看看。
不过我个人还是建议切换到社区维护的版本上。
一点感想
我不对作者的行为做任何评价,因为我并不清楚发生了什么,但是无疑这种删库的行为已经伤害了曾经的使用者,以及曾经贡献过代码的开发者。代码容易恢复,当作者仓库的 wiki 内容已经只能从 Google Cache 中恢复了,这无疑会对使用者造成一些困扰。
从这件事情延伸到生活中,以及这两天刚刚发生的 [[Notability]] 买断制更改为订阅模式造成的恶劣舆论影响,让我不经去思考,在如今这样的严重依赖数字化的生活中保持安定。在过去的经历中,已经让我渐渐地养成习惯,尽量去使用[[自由软件]](能够获取源码),尽量去使用跨平台能导出可使用数据的软件(比如 Obsidian 即使再用不了,我还可以用任何编辑器去编辑我的笔记),如果有离线可用的,绝不用在线服务(Obsidian 相较于 Notion,Notion 开始就不在我的备选方案)。虽然已经这样的做法已经渐渐地让我不会再受到服务关闭的影响,但于此同时我需要考虑的东西就变得多了,数据安全问题,数据备份的问题,这只是涉及数字资产。
但生活中比数字资产重要多的东西也非常多,要做好任何重要的东西可能丢失的备份策略,如果丢失身份证呢,如果在旅行的过程中丢失了护照呢,或者手机失窃了呢? 去备份任何你生活需要依赖的东西,不要将手机和身份证放到一起,不要将银行卡和任何证件放到一起,去备份你生活中产生的任何个人的数据。
reference
- 使用 zinit 管理 zsh 插件 代替 Antigen
- [[2020-10-17-use-zinit-to-manage-zsh-plugins]]
- Reddit discuss
- https://github.com/nuta/nsh
升级 Gogs(Docker) 从 0.11.91 到 0.12.3
很早之前在 QNAP 上就已经安装过老版本的 Gogs,一路升级到 0.11.91 之后很久没有更新,看了一下用的镜像还是 2020 年 2 月份的,看到 Gogs 也已经迭代了好几个版本,正好这一次做迁移,把 Gogs 从 QNAP 迁移到 VPS 上,随便想着也升级一下 Gogs 的版本。
因为之前使用 Docker 安装的,所以迁移的步骤也比较简单,两个部分数据,一部分是 MySQL 数据库,mysqldump 迁移导入即可,另一部分是写的磁盘持久化部分,tar 打包,scp 或 rsync 传输也比较快。
修改配置文件
Gogs 升级到 0.12.x 的时候官方有一些配置发生了变化,我的所有配置文件都在 ~/gogs 文件夹下,所以我需要修改:
vi ~/gogs/gogs/conf/app.ini
然后修改其中的配置。官方的 0.12.0 的 changelog 已经写的非常清楚了,将这些修改都更改了。
❯ cat ~/gogs/gogs/conf/app.ini
BRAND_NAME = Gogs
RUN_USER = git
RUN_MODE = dev
[database]
TYPE = mysql
HOST = db_host:3306
NAME = gogs
USER = gogs
PASSWORD = BTxax
SSL_MODE = disable
PATH = data/gogs.db
[repository]
ROOT = /data/git/gogs-repositories
[server]
DOMAIN = git.example.com
HTTP_PORT = 3000
EXTERNAL_URL = https://git.example.com
DISABLE_SSH = false
SSH_PORT = 10022
START_SSH_SERVER = false
OFFLINE_MODE = false
[mailer]
ENABLED = false
[service]
REQUIRE_EMAIL_CONFIRMATION = false
ENABLE_NOTIFY_MAIL = false
DISABLE_REGISTRATION = false
ENABLE_CAPTCHA = true
REQUIRE_SIGNIN_VIEW = false
[picture]
DISABLE_GRAVATAR = false
ENABLE_FEDERATED_AVATAR = false
[session]
PROVIDER = file
[log]
MODE = file
LEVEL = Info
ROOT_PATH = /app/gogs/log
[security]
INSTALL_LOCK = true
SECRET_KEY = Mj
可以大致参考我的,但不是每一个选项都要一致,最好自行查看每个选项的含义。
cp app.ini app.ini.bak
sed -i \
-e 's/APP_NAME/BRAND_NAME/g' \
-e 's/ROOT_URL/EXTERNAL_URL/g' \
-e 's/LANDING_PAGE/LANDING_URL/g' \
-e 's/DB_TYPE/TYPE/g' \
-e 's/PASSWD/PASSWORD/g' \
-e 's/REVERSE_PROXY_AUTHENTICATION_USER/REVERSE_PROXY_AUTHENTICATION_HEADER/g' \
-e 's/\[mailer\]/\[email\]/g' \
-e 's/\[service\]/\[auth\]/g' \
-e 's/ACTIVE_CODE_LIVE_MINUTES/ACTIVATE_CODE_LIVES/g' \
-e 's/RESET_PASSWD_CODE_LIVE_MINUTES/RESET_PASSWORD_CODE_LIVES/g' \
-e 's/ENABLE_CAPTCHA/ENABLE_REGISTRATION_CAPTCHA/g' \
-e 's/ENABLE_NOTIFY_MAIL/ENABLE_EMAIL_NOTIFICATION/g' \
-e 's/GC_INTERVAL_TIME/GC_INTERVAL/g' \
-e 's/SESSION_LIFE_TIME/MAX_LIFE_TIME/g' \
app.ini
使用命令 sed 替换。1
修改 Docker Compose 配置
然后在新的 VPS 上使用 docker-compose:
version: "3"
services:
gogs:
image: gogs/gogs:0.12.3
container_name: gogs
restart: always
volumes:
- ~/gogs:/data
ports:
- "10022:22"
environment:
VIRTUAL_HOST: git.example.com
VIRTUAL_PORT: 3000
LETSENCRYPT_HOST: git.example.com
LETSENCRYPT_EMAIL: admin@example.info
networks:
default:
external:
name: nginx-proxy
因为我使用 Nginx Proxy 做反向代理,如果需要可以去除掉。
然后直接 docker-compose up -d 启动即可。
这个时候我遇到一些问题。查看日志
less ~/gogs/gogs/log/gogs.log
2021/10/30 07:35:18 [ INFO] Gogs 0.12.3
2021/10/30 07:35:18 [FATAL] [...o/gogs/internal/route/install.go:75 GlobalInit()] Failed to initialize ORM engine: auto migrate "LFSObject": Error 1071: Specified key was too long; max key length is 767 bytes
会发现报错,这个错误 GitHub issue 上面也有人报错,之前因为迁移,没有来得及查看,后来仔细查看 Gogs 其他日志:
less ~/gogs/gogs/log/gorm.log
发现 gorm 日志中在创建 lfs_object 表的时候发生了错误。
2021/10/30 07:33:49 [log] [gogs.io/gogs/internal/db/db.go:166] Error 1071: Specified key was too long; max key length is 767 bytes
2021/10/30 07:33:49 [sql] [gogs.io/gogs/internal/db/db.go:166] [823.087µs] CREATE TABLE `lfs_object` (`repo_id` bigint,`oid` varchar(255),`size` bigint NOT NULL,`storage` varchar(255) NOT NULL,`created_at` DATETIME NOT NULL , PRIMARY KEY (`repo_id`,`oid`)) ENGINE=InnoDB [] (0 rows affected)
结合之前在 changelog 中看到的,升级到 0.12.x 之后 Gogs 会自动创建这张表,而创建失败了自然就无法启动报 502 错误了。
看这个错误 Error 1071,一看就是 MySQL 的错误。
Error 1071: Specified key was too long; max key length is 767 bytes
我的机器上使用的是 MariaDB,然后 gogs 数据库默认使用的是 utf8mb4_general_ci collation,默认情况下索引长度会有问题,所以将数据库的默认 collation 改成 utf8_general_ci 即可。
使用 phpmyadmin 修改 collation
登录 phpmyadmin 选中数据库 gogs,然后在 Operations 最下面可以看到 Collation 设置,直接修改保存即可。
使用命令行修改 collation
ALTER DATABASE <database_name> CHARACTER SET utf8 COLLATE utf8_general_ci;
修复 Ubuntu 18.04 网络设置中无有线设置的问题
在 Ubuntu 18.04 网络配置中,某一次升级之后就发现网络配置中心里面少了有线网络配置。
为了恢复有线网络配置,需要手动修改 NetworkManager 的配置文件。
首先查看 interfaces 文件中内容。
❯ sudo cat /etc/network/interfaces
# interfaces(5) file used by ifup(8) and ifdown(8)
auto lo
iface lo inet loopback
确保该配置文件正确。
然后修改 NetworkManager.conf 文件
sudo vi /etc/NetworkManager/NetworkManager.conf
将文件中的 :
managed=false
修改为
managed=true
然后修改 10-globally-managed-devices.conf 配置文件,添加有线设备:
