在 Linux 上使用 Clash 作代理
去年年中的时候切换到 macOS,一直用 ClashX,时隔半年又迁移回了 Linux1,发现原先使用的 V2rayL 虽然能用,但是有些简陋,并且不支持分流,并且如果一个地址失效了,还需要手动地进行切换。所以看到 Linux 的 Clash 可以自动进行流量切换的时候,就试一下。
Clash 是 Go 语言实现的,跨平台代理工具,支持 Shadowsocks/v2ray,支持规则分流等等。
可以在官方页面下载。
Linux 下载对应的 linux-amd64 即可。
2021 年 11 月更新
在用了很长一段时间的 Clash 命令行之后,我发现 Clash For Windows 这个应用也能够在 Linux 下使用。所以最近就切换到了这个应用上。
另外欢迎订阅使用 EV Proxy 注册之后一键订阅即可使用。
安装
下载对应的二进制,比如默认放到 ~/Downloads 目录,在终端进入该目录。
gunzip clash-linux-amd64-v0.18.0.gz
sudo mv clash-linux-amd64-v1.4.2 /usr/local/bin/clash
sudo chmod +x /usr/local/bin/clash
./clash
clash 启动后会在 ~/.config/clash 目录生成配置文件。
ls -al ~/.config/clash
.rw-r--r-- 10 einverne 23 Mar 19:30 config.yaml
.rw-r--r-- 4.0M einverne 23 Mar 19:30 Country.mmdb
修改配置
比如说对于我使用的Wallless 代理,在后台复制地址之后,在网址的后面增加 &flag=clash 获取 clash 的配置文件,右击网页 Save as,选择仅网页内容,下载到本地, sub.html。
另外还有一个代理,有兴趣的可以试用一下。
然后将查看 sub.html 内容,应该是一个 yaml 格式的文件。将此格式的文件替换默认的配置。
cat ~/Downloads/sub.html > ~/.config/clash/config.yaml
然后重新执行 /usr/local/bin/clash。
此时检查一下配置中的 socks 端口,我一般用本地的 1080,修改一下:
socks-port: 1080
然后再运行。去浏览器中,访问 youtube.com 检查一下。
如果正常访问即完成了配置。
配置开机启动
在配置开机启动之前,将配置文件移动到 /etc 目录:
sudo mv ~/.config/clash /etc
以后修改配置都记住修改 /etc/clash 目录下的这个配置文件。
然后使用 vi 增加 systemd 配置 sudo vi /etc/systemd/system/clash.service 放入如下内容:
[Unit]
Description=Clash Daemon
[Service]
ExecStart=/usr/local/bin/clash -d /etc/clash/
Restart=on-failure
[Install]
WantedBy=multi-user.target
启用 clash service:
sudo systemctl enable clash.service
手动启动 clash.service:
sudo systemctl start clash.service
可以使用 systemd 提供的 disable, stop 等等命令来管理。
如果要查看 Clash service 的日志可以使用:
journalctl -e -u clash.service
如果想要将日志单独记录到文件,可以使用 systemd 的 StandardOutput 和 StandardError 将日志定向到文件中。这部分可以参考 systemd 的文档
# Works only in systemd v240 and newer!
StandardOutput=append:/var/log/clash/log.log
StandardError=append:/var/log/clash/error.log
远程管理端口
Clash 提供了默认的 9090 端口作为远端管理端口,在配置中可以看到:
external-controller: '127.0.0.1:9090'
这样的配置。
可以使用 Clash 远程管理的页面进行管理: http://clash.razord.top/#/proxies
这个页面要求提供,Host,Port,Secret 三个输入:
- Host: 127.0.0.1
- Port: 9090
- Secret: 配置文件配置的 secret
其中 Secret 是在配置文件中通过:
secret: 'xxx'
进行配置的。
related
- 在终端下使用 socks 代理
- 你还可以在终端下对代理进行测速
感谢 BobMaster 在评论里面提供其他解决方式,有兴趣可以尝试 v2rayA, 或 Qv2ray
reference
使用 Beancount 记账篇六:利用 VS Code 插件辅助
[[Beancount]] 是一个纯文本的复式记账工具,因为是纯文本的记账工具,所以帐本就可以理解成为有一定格式的「代码」,所以编写这一份帐本,就可以和代码补充的 IDE 一样,比如在输入消费 Expenses,或者 Liabilities 等时,可以利用账户的关键字来借助插件自动补全,快速完成记账。
这篇文章重点介绍一下 VSCode 下的 Beancount 插件。
VSCode 插件
VSCode-Beancount 插件提供了语法高亮和账户自动补全功能。
{
"beancount.mainBeanFile": "main.bean",
"beancount.inputMethods": ["pinyin"]
}
Drools 原理之 RETE 算法
RETE 算法是卡内基梅隆大学的 [[Charles L.Forgy]] 博士在 1974 年发表的论文中实现的算法,是一种[[模式匹配算法]]。简易版本的论文发表于 1982 年 (http://citeseer.ist.psu.edu/context/505087/0)。拉丁语的 rete 表示 ”net” 和 “network”。
这个算法设计的目的是为了在大量的规则,Objects(或者说 Facts)中寻找匹配的规则。其核心思想是通过分离的匹配项,根据内容动态的构造匹配树,缓存中间结果,以空间换取时间,降低计算量。
RETE 算法主要可以分成两个部分:
- 规则编译 rule compilation,构建 RETE 网络,一个有向无环图。
- 规则执行 runtime execution
- 找出符合 LHS 部分的集合
- 选择一个条件被满足的规则
- 执行 RHS 内容
RETE 算法通过规则条件生成了一个网络,每个规则条件是网络中的一个节点。
大量模式集合和大量对象集合间比较的高效方法,通过网络筛选的方法找出所有匹配各个模式的对象和规则。
在 Dr. Forgy 1982 年的论文中,他定义了 4 种基本节点:
- root
- 1-input
- 2-input
- terminal
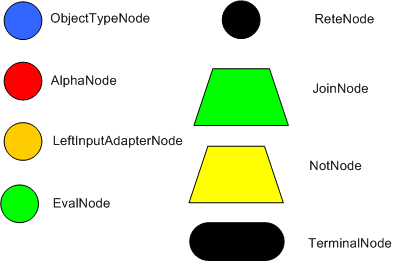
RETE 网络中的节点,除了根节点之外,每一个节点都对应一个 Pattern,对应规则的条件部分模式。从根节点到叶子节点定义了完整的 left-hand-side 的条件。每一个节点都保存满足这个 Pattern 的部分内存。
当一个新的 Fact 被插入或被修改时,会沿着网络传播,当满足 Pattern 时,标记节点。当一个 Fact 或者一组 Facts 满足所有 Patterns 是,就达到了叶子节点,对应的规则就被触发了。
RETE 算法设计用内存来换取执行时间。
规则
首先来看一下 Drools 的最简单的一条规则:
rule
when
Cheese( $chedddar : name == "cheddar" )
$person : Person( favouriteCheese == $cheddar )
then
System.out.println( $person.getName() + " likes cheddar" );
end
规则中可以看到 when-then 的结构,当满足 when 中的条件时,则执行 then 语句。
可以看到条件中有两个 Fact,分别是 Cheese 和 Person。
假设有两个 Fact,Person 和 Cheese。
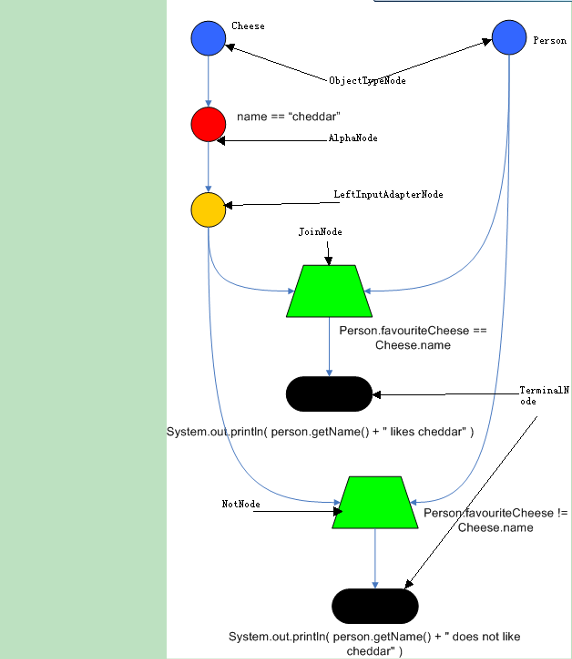
相关概念
- Fact 事实,通常是一个 Object,通常一个 Fact 会有很多对象的属性
- Rule 规则:条件和结果的推理语句,条件部分叫做 LHS(Left-hand-side),结果部分为 RHS(right-hand-side)。
- Pattern 模式:规则的条件部分
- RETE 网络:Drools 会根据规则在编译阶段构建一个 RETE 网络
Alpha Network
Alpha 网络形成一个 discrimination network,负责根据条件选择每一个独立的 WMEs。
在 discrimination network 中每一个 AlphaNode ( 1-input node)分支,
用非专业的术语来描述 discrimination network 就是一种当数据在其中传播的时候过滤数据的网络。在网络顶层的节点会有很多的匹配,当随着网络传播,会越来越少匹配。在网络的底部是 Terminal Nodes(结束节点),当走到这个节点意味着之前所有的 Pattern 都需要满足。
Alpha 网络,用来过滤 Fact,通过模式匹配找出事实集中所有符合模式的集合,Alpha 网络中包含 - ObjectTypeNode,类型节点,根节点的直接子节点,对象的类型 - Alpha Node,条件节点
Beta Network
Beta 网络则执行不同 WMEs 之间的 joins。这个网络中包含 2-input nodes(两个输入的节点)。每一个 Beta Node 都会将结果发送给 Beta Memory。
- Beta 网络,用于匹配规则,通过连接操作将模式集组合成匹配集,最终将匹配集转化为规则结果并执行,包含两类节点
- BetaNode 连接节点,接受条件节点的输入,将规则中关联的条件节点组合起来
- Terminal Node 终端节点,规则的 THEN 部分
RETE 网络中的节点
RETE 网络中的节点:
- RootNode,根节点,所有对象通过 RootNode 进入网络,虚拟节点,然后对象会立即进入 ObjectTypeNode
- ObjectTypeNode,对象类型节点,保证对应类型的对象才会进入,比如两个对象 Cheese 和 Person。为了保证效率,引擎只会将对象传递到符合对象类型的节点。ObjectTypeNode 会继续传播到 AlphaNode, LeftInputAdapterNodes, BetaNodes。
- AlphaNode 用来计算 Literal conditions,规则的条件部分的一个模式,一个对象只有和本节点匹配成功后,才能继续向下传播。在 1982 年的论文中,只提到了相等条件,当很多 RETE 实现了更多的操作。比如 Account.name == “Mr Trout”。
- 当一个单一对象有多个 literal conditions 条件的时候,会连接到一起,这意味着当插入一个对象 Account 时,必须先满足第一个条件,然后才会继续到第二个 AlphaNode。
- BetaNode 节点用于比较两个对象和它们的字段,两个对象可能是相同或不同的类型。我们将这两个输入称为左和右。BetaNode 的左输入通常是一组对象的数组。BetaNode 具有记忆功能。左边的输入被称为 Beta Memory,会记住所有到达过的语义。右边的输入成为 Alpha Memory,会记住所有到达过的对象。
- JoinNode,用作 join 节点, 相当于 and,属于 BetaNode 类型的节点。
- NotNode,exists 检查
- LeftInputAdapterNodes,当个对象转换和数组
- Terminal Nodes,表明一条规则已经匹配了它的所有条件
比如如下的 Alpha_Nodes 就表明是 Cheese( name =="cheddar", strength == "strong" )
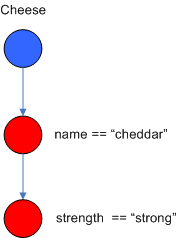
构建 RETE 网络
编译的结果是规则集对应的 RETE 网络,一个 Fact 可以流动的图。
- 创建根节点
- 加入一条规则 Account(name=”abc”, age>10)
- a. 取出规则中的一个模式,模式就是规则中最小的匹配项,比如 age > 10, age < 20 就是两个基本的模式,如果是新类型,加入一个 ObjectTypeNode 节点
- b. 检查模式对应的 AlphaNode 节点是否存在,如果存在则记录下节点位置,如果没有则将模式作为 Alpha 节点加入到网络,同时根据 Alpha 节点的模式建立 Alpha 内存表
- 重复 b 直到所有的模式处理完毕
- d. 组合 Beta 节点,按照: Beta 左输入节点为 Alpha(1),右输入节点为 Alpha(2),Beta(i)节点左输入节点为 Beta(i-1),右输入节点为 Alpha(i) ,并将两个父节点的内存表内联成自己的内存表
- e. 重复 d 直到所有的 Beta 节点处理完毕;
- f. 将动作 Then 部分,封装成叶节点(Action 节点)作为 Beta(n)的输出节点;
- 重复上面的步骤,添加规则,直到所有的规则处理完毕。
运行时执行
Working Memory Element,简称 WME,用于和非根节点代表的模式进行匹配的元素
当 facts 被插入到 Working Memory,引擎会为每一个 Fact 创建 Working memory elements(WMEs)。Facts 是一个 n 位元祖。
当 WME 从根节点进入 到 RETE 网络之后,根节点会将 WME 传到子节点中,然后每一个 WME 会通过网络传播下去,直到达到 Terminal Node。
1)如果 WME 的类型和根节点的后继结点 TypeNode(alpha 节点的一种)所指定的类型相同,则会将该事实保存在该 TypeNode 结点对应的 alpha 存储区中,该 WME 被传到后继结点继续匹配,否则会放弃该 WME 的后续匹配; 2)如果 WME 被传递到 alpha 节点,则会检测 WME 是否和该结点对应的模式相匹配,若匹配,则会将该事实保存在该 alpha 结点对应的存储区中,该 WME 被传递到后继结点继续匹配,否则会放弃该 WME 的后续匹配: 3)如果 WME 被传递到 beta 节点的右端,则会加入到该 beta 结点的 right 存储区,并和 left 存储区中的 Token 进行匹配(匹配动作根据 beta 结点的类型进行,例如:join,projection,selection),匹配成功,则会将该 WME 加入到 Token 中,然后将 Token 传递到下一个结点,否则会放弃该 WME 的后续匹配: 4)如果 Token 被传递到 beta 结点的左端,则会加入到该 beta 结点的 left 存储区,并和 right 存储区中的 WME 进行匹配(匹配动作根据 beta 结点的类型进行,例如:join,projection,selection),匹配成功,则该 Token 会封装匹配到的 WME 形成新的 Token,传递到下一个结点,否则会放弃该 Token 的后续匹配; 5)如果 WME 被传递到 beta 结点的左端,将 WME 封装成仅有一个 WME 元素的 WME 列表做为 Token,然后按照 4) 所示的方法进行匹配: 6)如果 Token 传递到 Terminal,则和该根结点对应的规则被激活,建立相应的 Activation,并存储到 Agenda 当中,等待激发。 7)如果 WME 被传递到 Terminal Node,将 WME 封装成仅有一个 WME 元素的 WME 列表做为 Token,然后按照 6) 所示的方法进行匹配;
特点和不足
特点:
- 启发式算法,不同规则间共享相同的模式,如果 BetaNode 被多个规则共享,会提高 N 倍
- 当事实集合变化不大时,保存在 Alpha 和 Beta 节点的状态不需要太多变化,避免了大量的重复计算,提高了匹配效率。
- RETE 匹配速度与规则数目无关,只有 Fact 满足本节点才会继续向下沿网络传递
不足:
- RETE 算法使用存储区存储已计算的中间结果,牺牲空间换取时间,加速系统的速度,存储区根据规则和事实成指数级增长,当规则和事实很多的时候,会耗尽系统资源。
建议:
- 容易变化的规则尽量后置,减少规则的变化带来的规则库变化
- 约束性通用或较强的模式尽量前置,避免不必要的匹配
- 针对 Rete 算法内存开销大和事实增加删除影响效率的问题,技术上应该在 alpha 内存和 beata 内存中,只存储指向内存的指针,并对指针建索引(可用 hash 表或者非平衡二叉树)。 d. Rete 算法 JoinNode 可以扩展为 AndJoinNode 和 OrJoinNode,两种节点可以再进行组合
一个 Python 实现的 RETE 算法
reference
- 《一种基于共享度模型的改进 Rete 算法》 孙新, 严西敏, 尚煜茗, 欧阳童, 董阔
使用 Beancount 记账篇二:各类账单导入
在上一篇如何给 Beancount 账户命名 的文章中,我们已经迈出了 Beancount 使用的第一步,建立一套属于自己的账户系统,之后所有的资金就会在这些账户之间流转。复式记账讲求账户的流入与流出。
那接下来就是 Beancount 真正关键的地方,熟悉并导入以前的帐本。使用 Beancount 就会想着如何将之前的账单导入到 Beancount。
但人的惰性总是让我们不会每一笔交易都事无巨细的记录下来,所以我的方式便是固定一个时间,然后对上一个周期内的账单进行一次性批量处理,比如在信用卡账单日对信用卡消费做处理,或者在月末对微信账单进行处理。
这样就使得我需要有地方可以直接导出我的账单,下面就是我经常使用的账单导出整理的方式。因为微信,京东等日常消费的账户绑定了信用卡,其中还涉及到了信用卡负债账户的部分,所以我的选择可以分成两个部分。一个就是从源头上,导出并处理信用卡账单,另一部分就是消费账户的账单,比如微信,京东的账单。
这两部分的优缺点都非常明显:
- 微信,京东的账单可以将账单的具体明细列举的非常清晰,而信用卡账单则比较简陋
- 但是信用卡账单可以方便地和 Liabilities 账户关联起来,而微信和京东则需要提取付款账户来进行判断,才能合理地将账单划分到账户
正因为这两个的区别,目前我还在混合使用这两个方法,不过以信用卡账单为主。
交行信用卡账单导入 Beancount
我目前主要使用的卡片是交通银行的,所以这里整理了一下交通银行账单的处理过程。不过大体思路都是相差不多的。
交通银行每个月的账单日都会发一份电子邮件到邮箱,在邮件中列出了记账周期中的消费记录,利用 Download table as csv 这个开源的 Chrome 插件,或者也可以使用 Table capture,可以将账单导出成 CSV 格式,然后用 vim 简单处理一下,比如把第一列删除,可以得到如下格式的文件:
"交易日期","记账日期","卡末四位","交易说明","交易金额","入账金额"
"2011/01/16","2011/01/17","2987","消费 支付宝 - xxx科技有限公司","RMB 6.30","RMB 6.30"
