Termux app 使用记录
Termux 是一个 Android 上的应用,但是这个应用是一个终端模拟器,可以完美的在 Android 上模拟一个 Linux 终端环境。甚至不需要 root 权限,正常安装即可使用。Termux 还提供了一套自己的包管理。
Termux is an Android terminal emulator and Linux environment app that works directly with no rooting or setup required. A minimal base system is installed automatically - additional packages are available using the APT package manager.
官网地址:
和 Linux 类似,Termux 有着自己的软件源 http://termux.net/
Termux 和其他终端模拟的区别
Android 上有很多终端模拟,SSH 连接的工具,以前经常用 Juice SSH,Terminal Emulator for Android,这些工具和 Termux 有什么区别呢。
- ConnectBot Juice SSH 仅提供了 SSH client 功能,但是不支持本地命令
- Android Terminal Emulator 仅提供了有限的本地 bash shell 支持
那么 Termux 首先是一个 Android Terminal Emulator,可以和其他 Terminal 一样提供本地 Shell 支持,安装 openssh 就支持 SSH Client,除开这两个功能以外,Termux 模拟了一套 Linux 运行环境,可以在无需 root 情况下对 Android 设备进行如同 Linux 设备一样的操作,甚至可以在其中使用 pkg 的包管理(实际也是使用的 apt)。所以在 Linux 设备上能做的一切操作,Termux 都能支持。比如:
- 包管理
- zsh, vim, tmux, ssh, wget, curl, etc
- python, php, etc
- 搭建数据库,运行 nginx,跑网站
- 编写源代码,版本控制,编译,运行程序
- 网络分析工具,nmap, iperf
使用
基本 UI 操作
- 左侧滑出,侧边栏,管理 session
- 长按终端,弹出上下文菜单
快捷键,音量减 (-) 代表 Ctrl
pkg 命令
pkg search <query> 搜索包
pkg install <package> 安装包
pkg uninstall <package> 卸载包
pkg reinstall <package> 重新安装包
pkg update 更新源
pkg upgrade 升级软件包
pkg list-all 列出可供安装的所有包
pkg list-installed 列出已经安装的包
pkg shoe <package> 显示某个包的详细信息
pkg files <package> 显示某个包的相关文件夹路径
两个重要的文件路径
$HOME进入终端的默认位置,一般在/data/data/com.termux/files/home$PREFIX是 usr 目录,包含配置文件 etc/ 目录和可执行文件 bin/ 目录,一般为/data/data/com.termux/files/urs
可以使用 echo $HOME 和 echo $PREFIX 来查看。
开启存储访问
在 Termux 下执行:
termux-setup-storage
点击允许,使得 Termux 可以访问本地文件。开启之后可以通过 cd /sdcard 来访问内部存储 sdcard。
默认会创建如下的软链接:1
~/storage/dcim -> /storage/emulated/0/DCIM
~/storage/downloads -> /storage/emulated/0/Download
~/storage/movies -> /storage/emulated/0/Movies
~/storage/music -> /storage/emulated/0/Music
~/storage/pictures -> /storage/emulated/0/Pictures
~/storage/shared -> /storage/emulated/0
或者也可以手工使用软链接 link 到 home 目录方便访问
ln -s /sdcard/ ~/storage
这样就可以直接在 home 目录下访问 storage 目录来快速访问 sdcard。
更换清华源
更换软件源:
export EDITOR=vi
apt edit-sources
将其中内容替换为:
deb https://mirrors.tuna.tsinghua.edu.cn/termux stable main
在新版的 Termux 中官方提供了图形界面(TUI)来半自动替换镜像2:
termux-change-repo
执行前确保 termux-tools 包安装了。
如果遇到报错说:
CANNOT LINK EXECUTABLE “library “libssl.so.1.1” not found”
那么可以重新安装 F-droid 市场中的版本,Play Store 中的版本可能优点问题。
安装基础的工具
pkg install git vim curl wget tree fzf
zsh
安装 zsh
pkg install wget curl git vim zsh unrar unzip
使用我的 dotfiles。
然后在目录下执行 make termux 完成初始化。
SSH
默认 Termux 并没有安装 ssh 客户端,所以输入下面命令安装:
pkg install openssh
安装了 ssh 客户端就能够 ssh 连接远程服务器了。如果要从其他设备连接 Termux ,那么需要做一些设置。
生成密钥:
ssh-keygen -b 4096 -t rsa
# 或生成 ed25519
ssh-keygen -t ed25519 -C "i@einverne.info"
此时会在 Termux 手机上生成一对公钥私钥,在 ~/.ssh 目录下。
从电脑 SSH 连接 Termux
Termux 不支持密码登录,所以需要将客户端设备的 id_rsa.pub 文件内容拷贝到 Termux 的 ~/.ssh/authorized_keys 文件中。因为 Termux 不支持 ssh-copy-id 所以只能手动操作。
要实现如此可以在 Termux home 目录中 SSH 到客户端的机器上,然后拷贝:
scp username@desktop.ip:~/.ssh/id_rsa.pub .
cat id_rsa.pub >> ~/.ssh/authorized_keys
或在 Termux 中一行命令,将需要登录 Termux 机器上的公钥拷贝到 Termux 机器上的 authorized_keys 中:
ssh user@desktop_clinet "cat ~/.ssh/id_rsa.pub" >> ~/.ssh/authorized_keys
然后在 Termux 上启用 sshd:
sshd -d # -d 开始 debug 模式,可以不加
默认 sshd 监听的是 8022 端口,需要注意。
在电脑上使用 ssh 登陆手机 Termux
ssh -p 8022 -i ~/.ssh/id_rsa ipOfAndroidDevice
Termux 是单用户系统,所以不需要输入用户名,即使输入了 Termux 也会忽略。
传输文件
这样就免去了使用数据线连接手机传文件的问题,只要在局域网中能够互相访问,相互传输文件就方便许多。
# PC to Phone
scp -P 8022 -r ~/Downloads/ username@deviceIP:~/storage/pc/
# Phone to PC
scp -P 8022 -r username@deviceIP:~/storage/Downloads/ ~/
如果要在 Termux 上查看 sshd 日志,可以输入 logcat -s 'syslog:*'
确保这些目录的权限正确
chmod 700 ~/.ssh
chmod 600 ~/.ssh/id_rsa
chmod 600 ~/.ssh/id_rsa.pub
chmod 600 ~/.ssh/known_hosts
chmod 600 ~/.ssh/authorized_keys
最后可以在桌面端配置 vi ~/.ssh/config
Host op7
HostName ipOfYourDevice
User termux
Port 8022
ForwardX11 yes
ForwardX11Trusted yes
IdentitiesOnly yes
IdentityFile ~/.ssh/id_rsa
这样就可以 ssh op7 来登陆手机 Termux 了。
比如我手机的 sdcard 路径就是 /storage/emulated/0/ .
