VPS 性能测试
VPS 性能测试的几个方面:
- 综合性能测试
- IO 性能测试
- 网速
- 路由
综合类测试
在运行这类测试脚本之前,最好先将脚本下载下来之后打开看一眼,以防止安装执行一些不可信的文件。
IPASN AIO Benchmark by mastervnc
The Ultimate Benchmark Script 相较于其他 benchmark 的优势在于可以测试全球不同地区的网络延迟情况。
sudo curl -sL -k https://ipasn.com/bench.sh | sudo bash
来自:LET
NodeBench
NodeBench 是一个聚合脚本
- 自动测试 Yabs,三网线路,地区解锁情况
- 输出 Markdown 格式
- 自动复制到粘贴板
bash <(curl -sL https://raw.githubusercontent.com/LloydAsp/NodeBench/main/NodeBench.sh)
来自:nodeseek
bench.sh
teddysun 提供的综合脚本,检测 CPU,内存,负载,磁盘 IO,带宽:
wget -qO- bench.sh | bash
curl -Lso- bench.sh | bash
UnixBench 测试,UnixBench 跑分不一定代表真实性能,但可以提供一定参考。
wget --no-check-certificate https://github.com/teddysun/across/raw/master/unixbench.sh
chmod +x unixbench.sh
./unixbench.sh
Yet-Another-Bench-Script
Yet Another Bench Script 正如其名,也是一个用来全面测试 VPS 性能的脚本。
curl -sL yabs.sh | bash
默认情况下脚本会测试:
- 磁盘读写
- 网络带宽
- Geekbench 5 Benchmark
可以通过如下参数来禁用一些检测。
格式:
curl -sL yabs.sh | bash -s -- -flags
将其中的 flags 替换:
-f/-d禁用 fio 磁盘-i禁用 iperf 网络带宽检测-g禁用 Geekbench
比如只想检测磁盘读写,可以使用如下的命令:
curl -sL yabs.sh | bash -s -- -i -g
bench monster
Bench.monster 是一个服务器网络连接速度,I/O 速度等等的脚本。
curl -LsO bench.monster/speedtest.sh; bash speedtest.sh
nench
(curl -s wget.racing/nench.sh | bash; curl -s wget.racing/nench.sh | bash) 2>&1 | tee nench.log
Superspeed.sh
全国各地测速节点的一键测速脚本 Superspeed.sh
使用:
bash <(curl -Lso- https://git.io/superspeed)
Superbench
SuperBench.sh 是在 bench.sh 上的增强,增加了服务器类型检测,OpenVZ, KVM ,独立服务器通电时间检测等。
该脚本需要 root 运行:
wget -qO- https://raw.githubusercontent.com/oooldking/script/master/superbench.sh | bash
#或者
curl -Lso- https://raw.githubusercontent.com/oooldking/script/master/superbench.sh | bash
wget -qO- git.io/superbench.sh | bash
curl -Lso- git.io/superbench.sh | bash
Serverreview Benchmark
curl -LsO git.io/bench.sh; chmod +x bench.sh && ./bench.sh -a share
LemonBench
LemonBench,是一款针对 Linux 服务器设计的服务器性能测试工具。通过综合测试,可以快速评估服务器的综合性能,为使用者提供服务器硬件配置信息。
Speedtest
curl -LsO bench.monster/speedtest.sh; bash speedtest.sh -asia
CPU 测试
可以通过手工执行命令的方式查看 CPU 信息:
cat /proc/cpuinfo
同理可以查看内存:
cat /proc/meminfo
以及硬盘:
fdisk -l
df -lh
I/O test
The speed of read and write of your hard drive.
dd if=/dev/zero of=test bs=64k count=4k oflag=dsync
dd if=/dev/zero of=test bs=8k count=256k conv=fdatasync
网速 Net speed
个人比较常用的是 speedtest-cli
pip install speedtest-cli
speedtest-cli
一键脚本测速
wget -qO- network-speed.xyz | bash
测试服务器到国内的速度,oooldking:
wget -qO- https://raw.githubusercontent.com/oooldking/script/master/superspeed.sh | bash
网络连通性
wget https://raw.githubusercontent.com/helloxz/mping/master/mping.sh && bash mping.sh
测试带宽
wget https://raw.github.com/sivel/speedtest-cli/master/speedtest.py
python speedtest.py --share
ping测试
全球各地 ping 测试网站:
或者
http://www.ipip.net/ping.php
wget https://raw.githubusercontent.com/helloxz/mping/master/mping.sh
bash mping.sh
路由测试
脚本:
wget -qO- https://raw.githubusercontent.com/zq/shell/master/autoBestTrace.sh | bash
一键检测VPS回程国内三网路由,root1:
curl https://raw.githubusercontent.com/zhucaidan/mtr_trace/main/mtr_trace.sh|bash
支持的线路为:电信CN2 GT,电信CN2 GIA,联通169,电信163,联通9929,联通4837,移动CMI
BestTrace 工具。
wget https://cdn.ipip.net/17mon/besttrace4linux.zip
unzip besttrace*
chmod +x besttrace
./besttrace -q1 202.106.196.115
在线测试工具
http://ping.chinaz.com/
https://www.17ce.com/
http://www.webkaka.com/
http://ce.cloud.360.cn/
独立服务器检测 VPS 通电时间
安装检查工具:
sudo apt install -y smartmontools
使用 df -h 查看硬盘设备,然后执行:
smartctl -A /dev/sda | grep "Power_On_Hours"
后面的数字即为硬盘的通电时间小时数。如果通电时间比较长,就要做好备份工作了。
一键脚本:
wget -q https://github.com/Aniverse/A/raw/i/a && bash a
手动测试
CPU
# cpu
cat /proc/cpuinfo
lscpu
IO
dd if=/dev/zero of=test bs=64k count=16k conv=fdatasync
dd if=/dev/zero of=test bs=64k count=4k oflag=dsync
网速