sudo vi /usr/lib/NetworkManager/conf.d/10-globally-managed-devices.conf
修改为:
[keyfile]
unmanaged-devices=*,except:type:ethernet,except:type:wifi,except:type:wwan
注意其中的 except: type: ethernet 这一部分。
最后重启 NetworkManager
sudo service network-manager restart
最后就能够在网络配置中心中手动配置有线网络连接。
reference
Terraform 使用笔记
在之前看 Perfect Media Server 的时候看到作者有推荐一本叫做 《Infrastructure as Code》, O’REILLY 出品,作者描述了一个使用文本文件来定义基础设施的框架。在没有了解到这个概念之前我只是简单了解过 [[Ansible]] 这个代码即配置的应用,也就是定义了软件的配置,而 [[Terraform]] 则更像是用纯文本(代码)定义了硬件配置。
这句话让我茅塞顿开:
Infrastructure as Code
在过去很长的一段时间里面,我都保存我使用的 docker-compose 配置文件,这样使得我无论拿到哪一台机器都可以快速的恢复之前的服务,这都依赖于这些年 Docker 的兴起。
Infrastructure as Code - Ansible Terraform https://t.co/RlqVlXGUCk
— Ein Verne (@einverne) October 22, 2021
管理配置文件的方式就和代码开发一样,像 Ansible 和 Terraform 这样的工具可以将对基础设施的配置完全配置化。使用 Terraform 来创建基础设施,而使用 Ansible 来配置。想象一下如果有一台全新的 Ubuntu,可以通过一行配置,在几分钟之内就可以恢复到一个可用的环境,这远比维护很多 bash 脚本来的方便。
Terraform 是什么
[[Terraform]] 是一个安全有效地构建、更改和版本控制基础设施的工具(基础架构自动化的编排工具)。Terraform 由 HashiCorp 创立并开源,Terraform 提倡「基础架构即代码」的哲学。它的口号是「Write,Plan,and Create Infrastructure as Code」。
Terraform 是一种声明式编码工具,让开发人员通过 HCL(HashiCorp 配置语言)来描述运行应用程序的最终状态环境。
Terraform is a tool to express the nuts of bolts of infrastructure as code. Think VMs, load balancers, storage, DNS, etc defined as code and stored in versioned source control.
Terraform 解决了什么问题
在没有 Terraform 之前,运维人员需要手动定位对基础硬件进行管理,在有了 Terraform 之后运维人员也可以通过文本来定义硬件资源的分配,并让 Terraform 去管理资源的分配问题。
Terraform 特点:
- 开源
- 并发,效率高
- HCL 配置预发,使得基础设施的控制可以和代码一样管理,共享和重用
- planning 步骤会生成执行计划,调用时会显示所有操作,避免人为误操作
- 硬件资源分配问题
- 平台无关,可以配合任何云服务提供商
- 不可变基础架构
Terraform 安装
Ubuntu:
sudo apt install terraform
Ubuntu 下安装:
sudo wget https://releases.hashicorp.com/terraform/0.12.18/terraform_0.12.18_linux_amd64.zip
sudo unzip terraform_0.12.18_linux_amd64.zip
sudo mv terraform /usr/local/bin/
macOS:
brew install terraform
安装完成后命令是 terraform。常用的是 terraform init, terraform plan, terraform apply
更多安装方式可以参考官网
Terraform 配置
Terraform 的配置文件以 .tf 为后缀,配置文件有两种格式:
- JSON,以
.tf.json结尾 - Terraform,Terraform 格式支持注释,通常更加可读,推荐,以
.tf结尾
配置文档
Terraform 配置,将按照字母顺序加载指定目录中的配置文件。
配置举例:
provider "aws" {
region = "us-east-1"
access_key = "your-access-key-here"
secret_key = "your-secret-key-here"
}
resource "aws_s3_bucket" "b" {
bucket = "my-tf-test-bucket"
acl = "private"
tags = {
Name = "My bucket"
Environment = "Dev"
}
}
provider 部分指定了使用什么 provider,通过指定 access_key 和 secret_key 来访问资源。
aws_s3_bucket 表示的是配置 S3 Bucket 资源,更多的资源配置方式可以参考这里
如果指定的 my-tf-test-bucket 不存在的话,terraform apply 会创建。
terraform init
在执行 apply 等命令之前需要先初始化工作目录:
terraform init
执行后,会在当前目录中生成 .terraform 目录,并按照 *.tf 文件中的配置下载插件。
terraform plan
可以使用 terraform plan 命令预览执行计划。
terraform apply
执行 terraform apply 会根据配置应用,并生效。
工作目录设定
Terraform 执行时会读取所有 *.tf 命令
provider.tf -- provider 配置
terraform.tfvars -- 配置 provider 要用到的变量
varable.tf -- 通用变量
resource.tf -- 资源定义
data.tf -- 包文件定义
output.tf -- 输出
HCL
Terraform 配置语法称为 HashiCorp 配置语言,简称 HCL。 语法说明可以参考如下: https://www.terraform.io/docs/configuration/syntax.html
示例:
# An AMI
variable "ami" {
description = "the AMI to use"
}
/* A multi
line comment. */
resource "aws_instance" "web" {
ami = "${var.ami}"
count = 2
source_dest_check = false
connection {
user = "root"
}
}
http://hashivim.github.io/vim-terraform/
可以安装 hashivim/vim-terraform 插件,在 Vim 中实现 HCL 语法加亮。写好的 *.tf 文件后可以调用 terraform fmt 对配置文件进行格式化。
延伸
- awesome-terraform
- [[Terraform]]
So you Start 独服 Proxmox VE 配置 RAID 10
之前购买的 So you Start(OVH 旗下品牌) 的独服,配置有 4 块 2T 的硬盘,但是 So you Start 后台默认的 RAID 级别是 RAID1,这样使得可用的空间只有 8T 中的 2T,25% 的使用率,虽然硬盘安全性级别比较高(允许多块硬盘损坏的情况下依然不丢数据),但是空间可用率太低了,所以折中一下可以使用 RAID-10(允许一块硬盘损坏而不丢失数据),这里就记录一下如何把 So you Start 的独服从 RAID-1 级别在线调整成 RAID-10。正常情况下 OVH 旗下的主机品牌,包括 OHV,So you Start, Kimsufi 都可以适用本教程,其他独服的操作也类似。
前提知识
- mdadm, fdisk 等基础命令的使用
- 对 RAID 级别有基础的了解
- 了解 Linux 下分区
几个主要的步骤
- 首先使用 So you Start 后台的系统安装工具,使用默认的 RAID1 安装 Debian Buster
- 然后在线调整 RAID1 到 RAID10
- 在 Debian 基础之上安装 [[Proxmox VE]]
主要分成后面几个步骤(具体的操作步骤和演示可以参考后文):
mdadm /dev/md1 --fail /dev/sdc1
mdadm /dev/md1 --remove /dev/sdc1
wipefs -a /dev/sdc1
mdadm --grow /dev/md1 --raid-devices=2
first think about a partitioning scheme. usually there is no need to absolutely put everything on a single large partition. proxmox for instance puts disk images and whatnot into /var/lib/vz which then is an ideal mount point for a split partition.
Install Debian
首先在 So you Start 后台管理面板中使用 Reinstall 重新安装系统。
- 使用 Custom 安装
- 在下一步分区中,使用 RAID1 安装系统,可以根据自己的需要调整分区大小,如果怕麻烦可以,可以把所有空间划分给
/然后留一定空间给swap。比如我的机器是 32G 的,可以给 16G swap,然后剩余的空间都划给/。如果熟悉 Linux 的分区,并且想要自己定义剩下的空间给 RAID-x,或 ZFS,或 LVM,可以划分一个比如 2G 给/boot分区,然后划分240G 给/然后 16G 给swap,之后可以把/从 RAID1 调整为 RAID10
安装完成进入系统:
debian@pve:~$ lsb_release -a
No LSB modules are available.
Distributor ID: Debian
Description: Debian GNU/Linux 10 (buster)
Release: 10
Codename: buster
Reshape RAID
重新调整 RAID 级别。需要特别感谢 LET 上面的 Falzo 根据他所提供的详细步骤我才完成了 RAID1 到 RAID10 的在线调整。
大致的步骤需要先将 RAID1 调整为 RAID0,然后在调整为 RAID10.
