GitHub Code Search 使用小技巧
前两天收到 GitHub Code Search 的申请通过邮件,现在可以使用 https://cs.github.com 来作为之前的搜索的代替了,从第一手直观的感受来看就是更加精准的搜索,能根据文件名,代码方法,编程语言等等来进行搜索。
这里就只简单的记录一下我的使用体验,更加详细的使用指南请参考官方文档。
概念
在进入下面的使用体验之前先了解一下 GitHub Code Search 中的一些概念。
理解 Scope
在 GitHub Code Search 中可以通过 Scope 来定义搜索的范围。
Scope 在字典里面的解释也比较直观:
the range of things that a subject, an organization, an activity, etc deals with
中文一般翻译成「范围」。
GitHub 有一些约定:
- 必须登录 GitHub 账号才可以搜索全部公开的仓库
- 在 forks 中的代码只有当 stars 数超过父仓库时才会被列入索引,当需要搜索 star 数超过父项目的仓库时,需要使用
fork:true或者fork:only参数。更多可以参考如何搜索forks - 只有默认的分支会被索引
- 只有小于 384KB 的文件会被索引
- 只有小于 500000 个文件的仓库能被搜索
- 只有在过去一年中有活动的,或者在搜索结果中有记录的仓库才能被搜索
- 除了 filename 的搜索,必须至少有一个关键字才能搜索,比如,搜索
language:javascript不是合法的,只有amazong language:javascript才是合法的 - 搜索结果中只会显示同一个文件的两个片段,但是有可能在文件中会存在更多的符合结果的内容
-
搜索中不能包含
. , : ; / \ ` ' " = * ! ? # $ & + ^ | ~ < > ( ) { } [ ] @
qualifiers
Code Search 中提供了一些修饰语语法,可以用来对搜索结果做限定。
- 限定在某仓库中 (eg.
repo:github/primer) - 限定在组织中 (eg.
org:github或者user:colinwm) - 限定语言
language:python - 限定文件路径
path:README.md - Symbol qualifier
symbol:scanbytes - 限定内容
content:hello
正则
Code Search 还支持使用正则表达式来搜索:
/git.*push/
正则表达式需要使用 / 作为范围,上面的搜索词就会搜索所有以 git 开头 push 结束的内容。
记住如果要在其中使用 / 那么需要进行转义,比如搜索目录 App/src:
/^App\/src\//
正确匹配
正常情况下搜索 hello world 相当于搜索 hello AND world 这两个词可能不连在一起,如果要精确地查找搜索词,可以使用双引号:
"hello world"
Boolean operations
Code search 支持几种常用的搜索连接词:
- AND
- OR
- NOT
可以使用括号来改变优先级:
(language:ruby OR language:python) AND NOT path:"/tests/"
可以点击这里加入到 waitlist
使用
搜索样例
过去几天我最常用的就是搜索学习别人是如何写 docker-compose.yml 文件的,因为最近在学习 Traefik 入门使用 所以把历史上用 Nginx-proxy 反向代理的一些服务重新配置了一下。因为 Traefiki 的配置语法略微复杂,我先阅读了一遍 Traefik 官网的文档,了解了一些基础概念,然后因为官网没有整体配置的一个样例,我就觉得直接看完整的项目配置比较快,所以直接用 Code Search 搜索一些完整的配置进行学习。
比如把 [[Vaultwarden]],[[NextCloud]] 等,这个时候我就使用搜索语法:
bitwarden path:docker-compose.yml
nextcloud path:docker-compose.yml
搜索出来一些结果然后学习,然后配置的过程中还发现了不少很好的项目。
搜索配置
之前在配置 ArchiveBox 服务的 ArchiveBox.conf 的时候,直接搜索该文件直接可以找到对应的官网仓库的样例配置,依照样例配置进行自己的修改。
关键字搜索
我常用的另外一个比较多的场景就是搜索错误代码或者错误描述,常常在 IDE 中当然也能搜索,但是有些大型的库常常我本地没有索引所以搜索起来可能比较慢,这个时候拿到错误直接到界面搜索,反而可以更快的定位到问题。这个时候只需要限定仓库的位置,然后加上错误描述即可。
reference
小米平板 5 Pro 初体验及设置
年初的时候去线下做了一下体验,觉得小米平板 5 在影音和阅读方面还能胜任,所以就购入了一台小米平板 5 Pro,日常可能就用来阅读 PDF 和用来看视频。
选购思路
为什么买 Android 平板?
因为我重度使用的应用,比如 [[Syncthing]], [[Obsidian]], [[静读天下 Moon+Reader]] 等等在 Android 下运行良好,我也不需要 iPad 那些独占的功能。
而且 Android 的开放性比较好,安上 Termux,甚至能够在 Android 环境下使用 Linux ,简单的 ssh 命令也可以瞬间让平板成为一个连接远程服务器的利器。
小米平板对比三星,联想平板?
