Apache [[ZooKeeper]] 是 Apache 软件基金会的一个软件项目,为大型分布式计算提供开源的分布式协调系统,提供的功能包括配置服务、同步服务和命名注册等。Zookeeper 项目的初衷就是为了降低分布式应用从头开发协同服务的负担。
ZooKeeper
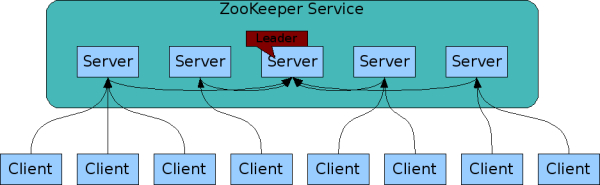
ZooKeeper is a high-performance coordination service for distributed applications. It exposes common services - such as naming, configuration management, synchronization, and group services - in a simple interface so you don’t have to write them from scratch. You can use it off-the-shelf to implement consensus, group management, leader election, and presence protocols. And you can build on it for your own, specific needs.
基本功能也如上述所说可以概括成:
- 配置管理,将配置内容放到 ZooKeeper 某节点中
- 集群管理,管理节点,选主
- 命名服务,创建全局唯一 path
- 共享锁
- 队列管理
通常实际使用场景比如管理 HBase 集群,配置管理,和 Kafka 配合等等,Zookeeper 设计更专注于任务协作,并没有提供任何锁的接口或通用存储数据接口。
Zookeeper 不适合用来作为海量存储,对于大量数据的存储应该考虑数据库或者分布式文件系统。
设计目的
- 最终一致性:client 不论连接到哪个 Server,展示给它都是同一个视图,这是 zookeeper 最重要的性能。
- 可靠性:具有简单、健壮、良好的性能,如果消息 m 被其中一台服务器接受,那么它将被所有的服务器接受。
- 实时性:Zookeeper 保证客户端将在一个时间间隔范围内获得服务器的更新信息,或者服务器失效的信息。但由于网络延时等原因,Zookeeper 不能保证两个客户端能同时得到刚更新的数据,如果需要最新数据,应该在读数据之前调用 sync() 接口。
- 等待无关(wait-free):慢的或者失效的 client 不得干预快速的 client 的请求,使得每个 client 都能有效的等待。
- 原子性:更新只能成功或者失败,没有中间状态。
- 顺序性:包括全局有序和偏序两种:全局有序是指如果在一台服务器上消息 a 在消息 b 前发布,则在所有 Server 上消息 a 都将在消息 b 前被发布;偏序是指如果一个消息 b 在消息 a 后被同一个发送者发布,a 必将排在 b 前面。
数据结构和等级
Zookeeper 提供的命名空间通常是 / 开头,并且有着明确的等级管理。
Zookeeper 命名空间中的每一个节点(node)都包含一组数据,子节点亦然。可以想象成文件系统中的目录,但是这个目录同样也有数据。Zookeeper 被设计用来保存协同数据,包括状态信息,配置,位置信息,等等,所以数据通常很小,bytes 到 kilobyte 大小。通常把这些节点叫做 znode。
Znodes 维护一个结构,包含数据变化版本号,ACL 变化,时间戳,cache 验证等。每一个节点都拥有 Access Control List(ACL) 限制谁可以访问。Znode 的版本号随着数据变化而递增。
基本原理
ZooKeeper 数据节点类型:
- 临时节点 (ephemeral) 会话结束,被服务端干掉
- 永久节点 (persistent) 可持久化
- 顺序节点 (sequence) 顺序节点
服务器节点类型
- leader: 选举出的 leader 服务器节点
- follower: 负责参与选举的服务器节点
- observer: 不参加选举
服务端选举算法 Paxos 类似 客户端通信方式 JAVA-NIO
服务端运行
ZooKeeper 服务器端运行于两种模式下:standalone 和 quorum。
- standalone 一个单独服务器,ZooKeeper 状态无法复制。
- quorum 一组服务器,同时服务器客户端请求。
选举算法,类似 [[Paxos 算法]]
ZKReentrantLock lock = new ZKLock(zk,timeout,sessionManager);
lock.lock();
....... your thing
lock.unlock();
ZAB 协议
ZAB 协议(Zookeeper Atomic Broadcast)是为分布式协调服务 ZooKeeper 专门设计的一种支持崩溃恢复的原子广播协议。在 ZooKeeper 中,主要依赖 ZAB 协议来实现分布式数据一致性
术语
quorum:集群中超过半数的节点集合
ZAB 中的节点有三种状态:
- following:当前节点是跟随者,服从 leader 节点的命令
- leading:当前节点是 leader,负责协调事务
- election/looking:节点处于选举状态
节点的持久状态
- history:当前节点接收到事务提议的 log
- acceptedEpoch:follower 已经接受的 leader 更改年号的 NEWEPOCH 提议
- currentEpoch:当前所处的年代
- lastZxid:history 中最近接收到的提议的 zxid (最大的)
Zab 可以满足以下特性
- Reliable delivery 可靠提交:如果消息 m 被一个 server 递交 (commit) 了,那么 m 也将最终被所有 server 递交。
- Total order 全序:如果 server 在递交 b 之前递交了 a,那么所有递交了 a、b 的 server 也会在递交 b 之前递交 a。
- Casual order 因果顺序:对于两个递交了的消息 a、b,如果 a 因果关系优先于 (causally precedes)b,那么 a 将在 b 之前递交。
follower 要么 ack,要么抛弃 Leader,因为 zookeeper 保证了每次只有一个 Leader。另外也不需要等待所有 Server 的 ACK,只需要一个 quorum 应答就可以了。
Zab 工作模式
两种模式,分为 broadcast 模式(广播模式,同步)和 recovery 模式(恢复模式,选 leader)
为了保证事务的顺序一致性,ZooKeeper 采用了递增的事务 id 号(zxid)来标识事务。所有的提议(proposal)都在被提出的时候加上了 zxid。实现中 zxid 是一个 64 位的数字,它高 32 位是 epoch 用来标识 leader 关系是否改变,每次一个 leader 被选出来,它都会有一个新的 epoch,标识当前属于那个 leader 的统治时期。低 32 位用于递增计数。
每个 Server 在工作过程中有三种状态:
- LOOKING:当前 Server 不知道 leader 是谁,正在搜寻
- LEADING:当前 Server 即为选举出来的 leader
- FOLLOWING:leader 已经选举出来,当前 Server 与之同步
Follower 收到 proposal 后,写到磁盘(尽可能批处理),返回 ACK。
Leader 收到大多数 ACK 后,广播 COMMIT 消息,自己也 deliver 该消息。
Follower 收到 COMMIT 之后,deliver 该消息。
选主流程
leader 奔溃或者 leader 失去大多数 follower 时,zk 进入恢复模式,恢复
reference
- https://zookeeper.apache.org/
- http://zookeeper.apache.org/doc/r3.4.13/zookeeperOver.html
- 《ZooKeeper 分布式过程协同技术》