"2011/01/18","2011/01/19","2987","消费 支付宝 - xxx科技有限公司","RMB 0.90","RMB 0.90"
"2011/01/19","2011/01/20","2987","消费 食堂","RMB 100.00","RMB 100.00"
然后批量将金额中的 RMB 去掉。%s/RMB //g,然后保存到 datas/comm-2021.01.csv 文件中。随后执行:
export PYTHONPATH=.
bean-extract config.py datas/comm-2021.01.csv > beans/comm-2021.01.bean
只要 config.py 中设置的账户分类能够覆盖账单中的关键字,基本上就完工了。如果有些账单分入了错误的账户,那么手动的调整一下 config.py 再执行一次。
在文件夹 importers 中创建文件 beanmaker.py 填入如下内容:
"""CSV importer.
"""
import collections
import csv
import datetime
import enum
import io
import os
import re
from os import path
from typing import Union, Dict, Callable, Optional
import dateutil.parser
from beancount.core import data
from beancount.core.amount import Amount
from beancount.core.number import D
from beancount.core.number import ZERO
from beancount.ingest import importer
from beancount.utils.date_utils import parse_date_liberally
DEFAULT = "DEFAULT"
# The set of interpretable columns.
class Col(enum.Enum):
# The settlement date, the date we should create the posting at.
DATE = '[DATE]'
# The date at which the transaction took place.
TXN_DATE = '[TXN_DATE]'
# The time at which the transaction took place.
# Beancount does not support time field -- just add it to metadata.
TXN_TIME = '[TXN_TIME]'
# The payee field.
PAYEE = '[PAYEE]'
# The narration fields. Use multiple fields to combine them together.
NARRATION = NARRATION1 = '[NARRATION1]'
NARRATION2 = '[NARRATION2]'
REMARK = '[REMARK]'
# The amount being posted.
AMOUNT = '[AMOUNT]'
# Debits and credits being posted in separate, dedicated columns.
AMOUNT_DEBIT = '[DEBIT]'
AMOUNT_CREDIT = '[CREDIT]'
# The balance amount, after the row has posted.
BALANCE = '[BALANCE]'
# A field to use as a tag name.
TAG = '[TAG]'
# A column which says DEBIT or CREDIT (generally ignored).
DRCR = '[DRCR]'
# Last 4 digits of the card.
LAST4 = '[LAST4]'
# An account name.
ACCOUNT = '[ACCOUNT]'
# Transaction status
STATUS = '[STATUS]'
# Transcatin type.
TYPE = "[TYPE]"
# The set of status which says DEBIT or CREDIT
class Drcr(enum.Enum):
DEBIT = '[DEBIT]'
CREDIT = '[CREDIT]'
UNCERTAINTY = '[UNCERTAINTY]'
def cast_to_decimal(amount):
"""Cast the amount to either an instance of Decimal or None.
Args:
amount: A string of amount. The format may be '¥1,000.00', '5.20', '200'
Returns:
The corresponding Decimal of amount.
"""
if amount is None:
return None
amount = ''.join(amount.split(','))
numbers = re.findall(r"\d+\.?\d*", amount)
assert len(numbers) >= 1
return D(numbers[0])
def strip_blank(contents):
"""
strip the redundant blank in file contents.
"""
with io.StringIO(contents) as csvfile:
csvreader = csv.reader(csvfile, delimiter=",", quotechar='"')
rows = []
for row in csvreader:
rows.append(",".join(['"{}"'.format(x.strip()) for x in row]))
return "\n".join(rows)
def get_amounts(iconfig: Dict[Col, str], row, DRCR_status: Drcr,
allow_zero_amounts: bool = False):
"""Get the amount columns of a row.
Args:
iconfig: A dict of Col to row index.
row: A row array containing the values of the given row.
allow_zero_amounts: Is a transaction with amount D('0.00') okay? If not,
return (None, None).
Returns:
A pair of (debit-amount, credit-amount), both of which are either an
instance of Decimal or None, or not available.
"""
debit, credit = None, None
if Col.AMOUNT in iconfig:
amount = row[iconfig[Col.AMOUNT]]
# Distinguish debit or credit
if DRCR_status == Drcr.CREDIT:
credit = amount
else:
debit = amount
else:
debit, credit = [row[iconfig[col]] if col in iconfig else None
for col in [Col.AMOUNT_DEBIT, Col.AMOUNT_CREDIT]]
# If zero amounts aren't allowed, return null value.
is_zero_amount = (
(credit is not None and cast_to_decimal(credit) == ZERO) and
(debit is not None and cast_to_decimal(debit) == ZERO))
if not allow_zero_amounts and is_zero_amount:
return None, None
return (
-cast_to_decimal(debit) if debit else None,
cast_to_decimal(credit) if credit else None
)
def get_debit_or_credit_status(iconfig: [Col, str], row, DRCR_dict):
"""Get the status which says DEBIT or CREDIT of a row.
"""
try:
if Col.AMOUNT in iconfig:
DRCR = DRCR_dict[row[iconfig[Col.DRCR]]]
return DRCR
else:
if Col.AMOUNT_CREDIT in iconfig and row[iconfig[Col.AMOUNT_CREDIT]]:
return Drcr.CREDIT
elif Col.AMOUNT_DEBIT in iconfig and row[iconfig[Col.AMOUNT_DEBIT]]:
return Drcr.DEBIT
else:
return Drcr.UNCERTAINTY
except KeyError:
return Drcr.UNCERTAINTY
class Importer(importer.ImporterProtocol):
"""Importer for CSV files."""
def __init__(self,
config,
default_account,
currency,
file_name_prefix: str,
skip_lines: int = 0,
last4_map: Optional[Dict] = None,
categorizer: Optional[Callable] = None,
institution: Optional[str] = None,
debug: bool = False,
csv_dialect: Union[str, csv.Dialect] = 'excel',
dateutil_kwds: Optional[Dict] = None,
narration_sep: str = '; ',
close_flag: str = '',
DRCR_dict: Optional[Dict] = None,
assets_account: Optional[Dict] = None,
debit_account: Optional[Dict] = None,
credit_account: Optional[Dict] = None):
"""Constructor.
Args:
config: A dict of Col enum types to the names or indexes of the
columns.
default_account: An account string, the default account to post
this to.
currency: A currency string, the currency of this account.
skip_lines: Skip first x (garbage) lines of file.
last4_map: A dict that maps last 4 digits of the card to a friendly
string.
categorizer: A callable that attaches the other posting (usually
expenses) to a transaction with only single posting.
institution: An optional name of an institution to rename the files
to.
debug: Whether or not to print debug information.
dateutil_kwds: An optional dict defining the dateutil parser kwargs.
csv_dialect: A `csv` dialect given either as string or as instance
or subclass of `csv.Dialect`.
close_flag: A string show the garbage transaction from the STATUS
column.
DRCR_dict: An optional dict of Debit_or_credit.DEBIT or
Debit_or_credit.CREDIT to user-defined debit or credit string
occurs in the DRCR column. If DRCR column is revealed and
DRCR_dict is None, the status of trasaction will be uncertain.
assets_account: An optional dict of user-defined.
"""
assert isinstance(config, dict)
self.config = config
self.default_account = default_account
self.currency = currency
self.file_name_prefix = file_name_prefix
assert isinstance(skip_lines, int)
self.skip_lines = skip_lines
self.last4_map = last4_map or {}
self.debug = debug
self.dateutil_kwds = dateutil_kwds
self.csv_dialect = csv_dialect
self.narration_sep = narration_sep
self.close_flag = close_flag
# Reverse the key and value of the DRCR_dict.
self.DRCR_dict = dict(
zip(DRCR_dict.values(), DRCR_dict.keys())) if isinstance(DRCR_dict,
dict) else {}
self.assets_account = assets_account if isinstance(assets_account,
dict) else {}
self.debit_account = debit_account if isinstance(debit_account,
dict) else {}
self.credit_account = credit_account if isinstance(credit_account,
dict) else {}
if DEFAULT not in self.assets_account:
self.assets_account[DEFAULT] = self.default_account
if DEFAULT not in self.debit_account:
self.debit_account[DEFAULT] = self.default_account
if DEFAULT not in self.credit_account:
self.credit_account[DEFAULT] = self.default_account
# FIXME: This probably belongs to a mixin, not here.
self.institution = institution
self.categorizer = categorizer
def name(self):
"""Generate an importer name printed out.
This method provides a unique id for each importer instance. It’s
convenient to be able to refer to your importers with a unique name;
it gets printed out by the identification process, for instance.
Returns:
A name str.
"""
return '{}: "{}"'.format(super().name(), self.file_account(None))
def identify(self, file):
"""Whether the importer can handle the given file.
This method just returns true if this importer can handle the given
file. You must implement this method, and all the tools invoke it to
figure out the list of (file, importer) pairs. This function is used
by bean-identity and bean-extract tools.
Returns:
A bool to identity whether or not.
"""
if file.mimetype() != 'text/csv':
return False
if not os.path.basename(file.name).startswith(self.file_name_prefix):
return False
iconfig, has_header = normalize_config(self.config, file.head(-1),
self.skip_lines)
if len(iconfig) != len(self.config):
return False
return True
def file_account(self, _):
"""Provide the root account.
This method returns the root account associated with this importer.
This is where the downloaded file will be moved by the filing script.
This function is used by bean-file tool.
Returns:
A root acount name str.
"""
return self.default_account
def file_name(self, file):
"""Rename the given file.
It’s most convenient not to bother renaming downloaded files.