# speed
wget http://cachefly.cachefly.net/100mb.test
流媒体解锁脚本
RegionRestrictionCheck
GitHub 地址:https://github.com/lmc999/RegionRestrictionCheck
执行命令:
bash <(curl -L -s https://raw.githubusercontent.com/lmc999/RegionRestrictionCheck/main/check.sh)
reference
- 脚本地址:https://github.com/teddysun/across/blob/master/bench.sh
- https://www.lowendtalk.com/discussion/162132/vps-benchmark-scripts
- https://github.com/haydenjames/bench-scripts/
- [[整理合集]]
使用 Mailu 搭建邮件服务器
Mailu 是一个开源的邮件服务器,可以使用 Docker 部署安装,后台界面使用 Python & Flask 开发。
个人总结的优点
- Mailu 非常轻量,相较于 Mailcow 非常轻量简洁
- 自带域名昵称,转发等等常用功能
- 支持两个 Webmail 分别是 roundcube/rainloop
- 自动生成 DKIM/DMARC/SPF 记录
- 可以使用官网的配置,使用 Docker 一键完成安装
建议在开始自建之前先阅读:
了解常用的 [[SPF]],[[DKIM]],[[DMARC]] 记录的作用。
Prerequisite
系统环境要求:
- 一台 2GB 具有独立 IP 的 VPS,25 端口开放,可以通过
telnet smtp.gmail.com 25来测试,返回 220 表示可以。- VPS 服务提供商可以设置 rDNS
- VPS 的 IP 最好要比较干净,没有被拉入黑名单
- 一个可以进行配置 DNS 的域名
本文在 Ubuntu 20.04 LTS 上进行。
确保 25 端口开放
可以使用如下命令测试 25 端口是否开放:
telnet smtp.gmail.com 25
如果返回超时需要向主机提供商申请开通 25 端口。
确保如下的端口可用:
netstat -tulpn | grep -E -w '25|80|110|143|443|465|587|993|995'
设置 hostname
以 example.com 为例:
sudo hostnamectl set-hostname mx.example.com
重启之后使用如下命令检查:
hostname
# 应该显示 mx
hostname -f
# 应该显示 mx.example.com
DNS 设置
假设 VPS 的域名是 1.1.1.1,以 example.com 为例:
- 设置 A 记录,
mx.example.com到 1.1.1.1 - 设置 SPF,TXT 记录,值为
v=spf1 mx ~all - DMARC,
_dmarc.example.comTXT 记录,值为v=DMARC1;p=none;pct100;rua=mailto: admin@example.com;ruf=mailto: admin@example.com
记得修改其中的 admin@example.com 为自己的域名。
设置 PTR 反向域名解析
这一步需要在 VPS 提供商后台进行设置,有一些服务器商不支持用户自行修改,那么需要用户 open ticket 来咨询,并设置 IP 到域名的解析记录。
设置完成之后可以通过 dig -x IP 来查看是否生效。
安装 Docker 和 docker-compose 命令
可以参考 Docker 官网安装。
sudo apt-get update
sudo apt-get install \
apt-transport-https \
ca-certificates \
curl \
gnupg-agent \
software-properties-common -y
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -
sudo add-apt-repository \
"deb [arch=amd64] https://download.docker.com/linux/ubuntu \
$(lsb_release -cs) \
stable"
sudo apt-get install docker-ce docker-ce-cli containerd.io -y
systemctl start docker
systemctl enable docker
安装 Docker Compose
curl -fsSL https://get.docker.com | bash -s docker
curl -L "https://github.com/docker/compose/releases/download/1.26.1/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose
chmod +x /usr/local/bin/docker-compose
Mailu 配置
Mailu 官方提供了一个自动配置生成网页
可以选择两种 Webmail
将配置下载之后查看配置,然后使用 Docker Compose 安装
docker-compose up -d
安装成功后:
- 后台地址: http://example.com/admin
- Webmail 地址: http://example.com/webmail
等待服务启动之后,登录后台,然后进行一定初始化配置。然后在界面中添加域名。
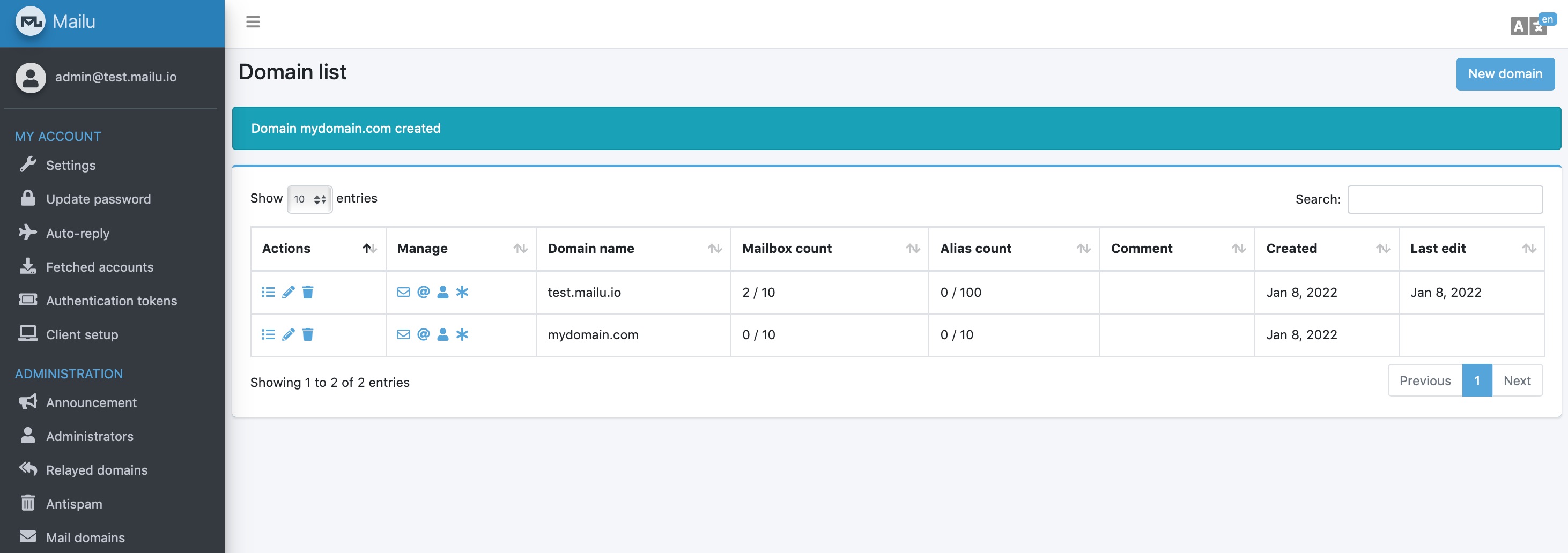
添加域名
在后台添加域名:
配置 DNS 解析
登录后台之后,点击 Mail Domains,然后在列表也点击最前面的按钮,进入域名详情之后点击右上角的 Regenerate Keys 生成 [[DKIM]] 和 [[DMARC]] 记录。
然后按照界面显示的内容,将 DNS 记录更新到域名的 DNS 中,等待一段时间生效即可。
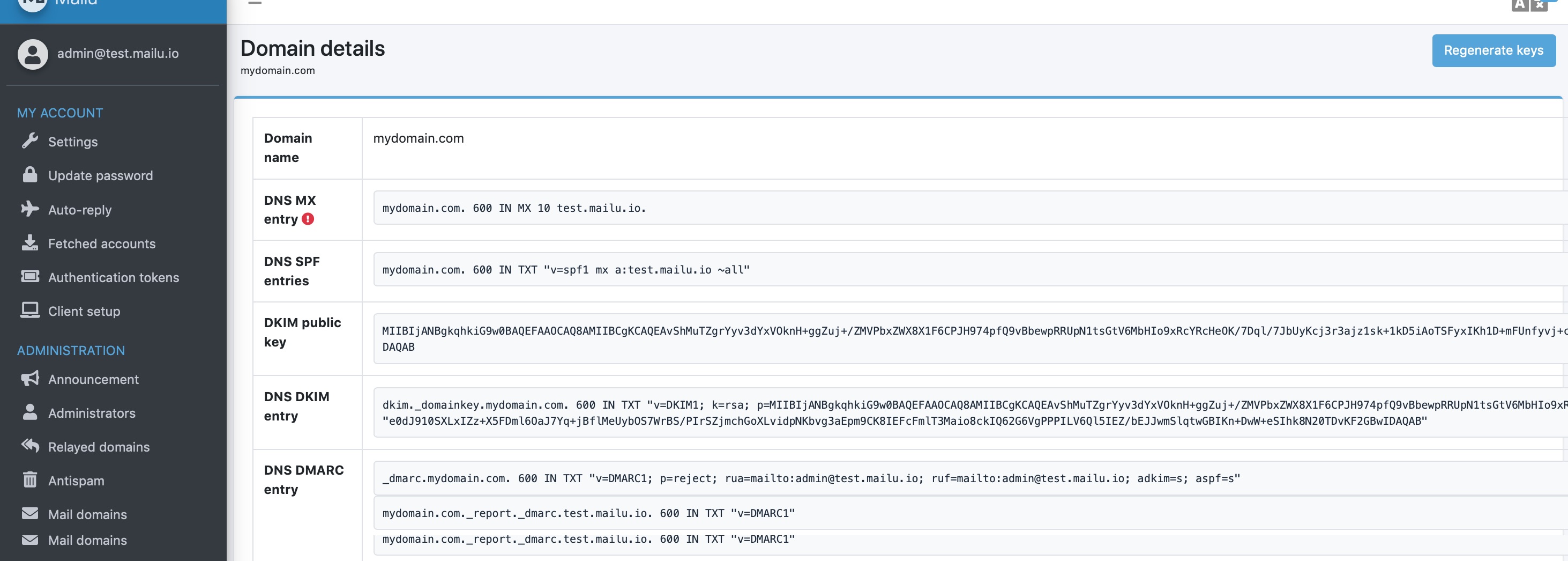
设置 DKIM
添加域名后在后台找到 DKIM,将其值拷贝出来,到 Cloudflare,或者任何 DNS 服务提供商添加 DKIM
添加信箱
在域名界面添加用户邮箱,这个用户邮箱之后就可以通过 [[webmail]] 来登录,发信或者收信。
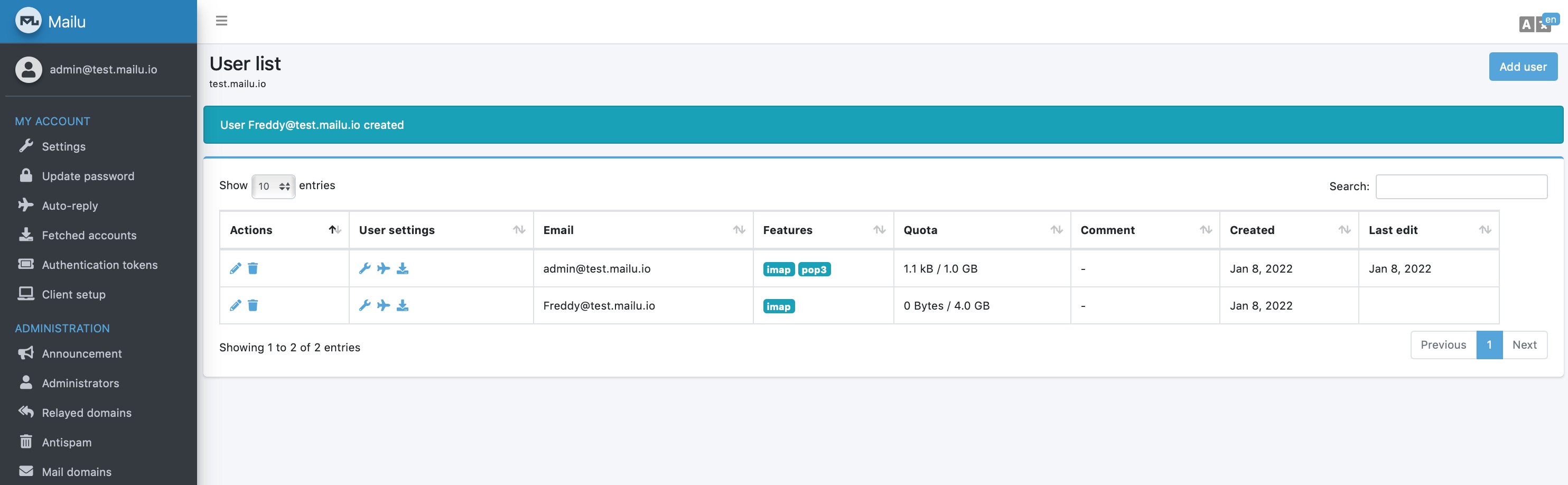
发信测试
最后可以使用 https://www.mail-tester.com/ 来发信测试。
推广
如果你不想自己搭建邮件服务器,那么也可以选购 EV Hosting 推出的域名邮箱托管服务,可以以极低的价格获得无限域名无限邮箱服务。
k3s k3d kind minikube microk8s 对比
在本地运行一个 [[Kubernetes]] 可以确保应用可以运行生产环境中。所以可以在本地运行一个类似于 [[minikube]] 的服务,提供一个 Kubernetes 环境。
Kubernetes 是一个 Google 开源的容器编排平台,提供了强大的自动化部署,扩容,管理功能。它提供了非常简单的方式来管理多台机器上的容器,并且提供了负载均衡,资源分配等方式来确保每一个应用都以最优的方式运行。
虽然 Kubernetes 被设计跑在云上,但是很多开发人员依然需要在本地跑起一个 Kubernetes,这就需要一些工具来帮助我们在本地设置这样的一个环境。本文就对比一下这些常用的工具。
K3s
[[k3s]] 是一个轻量级工具,旨在为低资源和远程位置的物联网和边缘设备运行生产级 Kubernetes 工作负载。 K3s 帮助你在本地计算机上使用 VMware 或 VirtualBox 等虚拟机运行一个简单、安全和优化的 Kubernetes 环境。
K3s 提供了一个基于虚拟机的 Kubernetes 环境。如果要设置多个 Kubernetes 服务器,你需要手动配置额外的虚拟机或节点,这可能相当具有挑战性。
然而,它是为在生产中使用而设计的,这使它成为本地模拟真实生产环境的最佳选择之一。要设置多个 Kubernetes 服务器,你需要手动配置额外的虚拟机或节点,这可能相当具有挑战性。