字体
若出现 zsh 的 agnoster 主题(或其他依赖 powerline 字体的主题)无法正常显示,可将您的 powerline 字体拷贝到 ~/.termux/font.ttf 后执行 termux-reload-settings
备份 Termux
https://wiki.termux.com/wiki/Backing_up_Termux
adb
如果开启了 Android 远程调试,那么使用 adb connect ip 就方便许多,安装 adb 以备不时之需。
Penetration Test
日常 nmap
pkg install hydraNetwork logon cracker and bruteforcer supporting different services like ssh, telnet, ftp etcpkg install nmapUtility for network discovery and security auditing- Metasploit Framework
- RouterSploit
- slowloris
更多可以参考 Termux Hacking
外延
reference
- 目前最强的教程 https://www.sqlsec.com/2018/05/termux.html
- https://wiki.termux.com/wiki/Main_Page
- https://wiki.termux.com/wiki/Remote_Access
- https://tonybai.com/2017/11/09/hello-termux/
全平台开源的密码管理软件 Bitwarden
今天逛博客偶然间见到了一款全平台开源的密码管理软件 – Bitwarden,回想 2013 年的时候曾经写过一篇密码管理的方案,一回首已经六年,而这六年间换了无数设备,换过无数密码,从最早手写,固定规则,到 KeePass,到 LastPass,还曾经买过一年的 LastPass 会员,如今稳定地用着 LastPass。也见证了 LastPass 从简陋的单纯的密码管理到 Chrome 上的自动填充,再到 Android 上的一键填充,最后 iOS 也开放了支持,所有的平台几乎 LastPass 通吃了, Auto Fill 的功能实在太贴心。
然后为了增加安全性很多网站开始开启二步验证,最早只有孤零零的 Google 一家,而如今但凡安全措施做的比较好的网站都支持了二步验证,而二步验证非常不愉快的一个使用体验就是无法跨设备同步,Google Authenticator 但只是非联网的一个本地应用,当然站在 Google Authenticator 的角度无疑是对的,完全隔离网络,那么再厉害的黑客也无法获知二步验证的数字,然而这一点却牺牲了用户使用的便携程度。我曾经遇到过一次手机无法开机而丢失所有二步验证的 token,这几乎让我崩溃,我需要到每一个网站去重置我的二步验证设置。而 LastPass Authenticator 虽然牺牲了一定的安全性,但带来的易用性确实方便了。只要开启同步换一个设备登录 LastPass 那么所有的内容都回来了。所以 LastPass 和 LastPass Authenticator 也成为了我每个设备的必用软件。
然而时间到了 2019 年,网络安全问题和个人隐私的问题日渐严重,在这样一个时间节点,我发现了 Bitwarden 这样一款软件,更让我惊讶的是从服务端到客户端全开源,并且全平台支持,甚至还支持命令行登录,这一点连 LastPass 都不曾做过。但这个应用服务如今还依然不流行,大多数的潜在用户都被 1Password 或者 LastPass 这样的服务提供方吸收了。基于这样的理由,虽然目前可能自动填充的功能还不及 LastPass, 但 Bitwarden 还是非常值得一试。
简单的看了一下客户端基本用 C# 和 [[TypeScript]] 写成,因为不太熟悉 C# 暂时不看代码了。感兴趣可以自行到 GitHub 审查代码。
Bitwarden 解决了 LastPass 潜在的一些问题,但依然也引入了一些问题。LastPass 带来的问题一个就是安全问题,如何保证用户的密码在服务器同步时的安全性,虽然 LastPass 曾正面出来声明过所有的密码都是由客户端加密再进行传输,服务端是不进行解密的,但是这个不确定性就在于 LastPass 是否可信。另外一个问题就是 LastPass 集中了用户大量的密码,肯定是黑客等等专注需要攻破的系统,一旦发生 LastPass 主密码泄露事件,那么造成的影响就不是一家网站,而是附带的很多网站,那就是互联网的大事情了。而这一点也正是幸运的地方,那么 LastPass 肯定会雇佣一批安全专家对他们的系统进行维护,这远比维护一套自己的 Bitwarden 服务端的安全系数要高。
另外如果自行搭建 Bitwarden 服务端,那么一定要做好充分的安全工作,首先得保证服务器的安全,其次开启系统防火墙,保证只有自己才能访问。先写这么多之后再补充。
安装 Bitwarden 服务端
Bitwarden 的官方网站 提供了各个系统的安装方式。
Bitwarden 自己的服务端 依赖比较重,还需要 MySQL,所以我选择了 Rust 实现的版本
官方的 Wiki 中写的非常详细,使用 Docker Compose 搭建。
使用 Bitwarden 客户端
Bitwarden 提供了非常丰富的客户端支持,从桌面端,到浏览器扩展,非常好用,并且 macOS 上还支持指纹。
Bitwarden 结合 Alfred
[[Alfred]] 是 macOS 上一个启动器,Bitwarden 自身支持 cli,两者结合起来就非常方便使用了。
推荐使用:
主要的几个命令:
.bwauth授权.bwconfig配置.bwf搜索文件夹.bw search_keyword搜索关键字
vaultwarden 开启 admin 页面
强烈建议开启 HTTPS 之后再启用 admin 管理页面。
该页面允许管理员检查注册用户并进行管理,即使注册关闭了也允许邀请用户。
在配置中启用 ADMIN_TOKEN:
docker run -d --name bitwarden \
-e ADMIN_TOKEN=some_random_token_as_per_above_explanation \
-v /vw-data/:/data/ \
-p 80:80 \
vaultwarden/server:latest
强烈推荐使用 openssl rand -base64 48 来生成随机字符串作为 TOKEN。
启用之后页面会在 /admin 页面上使用,进入管理员的页面。
reference
Magisk 模块整理 For OnePlus 7 Pro
Magisk 通过修改启动(Boot)文件,在开机时加载 Magisk 框架,“不修改实际的系统文件”而“达到修改系统的效果”.
