使用 Nemo 文件管理器
自从用上 mint 之后,我才发现原来 File Manager 能这么好用,Cinnamon 自带的文件管理叫做 Nemo ,至今用过 Windows,Mac,Ubuntu 还要各种发行版,但是唯有 Cinnamon 自带的这个 Nemo 的文件管理器让我用起来最舒服。至于为什么,我一一道来。
功能
双栏
Nemo 外观很简单,和大多数操作系统的 File Browser 都差不多,左边栏基本上是顶层导航栏,然后主体部分是文件浏览的功能。但是我非常喜欢的双栏设计,当时使用 Windows 的时候还需要借助 Total Commander,而 Mac 的 Finder 是层级的,基本上如果一层一层打开文件夹就会出现一连串的中间文件夹列表,依然不能使用双栏。
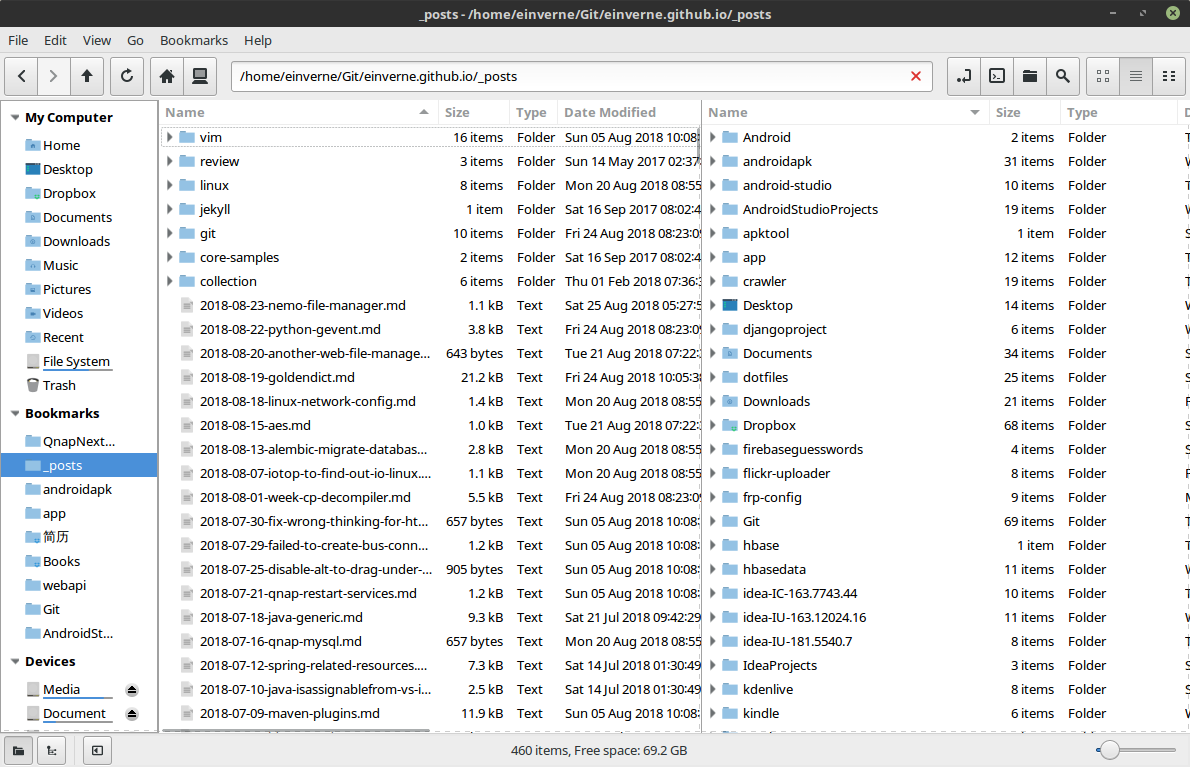
Nemo 的双栏模式叫做 Extra pane,右边一栏可以通过快捷键 F3 快速启动和隐藏,这就使得文件移动复制变得异常简单。当然有人说 mv path1 path2 更快当然在有命令行的情况下就不是同一比较线了。
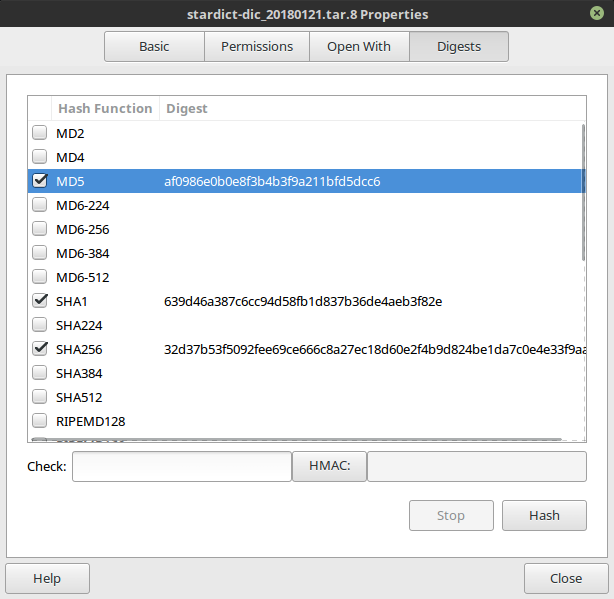
检查 md5
很多时候下载文件要检查文件的完整性,大部分情况下都 md5sum ~/Downloads/large.file.tar.gz 然后完成了,但是 Nemo extension 原生支持
折叠文件夹
同一个层级的文件夹也可以类似树形展开
标签页
我可以说其他 Windows,Mac 都需要其他额外的软件来支持文件管理器中的标签页,而 Nemo Ctrl+T 就能支持,这和我 Chrome 的快捷键 是一致的。
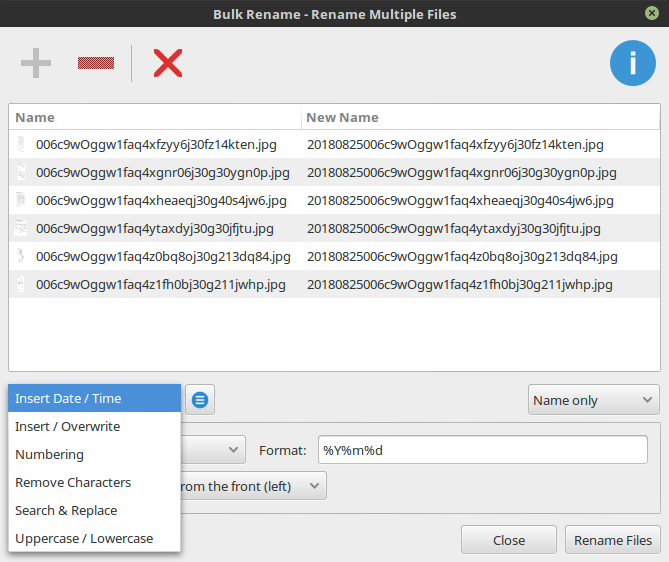
批量修改文件名
有人说不存在,其实 Nemo 本身不带批量重命名功能,但是 Nemo 是支持调用 thunar 的。
sudo apt install thunar
然后在设置中 Edit->Preferences->Behaviour 标签下 ‘Bulk rename’ 空白栏中填入:
thunar -B
然后 nemo -q 重启,此时再多选,就可以批量重命名了
扩展
下面就是最主要的部分了,记住如果要想使得 Nemo 在安装之后生效需要强制重启 Nemo nemo -q 来退出。
Dropbox 支持
Dropbox 同步标示
sudo apt install nemo-dropbox
Nextcloud 支持
Nextcloud 同步标示
sudo apt install nextcloud-client-nemo
nemo-gtkhash
Nemo gtkhash 就是用来显示文件 md5,sha 等等
sudo apt install nemo-gtkhash
nemo-fileroller
Nemo Fileroller 扩展就是用来在上下文菜单中管理压缩包,压缩 / 解压功能的,配合 Compress,几乎可以解压所有文件,压缩也支持非常多的格式。如果 Nemo 中右键没有压缩和解压缩的选项,不要慌一行命令就能解决。
sudo apt-get install nemo-fileroller
nemo -q
然后重启 nemo 即可。
nemo-share
能够快速在浏览文件时共享到 samba
sudo apt install nemo-share
nemo-compare
使用 meld 来比较两个文件夹,或者两个文件
sudo apt install nemo-compare
nemo-seahorse
PGP 加密和签名的工具
sudo apt install nemo-seahorse
nemo-terminal
在文件夹中显示嵌入的命令行
sudo apt install nemo-terminal
nemo-emblems
可以用来自定义文件夹图标
nemo-audio-tab
用来显示 mp3 的包含的 meta 信息,包括 title, artist, album 等等
nemo-pastebin
支持直接上传到 pastebin ,我不怎么用所以没有安装
Tips
Nemo Actions
Nemo 允许用户自己定义上下文菜单,文件 /usr/share/nemo/actions/sample.nemo_action 包含一个样例,存放自定义 actions 脚本的目录:
/usr/share/nemo/actions/系统级别~/.local/share/nemo/actions/用户级别脚本
actions 脚本必须以 .nemo_action 结尾
扫描病毒脚本 clamscan.nemo_action,需要提前安装 ClamAV
[Nemo Action]
Name=Clam Scan
Comment=Clam Scan
Exec=gnome-terminal -x sh -c "clamscan -r %F | less"
Icon-Name=bug-buddy
Selection=Any
Extensions=dir;exe;dll;zip;gz;7z;rar;
在比如检查 md5 或者 sha1 也可以直接放到右击菜单中
[Nemo Action]
Active=true
Name=Check SHA256
Name[fr]=Vérifier le SHA256
Comment=Check the SHA256 signature of the file
Comment[fr]=Vérifier la signature SHA256 de ce fichier
Exec=mint-sha256sum '%F'
Icon-Name=gtk-execute
Selection=S
Mimetypes=application/x-iso9660-image;image/png;image/jpeg;
再比如我写一个脚本将选中的文件或者文件夹中空格部分替换为 _
format_filename.nemo_action 如下
[Nemo Action]
Active=true
Name=Format filename %N
Comment=Replace filename space with - applied to %N
Exec=<format_filename.py %F>
Selection=any
Extensions=any;
EscapeSpaces=true
python 脚本名叫 format_filename.py
import sys
import os
command = sys.argv[0]
print("Running " + command)
print("With the following arguments:")
for arg in sys.argv:
if command == arg:
continue
else:
formated_path = arg.replace(' ', '_')
os.rename(arg, formated_path)
在 nemo_action 文件中用到了一些内置的变量
- %U - insert URI list of selection
- %F - insert path list of selection
- %P - insert path of parent (current) directory
- %f or %N (deprecated) - insert display name of first selected file
- %p - insert display name of parent directory
- %D - insert device path of file (i.e. /dev/sdb1)
官方的样例可以查看本地的文件也可以看 GitHub
Nemo Actions 将 Nemo 文件管理器的功能上升了另外一个层面,如果 Python/Bash 能够做的事情,那么在 Nemo 中都能够完成。那几乎就是所有的任务都能够在文件管理器中右键完成了。再举个简单的例子,我经常用 ffmpeg 将 Mp4 中的音频提取出来,那么就可以直接用 Actions ,然后定义
Exec=gnome-terminal -x sh -c 'ffmpeg -i %F -f mp3 anyname.mp3'
当然其他的都可以完成了。
配置
默认情况下 Ubuntu 下面默认的文件管理器还是 nautilus.desktop , 可以使用如下命令查看默认的文件管理器
xdg-mime query default inode/directory
我电脑上返回的结果是 nautilus-folder-handler.desktop
如果本地机器已经安装了 nemo,那么可以使用如下命令将默认的文件管理器设置为 nemo
xdg-mime default nemo.desktop inode/directory application/x-gnome-saved-search
如果想要恢复之前的设置,将 nemo.desktop 设置回去即可