说实话在没有体验小米平板 5 之前,我一直观望的是三星的平板,毕竟在那几年里面,Android 平板几乎消失,在这两年 iPad 生态逐渐强大,各大 Android 厂商才又将 Android 平板拿起来,但 Android 平板和 iOS 的差距很快就被系统的扩展性赶上了,虽然应用的适配和兼容性可能无法赶上 iPad,一些精品的应用体验,比如书写,绘画可能也无法短时间内追赶上 iPad,但是在体验了一番 MIUI 之后,感觉小窗模式,分屏模式还是稍微超出了我的预期,所以,想买过来深度再体验一下。
小米平板 5 对比 5 Pro 版本?
在硬件方面,
- Pro 版本采用 870 芯片,略强于 860
- 扬声器方面,内置八个扬声器,外加杜比音效,好过 5 的四个扬声器
- 运行内存,Pro 版本 LPDDR5+UFS 3.1,普通版本 LPDDR4x+UFS 3.1,但这一点差距似乎对整体影响并不突出
- 后置摄像头,Pro 版本后置双摄1300万像素+500万景深镜头,5 只有单摄 1300 万像素,不过好像我也不会拿平板去拍照,这个不太重要
- Pro 支持蓝牙 5.2,普通版本只支持蓝牙 5.0
- 充电方面,Pro 支持 67W 快充,5 默认带 33W 充电
- Pro 版本带有指纹解锁
- Pro 版本电池 8600 毫安,而 5 略微大一些,为 8720 毫安
而二者的屏幕都是一块 11 英寸的 IPS LCD,带 120Hz 的刷新率,分辨率是 1600*2560.
Pro 版本多出了一个指纹解锁,CPU 更好一些,我愿意为这点升级补差价。
Termux 初始化
之前就已经知道 Termux 可以在 Android 上模拟出一套 GNU/Linux 环境,所以直接更新一套初始化脚本到我的 dotfiles。
配件
小米平板 5 Pro 自带的两个配件有一只笔和一个键盘,当时买完就脑袋一发热买了一个键盘,虽然日常还是会用到,但感觉似乎任何一个蓝牙键盘都可以代替,除了便携性好一些之外没有太多想说的。键盘的手感也只是能用而已。
笔的话,我没有购买,因为我觉得不会在这个平板上面来写字做笔记,如果是看 PDF 的需求,我还有 Boox Note 2 ,自带的笔已经够用了。
认识 Linux 下 btmp 日志文件
查看 VPS 日志的时候发现 /var/log/ 下存在一个 100M+ 大小的 btmp 文件,我知道 /var/log 目录下一般都是 Linux 系统的日志存放路径,通常 auth.log 会记录登录相关的日志,其他的 Nginx,PHP,dpkg,syslog 等等都比较熟悉,唯一没见过的就是 btmp 文件。所以简单记录一下。
btmp 文件也是日志文件,不过仅仅记录失败的登录。这也就意味着有人尝试暴力登录我的服务器。
和 btmp 相关的日志文件还有两个:
- utmp 文件记录用户登录信息,包括用户登录的终端,登出状态,系统时间,当前系统的状态,系统启动的时间(被 uptime 命令使用)等等
- wtmp 会记录 utmp 文件的历史记录,包括了当前登录用户信息和历史用户登录信息
以上三个文件都是二进制数据。
查看 btmp 文件
btmp 文件不是一个纯文本的文件,所以不能直接使用 less, cat 查看,需要借助 last 命令:
last -f /var/log/btmp
last -f /var/log/wtmp
last -f /var/log/utmp
如果直接执行 last 不带任何参数,则会展现用户什么时候登录,什么时候登出的。
也可以使用 lastb 命令,默认会读取 /var/log/btmp 文件。
另外也可以使用 utmpdump 命令将二进制文件转成文本文件查看。
utmpdump /var/log/btmp
遇到 btmp 文件过大的情况下的安全措施
上文提到过 btmp 只会记录失败的登录,如果这个文件增长很快那么也就意味着有人在不断尝试登录,可能就是在暴力尝试,在上面的日志文件中也能看到很多 root 尝试登录,也有很多默认的用户在不停尝试。这个时候就需要特别注意一下系统的安全。
通常情况下,在刚初始化系统的时候这些安全措施就需要补全。
通常在配置了 [[fail2ban]] 之后就会好很多了。
reference
在线数据泄漏查询网站
have i been pwned
have i been pwned? 是一个提供了查询电子邮件、电话号码、密码等是否被泄漏的在线网站。该网站提供了过去几十年中的各大数据泄漏事件。用户注册账户之后,可以在数据被泄漏的第一时间收到提醒。
这一次 Twitter 的 2 亿多条数据泄漏,包括邮箱,用户名,手机号等,就是 have i been pwned 第一事件发送了提醒。
Firefox Monitor
Firefox Monitor 是由 Mozilla 开发的,在 Firefox 上提供的一项服务,可以帮助用户检查电子邮件或者密码有没有被泄漏。
在网站上输入电子邮箱地址,Firefox Monitor 会在自己的数据库中查询历史上曾经发生的数据泄露事件中有没有泄漏查询的数据,对于保护用户个人的网络安全非常有用。
在 Obsidian 中集成 GPT-3 提高输入效率
前两天在 Twitter 上发了一个贴子,说如果 [[Obsidian]] 中能继承 [[ChatGPT]] 和 [[GitHub Copilot]] 就好了,我想来虽然也可以在 IntelliJ 和 VSCode 中打开本地的笔记仓库,但是一个礼拜前我尝试了一下用 VSCode 打开,竟然比 Obsidian 还卡,不知道哪里除了问题,所以只能再切换回 Obsidian。好在发帖没多久就发现了 Text Generator 这个插件,用 GTP-3 的 API 驱动的文字生成,并且在调研的过程中又还发现了 Obisidain 下不少能提高输入效率的工具,这里就一切总结一下。