Magisk 在数据(非系统)分区里放置了一些修改好的系统文件 / 程序,系统启动时会加载这些修改过的文件 / 程序,而不是系统本身的文件,这样系统本身的文件并没有被实际修改,
Magisk 的另一大功能就是获取 Root 权限 / 授权(Root)管理(MagiskSU)了,在原本的 SuperSu 被国内厂家收购后就失去了大部分的支持,所以现在 ROOT 基本通过 Magisk 来实现了。
Magisk 的另一个用处是帮助系统通过各种检测系统安全 / 完整性的测试。部分应用游戏 和 Google 的 SafetyNet 检测(用于 Google Pay 等)会检测 Root 权限 / 系统文件是否被修改,Magisk 的 Magisk 隐藏(Magisk Hide)功能可以让它们无法检测到 Magisk 的存在,你便可以在正常使用这些应用 / 游戏 / 功能的同时享受 Magisk 带来的便捷。Magisk Hide 功能也能解决 Magisk 和一些软件的冲突。
和 Magisk 不同, Xposed 通过劫持系统文件,使得所有程序启动时都会被注入 Xposed 的进程,这样 Xposed 模块就可以通过这些进程对程序进行系统层面的几乎任何修改。Magisk 除了 Magisk Hide 功能,再无单个应用级别的操作,同时在开机后也几乎无法再对系统 / 应用进行修改,所以 Xposed 所能实现的绝大多数功能,Magisk 都无法完美实现。
所以这篇文章就暂时先列举一些好用的 Magisk 模块,Xposed 和 EdXposed 模块另外写总结。
Magisk Manager for Recovery Mode (mm)
这个 Module 可以让我们在 Recovery (比如 TWRP) 下修改 Magisk 的设置
使用方法:
- 在终端中执行
sh /sdcard/mm - 或者在 Recovery 模式终端下执行
sh /sdcard/mm
Riru - Core
Riru 模块进入应用进程或系统服务进程并执行他们的代码
Riru - EdXposed
Android Pie 无法使用原版的 Xposed 所以有了 EdXposed 。
Busybox for Android NDK
BusyBox 是标准 Linux 工具的一个单个可执行实现,简单的说 BusyBox 就好像是个大工具箱,它集成压缩了 Linux 的许多工具和命令。
- https://github.com/Magisk-Modules-Repo/busybox-ndk
- https://forum.xda-developers.com/showpost.php?p=64228091
Wifi Bonding (Qualcomm)
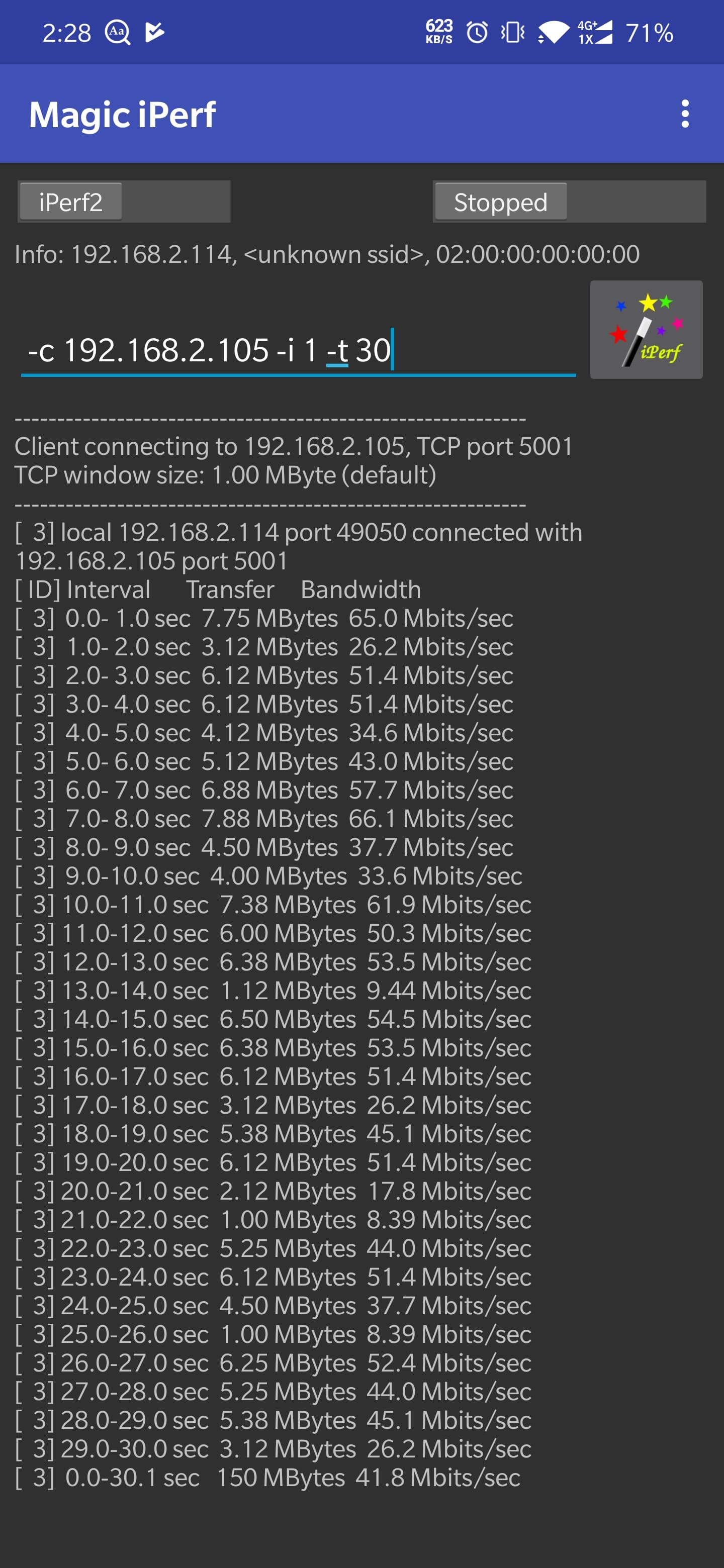
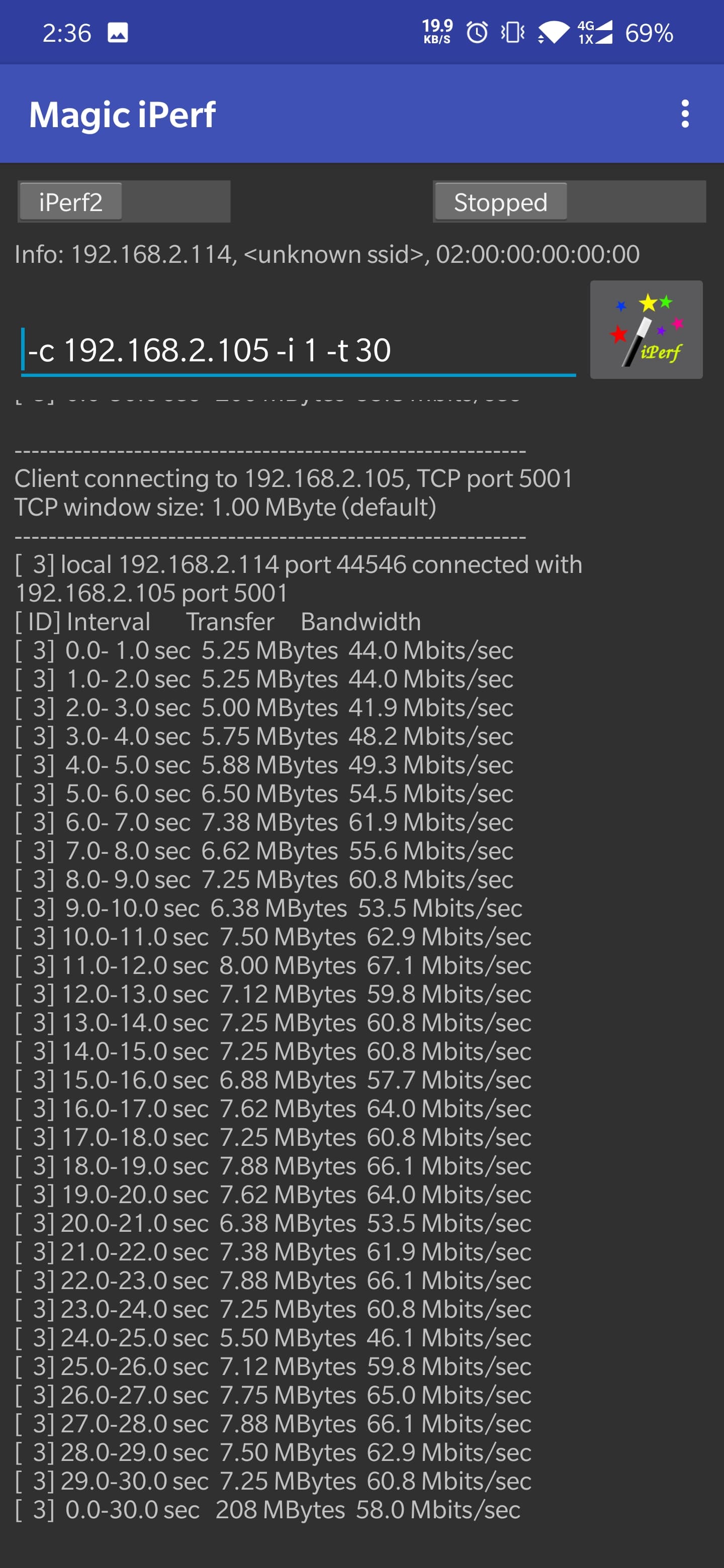
在高通设备上以 40MHz 的运行的 2.4GHz / 5.0GHz 的无线网络连接。在使用该 Module 之前需要了解什么是 Channel bonding,简单来说 Channel bonding 就是使用多于一条的通道来传输数据。
但说实话个人感觉提升并不明显。具体数据可以看下方。
Before
After
Riru - Location Report Enabler
一直都是使用 Market Unlocker 来虚拟运营商来开启 Google Location 的,但是每次 Market Unlocker 都需要手动启用一下,换成这个开机启动即可。
其他模块
Energized Protection
去广告模块,本人尝试后,误杀率挺大的,所以暂时先禁用。
Greenify4Magisk
似乎在 Pie 上系统自带的后台管理已经很强大,绿色守护也不怎么用了。
NFS-INJECTOR
内核优化,知识体系还没有深入到这里,暂时不安装。
App Systemizer
把系统应用转成系统应用,需要借助终端,下载 Termux 或者 Terminal Emulator
su获取 root 权限- 输入
systemize进入设置
编写 Magisk 模块
从模板克隆一份
各个目录解释:
- META-INF: 刷机包签名 / 脚本文件,通常不动
- common/post-fs-data.sh、common/service.sh:开机时执行的脚本文件,通常不动
- common/system.prop: Build.prop 文件
- system: 将需要替换的系统文件(空文件(夹)也可)按照位置放置即可
- config.sh: 模块设置和安装 / 刷入时使用 ui_print 命令显示的提示信息
- module.prop: 模块信息
然后将模块打包压缩成 zip 文件。
如果你使用 Telegram,这有一个频道可以关注一下,会发布 Magisk 模块。
- https://t.me/magiskmod
git describe 使用
git describe — 显示当前离当前提交最近的 tag
git describe --tags --abbrev=0
Android Kernel
说到 Android Kernel 那就不得不说到 Linux Kernel,Android Kernel 基于 Linux Kernel 的长期稳定版本,
Linux Kernel
首先 Linux Kernel 是什么? Linux Kernel 是在 GNU GPL v2 开源许可下开源的硬件底层驱动,包括了 CPU 调度,存储管理,IO 管理,等等。Linux Kernel 是 GPL 开源,所以为了适用移动设备内存,CPU 频率,耗电等特点,Google 将这部分 Linux Kernel 做了修改,并按照 GPL 将修改开源了。
The kernel has complete control over the system.
Android 最早的内核是基于 Linux 2.6 内核的,在很长一段时间内,Android 的 Kernel 一直使用非常老版本的 Linux Kernel,但是随着时间发展,渐渐的每一个版本的 Android 发布都再使用最新的 Linux Kernel 1.
Android Kernel
