使用 Docker 安装最新 8.x Elasticsearch 和 Kibana
[[Elasticsearch]] 是基于 [[Lucene]] 开源的全文搜索引擎。提供 RESTful 接口,可以实现精确快速的实时检索。
[[Kibana]] 是一个基于 Web 的可视化前端。还有一个 [[elasticsearch-head]] 也是一个 Elasticsearch 的前端,不过这里因为 Kibana 使用场景更加广泛,就选择 Kibana。
Installation
创建 network:
docker network create elastic
这里仅演示单节点的 Elasticsearch 搭建过程,如果要搭建集群模式,可以自行参考官网。
version: "3.0"
services:
elasticsearch:
container_name: es
image: elasticsearch:8.3.2
environment:
- xpack.security.enabled=false
- "discovery.type=single-node"
- "ELASTIC_PASSWORD=${ELASTIC_PASSWORD}"
networks:
- elastic
ports:
- 9200:9200
kibana:
container_name: kibana
image: kibana:8.3.2
environment:
- ELASTICSEARCH_HOSTS=http://es:9200
networks:
- elastic
depends_on:
- elasticsearch
ports:
- 5601:5601
networks:
elastic:
driver: bridge
Docker compose 会启动两个容器,一个容器运行 Elasticsearch,使用端口 9200,一个容器运行 Kibana 使用端口 5601.
两个镜像最新的版本可以分别在这里查看:
使用如下的命令检查 Elasticsearch 的状态:
❯ curl http://localhost:9200
{
"name" : "d9f0b969f13c",
"cluster_name" : "docker-cluster",
"cluster_uuid" : "VRWzzZpISPugOCQadlC88A",
"version" : {
"number" : "8.3.2",
"build_type" : "docker",
"build_hash" : "8b0b1f23fbebecc3c88e4464319dea8989f374fd",
"build_date" : "2022-07-06T15:15:15.901688194Z",
"build_snapshot" : false,
"lucene_version" : "9.2.0",
"minimum_wire_compatibility_version" : "7.17.0",
"minimum_index_compatibility_version" : "7.0.0"
},
"tagline" : "You Know, for Search"
}
当启动 Elasticsearch 之后会产生一些证书,这些证书用来安全的在 Kibana 中访问 Elasticsearch。
http_ca.crt:CA 证书,用来签名 HTTP 请求http.p12:Keystore that contains the key and certificate for the HTTP layer for this node.transport.p12:Keystore that contains the key and certificate for the transport layer for all the nodes in your cluster.
http.p12 和 transport.p12 是密码保护的 PKSC#12 keystore。
可以使用如下命令获取 http.p12 密码:
bin/elasticsearch-keystore show xpack.security.http.ssl.keystore.secure_password
可以使用如下命令获取 transport.p12 密码:
bin/elasticsearch-keystore show xpack.security.transport.ssl.keystore.secure_password