文本生成
使用 Text Generator 生成文本
- 在 Obsidian 下安装 Text Generator 插件
- 获取 OpenAI API Key
- 登录 OpenAI 官网,点击 Account,然后点击
View API keys,或者直接访问 OpenAI API key
- 登录 OpenAI 官网,点击 Account,然后点击
- 使用
cmd+j快捷键
使用方式
- 第一种方式,在记笔记的过程中,使用快捷键
cmd+j,让 Text Generator 续写后文内容。 - 第二种方式是使用左侧边栏上的按钮
文本扩展
Text Expander 类的工具是将用户的输入自动扩展成一个更长的内容,通常用来快速输入某些内容。因为我已经有了很多方法来实现 Text Expander(文本扩展),就没有使用 Obsidian 中的插件。
我个人使用的文本扩展方法主要有两个:
- [[RIME]] 中的缩略语
- [[Espanso]] 使用指南
这两个工具一直都秉持我的理念,开源,跨平台,并且可以通过文本的方式配置。
RIME
RIME 是中州韻輸入法引擎 (Rime Input Method Engine) 的缩写,由 RIME 扩展出了不同平台上的输入法,小狼毫,中州韵,鼠须管等等,在 RIME 中可以配置自定义词库,然后在输入法中,通过自定义的映射来实现快速输入。
比如在自定义短语中配置:
MySQL mysql 100
我看下 wkx 30
就可以实现在输入 mysql 的时候自动修正为 MySQL,在输入 wkx 的时候扩展成 我看下。通过进阶的 lua 脚本也可以实现输入 date 自动扩展成当前日期等等。
Espanso
Espanso 是一款是 Rust 编写的跨平台的 Text Expander。Espanso 可以通过纯文本配置 来设定文本的扩展。

比如演示中输入 :date 自动扩展成日期。为了防止误扩展,一般都会在缩略词前面加上冒号。
related
- [[HuggingFace]]
reference
Logseq 第一次试用记录以及发布 Logseq 到网页
早之前在使用 [[Obsidian]] 的时候就有了解过 [[Logseq]] 但一直没有找到机会去尝试一下,毕竟我从 [[WizNote]] 迁移到 Obsidian 之后使用一直没有遇到任何问题,毕竟 Obsidian 够简单,也足够扩展性,并且基于 Markdown 文件的笔记是我过去一直在使用的方式。但现在让我有尝试使用一下 Logseq 的契机是因为在以前我都是使用 Vault 存放所有的笔记,然后使用其中一个 Blog 目录存放我想发布的内容,这样每一次我想发布一个具体的文章的时候就可以直接将文件移动到 Blog/_posts 目录之下,然后 Git 提交即可,但这个发布存在的问题便是其中的特殊双向链接 [[]] 会在页面上有些违和,而我看到 Logseq 可以将页面直接以 HTML 方式发布,并且也可以非常好的处理双向链接的问题,于是想来试一试。
Logseq 官方的文档 便是一个非常好的例子,展示界面几乎和用户的编辑页面是一致的,在线浏览也没有任何卡顿的情况。
Logseq 和 Obsidian 存在的区别
block
上手体验的第一个非常大的区别就在于 Logseq 有 block 的概念,这个概念可能是从 Roam Research 中借用而来,不像 Obsidian 整个文档就是一个 markdown 文件,所以每一行文字其实还是段落,但是 Logseq 中每一次 “Enter” 都创建了一个 block。Logseq 中使用 ((uuid)) 的语法来引用 block。有了 block 的概念之后就会发现其实文档内容的最小单元变成了 block,而在 Obsidian 中我能使用的最小单元也无非是通过 # 来划分出来的页面的段落。这可能是 Logseq 更加灵活的地方,但因为目前我还没有想好怎么使用这个 block 所以之后有了具体的使用场景再来分享。
command
Obsidian 中的 Command 和 Logseq 中的 Command 在使用起来还有一些区别,我设定了 Ctrl + P 来调用 Obsidian 中的 Command Palette,而这其中的命令大部分是对整个文档,或者部分内容进行的调整。而在 Logseq 中,在任何页面中使用 / 都可以进行响应的插入,/ 更像是 Notion 的方式,通过 / 来快捷调用复杂的输入操作,比如插入页面引用、块引用、标题、图片等等。
但我个人觉得在 / 中提示输入标题有些累赘,我个人的习惯一般不会在一篇文章中使用三级标题以上的子标题,那这也就意味着我只会使用 1~3 个 #,那么在纯 markdown 文档中,输入 # 要远比先输入 / 然后搜索对应的标题,选中要来的快,即使是输入三个 # 也会比 / 快。
/ 让我觉得最重要的就应该是页面引用和块引用了,通过模糊搜索,在笔记和笔记之间建立关系使用 / 就大大简化的。而在 Obsidian 中我就只能使用 [[ 来进行页面的关联。
vim mode