Oftentimes, the files generated from your bank either all have a
unique name and they end up getting renamed by your browser when you
download multiple ones and the names collide. This function is used
for the importer to provide a “nice” name to file the download under.
Returns:
A new file name str.
"""
filename = path.splitext(path.basename(file.name))[0]
if self.institution:
filename = '{}.{}'.format(self.institution, filename)
return '{}.csv'.format(filename)
def file_date(self, file):
"""Get the maximum date from the file.
If a date can be extracted from the statement’s contents, return it
here. This is useful for dated PDF statements… it’s often possible
using regular expressions to grep out the date from a PDF converted to
text. This allows the filing script to prepend a relevant date instead
of using the date when the file was downloaded (the default).
"""
iconfig, has_header = normalize_config(self.config, file.head(-1),
self.skip_lines)
if Col.DATE in iconfig:
reader = iter(csv.reader(open(file.name)))
for _ in range(self.skip_lines):
next(reader)
if has_header:
next(reader)
max_date = None
for row in reader:
if not row:
continue
if row[0].startswith('#'):
continue
date_str = row[iconfig[Col.DATE]]
date = parse_date_liberally(date_str, self.dateutil_kwds)
if max_date is None or date > max_date:
max_date = date
return max_date
def extract(self, file):
"""Parse and extract Beanount contents from the given file.
This is called to attempt to extract some Beancount directives from the
file contents. It must create the directives by instantiating the
objects defined in beancount.core.data and return them. This function
is used by bean-extract tool.
Returns:
A list of beancount.core.data object, and each of them can be
converted into a command-line accounting.
"""
entries = []
# Normalize the configuration to fetch by index.
iconfig, has_header = normalize_config(self.config, file.head(-1),
self.skip_lines)
reader = iter(csv.reader(open(file.name), dialect=self.csv_dialect))
# Skip garbage lines
for _ in range(self.skip_lines):
next(reader)
# Skip header, if one was detected.
if has_header:
next(reader)
def get(row, ftype):
try:
return row[iconfig[ftype]] if ftype in iconfig else None
except IndexError: # FIXME: this should not happen
return None
# Parse all the transactions.
first_row = last_row = None
for index, row in enumerate(reader, 1):
if not row:
continue
if row[0].startswith('#'):
continue
if row[0].startswith("-----------"):
break
# If debugging, print out the rows.
if self.debug:
print(row)
if first_row is None:
first_row = row
last_row = row
# Extract the data we need from the row, based on the configuration.
status = get(row, Col.STATUS)
# When the status is CLOSED, the transaction where money had not been paid should be ignored.
if isinstance(status, str) and status == self.close_flag:
continue
# Distinguish debit or credit
DRCR_status = get_debit_or_credit_status(iconfig, row,
self.DRCR_dict)
date = get(row, Col.DATE)
txn_date = get(row, Col.TXN_DATE)
txn_time = get(row, Col.TXN_TIME)
account = get(row, Col.ACCOUNT)
tx_type = get(row, Col.TYPE)
tx_type = tx_type or ""
payee = get(row, Col.PAYEE)
if payee:
payee = payee.strip()
fields = filter(None, [get(row, field)
for field in (Col.NARRATION1,
Col.NARRATION2)])
narration = self.narration_sep.join(
field.strip() for field in fields)
remark = get(row, Col.REMARK)
tag = get(row, Col.TAG)
tags = {tag} if tag is not None else data.EMPTY_SET
last4 = get(row, Col.LAST4)
balance = get(row, Col.BALANCE)
# Create a transaction
meta = data.new_metadata(file.name, index)
if txn_date is not None:
meta['date'] = parse_date_liberally(txn_date,
self.dateutil_kwds)
if txn_time is not None:
meta['time'] = str(dateutil.parser.parse(txn_time).time())
if balance is not None:
meta['balance'] = D(balance)
if last4:
last4_friendly = self.last4_map.get(last4.strip())
meta['card'] = last4_friendly if last4_friendly else last4
date = parse_date_liberally(date, self.dateutil_kwds)
# flag = flags.FLAG_WARNING if DRCR_status == Debit_or_credit.UNCERTAINTY else self.FLAG
txn = data.Transaction(
meta,
date,
self.FLAG,
payee,
"{}({})".format(narration, remark),
tags,
data.EMPTY_SET,
[]
)
# Attach one posting to the transaction
amount_debit, amount_credit = get_amounts(iconfig, row, DRCR_status)
# Skip empty transactions
if amount_debit is None and amount_credit is None:
continue
for amount in [amount_debit, amount_credit]:
if amount is None:
continue
units = Amount(amount, self.currency)
# Uncertain transaction, maybe capital turnover
if DRCR_status == Drcr.UNCERTAINTY:
if remark and len(remark.split("-")) == 2:
remarks = remark.split("-")
primary_account = mapping_account(self.assets_account,
remarks[1])
secondary_account = mapping_account(self.assets_account,
remarks[0])
txn.postings.append(
data.Posting(primary_account, -units, None, None,
None, None))
txn.postings.append(
data.Posting(secondary_account, None, None, None,
None, None))
else:
txn.postings.append(
data.Posting(self.default_account, units, None,
None, None, None))
# Debit or Credit transaction
else:
# Primary posting
# Rename primary account if remark field matches one of assets account
primary_account = mapping_account(self.assets_account,
remark)
txn.postings.append(
data.Posting(primary_account, units, None, None, None,
None))
# Secondary posting
# Rename secondary account by credit account or debit account based on DRCR status
payee_narration = payee + narration
_account = self.credit_account if DRCR_status == Drcr.CREDIT else self.debit_account
secondary_account = mapping_account(_account,
payee_narration)
# secondary_account = _account[DEFAULT]
# for key in _account.keys():
# if key == DEFAULT:
# continue
# if re.search(key, payee_narration):
# secondary_account = _account[key]
# break
txn.postings.append(
data.Posting(secondary_account, None, None, None, None,
None))
# Attach the other posting(s) to the transaction.
if isinstance(self.categorizer, collections.Callable):
txn = self.categorizer(txn)
# Add the transaction to the output list
entries.append(txn)
# Figure out if the file is in ascending or descending order.
first_date = parse_date_liberally(get(first_row, Col.DATE),
self.dateutil_kwds)
last_date = parse_date_liberally(get(last_row, Col.DATE),
self.dateutil_kwds)
is_ascending = first_date < last_date
# Reverse the list if the file is in descending order
if not is_ascending:
entries = list(reversed(entries))
# Add a balance entry if possible
if Col.BALANCE in iconfig and entries:
entry = entries[-1]
date = entry.date + datetime.timedelta(days=1)
balance = entry.meta.get('balance', None)
if balance:
meta = data.new_metadata(file.name, index)
entries.append(
data.Balance(meta, date,
self.default_account,
Amount(balance, self.currency),
None, None))
# Remove the 'balance' metadta.
for entry in entries:
entry.meta.pop('balance', None)
return entries
def normalize_config(config, head, skip_lines: int = 0):
"""Using the header line, convert the configuration field name lookups to int indexes.
Args:
config: A dict of Col types to string or indexes.
head: A string, some decent number of bytes of the head of the file.
skip_lines: Skip first x (garbage) lines of file.
Returns:
A pair of
A dict of Col types to integer indexes of the fields, and
a boolean, true if the file has a header.
Raises:
ValueError: If there is no header and the configuration does not consist
entirely of integer indexes.
"""
assert isinstance(skip_lines, int)
assert skip_lines >= 0
for _ in range(skip_lines):
head = head[head.find("\n") + 1:]
strip_blank(head)
has_header = csv.Sniffer().has_header(head)
if has_header:
header = next(csv.reader(io.StringIO(head)))
field_map = {field_name.strip(): index
for index, field_name in enumerate(header)}
index_config = {}
for field_type, field in config.items():
if isinstance(field, str):
try:
field = field_map[field]
except KeyError as e:
print(e)
break
index_config[field_type] = field
else:
if any(not isinstance(field, int)
for field_type, field in config.items()):
raise ValueError("CSV config without header has non-index fields: "
"{}".format(config))
index_config = config
return index_config, has_header
def mapping_account(account_map, keyword):
"""Finding which key of account_map contains the keyword, return the corresponding value.
Args:
account_map: A dict of account keywords string (each keyword separated by "|") to account name.
keyword: A keyword string.
Return:
An account name string.
Raises:
KeyError: If "DEFAULT" keyword is not in account_map.
"""
if DEFAULT not in account_map:
raise KeyError("DEFAULT is not in " + account_map.__str__)
account_name = account_map[DEFAULT]
for account_keywords in account_map.keys():
if account_keywords == DEFAULT:
continue
if re.search(account_keywords, keyword):
account_name = account_map[account_keywords]
break
return account_name
然后创建 config.py 如下:
#!/usr/bin/env python3
import sys
from beancount.core.data import Transaction
sys.path.append("./importers")
from importers.beanmaker import Drcr, Col, Importer
# Col为枚举类型,预定义了每笔交易记录所需要的内容,_config_alipay负责定义枚举内容与csv表头之间的对应关系
_config_alipay = {
Col.DATE: "交易创建时间",
Col.PAYEE: "交易对方",
Col.NARRATION: "商品名称",
Col.REMARK: "备注",
Col.AMOUNT: "金额(元)",
Col.DRCR: "收/支",
Col.STATUS: "资金状态",
Col.TXN_TIME: "交易创建时间",
Col.TXN_DATE: "交易创建时间",
Col.TYPE: "类型",
}
_config_wechat = {
Col.DATE: "交易时间",
Col.PAYEE: "交易对方",
Col.NARRATION: "商品",
Col.REMARK: "支付方式",
Col.AMOUNT: "金额(元)",
Col.DRCR: "收/支",
Col.STATUS: "当前状态",
Col.TXN_TIME: "交易时间",
Col.TXN_DATE: "交易时间",
Col.TYPE: "交易类型",
}
# _default_account负责定义默认账户
_default_account_alipay = "Assets:Alipay:Balance"
_default_account_wechat = "Assets:WeChat:Balance"
_default_account_comm = "Liabilities:CreditCard:BOC:CN"
# _currency定义货币单位
_currency = "CNY"
# Debit_or_credit也是枚举类型,预定义了支出和收入两类,_DRCR_dict负责定义这两类与csv中能够表明该状态的文本之间的对应关系
_DRCR_dict = {
Drcr.DEBIT: "支出",
Drcr.CREDIT: "收入"
}
common_assets_account = {
"交通银行|2222": "Liabilities:CreditCard:BOC"
}
# _assets_account负责保存账户信息,key为手工对账时在备注中输入的关键词;
# 关键词中,"DEFAULT"为非必选项,不提供时将以"_default_account_xxx"的属性值作为"DEFAULT"对应的值;
# 多个关键词用竖线分割,只要备注中出现该关键词,就把该交易分类到对应账户下。
_wechat_assets_account = {
"DEFAULT": "Assets:WeChat:Balance",
"招行信用卡|0000": "Liabilities:CreditCard:CMB",
"招商银行": "Assets:DebitCard:CMB",
"交通信用卡银行|2222": "Liabilities:CreditCard:BOC:CN",
"中信银行": "Liabilities:CreditCard:CITIC",
"汇丰银行": "Liabilities:CreditCard:HSBC:CN",
"支付宝": "Assets:VirtualCard:Alipay",
"余额宝": "Assets:MoneyFund:Yuebao",
"零钱|微信": "Assets:WeChat:Balance"
}
_wechat_assets_account.update(common_assets_account)
# _debit_account负责保存支出账户信息,key为与该账户相关的关键词;
# 关键词中,"DEFAULT"为非必选项,不提供时将以"_default_account_xxx"的属性值作为"DEFAULT"对应的值;
# 多个关键词用竖线分割,只要当交易为“支出”,且交易对方名称和商品名称中出现该关键词,就把该交易分类为对应支出。
_debit_account = {
"DEFAULT": "Expenses:Food:Other",
"iCloud|腾讯云|阿里云|Plex": "Expenses:Fun:Subscription",
"滴滴|司机": "Expenses:Transport:Taxi",
"天和亿|单车": "Expenses:Transport:Bike",
"中国铁路": "Expenses:Transport:Railway",
"卡表充值|燃气": "Expenses:House:Gas",
"友宝|芬达|雪碧|可乐|送水|怡宝|饮料|美年达|售货机": "Expenses:Food:Drinks",
"水果": "Expenses:Food:Fruits",
"买菜|叮咚|美团买菜": "Expenses:Food:Cooking",
"泰餐": "Expenses:Food:Restaurant",
"App Store|Steam|会员": "Expenses:Fun:Software",
"全时|华联|家乐福|超市|红旗|WOWO|百货|伊藤|永旺|全家": "Expenses:Daily:Commodity",