回到 Android Kernel,不同设别出厂的时候就会带一个 stock 官方的 kernel,当然这个 Kernel 是稳定可以用于日常使用的。但是有些官方优化的 Kernel 并没有发挥硬件的最佳,所以 xda 上就有很多人发布不同的 Kernel,可以支持一些电池的优化,或者对硬件一些更好的支持。
ElementalX
ElementalX 内核是一个我从 Nexus 6, OnePlus 3 开始就使用过的 Kernel,由 flar2 开发。
ElementalX 内核的突出特点就是稳定,在不牺牲稳定性的前提下对系统做一些优化,比如滑动手势,亮度模式,震动模式,声音控制,文件系统格式等等。
个人使用的情况也是非常稳定,没有遇到过任何硬件不兼容问题。
Franco Kernel
Franco Kernel 由 franciscofranco 开发,是非常著名的一个 Kernel,支持非常多的设备。
blu_spark
blu_spark kernel 由 eng.stk 开发。
更多的 kernel 可以查阅这里
CPU 调频器
OnDemand
OnDemand 是一个比较老的 linux kernel 中的调频器,当负载达到 CPU 阈值时,调频器会迅速将 CPU 调整到最高频率。由于这种偏向高频的特性,使得它有出色的流动性,但与其他调频器相比可能对电池寿命产生负面影响。OnDemand 在过去通常被制造商选用,因为它经过了充分测试并且很可靠,但已经过时,并且正在被 Google 的 interactive 控制器取代。
OndemandX
基本上是拥有 暂停、唤醒配置的 OnDemand,没有在 OnDemand 上做更多的优化。
Performance
Performance 调频器将手机的 CPU 固定在最大频率。
Powersave
与 Performance 调频器相反,Powersave 调频器将 CPU 频率锁定在用户设置的最低频率。
Conservative
该调速器将手机偏置为尽可能频繁地选择尽可能低的时钟速率。换句话说,在 Conservative 调频器提高 CPU 时钟速度之前,必须在 CPU 上有更大且更持久的负载。根据开发人员实现此调频器的方式以及用户选择的最小时钟速度,Conservative 调频器可能会引入不稳定的性能。另一方面,它可以有利于电池寿命。
Conservative 调频器也经常被称为“slow OnDemand”。原始的、未经修改的 Conservative 是缓慢并且低效的。较新版本和修改版本 Conservative(来自某些内核)响应速度更快,并且几乎可以用于任何用途。
Userspace
这种调频器在移动设备中极为罕见,它允许用户执行的任何程序设置 CPU 的工作频率。此调频器在服务器或台式 PC 中更常见,其中应用程序(如电源配置文件应用程序)需要特权来设置 CPU 时钟速度。
Min Max
Min Max 调频器会根据负载选择最低或者最高的频率,而不会使用中间频率。
Interactive
Interactive 会平衡内核开发人员(或用户)设置的时钟速度。换句话说,如果应用程序需要调整到最大时钟速度(CPU 100%负载),用户可以在调频器开始降低 CPU 频率之前执行另一个任务。由于此计时器,Interactive 还可以更好地利用介于最小和最大 CPU 频率之间的中间时钟速度。它的响应速度明显高于 OnDemand,因为它在调整到最大频率时速度更快。
Interactive 还假设用户打开屏幕之后很快就会与其设备上的某个应用程序进行交互。 因此,打开屏幕会触发最大时钟速度的斜坡,然后是上述的定时器行为。
Interactive 是当今智能手机和平板电脑制造商的首选默认调频器。
InteractiveX
由内核开发人员“Imoseyon”创建,InteractiveX 调频器主要基于交互式调频器,增强了调整计时器参数,以更好地平衡电池与性能。但是,InteractiveX 调频器的定义功能是在屏幕关闭时将 CPU 频率锁定到用户最低定义的速度。
Smartass
基于 Interactive,表现和之前的 minmax 一致,smartass 相应更快。电池寿命很难精确量化,但它确实在较低频率下可以使用更长。
当睡眠时调整到 352Mhz ,Smartass 还会限制最大频率(或者如果您设置的最小频率高于 352,它将限制到您设定的最小频率)。
该调频器会在屏幕关闭时缓慢的降低频率,甚至它也可以让手机 CPU 频率降至一个让手机无法正常使用的值(如果最小频率没有设置好的话)。
SmartassV2
从 Erasmux 中而来的 Version 2 版本,该调频器的目标是“理想的频率”,并且更加积极地向这个频率增加,并且在此之后不那么激进。它在屏幕开启或者关闭时使用不同的频率,即 awake_ideal_freq 和 sleep_ideal_freq。 当屏幕关闭时,此调频器非常快地降低 CPU(快速达到 sleep_ideal_freq )并在屏幕开启时快速向上调整到 awake_ideal_freq。 屏幕关闭时,频率没有上限(与 Smartass 不同)。因此,整个频率范围可供调频器在屏幕开启和屏幕关闭状态下使用。这个调频器的主打功能是性能和电池之间的平衡。
Scary
Scary 基于 Conservative 并增加了一些 smartass 的特征,它相应地适用于 Conservative 的规则。所以它将从底部开始,采取一个负载样本,如果它高于上限阈值,一次只增加一个梯度,并一次减少一个。 它会自动将屏幕外的速度限制为内核开发人员设置的速度,并且仍然会根据保守法律进行调整。 所以它大部分时间都花在较低的频率上。 这样做的目的是通过良好的性能获得最佳的电池寿命。
schedutil
Schedutil is the newest CPUFreq governor introduced back during Linux 4.7 as an alternative to ondemand, performance, and others. What makes Schedutil different and interesting is that it makes use of CPU scheduler utilization data for its decisions about CPU frequency control
reference
OnePlus 7 pro Oxygen OS 设置