Obsidian 让我直接上手的一个非常重要的原因就是开箱支持的 Vim 模式,我几乎没有想就启用了,并且一直使用到现在,这无非只是让我在终端的笔记转移到了 Obsidian,并且我熟悉而这个快捷键,命令都可以直接使用,这也让我在终端,IntelliJ IDEA,浏览器 Vimium 达成了统一。而 Logseq 开箱就是所见即所得的界面,当然普通使用起来是没有问题的,但用起来就慢慢地发现有些别扭,比如在上一行插入,或者快速跳转到页尾,以前非常熟悉的 O 或者 G 突然没有了就有些陌生。
然后再看到 Logseq 的 Feature Request ,大家对 Vim-mode 的讨论,要求支持还是挺多,不过截止目前还用不了。
分享
就像上面提到的一样,让我试用 Logseq 最重要的一个原因就是 Logseq 生成在线文档的能力,因为我之前使用 Jekyll 的文档分享部分 Obsidian Vault 中的内容就没有购买 Obsidian Publish 服务,因为一来我觉得 Jekyll 够用,然后 Obsidian Publish 服务的页面最初的时候访问优点慢,并且早鸟价 8$ 一个月的价格也有些高。但后来在使用的过程中还是会有一些些的不便,毕竟双向链接如果没有特殊的处理会显得有些奇怪。
Tag 使用
在 Logseq 中使用 #tag 新建 tag,当点击 tag 的时候会创建新的页面,而在 Obsidian 中 #tag 就只是页面的一个元数据,标签。在 Logseq 中可以点击 tag 页面来查看所有该标签下的页面和块,而在 Obsidian 中我通常是使用搜索。
Logseq 中特殊的语法
Logseq 中使用 key:: value 格式来对页面或块进行属性设置,页面的属性在页面的第一个块定义,作为 frontmatter,块属性可以在任何块中定义。
Logseq 中的 Properties 的两大作用:
- Query,可以通过查询语法来将带有 property 的内容检索出来
- 定义 Page/Block 的通用属性,比如想要有一个模板,当记录一本书的时候自动会有相应的属性
Obsidian 搭配 Logseq 使用
在上面的使用过程中,我一直使用 Git 来追踪 Logseq 界面中修改了文档之后在原始文档中的体现,大体来看如果没有使用 Logseq 自身的特殊语法,大致还是兼容 markdown 语法的。
所以我想到了如果将 Logseq 仓库存放在 Obsidian Vault 中,那么其实和我之前使用 Jekyll 发布内容的方式就是一致的了,我只需要把需要发布的内容移动到 Logseq 文件夹下即可。比如说我的 Logseq 仓库叫做 notes,那么他下面会有一个 pages 文件夹,存放的都是 Logseq 中的笔记原始文件。那么我将整个 notes 作为我 Obsidian Vault 的一部分,那么我既可以在 Obsidian 中编辑这些笔记,也可以用 Logseq 打开这个子文件夹来编辑。我只需要使用 Logseq 兼容的语法,那么每一次提交,然后推送到 GitHub 之后,就可以利用 GitHub Actions 自动发布。
Obsidian Vault 是一个独立的仓库,然后使用 git submodule 将 Logseq 仓库添加到其中,还可以利用版本控制来管理。
将 Logseq 发布到 GitHub Pages
这里使用 pengx17 的 Logseq-publish 的 GitHub Action,在个人仓库下创建 .github/workflows/main.yml 文件,根据自己的情况填入配置:
name: CI
# Controls when the workflow will run
on:
push:
branches: [master]
# Allows you to run this workflow manually from the Actions tab
workflow_dispatch:
# A workflow run is made up of one or more jobs that can run sequentially or in parallel
jobs:
# This workflow contains a single job called "build"
build:
# The type of runner that the job will run on
runs-on: ubuntu-latest
# Steps represent a sequence of tasks that will be executed as part of the job
steps:
# Checks-out your repository under $GITHUB_WORKSPACE, so your job can access it
- uses: actions/checkout@v2
- name: Logseq Publish
uses: pengx17/logseq-publish@main
- name: add a nojekyll file
run: touch $GITHUB_WORKSPACE/www/.nojekyll
- name: Deploy
uses: JamesIves/github-pages-deploy-action@v4
with:
branch: gh-pages # The branch the action should deploy to.
folder: www # The folder the action should deploy.