"汽车票|蒜芽信息科技|优步|火车|动车|空铁无忧网|滴滴|汽车|运输|机场|航空|机票|高铁|出行|车费|打车": "Expenses:Travel",
"捐赠": "Expenses:PublicWelfare",
"话费|流量|手机|中国移动": "Expenses:Daily:PhoneCharge",
"电影|大麦网|演出|淘票票": "Expenses:Fun:Amusement",
"地铁|轨道交通": "Expenses:Transport:Public",
"青桔|骑安": "Expenses:Transport:Bike",
"衣|裤|鞋": "Expenses:Dressup:Clothing",
"造型|美发|理发": "Expenses:Dressup:Hair",
"化妆品": "Expenses:Dressup:Cosmetic",
"医院|药房": "Expenses:Health:Hospital",
"酒店|airbnb": "Expenses:Travel:Hotel",
"机票|高铁|票务|特快|火车票|飞机票": "Expenses:Travel:Fare",
"借款": "Assets:Receivables",
"蚂蚁财富": "Assets:MoneyFund:BondFund",
'签证': "Expenses:Travel:Visa",
"门票": "Expenses:Travel:Ticket",
"gopro|键盘|电脑|手机|SD卡|相机|MacBook|boox|ipad|apple|oneplus": "Expenses:Digital",
"快递": "Expenses:Daily",
'PLAYSTATION': "Expenses:Fun:Game",
}
# _credit_account负责保存收入账户信息,key为与该账户相关的关键词
# 关键词中,"DEFAULT"为非必选项,不提供时将以"_default_account_xxx"的属性值作为"DEFAULT"对应的值;
# 多个关键词用竖线分割,只要当交易为“收入”,且交易对方名称和商品名称中出现该关键词,就把该交易分类为对应收入。
_credit_account = {"DEFAULT": "Income:RedPacket", "借款": "Assets:Receivables"}
wechat_config = Importer(
config=_config_wechat,
default_account=_default_account_wechat,
currency=_currency,
file_name_prefix='微信支付账单',
skip_lines=0,
DRCR_dict=_DRCR_dict,
assets_account=_wechat_assets_account,
debit_account=_debit_account,
credit_account=_credit_account
)
_alipay_assets_account = {
"DEFAULT": "Assets:Alipay:Balance",
"花呗": "Liabilities:VirtualCard:Huabei",
}
_alipay_assets_account.update(common_assets_account)
alipay_config = Importer(
config=_config_alipay,
default_account=_default_account_alipay,
currency=_currency,
file_name_prefix='alipay_record',
skip_lines=0,
DRCR_dict=_DRCR_dict,
assets_account=_alipay_assets_account,
debit_account=_debit_account,
credit_account=_credit_account
)
_comm_assets_account = {
"DEFAULT": "Liabilities:CreditCard:BOC:CN"
}
_comm_assets_account.update(common_assets_account)
from beancount.ingest.importers import csv
# 信用卡
_config_com = {
csv.Col.DATE: "记账日期",
csv.Col.PAYEE: "交易说明",
csv.Col.NARRATION: "交易说明",
csv.Col.AMOUNT_DEBIT: "交易金额",
csv.Col.TXN_DATE: "交易日期",
csv.Col.LAST4: "卡末四位",
}
def comm_categorizer(txn: Transaction):
# At this time the txn has only one posting
try:
posting1 = txn.postings[0]
except IndexError:
return txn
from importers.beanmaker import mapping_account
account_name = mapping_account(_debit_account, txn.narration)
posting2 = posting1._replace(
account=account_name,
units=-posting1.units
)
# Insert / Append the posting into the transaction
if posting1.units < posting2.units:
txn.postings.append(posting2)
else:
txn.postings.insert(0, posting2)
return txn
comm_config = csv.Importer(
config=_config_com,
account=_default_account_comm,
currency=_currency,
last4_map={"2222": "优逸白"},
categorizer=comm_categorizer
)
CONFIG = [
wechat_config,
alipay_config,
comm_config,
]
文件结构:
├── README.md
├── account
│ ├── assets.bean
│ ├── crypto.bean
│ ├── equity.bean
│ ├── expenses.bean
│ ├── income.bean
│ ├── liabilities.bean
│ ├── securities.bean
│ └── vesting.bean
├── beans
│ ├── 2020.bean
│ ├── 2021
│ │ ├── 01.bean
│ │ ├── 02.bean
│ │ ├── 03.bean
│ │ └── 04.bean
│ ├── 2021.bean
│ ├── alipay_record_20190101_20191231.bean
│ ├── alipay_record_20200101_20201231.bean
│ ├── assets-broker.bean
│ ├── comm-2021.01.bean
│ ├── comm-2021.02.bean
│ ├── comm-2021.03.bean
│ ├── 微信支付账单(20200701-20200930).bean
│ └── 微信支付账单(20201001-20201231).bean
├── config.py
├── datas
│ ├── alipay_record_20190101_20191231.csv
│ ├── alipay_record_20200101_20201231.csv
│ ├── comm-2021.01.csv
│ ├── comm-2021.02.csv
│ ├── comm-2021.03.csv
│ ├── 微信支付账单(20200701-20200930).csv
│ └── 微信支付账单(20201001-20201231).csv
├── importers
│ └── beanmaker.py
├── main.bean
├── processing.sh
├── requirements.txt
└── strip_blank.py
其中,account 目录是定义了各类的账户,下面的账单整理主要涉及的目录是 datas 和 beans 目录。我将账单的原始文件放在 datas 目录中,而 beans 则存放处理过后的 bean 文件。
微信账单的导入 Beancount
微信的账单可以通过,钱包 -> 账单 -> 常见问题 -> 账单下载导出,但是需要注意的是,每次导出只能跨 3 个月。导出的账单会发送到邮箱中。账单格式是 CSV。在邮件附件中下载的压缩包需要密码,解压的密码会通过官方的账号发送到微信通知。
解压之后会得到如下格式的文件:
微信支付账单明细,,,,,,,,
微信昵称:[xxx],,,,,,,,
起始时间:[2018-01-01 00:00:00] 终止时间:[2018-03-31 23:59:59],,,,,,,,
导出类型:[全部],,,,,,,,
导出时间:[2020-02-28 12:59:49],,,,,,,,
,,,,,,,,
共207笔记录,,,,,,,,
收入:137笔 xxxx.34元,,,,,,,,
支出:66笔 xxxx.60元,,,,,,,,
中性交易:4笔 xxxx.13元,,,,,,,,
注:,,,,,,,,
1. 充值/提现/理财通购买/零钱通存取/信用卡还款等交易,将计入中性交易,,,,,,,,
2. 本明细仅展示当前账单中的交易,不包括已删除的记录,,,,,,,,
3. 本明细仅供个人对账使用,,,,,,,,
,,,,,,,,
----------------------微信支付账单明细列表--------------------,,,,,,,,
交易时间,交易类型,交易对方,商品,收/支,金额(元),支付方式,当前状态,交易单号,商户单号,备注
2018-03-31 21:35:09,微信红包,/,"/",支出,¥100.00,零钱,支付成功,1000039501180331000xxxxxxxxxxxxxxxxx ,10000395012018033xxxxxxxxxxxxxx ,"/"
可以看到前16行都是一些注释信息,并不是正式的交易数据。真正的交易数据从 17 行开始。有这样一份数据就可以使用脚本到入成 Beancount 文件。
Vim 下将文件格式转换成 UTF-8 避免不必要的麻烦:
:set fileencoding=utf-8
:w
支付宝账单的导入 Beancount
支付宝的账单可以通过网页端,在我的账单页面选择时间范围,单次跨度不能超过 1 年,然后在页面底部点击「下载查询结果」,导出的格式为 CSV 格式。
支付宝交易记录明细查询
账号:[xxxxxxxx@xxxxx.com]
起始日期:[2019-01-01 00:00:00] 终止日期:[2020-01-01 00:00:00]
---------------------------------交易记录明细列表------------------------------------
交易号 ,商家订单号 ,交易创建时间 ,付款时间 ,最近修改时间 ,交易来源地 ,类型 ,交易对方 ,商品名称 ,金额(元) ,收/支 ,交易状态 ,服务费(元) ,成功退款(元) ,备注 ,资金状态 ,
2019123122001456xxxxxxxxxxxx ,M201912317xxxxxxx ,2019-12-31 13:26:28 ,2019-12-31 13:26:29 ,2019-12-31 13:26:29 ,其他(包括阿里巴巴和外部商家),即时到账交易 ,中国铁路网络有限公司 ,火车票 ,493.50 ,支出 ,交易成功 ,0.00 ,0.00 , ,已支出 ,
20191231343073829431 , ,2019-12-31 05:39:17 , ,2019-12-31 05:39:17 ,支付宝网站 ,即时到账交易 ,博时基金管理有限公司 ,余额宝-2019.12.30-收益发放 ,2.83 , ,交易成功 ,0.00 ,0.00 , ,已收入 ,
京东账单导出及导入 Beancount
京东不提供历史交易记录的导出,这就使得我们得从京东后台的我的订单中手动的将账单导出。
受到 zsxsoft 使用 userscript 脚本的启发。经过一定的修改
到订单页面直接在浏览器自动生成 Beancount,粘贴即可。
reference
使用 Beancount 记账篇一:给账户命名
在之前整理复式记账 的文章中曾短暂的提及过 Beancount,上一篇文章简单介绍了一下 Beancount,现在经过一段时间的使用,也正好回顾总结一下自己的使用经历和经验。
要入门 Beancount 的使用,其中最重要的第一步便是充分的认识 Beancount 中的账户概念,在复式记账中资金都是在账户与账户之间流转,因此账户就非常重要。但是因为 Beancount 的入门难度要远远超过其他的记账软件,所以迈出第一步就变得至关重要,迈出了这第一步后面就会发现 Beancount 能带来远超预期的收益。
在 Beancount 中内置类几类账户,这几类账户会用来生成最后的 [[资产损益表]]、[[资产负债表]] 等等报表。这几类账户在之前的文章中也提及过:
- Assets
- Income
- Expense
- Liabilities
- Equity
在 fava 展示损益表的时候会使用到 Income 和 Expense,而在展示负债表的时候会用到 Assets, Liabilities 和 Equity。
文件组织
在构建了一个完整的命名体系之前,可以先对 Beancount 帐本进行提前的规划。比如我以如下的方式管理:
├── account
│ ├── assets.bean
│ ├── equity.bean
│ ├── expenses.bean
│ ├── income.bean
│ ├── liabilities.bean
├── beans
│ ├── 2020.bean
│ ├── 2021
│ │ ├── 01.bean
│ │ ├── 02.bean
│ │ ├── 03.bean
│ │ └── 04.bean
│ ├── 微信\224\230账\215\225(20200701-20200930).bean
│ └── 微信\224\230账\215\225(20201001-20201231).bean
├── config.py
├── datas
│ ├── 微信\224\230账\215\225(20200701-20200930).csv
│ └── 微信\224\230账\215\225(20201001-20201231).csv
├── importers
│ └── beanmaker.py
├── main.bean
├── processing.sh
├── requirements.txt
说明:
- account 账户中只定义
open和close账户的语句,不同的名字命名的账户分开管理 - beans 目录中是真正记录交易的地方
- datas 目录则是账单的原始数据
main.bean主帐本的定义processing.sh以及importers是处理原始账单数据的脚本
在 main.bean 中通过 include 语法将其他 bean 引入,同时还定义了一些可选项。
option "title" "ledger" ; "我的账本" ledger
option "operating_currency" "CNY" ; 帐本货币
option "operating_currency" "USD"
; fava
2016-04-14 custom "fava-option" "auto-reload" "true"
include "account/*.bean"
include "beans/*.bean"
剩下的其他几个文件一个是配置从原始账单自动生成对应 bean,以及提前预处理账单的脚本 processing.sh,这部分内容会在后续介绍多个类型账单导入的文章中介绍。
当然你并不需要按照这样的方式来管理,Beancount 完全支持在一个文件中记录所有的内容,就像这个演示 那样。
给 Assets 账户命名
对于个人而言,如果用最通俗的语言来解释 Assets 的话,「那就是你所拥有的资产」,这个资产包括现金,银行的存款,证券市场上的股票等等能够产生购买力的,或者能够用来清还债务的东西。
对于国内的场景,可能还会有账户叫做支付宝余额,或者微信零钱。那么有这样的概念之后就可以轻松的定义出这样的账户。
; 现金
2010-11-11 open Assets:Cash
; 支付宝
2015-11-11 open Assets:Alipay:Balance ;"余额"
; 微信余额
2010-01-01 open Assets:WeChat:Balance
; 老虎证券
2018-06-01 open Assets:Broker:US:Tiger
; 银行账户来
2010-11-11 open Assets:DebitCard:CMB CNY
去除上面这些比较好理解的实体账户,还有一类虚拟账户,比方说借钱给了张三 10000 元,那么就应该开一个「应收款」账户:
; 欠的钱
2000-01-01 open Assets:Receivables:Zhangsan CNY
记录一笔交易
2000-03-09 * "借钱给张三 100000"
Assets:Receivables:Zhangsan 10000 CNY
Assets:DebitCard:CMB -10000 CNY
等张三将钱归还,就可以将此账户关闭:
2001-01-01 close Assets:Receivables:Zhangsan
但是如果要去通过 Beancount 来记录证券交易,那么便会稍微复杂一些。之后会再写新的文章进行总结。
给 Income 账户命名
收入账户也比较好理解,有多少收入便开通多少个收入账户。一般来说如果是月工资则会按序进入上面开的银行账户。如果年终有奖励则还会开一个 Bonus 的账户。
2010-11-11 open Income:Salary:Hooli CNY ; "Regular Pay"
2010-11-11 open Income:Bonus:Hooli CNY ; "Annual bonus"
对于普通的收入账户比较明确,但是如果要记录比如未成熟的期权,股票等,则就稍微复杂一些,之后再用其他文章说明。
给 Expense 账户命名
开支账户是一个相对比较繁琐的账户,但理念非常容易理解。在普通的记账软件中,一般会对消费进行分类,那么就可以根据自己的真实情况将这一个分类搬到 Beancount 的 Expense 账户中。
如果之前没有使用过类似的记账软件,那么大概也会知道可能有那么几类,衣、食、住、行。日常生活的开支基本上这几大类也都覆盖了,其他的开支账户可以等用到的时候再建立。
可以来参考一下其他软件的账户分类。
对于开支账户,不建议设置很多,但也不建议设置得比较笼统,需要自己把握那个度。开设很多账户在记账的时候就会需要花费很多时间思考一笔交易被划分到哪个账户;而设置的比较少的时候,后期进行统计的时候就没有区分度。
在创建账户的时候也可以参考一些市面上成熟的应用的内置分类。
之前用过的一个叫做 Wallet 的应用的内部账户分类。
Food & Drinks
Bar, cafe
Groceries
Restaurant, fast-food
Shopping
Clothes & shoes
Drug-store chemist
Gifts
Jewels
Pets
Stationery
Housing
Energy
Maintenance
Mortgage
Property insurance
Rent
Services
Transportation
Business trips
Long distance
Public transport
Taxi
Vehicle
Fuel
Leasing
Parking
Rentals
Vehicle insurance
Vehicle maintenance
Life & Entertainment
Sport
fitness
Alcohol
Book, audio, subscriptions
Charity
Wellness
Communication
Internet
Phone
Postal Services
Software
再比如 MoneyWiz 默认账户名
Automobile
Accessories
Car Insurance
Gas/Fuel
Lease
Maintenance
Other
Parking
Bills
Cable
Electricity
Gas
Internet/Broadband
Mobile Phone
Other
Phone
Water
Clothing
Accessories
Clothes
Jewelry
Other
Shoes
Digital
Apps
Books
Movies
Music
Other
Podcasts
TV Shows
Food & Dining
Dining/Eating Out
Groceries
Other
Health Care
Dental
Eye Care
Health Insurance
Medical
Other
Pharmacy
Housing
Furniture/Accessories
Home Insurance
Maintenance
Mortgage
Other
Rent
Leisure
Entertainment
Fitness/Sport
Other
Personal Care
Loans
Other
Taxes
Transportation
Travel
当然我觉得个人没有必要划分的这么细,可以在使用的过程中再逐步增加分类。
; 衣、鞋
2010-01-01 open Expenses:Dressup:Clothing
; 食
2010-01-01 open Expenses:Food:Drinks ;"饮料"
2010-01-01 open Expenses:Food:Fruits ;"水果"
; 住
2010-11-11 open Expenses:House:Rent ; 房租
2010-11-11 open Expenses:House:WaterElectricity ; 水费、电费
2010-01-01 open Expenses:House:Gas ;"燃气"
; 行
2010-11-11 open Expenses:Transport:Public
2010-11-11 open Expenses:Transport:Taxi
; other
2010-01-01 open Expenses:Digital
开支分类这个事情也可以做的比较智能一些,比如通过学习,自动进行分类。
不过我个人还是觉得通过关键字自动进行开支账户的导入还是足够精确的。
给 Liabilities 账户命名
最常见的负债账户就是信用卡了,可以将开卡的时间以及开卡的银行记录下来。以后按月整理信用卡账单就会方便很多。
如果涉及到房贷等等,其实是差不多的。
比如开通一个交通银行信用卡的账户:
2010-11-11 open Liabilities:CreditCard:BOC CNY
和之前一样,在处理借款的时候,也可以用账户来追踪:
; 欠钱
2000-01-01 open Liabilities:Payables:Zhangsan CNY
Beancount 这样的纯文本记账工具,对于账户开通和关闭处理几乎没有成本,可以任性地添加账户。
命令规范
命名规范可以简化理解的成本,和代码规范一样,帐本被阅读的次数肯定要比记录的时候要多,尤其是当帐本越来越复杂的时候。一套有机完整的命名不仅可以让记账更人性化,也可以免去之后再去频繁修改账户名字的烦恼。
个人为 Beancount 的账户命名应该要遵守几点:
- 账户名要尽量详细,但不应该太长,个人使用的习惯一般不会超过 3 级目录。
- 帐户名有大到小整理,在 fava 界面中,多级账户会进行归类求和,可以清晰地看到上一级账户的总额
- 在初始开通账户的时候尽量采用详细的多级账户,在未来合并账户的操作可以通过替换完成,但是拆分账户的操作则需要一一核对
- 降低记账的认知负担,在确定好帐户名之后尽量可以通过直觉直接确定应该归属到哪一类账户。
附录
mint-categories
mint-categories https://www.mint.com/mint-categories
Expenses (all types)
1. Rent/Mortgage
a. Home Owners Association Dues
b. Rental Insurance
c. Home Owners Insurance
2. Fixed Expenses
a. Utilities
b. Gas
c. Electric
d. Water/Trash/Sewer
e. Cable/Internet/Phone
f. Cell Phone
g. Credit Cards
h. Car Expenses
i. Maintenance
j. Gas
3. Extra Expenses
a. Grocery (Food)
b. Clothes/Shoes/Hygiene
c. Extra for Home Expenses
4. Savings
a. Savings Account. Speak with employer; some saving plans can pull from paycheck before taxes. That means less of your paycheck is taxable.