xdg-mime default nautilus.desktop inode/directory application/x-gnome-saved-search
然后可以使用 xdg-open $HOME 来验证有没有生效。
reference
Python 并发编程之 gevent
gevent 中最主要的是 greenlet,greenlet 是 Python 的 C 扩展,用来实现协程。
协程 [[Coroutine]],就是可以暂时中断,之后再继续执行的程序
事实上 Python 就有最基础的 Coroutine,也就是生成器 generator
协程就是一种特殊的并发机制,其调度”就是指什么时候调用什么函数”完全由程序员指定
- 进程是一个操作系统级别的概念,拥有自己独立的堆和栈,既不共享堆,亦不共享栈,进程由操作系统调度。
- 线程拥有自己独立的栈和共享的堆,共享堆,不共享栈,线程亦由操作系统调度(标准线程)。
- 协程和线程一样共享堆,不共享栈,协程由程序员在协程的代码里显示调度。
greenlet
看一个最经典的生产者消费者模型。
from greenlet import greenlet
from time import sleep
def consumer():
last= ''
while True:
receival = pro.switch(last)
if receival is not None:
print(f'Consume {receival}')
last = receival
sleep(1)
def producer(n):
con.switch()
x = 0
while x < n:
x += 1
print(f'Produce {x}')
last = con.switch(x)
pro = greenlet(producer)
con = greenlet(consumer)
pro.switch(10)
gevent
gevent 是一个并发网络库,他的协程是基于 greenlet 的。并基于 libev 实现快速事件循环(Linux 上是 epoll,FreeBSD 上是 kqueue,Mac OS X 上是 select)。
一个比较通俗的解释就是当 greenlet 遇到 IO 操作,比如访问网络时自动切换到其他 greenlet ,等 IO 操作完成,在适当的时候切换回来继续执行。由于 IO 操作非常耗时,经常使程序处于等待状态,所以 gevent 保证总是有 greenlet 在运行,而不是等待 IO。
import gevent
def foo():
print('Running in foo')
gevent.sleep(0)
print('Explicit context switch to foo again')
def bar():
print('Explicit context to bar')
gevent.sleep(0)
print('Implicit context switch back to bar')
gevent.joinall([
gevent.spawn(foo),
gevent.spawn(bar),
])
gevent.spawn() 方法会创建一个新的 greenlet 协程对象,gevent.joinall() 方法会等待所有传入的 greenlet 协程运行结束后再退出。
优缺点
gevent 的优点如下:
- 执行效率高,子程序切换几乎没有开销,与多线程相比,线程越多,协程性能越明显
- 不需要多线程的锁机制,因为只有一个线程,也不存在同时写变量冲突,在控制共享资源时也不需要加锁
- I/O 多路复用是在一个进程内部处理多个逻辑流程,不用进行进程切换,性能较高,另外流程间共享信息简单。
- 协程有编程语言提供,由程序员控制进行切换,所以没有线程安全问题,可以用来处理状态机,并发请求等 IO 密集型任务
gevent 缺点如下:
- 不能利用 CPU 多核优势
- 程序流程被事件处理切割成一个个小块,程序比较复杂,难于理解
所以,协程的适用场景,应该是一些IO 密集型的并行程序,而对应的计算密集型,应当采用传统的多线程、多进程方案。
相关知识点
- Threads
- Processes
- SubProcess (Or os.system calls)
- concurrent.futures
- gevent, greenlet etc
- asyncio aiodns
- cython (Disabling the GIL)
- Writing C extensions
reference
又一个网页文件管理:filebrowser
之前一直使用的是 h5ai,平时也够用,不过 h5ai 是不能上传文件编写文件的,这算是一个问题吧,今天正好看到了 filebrowser,以前叫做 file manager。
File Browser 是一个用 Go 和 Vue 编写的基于 Web 的文件管理器。
去官网看来一眼,发现支持 docker, 所以就比较方便了。
具体 docker compose 的文件见 这里
只要配置好,几乎就是一键安装了。以后转战 filebrowser 了。
默认的用户名和密码是 admin/admin,记得登录进去第一件事情就是修改密码。
Linux 下非常好用的字典 GoldenDict
最近在使用 Linux 版有道的时候发现非常卡,影响正常使用,所以就发现了这个 GoldenDict。以前在 Win 下用过 lingoes 但是无奈只有 Win 版本。有的时候也真的挺有意思,闭源的软件用着不舒服,切换到开源软件之后就像打开了新天地,从搜狗切换到 Rime 也是,开源软件不仅在功能上优于这些闭源软件,自己稍微调整一下之后就会发现体验也远超有道,搜狗之类。
GoldenDict 是一个开源词典,用 QT 编写,使用 WebKit 作为渲染核心,它像 Eudict、Mdict、Lingoes 以及 BlueDict 等词典一样可以加载外挂词典文件。基于 GNU GPL 第三版以上协议。
使用 GoldenDict 配上习惯的词典和脚本之后就再也离不开这个工具了,设置开机启动,设置 Ctrl + c两次查当前选中的词,定期的复习和整理查词列表中的词汇,这个工具完美的解决了我查词的需求,并且提供了远超出我想象的功能,中文成语,地名人名,专业术语,韩语,日语完全完全满足了所有查询的需求。
2020 年 8 月更新,让我异常惊喜的时,当我更换到 MacOS 时,GoldenDict 的 Mac 版虽然很久没有更新,但依然可以非常完美的工作,Syncthing 同步字典文件和脚本 后立马就工作,不用改变习惯,并且我也没有习惯使用 Mac 上自带的词典(虽然和系统集成得比较好,重按触摸板选中单词即可)。
2023 年 3 月更新,macOS 因为发布了 ARM 芯片的 MacBook,所以 GoldenDict 也可以选择 这个版本 ,可以在 M1,M2,芯片下运行。
安装
Ubuntu/Linux Mint 下安装非常简单
sudo apt install goldendict
- For linux: https://github.com/goldendict/goldendict/wiki/Early-Access-Builds-for-Linux-Portable
- For Mac OS X : https://github.com/goldendict/goldendict/wiki/Early-Access-Builds-for-Mac-OS-X
- For Windows: https://github.com/goldendict/goldendict/wiki/Early-Access-Builds-for-Windows
macOS
原始版本的 GoldenDict 因为有一些时间没有发布二进制,所以在最新的 macOS 上可能会遇到一些兼容性问题。
这里推荐几个别人维护的版本
- GoldenDict++ 增强了 OCR,以及做了一些兼容性修改
功能特色
支持的字典格式
- Babylon .BGL files, Babylon(巴比伦)词典的 .BGL 格式文件,完整保留全部图片及其他资源
- StarDict .ifo/.dict./.idx/.syn dictionaries StarDict(星际译王)
- MDict .mdd and .mdx 文件,mdd 文件是音频图片部分,mdx 是索引
- Dictd .index/.dict(.dz) dictionary files
- ABBYY Lingvo .dsl 源文件,together with abbreviations. The files can be optionally compressed with dictzip. Dictionary resources can be packed together into a .zip file.
- ABBYY Lingvo .lsa/.dat 格式音频档案 . Those can be indexed separately, or be referred to from .dsl files.