k3s 可以运行在极低的资源下,只需要 512 MB 内存即可运行。
K3d
K3d 是一个平台无关的轻量级包装器,在 docker 容器中运行 K3s。它有助于快速运行和扩展单节点或多节点的 K3S 集群,无需进一步设置,同时保持高可用性模式。
作为 K3s 的一个实现,K3d 分享了 K3s 的大部分功能和缺点;但是,它排除了多集群的创建。K3s 是专门为使用 Docker 容器的多个集群运行 K3s 而构建的,使其成为 K3s 的可扩展和改进版本。
Kind
Kind(Kubernetes in Docker)主要是为了测试 Kubernetes,它可以帮助你在本地和 CI 管道中使用 Docker 容器作为 “节点 “运行 Kubernetes 集群。
它是一个开源的 CNCF 认证的 Kubernetes 安装程序,支持高可用的多节点集群,并从其源头构建 Kubernetes 的发布版本。
microK8s
microK8s 由 Canonical 创建,是一个 Kubernetes 发行版,旨在运行快速、自愈和高可用的 Kubernetes 集群。它为在多个操作系统(包括 macOS、Linux 和 Windows)上快速、轻松地安装单节点和多节点集群进行了优化。
它是在云、本地开发环境以及边缘和物联网设备中运行 Kubernetes 的理想选择。它还可以在使用 ARM 或英特尔的独立系统中高效工作,如 Raspberry Pi。
和 minikube 不同的是,microK8s 可以在本地 Kubernetes 集群中运行多个节点。但 microK8s 的问题在于,它运行在 snap package 之下,它很难运行在不支持 snap 的 Linux 发行版之上。
minikube
minikube 是一个使用最广泛的、可以让用户在本地运行 Kubernetes 的工具。它提供了非常方便的方式可以让用户在不同操作系统上安装和运行单一的 Kubernetes 环境。minikube 通过虚拟机实现。它具有很多功能,如负载平衡、文件系统挂载和 FeatureGates。
尽管 minikube 是本地运行 Kubernetes 的最佳选择,但主要缺点是,它只能运行在单一节点上,也也就意味着本地搭建的 Kubernetes 集群中只能有单个节点–这使得它离生产型多节点 Kubernetes 环境有点远。
Katacoda
也可以通过线上教学平台如 Katacoda 上的免费课程来学习 Kubernetes,它们都是云托管的,你不需要自己安装,只不过你需要云供应商的集群需要付费。
reference
配置 MySQL master-master 双主同步
最近正好买了两台配置一样的 VPS,整理学习一下 MySQL 的双主同步配置。
假设有两台服务器,分别安装了 MariaDB。
Install MariaDB on Ubuntu 18.04
sudo apt update
sudo apt install mariadb-server
sudo mysql_secure_installation
两台机器的IP分别是:
- 10.10.10.1
- 10.10.10.2
首先配置第一台
修改 MySQL 配置 vi /etc/mysql/mariadb.conf.d/50-server.cnf:
server-id = 1
log_bin = /var/log/mysql/mysql-bin.log
binlog_do_db = demo
# bind-address = 127.0.0.1
- server-id, 服务ID
- log_bin, binlog 位置
- binlog_do_db,后面配置需要同步的数据库,如果需要同步多个数据,那么需要配置多行
- 然后注释
bind-address允许 MySQL 与外部通信,如果清楚自己需要从外网连接,可以设置0.0.0.0,不过要清楚如果允许 MySQL 从外部访问,可能带来数据安全问题
然后需要重启 MySQL:
sudo /etc/init.d/mysql restart
create login user
然后使用 sudo mysql -u root -p 登录,创建登录用户:
CREATE USER 'your_name'@'%' IDENTIFIED BY 'password';
grant all on *.* to 'your_name'@'%';
grant all privileges on *.* to 'your_name'@'%' with grant option;
这样可以在其他机器上通过 your_name 来访问 MySQL,而不是用 root。
create slave user
创建同步数据的账户,并授予复制权限:
create user 'slave_user'@'%' identified by 'password';
grant replication slave on *.* to 'demouser'@'%';
flush privileges;
最后执行:
show master status;
显示:
+------------------+----------+--------------+------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB |
+------------------+----------+--------------+------------------+
| mysql-bin.000002 | 741 | demo | |
+------------------+----------+--------------+------------------+
记住该信息,接下来在另外一台机器中需要使用。
配置另一台机器
同样,安装,修改配置,重启,然后登录。
不过需要注意的是在第二台机器中,需要将服务 ID 改成 2:
server-id = 2
然后执行:
stop slave;
CHANGE MASTER TO MASTER_HOST = '10.10.10.1', MASTER_USER = 'slave_user', MASTER_PASSWORD = 'password', MASTER_LOG_FILE = 'mysql-bin.000002', MASTER_LOG_POS = 741;
start slave;
然后在第二台机器,创建 slave_user 账号。
执行:
show master status;
MariaDB [(none)]> show master status;
+------------------+----------+--------------+------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB |
+------------------+----------+--------------+------------------+
| mysql-bin.000002 | 866 | demo | |
+------------------+----------+--------------+------------------+
同理,回到 10.10.10.1 第一台机器。
执行:
stop slave;
CHANGE MASTER TO MASTER_HOST = '10.10.10.2', MASTER_USER = 'slave_user', MASTER_PASSWORD = 'password', MASTER_LOG_FILE = 'mysql-bin.000002', MASTER_LOG_POS = 866;
start slave;
测试
因为上面的配置是同步了 demo 数据库,所以可以在 demo 数据库中创建表,然后分别在两台机器中查看。
use demo;
create table dummy(`id` varchar(10));
然后分别在两台机器中查看:
show tables;
然后删除表 drop table dummy。
可以通过如下命令查看 slave 状态:
show slave status\G;
Slave_IO_Running 及Slave_SQL_Running 进程必须正常运行,即 Yes 状态,否则说明同步失败 若失败查看 MySQL 错误日志中具体报错详情来进行问题定位。
配置解释
# 主数据库端ID号
server_id = 1