b. Create an Emergency Fund; it should be at least 6 months of expenses. Emergencies can happen and drain a well-established savings account
5. Taxes
a. No explanation needed
6. Fun Cash
a. Out with friends
b. Movies
c. Vacations
GnuCash
Adjustment
Auto
Fees
Gas
Parking
Repair and Maintenance
Bank Service Charge
Books
Cable
Charity
Clothes
Computer
Dining
Education
Entertainment
Music/Movies
Recreation
Travel
Gifts
Groceries
Hobbies
Insurance
Auto Insurance
Health Insurance
Life Insurance
Laundry/Dry Cleaning
Medical Expenses
Miscellaneous
Online Services
Phone
Public Transportation
Subscriptions
Supplies
Taxes
Federal
Medicare
Other Tax
Social Security
State/Province
Utilities
Electric
Garbage collection
Gas
Water
其他模板
reference
如何进行有效的讨论 论 Clubhouse
这两天 Clubhouse 非常火热,又使得「声音」这一载体被放到了台前,但听了多个 Room,并没有收获太多,反而是相对较大的「杂音」影响了收听,并且大部分的观点并没有让人眼前一亮的感觉。
而从去年读[[洛克]], [[密尔]]开始,我就在思考什么叫做「有效讨论」,这些先贤们在写下他们流传百世的著作之前,当然有其自身深入地思考,但也绝不是将自己关在小黑屋与世隔绝而诞生了其思想,往往在他们形成自己的思想之前,他们会阅读大量比他们时代更早的作品,也会与他们同时代的伟大思想家进行书信,甚至直接的交流。在这样的思辩和讨论之中,他们最终才会形成自己的思想,这些伟大的思想有可能是他们首先提出,但有会有部分在修正以前思想的问题。但无论这些思想对与否,他们都以自己深入的思考给出了他们自己认为的答案,我想或许这就是一种值得我们学习的方式。伟大的思想家都有自知,每个时代都有许多被后世认为错误而且荒谬的看法,但经过讨论,错误的意见和行为就会逐渐屈从事实和论证。
有效讨论
有效的讨论一定是有主题的
讨论的中心一定是要有的,不管这个主题是什么,一定要约束一次讨论不会偏离这个主题,直到满足下一个条件,也就是得出一定的结论,才可以转换主题。
比如可以聊创业,可以聊技术,可以聊哲学,可以聊某某地方的吃喝,而从这些主题中可以延伸出非常多的内容,有讨论就必然会有讨论的组织者,讨论的组织者可以参与讨论,也可以不参与,但是要将讨论的主题限定在这个范围内,一旦偏离主题就要及时地将话题来回来。Clubhouse 中的 moderator 就是这样的角色。
有主题的讨论一方面保证了话题的可持续性,可以产生源源不断的新内容,另一方面也使得听众可以迅速地抓住话题重点,从而判断是继续听,还是进一步地参与到讨论中。
有效的讨论至少要有结论
有效的讨论一定需要结论。不管这个结论是否是最后的真理,也需要达成最大部分人的共识。
有人可能会反驳,比如一次哲学思辩,一次课堂讨论,可能并不会有真正的结果,比如《公正课》中讨论的著名的电车难题,虽然讨论的过程是双方,甚至多方对立的,但是在讨论的过程中,一定会形成一种思考的方式,那这就是这次讨论的目的,比如《公正课》中,学生的目的便是为了学习,更进一步地说可以是学习认识世界的一种方式。
回想美国建国之初,即使分歧那么大,即使十三个州相互不同意各自的方法,但在 [[詹姆斯 麦迪逊]]、[[亚历山大·汉密尔顿]] 等等先辈的 [[联邦党人文集]] 中通过几十篇理性的论证说服大部分人认同联邦要比各州各自为政要好。并在之后的立宪会议上在多方博弈后终于指定下,切实可行的制度。虽然这个「结论」并不一定是最后的真理,但是所有人应该按照约定,或者说按照「契约」去履行。我们站到今天来回看美国的宪法,当然是有问题,黑人、妇女的权利就没有考虑到宪法内,但这不影响暂时性的结论,如果喋喋不休争论200年,那将会一事无成。而一旦确立了一部切实可行的宪法,那么可以在这个基础之上对其进行修正,可以看到[[宪法第十五修正案]]、[[宪法第十九修正案]]分别赋予了黑人及女人以选举的权利。
再回到武汉肺炎和 COVID-19 的分歧,有一天在海峡两岸的 Room 中听到有人在论证,在开始传播的时候通过地名加上病毒名,简单易懂,但是在全球达成共识之后,更名为 COVID-19,这个时候为了统一最后的结论就应该沿用正式的命名。但与此同时,在这个共同体内的成员,就不能再称呼现在以及未来新诞生的病毒的名字为地名加病毒名。因为讨论的结果是,当我们给病毒命名的时候,尽管过去我们都犯过错误,但是现在以及未来,共识是:
- 不再针对个别的宗教(中东呼吸道综合征)
- 不再针对特定的群体(武汉肺炎、西班牙大流感)
- 不再制造不合理的旅游、商务和贸易屏障
- 以及触发不必要的动物宰杀(猪流感)
对于这样的讨论或许我们一方面需要反思自己,难道不是大陆在描述日本人的时候称为鬼子,称韩国人为棒子的时候就已经犯下错误。而现在即使对岸再去说武汉肺炎其实也无可厚非,我在上面提及的 WHO,并没有让台湾加入。所以这一份协议,台湾并没有参加。这获取是另外一个深入的问题,那就是一份国际协议如何签署,或者国际联盟应该如何相处的问题了。
[[波普尔]] 在 [[通过知识获得解放]] 的 [[社会科学的逻辑]] 一章中提到的那样,我们的[[知识]]是建立在暂时性和尝试性解决办法之上的,而证明其为真的唯一方式就是其本身仅仅是暂时的,换一句话说就是我们尝试的解决办法可以经得住我们最尖锐的批评。而找到这样的尝试性解决办法就是我们讨论的目的。
有人或许要说达成大多数人认可的结论未必有可行,现实可能确实确实比较困难,想要叫醒同一个时代沉睡的人的尝试多少人都曾经试过,但都几乎没有用,但我总是相信,只要有人不停地记录,描述,呼喊,总有一天,真理会出现。
有效的讨论一定是相互增进了解的
「倾听」和「表达」是相互的,尤其是在讨论的过程中,不仅是对其人的事实增进了解,也是对其想法,观点的了解。文字当然也能充当一部分了解的渠道,但是通过讨论,透过语音语调能够更进一步的他是如何思考的。
如何进行有效的讨论
讨论双方保持谦逊和尊重
讨论的前提是,讨论双方相互保持一点谦逊,双方都要了解到自己的认知和观点可能是错误的,才能听取对方反对的意见。
[[密尔]]早在几百年前就提过关于公共讨论的道德:
- 辩论的双方,不管站在哪一方,只要讨论中缺乏坦诚,或表现出不宽容和固执,都需要予以谴责
- 但是不能从一个人所选定的立场来推断其个人的恶行
- 而且无论这个人持有什么样的观点,只要能够冷静地观察,诚实地表述他反对者及其观点究竟是什么,既不夸大,也不掩藏,那就应该予以这样的人尊重
就像 [[洛克]]、[[波普尔]]等哲学家对世界的认识一样,我们无法保证我们当前的认识就一定是真的,所以我们要在现阶段讨论,以及充分、有效地讨论,经过讨论,错误的意见和行为才会逐渐服从事实和论证,一个聪明人获得智慧的途径就是聆听各种不同的意见。
得出暂时性的解决办法后再将注意力转移到其他事务
在什么是有效的讨论中,论述了一个有效讨论需要一个暂时性的解决方案,如果当一个事件并没有得出暂时性的解决方案,我们的注意力就被转移到另外的地方,那么就陷入了当前社交媒体的陷阱。现在的社交媒体,「流」的显示形式和用户的参与方式,使得用户的注意力不断地从一个事件飞向另外一个事件。
这样的方式像极了司法审判,不管这个判决如何撕裂社会,不管这个判决是否会遭受到大众的攻击,也要给这样的按键定一下一个先例,定一下一个当前最合适的方案。
[[马克思 韦伯]]
Clubhouse 如何
Clubhouse 是什么
Clubhouse 是什么,官方的解释是 new type of social network based on voice。这边就能看到两个重要的关键字 social network 和 voice,一个是社交网络,一个是声音。社交网络想必想必都非常熟悉,但是如果要去定义社交网络的话,也还是一件比较复杂的事,借用维基百科的解释,社交网络就是一个由独立个人或组织组成的关系网络,这样的社会网络会根据血缘、爱好,友谊,价值观等等因素连接起来。这样的网络结构一般是比较复杂的。
当我们解析完社交网络就会发现当生活在社会中的我们通过这样的方式连接起来之后,并借助这些年互联网的发展,提供给了我们非常多的工具来沟通,有文字的(Facebook,Twitter),重在图片的(Instagram),当然还有基于短视频的(抖音),而现在又多了一个声音。
这两年关于声音尤其是播客的创业明显地多了起来,从播客制作工具,到托管平台,再到各家大厂不断的收购播客相关内容可以看到越来越多的人开始关注到声音。声音从广播开始,到有声电影,曾经有一段时间被视频的光芒所掩盖了。声音总是伴随着视频一同出现,以至于我们曾经忘了还有这样一种信息传播的媒介。
但不管是广播,还是演讲,或是播客,都是单方向的传播,而 Clubhouse 的出现使得这样的传播方式发生了转变,虽然可以预料到是交流的过程中会混入不同的声音,但是在交流的过程中必然会产生新的观点。这或许才是这个应用最有价值的地方。
Clubhouse 中有三种类型的 Room :
- Open
- Social
- Closed
其中 Open 和 Closed 自不必说,Social 类型的房间会开放给你追踪的人。这里看得出来 Clubhouse 还是面对的熟人社交,因为只有熟人才会进我们自己的房间。
但仔细的再思考这三种类型的 Room,Open 的房间可以应对到现实中公开的演讲,而 Closed 房间可以对应到熟人之间的聚会,而 Social 则可以对应到一定程度上私密的沙龙。
Clubhouse 吸引我的地方
- 听名人的对话和分享,虽然当今世界已经了有了足够多的资料去了解一个人,但我对实时直播的对话依然有足够兴趣,毕竟这样的机会并不会很多
- 对不确定主题的新鲜感,对全世界不同地方的人的好奇,在初到 Clubhouse 的时候我钻进了不同的房间,听各种各样的主题
- 学习语言的好地方,用过一段时间之后会发现,Clubhouse 给了语言学习者一个极好的学习机会,因为在这这里不能发文字,不能发图片,只能使用语音,那就天然的适合学习外语
我所认为的 Clubhouse 的问题
- 对话的质量无法保障,我们都知道播客的信息含量肯定不如图书,而 Clubhouse 的信息含量可能连播客也比不上。但这就使得我不再去关注对话本身,使得我去追踪个人。
- 不能被检索的信息,聊天的内容并不能在 Clubhouse 上留下来,这也就导致大量的信息都会随着房间的消失而消失。除非花费大量的时间在上面,否则平台不会对新用户产生任何价值,也形成不了一个价值闭环。