这些年用 Android 下来总是最喜欢原生的系统,但是却总觉得缺少一些什么,而这些东西在用 Oxygen OS(后简称 OOS)之后发现竟然如此的贴心好用,甚至有一定程度上要超越 Google 原生的系统。比如一些非常不错的小功能,状态来显示网速,三指截屏等。
OOS 自带
- 内置录屏,虽然是一个使用频率不高的功能,但需要起来就能使用还是很不错的
- 三指截屏,滚动获取长截图,以前多屏长截图需要额外的软件支持,自带还是很贴心的
- 翻转静音
- 可选虚拟按键,本人一直喜欢虚拟按键,但是用过 OOS 的 Navigation 手势之后发现原来真的可以不用常驻的虚拟键,虽然 OOS 的返回依然有些难用,但是也是一个不错的选择。
界面 Tweak
- 电量显示百分比,默认情况下电量只会显示一个电池,并不会显示百分比,可以在设置中开启
- 状态栏显示网络速度,设置开启
使用 GravatyBox 调整
- Statue Bar 支持滑动调整亮度,OnePlus 7 Pro 的自动调亮似乎总是把屏幕亮度调低
- 状态栏显示下载进度条
- 显示上传下载网速,可选,和 OOS 原生类似
Android 9.0 uses xposed solutions
- https://github.com/solohsu/EdXposed/releases
- https://github.com/RikkaApps/Riru/releases
- https://github.com/ElderDrivers/EdXp…nager/releases
- https://github.com/solohsu/XposedInstaller/releases
Use Magisk order to install
- Flash magisk-riru-core-arm-arm64-v10.zip
- Flash magisk-EdXposed-arm-arm64-v x.x_beta-release.zip
- Installation XposedInstaller_by_dvdandroid_19_10_18. apk
Reboot the device
Android Pie 在 EdXposed 下可用的模块列表
reference
OnePlus 7 Pro 折腾记
OnePlus 7 Pro 折腾记。
Unlock Bootloader
先前准备:
- 备份数据,具体可以使用 adb 命令,见后文
- 开启开发者模式,Settings -> About Phone -> 点击 Build Number 7 次
- 调试模式,Settings -> Developer option -> Enable USB Debugging
- 开启 OEM Unlocking,Settings -> Developer options -> OEM Unlocking 开启
- PC 上安装 fastboot 工具
具体步骤
- 数据线连接手机,adb devices 确认连接成功
- 手机出现 Debug 对话框,确认
- 进入 bootloader 模式,
adb reboot bootloader fastboot devicesfastboot oem unlock- 然后使用音量键选择,重启
- 等待重启完毕就 OK 了
TWRP
第三方的 Recovery,首推 TWRP, 在 OnePlus 7 Pro 推出不久之后 xda 上面的 mauronofrio 就发布了非官方版本的 TWRP,当然随着时间往后 mauronofrio 将其制作的 TWRP 发布到了官方页面 . 本人测试 2019-06-08 的 twrp-3.3.1-3-guacamole.img ,非常完美。
安装 TWRP 过程
- 去官方网站下载 twrp-3.3.1-3-guacamole.img 和 twrp-installer-3.3.1-3-guacamole.zip 文件准备,img 文件放到桌面版以便于 adb 刷入,zip 包拷贝到手机内存
- 连接电脑,让手机进入 fastboot 模式
fastboot boot twrp-3.3.1-3-guacamole.img让手机用该 Recovery 启动,boot 命令只会让手机此次启动使用 TWRP,需要进行下一步才能让手机保持 TWRP Recovery- 在 TWRP 中 flash 之前准备好的 zip 包
刷完重启进入系统
注意:OnePlus 7 Pro 使用 Slot A/B,但是最新的 TWRP 已经自动支持 A/B 识别,不用担心 A/B 的问题
Root OnePlus 7 Pro with patched Boot Image
在 root 之前需要注意
- 使用原生 OOS
- Unlocked bootloader
- fastboot 工具
然后根据一下流程:
- 根据自己的版本 GM1910,系统版本 Oxygen OS 9.5.6 下载 patched boot image,或者自己制作 patched boot image
- 安装最新的 Magisk Manager
- adb reboot bootloader 进入 fastboot mode
- fastboot devices
- 如果担心下错 boot image,可以尝试使用 fastboot boot boot.img 来用本地的 image 文件启动
- 确认没有问题之后,刷入
fastboot flash boot boot_patched.img fastboot reboot重启- 打开 Magisk ,安装,使用 Direct Install
- 这样就有了一个 root 的 OnePlus 7 Pro
From: xda
Magisk
使用 Magisk ROOT
- 确保已经安装 Magisk v17.2 版本
- Download Riru-Core riru-core-v19.1
- Download EdXposed From magisk-EdXposed-v0.4.2.3_alpha-release
- 在 Magisk Module 中,点击
+号,选择 Riru-Core 和 EdXposed - 然后重启手机,然后下载 EdXposed Apk From here
From: xda
更新系统 OTA 之后保留 recovery root 等
更新 OTA, Magisk 在拥有 slot A/B 的设备上有新的特性,能让系统正常更新而不会丢失 ROOT。如果想要了解更多 A/B 分区的问题可以参考这里.