- Lingoes 灵格斯词霸 .ld2 这里需要指出来的是 ld2 格式只有移动版 Android 才支持
更多支持的格式可以参考这里
其他功能特色
- 支持 Windows, Linux, Mac, Android,Android 版是商业软件,免费版最多能用 5 本词典,支持分享查词。
- 完美支持单词复数,ing 形式等变形(软件设置中 morphology)
- 支持查阅 Wikipedia、Wikitionary 及任何其他基于 Mediawiki 的站点。
- 支持使用模板化的 Url 样式来使用任何网页。
- 支持查找与收听 forvo.com 网站上面的发音。
- 基于 hunspell 的词法系统,用于词语的溯源及拼法建议。
- 能够索引任意路径下面的音频文件以查找语音。
- 弹出搜索功能:一个小窗口会弹出,用于显示在另一程序中选中的单词的词义。
- 支持全局热键,可在任何一点触发该程序,或直接从剪切板中查找词义。
GoldenDict 开机启动
在 Linux gnome 桌面环境下,可能会发现 GoldenDict 设置选项中的开机启动是灰色的按钮无法选中。其实 gnome 自己有一个开机管理的应用叫做 startup application,在这个应用中添加 GoldenDict 即可。
GoldenDict 长句翻译问题
GoldenDict 在查词方面非常完美,但唯独在长句翻译上落后一些,但是问题不大,利用 Python脚本 添加到 GoldenDict 后整段的翻译问题也解决了。
[[202008262304-GoldenDict查长句]]
词典分组
可以在菜单栏中群组,添加群组,然后为群组增加几部字典,然后添加快捷键对字典进行分组,方便快速查阅。
比如可以将同义词词典单独分类,比如可以将常用词词典分类,方便进行查看。
字典安装
在线字典
菜单栏选择【编辑】>【词典】>【词典来源】>【网站】> 添加 > 启用 可以启用在线的字典。
欧陆
https://dict.eudic.net/dicts/en/%GDWORD%
有道的源
http://dict.youdao.com/search?q=%GDWORD%&ue=utf8
Bing 中文的源
https://cn.bing.com/dict/search?q=%GDWORD%
iciba
http://www.iciba.com/%GDWORD%/
zdic
http://www.zdic.net/sousuo/?q=%GDWORD%
Collins
https://www.collinsdictionary.com/dictionary/english/%GDWORD%
其他同类型的网站可以照上面的方式自行添加。
离线字典
英国学习词典五虎是牛津、朗文、柯林斯、剑桥和麦克米伦,再加上美国的韦氏学习词典,6 大学习词典。
简明英汉字典增强版
收录 324 万词条,如果只是单纯的想要划词翻译,并不是那么在意英语学习,而只想要快速获知单词含义,这本字典足矣。不管是单词还是短语,这本词典收录非常详细。
Longman Dictionary of Contemporary English 5th Edition (朗文当代高级英语辞典第五版) 五星推荐
记得当时上学的时候,隔壁寝室英语专业的学长唯一给我推荐的字典就是朗文当代(LDOCE5),后来渐渐的才了解到,这本英英词典收录单词量最大,例句最多,搭配和用法也最全。
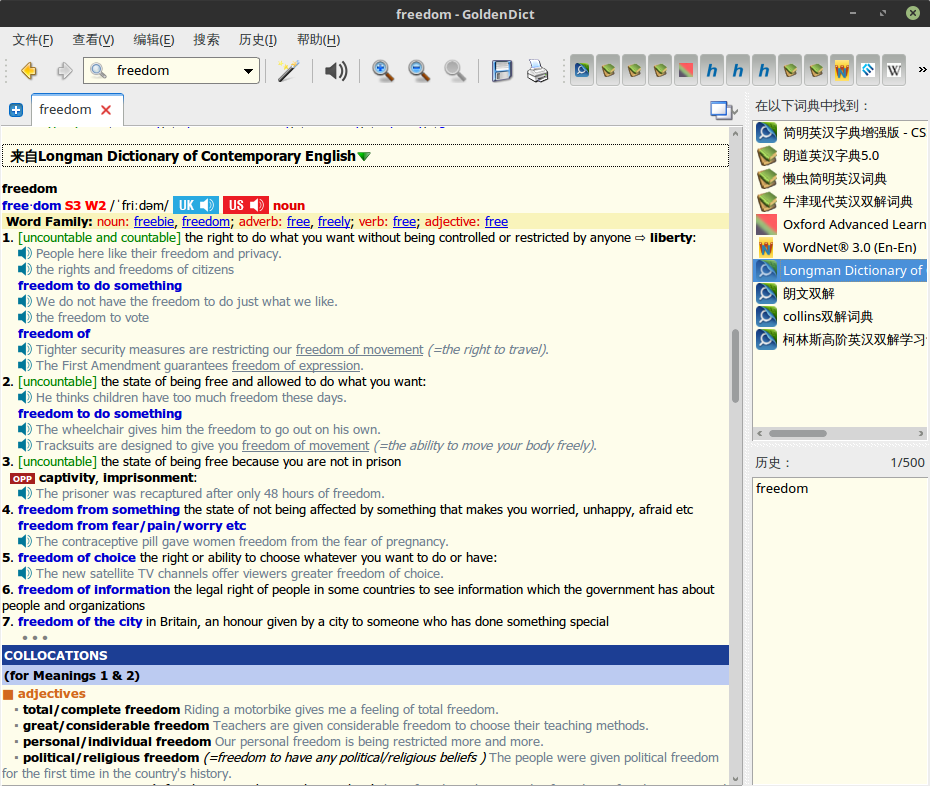
词典给出了每个单词的音标以及英式和美式发音,单词的各种变形,单词出现时间,同时还有单词的词源。同时它会列出每个词条的英文解释和各种搭配例句,甚至这本朗文当代连例句的音频也有,并且不是那种合成的机械式发音,而是真人原声,非常自然。
朗文当代还有一个实用功能就是:COLLOCATIONS,也就是单词搭配
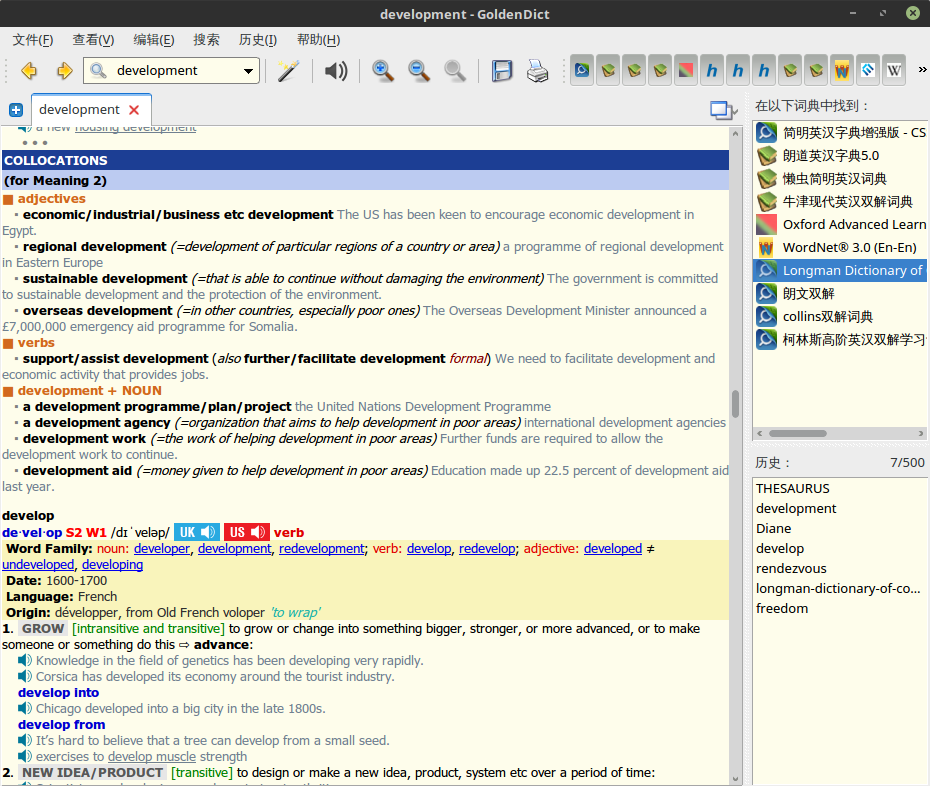
比如一些简单的单词,可能平时知道解释,但是并不了解一些搭配使用,这个功能让学习单词更上了一层。比如说上图中,development 组合,前面加形容词,动词,后面可以接名词。
词典另外一个实用功能就是:THESAURUS,也就是同类词典,朗文当代会列举出当前单词同类的其他单词,比如 walk
- walk to move forward by putting one foot in front of the other
- wander to walk without any clear purpose or direction
- stride to walk with long steps in a determined, confident, or angry way
- pace to walk first in one direction and then in another many times, especially because you are nervous
- march to walk quickly with firm regular steps – used especially about soldiers or someone who is angry
- wade to walk through deep water
- stomp to walk putting your feet down very hard, especially because you are angry
这些单词都有“行走”的意思,但是看到英文解释就会发现,每个单词都有细微的区别,”wander”是“漫无目的的走”,”stride”是“大踏步走”,”pace” 是“踱步走”。
Macmillan English Dictionary for Advanced Learners (麦克米伦高阶英语词典 第二版)
《麦克米伦高阶英语词典》是针对高阶英语学习者推出的学习型字典,有如下特点
- 采用星号标注词频,使用一、二、三个不等的星号来标示其使用频率的高低(一二三星词汇加起来一共有 7500 个,三星词汇出现频率最高,一星最少)
- 另外字典带有大量的短语搭配,每个词条相应都会列出常用的短语搭配
- 另外有发音和同义词,但是他的同义词不像朗文当代会单独列出一个小篇幅介绍,而是穿插在单词的释义下面。
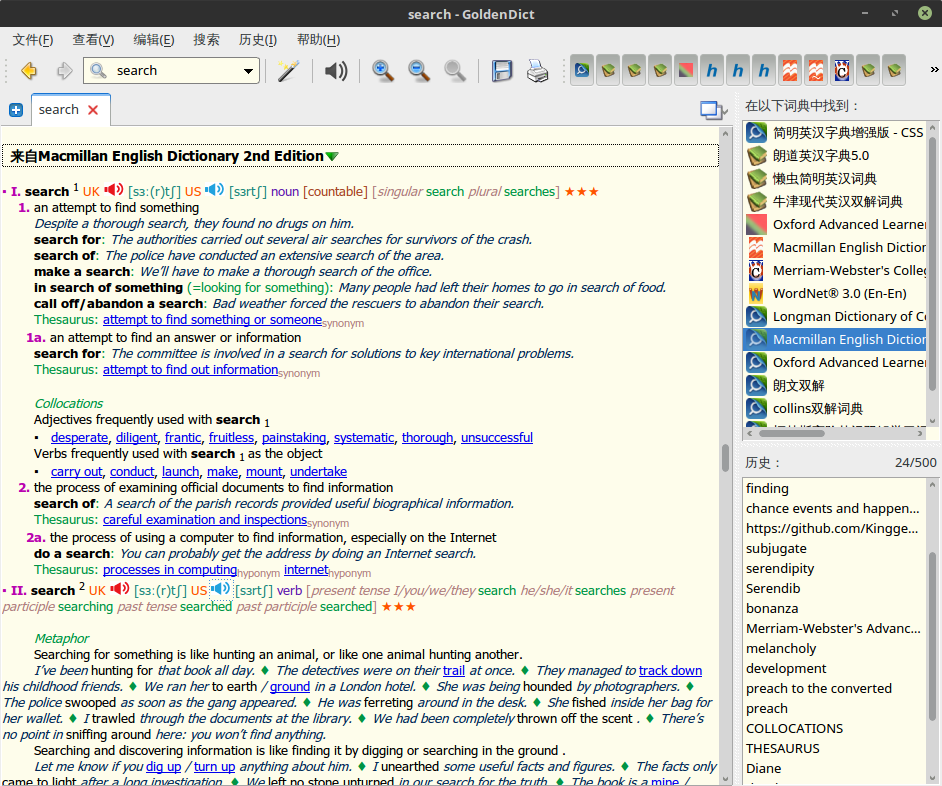
Oxford Advanced Learner’s English-Chinese Dictionary 8th Edition (牛津高阶英汉双解词典)
牛津高阶应该是我最熟悉的一本字典了,从高中起老师推荐,基本算是人手一本的必备词典。不知道在别的地方教学用字典是什么,反正在我看来即使到了大学当时的牛津高阶英汉词典也是非常常见,那个大红色的封面,至今记忆犹新。