最后欢迎大家搜索 @einverne 来找我聊天。
使用 Beancount 记账篇零:Beancount 入门使用
说起 Beancount,就不得不提复式记账,在之前的文章里面已经完整的叙述过复式记账是比单式记帐更加科学的记账方法,但是复式记账在目前只被大多数企业所采用,并没有被大众所接受,市面上也依然缺少复式记账的工具。而 Beancount 就是其中比较好用的一个工具。
为什么要用 Beancount 记账
为什么要用 Beancount 记账? 要回答这个问题需要从两个方面说起,一方面是为什么要记账,另一方面是在这么多的记账软件中为什么要用 Beancount。
首先回答为什么要记账,在之前的文章中也提到过,通过记账是认识自己的一种方式,通过周期性的记账可以更好的理清自己的财务状况,可以对自己的[[资产损益表]]、[[资产负债表]]情况一目了然。尤其是当自己的收入一部分在银行,一部分在支付宝,一部分在微信,还有一部分在股市的时候,就很难具体地回答出自己到底有多少资产。并且如果不有意识地记录自己的每个月的开销,那么对自己的支出也可能非常模糊。通过记账不仅可以加深对自己的财务的了解,也可以根据支出的数据针对性的进行优化。就像启蒙我使用 Beancount 的 byvoid 的文章 中提到的那样,如果要达到财务自由,需要达到三点要求,对支出的预期,对资产和收入的了解,和对寿命的期望。而记账可以解决前两点。
再考虑一下第二个问题,相比较于其他的复式记账工具,为什么要选择 Beancount,回答这个问题之前,我就要先拿出我自己一贯的选择软件或者工具的准则,第一开源优先,第二跨平台,第三数据可以导出或自行管理。并且因为私人的财务数据是非常重要的个人隐私,我不相信任何托管数据的商业机构的软件。所以按照我的准则,我去了解支持复式记账的工具,有如下的选择:
- 开源并且跨平台的 GnuCash
- John Wiegley 的 Ledger,C++ 编写,基于命令行的复式记账工具
- hledger 使用 Haskell 重新编写的 Ledger CLI
- Beancount 纯文本,命令行,Python 编写,源自 Ledger
除开第一个 GnuCash 下面三个都是纯文本的记账工具,纯文本工具带来的好处便是,可以将这个系统放入到版本控制,比如 Git 中,也可以将数据同步到其他平台。并且只要有一套渲染工具就可以提供非常详细的报表数据。Beancount 提供了 fava 这样基于 Web 的展示工具。plaintextaccounting 这个网站提供了更加详细的对比,对于这些纯文本的工具,只有自己掌握数据,那么从一个工具迁移到另一个工具的成本也不会很高。
我选择 Beancount 的理由便是,Beancount 足够简单,但又有丰富的扩展性,就像作者自己说的 那样,简化了 Ledger 中的概念,并且通过自己的实践重新定义了 Beancount 的能力。
什么是 Beancount
经过上面这么多说明,Beancount 是什么就不需要多说了,需要记住的就是纯文本,复式记账工具,这两个重要的特性了。
Beancount 其他重要的特性:
- Python 编写可以直接运行在本地
- Beancount 提供自定义的货币单位,可以实现虚拟货币,证券交易等等场景,甚至可以将年假以天的方式记录到账簿
- 凭借 fava 提供了丰富的查询功能
- 可以利用 SQL 进行更加复杂的统计
- 可以通过脚本快速导入微信,支付宝,信用卡等账单
基础使用
在交易记录中,会使用 + 或 - 来表示资金的流动。一般来说:
- Assets 资产账户,正数表示资金增加,负数表示资金减少
- Income 收入账户,一般使用
-负数表示 - Expense 支出账户使用
+, 表示支出增加 - Liabilities 负债账户,
-表示借款,负债增加,+表示还款,负债减少
每一笔交易(Transaction)都是资金在这样四个基础账户中流转。
Beancount 定义了一些基本的语法规则,用户需要按照这样的规则对自己的交易进行记录。
定义使用的货币
option "operating_currency" "CNY" ; 帐本货币
option "operating_currency" "USD"
或者等熟悉了基本使用之后,可以用 commodity 来自定义货币。
1990-01-01 commodity BTC
name: "Bitcoin"
使用 open 和 close 来开通或关闭账户,在 Beancount 中作者将顶级的账户限制为了五类,Assets,Income, Expense, Liabilities, Equity。暂且可以按照字面去了解其具体作用,之后会再写一篇文章来讲述如何对这五类账户进行命名。
比如 2016 年 1 月 1 日,开通了一个招行借记卡
2010-11-11 open Assets:DebitCard:CMB CNY
name: "招商银行借记卡"
2010-01-01 open Income:Salary:Company CNY
开户的语法:
;开户,支持 Unicode, yyyy-MM-dd 表示开户时间
yyyy-MM-dd open 账户类型:命名:命名区别 货币[,货币2]
2016 年 1 月 2 日,收到第一笔工资,那么就是收入账户到资产账户的流转,钱从收入账户 Income:Salary:Company 中流转到刚开通的招行 Assets:DebitCard:CMB:
2016-01-02 * "Income"
Income:Salary:Company -1234 CNY
Assets:DebitCard:CMB
这里需要注意的是收入一般使用 - 来表示。
在 2020 年销户了
2020-01-01 close Assets:DebitCard:CMB
记录交易,比如 2021 年 1 月 1 日,使用招行的信用卡买了 40 元的咖啡。这个 40 元被分别记录到两个账户中。
2010-01-01 open Expenses:Drink:Coffee
2010-01-01 open Liabilities:CreditCard:CMB
2021-01-01 * "收付款方:某某咖啡店" "备注:Coffee"
Expenses:Drink:Coffee +40.00 CNY
Liabilities:CreditCard:CMB
如果一笔交易只涉及到两个账户,根据正负平衡原则,第二个账户后面的 -40.00 CNY 可以省略。
交易的基本的语法可以简记为:
[yyyy-MM-dd] [*|!] "payee" "备注"
[account1] +[num] [currency-unit]
[account2] (-[num] [currency-unit])
在日期后面有一个标识符,flag,用来标记交易的状态:
*完成的交易,确切的知道交易额!未完成的交易,需要确认或修改交易额
另外还可以使用如下的语法给交易添加 #标签 和 链接
2015-05-30 ! "Cable Co" "Phone Bill" #tag ^link
id: "TW378743437" ; Meta-data
Expenses:Home:Phone 87.45 USD
Assets:Checking ; You may leave one amount out
记住这个公式:
(Assets + Expenses) + (Liabilities + Income) + Equity = 0
这样就已经了解了 Beancount 的基本使用,先迈进第一步,后面再慢慢了解 Beancount 的货币转换,断言,账户平衡等等特性。
Beancount 账户概念
在 Beancount 中每一笔交易都会被划进不同的账户中。
这里只对账户进行简单的介绍,之后会在展开。
Beancount 中的五类根账号:
- Assets 资产账户,可以用来记录现金,银行卡余额,证券账户余额等等
- Liabilities 负债,比如信用卡,房贷账户,车贷账户等等
- Income,收入账户,比如工资账户,其他收入账户等等
- Expense,开支账户,比如房租,日常用品,数码产品等等
- Equity,权益账户,一般不直接使用,Beancount 中一般用来平衡其他账户,比如初始化 Beancount 的使用
在 Beancount 中给账户命名,一般使用冒号来间隔,比如要记录一个外出打车的开支,可以命名成:
2010-11-11 open Expenses:Transport:Taxi
同一分类下,还可以定义:
2010-11-11 open Expenses:Transport:Public
2010-11-11 open Expenses:Transport:Taxi
2010-11-11 open Expenses:Transport:Bike
范围由粗略到详细,这样之后在 fava 中通过界面可以一层层通过统计得出,在出行方面的开支。
Beancount 记录交易
在了解基本的 Beancount 之后,可以再举一些经常使用的例子。
收入
这里需要注意的是 Beancount 中,收入账户一般使用 - 来记录。
2020-02-01 * "北京某有限公司" "工资"
Income:Salary -5000 CNY
Expenses:Endowment +1000 CNY; 养老保险
Expenses:Unemployment +30 CNY; 失业保险
Expenses:Medical +300 CNY; 医疗保险
Expenses:Taxes +100 CNY; 个人所得税
Income:HousingFund -500 CNY; 公司额外支付的住房公积金
Assets:HousingFund +1000 CNY; 住房公积金
Assets:DebitCard:CMB +3070 CNY; 招商银行工资卡
消费
2020-02-29 * "超市" "食材 牛奶"
Liabilities:CreditCard:BOC -90 CNY; 交通银行信用卡
Expenses:Food:Ingredients +40 CNY; 食材
Expenses:Food:Drinks +50 CNY; 饮品
信用卡还款
2021-01-05 * "信用卡还款"
Assets:DebitCard:CMB -100 CNY
Liabilities:CreditCard:BOCOM +100 CNY
如果遇到双币信用卡还款问题可以使用 @ 转换汇率:
2021-09-25 * "购汇 还款"
Liabilities:CreditCard:BOC:US 152 USD @ 6.461381579 CNY
Assets:DebitCard:CMB -982.13 CNY
垫付
2019-10-12 * "合租交燃气费用"
Expenses:House:Gas +200 CNY
Liabilities:CreditCard:BOC -200 CNY
Assets:WeChatPay +150 CNY; 发回来的红包
标签
假如已经计划了一次外出的度假,想把所有的相关的交易都打上一个标签,那么可以不用在每一个交易记录上手动加上标签,可以使用 pushtag 和 poptag 的语法。
pushtag #trip-to-japan
...