# 开启 binlog
log-bin = /var/log/mysql/mysql-bin.log
# 需要复制的数据库名,如果复制多个数据库,重复设置这个选项即可
binlog-do-db = demo
# 将从服务器从主服务器收到的更新记入到从服务器自己的二进制日志文件中
log-slave-updates
# 控制binlog的写入频率。每执行多少次事务写入一次(这个参数性能消耗很大,但可减小MySQL崩溃造成的损失)
sync_binlog = 1
# 这个参数一般用在主主同步中,用来错开自增值, 防止键值冲突
auto_increment_offset = 1
# 这个参数一般用在主主同步中,用来错开自增值, 防止键值冲突
auto_increment_increment = 1
# 二进制日志自动删除的天数,默认值为0,表示“没有自动删除”,启动时和二进制日志循环时可能删除
expire_logs_days = 7
# 将函数复制到slave
log_bin_trust_function_creators = 1
binlog-ignore-db 是 master 侧的设置,告诉 Master 不要记录列出的 DB 修改。
replicate-ignore-db 是一个 slave 侧的设置,告诉 Slave 忽略列出的 DB。
设置同步多个数据库
binlog-do-db=DATABASE_NAME1
binlog-do-db=DATABASE_NAME2
或者像这样忽略系统的,然后同步所有的
binlog_ignore_db = mysql
binlog_ignore_db = information_schema
binlog_ignore_db = performance_schema
bin log 管理
MySQL 会产生很多 mysql-bin.[index] 这样的 log 在系统中。不建议直接删除,可以使用 MySQL 内建的机制定期清理。
SET GLOBAL expire_logs_days = 3;
然后编辑配置 vi /etc/mysql/my.cnf:
[mysqld]
expire_logs_days=3
reference
使用 gdu 快速查看磁盘空间占用
gdu 是一个使用 Go 编写的,非常漂亮的磁盘空间占用分析工具。
直接运行 gdu 可以展示一个非常直观的磁盘空间占用。
gdu 为 SSD 做了优化,但在机械硬盘上也能很好的工作。
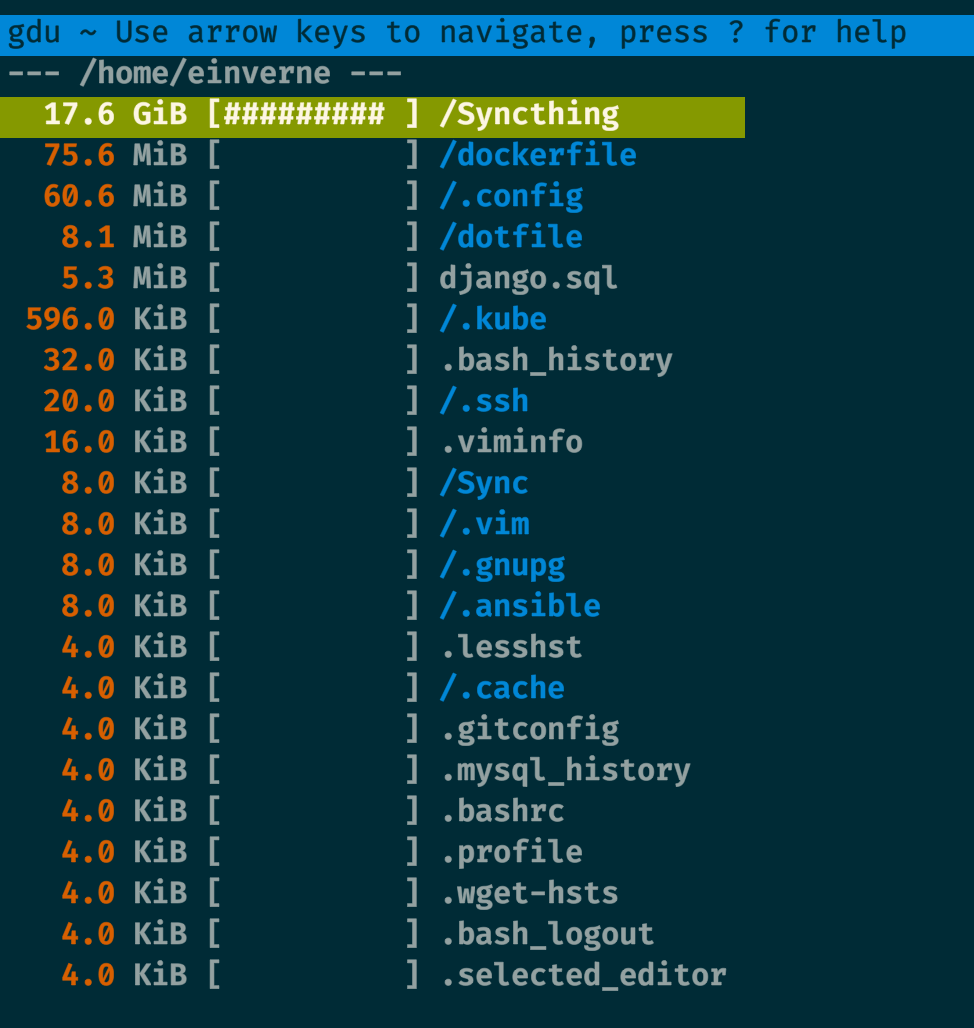
Install
Linux:
curl -L https://github.com/dundee/gdu/releases/latest/download/gdu_linux_amd64.tgz | tar xz
chmod +x gdu_linux_amd64
sudo mv gdu_linux_amd64 /usr/bin/gdu
macOS:
brew install -f gdu
brew link --overwrite gdu # if you have coreutils installed as well
在 macOS 下因为 gdu 和 coreutils 中的命名冲突了,所以 Brew 安装完成之后名字叫做 gdu-go。
Android Termux 安装:
wget https://github.com/dundee/gdu/releases/lastest/download/gdu_linux_arm64.tgz
tar xzvf gdu_linux_arm64.tgz
chmod +x gdu_linux_arm64
更多的安装方式可以参考 repo
Usage
gdu # analyze current dir
gdu -a # show apparent size instead of disk usage
gdu <some_dir_to_analyze> # analyze given dir
gdu -d # show all mounted disks
gdu -l ./gdu.log <some_dir> # write errors to log file
gdu -i /sys,/proc / # ignore some paths
gdu -I '.*[abc]+' # ignore paths by regular pattern
gdu -c / # use only white/gray/black colors
gdu -n / # only print stats, do not start interactive mode
gdu -np / # do not show progress, useful when using its output in a script
gdu / > file # write stats to file, do not start interactive mode
gdu -o- / | gzip -c >report.json.gz # write all info to JSON file for later analysis
zcat report.json.gz | gdu -f- # read analysis from file
手工编译安装 macOS 下的 Rime(鼠须管)
因为 macOS 下的 Rime 输入法(鼠须管) 不是经常更新二进制,所以要体验性特性总是要手工进行编译安装。
之前的想要 Rime 实现按下 Esc 切换为英文时,看到 commit history 有提交的时候就尝试手工编译安装了一下。一直都在笔记里面,现在整理一下发出来。
Prerequisites
安装 Xcode 12.2 及以上
首先从 App Store 中安装 Xcode 12.2 及以上版本。
如果只有 Xcode 10 只能编译 x86_64 的版本。
安装 cmake
从官网 下载安装。
或者从Homebrew 安装:
brew install cmake
或者从 MacPorts 安装:
port install cmake
Checkout the code
获取 Squirrel 的源码:
git clone --recursive https://github.com/rime/squirrel.git
cd squirrel
通过如下方式获取 Rime 的插件(这一步如果不需要可以跳过,不过建议安装特定的插件以提高使用舒适度):
bash librime/install-plugins.sh rime/librime-sample # ...
bash librime/install-plugins.sh hchunhui/librime-lua
bash librime/install-plugins.sh lotem/librime-octagram
添加两个插件 librime-lua,librime-octagram
- librime-lua 可以使用户可以编写 lua 脚本,编写函数来处理输出,比如在英文单词后面自动添加一个空格,或者当输入 date 或 「日期」的时候自动出现当前的日期。
- librime-octagram 是八股文插件,通过提前训练的模型增强 RIME 的长句组词能力
Shortcut: get the latest librime release
You have the option to skip the following two sections - building Boost and librime, by downloading the latest librime binary from GitHub releases.
可以直接执行如下命令从 GitHub release 页面下载编译好的 Boost 和 librime,跳过下面两个步骤:
bash ./travis-install.sh
准备工作做好之后,就可以开始编译 Squirrel
Install Boost C++ libraries
选择下面两种方式中的一个安装 Boost 库。
Option: 下载源码编译安装:.
export BUILD_UNIVERSAL=1
make -C librime xcode/thirdparty/boost
export BOOST_ROOT="$(pwd)/librime/thirdparty/src/boost_1_75_0"
Let’s set BUILD_UNIVERSAL to tell make that we are building Boost as