clean: true
single-commit: true
然后每一次 push 之后会自动触发 build,将静态 HTML 文件发布到 gh-pages 分支中。然后在 GitHub 仓库设置界面 Pages 中设置域名即可。
我发布的内容 https://notes.einverne.info
2021 年读书笔记
根据豆瓣的记录,今年读了 48 本书,没去年读哲学、金融那么入迷,所以大部分的读书记录还是集中在了前两个季度。
之间几年的读书笔记:
哲学
因为去年政治学的著作,所以想要开始读一些西方哲学史相关的内容,但柏拉图、苏格拉底等著作目前又无法直接读懂,需要借助大量的二手著作,二次解读,所以经过了去年大量[[洛克]]的作品之后,今年第一季度就读了很多[[卢梭]]的作品:
- [[社会契约论]],这是卢梭关于政治学的一本著作,其大名应该很多人都知道,尤其是其中最著名的一句话「人生而自由,却无往不在枷锁之中。自以为能掌控一切的人,却比其他任何人更是奴隶」。
- [[论人类不平等的起源和基础]],卢梭认为人类不平等的起源是人的虚荣心和私有制。人在[[自然状态]]下是平等的,只是进入了社会之后才不平等。这本书只是卢梭为第戎学院写的一个征文内容,但其观点却另当时的社会为之一振。
- 接下来读的就是[[忏悔录]],这是一部卢梭的自传,卢梭毫无顾忌地把自己一生中不堪、肮脏都放到了读者面前。
- [[爱弥尔]] 这一本书并没有消化完全,虽然我知道这本书是卢梭想要教育出一个合格公民而写的一部关于教育的书,但我因为缺乏对那个时期的一些认识,可能需要再补充一些历史背景之后再读。
- [[通过知识获得解放]],这是 2021 年重读的一本书,这是[[波普尔]]的一本论文集,从知识,社会科学,到书籍思想,到文化,在这本书里面波普尔探讨了非常多的问题以及思考。最让我印象深刻的是破普尔对于科学知识的认识,[[我们的知识是建立在暂时性和尝试性解决办法之上]],我们当前的科学知识正确的唯一原因就是其是暂时经受了猛烈的批评。自然科学的方法和社会科学一样,通过实验得出尝试性解决方法,如果经得住批评就接受,如果被驳倒就尝试另外一个方法。
社科
- [[人类理解论]]
- [[人类大瘟疫 一个世纪以来的全球性流行]]
- [[生活在宋朝]]
- [[牛津通识读本:大卫休谟]]
- [[刘擎西方现代思想讲义]],非常容易读,作为一本哲学入门书籍不错,并且对西方哲学的流派和哲学家都有一个介绍和总结,如果对其中的某些思想或哲学家感兴趣不妨再找其他著作阅读
- [[做一个清醒的现代人]]
- [[马克思韦伯 跨越时代的人生]]
- [[货币的非国家化]],这是一本读着读着就不自觉想起 Web 3,区块链,比特币的书,[[哈耶克]] 在其中主张废除中央银行,允许私人发币,货币也可以自由竞争。
- [[文明 现代化 价值投资与中国]] 这是投资人李录关于「价值投资」,现代化,文明和中国的思考,在我看来是一本非常容易读的书,李录在书中也就很多问题展开了自己的论述,关于「文明的传播」,「现代化是否有可能在中国诞生」,「现代化的传播和现代化的道路之争」,「现代化的本质和铁律」,「对未来中国的预测」 等等问题。在投资上,我至始至终都坚信的是认识到了才能赚到超额的收益,而如何提高自己的认识,去读伟大的投资家是如何思考问题的,他们就是学习的对象。
投资 期权
- [[投资中最重要的事]] 算是一本投资经典书吧,作者是 [[霍华德 马克斯]],作者在其中阐述了自己的投资逻辑,如何看待市场,判断估值,理解风险,关注周期,等等,是一部非常不错的投资书籍,并且通过这一本书,可以了解非常多的观点,就这些观点也可以去发现更多的经典著作。
- [[简易期权]],算是期权的入门书吧,看名字就大概能理解,这算是一本非常简单介绍期权的著作,不是非常推荐,但如果要看可以快速的根据目录来了解一下什么期权,以及各种期权的种类
- [[每天学一点金融投资学]]
- [[投资 一部历史]]
- [[彼得林奇教你理财]],彼得林奇也是在投资历史上留下了辉煌的一笔
- [[对赌]]
- [[期权交易:核心策略与技巧解析]]
- [[漫步华尔街]],个人非常推荐的一本投资书,因为通过这一本书让我了解了更多的投资理论,[[价值投资]],[[技术分析]],[[基本面分析]],[[随机漫步理论]],[[现代投资组合理论]],[[行为金融学]] 等等理论,没有哪一个理论是绝对的正确,也不是说坚守哪一个理论就能百分之百超越市场
- [[麦克米伦谈期权]]
- [[暗池]]
人物传记
-
[[算法帝国]] 当时了解到盈透证券,偶然间获知了此书,书中的第一章关于[[Interactive Brokers 盈透证券]] 创始人的故事非常精彩,读完了这部分后面就略读过去了 - [[将心注入 舒尔茨]] 这是星巴克创始人[[霍华德 舒尔茨]]的第一本个人传记,这也是舒尔茨关于创办星巴克的故事。故事也非常精彩,读完之后对星巴克又有了全新的认识,它在我这里便不再只是一个咖啡品牌了。