首先来查看一下默认的 RAID 信息:
root@pve:~# cat /proc/mdstat
Personalities : [raid1] [linear] [multipath] [raid0] [raid6] [raid5] [raid4] [raid10]
md2 : active raid1 sda2[0] sdc2[1] sdd2[3] sdb2[2]
511868928 blocks super 1.2 [4/4] [UUUU]
bitmap: 2/4 pages [8KB], 65536KB chunk
unused devices: <none>
可以看到有一个 md2 RAID,使用了 raid1,有四个分区分别是 sda2, sdc2, sdd2, sdb2 组合而成。
查看硬盘信息(模糊掉敏感的一些标识信息):
root@pve:~# fdisk -l
Disk /dev/sdb: 1.8 TiB, 2000398934016 bytes, 3907029168 sectors
Disk model: HGST HUS7-----AL
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disklabel type: gpt
Disk identifier: B411C4C1-EA13-42F1-86D8-DC-------115
Device Start End Sectors Size Type
/dev/sdb1 2048 1048575 1046528 511M EFI System
/dev/sdb2 1048576 1025048575 1024000000 488.3G Linux RAID
/dev/sdb3 1025048576 1058603007 33554432 16G Linux filesystem
Disk /dev/sdc: 1.8 TiB, 2000398934016 bytes, 3907029168 sectors
Disk model: HGST HUS7-----AL
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disklabel type: gpt
Disk identifier: DA108B72-B409-4F9E-8FF1-0D---------8
Device Start End Sectors Size Type
/dev/sdc1 2048 1048575 1046528 511M EFI System
/dev/sdc2 1048576 1025048575 1024000000 488.3G Linux RAID
/dev/sdc3 1025048576 1058603007 33554432 16G Linux filesystem
Disk /dev/sdd: 1.8 TiB, 2000398934016 bytes, 3907029168 sectors
Disk model: HGST HUS-----0AL
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disklabel type: gpt
Disk identifier: DC27A340-79CB-437E-952F-97A-------A8
Device Start End Sectors Size Type
/dev/sdd1 2048 1048575 1046528 511M EFI System
/dev/sdd2 1048576 1025048575 1024000000 488.3G Linux RAID
/dev/sdd3 1025048576 1058603007 33554432 16G Linux filesystem
Disk /dev/sda: 1.8 TiB, 2000398934016 bytes, 3907029168 sectors
Disk model: HGST HU------0AL
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disklabel type: gpt
Disk identifier: 76C633FE-ACC3-40FA-A111-2C--------C8
Device Start End Sectors Size Type
/dev/sda1 2048 1048575 1046528 511M EFI System
/dev/sda2 1048576 1025048575 1024000000 488.3G Linux RAID
/dev/sda3 1025048576 1058603007 33554432 16G Linux filesystem
/dev/sda4 3907025072 3907029134 4063 2M Linux filesystem
Disk /dev/md2: 488.2 GiB, 524153782272 bytes, 1023737856 sectors
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
然后可以通过 mdadm 命令 reshape RAID1,这一步可以直接在线执行,完全不需要 [[IPMI]] 等等额外的工具。
在线将 RAID1 转变成 RAID10 的步骤可以参考这篇文章 作者写的非常清楚。[[Converting RAID1 to RAID10 online]]
具体的步骤可以查看如下:
root@pve:~# cat /proc/mdstat
Personalities : [raid1] [linear] [multipath] [raid0] [raid6] [raid5] [raid4] [raid10]
md2 : active raid1 sda2[0] sdc2[1] sdd2[3] sdb2[2]
511868928 blocks super 1.2 [4/4] [UUUU]
bitmap: 2/4 pages [8KB], 65536KB chunk
unused devices: <none>
root@pve:~# mdadm /dev/md2 --fail /dev/sdc2
mdadm: set /dev/sdc2 faulty in /dev/md2
root@pve:~# mdadm /dev/md2 --remove /dev/sdc2
mdadm: hot removed /dev/sdc2 from /dev/md2
root@pve:~# wipefs -a /dev/sdc2
/dev/sdc2: 4 bytes were erased at offset 0x00001000 (linux_raid_member): fc 4e 2b a9
root@pve:~# mdadm /dev/md2 --fail /dev/sdd2
mdadm: set /dev/sdd2 faulty in /dev/md2
root@pve:~# mdadm /dev/md2 --remove /dev/sdd2
mdadm: hot removed /dev/sdd2 from /dev/md2
root@pve:~# wipefs -a /dev/sdd2
/dev/sdd2: 4 bytes were erased at offset 0x00001000 (linux_raid_member): fc 4e 2b a9
root@pve:~# mdadm --grow /dev/md2 --raid-devices=2
raid_disks for /dev/md2 set to 2
root@pve:~# cat /proc/mdstat
Personalities : [raid1] [linear] [multipath] [raid0] [raid6] [raid5] [raid4] [raid10]
md2 : active raid1 sda2[0] sdb2[2]
511868928 blocks super 1.2 [2/2] [UU]
bitmap: 3/4 pages [12KB], 65536KB chunk
unused devices: <none>
root@pve:~# mdadm --detail /dev/md2
/dev/md2:
Version : 1.2
Creation Time : Thu Oct 21 12:58:06 2021
Raid Level : raid1
Array Size : 511868928 (488.16 GiB 524.15 GB)
Used Dev Size : 511868928 (488.16 GiB 524.15 GB)
Raid Devices : 2
Total Devices : 2
Persistence : Superblock is persistent
Intent Bitmap : Internal
Update Time : Thu Oct 21 13:33:45 2021
State : clean
Active Devices : 2
Working Devices : 2
Failed Devices : 0
Spare Devices : 0
Consistency Policy : bitmap
Name : md2
UUID : 0686b64f:07957a70:4e937aa2:23716f6e
Events : 158
Number Major Minor RaidDevice State
0 8 2 0 active sync /dev/sda2
2 8 18 1 active sync /dev/sdb2
root@pve:~# sudo mdadm --grow /dev/md2 --level=0 --backup-file=/home/backup-md2
mdadm: level of /dev/md2 changed to raid0
root@pve:~# cat /proc/mdstat
Personalities : [raid1] [linear] [multipath] [raid0] [raid6] [raid5] [raid4] [raid10]
md2 : active raid0 sdb2[2]
511868928 blocks super 1.2 64k chunks
unused devices: <none>
root@pve:~# mdadm --misc --detail /dev/md2
/dev/md2:
Version : 1.2
Creation Time : Thu Oct 21 12:58:06 2021
Raid Level : raid0
Array Size : 511868928 (488.16 GiB 524.15 GB)
Raid Devices : 1
Total Devices : 1
Persistence : Superblock is persistent
Update Time : Thu Oct 21 13:40:10 2021
State : clean
Active Devices : 1
Working Devices : 1
Failed Devices : 0
Spare Devices : 0
Chunk Size : 64K