如果想要在 OTA 之后保留 ROOT:
- 使用全量包更新,然后在 System 设置中使用本地更新,切记更新完成不要立即重启
- 打开 Magisk ,点击 Magisk 一行的安装,在弹出的对话框中点击安装
- 然后在弹出的对话框 (select Method) 中选择
Install to Inactive Slot (After OTA)选项 (中文应该是,安装到未使用的槽位,安装完 OTA 后) - 最后安装重启
在上方的步骤重启进入系统之后会丢掉 TWRP,进入系统后需要重新刷入,在 OTA 之后保留 TWRP:
- 打开 Magisk Manager ,然后像刷入其他 Module 一样输入之前 TWRP 的 zip 包
- 不要重启,刷入 TWRP 之后会丢失 ROOT Access
- 然后重新到 Magisk,点击 Install , Direct Install,然后再重启
在最后一步,有些教程可能有问题,在这里只需要 Direct Install,而不需要 Install to Inactive Slot(After OTA) 了。
这些步骤之后就 OTA 成功,并且保留了 TWRP,以及 Magisk 和 Magisk 下所有的模块。
使用 adb 备份数据
使用 adb 备份数据的时候千万注意,adb 备份的数据恢复时不会自动安装应用,并且可能恢复不完整。如果可能还是使用 Titanium Backup (ROOT) 等专业工具备份和恢复。
adb backup -apk -shared -all -f op7pro-backup-file.ad
参数解释:
-apk|-noapk是否备份包含 apk 或者仅仅备份应用数据,推荐使用-apk选项,默认为-noapk-shared|-noshared决定是否备份设备共享的 SD 卡内容,默认为-noshared,主要包括内部存储中的音乐,图片和视频等,推荐使用-shared-all备份所有应用-system|-nosystem决定-all选项是否包含系统应用,默认是-system-f后面需要指定路径及文件名,表示用来存储的位置,比如-f /path/backup.file那么会存储在path目录下名为backup.file的文件中
恢复数据
设备连接电脑,adb devices 查看连接成功
adb restore op7pro-backup-file.ad
如果想要手动解开这个备份文件,可以参考这个项目
一些问题
GM 版本问题
氧系统有好几个版本的全量 ROM, GM21AA,GM21BA。这两个版本的含义是:
-
标记有 GM21AA 的包适用于印度、全球(不含欧洲)、美国的无锁版 Model
- GM1911: India - GM1917: Global/US Unlocked (?) -
GM21BA 欧洲销售版本
- GM1913: EU - GM27BA EU 5G 版本,GM 1915
- GM31CB GM1915 T-Mobile (Carrier Locked)
adb 连接问题
adb 之前保证打开开发者模式,并且设置中确保设置打开,
adb devices
List of devices attached
5fxxxxxx no permissions (verify udev rules); see [http://developer.android.com/tools/device.html]
在使用 adb 连接的时候如果遇到这个问题,那么在通知栏中,换一种 USB 连接模式,保证非充电模式。如果还不行可以尝试
adb kill-server
adb start-server
更多关于 adb 和 fastboot 命令的使用可以参考之前的 adb 文章 和 fastboot 文章
从 recovery 中删除导致无限重启的 magisk module
按住音量下+电源键进入 Recovery 模式,在 TWRP Recovery 下,Advanced > File Manager,打开文件管理,找到:
/data/adb/modules
在这个目录里面就能看到安装的 Magisk 模块,删除新增的模块即可。
reference
Java 定时任务框架 Job-scheduling Quartz 使用
Quartz is a richly featured, open source job scheduling library that can be integrated within virtually any Java application - from the smallest stand-alone application to the largest e-commerce system.
Setup
<dependency>
<groupId>org.quartz-scheduler</groupId>
<artifactId>quartz</artifactId>
<version>2.2.1</version>
</dependency>
Usage
客户端调用
JobDetail job = newJob(MyJob.class)
.withIdentity("myJob")
.build();
Trigger trigger = newTrigger()
.withIdentity(triggerKey("myTrigger", "myTriggerGroup"))
.withSchedule(simpleSchedule()
.withIntervalInHours(1)
.repeatForever())
.startAt(futureDate(10, MINUTES))
.build();
scheduler.scheduleJob(job, trigger);
Source Code
StdSchedulerFactory 是 Scheduler 的工厂方法,实现了 SchedulerFactory 接口。
// 提供客户端可用的 Scheduler
Scheduler getScheduler() throws SchedulerException;
// 通过名字获取
Scheduler getScheduler() throws SchedulerException;
// 返回当前 JVM 中通过该 Factory 创建的所有 Scheduler
Collection<Scheduler> getAllSchedulers() throws SchedulerException;
SchedulerRepository 单例,内部持有一个 Map HashMap<String, Scheduler> schedulers
类中,绑定 (bind),解绑 (remove) 都为同步方法,保证线程安全。
Scheduler
Scheduler 是一个很庞大的接口,它的实现主要有
- RemoteScheduler, via RMI
- StdScheduler, std
- JBoss4RMIRemoteMBeanScheduler, via JBoss’s JMX RMIAdaptor
Quartz 的核心实现也基本都在这些实现类中,Scheduler 可以用来定时触发任务。
CronScheduleBuilder
CronScheduleBuilder 用来将字符串的 cron 表达式变成 CronScheduleBuilder 对象,ScheduleBuilder 是一个抽象类
public class CronScheduleBuilder extends ScheduleBuilder<CronTrigger> {
public static CronScheduleBuilder cronSchedule(String cronExpression) { }
}
主要的实现有:
- CronScheduleBuilder 主要实现 cron 定时任务,通过字符表达式
- SimpleScheduleBuilder 比较简单的 ScheduleBuilder
- CalendarIntervalScheduleBuilder 看例子
withIntervalInDays(3)每隔 3 天,如果要使用固定间隔的可以看一下这个 - DailyTimeIntervalScheduleBuilder 看例子比较简单
onDaysOfTheWeek(MONDAY, THURSDAY), 每一个周一和周四
比如
CronScheduleBuilder scheduleBuilder = CronScheduleBuilder.cronSchedule(job.getCronExpr());
trigger = TriggerBuilder.newTrigger().withIdentity(triggerId).withSchedule(scheduleBuilder)
.forJob(jobDetail).build();
scheduler.scheduleJob(jobDetail, trigger);
jbpm 中 ProcessEventListener 顺序问题
在 jBPM 商业流程中有一个 ProcessEventListener ,可以用来回调流程的执行过程,但是这个 Listener 的执行顺序非常奇怪。
首先我们先看看这个 interface
public interface ProcessEventListener {
void beforeProcessStarted( ProcessStartedEvent event );
void afterProcessStarted( ProcessStartedEvent event );
void beforeProcessCompleted( ProcessCompletedEvent event );
void afterProcessCompleted( ProcessCompletedEvent event );
void beforeNodeTriggered( ProcessNodeTriggeredEvent event );
void afterNodeTriggered( ProcessNodeTriggeredEvent event );
void beforeNodeLeft( ProcessNodeLeftEvent event );
void afterNodeLeft( ProcessNodeLeftEvent event );
void beforeVariableChanged(ProcessVariableChangedEvent event);
void afterVariableChanged(ProcessVariableChangedEvent event);