- [[一路向前]] 这是舒尔茨再次担任 CEO 之后的著作,星巴克在丢失了创始人舒尔茨之后一度曾经走上了歧路
- [[大投机家]],这是德国投资家科斯托拉尼的自传,在他的历史时代,他有着非常超前的思考,对「投机」也有自己的行事逻辑。不借钱投资(不加杠杆),构建富有想象力的投资方案,耐心。书中对股市的长期,短期,已经外部影响因素都有一定的讨论。这算不上一本投资的经典书籍,但作为业余读物却也能在其中收获不少。
小说
- [[希望之线]] 东野圭吾 2021 最新的小说
- [[无名之町]] 疫情下的海边小镇发生的一起命案,死者是受人尊敬的老师
纪实文学
- [[巨浪下的小学]] 海啸过后
- [[无规则游戏:阿富汗屡被中断的历史]]
社科
- [[繁荣与衰退]] 美联储前主席[[格林斯潘]] 的著作
- [[全球房地产]],正如其名,就是介绍了世界各个主流市场的房地产经济,包括了香港的,德国的,美国的等等。我没有精读,大致留下了一个印象。
其他
- [[费曼学习法]],以输出来促使输入,通过教别人来学习。费曼学习法可以简化成四个步骤,理解概念,教给别人,回顾,简化内容。
- [[不购买的习惯]],法语中并不存在「穷」这个说法,法国人不说「穷」,而是说现在没有钱,也就是说「穷」不是一种属性,而是一种状态。只允许拥有少量的物品,就促使我们去好好利用,好好相处。
专业
- [[Reading-2021]]
Bash 中的 Parameter Expansion
Parameter Expansion 是一个用来描述命令行中部分参数被展开(内容被替换)的术语。在大部分的场景中,被展开的参数通常会带有 $ 符号,在一些特定的场景中,额外的花括号(curly braces)也是必须的。
比如:
echo "'$USER', '$USERs', '${USER}s'"
'testuser', '', 'testusers'
上面的例子展示了基本的 parameter expansions(PE) 是什么,第二个 PE 结果是一个空字符串,那是因为参数 USERs 是空的。其实 s 不是参数的一部分,但是因为 bash 无法分辨这一点,所以我们需要使用 {} 来限定参数的边界(前后)。
Parameter Expansion 也可以让我们去修改会被展开的字符串,这个操作会使得一些修改变得非常方便:
for file in *.JPG *.jepg
do mv -- "$file" "${file%.*}.jpg"
done
上述的代码会重命名所有扩展名为 .JPG 和 .jepg 的 JPEG 文件到 .jpg 扩展名。然后 ${file%.*} 表达式则会截取 file 文件从开头到最后一个 . 的内容。
其他的一些 PE tricks
${parameter:-word}, Use Default Value 如果当 parameter 未设置或为null时,使用默认值word,否则直接使用 parameter 的值${parameter:=word},Assign Default Value 赋值,当parameter未设置或为 null 时,word会被赋值给 parameter,然后 parameter 的值会被展开${parameter:+word},Use Alternate Value 如果 parameter 是 null 或者 未设置,那么结果没有任何被替换,如果 parameter 有值,则会被替换成 word${parameter:offset:length}Substring Expansion,使用 offset 和 length 限定的字串展开,序号从0开始。${#parameter}使用 parameter 的长度展开,如果 parameter 是一个数组名,则展开其中元素个数${parameter#pattern}pattern会从 parameter 值开始匹配,最短的 match 会从 parameter 中被删除然后剩余的被展开${parameter##pattern},##后面的 pattern 会把最长的 match 删掉${parameter%pattern},pattern 从 parameter 后往前匹配,最短的匹配被删除,剩余部分展开${parameter%%pattern},从后往前,最长的 match 会被删除${parameter/pat/string},parameter 值中的第一个出现的pat会被替换为string${parameter//pat/string}, 每一个出现的pat都会被替换${parameter/#pat/string},${parameter/%pat/string}