universal macOS binaries. Skip this if building only for the native architecture.
After Boost source code is downloaded and a few compiled libraries are built,
be sure to set shell variable BOOST_ROOT to its top level directory as above.
You may also set BOOST_ROOT to an existing Boost source tree before this step.
Option: 从 Homebrew 从安装:
brew install boost
Note: with this option, the built Squirrel.app is not portable because it links to locally installed libraries from Homebrew.
Learn more about the implications of this at https://github.com/rime/librime/blob/master/README-mac.md#install-boost-c-libraries
Option: 从 MacPorts 安装:
port install boost -no_static
Build dependencies
Again, set BUILD_UNIVERSAL to tell make that we are building librime as
universal macOS binaries. Skip this if building only for the native architecture.
Build librime, dependent third-party libraries and data files:
export BUILD_UNIVERSAL=1
make deps
Build Squirrel
当所有的依赖都安装准备好之后, 开始编译 Squirrel.app:
make
To build only for the native architecture, pass variable ARCHS to make:
# for Mac computers with Apple Silicon
make ARCHS='arm64'
# for Intel-based Mac
make ARCHS='x86_64'
Install it on your Mac
编译后之后就可以安装到系统上:
# Squirrel as a Universal app
make install
# for Intel-based Mac only
make ARCHS='x86_64' install
之后就可以享受完美的 Rime 输入法体验了。
Question
在 make ARCHS='x86_64' 的时候遇到错误:
CompileXIB /Users/einverne/Git/squirrel/zh-Hans.lproj/MainMenu.xib (in target 'Squirrel' from project 'Squirrel')
cd /Users/einverne/Git/squirrel
export XCODE_DEVELOPER_USR_PATH\=/Applications/Xcode.app/Contents/Developer/usr/bin/..
/Applications/Xcode.app/Contents/Developer/usr/bin/ibtool --errors --warnings --notices --module Squirrel --output-partial-info-plist /Users/einverne/Git/squirrel/build/Squirrel.build/Release/Squirrel.build/zh-Hans.lproj/MainMenu-PartialInfo.plist --auto-activate-custom-fonts --target-device mac --minimum-deployment-target 10.9 --output-format human-readable-text --compile /Users/einverne/Git/squirrel/build/Release/Squirrel.app/Contents/Resources/zh-Hans.lproj/MainMenu.nib /Users/einverne/Git/squirrel/zh-Hans.lproj/MainMenu.xib
Command CompileXIB failed with a nonzero exit code
** BUILD FAILED **
The following build commands failed:
CompileXIB /Users/einverne/Git/squirrel/Base.lproj/MainMenu.xib (in target 'Squirrel' from project 'Squirrel')
CompileXIB /Users/einverne/Git/squirrel/zh-Hant.lproj/MainMenu.xib (in target 'Squirrel' from project 'Squirrel')
CompileXIB /Users/einverne/Git/squirrel/zh-Hans.lproj/MainMenu.xib (in target 'Squirrel' from project 'Squirrel')
(3 failures)
make: *** [release] Error 65
- removing the old tools (
$ sudo rm -rf /Library/Developer/CommandLineTools) - install xcode command line tools again (
$ xcode-select --install).
ld: warning: directory not found for option '-L/usr/local/lib/Release'
ld: warning: directory not found for option '-L/Users/einverne/Git/squirrel/librime/thirdparty/lib/Release'
ld: library not found for -licudata
clang: error: linker command failed with exit code 1 (use -v to see invocation)
手工编译安装 librime
librime 是 Rime,包括各个系统上的桌面版,Squirrel(鼠须管) 等等依赖的核心库。
Preparation
首先要安装 Xcode 和命令行工具,以及必要的编译工具:
brew install cmake git
Get the code
获取代码:
git clone --recursive https://github.com/rime/librime.git
or download from GitHub, then get code for third party dependencies separately.
Install Boost C++ libraries
安装 Boost 库,Boost 库是一个 C++ 的第三方库,Rime 大量地依赖了这个库。
选择一 (推荐): 下载源码,手工编译:
cd librime
make xcode/thirdparty/boost
The make script will download Boost source tarball, extract it to
librime/thirdparty/src/boost_<version> and create needed static libraries
for building macOS uinversal binary.