牛津高阶为世所公认的权威英语学习词典,创同类词典之先河。自 1948 年出版至今,累计发行量逾 3000 万册,广受全球读者欢迎。收录 183500 单词、短语、释义:英美并重;85000 示例:英汉对照;2000 新词:如 life coach、offshoring;7000 同义词、反义词:有助扩充词汇;5000 专科词语:涵盖文理、工商、科技;700 世界各地用语:如 stickybeak、godown;2600 文化词语:如 Walter Mitty、Capitol Hill;2000 图解词语:图文并茂;400 用法说明:辨析常见疑难;130 研习专页:全面介绍英语应用知识;44 彩页:提供实用帮助;全书逾 2500 页。内容较前一版增加 20%。
这本字典和其他字典比较起来就显得非常贴近中文为母语的英语学习者了。英语解释和汉语解释都很详细。包括习语,搭配,同义等等也都有。这里就是牛津词典和其他词典不同的地方了,在牛津的版本中会出现 IDM,是 idiom,表示的是习语,习惯用法,SYN 是 synonym 也就是同义,对于一般的单词牛津词典都会单独把这些列出来。其他常见的标志
PHR V是 phrase verb 动词短语AW学术单词
其他的非常用的就去看字典的说明吧
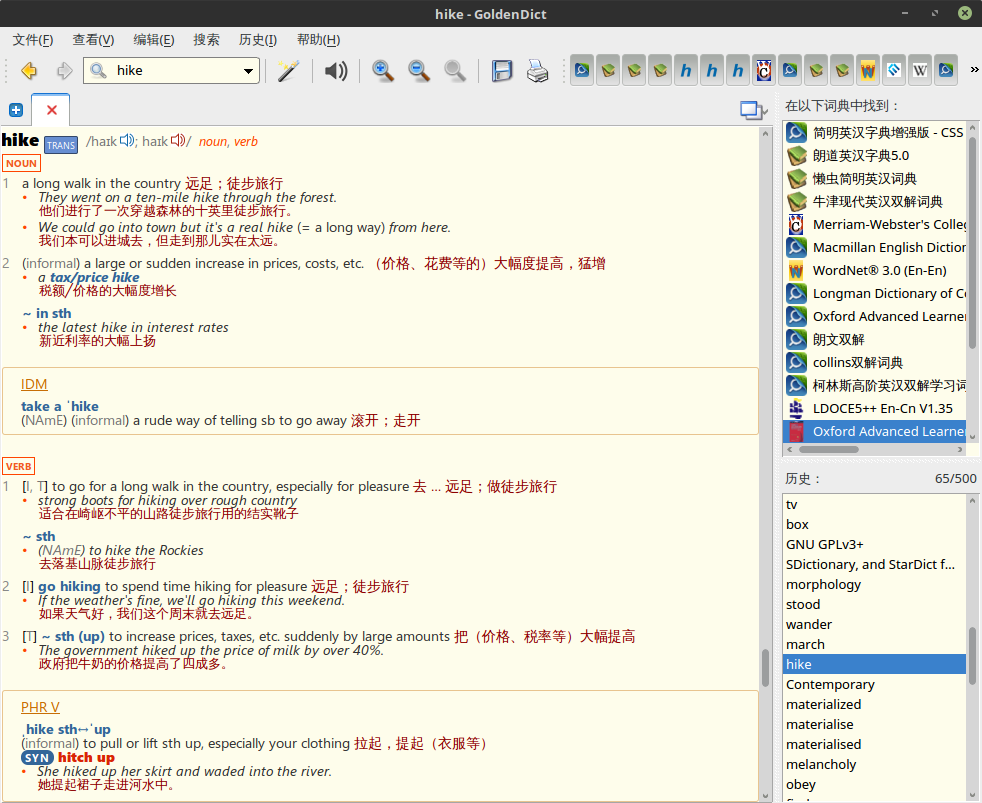
Collins Cobuild Advanced Learner’s English Dictionary (柯林斯高阶英英词典)
柯林斯字典有两个特点
- 采用英文整句释义来解释单词
- 用五颗星来标记词频
柯林斯词典有一个高达 2.5 亿的语料库,从语料库中筛选出了最常用的 14600 词用五星标注。其中五星(最常用词,以下逐级次之)680 词,四星 1040 词(累计 1720 词),三星 1580 词(累计 3300 词),二星 3200 词(累计 6500 词),一星 8100 词(累计 14600 词)。根据语料库的统计结果,掌握五级四级的前 1720 詞,就可以读通英语资料的 75%,掌握五、四、三、二级的 6500 词,就可以读通英语资料的 90%,掌握这 14600 词,就可以读懂任何英语资料的 95%,即从理论上说,任何一篇 100 词的文章里大概只有 5 个词不认识。
Cambridge Advanced Learner’s Dictionary (剑桥高阶英语学习词典)
剑桥高阶英语学习词典(又称 CALD),它以剑桥国际英语语料库(CIC)中逾 7 亿词条为蓝本,并参考了剑桥英语学习者语料库(CLC)中剑桥测试系统的原始语料,收词量和词条搭配量都非常巨大。这本词典的收词量很大,而且带有大量的短语。对于每个单词,词典中都会给出英式和美式的音标以及发音。
Merriam-Webster’s Advanced Learner’s English Dictionary (韦氏高阶英语词典)
《韦氏高阶英语词典》是美系品牌,因此收录了较多的美式常用惯用语以及动词搭配。词典最大的特点是:例句超级多。这本词典据说收录了 160,000 个例句,号称是市面上所有英语学习字典中收录例句最多者。韦氏不仅收录例句多,对于比较难的例句,它还会贴心地在例句后面附带上一句通俗版的解释,从为学习者考虑这一点来说,这是我见过的最有诚意的一本词典了。
如果你喜欢看大量的例句,喜欢通过例句来记单词,那么这本词典会是你最好的选择。
Merriam-Webster’s Collegiate Dictionary (韦氏大学辞典)
与上面提到的几本学习型词典不同,这本词典是母语词典,其使用对象是英语母语人士,有点类似与汉语中的《新华词典》。韦氏大学辞典释义的用词难度也比学习型词典高上不止一个等级,而且一般没有例句。我们可以对比一下”melancholy”在柯林斯和韦氏大学词典中的解释:an abnormal state attributed to an excess of black bile and characterized by irascibility or depression
black bile 是什么?irascibility 又是什么? 如果词汇量太低的话你会发现查个单词结果连释义都看不懂。这种母语词典最大的优点是释义精准且全面,收词量巨大,缺点是释义用词难度没有上限,对初学者来说难度太高,容易打击自信心。建议将韦氏大学辞典与其他学习型词典一起搭配使用,互为补充,不建议单独使用。
Vocabulary.com
这本词典来源于单词学习网站 http://Vocabulary.com ,它是一本能让你感觉到是在“学单词”而不是在“记单词”的词典,比如词典会采用口语化举例子的形式来让你理解单词的意思,用法和来源,让你学以致用。
Longman Language Activator (朗文英语联想活用词典)
《英语联想活用词典》是一本学习型字典,也是一本同义词词典,它的主要排版形式如下
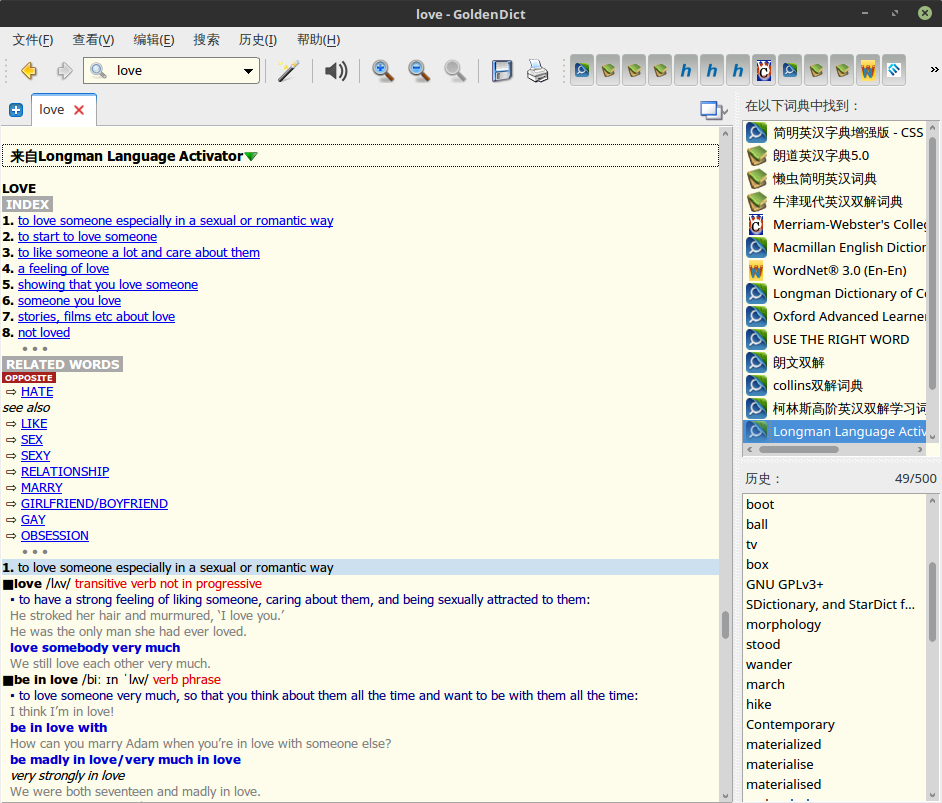
联想词活用词典,是 Thesaurus (同义词典) 的进一步细化,将同义的单词和词组进一步展开说明的词典,被称为联想词,也就意味着这本词典并不止索引了同义词,相关联的单词都会在 RELATED 中显示。这本字典是全英字典,适合学习英语到一定程度,想要进一步学习同义词用法的英语学习者。
比如上图中索引的是 love,相关的单词中有反义词 hate,有同义的 like,还有联想的 sex,relationship,boyfriend/girlfriend, marry,obsession 等等,这是一本值得用来读的字典。
Collins Thesaurus (柯林斯同义词词典)
与上面的学习型词典不同,柯林斯同义词词典是一本工具词典。它能够列出常用词条的同义词。我们可以使用它来扩大词汇量,丰富写作用词。举个例子,表示寒冷最简单的可以用”cold”,但我们还可以有更多选择,查一查词典,它会告诉你还可以用 “chilly, arctic, bleak, cool, freezing, frigid, frosty, frozen, icy, wintry” 这些词。
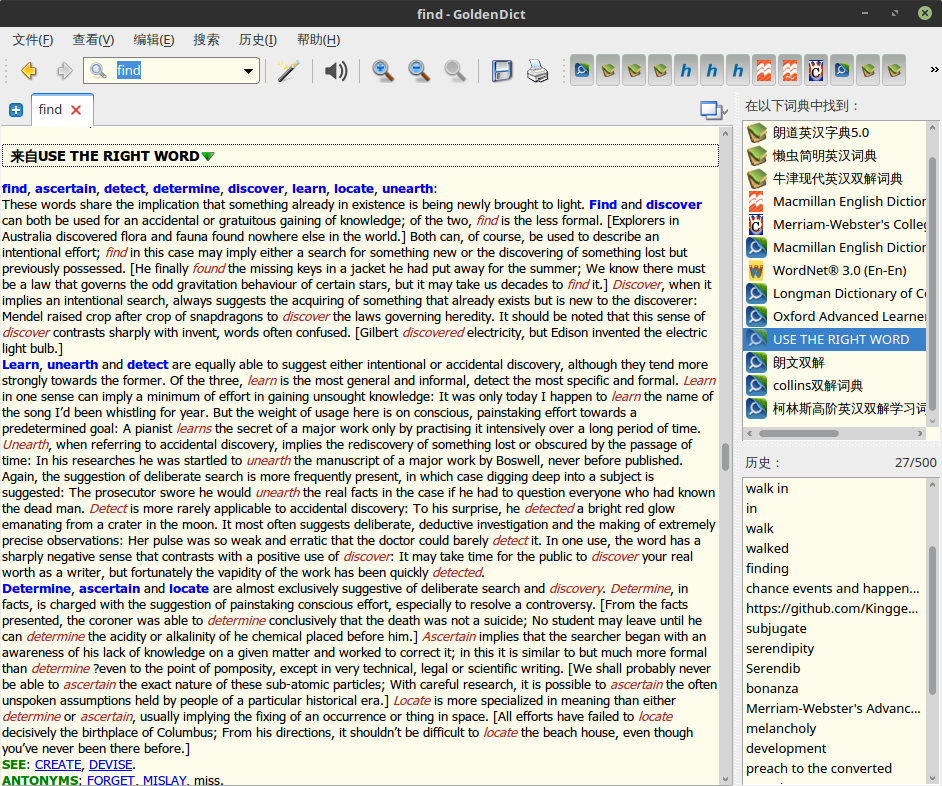
USE THE RIGHT WORD
上面的 Collins Thesaurus 是同义词词典,而这本 USE THE RIGHT WORD 则是同义词辨析词典。
其实即使是同义词,它们的意思也往往是有细微差别的。小学的时候你一定学过 “安静”和“宁静”这两个词,我们可以说“上课铃响了,教室里逐渐安静下来”,却没有人说“上课铃响了,教室里逐渐宁静下来”,这就是词与词之间的区别。
英语中也是如此,比如”disaster”和”catastrophe” 都能表示“灾难”,但两者是有区别的,”disaster”更加强调灾难已经形成的事实,而”catastrophe”是强调灾难本身,所以才有这样一个句子 “They were glad they had survived the catastrophe and had met with no disaster.”