reference
使用 HandBrake 压缩转码视频
HandBrake 是一款开源的全平台的视频转码压制工具,基于 [[FFmpeg]],可以算作一个 GUI 版本的 FFmpeg。
安装
macOS:
brew install --cask handbrake
基础知识复习
分辨率 resolution
分辨率,也称为解析度,指的是视频中像素点的个数。
帧率 frame rate
帧率指的是每秒在屏幕上刷新的画面个数。
需要显示器硬件支持,大多数屏幕的刷新率在 60Hz 左右。
通常情况下 30FPS 已经能够保证流畅。
码率 bit rate
码率指的是单位时间内文件包含的数据量。
相同分辨率,码率越高约清晰。但是超过一定范围之后,清晰度变不会显著提高。
文件体积 = 总码率 * 时长。
媒体封装格式
通常见到的媒体封装格式包括:
- MKV
- MP4
- WebM
编解码格式
视频、音频数据的压缩方式。
常见的有:
- H.264 / H.265(HEVC)
预估文件的大小
通常可以通过分辨率大小、码率、帧率来预估一个视频文件的大小:
- 720P / 1 Mbps / 30 FPS / x264 / AAC = 1 小时视频大小在 450M 左右
- 1080P / 2 Mbps / 30 FPS / x264 / AAC = 1 小时视频大小在 900M 左右
使用
当了解了视频编解码的基本信息之后再去使用 HandBrake 就简单很多了。
使用 HandBrake 的使用场景通常有:
- 压缩原始文件,如果想要在互联网上分发音视频文件,可以通过 HandBrake 压缩到一个合适的大小之后再分发
- 视频转码,将视频文件转码成各个平台都兼容的格式,比如 MP4 等
- 给视频文件增加字幕,音轨
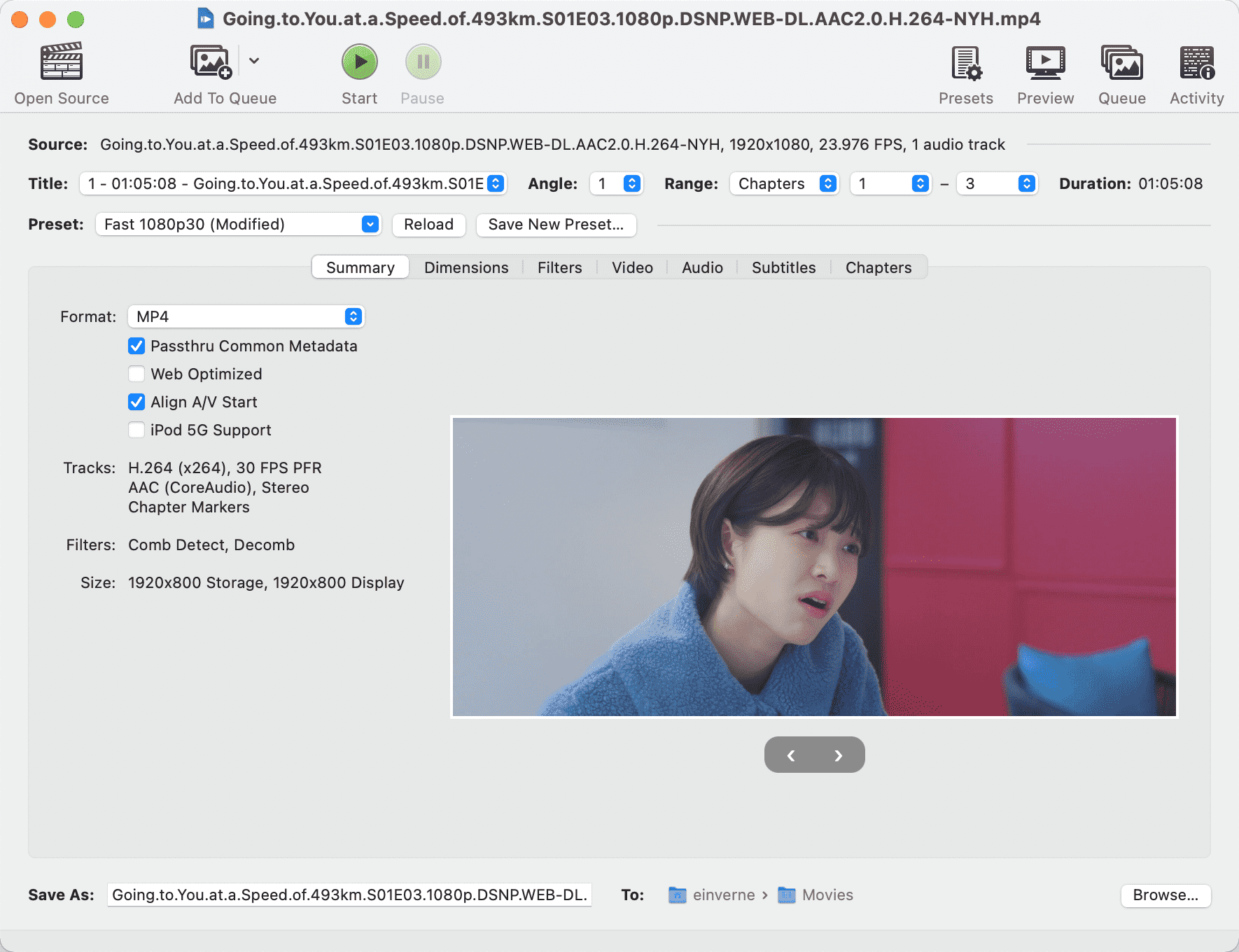
软件界面:
不丢失数据 降级 Android 应用版本
之前一次不消息把 Google Play Store 中的自动更新启用了,之后一个夜里把所有应用都更新了,不过有些应用本来就不想升级的,比如网易云音乐(有一些低版本没有广告,没有乱七八糟的直播什么的),微信。所以想着能不能在不丢失数据的情况下降级应用。简单的搜索了一下果然可以。
这里需要使用到 adb 命令,不同的系统直接安装即可,我现在在 Linux 下之前就已经安装过。
macOS 下:
brew cask install android-platform-tools
执行:
adb devices
查看是否连接,如果出现了设备 ID,则表明连接成功了。
然后准备好特定版本的 apk。
adb push wechat_7.0.0.apk /sdcard/Download/wechat_7.0.0.apk
然后进入下一步:
adb shell
进入系统的 shell 环境。
pm install -d -r /sdcard/Download/wechat_7.0.0.apk
说明:
-d表示运行降级安装-r表示保存数据重新安装现有应用
如果无法安装报错:
255|OnePlus7Pro:/ $ pm install -d -r /sdcard/Download/wechat_7.0.0.apk
avc: denied { read } for scontext=u:r:system_server:s0 tcontext=u:object_r:fuse:s0 tclass=file permissive=0
System server has no access to read file context u:object_r:fuse:s0 (from path /sdcard/Download/wechat_7.0.0.apk, context u:r:system_server:s0)
Error: Unable to open file: /sdcard/Download/wechat_7.0.0.apk
Consider using a file under /data/local/tmp/
Error: Can't open file: /sdcard/Download/wechat_7.0.0.apk
Exception occurred while executing 'install':
java.lang.IllegalArgumentException: Error: Can't open file: /sdcard/Download/wechat_7.0.0.apk
at com.android.server.pm.PackageManagerShellCommand.setParamsSize(PackageManagerShellCommand.java:520)