poptag #trip-to-japan
在两个标签中间添加自己的账单交易即可。
初始化设置
使用 pad 来初始化账户。如果一开始的时候账户中本身有一些数据,可以使用 pad 来初始化账户。
比如在开始使用 Beancount 的时候银行卡中有 20000 人民币余额,那么就可以定义为:
2019-01-01 pad Assets:DebitCard:CMB Equity:Opening-Balances
2019-01-02 balance Assets:DebitCard:CMB 20000.00 CNY
Beancount 生成报表
Beancount 可以配合 fava 一起使用,使用 pip install beancount fava,然后执行:
fava main.bean
fava 就会根据你在 main.bean 文件中定义的内容渲染一个网页端。官网提供了一个简单的例子。
在这个界面上可以看到 Income Statement [[资产损益表]], Balance Sheet [[资产损益表]],Trail Balance [[试算表]],Journal 日记帐等等功能。
之后会再写一篇文章重点介绍一下 [[Fava]] 的使用。
reference
Maven 中的 classifier
今天看 maven-embedder 中定义的引用 [[Google Guice 轻量级依赖注入]] 依赖时,定义了 classifier 标签。故来学习一下 Maven 配置中 classifier 的含义。
首先来看两个例子:
<dependency>
<groupId>net.sf.json-lib</groupId>
<artifactId>json-lib</artifactId>
<version>2.2.2</version>
<classifier>jdk15</classifier>
</dependency>
<dependency>
<groupId>net.sf.json-lib</groupId>
<artifactId>json-lib</artifactId>
<version>2.2.2</version>
<classifier>jdk13</classifier>
</dependency>
实际上 Maven 会去寻找的是 json-lib-2.2.2-jdk15.jar 和 json-lib-2.2.2-jdk13.jar 这两个 jar 包。
回到正题:
<dependency>
<groupId>com.google.inject</groupId>
<artifactId>guice</artifactId>
<version>4.2.1</version>
<classifier>no_aop</classifier>
</dependency>
classifier 用于区分从项目不同的组成部分,源代码、javadoc,类文件等等。
这是一个可选项,当存在时,会附加到 artifact 名字和版本后面。最终的 jar 包会是 guice-4.2.1-no_aop.jar
Build different classified version
如果要在构建的时候构建不同的包,可以使用 maven-jar-plugin 插件,然后也是通过 classifier 来区分。
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-jar-plugin</artifactId>
<version>3.0.2</version>
<configuration>
<classifier>${classifier}</classifier>
</configuration>
</plugin>
引用的时候指定不同的 classifier 就行了。
Deploy an artifact with classifier
通过手动执行命令来 deploy
mvn org.apache.maven.plugins:maven-deploy-plugin:3.0.0:deploy-file -Durl=http://localhost:8081/repomanager/ \
-DrepositoryId=some.id \
-Dfile=path/to/artifact-name-1.0.jar \
-DpomFile=path-to-your-pom.xml \
-Dfiles=path/to/artifact-name-1.0-debug.jar,path/to/site.pdf \
-Dclassifiers=debug,site \
-Dtypes=jar,pdf
通过 classifiers 来指定。
reference
解决 NoSuchMethodException 错误的方法
问题的出现
在使用 Java Instrumentation API 的时候,因为在应用启动的时候加载了一个 Java Agent,然后在 Java Agent 中依赖的包,和应用内依赖的包产生了冲突,同时使用了 commons.lang3 这个包,但是依赖的版本不一致。导致使用 FieldUtils 的时候出现了 NoSuchMethodError:
Caused by: java.lang.NoSuchMethodError: org.apache.commons.lang3.reflect.FieldUtils.getFieldsWithAnnotatio
n(Ljava/lang/Class;Ljava/lang/Class;)[Ljava/lang/reflect/Field;
at com.opencsv.bean.AbstractMappingStrategy.loadRecursiveClasses(AbstractMappingStrategy.java:498)
at com.opencsv.bean.AbstractMappingStrategy.loadFieldMap(AbstractMappingStrategy.java:440)
at com.opencsv.bean.AbstractMappingStrategy.setType(AbstractMappingStrategy.java:363)
at com.opencsv.bean.util.OpencsvUtils.determineMappingStrategy(OpencsvUtils.java:79)