而 USE THE RIGHT WORD 就是一本能告诉你单词之间细微区别的词典。将它装载到手机词典中,查单词时顺便看看相应的同义词辨析,这样能不断提高你对单词的敏感度。

下面是词典截图,收录单词不是很多,但是解释比较多。
The American Heritage Dictionary 美国传统词典 英英
美国传统字典,简称 AHD。这本字典随着第五版的发布已经有 50 年的历史,经过多次的版本修订 AHD 增加了许多互联网,电子商务,电视频道等等相关的词条 1。
AHD 字典的解释简单清晰,针对一些特定的词条会有用法介绍,同义词延伸等等,一句话介绍解释就是非常时候快速查词使用。
AHD 第五版出版介绍
第五版在第四版的基础上新增加了 10000 多词条和短语,超过 4000 张全新全彩的图片。为了让 AHD 紧跟前沿,第五版的出版依靠了一大群专家,学者和贡献者。成千的定义随着时间发生了巨大的变化,比如天文学,生物学,地理学等等。词典中的地图,脚注,同义,语言变化都有了增强和提高。
《美国传统词典》是美国国内非常有影响非常权威的辞典,而且自成系列.35 万个单词,3.4 万个应用实例,500 多种使用注释和新修订的词源附录,曾经被 Amazon.com 评为”编辑选择的参考工具”,是专业英语工作者必不可少的重要工具,也是广大英语爱好者的良师益友,具有非常高的权威性。《美国传统词典》收录了不少英语词根。解释词义的时候会追根溯源寻求词源、词根,可读性强,如同用偏旁部首学习汉字,这对理解和记忆是很有帮助的。所有例句力求语出有典,绝绝非一时的生造。有近义词用法说明,并且用同样有典的例句加以示范。对于渊源曲折的词有风趣而又不失严谨的注释。它是一部典型的英英辞典.它对于学习英语的重要性时非常明显的。许多英语单词都有多重词义,只有原汁原味的英英解释才能准确地道的把它们诠释出来。尤其是许多同义词之间的细微差别,用汉语很难清楚的加以区分,必须放到特定的语言环境中才能体现出来。
单词的释义通过引用经典和同时代的作家的用法变的更加简单。解释单词起源和发展的词源学被重新修订。许多单词可以通过词典的两个附录来追溯词根,这两个附录分别是古印欧语和犹太语。2
在线查词:
WordNet 3.0 英英字典
WordNet 是由普林斯敦大学的心理学家,语言学家和计算机工程师联合设计的一种基于认知语言学的英语词典。它不是光把单词以字母顺序排列,而且按照单词的意义组成一个“单词的网络”。它是一个覆盖范围宽广的英语词汇语义网。名词,动词,形容词和副词各自被组织成一个同义词的网络,每个同义词集合都代表一个基本的语义概念,并且这些集合之间也由各种关系连接。(一个多义词将出现在它的每个意思的同义词集合中)。WordNet 跟传统的词典相似的地方是它给出了同义词集合的定义以及例句。在同义词集合中包含对这些同义词的定义。对一个同义词集合中的不同的词,分别给出适合的例句来加以区分。
- http://goldendict.org/screenshots.php?show=wordnet#pic
- 下载地址 https://sourceforge.net/projects/goldendict/files/dictionaries/
English Etymology
这是一本英语词源字典,比较简单,排版也比较简陋。对于单词由来比较关注的学习者可以备一份。
简单韩语字典
21 世纪英汉汉英双向词典
从各个方面上来看比较平衡的字典,容量、词条量、解释都介于朗道繁体词典和牛津高阶之间。解释虽然简介但也附有许多详细的解释和例句,相比来说是较为适合大众使用。
官方介绍:
本词典的收词范围是英语基础词汇,包含了我国初级和高级中学使用的最新英语课本及旧版英语课本中的全部单词、复合词和词组;也包含了高等学校英语专业以及文、理、工科本科生在大学英语一级至六级所要掌握的总词汇;还包含了中华人民共和国国家教育委员会制定的全国各类成人高等学校招生考试复习大纲英语词汇表中所有单词和词组。此外还参考各(1)英汉部分:收入单词 15000 余条。为了方便读者学习,本部分还提供了大量的固定搭配和惯用句型。(2)汉英部分:收入汉语词条 23000 余条,除一般词语外,还收入了一些常见的方言、成语、谚语以及自然科学和社会科学的常用词组。
新世纪英汉科技大词典
该词典针对工科学生及科技者编撰,不完全统计词条总数 532388 ,如果你是个工科文艺青年,绝对不甘心于仅仅拿着 kindle 神器却看着小清新。那么本词典是您居家旅行的必备良器。有了金刚钻,你还怕揽不着瓷器活?
朗道英汉字典
实际上朗道是上海一家信息公司,名不见经转。想大家都用过金山词霸的电子辞典软件,可能也用过快译点之类的电子辞典。而朗道是国内中英文翻译软件的鼻祖。收录词汇量大。
牛津现代英汉双解词典
该词典一直被誉为“现代英语之权威”。近一个世纪以来,十次修订,与时俱进,品质更臻完美,既为全世界英语学习者的良师益友,也早已成为我国高级英语学习者首选之必备工具书。其收词多达 130,000 余条,精选新词 10,000 余条,英文释义精,中文译文规范权威,近千条实用的用法说明,大量的词源信息,还有丰富的附录,等等。
简明英汉词典
该词典是权威山寨版词典,胜在什么烂词都收,解释简单好用,如果要是做个词汇量大全,生僻词排名的话,这个词典没准能混出个水分颇多的冠军。金山词霸中默认词典即为此词典,复制一下官方介绍: 该词典是一本针对中高级水平的英语学习者的工具书,是一部针对中国人学习特点、适应英语多层次运用的词典。本词典突出现代性、实用性和简明性;力求选词实用精练,体现时代特征;例证典型地道,释义简明准确;编排科学合理,检索方便省时。其创新意识和鲜明特色,博采了中外英语词典之所长。设计新颖,视野开阔,融短语、辨析、语法、相关词、构词、助记、现代成语及用法为一体,兼具学术性、实用性、知识性和趣味性。
牛津英汉词典
这本词典是外研社从世所公认的英语词典权威出版机构牛津大学出版社引进,根据《牛津学生词典》(Oxford Student’s Dictionary) 翻译而成,是为初高中生及大中专英语学习者编纂的一部简明词典。共收词及短语 50000 余条,释义浅显易懂,简易精练;例证精当,易学易用;语法标注简明清晰,方便实用;同义词列举精益求精,利于扩充使用者词汇量;词源说明,利于使用者记忆单词。
朗文英汉综合电脑词典
码农们有福了,这是一本朗文针对计算机专业制做的英汉词典,码农们可以尝试一下,是不是好用,如果不好用的话,您说一声。我就不用了。
现代英汉词典(2001 年外研社版,kindle 正版词典)
《现代英汉词典》(新版)经过众人的通力合作和不懈努力终于问世了。现在呈献在读者面前的是一部全新的英语学习词典,它收词新、义项全、例证丰富、实用性强,能很好地满足我国中高级英语学习者的需要。 本词典注重吸收现代词典学理论的研究成果,充分借鉴国际英语学习词典的编纂经验,同时结合我国学生学习英语的特点,力求做到科学性、准确性、实用性和趣味性的完美结合。
本词典具有以下四大特色:
一、时代性强,收词广泛。本词典紧跟时代,所收词语较新,丰富全面,共收词目 38, 000 余条(不包括派生词及短语)。这些词语反映了近 10 年来科技、经济等领域出现的词汇变化。所收义项也较同类词典丰富。在拼写和注音上,本词典兼顾英国英语和美国英语的区别,采用第十四版国际音标。 二、释义准确,例证恰当。本词典释义力求准确、完整;例证,无论是英文还是中译文, 也力求恰当、贴切、地道。 三、内容丰富,针对性强。本词典例证丰富,具体说明常用词语的语义、句法、搭配、用 法等特点,有助于培养英语学习者的词汇运用能力。此外,本词典语法标注详尽,不仅对形容词用在名词前、不用在名词前、动词不用进行式、常用被动式等作了标注,还对名词用于可数与不可数、用于单数与复数等作了标注,这些有助于中国学生提高正确运用英语的能力。 四、实用性强,趣味性强。本词典提供用法说明 489 条,详解中国学生易混淆词语的用法及区别。 同时配有插图 200 余幅,有助于学习者理解词义和形象记忆,这些无疑为词典增添了实用性和趣味性。
韦氏国际词典——Webster’s Revised Unabridged Dictionary 1913『英英』
《韦氏国际词典》是美国结构主义语言学的硕果。它的篇幅极大,收词 45 万条,是最大型的单卷本英语词典。该书抱着对语言作客观的记录和描写的宗旨,有闻必录,收罗了大量的俗语(包括许多不雅的字眼)。在一段时间里这种编辑方针受到人们尖锐的批评;一二十年后争论才平息下来。
Collaborative International Dictionary of English『英英』
The Collaborative International Dictionary of English (CIDE) was derived from the 1913 Webster’s Dictionary and has been supplemented with some of the definitions from WordNet. It is being proof-read and supplemented by volunteers from around the world. This electronic dictionary is also made available as a potential starting point for development of a modern comprehensive encyclopedic dictionary, to be accessible freely on the Internet, and developed by the efforts of all individuals willing to help build a large and freely available knowledge base.