Set shell variable BOOST_ROOT to the path to boost_<version> directory prior
to building librime.
export BOOST_ROOT="$(pwd)/thirdparty/src/boost_1_75_0"
选择 2: 从 Homebrew 安装 Boost 库:
brew install boost
如果你只想编译,并且安装到自己的 macOS 上,这是一个节省时间的选择。通过 Homebrew 中的 Boost 编译安装的 librime 可能不能在其他机器上完美的工作。
Built with Homebrewed version of Boost, the librime binary will not be
portable to machines without certain Homebrew formulae installed.
选择 3: Install an older version of Boost libraries from Homebrew.
Starting from version 1.68, boost::locale library from Homebrew depends on
icu4c, which is not provided by macOS.
Make target xcode/release-with-icu tells cmake to link to ICU libraries
installed locally with Homebrew. This is only required if building with the
librime-charcode plugin.
To make a portable build with this plugin, install an earlier version of
boost that wasn’t dependent on icu4c:
brew install boost@1.60
brew link --force boost@1.60
Build third-party libraries
Required third-party libraries other than Boost are included as git submodules:
# cd librime
# if you haven't checked out the submodules with git clone --recursive ..., do:
# git submodule update --init
make xcode/thirdparty
This builds libraries located at thirdparty/src/*, and installs the build
artifacts to thirdparty/include, thirdparty/lib and thirdparty/bin.
You can also build an individual library, eg. opencc, with:
make xcode/thirdparty/opencc
Build librime
make xcode
This creates build/lib/Release/librime*.dylib and command line tools
build/bin/Release/rime_*.
Or, create a debug build:
make xcode/debug
Run unit tests
make xcode/test
Or, test the debug build:
make xcode/test-debug
Try it in the console
(
cd debug/bin;
echo "congmingdeRime{space}shurufa" | Debug/rime_api_console
)
Use it as REPL, quit with Control+d:
(cd debug/bin; ./Debug/rime_api_console)
JWT 认证使用
现代 Web 应用一般常用的认证方式有如下两种:
- session
- cookie
session 认证需要服务端大量的逻辑处理,保证 session 一致性,并且需要花费一定的空间实现 session 的存储。
所以现代的 Web 应用倾向于使用客户端认证,在浏览器中就是 cookie 认证, 但是 Cookie 有明显的缺陷:
- Cookie 会有数量和长度限制
- Cookie 如果被拦截可能存在安全性问题
为什么要认证
数据安全:
- 进行安全的验证,服务端可以无状态认证
签名,只有信息发送者才能产生别人无法伪造的字串,这个字串同时是发送者真实信息的证明。
用户登录成功后,服务端产生 token 字串,并将字串下发客户端,客户端在之后的请求中携带 token。
Token 验证的优点
- 支持跨域访问,Cookie 不允许跨域访问
- 无状态,服务端不需要存储 session 信息,Token 自身包含了所有登录用户的信息
- 解耦,不需要绑定到一个特定的身份验证方案,Token 可以在任何地方生成
- 适用范围广,只要支持 HTTP 协议客户端就可以使用 Token 认证
- 服务端只需要验证 Token 安全,不必再获取登录用户信息
- 标准化,API 可以采用标准化的 JWT(JSON Web Token)
Token 的缺点
- 数据传输量大,Token 存储了用户相关的信息,比单纯的 Cookie 信息要多,传输过程中消耗更多的流量
- 和所有客户端认证方式一样,很难在服务端注销 Token,很难解决客户端劫持问题。并且 Token 一旦签发了,在到期之前就始终有效,除非服务器部署额外的逻辑
- Token 信息在服务端增加了一次验证数据完整性的操作,比 Session 认证方式增加了 CPU 开销
JWT
JSON Web Token(JWT) 是一个开放标准(RFC 7519),定义了紧凑、自包含的方式,用于 JSON 对象在各方之间传输。
JWT 实际就是一个字符串,三部分组成:
- 头部
- 载荷
- 签名
header
Header 由两部分组成,token 类型和算法名称(HMAC SHA256,RSA 等等)
{
"alg": "HS256",
"typ": "JWT"
}
payload
Payload 部分也是 JSON 对象,存放实际传输的数据,JWT 定义了7个官方的字段。
iss (issuer):签发人
exp (expiration time):过期时间
sub (subject):主题
aud (audience):受众
nbf (Not Before):生效时间
iat (Issued At):签发时间
jti (JWT ID):编号
可以添加任何字段:
{
"Name":"Ein Verne",
"Age":18
}
Signature
签名部分通过如下内容生成:
- 编码过的 header
- 编码过的 payload
- 一个密钥(只有服务端知道)
通过指定的签名算法加密:
HMACSHA256(base64UrlEncode(header) + "." + base64UrlEncode(payload), secret)
算出签名之后,header, payload, signature 三个部分拼成字符串,用 . 分隔,返回给用户。
Token 认证流程
- 客户端携带用户登录信息(用户名、密码)提交请求
- 服务端收到请求,验证登录信息,如果正确,则按照协议规定生成 Token,经过签名并返回给客户端
- 客户端收到 Token,保存在 Cookie 或其他地方,每次请求时都携带 Token
- 业务服务器收到请求,验证 Token 正确性
无论是 Token,Cookie 还是 Session 认证,一旦拿到客户端标识,都可以伪造。为了安全,任何一种认证方式都要考虑加入来源 IP 或白名单,过期时间。
JWT 如何保证安全性
JWT 安全性保证的关键就是 HMACSHA256,等等加密算法,该加密过程不可逆,无法从客户端的 Token 中解出密钥信息,所以可以认为 Token 是安全的,继而可以认为客户端调用是发送过来的 Token 是可信任的。
常用的 Python 库
pyjwt
常用的 Java 库
jjwt
auth0
<dependency>
<groupId>com.auth0</groupId>
<artifactId>java-jwt</artifactId>
<version>3.10.3</version>
</dependency>
用法:
public static String create(){
try {
Algorithm algorithm = Algorithm.HMAC256("secret");
String token = JWT.create()
.withIssuer("auth0")
.withSubject("subject")
.withClaim("name","古时的风筝")
.withClaim("introduce","英俊潇洒")
.sign(algorithm);
System.out.println(token);
return token;
} catch (JWTCreationException exception){
//Invalid Signing configuration / Couldn't convert Claims.