at com.android.server.pm.PackageManagerShellCommand.doRunInstall(PackageManagerShellCommand.java:1283)
at com.android.server.pm.PackageManagerShellCommand.runInstall(PackageManagerShellCommand.java:1249)
at com.android.server.pm.PackageManagerShellCommand.onCommand(PackageManagerShellCommand.java:185)
at android.os.BasicShellCommandHandler.exec(BasicShellCommandHandler.java:98)
at android.os.ShellCommand.exec(ShellCommand.java:44)
at com.android.server.pm.PackageManagerService.onShellCommand(PackageManagerService.java:22322)
at android.os.Binder.shellCommand(Binder.java:940)
at android.os.Binder.onTransact(Binder.java:824)
at android.content.pm.IPackageManager$Stub.onTransact(IPackageManager.java:4644)
at com.android.server.pm.PackageManagerService.onTransact(PackageManagerService.java:4515)
at android.os.Binder.execTransactInternal(Binder.java:1170)
at android.os.Binder.execTransact(Binder.java:1134)
那么需要将 apk 移动到 /data/local/tmp/:
mv /sdcard/Download/wechat_7.0.0.apk /data/local/tmp/
然后再安装:
pm install -d -r /data/local/tmp/wechat_7.0.0.apk
如果还不行,那么可以保留数据卸载应用然后重新安装:
pm uninstall -k com.tencent.mm
pm install -d /data/local/tmp/wechat_7.0.0.apk
文章分类
最近文章
- 从 Buffer 消费图学习 CCPM 项目管理方法 CCPM(Critical Chain Project Management)中文叫做关键链项目管理方法,是 Eliyahu M. Goldratt 在其著作 Critical Chain 中踢出来的项目管理方法,它侧重于项目执行所需要的资源,通过识别和管理项目关键链的方法来有效的监控项目工期,以及提高项目交付率。
- AI Shell 让 AI 在命令行下提供 Shell 命令 AI Shell 是一款在命令行下的 AI 自动补全工具,当你想要实现一个功能,敲一大段命令又记不住的时候,使用自然语言让 AI 给你生成一个可执行的命令,然后确认之后执行。
- 最棒的 Navidrome 音乐客户端 Sonixd(Feishin) Sonixd 是一款跨平台的音乐播放器,可以使用 [[Subsonic API]],兼容 Jellyfin,[[Navidrome]],Airsonic,Airsonic-Advanced,Gonic,Astiga 等等服务端。 Sonixd 是一款跨平台的音乐播放器,可以使用 [[Subsonic API]],兼容 Jellyfin,[[Navidrome]],Airsonic,Airsonic-Advanced,Gonic,Astiga 等等服务端。
- 中心化加密货币交易所 Gate 注册以及认证 Gate.io 是一个中心化的加密货币交易所。Gate 中文通常被称为「芝麻开门」,Gate 创立于 2013 年,前身是比特儿,是一家致力于安全、稳定的数字货币交易所,支持超过 1600 种数字货币的交易,提供超过 2700 个交易对。
- 不重启的情况下重新加载 rTorrent 配置文件 因为我在 Screen 下使用 rTorrent,最近经常调试修改 rtorrent.rc 配置文件,所以想要找一个方法可以在不重启 rTorrent 的情况重新加载配置文件,网上调查了一下之后发现原来挺简单的。