Consistency Policy : none
Name : md2
UUID : 0686b64f:07957a70:4e937aa2:23716f6e
Events : 163
Number Major Minor RaidDevice State
2 8 18 0 active sync /dev/sdb2
root@pve:~# mdadm --grow /dev/md2 --level=10 --backup-file=/home/backup-md2 --raid-devices=4 --add /dev/sda2 /dev/sdc2 /dev/sdd2
mdadm: level of /dev/md2 changed to raid10
mdadm: added /dev/sda2
mdadm: added /dev/sdc2
mdadm: added /dev/sdd2
raid_disks for /dev/md2 set to 5
root@pve:~# cat /proc/mdstat
Personalities : [raid1] [linear] [multipath] [raid0] [raid6] [raid5] [raid4] [raid10]
md2 : active raid10 sdd2[5] sdc2[4](S) sda2[3](S) sdb2[2]
511868928 blocks super 1.2 2 near-copies [2/1] [U_]
[>....................] recovery = 0.5% (2835392/511868928) finish=50.8min speed=166787K/sec
unused devices: <none>
root@pve:~# mdadm --misc --detail /dev/md2
/dev/md2:
Version : 1.2
Creation Time : Thu Oct 21 12:58:06 2021
Raid Level : raid10
Array Size : 511868928 (488.16 GiB 524.15 GB)
Used Dev Size : 511868928 (488.16 GiB 524.15 GB)
Raid Devices : 2
Total Devices : 4
Persistence : Superblock is persistent
Update Time : Thu Oct 21 13:42:49 2021
State : active, degraded, recovering
Active Devices : 1
Working Devices : 4
Failed Devices : 0
Spare Devices : 3
Layout : near=2
Chunk Size : 64K
Consistency Policy : resync
Rebuild Status : 1% complete
Name : md2
UUID : 0686b64f:07957a70:4e937aa2:23716f6e
Events : 221
Number Major Minor RaidDevice State
2 8 18 0 active sync set-A /dev/sdb2
5 8 50 1 spare rebuilding /dev/sdd2
3 8 2 - spare /dev/sda2
4 8 34 - spare /dev/sdc2
root@pve:~# mdadm --misc --detail /dev/md2
/dev/md2:
Version : 1.2
Creation Time : Thu Oct 21 12:58:06 2021
Raid Level : raid10
Array Size : 511868928 (488.16 GiB 524.15 GB)
Used Dev Size : 511868928 (488.16 GiB 524.15 GB)
Raid Devices : 2
Total Devices : 4
Persistence : Superblock is persistent
Update Time : Thu Oct 21 13:47:58 2021
State : active, degraded, recovering
Active Devices : 1
Working Devices : 4
Failed Devices : 0
Spare Devices : 3
Layout : near=2
Chunk Size : 64K
Consistency Policy : resync
Rebuild Status : 11% complete
Name : md2
UUID : 0686b64f:07957a70:4e937aa2:23716f6e
Events : 554
Number Major Minor RaidDevice State
2 8 18 0 active sync set-A /dev/sdb2
5 8 50 1 spare rebuilding /dev/sdd2
3 8 2 - spare /dev/sda2
4 8 34 - spare /dev/sdc2
root@pve:~# mdadm --misc --detail /dev/md2
/dev/md2:
Version : 1.2
Creation Time : Thu Oct 21 12:58:06 2021
Raid Level : raid10
Array Size : 511868928 (488.16 GiB 524.15 GB)
Used Dev Size : 511868928 (488.16 GiB 524.15 GB)
Raid Devices : 2
Total Devices : 4
Persistence : Superblock is persistent
Update Time : Thu Oct 21 13:48:29 2021
State : clean, degraded, recovering
Active Devices : 1
Working Devices : 4
Failed Devices : 0
Spare Devices : 3
Layout : near=2
Chunk Size : 64K
Consistency Policy : resync
Rebuild Status : 12% complete
Name : md2
UUID : 0686b64f:07957a70:4e937aa2:23716f6e
Events : 588
Number Major Minor RaidDevice State
2 8 18 0 active sync set-A /dev/sdb2
5 8 50 1 spare rebuilding /dev/sdd2
3 8 2 - spare /dev/sda2
4 8 34 - spare /dev/sdc2
root@pve:~# mdadm --grow /dev/md2 --raid-devices=4
root@pve:~# cat /proc/mdstat
Personalities : [raid1] [linear] [multipath] [raid0] [raid6] [raid5] [raid4] [raid10]
md2 : active raid10 sdd2[5] sdc2[4] sda2[3] sdb2[2]
511868928 blocks super 1.2 64K chunks 2 near-copies [4/3] [U_UU]
[>....................] reshape = 0.2% (1387520/511868928) finish=67.4min speed=126138K/sec
unused devices: <none>
root@pve:~# mdadm --misc --detail /dev/md2
/dev/md2:
Version : 1.2
Creation Time : Thu Oct 21 12:58:06 2021
Raid Level : raid10
Array Size : 511868928 (488.16 GiB 524.15 GB)
Used Dev Size : 511868928 (488.16 GiB 524.15 GB)
Raid Devices : 4
Total Devices : 4
Persistence : Superblock is persistent
Update Time : Thu Oct 21 13:50:47 2021
State : clean, degraded, reshaping
Active Devices : 3
Working Devices : 4
Failed Devices : 0
Spare Devices : 1
Layout : near=2
Chunk Size : 64K
Consistency Policy : resync
Reshape Status : 1% complete
Delta Devices : 2, (2->4)
Name : md2
UUID : 0686b64f:07957a70:4e937aa2:23716f6e
Events : 725
Number Major Minor RaidDevice State
2 8 18 0 active sync set-A /dev/sdb2
5 8 50 1 spare rebuilding /dev/sdd2
4 8 34 2 active sync set-A /dev/sdc2
3 8 2 3 active sync set-B /dev/sda2
root@pve:~# mdadm --misc --detail /dev/md2
/dev/md2:
Version : 1.2
Creation Time : Thu Oct 21 12:58:06 2021
Raid Level : raid10
Array Size : 511868928 (488.16 GiB 524.15 GB)
Used Dev Size : 511868928 (488.16 GiB 524.15 GB)
Raid Devices : 4
Total Devices : 4
Persistence : Superblock is persistent
Update Time : Thu Oct 21 13:51:59 2021
State : active, degraded, reshaping
Active Devices : 3
Working Devices : 4
Failed Devices : 0
Spare Devices : 1
Layout : near=2
Chunk Size : 64K
Consistency Policy : resync
Reshape Status : 3% complete
Delta Devices : 2, (2->4)
Name : md2
UUID : 0686b64f:07957a70:4e937aa2:23716f6e
Events : 769
Number Major Minor RaidDevice State