throw exception;
}
}
验证 Token
public static Boolean verify(String token){
try {
Algorithm algorithm = Algorithm.HMAC256("secret");
JWTVerifier verifier = JWT.require(algorithm)
.withIssuer("auth0")
.build(); //Reusable verifier instance
DecodedJWT jwt = verifier.verify(token);
String payload = jwt.getPayload();
String name = jwt.getClaim("name").asString();
String introduce = jwt.getClaim("introduce").asString();
System.out.println(payload);
System.out.println(name);
System.out.println(introduce);
return true;
} catch (JWTVerificationException exception){
//Invalid signature/claims
return false;
}
}
相关工具
reference
Duplicacy 增量备份工具使用
Duplicacy 是一个用 Go 语言实现的,开源的,跨平台的备份工具。
特性:
- 命令行版本对个人用户完全免费
- 付费授权会提供了一个网页端管理
- 支持 Amazon S3,Google Cloud Storage,Microsoft Azure,Dropbox 和 Backblaze 等云存储,本地磁盘,SFTP 等等
- 支持多个客户端备份到同一个云存储
- 支持增量备份
- 支持加密备份
Lock Free Deduplication
这是一个对 Duplicacy 实现原理的简单介绍,完整的说明可以参考发布在 IEEE Transactions on Cloud Computing 的 Paper。
Lock-Free Deduplication 的三个重要内容:
- 使用 variable-size chunking 算法将文件分割成多块
- 将每一块内容存储到云端空间,每一块的名字是其 hash,依赖文件系统的 API 来管理块,而不是用一个中心化的索引数据来管理
- 当备份被删除时使用 two-step fossil collection 算法移除未被引用的块
variable-size chunking 算法又被称为 Content-Defined Chunking,被很多备份工具使用。相较于固定大小的块划分算法(rsync 所使用的),
检查一个块是否被上传过,只需要通过文件名(hash)执行一个文件查询。这使得只提供了非常有限操作的云端存储变成了一个非常强大的现代化的备份工具后端,既可以实现 block-level 的重复数据删除,也可以实现 file-level 的重复数据删除。不依赖于一个中心的索引数据库也就意味着没有必要实现一个存储系统上的分布式锁。
通过消除 chunk indexing database, 无锁的备份不仅减少了代码复杂度,也使得删除重复的过程变得没那么容易出错。
但存在一个问题,当并发访问时,如果没有一个中心化的索引数据库,那么删除 snapshots 的操作就变得非常困难。单一节点去访问文件存储是可以保证的,但是删除的操作可以简化成搜索没有被任何备份引用的块,然后删除他们。但是如果并发的访问,那么一个未被引用的块就不能被轻易地移除,因为可能另外一个备份进程正在引用同一块。正在执行的备份程序可能并不知道删除进程,所以在扫描的过程中可能认为该块存在,而不上传该块,但是删除进程可能在此时删除了该块,那么就造成了数据丢失。
但幸运的是,Lock-free deduplication 的删除问题有一个解决方案,就是 two-step fossil collection algorithm。这个算法会使用两个步骤来删除未被引用的块:
- identify, collect them in the first step
- permanently remove them once certain conditions are met
安装
从项目 release 页面下载可执行二进制文件。
sudo wget -O /opt/duplicacy https://github.com/gilbertchen/duplicacy/releases/download/v2.0.10/duplicacy_linux_x64_2.0.10
sudo ln -s /opt/duplicacy /usr/local/bin/duplicacy
sudo chmod +x /usr/local/bin/duplicacy
macOS 下
https://github.com/gilbertchen/duplicacy/releases/download/v3.1.0/duplicacy_osx_arm64_3.1.0
前提知识
storage
在 Duplicacy 的概念中 storage 指的是备份存储的地方。这个地方可以是本地,也可以是 [[SFTP]],或者现成的云端存储服务比如 [[Backblaze]]。
repository
repository 可以理解成仓库,可以将一个本地文件夹作为仓库。
snapshot
snapshot 直译是快照,duplicacy backup 命令会将 repository 的一份本地快照备份到 storage。
使用
Duplicacy 相关的命令:
NAME:
duplicacy - A new generation cloud backup tool based on lock-free deduplication
USAGE:
duplicacy [global options] command [command options] [arguments...]
VERSION:
2.7.2 (175ADB)
COMMANDS:
init Initialize the storage if necessary and the current directory as the repository
backup Save a snapshot of the repository to the storage
restore Restore the repository to a previously saved snapshot
list List snapshots
check Check the integrity of snapshots
cat Print to stdout the specified file, or the snapshot content if no file is specified
diff Compare two snapshots or two revisions of a file
history Show the history of a file
prune Prune snapshots by revision, tag, or retention policy
password Change the storage password
add Add an additional storage to be used for the existing repository
set Change the options for the default or specified storage
copy Copy snapshots between compatible storages
info Show the information about the specified storage
benchmark Run a set of benchmarks to test download and upload speeds
help, h Shows a list of commands or help for one command
GLOBAL OPTIONS:
-verbose, -v show more detailed information
-debug, -d show even more detailed information, useful for debugging
-log enable log-style output
-stack print the stack trace when an error occurs
-no-script do not run script before or after command execution
-background read passwords, tokens, or keys only from keychain/keyring or env
-profile <address:port> enable the profiling tool and listen on the specified address:port
-comment add a comment to identify the process
-suppress, -s <id> [+] suppress logs with the specified id
-help, -h show help
初始化存储
Duplicacy 可以备份目录级别数据。
cd path/to/dir
duplicacy init mywork sftp://user@192.168.2.100/path/to/storage/
- mywork 是 duplicacy 用来区分备份的 snapshot_id,用来区分不用存储库的标签
- 远程的文件夹需要提前创建,duplicacy 不会自动创建文件。
开始备份
duplicacy backup -stats
每一次的备份都通过唯一的 repository id 和从 1 开始自增的 revision number 组成
备份
#默认命令
duplicacy backup
#如果有多个存储目标,可以用-storage指定存储名称
duplicacy backup -storage storage_name
查看快照
duplicacy list
# 查看指定存储的快照
duplicacy list -storage storage_name
# 查看所有存储的快照
duplicacy list -a
还原
可以使用如下的命令还原:
duplicacy restore -r revision_number
说明:
- 这里的 revision_number 可以通过
list命令查看。
删除历史快照
# 删除指定存储内所有快照
duplicacy prune -a
# 删除版本 2,`-r` 可以使用多次
duplicacy prune -r 2
# 删除一个范围
duplicacy prune -r 10-20
使用 -keep 选项可以指定保存策略,比如
duplicacy prune -keep 1:7
表示的是对于超过 7 天的版本,每天保留一个版本。总结一下,-keep 接受两个数字 n:m ,表示的是对于 m 天前的版本,每隔 n 天保留一个版本。如果 n 为 0,任何超过 m 天的版本会被删掉。
这样如果要实现删除 180 天前的版本:
duplicacy prune -keep 0:180
-keep 选项也可以使用多次,但是需要按照 m 值从大到小排列:
duplicacy prune -keep 0:180 -keep 7:30 -keep 1:7
备份到 Backblaze
[[Backblaze B2 Cloud Storage]] 提供了 10GB 免费存储空间
# 将本地存储加密备份到 B2 存储的 Bucket
duplicacy init -e repository_id b2://unique-bucket-name
执行命令后会需要输入 Backblaze 的 KeyID 和 applicationKey,这个在 Backblaze B2 后台可以查看。
执行备份:
duplicacy bacup
备份到多个存储
根据 [[3-2-1 备份原则]] 至少需要有三份完整的数据,其中一份必须在异地,Duplicacy 只需要添加多个存储即可实现多地备份。
cd path/to/dir
duplicacy init my-backups --storage-name backblaze b2://bucket-name
# add an additional storage
duplicacy add local snapshot_id /mnt/storage/
duplicacy add offsite_storage_name repository_id offsite_storage_url
说明:
add子命令和init命令相差不多,主要区别在于需要为新的存储指定一个名字。这里的offsite_storage_name可以是任何想要的名字,主要是为了助记。Duplicacy 的第一个存储空间默认的名字是 default。
当配置完成后使用 duplicacy backup 即可以实现多处备份。
如果只想要备份到一个地方,也可以使用 -storage 指定:
duplicacy backup -storage offsite_storage_name
另外一种推荐的做法是使用 copy 命令,将默认的存储内容复制到新配置的存储(offsite_storage) 上:
duplicacy copy -from default -to offsite_storage_name
恢复到另外的文件夹或恢复到另外的电脑
cd path/to/dir1
duplicacy init backup1 sftp://user@192.168.2.100/path/to/storage
duplicacy backup -stats
如果在当前的文件夹想要恢复,那么直接使用 duplicacy restore -r 1 即可。
但是如果要在另外的文件夹,或另一台机器上恢复呢,也非常简单
cd path/to/dir2
duplicacy init backup1 sftp://user@192.168.2.100/path/to/storage
duplicacy restore -r 1
这里需要注意备份的远端地址需要是一样的。比如上面的例子中都使用 SFTP 的地址。
Duplicacy 支持的 Storage
Local
本地文件的话,直接写文件路径:
/path/to/backup
SFTP
SFTP 语法:
sftp://username@server
Dropbox
Storage URL:
dropbox://path/to/storage
- 通过 Dropbox Developer 生成 Access Token。
- 或者通过 Link 来获取 Access Token。
Amazon S3
s3://amazon.com/bucket/path/to/storage (default region is us-east-1)
s3://region@amazon.com/bucket/path/to/storage (other regions must be specified)
需要提供 access key 和 secret key.