等待容器启动之后可以直接访问 Kibana http://localhost:5601/
reference
FFmpeg 使用指南之 concat demuxer 串联多个文件
FFmpeg 可以使用 -i 参数来输入一个或多个文件,但有些时候会有一些将多个文件串联成一个文件的需求。比如将多个视频合并成一个视频文件,将多个音频文件合并和一个长音频文件。这个时候就需要使用到 FFmpeg 的 concat demuxer。
concat demuxer 是 FFmpeg 1.1 引入的。主要可以用来合并多个媒体文件。
串联多个相同编码的文件
FFmpeg 有两种方式可以串联相同的文件:
- the concat “demuxer”
- the concat “protocol”
demuxer 更加灵活,需要相同的编码,容器格式可以不一样。而 protocol 则需要容器的格式也一致。
Concat demuxer
demuxer 通过从一个固定格式的文件中读取文件列表,然后 FFmpeg 可以对这些文件一同处理。
创建文件 mylist.txt,包含所有想要串联的文件:
# this is a comment
file '/path/to/file1.wav'
file '/path/to/file2.wav'
file '/path/to/file3.wav'
注意,这里的 # 是注释语句。文件中的文件路径可以是绝对的或相对的路径,然后就可以使用 FFmpeg 对这多个文件 stream-copy 或者 re-encode(重新编码) :
ffmpeg -f concat -safe 0 -i mylist.txt -c copy output.wav
如果路径是相对的,这里的 -safe 0 可以省略。
如果有多个文件要添加到 mylist.txt 文件中,可以使用 Bash 脚本批量生成:
# with a bash for loop
for f in *.wav; do echo "file '$f'" >> mylist.txt; done
# or with printf
printf "file '%s'\n" *.wav > mylist.txt
Concat protocol
demuxer 在文件流级别工作,concat protocol 在文件级别工作。特定的文件(比如 MPEG-2 传输流,或者其他)可以串联起来。
下面的命令将三个 MPEG-2 TS 文件串联到一起,不重编码:
ffmpeg -i "concat:input1.ts|input2.ts|input3.ts" -c copy output.ts
串联不同编码的文件
某些情况下,多个文件可能使用不同的编码,那么上面的命令就都无法使用。
Concat filter
如果要让 concat filter 工作,输入的文件必须拥有相同的 frame dimensions (eg. 1920*1080 pixels) 并且要有相同的 framerate。
假设有三个文件需要串联起来,每一个文件都有一个视频流和一个音频流:
ffmpeg -i input1.mp4 -i input2.webm -i input3.mov \
-filter_complex "[0:v:0][0:a:0][1:v:0][1:a:0][2:v:0][2:a:0]concat=n=3:v=1:a=1[outv][outa]" \
-map "[outv]" -map "[outa]" output.mkv
来拆解一下命令,首先指定所有的输入文件,然后实例化一个 -filter_complex filtergraph
然后:
[0:v:0][0:a:0][1:v:0][1:a:0][2:v:0][2:a:0]
告诉 ffmpeg 使用输入文件中的哪一个流,然后发送给 concat filter。在这个例子中,第一个文件的视频流 0 [0: v:0] 和音频流 0 [0: a:0] ,第二个文件的视频流 0 [1: v:0] 和音频流 0 [1: a:0]。
concat=n=3:v=1:a=1[outv][outa]
这个就是 concat fitler, n=3 告诉 filter 这里有三个输入分段,v=1 则表明每一个分段有一个视频流,a=1 表明每一个分段有一个音频流。filter 然后将这些分段连接产生两个输出流, [outv] 和 [outa] 两个输出流的名字。
注意的是两侧的双引号是必须的。
然后使用这些输出流,将他们 组合成输出文件 :