韦氏高阶英语词典——Merriam-Webster’s Advanced Learner’s English Dictionary『英英』
《韦氏高阶英语词典》是美国老牌权威的辞书出版机构梅里亚姆—韦伯斯特公司出版的一部英语学习工具书,由中国大百科全书出版社引进在中国国内出版,这是“Merriam—Webster”词典首次被引进中国,也是正宗的韦氏词典在中国的第一次授权。以此为契机,韦氏品牌旗下的相关词典将有计划地引入中国市场,形成系列化、规模化。全书收词 10 万,含 3000 核心词汇;16 万例句;22000 余个习语、动词词组、常用短语;12000 余个用法标注、注释和段落。版面字数为 1024 万字。
韦氏大学生词典——Merriam-Webster’s Collegiate Dictionary『英英』
韦氏大学生词典之所以深得美国人青睐,主要因为它具有 150 年历史,数代美国人在它的哺育下长大,它在美国的地位相当于中国的《新华字典》。曾经有人这么评论过:”韦氏词典是划时代的,它的出现标志着美语体系的独立”。GRE 考试的词汇主要依据就是美国韦氏学院辞典!根据统计比较,GRE 反义词所考短语用词大多是 M-W 词典中的原话。被认为是美式英语的典范,留学美国必备。结合新东方系列学习有奇效。
柯林斯英英字典第三版——Collins Cobuild V3『英英』
本词典属根据世界着名的三大语料库之一 COBUILD 中的英语语料库(The Bank of English)编写的工具书。词典中的例词和例句均取材于 COBUILD 英语语料库。故本词典收录了当代英语词目 75000 余条,其中 4000 余条为近年来进入英语的新词。本词典英语语料地道实用,版面新颖,语言信息特别详尽。本词典能帮助使用者扩大词汇量,不断提高口笔语能力,增强使用英语的自信心,是适合中高等程度的英语教师和学生使用的一本极有价值的参考工具书。柯林斯的特点是解释通俗易懂,每个解释都是用一句话来表达的,还有各种同意词举例,还有比如说形容词能不能用比较及,和什么介词搭配,动词能有几种句型可以使用都有说明。虽说这个词典目前已经发行到第五版,但是根据网上的评价,认为还是第三版最好。第三版的例句很多,而后面的版本开始大幅度删减例句,不只是何原因。希望喜欢韦氏词典的人都来下这个版本的 cobuild。
简明大英百科全书——Britannica Concise Encyclopedia『英英』
《不列颠百科全书》(Encyclopaedia Britannica ,简称 EB),又称《大英百科全书》,是享有盛誉的综合性英文百科全书。 Encyclopedia Britannica Online (简称 EB Online)除包括印刷版的全部内容外, 还整合了其他多个资源的信息。Britannica Concise Encyclopaedia 是《不列颠百科全书》简明版,包括 28,000 个短条目,可以迅速解答有关历史、艺术、科学等主题的问题。大英百科全书公司创立于 1768 年、距今已有 235 年悠久历史的《大英百科全书》,是全世界口碑第一、词条(Entry)最多、内容正确性最获肯定的综合性百科全书;大英百科全书公司(Encyclopedia Britannica Inc.)也以其坚强的内容编辑实力及与时并进的资料库检索科技,成为全球工具书的领导品牌。
牛津英语大词典(简编本,第五版)——Shorter Oxford English Dictionary『英英』
提到《牛津英语大词典》,研究过英语的人可能都知道语言研究与词典编篡中的历史主义原则。《牛津英语大词典》最初出版时,名称是“A Nnw English Dictionary on Historical Principles”。作为历史主义原则的应用典范,这部词典记录了自 1150 年以来的中古英语和现代的演变。可以说,它是英语发展轨迹研究的集大成者。历史主义原则在这部词典中主要表现为:收词释义尊重历史,以书证作为依据;义项排列遵循由古到今的时间顺序,词义的历史演变脉络清晰。《牛津英语大词典》自出版以来,成了英语语言的权威。但它卷帙浩繁,用“汗牛充栋”恐不足以形容其规模,作为个人藏书,多有不便。因此有人说这部词典“authoritative,fascinating,but unusable and unaffordable”。为使这部词典贴近普通读者,删繁就简、取精用弘就十分必要,因此大词典出版后不久就有了《牛津英语大词典》(简编本)(Shorter Oxford English Dictionary)。它容纳了《牛津英语大词典》三分之一以上的内容描述的是 1700 年至今所使用的英语语言。可以说,简编本是一部按历史主义原则编篡的现代英语词典。简编本在保持大词典特色与权威的同时,汲取了大词典修订项目的成果,融合了新词、新义, 反映了英语语言的新发展,具有新时代气息。
朗文当代英语词典(四版)——Longman Dictionary of Contemporary English『英英』
《朗文当代英语词典》共收词目 8 万条,其中百科词目 15000 条,篇幅逾 900 万字,是目前世界上第一部与百科全书相结合的英语学习型辞典,可以充分满足中、高级英语学习者学习语言及文化的需要。该辞典释义浅显易懂,例证典型丰富,用法说明详尽准确。其英文版问世以来,受到全球英语教学界的广泛喜爱。
不列颠百科全书——Britannica『英英』
《不列颠百科全书 (Encyclopedia Britannica)》(又称《大英百科全书》,简称 EB),被认为是当今世界上最知名也是最权威的百科全书,是世界三大百科全书(美国百科全书、不列颠百科全书、科利尔百科全书)之一。不列颠百科全书诞生于 18 世纪苏格兰启蒙运动 (Scottish Enlightenment) 的氛围中。第一个版本的大英百科在 1768 年开始编撰,历时三年,于 1771 年完成共三册的不列颠百科全书。全书约 4400 万单词,从 1768 年开始编写至今已经出版至 14 版。这套百科全书共 20 卷,字数达到 4350 万字;条目多达 81600 余条;图片有 15300 余幅。内容涵盖政治、经济、哲学、文学、艺术、社会、语言、宗教、民族、音乐、戏剧、美术、数学、物理、化学、历史、地理、地质、天文、生活、医学、卫生、环保、气象、海洋、新闻、出版、电视、广播、广告、军事、电脑、网络、航空、体育、金融等 200 多个学科。
法汉词典
该词典源于法语学习软件《我爱法语》,全本整理扩增法汉词库至 56000 单词。《我爱法语》是一款成熟的法语电子词典软件。
新德汉词典
该词典旨在帮助初学者及提高者学习德语之用,共收词条 20000 多,其中 5000 多条德语基本词含有例句或释例,同时还标明最常用词约 2000 个。其他词条也收录一些较常用的词组搭配。本词典根据德语新正字法编写而成,符合实际需要。
#### プログレッシブ英和中辞典
英語文化へ読者を招待する最良の英和辞典。 学習や実務に生きる精選された 11 万 7000 語を収録。時事語・生活語・新語・俗語の他、生命科学や金融、スポーツ用語なども追加。大学受験をめざす高校生から、新聞・雑誌を読みこなす社会人まで、幅広く使えます。
内容(「BOOK」データベースより) 総収録項目 11 万 7 千。時事語・生活語・新語・俗語のほか、生命科学・金融・スポーツ用語なども追加。重要見出し語を赤字で示し、語法・類語なども見やすく表示。定評ある語源欄をさらに目立たせ、語源的に関連のある語を赤字で示して、語彙ネットワークを立体的に構成している。 内容(「MARC」データベースより) 総収録項目 11 万 7 千。時事語、生活語、新語、俗語のほか、生命科学、金融、スポーツ用語なども追加。重要見出し語を赤字で示し、語法、類語なども見やすく表示。学習からビジネスまで対応する、1998 年刊に次ぐ第 4 版。
大辞泉
1966 年(昭和 41 年)に企画が持ち上がった [1]。実際に出版されたのは 1995 年。カラー図版が多いのが特徴である。初版の収録語数は、約 22 万語。2003 年現在、58 万部が発行されている [1]。iPhone や iPad アプリとして「デジタル大辞泉」が発売されているほか、電子辞書にも「デジタル大辞泉」が収録されている製品がある。さらに、Yahoo! 辞書や goo 辞書、infoseek 辞書、コトバンクに「デジタル大辞泉」が提供されており無料で利用できる。
新华词典 (Chinese Edition)(2001 年修订版,kindle 正版词典)
《新华词典》:1980 年 8 月第 1 版,1989 年 9 月第 2 版,2001 年 1 月第 3 版。主编韩作黎,曾任北京市教育局局长,全国教育学会第一、二届常务理事,北京市教育学会会长,中国作协北京分会儿童文学委员会主任,长期从事普通教育工作及儿童文学创作,对小学教育、教学和学校管理有较深研究。该词典是一部以语文为主兼收百科的中型词典,主要供中等文化程度的读者使用。
Macmillan Study Dictionary
暂无
其他字典
首推 pdawiki,这个论坛上有非常多精美的字典,不过要求门槛比较高,新人一般很难下载到这些离线的字典。
goldendict 官网给出的字典
解压后,在词典 - 文件添加路径即可
胡正网站给出了非常多语言的字典
babylon 免费的字典
最后这里有近 5 个 G 的英英和英俄字典,应该是个俄国人分享的
字典相关
引进词典又分为英系和美系两大类,目前英系词典占据中国市场的主导地位,著名的品牌如牛津、朗文、剑桥、麦克米伦、柯林斯,简称“牛朗剑麦柯”(谐音“牛郎见迈克”)合称“英国五虎”。
美系词典主要有《美国传统词典》(The American Heritage Dictionary) 和“韦氏词典”两大品牌,而实际上“韦氏”在这里是一个复数名词,在美国有众多出版社都出过冠以“韦氏”名号的词典,之所以造成今天“鱼龙混杂”的局面,是因为韦伯斯特最初编撰“韦氏词典”是早在距今 200 年前的 19 世纪初,根据美国法律,“韦氏”作为未经注册的商标早已超出了知识产权的保护期进入公共出版领域,所以今天变成一个共享品牌。对于中国读者而言,最熟悉的“韦氏”主要有两家,一个就是正宗的“韦伯斯特”,由老东家麦瑞安—韦伯斯特出版公司出版,旗舰品牌 Webster Third New International Dictionary,但普通读者(特别是准备雅思和 GRE 的同学)更熟悉的是该社各形各色的韦氏原版小词典,被大家戏称之曰“韦小宝”。麦瑞安—韦伯斯特于 08 年底推出第一部学习型词典 Webster Advanced Learner’s Dictionary,可惜尚未听说那家出版社引进该词典的版权;另一个就是美国鼎鼎大名的兰登书屋所出版的“韦氏词典”系列,现在兰登在所出“韦氏”前面一般都冠以“兰登书屋”的名目,一看便知,不会混淆,如商务 97 年引进出版的《蓝登书屋韦氏英汉大学词典》(Random House Webster’s Colledge Dictionary),外研社 06 年引进出版的《韦氏高阶英汉双解美语词典》(Random House Webster’s Dictionary of American English)。在英系美系两大类别之外,有一本词典我要特别提一下,外研社《英汉多功能词典》,这是一本日系词典,原书是日本人编给日本人学英语用的…… 说到这里,实际上今天大名鼎鼎的 OALD 最初就是霍恩比 (A S Hornby) 教授执教日本期间所编写的一部针对非母语人士(主要是以日本人为代表的亚洲读者)的学习型词典《现代英语学习词典》(A Learner’s Dictionary of Current English)……在英美两系之外,另有一本日系词典值得特别提一下,即外研社《英汉多功能词典》(A Multifunction English-Chinese Dictionary),日文原版(E-Gate English-Japanese Dictionary)由田中茂范主编。
词形匹配
GoldenDict 默认情况下,比如屏幕取词获取 “stores” 默认是没有结果的,但是其实并不是 GoldenDict 的问题,GoldenDict 默认情况下是没有附带构词法规则的,所以查询单词复数等变形形式时可能会差不到,只需要导入构词法规则库就能够让 GoldenDict 自动判断复数从而进行查词。
下载 英语构词法规则库,一般下载英文的 en_US_1.0.zip 即可:
然后在 编辑 ->词典 ->词典来源 ->构词法规则库 中设置规则目录,在我的电脑上是 /usr/share/myspell/dicts ,当然也可以将下载的文件拷贝到该目录中记载即可。
对比
GoldenDict 和其他可选字典的对比
在 stardict 被移除的 Sourceforge 页面上给出了一系列的 Alternative 选择
| 字典软件 | 链接 | 支持格式 | 平台 | 特色功能 | License |
|---|---|---|---|---|---|
| GoldenDict | https://github.com/goldendict/goldendict | 特别多,见上文 | GUN/Linux, Mac, Windows, Android | 见上文 | GNu GPLv3+ |