2 8 18 0 active sync set-A /dev/sdb2
5 8 50 1 spare rebuilding /dev/sdd2
4 8 34 2 active sync set-A /dev/sdc2
3 8 2 3 active sync set-B /dev/sda2
root@pve:~# cat /proc/mdstat
Personalities : [raid1] [linear] [multipath] [raid0] [raid6] [raid5] [raid4] [raid10]
md2 : active raid10 sdd2[5] sdc2[4] sda2[3] sdb2[2]
511868928 blocks super 1.2 64K chunks 2 near-copies [4/3] [U_UU]
[====>................] reshape = 21.8% (111798784/511868928) finish=59.6min speed=111736K/sec
unused devices: <none>
root@pve:~# mdadm --misc --detail /dev/md2
/dev/md2:
Version : 1.2
Creation Time : Thu Oct 21 12:58:06 2021
Raid Level : raid10
Array Size : 511868928 (488.16 GiB 524.15 GB)
Used Dev Size : 511868928 (488.16 GiB 524.15 GB)
Raid Devices : 4
Total Devices : 4
Persistence : Superblock is persistent
Update Time : Thu Oct 21 14:05:44 2021
State : active, degraded, reshaping
Active Devices : 3
Working Devices : 4
Failed Devices : 0
Spare Devices : 1
Layout : near=2
Chunk Size : 64K
Consistency Policy : resync
Reshape Status : 22% complete
Delta Devices : 2, (2->4)
Name : md2
UUID : 0686b64f:07957a70:4e937aa2:23716f6e
Events : 1345
Number Major Minor RaidDevice State
2 8 18 0 active sync set-A /dev/sdb2
5 8 50 1 spare rebuilding /dev/sdd2
4 8 34 2 active sync set-A /dev/sdc2
3 8 2 3 active sync set-B /dev/sda2
root@pve:~# df -h
Filesystem Size Used Avail Use% Mounted on
udev 16G 0 16G 0% /dev
tmpfs 3.2G 8.9M 3.2G 1% /run
/dev/md2 481G 1.5G 455G 1% /
tmpfs 16G 0 16G 0% /dev/shm
tmpfs 5.0M 0 5.0M 0% /run/lock
tmpfs 16G 0 16G 0% /sys/fs/cgroup
/dev/sdd1 511M 3.3M 508M 1% /boot/efi
tmpfs 3.2G 0 3.2G 0% /run/user/1000
root@pve:~# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 1.8T 0 disk
├─sda1 8:1 0 511M 0 part
├─sda2 8:2 0 488.3G 0 part
│ └─md2 9:2 0 488.2G 0 raid10 /
├─sda3 8:3 0 16G 0 part [SWAP]
└─sda4 8:4 0 2M 0 part
sdb 8:16 0 1.8T 0 disk
├─sdb1 8:17 0 511M 0 part
├─sdb2 8:18 0 488.3G 0 part
│ └─md2 9:2 0 488.2G 0 raid10 /
└─sdb3 8:19 0 16G 0 part [SWAP]
sdc 8:32 0 1.8T 0 disk
├─sdc1 8:33 0 511M 0 part
├─sdc2 8:34 0 488.3G 0 part
│ └─md2 9:2 0 488.2G 0 raid10 /
└─sdc3 8:35 0 16G 0 part [SWAP]
sdd 8:48 0 1.8T 0 disk
├─sdd1 8:49 0 511M 0 part /boot/efi
├─sdd2 8:50 0 488.3G 0 part
│ └─md2 9:2 0 488.2G 0 raid10 /
└─sdd3 8:51 0 16G 0 part [SWAP]
root@pve:~# cat /proc/mdstat
Personalities : [raid1] [linear] [multipath] [raid0] [raid6] [raid5] [raid4] [raid10]
md2 : active raid10 sdd2[5] sdc2[4] sda2[3] sdb2[2]
511868928 blocks super 1.2 64K chunks 2 near-copies [4/3] [U_UU]
[======>..............] reshape = 32.9% (168472448/511868928) finish=49.0min speed=116718K/sec
unused devices: <none>
等待很长一段时间之后 RAID10 完成:
root@pve:~# mdadm --misc --detail /dev/md2
/dev/md2:
Version : 1.2
Creation Time : Thu Oct 21 12:58:06 2021
Raid Level : raid10
Array Size : 1023737856 (976.31 GiB 1048.31 GB)
Used Dev Size : 511868928 (488.16 GiB 524.15 GB)
Raid Devices : 4
Total Devices : 4
Persistence : Superblock is persistent
Update Time : Fri Oct 22 01:39:27 2021
State : clean
Active Devices : 4
Working Devices : 4
Failed Devices : 0
Spare Devices : 0
Layout : near=2
Chunk Size : 64K
Consistency Policy : resync
Name : md2
UUID : 0686b64f:07957a70:4e937aa2:23716f6e
Events : 6536
Number Major Minor RaidDevice State
2 8 18 0 active sync set-A /dev/sdb2
5 8 50 1 active sync set-B /dev/sdd2
4 8 34 2 active sync set-A /dev/sdc2
3 8 2 3 active sync set-B /dev/sda2
Install Proxmox VE on Debian
完成 RAID10 的调整之后,如果磁盘还有剩余的空间,可以再分区,之后使用 ZFS,raidz 可以自己选择。
然后可以更具官方的教程,直接在 Debian 的基础之上安装 Proxmox VE。之后需要移除掉 cloud-init 否则网络配置会产生问题。
reference
- [[mdadm-command]]
Ubuntu 20.04 使用 MergerFS
[[so-you-start]] 的独服有4块 2T 的硬盘,本来想配置一个 Soft RAID-10,但折腾了一个礼拜,重装了无数遍系统,配置了很多次,从 Ubuntu,Proxmox VE,Debian 都尝试了一遍,最终放弃了,想着充分利用其空间,使用 Proxmox VE,备份好数据,不用 RAID 了,毕竟如果使用默认的 RAID-1,我只能利用8T空间中的 2T 不到,而使用 RAID-10 也只能利用不到 4T 左右空间。至于使用单盘,所有的数据备份,和数据安全性的工作就完全依靠自己的备份去完成了。但是好处是可利用的空间大了。
Proxmox VE 硬盘直通
参考之前的文章Proxmox VE 硬盘直通,将 Proxmox VE 安装后剩下的三块硬盘直通给 Ubuntu。
root@pve:/var/lib/vz/dump# qm set 101 -scsi1 /dev/disk/by-id/ata-HGST_HUS726020ALA610_K5HWJ6NG
update VM 101: -scsi1 /dev/disk/by-id/ata-HGST_HUS726020ALA610_K5HWJ6NG
root@pve:/var/lib/vz/dump# qm set 101 -scsi2 /dev/disk/by-id/ata-HGST_HUS726020ALA610_K5J0ZUWA
update VM 101: -scsi2 /dev/disk/by-id/ata-HGST_HUS726020ALA610_K5J0ZUWA
root@pve:/var/lib/vz/dump# qm set 101 -scsi3 /dev/disk/by-id/ata-HGST_HUS726020ALA610_K5HW9RJG
update VM 101: -scsi3 /dev/disk/by-id/ata-HGST_HUS726020ALA610_K5HW9RJG
在 Ubuntu 虚拟机就可以看到:
einverne@sysubuntu:~$ lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
loop0 7:0 0 61.9M 1 loop /snap/core20/1169
loop1 7:1 0 55.4M 1 loop /snap/core18/2128
loop2 7:2 0 70.3M 1 loop /snap/lxd/21029
loop3 7:3 0 67.3M 1 loop /snap/lxd/21545
loop5 7:5 0 32.4M 1 loop /snap/snapd/13270
loop6 7:6 0 32.5M 1 loop /snap/snapd/13640
sda 8:0 0 64G 0 disk
├─sda1 8:1 0 1M 0 part
└─sda2 8:2 0 64G 0 part /
sdb 8:16 0 1.8T 0 disk
sdc 8:32 0 1.8T 0 disk
sdd 8:48 0 1.8T 0 disk
sr0 11:0 1 1024M 0 rom