-map "[outv]" -map "[outa]" output.mkv
这行告诉 FFmpeg 使用 concat filter 的结果,而不是直接使用输入的 streams。
有一个叫做 mmcat 的 Bash script,可以在老版本的 FFmpeg 中实现 concat filter。
reference
Linux 服务器控制面板 HestiaCP 使用
Hestia CP 是一个开源的 Linux 服务器控制面板(Control Panel),HestiaCP fork 自另一款流行的控制面板 VestaCP 。由于 VestaCP 开发和维护趋于停止,很多安全问题和漏洞没有及时修复,所以有人从 VestaCP 拉出新分支进行开发和维护。Hestia 可以作为 aaPanel(宝塔面板)的很好的开源代替。
HestiaCP 提供了一个简单干净的网页界面,给网站维护人员提供了更加简单的方式维护网页服务器。HestiaCP 提供了很多功能,包括
- 管理部署网站(Nginx, Apache,PHP)
- SSL 证书及 SNI Wildcard support
- 数据库(MySQL,PostgreSQL)
- FTP([[ProFTPd]], [[vsftpd]])
- DNS zones(Bind)DNS 服务器
- 邮件服务器([[Dovecot]], [[exim4]])支持 [[SPF]]、[[DKIM]] 等
- 垃圾邮件扫描([[SpamAssassin Score]])
- 邮件病毒扫描([[ClamAV]])
- 多种数据备份方案
HestiaCP 还提供了基于命令行的管理工具,具体可以见 文档。
另一个值得一说的功能就是,HestiaCP 提供了一键安装网站(Quick Install App)的功能,默认提供了一些非常受欢迎的网页应用,包括 [[WordPress]], [[Drupal]], [[Joomla]], [[Opencart]], [[PrestaShop]], [[Lavarvel]], [[Symfony]] 等等。
在接触 Hestia 之前,有段时间直接使用 LNMP,或者使用 [[aapanel]],但后来发现 aaPanel 的 License 或许存在某些问题,并且在读了 Stallman 的 著作 之后对自由软件的认识更深刻了一些,所以直接替换成 GPL 发布的 Hestia。作为 aaPanel 的开源代替品,发现 Hestia 还是非常不错的。
后台演示:
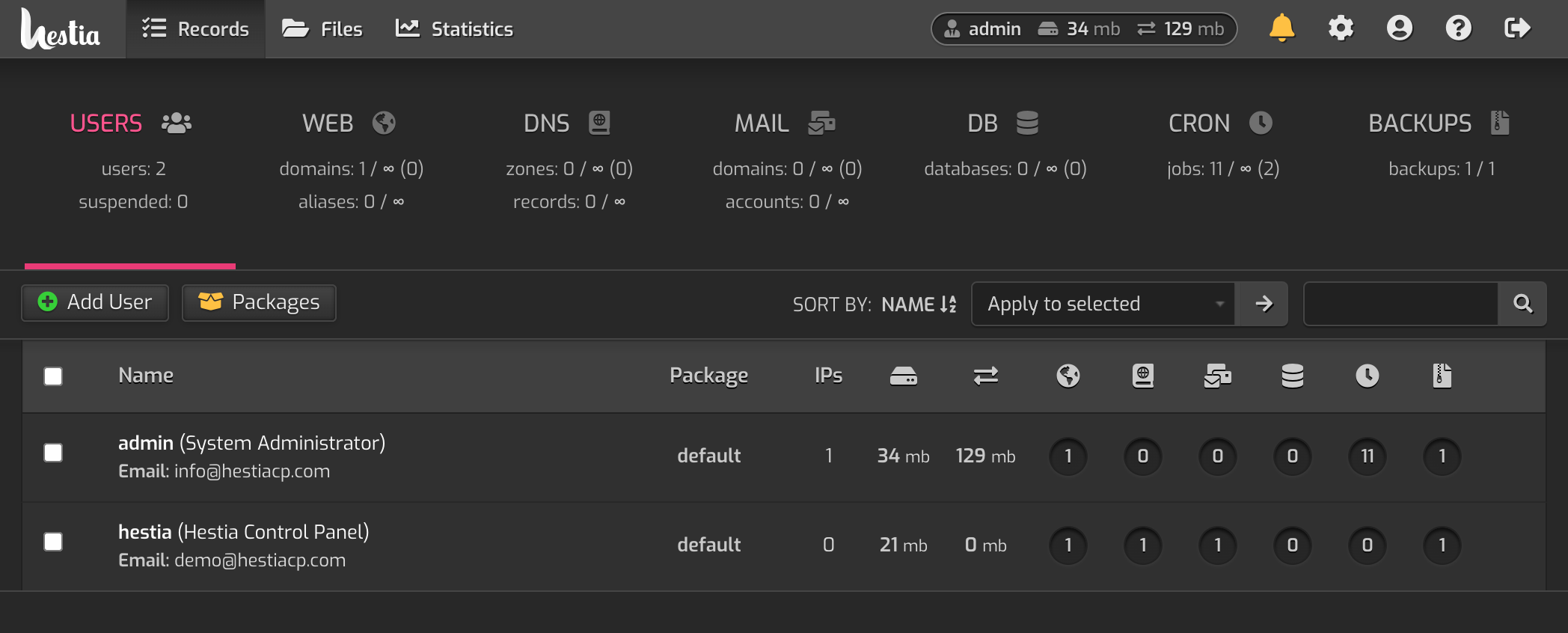
Features
- Apache2, Nginx, PHP-FPM
- 多 PHP 版本
- 集群功能的 DNS 服务器
- POP/IMAP/SMTP 邮件服务器,带反垃圾邮件,病毒扫描
- 支持 MariaDB 和 PostgreSQL 数据库
- 自带 [[fail2ban]] 和防火墙
Prerequisites
- 一台运行 Debian 或 Ubuntu 的服务器或 VPS,推荐使用一个全新安装的系统,避免可能出现的任何问题
- root 权限,或者使用
sudo
Installation
本文中演示在 Ubuntu 20.04 上安装 HestiaCP。整个过程可能会需要 15 分钟左右。
安装脚本:
wget https://raw.githubusercontent.com/hestiacp/hestiacp/release/install/hst-install.sh
bash hst-install.sh
可以通过 安装器 自己选择安装的组件。选择组件之后会产生一个命令:
wget https://raw.githubusercontent.com/hestiacp/hestiacp/release/install/hst-install.sh
sudo bash hst-install.sh --apache no --phpfpm yes --multiphp no --vsftpd yes --proftpd no --named yes --mysql yes --postgresql no --exim yes --dovecot yes --sieve no --clamav no --spamassassin no --iptables yes --fail2ban yes --quota no --api yes --interactive yes --with-debs no --port '8083' --hostname 'your_hostname' --email 'i@youremail.com' --password 'your_password' --lang 'en'