| 支持 [[2021-07-24-minio-usage | MinIO 自建对象存储]]: |
minio://region@host/bucket/path/to/storage (without TLS)
minios://region@host/bucket/path/to/storage (with TLS)
其他 S3 兼容的存储:
s3c://region@host/bucket/path/to/storage
Wasabi
wasabi://region@s3.wasabisys.com/bucket/path
wasabi://us-east-1@s3.wasabisys.com/bucket/path
wasabi://us-east-2@s3.us-east-2.wasabisys.com/bucket/path
wasabi://us-west-1@s3.us-west-1.wasabisys.com/bucket/path
wasabi://eu-central-1@s3.eu-central-1.wasabisys.com/bucket/path
DigitalOcean Spaces
s3://nyc3@nyc3.digitaloceanspaces.com/bucket/path/to/storage
Google Cloud Storage
gcs://bucket/path/to/storage
Google Cloud Storage 也可以在设置中开启 S3 兼容 那就可以使用:
s3://storage.googleapis.com/bucket/path/to/storage
Microsoft Azure
azure://account/container
NetApp StorageGRID
s3://us-east-1@storagegrid.netapp.com/bucket/path/to/storage
Backblaze B2
b2://bucketname
Google Drive
gcd://path/to/storage (for My Drive)
gcd://shareddrive@path/to/storage (for Shared Drive)
Microsoft OneDrive
one://path/to/storage (for OneDrive Personal)
odb://path/to/storage (for OneDrive Business)
Hubic
hubic://path/to/storage
OpenStack Swift
swift://user@auth_url/container/path
WebDAV
[[WebDAV]] 链接:
webdav://username@server/path/to/storage (path relative to the home directory)
webdav://username@server//path/to/storage (absolute path with double `//`)
更多的 Storage URL 可以参考这里
备份脚本
#!/bin/bash
#关闭服务
#duplicacy变量
export DUPLICACY_B2_ID=b2_id
export DUPLICACY_B2_KEY=b2_key
export DUPLICACY_PASSWORD=your_password
#导出数据库
cd /data/mysql/
/usr/local/mysql/bin/mysqldump -h 127.0.0.1 -P 3306 --all-databases > /data/mysql/all.sql
zip -mqP password ./all.sql.zip ./all.sql
#增量备份mysql文件夹
cd /data/mysql/
duplicacy backup
#增量备份wordpress文件夹
cd /home/wordpress/
duplicacy backup
#删除60天前的快照,超过30天的快照每15天保留一个
duplicacy prune -all -keep 0:60 -keep 15:30
#启动服务
Duplicacy vs duplicity
Duplicacy 和 duplicity 相比较而言,Duplicacy 在备份很多次的情况下会比 duplicity 占用更多的空间,但是 Duplicacy 每一次备份的时间都要远远少于 duplicity。
duplicity 有一个严重的缺陷在于其增量备份方法,每一次备份都需要用户选择是否全量备份或者增量备份,并且其设计决定了在一个备份了很多次的仓库中删除任何一个历史的备份变得不可能。
具体的比较可以参考这里。
reference
使用 Netdata Cloud 监控所有的机器
很早就开始用 Netdata,新买来的 VPS 直接一行命令就可以安装,并且提供了一个非常不错的监控后台。但是因为没有办法在一个中心化的地方管理我所有的机器,所以之前都是用一个简单的 nodequery 服务来监控服务器是否在线,CPU、内存、流量使用率,但 nodequery 已经很多年没有更新,而最近去看 Netdata 官网的时候发现其退出了一个 Netdata Cloud 的服务,体验下来确实直接可以代替 nodequery 了。
什么是 Netdata Cloud
[[Netdata]] 是一款非常漂亮并且非常强大的监控面板,由于 Netdata 并没有提供验证等等功能,所以一旦启动,所有人都可以通过 IP:19999 来访问监控面板,虽然 Netdata 做了充分的安全检查,后台面板对系统只读,黑客或破坏分子并不能通过监控面板来控制系统,但是有心人还是能够通过面板来看出系统运行的服务,从而进行破坏,所以一般会通过反向代理或放在防火墙后面来规避安全问题,但与此同时带来的管理上的困难。
在之前 Netdata 没有提供 Netdata Cloud 服务之前,需要自己配置防火墙,只允许特定 IP 访问;或者配置反向代理,通过密码进行保护1。现在通过 Netdata Cloud 多了一种完美的解决方案,我们可以将 Netdata 数据添加到 Cloud,然后禁用本地暴露在 19999 端口的面板。
并且通过 Cloud 后台,可以在一个中心化的地方监控到所有机器的状况,并且 Netdata Cloud 还提供了免费的邮件报警服务。
安全性
- Netdata 提供了他们的数据隐私政策
- 所有的数据在传输过程中都通过 TLS 加密过
基础概念
虽然 Netdata Cloud 服务并不复杂,但这里还是要提前把一些概念理清楚一下。
Node
每一台机器都都相当于一个节点。
War Rooms
War Rooms 组织节点,提供了跨节点的视图。可以认为 War Rooms 是一系列节点的合集。
几种方式管理 War Rooms:
- 根据服务(Nginx,MySQL,Pulsar 等等),目的(webserver, database, application),地点(服务器真实地址)等等来管理,比如可以根据
- 将整个后端基础架构放到 War Rooms 管理,可以是 Kubernetes cluster, proxies, databases, web servers, brokers 等等
Spaces
Spaces 是一个高层级的抽象,用来管理团队成员和节点。Spaces 下面会有不同的 War Rooms。这也就意味着通过 Space 可以让成员和节点在一起。
这样也就可以将特定的后台分配给不同的成员。
将 Netdata Agent 添加到 Netdata Cloud
使用 docker exec 将已经在运行的节点添加到 Netdata
docker exec -it netdata netdata-claim.sh -token=TOKEN -rooms=ROOM1,ROOM2 -url=https://app.netdata.cloud
其中:
- TOKEN 需要替换
- ROOM1,ROOM2 替换成自己的
禁用本地面板
编辑 vi /etc/netdata/netdata.conf 配置文件:
找到 bind to 这样行,修改为:
[web]
bind to = 127.0.0.1 ::1
然后重启 sudo systemctl restart netdata
对于 Docker 安装的,直接在配置中将 19999 的端口映射移除即可。
文章分类
最近文章
- 从 Buffer 消费图学习 CCPM 项目管理方法 CCPM(Critical Chain Project Management)中文叫做关键链项目管理方法,是 Eliyahu M. Goldratt 在其著作 Critical Chain 中踢出来的项目管理方法,它侧重于项目执行所需要的资源,通过识别和管理项目关键链的方法来有效的监控项目工期,以及提高项目交付率。
- AI Shell 让 AI 在命令行下提供 Shell 命令 AI Shell 是一款在命令行下的 AI 自动补全工具,当你想要实现一个功能,敲一大段命令又记不住的时候,使用自然语言让 AI 给你生成一个可执行的命令,然后确认之后执行。
- 最棒的 Navidrome 音乐客户端 Sonixd(Feishin) Sonixd 是一款跨平台的音乐播放器,可以使用 [[Subsonic API]],兼容 Jellyfin,[[Navidrome]],Airsonic,Airsonic-Advanced,Gonic,Astiga 等等服务端。 Sonixd 是一款跨平台的音乐播放器,可以使用 [[Subsonic API]],兼容 Jellyfin,[[Navidrome]],Airsonic,Airsonic-Advanced,Gonic,Astiga 等等服务端。
- 中心化加密货币交易所 Gate 注册以及认证 Gate.io 是一个中心化的加密货币交易所。Gate 中文通常被称为「芝麻开门」,Gate 创立于 2013 年,前身是比特儿,是一家致力于安全、稳定的数字货币交易所,支持超过 1600 种数字货币的交易,提供超过 2700 个交易对。
- 不重启的情况下重新加载 rTorrent 配置文件 因为我在 Screen 下使用 rTorrent,最近经常调试修改 rtorrent.rc 配置文件,所以想要找一个方法可以在不重启 rTorrent 的情况重新加载配置文件,网上调查了一下之后发现原来挺简单的。