| Babiloo | https://code.google.com/archive/p/babiloo/ 已停止 | SDictionary, and StarDict formats | Linux, Windows, Mac | 已停止维护 | GPL v3 |
| LightLang | https://code.google.com/archive/p/lightlang/ 已停止开发 | 俄语 | Linux only | 已停止维护略 | GPL v2 |
| Lingoes | http://www.lingoes.net/ | 私有格式 | Windows only | Windows 下比较好用,但有广告 | |
| Dicto | http://dicto.org.ru/ | XDXF dictionaries | windows only | 只面向俄语 略 |
其他编程资源
使用 stardict-tools 可以将 stardict 格式的字典转变成可读的格式
sudo apt-get install stardict-tools
# 工具安装之后会在 `/usr/lib/stardict-tools/` 目录下
一个将各种字典文件转变格式的脚本
一个使用 Python 编写的生成 .mdx 文件的脚本
一份关于 MDD 和 MDX 文件格式的分析
Wikipedia 的离线包,很大,好几十个 G
原来只是想要找到一个 Linux 下代替有道的桌面词典,没想到竟然过了一个礼拜,这一个礼拜每天回来的第一件事情就是整理可用的字典。在一个礼拜的努力下,终于已经完美可用。这一个礼拜所看过的字典版本已经超过了我过去二十多年的数量,也让我发现了原来学习英语一直以来都缺失了这么重要的一环。真的有些单词,英英解释起来要比中文要轻松许多。今天也同样遇到了一个 argument 和 parameter 两个单词在编程的语境中经常被翻译成一个词 —- 参数,但其实仔细看英英解释就能发现
- argument 是 a reference or value that is passed to a function, procedure, subroutine, command, or program
- parameter 是 a set of fixed limits that control the way that something should be done
虽然两者本身的含义也非常类似,在计算机术语中几乎也是等价,但是英英的解释能看到,argument 是调用者的传参,而 parameter 是定义方法或者函数时候的参数,虽然两者表达的东西是一样的,但是其实有着一定的区别。
再比如之前也提到的 walk, wander, stride, pace, wade 都有走的意思,但是其实每个单词使用的场景都不一样都需要仔细考虑。或许这就是语言学习最难过的一关,这也是学习者无论如何都很难超越母语使用者最为重要的一点了吧。
reference
- http://goldendict.org/
- Source Code https://github.com/goldendict/goldendict
- SourceForge https://sourceforge.net/projects/goldendict/files/
- https://blog.yuanbin.me/posts/2013-01/2013-01-31_23-07-00/
- http://forum.ubuntu.org.cn/viewtopic.php?f=95&t=265588
- lingoes 词典 http://www.lingoes.cn/zh/dictionary/index.html
- https://xinyo.org/archives/61412/ 朗文 5、韦伯 11、牛津 8(均含发音)词典包
- https://www.cnblogs.com/oucbl/p/6839493.html
- 字典推荐 https://www.jianshu.com/p/817284262546
- https://zhuanlan.zhihu.com/p/20214473
- 各个版本字典介绍 https://book.douban.com/review/2292414/
- https://dictionaryphile.github.io/
- https://www.douban.com/group/topic/31690870/
Linux 网络配置
昨天升级 Ubuntu ,不知为何将网卡配置覆盖了,导致一时间无法上网,然后看了一些网络配置的文章,感觉自己需要补习一下相关知识,所以有了这篇文章。
下面就按照命令分别展开吧
ifconfig
这个命令是查看本地网络端口最常见的命令了,略
设置网卡及 IP
/etc/network/interfaces 文件中保存着本地网络网卡的相关配置
配置 DHCP 自动获取 IP
auto eth0
iface eth0 inet dhcp
假如要配置静态 IP
auto eth0 # 要设置的网卡
iface eth0 inet static # 设置静态 IP;如果是使用自动 IP 用 dhcp,后面的不用设置,一般少用
address xxx.xxx.xxx.xxx # IP 地址
netmask xxx.xxx.xxx.xxx # 子网掩码
gateway xxx.xxx.xxx.xxx # 网关
修改保存,之后使用 sudo /etc/init.d/networking restart 来使其生效。
设置 DNS
DNS 相关的配置在 /etc/resolv.conf 文件中。如果希望永久生效可以修改 /etc/resolvconf/resolv.conf.d/base 文件中
nameserver 8.8.8.8 # 希望修改成的 DNS
nameserver 8.8.4.4
然后使用 sudo /etc/init.d/resolvconf restart 来使得 DNS 生效。
resolv.conf 配置
/etc/resolv.conf 配置文件是客户端 DNS 配置,一般在该文件中配置了 DNS 服务器的 IP 地址和域名。
配置的参数格式非常简单,由关键字开头,后面接着是空格分隔的几个参数。resolv.conf 配置中主要的关键字有四个:
- domain
- nameserver
- search
一个基本的配置:
domain some-example.com
nameserver 8.8.8.8
nameserver 8.8.4.4
search exmaple.com example1.com
解释:
- domain: 指的是本地网络的名称,如果查询域名时没有包含点号,那么会自动加上网域的名称为结尾,再发送给 DNS 服务器
- nameserver: 指定客户端进行域名解析的时候要用到的域名服务器 IP 地址,因此可以指定多个地址,客户端会按照次序进行查询请求
- search: 非必填,举个例子来说明这个选项,当 search 设定为
example.com时,在 DNS 解析的时候,无法对输入解析的时候,比如查询 blog,DNS 客户端会使用 search 指定的值加上需要查询的名称,即blog.example.com来进行解析,解析失败的时候会依次往后 blog.example1.com 查询
当设定了 domain 时,配置的地址会自动成为 search 的第一个搜索域名。
当去 ping 一个域名时,如果访问的域名无法被 DNS 解析,resolver 会将该域名加上 search 参数后面配置的内容,重新请求 DNS,知道被正确解析或尝试完 search 指定的所有列表为止。
reference
AES 加密算法
高级加密标准 (AES,Advanced Encryption Standard) 为最常见的对称加密算法。对称加密算法也就是加密和解密用相同的密钥。
将明文 P 使用加密密钥 K 加密成密文 C ,传输,然后在使用 AES 解密函数使用相同的密钥 K 解密,产生明文 P
设 AES 加密函数为 E,则 C = E(K, P), 其中 P 为明文,K 为密钥,C 为密文。也就是说,把明文 P 和密钥 K 作为加密函数的参数输入,则加密函数 E 会输出密文 C。
加密和解密用到的密钥是相同的,这种加密方式加密速度非常快,适合经常发送数据的场合。缺点是密钥的传输比较麻烦。
基本原理
AES 为分组密码,分组密码也就是把明文分成一组一组的,每组长度相等,每次加密一组数据,直到加密完整个明文。
使用 alembic 迁移数据库结构
Alembic 是一个处理数据库更改的工具,它利用 SQLAlchemy 来实现形成迁移。因为 SQLAlchemy 只会在我们使用时根据 metadata create_all 方法来创建缺少的表 ,它不会根据我们对代码的修改而更新数据库表中的列。它也不会自动帮助我们删除表。 Alembic 提供了一种更新 / 删除表,更改列名和添加新约束的方法。因为 Alembic 使用 SQLAlchemy 执行迁移,它们可用于各种后端数据库。
安装
pip install alembic
使用
初始化,使用如下命令会创建环境到 migrations 文件夹下,通常情况下使用 migrations 文件夹来存储 alembic 环境,如果想使用别的名字,相应替换为别的名字即可。注意下面命令中的 migrations 将会是存储所有迁移脚本的目录名字
alembic init migrations
初始化过程会创建迁移环境和 alembic.ini 文件。创建成功后可以看到如下结构:
alembic
├── README
├── env.py
├── script.py.mako
└── versions
alembic.ini
在这个环境中可以找到 env.py 和 script.py.mako 模板还有 versions 文件夹。versions/ 目录会存储之后的所有迁移脚本。 env.py 文件用来定义和实例化 SQLAlchemy 引擎,连接引擎并进行事务,保证当 Alembic 执行命令时被合理的调用。 script.py.mako 模板在创建迁移时被使用,他定义了迁移的基本模板。
配置
在 init 生成之后需要修改 env.py 如下的两个配置,才能生效。改变 sqlalchemy.url 值,配置数据库连接。
sqlalchemy.url = driver://user:pass@localhost/dbname
为了让 Alembic 追踪到数据模型的变化,需要将 target_metadata 赋值为数据库的 metadata
from flask import current_app
config.set_main_option('sqlalchemy.url',
current_app.config.get('SQLALCHEMY_DATABASE_URI'))
target_metadata = current_app.extensions['migrate'].db.metadata
自动创建版本
使用alembic revision -m "comment" 来创建数据库版本。命令会产生一个数据库迁移脚本。
更新数据库
升级数据库使用 alembic upgrade,降级使用 alembic downgrade,更新到最新版则使用 alembic upgrade head。
查看数据库就会发现 alembic 会自动产生一个 alembic_version 的表,只有一个字段和值 version_num,记录当前数据库版本。
reference
- 《Essential SQLAlchemy 2nd Edition 2015》
应用消息推送解决方案 MiPush
Android 中实现消息推送的主流方案有下面几种。
| 方案 | 原理 | 优点 | 缺点 |
|---|---|---|---|
| Cloud to Device Messaging,云端推送,是 Android 系统级别的消息推送服务(Google 出品) | Push | 简单的、轻量级的机制,允许服务器可以通知移动应用程序直接与服务器进行通信,以便于从服务器获取应用程序更新和用户数据 | 依赖于 Google 官方提供的 C2DM 服务器,需要用户手机安装 Google 服务 |
| 轮询 | 基于 Pull 方式 | 实时性好 | 成本大,需要自己实现与服务器之间的通信 ; 到达率不确定,考虑轮询的频率:太低可能导致消息的延迟;太高,更费资源 |
| SMS 信令推送 | Push | 完全的实时操作 | 成本高 |
| 第三方平台 | Push 小米推送、华为推送 友盟推送、极光推送、云巴(基于 MQTT) 阿里云移动推送、腾讯信鸽推送、百度云推送 | 成本低,抵达率高 | 安全性低,服务会被杀 |
每天学习一个命令:iotop 查看 Linux 下每个进程 IO 占用