at com.opencsv.bean.CsvToBeanBuilder.build(CsvToBeanBuilder.java:234)
NoSuchMethodError 错误出现的根本原因
NoSuchMethodError 错误出现的根本原因是应用程序直接或间接依赖了同一个类的多个版本,并且在运行时因为版本不一致,其中依赖的版本缺少方法而导致的。编译时和运行时类路径不一致。
基于上面具体的问题,在排查应用内的错误的时候,完全没有发现包冲突的情况,但加上了 Agent 就出错。
同一个 Class 出现不同版本的原因
- JDK 版本不一致
- SNAPSHOT 版本不一致
- Maven 依赖作用域为 provided [[Maven scope 作用域]]
- 同一个 jar 包出现多个版本
- 同一个 Class 出现在不同的 Jar 中
哪个版本的 Class 会被执行
- [[202010141045-Maven 依赖仲裁机制]]
- [[JVM 类加载机制]] 决定了 Class 被加载到 JVM 的优先级
如何解决 NoSuchMethodError 错误
- 定位异常 Class 的全限定类名和调用方,堆栈日志
- 定位异常 Class 来源,可以通过 [[Arthas]] 等在线诊断工具反编译,使用
jad com.xxx.ClassName来获取该类运行时的源码,ClassLoader,Jar 包位置等信息- 如果程序启动失败,或无法在线诊断,可以考虑添加 JVM 启动参数
-verbose:class或-XX:+TraceClassLoading,在日志中输出每一个类的加载信息
- 如果程序启动失败,或无法在线诊断,可以考虑添加 JVM 启动参数
- 根据 ClassLoader 和 Jar 包全路径名,判断类加载、Maven 仲裁或其他原因
- 如果是 Jar 包多版本问题,可以指定需要的版本,或移除间接依赖中的低版本,使用
mvn dependency:tree查看 - 如果是同一个 Class 出现在不同 Jar 包中,如果可以排除,就排除依赖,如果不能排除,可以考虑升级或替换包
- 如果是 Jar 包多版本问题,可以指定需要的版本,或移除间接依赖中的低版本,使用
reference
- [[Java 常见问题]]
WhatPulse 使用记录
一年多以前购买 MacBook Pro 的时候安装了一款叫做 WhatPulse 的应用。WhatPulse 是一个记录键盘以及外设使用的工具,可以观察到使用了多少次键盘,触摸板,鼠标等等数据。
这一年多以来也并没有主力使用这一台 MacBook Pro, 但之前就是想记录一下键盘的按键次数,从而想要更换一下键盘布局的,看到很多人说更换成 Dvorak 之后会大大的减少手指的移动,但是这几年来虽然切换了中文输入法使用小鹤双拼,但键盘布局还是没有尝试更换过,切换的成本还是非常大。本来想使用科学的方法来记录一下,所以安装了 WhatPulse 但还是没有来得及统计数据。并且因为我大量的使用 Vim 的键盘映射,可以从下面的数据中看到很多 Vim 触发的键会异常得多,比如说 I,J,E,U 这几个键本来应该是没有那么高的权重的,但因为 Vim 中用 I 切换到插入模式,J,E,U 等等常常用来浏览,翻页等等所以使用次数也特别多。也正是因为各种场景混杂在了一起,所以我自己的这一份数据,更没有办法用来分析,因为中文输入,以及英文输入,在按键的使用上肯定是没有办法统一的。
界面展示
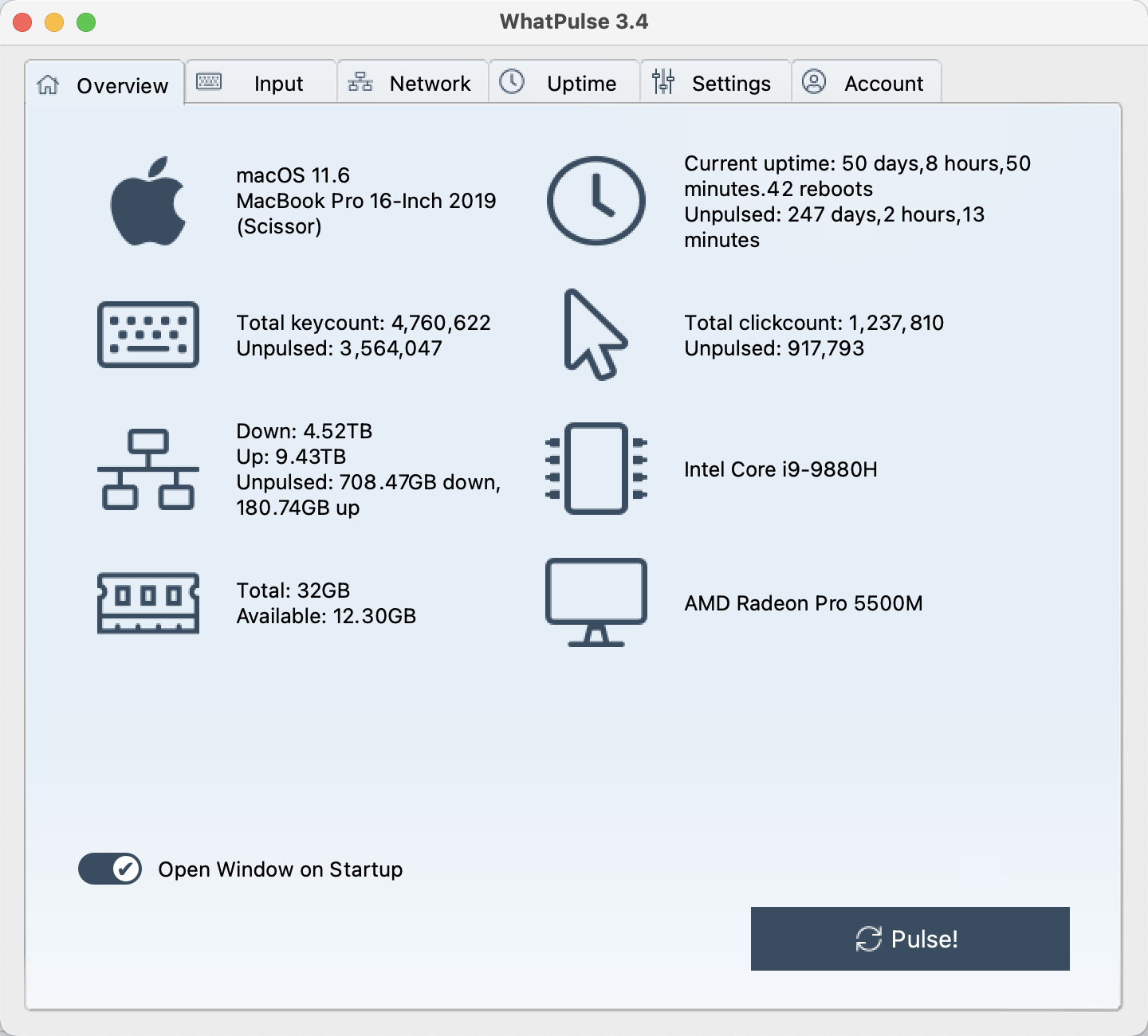
总览界面:
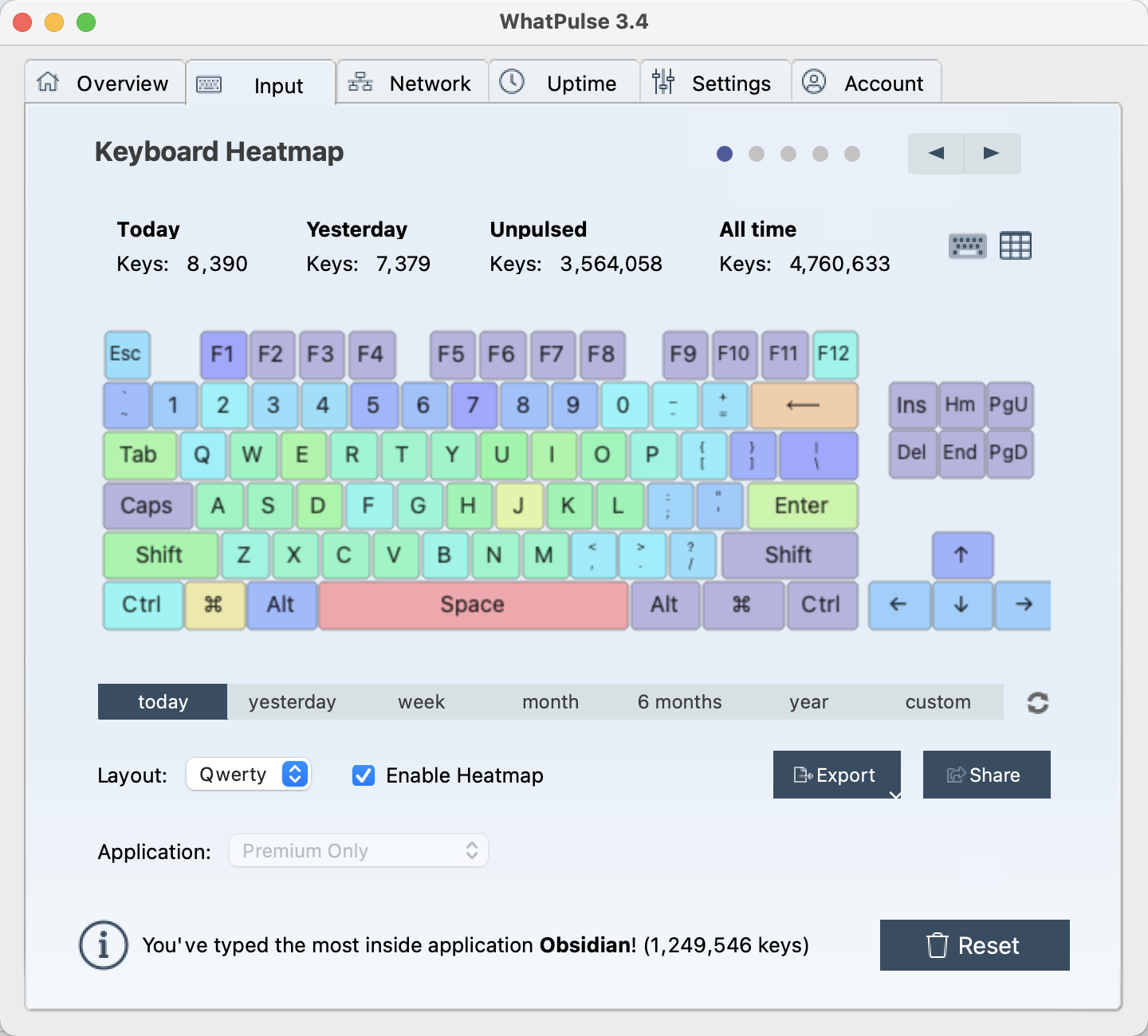
键盘使用热力图:
键盘使用次数:
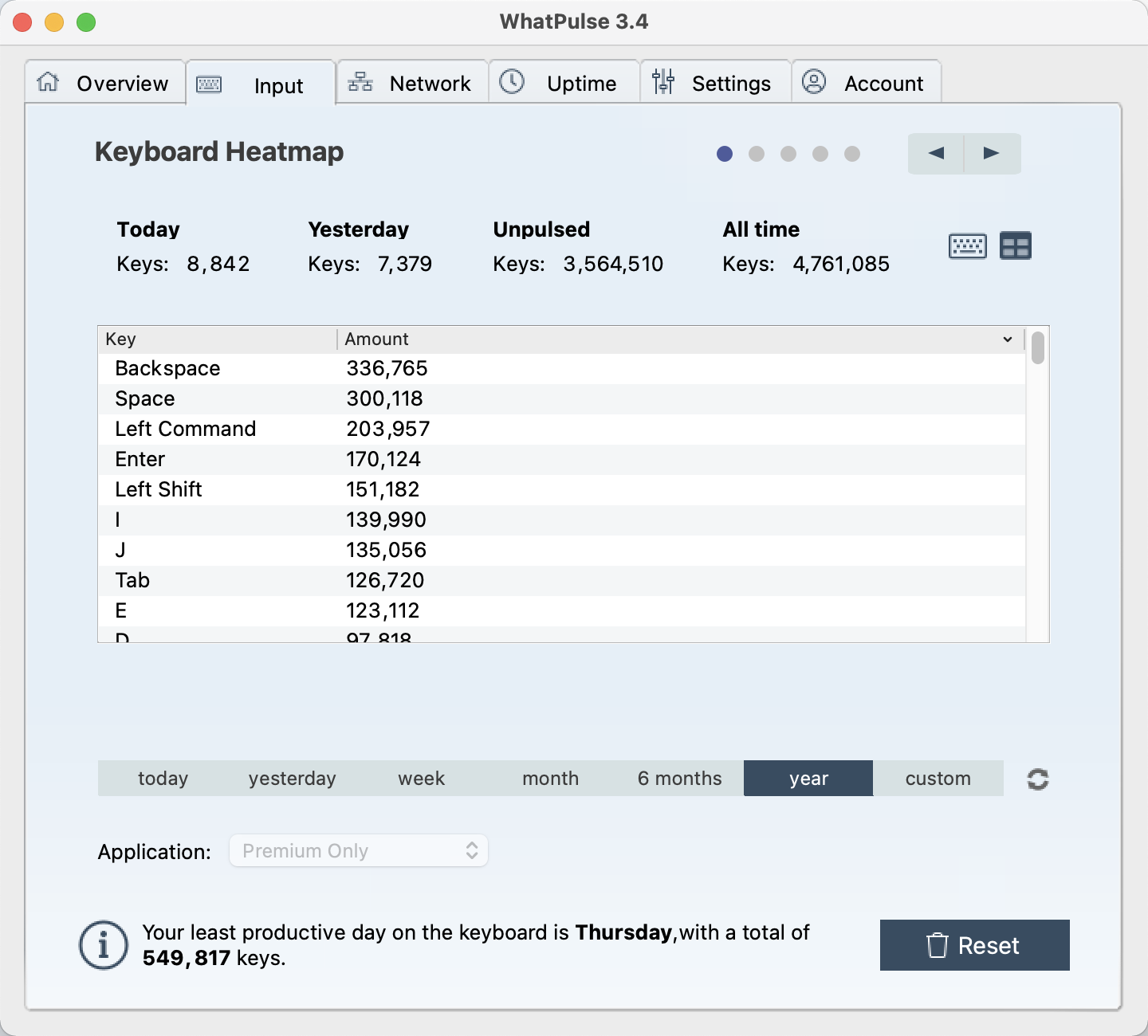
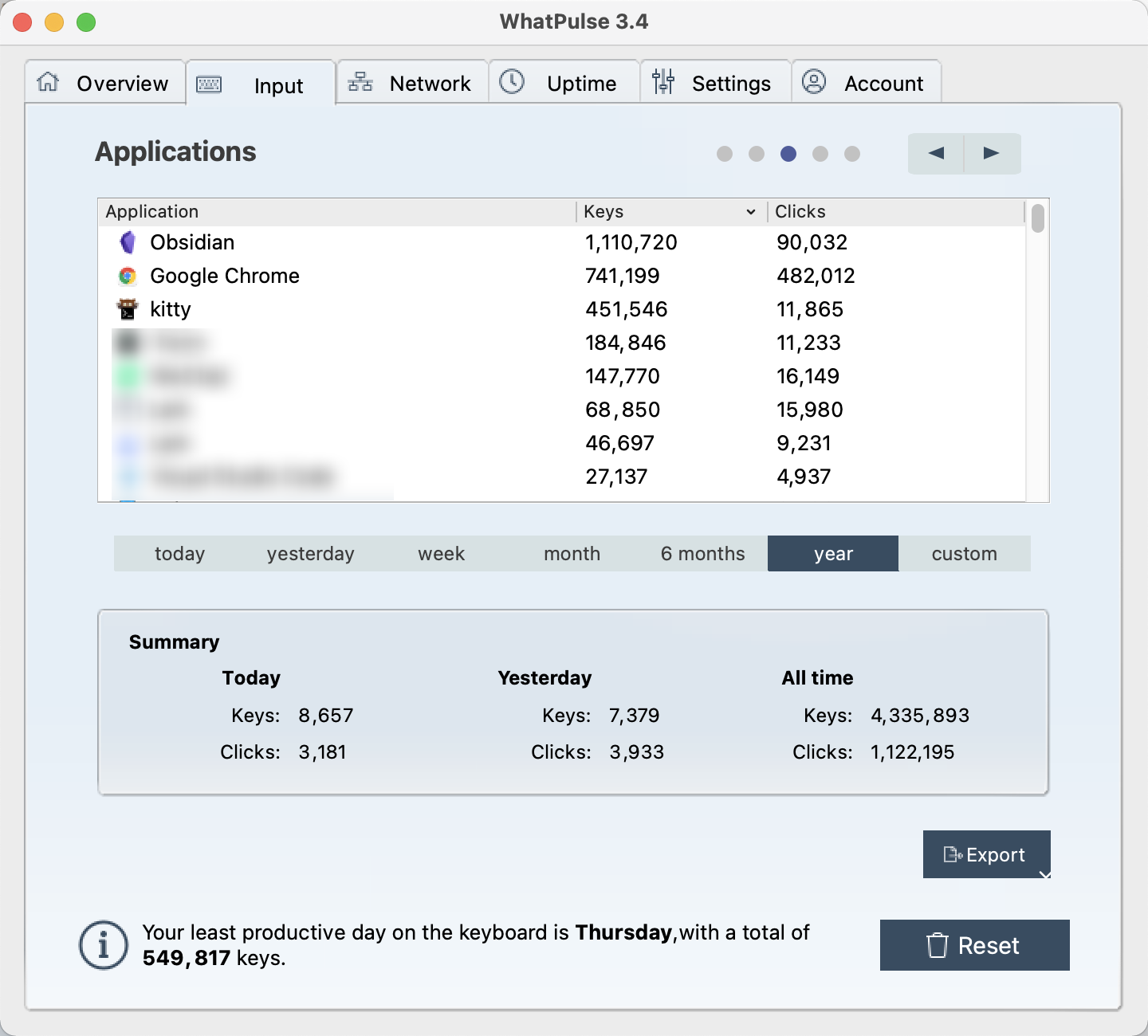
在 Obsidian 中敲击键盘次数最多,倒是也能够理解,毕竟大部分的工作现在都迁移到了 Obsidian 中。
触摸板使用热力图:
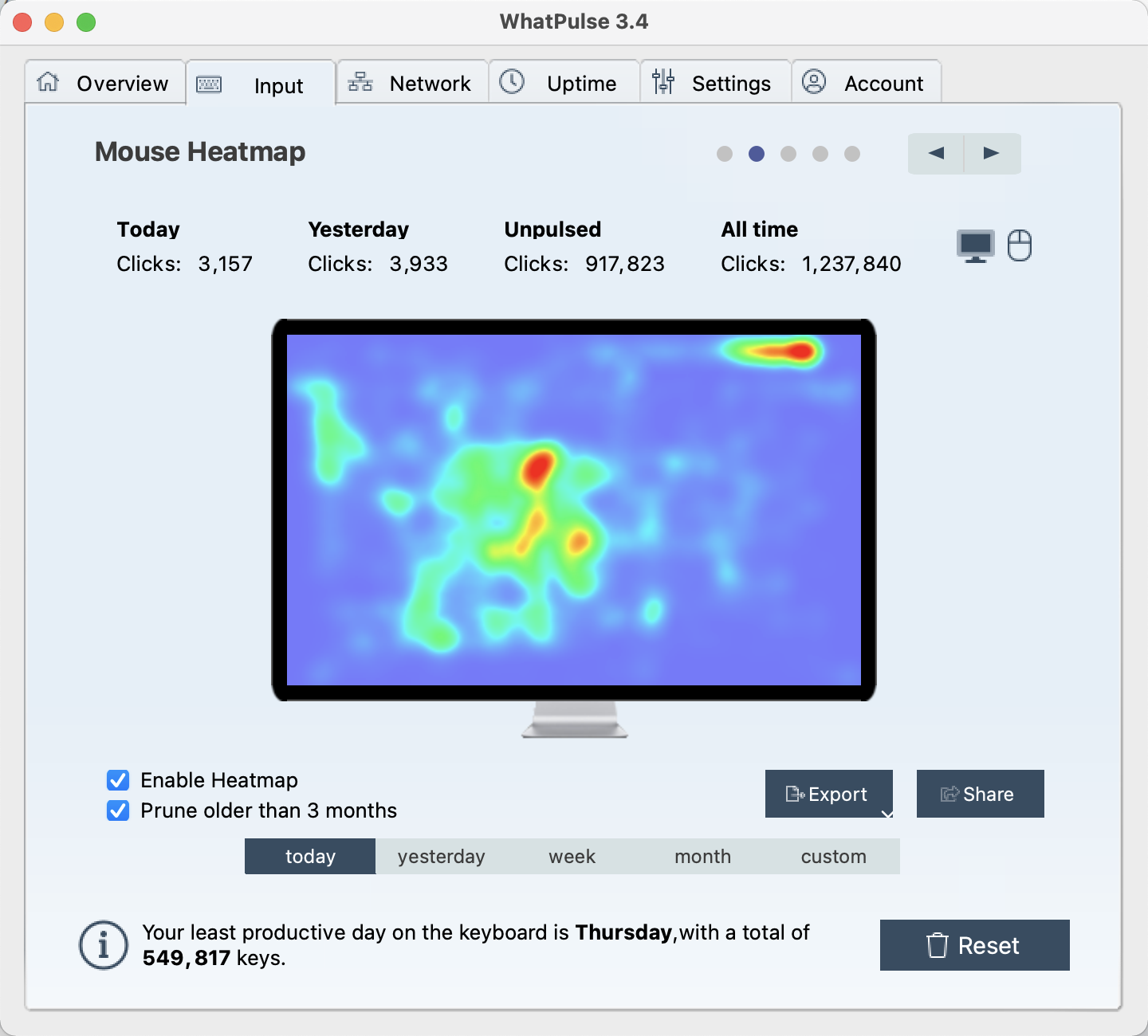
触摸板的热点图完美的展示了我喜欢用右手大拇指操作的习惯。
在各个应用中使用统计:
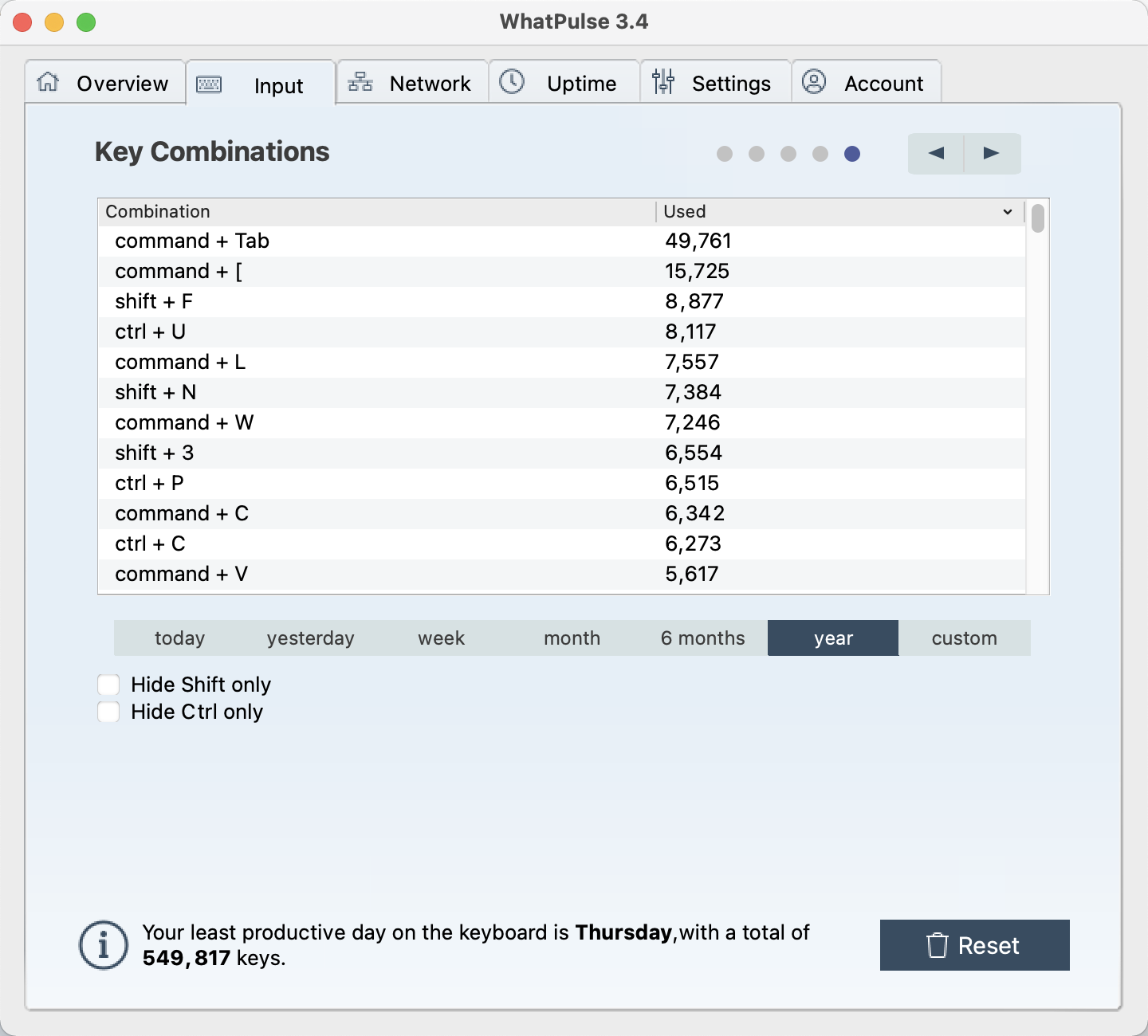
组合按键使用:
文章分类
最近文章
- 从 Buffer 消费图学习 CCPM 项目管理方法 CCPM(Critical Chain Project Management)中文叫做关键链项目管理方法,是 Eliyahu M. Goldratt 在其著作 Critical Chain 中踢出来的项目管理方法,它侧重于项目执行所需要的资源,通过识别和管理项目关键链的方法来有效的监控项目工期,以及提高项目交付率。
- AI Shell 让 AI 在命令行下提供 Shell 命令 AI Shell 是一款在命令行下的 AI 自动补全工具,当你想要实现一个功能,敲一大段命令又记不住的时候,使用自然语言让 AI 给你生成一个可执行的命令,然后确认之后执行。
- 最棒的 Navidrome 音乐客户端 Sonixd(Feishin) Sonixd 是一款跨平台的音乐播放器,可以使用 [[Subsonic API]],兼容 Jellyfin,[[Navidrome]],Airsonic,Airsonic-Advanced,Gonic,Astiga 等等服务端。 Sonixd 是一款跨平台的音乐播放器,可以使用 [[Subsonic API]],兼容 Jellyfin,[[Navidrome]],Airsonic,Airsonic-Advanced,Gonic,Astiga 等等服务端。
- 中心化加密货币交易所 Gate 注册以及认证 Gate.io 是一个中心化的加密货币交易所。Gate 中文通常被称为「芝麻开门」,Gate 创立于 2013 年,前身是比特儿,是一家致力于安全、稳定的数字货币交易所,支持超过 1600 种数字货币的交易,提供超过 2700 个交易对。
- 不重启的情况下重新加载 rTorrent 配置文件 因为我在 Screen 下使用 rTorrent,最近经常调试修改 rtorrent.rc 配置文件,所以想要找一个方法可以在不重启 rTorrent 的情况重新加载配置文件,网上调查了一下之后发现原来挺简单的。