}
我相信大多数人看到这些方法回调大致可以猜测 afterProcessStarted 应该是在流程开始之后被调用,然而实际的调用顺序是这样的:
- beforeProcessStarted
- beforeNodeTriggered
- beforeNodeLeft
- beforeNodeTriggered
- beforeVariableChanged
afterVariableChanged
- beforeNodeLeft
- beforeNodeTriggered
- beforeNodeLeft
- beforeNodeTriggered
afterNodeTriggered
afterNodeLeft
- beforeNodeLeft
beforeNodeTriggered
afterNodeTriggered
afterNodeLeft
afterNodeTriggered
afterNodeLeft
afterNodeTriggered
afterNodeLeft
afterNodeTriggered
afterProcessStarted
afterProcessStarted 会在流程结束时被调用。有人提过 bug 但是官方认为这是程序设计,所以使用文档的形式 将这种方式说明了。
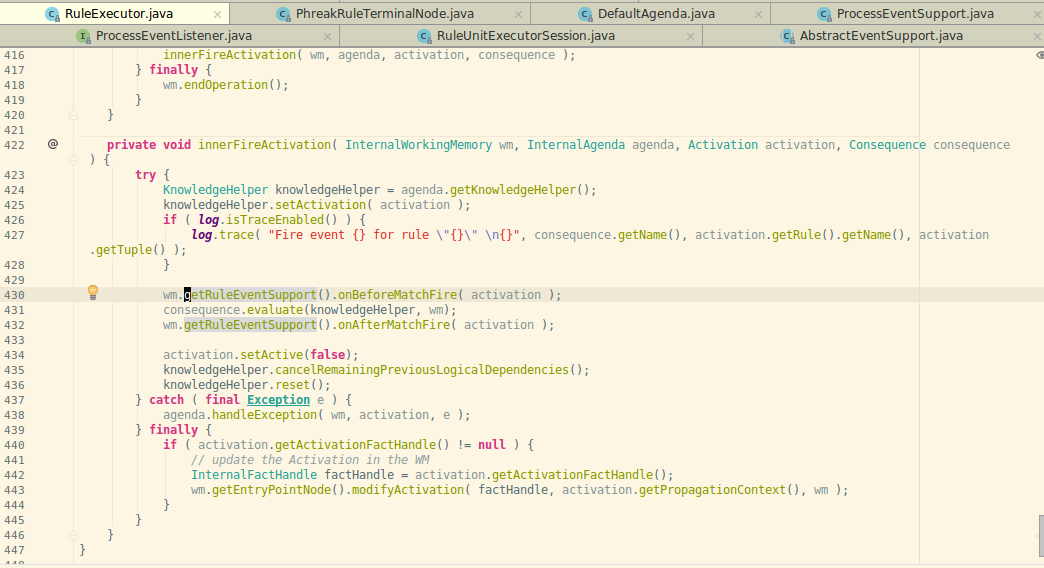
查看源代码可以在 RuleExecutor 中可以看到:
实验
假设有如下图的流程
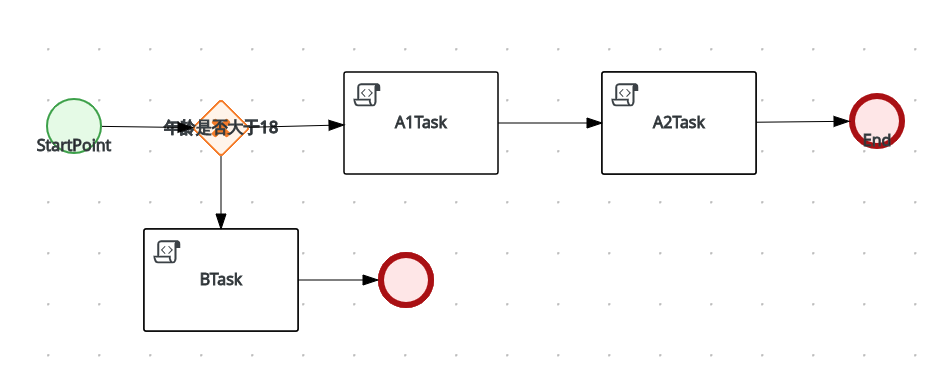
那么打印所有的日志可以观察到:
- DefaultRuleContainer beforeVariableChanged ==>[ProcessVariableChanged(id=age; instanceId=age; oldValue=null; newValue=18; processName=BPTest; processId=FlowTest.BPTest)]
- DefaultRuleContainer afterVariableChanged ==>[ProcessVariableChanged(id=age; instanceId=age; oldValue=null; newValue=18; processName=BPTest; processId=FlowTest.BPTest)]
- DefaultRuleContainer beforeProcessStarted ==>[ProcessStarted(name=BPTest; id=FlowTest.BPTest)]
- event ==>[ProcessStarted(name=BPTest; id=FlowTest.BPTest)]
- DefaultRuleContainer beforeNodeTriggered ==>[ProcessNodeTriggered(nodeId=4; id=0; nodeName=StartPoint; processName=BPTest; processId=FlowTest.BPTest)]
- DefaultRuleContainer beforeNodeLeft ==>[ProcessNodeLeft(nodeId=4; id=0; nodeName=StartPoint; processName=BPTest; processId=FlowTest.BPTest)]
- DefaultRuleContainer beforeNodeTriggered ==>[ProcessNodeTriggered(nodeId=7; id=1; nodeName= 年龄是否大于 18; processName=BPTest; processId=FlowTest.BPTest)]
- DefaultRuleContainer beforeNodeLeft ==>[ProcessNodeLeft(nodeId=7; id=1; nodeName= 年龄是否大于 18; processName=BPTest; processId=FlowTest.BPTest)]
- DefaultRuleContainer beforeNodeTriggered ==>[ProcessNodeTriggered(nodeId=2; id=2; nodeName=A1Task; processName=BPTest; processId=FlowTest.BPTest)]
- DefaultRuleContainer beforeNodeLeft ==>[ProcessNodeLeft(nodeId=2; id=2; nodeName=A1Task; processName=BPTest; processId=FlowTest.BPTest)]
- DefaultRuleContainer beforeNodeTriggered ==>[ProcessNodeTriggered(nodeId=6; id=3; nodeName=A2Task; processName=BPTest; processId=FlowTest.BPTest)]
- DefaultRuleContainer beforeNodeLeft ==>[ProcessNodeLeft(nodeId=6; id=3; nodeName=A2Task; processName=BPTest; processId=FlowTest.BPTest)]
- DefaultRuleContainer beforeNodeTriggered ==>[ProcessNodeTriggered(nodeId=3; id=4; nodeName=End; processName=BPTest; processId=FlowTest.BPTest)]
- DefaultRuleContainer beforeNodeLeft ==>[ProcessNodeLeft(nodeId=3; id=4; nodeName=End; processName=BPTest; processId=FlowTest.BPTest)]
- DefaultRuleContainer beforeProcessCompleted ==>[ProcessCompleted(name=BPTest; id=FlowTest.BPTest)]
- DefaultRuleContainer afterProcessCompleted ==>[ProcessCompleted(name=BPTest; id=FlowTest.BPTest)]
- event ==>[ProcessCompleted(name=BPTest; id=FlowTest.BPTest)]
- DefaultRuleContainer afterNodeLeft ==>[ProcessNodeLeft(nodeId=3; id=4; nodeName=End; processName=BPTest; processId=FlowTest.BPTest)]
- DefaultRuleContainer afterNodeTriggered ==>[ProcessNodeTriggered(nodeId=3; id=4; nodeName=End; processName=BPTest; processId=FlowTest.BPTest)]
- DefaultRuleContainer afterNodeLeft ==>[ProcessNodeLeft(nodeId=6; id=3; nodeName=A2Task; processName=BPTest; processId=FlowTest.BPTest)]
- DefaultRuleContainer afterNodeTriggered ==>[ProcessNodeTriggered(nodeId=6; id=3; nodeName=A2Task; processName=BPTest; processId=FlowTest.BPTest)]
- DefaultRuleContainer afterNodeLeft ==>[ProcessNodeLeft(nodeId=2; id=2; nodeName=A1Task; processName=BPTest; processId=FlowTest.BPTest)]
- DefaultRuleContainer afterNodeTriggered ==>[ProcessNodeTriggered(nodeId=2; id=2; nodeName=A1Task; processName=BPTest; processId=FlowTest.BPTest)]
- DefaultRuleContainer afterNodeLeft ==>[ProcessNodeLeft(nodeId=7; id=1; nodeName= 年龄是否大于 18; processName=BPTest; processId=FlowTest.BPTest)]
- DefaultRuleContainer afterNodeTriggered ==>[ProcessNodeTriggered(nodeId=7; id=1; nodeName= 年龄是否大于 18; processName=BPTest; processId=FlowTest.BPTest)]
- DefaultRuleContainer afterNodeLeft ==>[ProcessNodeLeft(nodeId=4; id=0; nodeName=StartPoint; processName=BPTest; processId=FlowTest.BPTest)]
- DefaultRuleContainer afterNodeTriggered ==>[ProcessNodeTriggered(nodeId=4; id=0; nodeName=StartPoint; processName=BPTest; processId=FlowTest.BPTest)]
- DefaultRuleContainer afterProcessStarted ==>[ProcessStarted(name=BPTest; id=FlowTest.BPTest)]
reference
drools workbench
Drools 是一个 Java 的商业过程实现,这是 Bob McWhirter 所编写的一个开源项目,由 JBoss 和 Red Hat Inc 支持。 Drools 提供一个核心的 Business Rules Engine(BRE) 和一个网页编写规则的管理系统(Drools Workbench)和 一个 Eclipse IDE 的插件,一同构成完整的 Drools 生态。