然后使用 fdisk 或 parted 给硬盘进行分区,格式化之后,挂载到 /mnt:
root@sysubuntu:~# df -h
Filesystem Size Used Avail Use% Mounted on
udev 1.9G 0 1.9G 0% /dev
tmpfs 394M 1.1M 393M 1% /run
/dev/sda2 63G 10G 50G 17% /
tmpfs 2.0G 468K 2.0G 1% /dev/shm
tmpfs 5.0M 0 5.0M 0% /run/lock
tmpfs 2.0G 0 2.0G 0% /sys/fs/cgroup
/dev/loop0 62M 62M 0 100% /snap/core20/1169
/dev/loop2 71M 71M 0 100% /snap/lxd/21029
/dev/loop1 56M 56M 0 100% /snap/core18/2128
/dev/loop3 68M 68M 0 100% /snap/lxd/21545
/dev/loop5 33M 33M 0 100% /snap/snapd/13270
/dev/loop6 33M 33M 0 100% /snap/snapd/13640
tmpfs 394M 0 394M 0% /run/user/1000
/dev/sdb1 1.8T 77M 1.7T 1% /mnt/sdb1
/dev/sdc1 1.8T 77M 1.7T 1% /mnt/sdc1
/dev/sdd1 1.8T 77M 1.7T 1% /mnt/sdd1
Install MergerFS
在官方发布页面 下载最新的安装包:
wget https://github.com/trapexit/mergerfs/releases/download/2.32.6/mergerfs_2.32.6.ubuntu-bionic_amd64.deb
sudo dpkg -i mergerfs_2.32.6.ubuntu-bionic_amd64.deb
MergerFS 配置
MergerFS 可以将一组硬盘(JBOD)组合形成一个硬盘,类似于 RAID,但完全不同。
root@sysubuntu:~# mkdir -p /mnt/storage
root@sysubuntu:~# mergerfs -o defaults,allow_other,use_ino,category.create=mfs,minfreespace=100G,ignorepponrename=true,fsname=mergerFS /mnt/sdb1:/mnt/sdc1/:/mnt/sdd1/ /mnt/storage/
root@sysubuntu:~# df -h
Filesystem Size Used Avail Use% Mounted on
udev 1.9G 0 1.9G 0% /dev
tmpfs 394M 1.1M 393M 1% /run
/dev/sda2 63G 10G 50G 17% /
tmpfs 2.0G 468K 2.0G 1% /dev/shm
tmpfs 5.0M 0 5.0M 0% /run/lock
tmpfs 2.0G 0 2.0G 0% /sys/fs/cgroup
/dev/loop0 62M 62M 0 100% /snap/core20/1169
/dev/loop2 71M 71M 0 100% /snap/lxd/21029
/dev/loop1 56M 56M 0 100% /snap/core18/2128
/dev/loop3 68M 68M 0 100% /snap/lxd/21545
/dev/loop5 33M 33M 0 100% /snap/snapd/13270
/dev/loop6 33M 33M 0 100% /snap/snapd/13640
tmpfs 394M 0 394M 0% /run/user/1000
/dev/sdb1 1.8T 77M 1.7T 1% /mnt/sdb1
/dev/sdc1 1.8T 77M 1.7T 1% /mnt/sdc1
/dev/sdd1 1.8T 77M 1.7T 1% /mnt/sdd1
mergerFS 5.4T 229M 5.1T 1% /mnt/storage
参数说明:
defaults: 开启以下 FUSE 参数以提升性能:atomic_o_trunc, auto_cache, big_writes, default_permissions, splice_move, splice_read, splice_write;allow_other: 允许挂载者以外的用户访问。需要编辑 /etc/fuse.conf。use_ino: 使用 mergerfs 而不是 libfuse 提供的 inode,使硬链接的文件 inode 一致;category.create=mfs: Spreads files out across your drives based on available space;minfreespace=100G: 最小剩余空间 100G,当写文件时,跳过剩余空间低于 100G 的文件系统ignorepponrename=true: 重命名时保持原来的存储路径
最后编辑 /etc/fstab 来在启动时自动挂载。
使用 lsblk -f 查看:
root@sysubuntu:~# lsblk -f
NAME FSTYPE LABEL UUID FSAVAIL FSUSE% MOUNTPOINT
loop0 squashfs 0 100% /snap/core20/1169
loop1 squashfs 0 100% /snap/core18/2128
loop2 squashfs 0 100% /snap/lxd/21029
loop3 squashfs 0 100% /snap/lxd/21545
loop5 squashfs 0 100% /snap/snapd/13270
loop6 squashfs 0 100% /snap/snapd/13640
sda
├─sda1
└─sda2 ext4 8ecce3ba-cd9f-494a-966a-d90fc31cd0fc 49.6G 16% /
sdb
└─sdb1 ext4 50292f2c-0f85-4871-9c41-148038b31e24 1.7T 0% /mnt/sdb1
sdc
└─sdc1 ext4 1de9b276-5a5d-41ac-989a-12bdc9ef4d0b 1.7T 0% /mnt/sdc1
sdd
└─sdd1 ext4 420d99a9-de31-4df4-af93-6863f3284f3d 1.7T 0% /mnt/sdd1
sr0
然后在 /etc/fstab 中配置:
/dev/disk/by-uuid/50292f2c-0f85-4871-9c41-148038b31e24 /mnt/sdb1 ext4 defaults 0 0
/dev/disk/by-uuid/1de9b276-5a5d-41ac-989a-12bdc9ef4d0b /mnt/sdc1 ext4 defaults 0 0
/dev/disk/by-uuid/420d99a9-de31-4df4-af93-6863f3284f3d /mnt/sdd1 ext4 defaults 0 0
/mnt/sdb1:/mnt/sdc1/:/mnt/sdd1 /mnt/storage fuse.mergerfs defaults,allow_other,use_ino,category.create=mfs,minfreespace=100G,fsname=mergerfs 0 0
这样重启也会自动进行挂载。
注意 rtorrent 使用
如果要在 mergerfs 上使用 rtorrent 需要注意使用如下配置:
allow_other,use_ino,cache.files=partial,dropcacheonclose=true,category.create=mfs
reference
在 Linux 下使用 Clash For Windows 管理 Clash 订阅
早之前写过一篇文章,当时我直接使用命令行的方式使用 clash,但用过一段时间之后发现 Clash For Windows 支持了 Linux,所以切换到 Clash For Windows,用 UI 界面方便随时切换。
不要看这个 Clash For Windows 的名字有点歧义,实际上是全平台的,不是 Windows 专属的。Clash For Windows 在下文中会简称 CFW。
Clash for Windows 的优点:
- 支持自动选择节点,可以根据延迟自动选择,也可以根据规则
- 支持本地编辑规则
- 支持查看当前订阅的流量等信息
更加详细的使用指南可以参考这个文档
CFW 使用
可以在 GitHub 下载(项目已被删除),也可以使用镜像地址下载。
下载完成后是一个压缩包,解压,并执行其中的 cfw 即可。
添加快捷方式,因为我使用 Cinnamon 是基于 Gnome ,所以可以执行如下命令添加一个快捷方式:
gnome-desktop-item-edit ~/.local/share/applications --create-new
在弹出的窗口中,填写 Name 和 Command
说明:
- Name: 显示的名字
- Command: cfw 的绝对路径
Dashboard:
Clash For Windows 页面:
在 Profile 页面上可以添加订阅地址,订阅地址可以在这里 获取。
related
独服 Proxmox VE 配置 NAT 使虚拟机共用一个公网 IP
[[so-you-start]] 的独立服务器本来安装了 Ubuntu 20.04,后来想想为了充分利用 CPU 和内存,不如安装一个 [[Proxmox VE]] 然后在其基础之上再安装 Ubuntu 或者其他的系统测试。So you Start 通过后台安装 Proxmox 的过程比较简单,我直接使用了后台的 Proxmox VE 6 模板安装了 Proxmox。
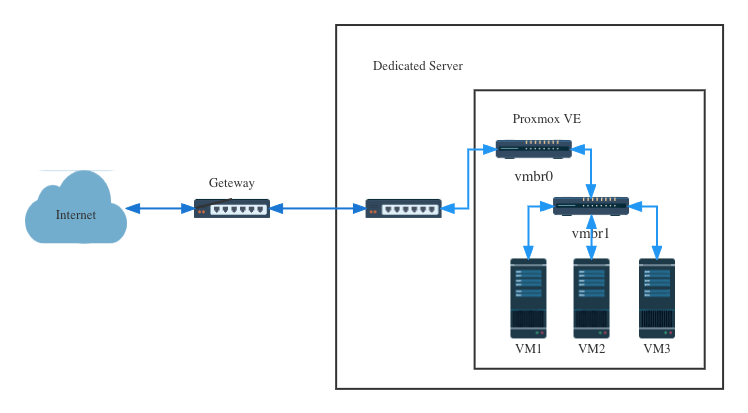
So you Start 其他独立服务器提供商通常只会提供一个公网 IP,其他的 failover IP 可能需要购买(So you Start 可以使用 1.5$ 购买一个),如果不想多花这个购买 IP 的钱,可以配置 Proxmox VE 的虚拟机走 NAT,共用宿主机 Proxmox VE 的 IP,做一下端口转发。实际在一些 VPS 提供商那边也能看到 [[NAT VPS]],这类型的 VPS 就是共用同一个 IP 的 VPS,这一类的 VPS 通常比较便宜,但是可用的端口数量有限。
完成下文的配置之后大致的网络拓扑图是这样的:
前提知识
在继续下文之前有一些前提知识需要了解,否则会理解起来有些困难。
Linux Bridge
Linux Bridge 一般翻译成网桥,相当于一个软件实现的交换机。
如果要配置成 NAT 网络,Proxmox VE 上所有的虚拟机共享一个网桥 vmbr1,通过 vmbr1 访问外部网络。
理论上 Proxmox VE 支持 4094 个网桥。默认情况下 Proxmox VE 会创建一个 vmbr0 的网桥,并和检测到的第一块网卡(eno3)桥接。可以查看网口的配置文件 /etc/network/interfaces 对应的信息:
root@pve:~# cat /etc/network/interfaces
# network interface settings; autogenerated
# Please do NOT modify this file directly, unless you know what
# you're doing.
#
# If you want to manage parts of the network configuration manually,
# please utilize the 'source' or 'source-directory' directives to do
# so.
# PVE will preserve these directives, but will NOT read its network
# configuration from sourced files, so do not attempt to move any of
# the PVE managed interfaces into external files!
auto lo
iface lo inet loopback
iface eno3 inet manual
iface eno4 inet manual
auto vmbr0
iface vmbr0 inet dhcp
bridge-ports eno3
bridge-stp off
bridge-fd 0
NAT
[[NAT]] 全称是 Network Address Translation,在计算机网络中是网络地址转换的含义,也被叫做网络掩蔽,这是一种在 IP 数据包通过路由器或防火墙时重写来源 IP 地址或目的 IP 地址的技术。
在我们的 Proxmox VE 只有一个公网 IP 的情况下,如果要让多个虚拟机共享同一个 IP 地址对外提供服务,就需要用到 NAT 技术,让请求访问到宿主机的时候,转发到对应的虚拟机。
所有的虚拟机使用内部私有 IP 地址,并通过 Proxmox VE 的公网 IP 访问外部网络。我们会使用 iptables 来改写虚拟机和外部通信的数据包:
- 对于虚拟机向外部网络发出的数据包,源地址是内网 IP,目标终端在返回数据的时候,无法把数据包发送对正确的路由,所以在发送出去前,将源地址替换成 Proxmox VE 的 IP 地址
- 对于外部网络返回的数据包,将目的地址替换成对应虚拟机的 IP
NDP
[[NDP]] 全称是 Neighbor Discovery Protocol,简称 NDP,类似 IPv4 中的 ARP 协议。
配置 Proxmox VE NAT
上面的配置也提到了默认情况下 Proxmox VE 会创建一个 vmbr0 桥接找到的网卡。
首先查看一下网络接口:
root@pve:~# ip -f inet a s
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
4: vmbr0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
inet 51.xx.xx.xx/24 brd 51.xx.xx.xxx scope global dynamic vmbr0
valid_lft 81976sec preferred_lft 81976sec
Proxmox VE 上使用 NAT 创建虚拟机的原理是,创建一个 Linux Bridge 并创建一个子网,然后将所有虚拟机包括宿主机都连接到这个子网内,再开启 [[iptables]] 的 NAT 功能。
创建 Linux Bridge
在安装网桥之前,首先安装:
apt install ifupdown2
然后登录 Proxmox VE 后台,创建 Linux Bridge,点击 PVE,然后选择 System -> Networks,然后点击创建。
填写 IP 和子网掩码,IP 地址填写个局域网的网段地址就行。其他项目不用填也不用改,保持默认(不用 IPv6 的情况下)。
- IP 地址填写一个局域网地址:10.0.0.1/24
上面的配置创建了一个新的 vmbr1 网桥分配了一个子网 10.0.0.1/24,宿主机(网关)在子网的 IP 是 10.0.0.1。
创建完成之后,查看 /etc/network/interfaces,然后在对应的 vmbr1 后面修改成相应的配置(注意 vmbr1 下面的配置):
auto lo
iface lo inet loopback
iface eno3 inet manual
iface eno4 inet manual
auto vmbr0
iface vmbr0 inet dhcp
bridge-ports eno3
bridge-stp off
bridge-fd 0
auto vmbr1
iface vmbr1 inet static
address 10.0.0.1/24
gateway 1.2.3.254 # 独立服务器IP前三个数加上 254
bridge-ports none
bridge-stp off
bridge-fd 0
post-up echo 1 > /proc/sys/net/ipv4/ip_forward
post-up iptables -t nat -A POSTROUTING -s '10.0.0.0/24' -o vmbr0 -j MASQUERADE
post-down iptables -t nat -D POSTROUTING -s '10.0.0.0/24' -o vmbr0 -j MASQUERADE
post-up iptables -t nat -A PREROUTING -i vmbr0 -p tcp --dport 2022 -j DNAT --to 10.0.0.102:22
post-down iptables -t nat -D PREROUTING -i vmbr0 -p tcp --dport 2022 -j DNAT --to 10.0.0.102:22
说明:
ip_forward一行表示开启 IPv4 转发,这个是内核参数,将 Linux 当作路由器用的参数。一般来说,一个路由器至少要有两个网络接口,一个 WAN,一个 LAN,为了让 LAN 和 WAN 流量相同,需要内核上的路由post-up和post-down分别表示网卡启用和禁用之后,执行后面的命令iptables行表示,开启防火墙转发,-A表示添加规则,配置一条 NAT 规则,源地址为10.0.0.0/24的流量,转发到vmbr0接口。- MASQUERADE 对 IP 地址数据包进行改写
- 网卡关闭后
-D删除这条规则 -
最后 2 行是把虚拟机 10.0.0.102 上的 22 端口 NAT 到宿主机的 2022 端口,这样使得外部的网络可以通过 Proxmox VE 宿主机的 2022 端口访问虚拟机的 22 端口,可以直接使用上面的配置,或者手动执行下面的命令:
iptables -t nat -A PREROUTING -i vmbr0 -p tcp --dport 2022 -j DNAT --to 10.0.0.102:22
最后两行配置在网络配置中是为了让系统重启之后配置依然生效。否则 iptables 的转发就可能丢失。
启用网桥:
sudo ifup vmbr1
显示信息:
ip address show dev vmbr1
查看 iptables 配置是否生效:
iptables -L -t nat
结果:
root@pve:~# ip address show dev vmbr1
9: vmbr1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UNKNOWN group default qlen 1000
link/ether 62:32:cf:9d:5d:f9 brd ff:ff:ff:ff:ff:ff
inet 10.0.0.1/24 scope global vmbr1
valid_lft forever preferred_lft forever
inet6 fe80::6032:cfff:fe9d:5df9/64 scope link
valid_lft forever preferred_lft forever
重启网络:
sudo systemctl restart networking
systemctl status networking.service
通过上面的方式创建了 vmbr1 的网桥之后,再创建新的虚拟机就可以使用这个新的子网。因为这里没有配置 DHCP,所以虚拟机需要设定静态 IP 地址。
在我的真实操作中,我发现无论我怎么重启 systemctl restart networking 都无法使得 Proxmox VE 的网络配置生效,最后不得不重启服务器才可以。
虚拟机配置
在创建虚拟机的时候,记得在网络配置的时候选择 vmbr1,因为没有配置 DHCP 所以需要用下面的方式手动指定虚拟机的静态 IP 地址。
Ubuntu 虚拟机网络配置
Ubuntu 从上一个版本开始就使用 netplan 来管理网络配置,所以需要修改 netplan 的配置:
einverne@ubuntu2:~$ cat /etc/netplan/00-installer-config.yaml
# This is the network config written by 'subiquity'
network:
ethernets:
ens18:
addresses:
- 10.0.0.102/24
gateway4: 10.0.0.1
nameservers:
addresses:
- 8.8.8.8
- 8.8.4.4
version: 2
注意配置其中的静态地址和网关。
- 静态地址配置
10.0.0.0/24网段下的地址,比如10.0.0.102 gateway4地址配置 vmbr1 网桥的地址- DNS 服务器可以使用 Google 的,也可以用 1.1.1.1 Cloudflare 的,或者 OVH,或者 So you Start 提供的都行
修改完成后执行:
netplan apply
之后可以使用如下命令测试连通性:
ping 1.1.1.1
ping google.com
Debian 虚拟机网络配置
Debian 上的网络配置如下:
einverne@debian:~$ cat /etc/network/interfaces.d/50-cloud-init
auto ens18
iface ens18 inet static
address 10.0.0.100
netmask 255.255.255.0
gateway 10.0.0.1
dns-nameserver 1.1.1.1
dns-nameserver 8.8.8.8
说明:
ens18是 Debian 虚拟机的网络接口address填写10.0.0.0/24网段的静态地址gateway填入 vmbr1 的地址
然后重启网络:systemctl restart networking。
如何调试
在配置的过程中遇到很多问题,可以用一下一些命令熟悉 Linux 下的网络配置。
iptalbes -L -t nat
ip a
ip route show
cat /proc/sys/net/ipv4/ip_forward
qm config <VMID>
遇到的问题
虚拟机 VM 内部无法访问互联网
在按照上述步骤配置后,登录 VM (Ubuntu 20.04) 内部,只能 Ping 通网关(10.0.0.1) 而无法 ping 通任何外部网络。
再经过一番调查之后发现在上述配置中的 iptables 转发并没有生效,并且重启网络也没有生效,所以我只能重启服务器解决。
端口映射
在启用 NAT 网络之后,如果要外部网络访问 VM 的端口,则需要开启 iptables 端口转发。
下面一句的含义就是将 Proxmox VE(vmbr0) 的 2022 端口转发到 10.0.0.102 这台虚拟机的 22 端口:
iptables -t nat -A PREROUTING -i vmbr0 -p tcp --dport 2022 -j DNAT --to 10.0.0.102:22
这样在外部互联网就可以通过 ssh -p 2022 root@<proxmox ip> 来访问 Proxmox VE 中的虚拟机了。
如果遇到要转发一组端口可以使用:
post-up iptables -t nat -I PREROUTING -p tcp -i vmbr0 --dport 8000:9000 -j DNAT --to 10.0.0.102:8000-9000
post-down iptables -t nat -D PREROUTING -p tcp -i vmbr0 --dport 8000:9000 -j DNAT --to 10.0.0.102:8000-9000
延伸阅读
如果已经购买了 Failover IP,或者独立服务器提供了多个可用的 IP,那么也可以参考 这篇文章 配置 Proxmox VE 的虚拟机使用额外的 IP 地址。这样使用一台独立服务器就可以开多个 KVM 的 VPS 了。
reference
命令行下使用 jdupes 删除重复的文件
很早之前整理过一篇文章介绍了几个之前在 Linux 上用过的用来快速找到重复文件并删除的文章,这么多年过去了,最后发现还是 jdupes 最好用,因为是 c 语言编写,可以在所有平台上面运行,并且速度远远好于其他的命令。
之前的文章对于 jdupes 总结的比较简单,所以这里单独再总结一下 jdupes 常用的几个例子。
查找文件夹下重复文件
查找文件夹下重复的文件,这也是最常见的需求,可以直接
jdupes -r path/to/dir
-r 参数在这里表示 --recurse 递归查找文件夹下所有的子文件夹。
删除重复内容
jdupes 在输出重复的内容的同时也提供了方法可以让用户自行选择删除哪个文件,或者自动发现并删除重复的文件。
注意:个人推荐每一次都手动选择需要删除的内容,否则请提前做好备份工作,防止文件丢失
jdupes 提供了 -d 选择,如果使用 -d 选项,jdupes 会弹出提示让用户选择是否删除重复文件:
jdupes -dr path/to/dir
如果确定自己不需要手动选择删除,可以使用 -N 选项,表示 --noprompt,谨慎使用该选项:
jdupes -r -N path/to/dir
查找两个文件夹下重复文件并删除第二个文件夹下的重复内容
有些时候文件在两个文件夹中,比如 dir1, dir2,需要实现的是将 dir2 中和 dir1 中重复的文件删除,而保留 dir1 中的文件,这个时候可以使用 -O 选项。
-O 选择可以让用户控制出现在第一条的文件,以便将其保留。
jdupes -nrdNO dir1 dir2
上面的命令会递归查找 dir1 和 dir2 中的文件,并自动将 dir2 中和 dir1 重复的文件删除。
reference
So you Start 独服 Proxmox VE 虚拟机配置 Failover IP
最近买了一台 [[so-you-start]] 的独立服务器,开始的时候安装了 Ubuntu 没有充分利用独立服务器的优势,所以这两天把系统重新安装成了 [[Proxmox VE]],然后在上面又安装了 Ubuntu 20.04,So you Start 提供了额外 16 个可以以 1.5 美元购买的 [[Failover IPs]],Failover IP 本来是为了可以将服务器迁移到另外的服务器而提供的机制,但在 Proxmox VE 虚拟化技术系统下,可以给虚拟机也分配不同的 IP,这样就实现了从一台服务器虚拟化多个 VPS 的操作。
安装 Proxmox VE 的过程就不多说了,在 So you Start 或者 OVH 后台直接使用模板安装即可,我使用的 6.x 版本,没有升级到最新的 7 版本。
安装完成后使用 Ubuntu Server 的 ISO 镜像完成虚拟机的安装。
前提准备工作
- 一台安装好 Proxmox VE 的独立主机
- 新建一台可以登录的虚拟机,操作系统不限 (推荐 Debian/Ubuntu)
- 购买好至少一个额外的 Failover IP
配置 Failover IP 到虚拟机
Create a Virtual MAC Address
首先到 So you Start 后台 IP,然后选择购买的 Failover IP,新增 virtual MAC 地址,然后复制该 MAC 地址备用。
比如:
02:01:00:78:95:aa
新增 MAC 地址可能有一点延迟,等待一小会儿生效即可。
Add virtual MAC to the NIC of a VM
然后需要在 Proxmox VE 虚拟机配置中将上述 MAC 地址配置。如果还没有安装虚拟机,可以参考 Proxmox VE 官网的教程 。
VM 配置前需要是关闭状态。
在 Proxmox VE 中,找到虚拟机的 Hardware
找到 Network Device 选项,默认情况下是一个随机生成的 MAC 地址:
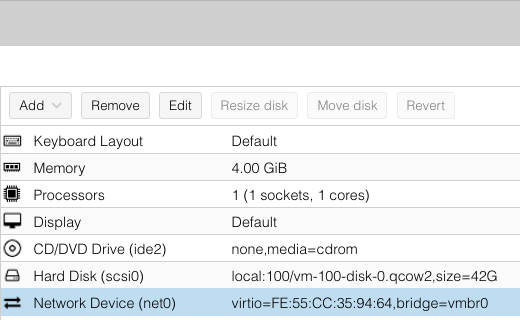
点击 Edit,然后在 MAC address 一栏将上一步的虚拟 MAC 地址填入,并保存。
然后启动 VM,接下来需要配置虚拟机的网络接口。
Configuring Network Settings
配置虚拟机网络。
Debian 10
首先查看一下接口:
ip addr
除了一个 lo 应该能看到类似 ens18 这样的接口。
Debian 的网络接口配置在 vi /etc/network/interfaces:
# This file describes the network interfaces available on your system
# and how to activate them. For more information, see interfaces(5).
source /etc/network/interfaces.d/*
# The loopback network interface
auto lo
iface lo inet loopback
# The primary network interface
auto ens18
iface ens18 inet static
address 192.0.2.1
netmask 255.255.255.0
gateway 203.0.113.254
dns-nameservers 208.67.222.222 208.67.220.220
说明:
- 修改其中的 ens18 为自己的相应的配置
- address 一行:
192.0.2.1修改为自己的 Failover IP - gateway 一行:
203.0.113.254前 3 个字节的数字,修改成独立服务器 IP 地址的前三个字节 IP 地址,最后添加 254,比如独立服务器的 IP 是1.2.3.4,那么使用1.2.3.254作为网关 - 最后一行是 DNS 设置,可以使用上面使用的 OpenDNS,也可以使用任何其他的,比如 Cloudflare 的 1.1.1.1, 或者 Google 的 8.8.8.8
然后使得接口生效:
ip link set ens18 up
最后重启 networking:
systemctl restart networking
然后可以测试连通性:
ping 8.8.8.8
能够 ping,表示已经可以联网。
ping google.com
然后看一下 DNS 解析,如果域名无法解析,我这边情况是少了 /etc/resolv.conf,手工创建文件并写入:
nameserver 8.8.8.8
即可。
Ubuntu 18.04
Ubuntu 从 17 版本开始就使用 Netplan 来管理网络配置,所以和 Debian 有一些区别。
修改 netplan 配置文件,根据不同的系统可能配置文件路径不一样,请注意一下:
vi /etc/netplan/01-netcfg.yaml
vi /etc/netplan/00-installer-config.yaml
然后使用:
# This is the network config written by 'subiquity'
network:
version: 2
renderer: networkd
ethernets:
ens18:
dhcp4: no
dhcp6: no
addresses:
- 192.0.2.1/32 # 这里填写 failover ip(vMAC 地址需要提前配好)
- 1111:2222:3333:6666::2/64 # 如果有 IPv6 地址也可以配上,an ipv6 from your server allocation
gateway4: 1.2.3.254
nameservers:
addresses: [8.8.8.8, 1.1.1.1]
routes:
- to: 1.2.3.254/32
via: 0.0.0.0
scope: link
和上面的配置类似,对应替换即可。
然后使之生效:
sudo netplan apply
注意在配置 Ubuntu 22.04 的时候 Netplan 可能会有一 WARNING:
gateway4has been deprecated, use default routes instead. See the ‘Default routes’ section of the documentation for more details.
简单的查了一下 Netplan 的配置格式发生了改变。如果不修改理论上也没有关系,不过为了之后兼容,可以改用 Netplan 最新的配置。1
reference
文章分类
最近文章
- Dinox 又一款 AI 语音实时转录工具 前两天介绍过 [[Voicenotes]],也是一款 AI 转录文字的笔记软件,之前在调查 Voicenotes 的时候就留意到了 Dinox,因为是在小红书留意到的,所以猜测应该是国内的某位独立开发者的作品,整个应用使用起来也比较舒服,但相较于 Voicenotes,Dinox 更偏向于一个手机端的笔记软件,因为他整体的设计中没有将语音作为首选,用户也可以添加文字的笔记,反而在 Voicenotes 中,语音作为了所有笔记的首选,当然 Voicenotes 也可以自己编辑笔记,但是语音是它的核心。
- 音流:一款支持 Navidrom 兼容 Subsonic 的跨平台音乐播放器 之前一篇文章介绍了Navidrome,搭建了一个自己在线音乐流媒体库,把我本地通过 [[Syncthing]] 同步的 80 G 音乐导入了。自己也尝试了 Navidrome 官网列出的 Subsonic 兼容客户端 [[substreamer]],以及 macOS 上面的 [[Sonixd]],体验都还不错。但是在了解的过程中又发现了一款中文名叫做「音流」(英文 Stream Music)的应用,初步体验了一下感觉还不错,所以分享出来。
- 泰国 DTV 数字游民签证 泰国一直是 [[Digital Nomad]] 数字游民青睐的选择地,尤其是清迈以其优美的自然环境、低廉的生活成本和友好的社区氛围而闻名。许多数字游民选择在泰国清迈定居,可以在清迈租用廉价的公寓或民宿,享受美食和文化,并与其他数字游民分享经验和资源。
- VoceChat 一款可以自托管的在线聊天室 VoceChat 是一款使用 Rust(后端),React(前端),Flutter(移动端)开发的,开源,支持独立部署的在线聊天服务。VoceChat 非常轻量,后端服务只有 15MB 的大小,打包的 Docker 镜像文件也只有 61 MB,VoceChat 可部署在任何的服务器上。
- 结合了 Google 和 AI 的对话搜索引擎:Perplexity AI 在日本,因为 SoftBank 和 Perplexity AI 开展了合作 ,所以最近大量的使用 Perplexity ,这一篇文章就总结一下 Perplexity 的优势和使用技巧。