iotop 是一个用来监控磁盘 I/O 的类似 top 的工具,Linux 下 IO 统计工具,比如 iostat, nmon 等只能统计到每个设备的读写情况,如果想要知道哪一个进程占用比较高的 IO 就要使用 iotop。 iotop 使用 Python 语言编写,要求 Python >= 2.5,Linux Kernel >= 2.6.20. (使用 python -V 和 uname -r 来查看)
使用这个命令最主要的一个原因就是快速找到 IO 占用比较高的程序,以便进行排查。
安装
sudo apt install iotop
sudo yum install iotop
install from source
wget http://guichaz.free.fr/iotop/files/iotop-0.6.tar.bz2
tar -xjvf iotop-0.6.tar.bz2
cd iotop-0.6/
./setup.py install
使用
直接使用,可以查看到对应进程的 IO 磁盘读写信息
iotop
只显示有实际 I/O 的进程或者线程
iotop -o
只显示进程的 I/O 数据:
iotop -P
显示某一个 PID 的 IO:
iotop -p PID
显示某一个用户的 I/O:
iotop -u USER
显示累计 IO 数据:
iotop -a
调整刷新时间为 10 秒:
iotop -d 10
快捷键
直接启动 iotop 会进入交互模式,使用如下快捷键可以控制显示。
- 左右箭头用来改变排序,默认按照 IO 排序,可以切换为读或者写排序等等。
- 交互式快捷键,
a用来切换累积使用量和 IO 读写速率。 r改变排序顺序o只显示有 IO 输出的进程q退出
reference
InfluxDB 使用
InfluxDB 数据库是用 Go 语言实现的一个开源分布式时序、事件和指标数据库。InfluxDB 提供类 SQL 语法。
需要注意的是 InfluxDB 单节点是免费的,但是集群版是要收费的。
安装
sudo apt install influxdb
数据库设计
正因为 InfluxDB 是一个时序数据库,在实际使用的时候有些概念需要提前知道。InfluxDB 数据库中的每一个数据都有一列 time 保存时间戳 (RFC3339 形式显示)。
| time | butterflies | honeybees | location | scientist |
|---|---|---|---|---|
| 2015-08-18T00:00:00Z | 12 | 23 | 1 | langstroth |
| 2015-08-18T00:00:00Z | 1 | 30 | 1 | perpetua |
以该数据说明,butterflies 和 honeybees 是 Field keys 用来保存元数据,每一个 key 都对应这 value,下面的数字都是要存储的值。
location 和 scientist 是 Tags,用来存储元数据。location 有两种取值,scientist 也有两种取值。所以组合可以有四种 tag 集合。tag 是可选的。但是推荐给数据加上 tags。和 field 不同,tags 都是索引,这意味着在查询时可以更快。
measurement 可以理解成 tags, fields 和 time 列的容器。measurement 的名字是数据的描述,和关系型数据库中的表可以做对应。在 InfluxDB 中可以创建多个数据库,不同数据库中的数据文件是隔离存放的,存放在磁盘上的不同目录
每一个 measurement 可以属于不同的 retention policies(存储策略),一个 retention policy 描述了 InfluxDB 保存数据多久(DURATION)和多少副本被保存到 cluster 中(REPLICATION)。(Replication factors 不对单节点开放)
在 InfluxDB 中 series 是一组数据的集合,这些数据共享一个 retention policy,measurement 和 tag set。理解 series 的概念才能设计好数据库的 schema。
最后 point 是在相同 series 中相同 timestamp 的数据。
InfluxDB Shell
如果需要使用 shell 需要安装
sudo apt install influxdb-client
然后在终端输入
influx
进入,默认的端口是 8086。输入 help 可以查看命令列表。
influx 命令参数
influx 启动命令常用参数
influx -database 'name' # 数据库
influx -host 'hostname' # 默认是 localhost
influx -password 'password' # 如果有密码
influx -port 'port' # 端口
更多参数可以使用 influx --help 查看。
基本操作
查看数据库
show databases
创建和删除数据库
create database test
drop database test
切换使用数据库
use test
表基本操作,查询,插入
显示所有表
show measurements
删除表
drop measurement test_table
插入数据
insert [measurement],[tag],[field],[time]
insert cpu,host=serverA,regin=us value=0.64
解释:
- 如果 measurement 表不存在,自动创建。
host和region是 tagvalue是 0.64- 如果字段存在则会报错
这里还要注意 measurement 和 tag 之间不能有空格,空格后面是真正要存储的值,所以如果要存两个 field,那么就需要
insert temperature,machine=unit42,tpye=assembly external=25,internal=37
注意 type=assembly 和 external 之间的空格。
查询数据
select "host","region","value" from "cpu"
select * from "temperature"
更多的查询可以参考这里
用户管理
查看用户
show users
创建用户
create user "username" with password "password"
create user "username" with password "password" with all privileges
删除用户
drop user "username"
Python Client
安装下面的客户端
pip install influxdb
其实这个 client 也只不过是在 influxdb 提供的 HTTP 接口外封装了一层 API,如果熟悉 HTTP 的接口,可以直接调用 influxdb 提供的接口。
curl -sL -I localhost:8086/ping
比如:
创建数据库
import requests
posturl = 'http://localhost:8086/query'
data = {'q': 'create DATABASE mydb'}
response = requests.post(posturl, data=data)
类似于 curl 命令如下:
curl -GET http://localhost:8086/query --data-urlencode "q=CREATE DATABASE mydb"
写数据
import requests
posturl = 'http://localhost:8086/write?db=mydb'
data="cpu_load_short,host=server01,region=us-west value=0.69"
response = requests.post(posturl, data=data)
类似于 curl 命令如下:
curl -i -XPOST 'http://localhost:8086/write?db=mydb' --data-binary 'cpu_load_short,host=server01,region=us-west value=0.64 '
如果使用 python client:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import psutil
import time
from influxdb import InfluxDBClient
host = "localhost"
port = 8086
user = "root"
password = "root"
dbname = "test"
def read_info():
cpu_time_info = psutil.cpu_percent(1, True)
data_list = [
{
'measurement': 'cpu',
'tags': {
'cpu': 'i7'
},
'fields': {
'cpu_info_user': cpu_time_info[0],
'cpu_info_system': cpu_time_info[1],
'cpu_info_idle': cpu_time_info[2],
'cpu_info_interrupt': cpu_time_info[3],
'cpu_info_dpc': cpu_time_info[4]
}
}
]
return data_list
def parse_db(dbs):
l = []
for db in dbs:
l.append(db['name'])
return l
if __name__ == '__main__':
client = InfluxDBClient(host, port, user, password) # 初始化
dbs = client.get_list_database()
if dbname not in parse_db(dbs):
client.create_database(dbname)
for i in range(20):
client.write_points(read_info())
time.sleep(2)
大致是这样,但是这个 client 似乎还有 bug,在使用的时候就发现 HTTP 方法不支持,Method Not Allowed 这样的错误,需要自己手动改一改。
reference
- https://docs.influxdata.com/influxdb/v1.6/tools/shell/
- https://influxdb-python.readthedocs.io/en/latest/include-readme.html
- https://blog.csdn.net/qq_37258787/article/details/79190027
- http://eskiyin.cc/2017/03/13/influxdb-and-influxdb-python/
文章分类
最近文章
- 从 Buffer 消费图学习 CCPM 项目管理方法 CCPM(Critical Chain Project Management)中文叫做关键链项目管理方法,是 Eliyahu M. Goldratt 在其著作 Critical Chain 中踢出来的项目管理方法,它侧重于项目执行所需要的资源,通过识别和管理项目关键链的方法来有效的监控项目工期,以及提高项目交付率。
- AI Shell 让 AI 在命令行下提供 Shell 命令 AI Shell 是一款在命令行下的 AI 自动补全工具,当你想要实现一个功能,敲一大段命令又记不住的时候,使用自然语言让 AI 给你生成一个可执行的命令,然后确认之后执行。
- 最棒的 Navidrome 音乐客户端 Sonixd(Feishin) Sonixd 是一款跨平台的音乐播放器,可以使用 [[Subsonic API]],兼容 Jellyfin,[[Navidrome]],Airsonic,Airsonic-Advanced,Gonic,Astiga 等等服务端。 Sonixd 是一款跨平台的音乐播放器,可以使用 [[Subsonic API]],兼容 Jellyfin,[[Navidrome]],Airsonic,Airsonic-Advanced,Gonic,Astiga 等等服务端。
- 中心化加密货币交易所 Gate 注册以及认证 Gate.io 是一个中心化的加密货币交易所。Gate 中文通常被称为「芝麻开门」,Gate 创立于 2013 年,前身是比特儿,是一家致力于安全、稳定的数字货币交易所,支持超过 1600 种数字货币的交易,提供超过 2700 个交易对。
- 不重启的情况下重新加载 rTorrent 配置文件 因为我在 Screen 下使用 rTorrent,最近经常调试修改 rtorrent.rc 配置文件,所以想要找一个方法可以在不重启 rTorrent 的情况重新加载配置文件,网上调查了一下之后发现原来挺简单的。