而这篇文章则主要侧重于 Drools Workbench。
Workbench
org.guvnor.m2repo.dir
The workbench stores its data, by default in the directory $WORKING_DIRECTORY/.niogit, for example wildfly-8.0.0.Final/bin/.niogit, but it can be overridden with the system property -Dorg.uberfire.nio.git.dir.
Note In production, make sure to back up the workbench data directory.
18.1.3. System properties Here’s a list of all system properties:
org.uberfire.nio.git.dir: Location of the directory .niogit. Default: working directory
org.uberfire.nio.git.daemon.enabled: Enables/disables git daemon. Default: true
org.uberfire.nio.git.daemon.host: If git daemon enabled, uses this property as local host identifier. Default: localhost
org.uberfire.nio.git.daemon.port: If git daemon enabled, uses this property as port number. Default: 9418
org.uberfire.nio.git.ssh.enabled: Enables/disables ssh daemon. Default: true
org.uberfire.nio.git.ssh.host: If ssh daemon enabled, uses this property as local host identifier. Default: localhost
org.uberfire.nio.git.ssh.port: If ssh daemon enabled, uses this property as port number. Default: 8001
org.uberfire.nio.git.ssh.cert.dir: Location of the directory .security where local certificates will be stored. Default: working directory
org.uberfire.nio.git.ssh.passphrase: Passphrase to access your Operating Systems public keystore when cloning git repositories with scp style URLs; e.g. git@github.com:user/repository.git.
org.uberfire.metadata.index.dir: Place where Lucene .index folder will be stored. Default: working directory
org.uberfire.cluster.id: Name of the helix cluster, for example: kie-cluster
org.uberfire.cluster.zk: Connection string to zookeeper. This is of the form host1:port1,host2:port2,host3:port3, for example: localhost:2188
org.uberfire.cluster.local.id: Unique id of the helix cluster node, note that ‘:’ is replaced with ‘_’, for example: node1_12345
org.uberfire.cluster.vfs.lock: Name of the resource defined on helix cluster, for example: kie-vfs
org.uberfire.cluster.autostart: Delays VFS clustering until the application is fully initialized to avoid conflicts when all cluster members create local clones. Default: false
org.uberfire.sys.repo.monitor.disabled: Disable configuration monitor (do not disable unless you know what you’re doing). Default: false
org.uberfire.secure.key: Secret password used by password encryption. Default: org.uberfire.admin
org.uberfire.secure.alg: Crypto algorithm used by password encryption. Default: PBEWithMD5AndDES
org.uberfire.domain: security-domain name used by uberfire. Default: ApplicationRealm
org.guvnor.m2repo.dir: Place where Maven repository folder will be stored. Default: working-directory/repositories/kie
org.guvnor.project.gav.check.disabled: Disable GAV checks. Default: false
org.kie.example.repositories: Folder from where demo repositories will be cloned. The demo repositories need to have been obtained and placed in this folder. Demo repositories can be obtained from the kie-wb-6.2.0-SNAPSHOT-example-repositories.zip artifact. This System Property takes precedence over org.kie.demo and org.kie.example. Default: Not used.
org.kie.demo: Enables external clone of a demo application from GitHub. This System Property takes precedence over org.kie.example. Default: true
org.kie.example: Enables example structure composed by Repository, Organization Unit and Project. Default: false
org.kie.build.disable-project-explorer: Disable automatic build of selected Project in Project Explorer. Default: false
To change one of these system properties in a WildFly or JBoss EAP cluster:
Edit the file $JBOSS_HOME/domain/configuration/host.xml.
Locate the XML elements server that belong to the main-server-group and add a system property, for example:
文章分类
最近文章
- 从 Buffer 消费图学习 CCPM 项目管理方法 CCPM(Critical Chain Project Management)中文叫做关键链项目管理方法,是 Eliyahu M. Goldratt 在其著作 Critical Chain 中踢出来的项目管理方法,它侧重于项目执行所需要的资源,通过识别和管理项目关键链的方法来有效的监控项目工期,以及提高项目交付率。
- AI Shell 让 AI 在命令行下提供 Shell 命令 AI Shell 是一款在命令行下的 AI 自动补全工具,当你想要实现一个功能,敲一大段命令又记不住的时候,使用自然语言让 AI 给你生成一个可执行的命令,然后确认之后执行。
- 最棒的 Navidrome 音乐客户端 Sonixd(Feishin) Sonixd 是一款跨平台的音乐播放器,可以使用 [[Subsonic API]],兼容 Jellyfin,[[Navidrome]],Airsonic,Airsonic-Advanced,Gonic,Astiga 等等服务端。 Sonixd 是一款跨平台的音乐播放器,可以使用 [[Subsonic API]],兼容 Jellyfin,[[Navidrome]],Airsonic,Airsonic-Advanced,Gonic,Astiga 等等服务端。
- 中心化加密货币交易所 Gate 注册以及认证 Gate.io 是一个中心化的加密货币交易所。Gate 中文通常被称为「芝麻开门」,Gate 创立于 2013 年,前身是比特儿,是一家致力于安全、稳定的数字货币交易所,支持超过 1600 种数字货币的交易,提供超过 2700 个交易对。
- 不重启的情况下重新加载 rTorrent 配置文件 因为我在 Screen 下使用 rTorrent,最近经常调试修改 rtorrent.rc 配置文件,所以想要找一个方法可以在不重启 rTorrent 的情况重新加载配置文件,网上调查了一下之后发现原来挺简单的。