你可以根据自己的需要自行选择需要的组件。可以在官网 文档 中查看默认会安装的组件。
安装完成之后会在日志中看到后台登录的链接,以及默认的用户名(admin)和密码。脚本执行完成后可能会需要一次重启来完成安装。
访问 https://ip:8083 ,或者如果已经配置了域名 A 记录指向该 IP,也可以使用域名加端口来访问。
netplan 错误
安装过程中如果遇到:
[ * ] Installing dependencies...
!!! !!! !!! !!! !!! !!! !!! !!! !!! !!! !!! !!! !!! !!! !!! !!! !!!
WARNING: Your network configuration may not be set up correctly.
Details: The netplan configuration directory is empty.
You may have a network configuration file that was created using systemd-networkd.
It is strongly recommended to migrate to netplan, which is now the
default network configuration system in newer releases of Ubuntu.
While you can leave your configuration as-is, please note that you
will not be able to use additional IPs properly.
If you wish to continue and force the installation,
run this script with -f option:
Example: bash hst-install-ubuntu.sh --force
!!! !!! !!! !!! !!! !!! !!! !!! !!! !!! !!! !!! !!! !!! !!! !!! !!!
Error: Unable to detect netplan configuration.
这个错误是因为 Ubuntu 没有使用 netplan,或者 VPS 主机提供的镜像没有使用 netplan,但是 /etc/netplan 文件夹存在,这就导致 HestiaCP 安装脚本执行过程中判断错误。
解决方案:查看 /etc/netplan 文件夹,如果配置文件夹是空的,那么可以直接删除该文件夹,如果确定自己已经使用了 netplan 作为网络配置,那么检查一下网络配置。
Usage
申请 Let’s Encrypt SSL 证书
在完成安装访问后台的时候,浏览器会报 Your connection is not private 的错误,这是因为 SSL 证书缺失了。
可以使用 v-add-letsencrypt-host 命令来申请证书。
不过我在执行的过程中发生一些问题,报错:
Error: Let's Encrypt validation status 400 (xxx.einverne.info). Details: Unable to update challenge :: authorization must be pending
Error: Let's Encrypt SSL creation failed
查看发现因为在机器上安装了 Docker,所以虚拟了一个网络端口,在后台 Web 查看域名的时候,看到其中关联的 IP 地址是一个本地的地址 172.17.0.1,把这个地址修改成 VPS 的真实 IP 地址。然后重新执行命令即可。
如果出现其他的错误,也可以到如下的目录中查看日志:
/var/log/hestia/LE-user-domain-timestamp
Create a new user
虽然以 admin 登录可以在后台做任何事情,但是还是推荐创建一个新用户,以新用户的身份来操作。
添加域名
创建完用户之后以该用户登录,然后在 Web 中,选择添加域名。
添加的过程中有如下配置:
- Domain:需要添加的域名
- IP Address: IP 地址,如果服务器有多个 IP 这里也会显示出来
- Create DNS zone: 如果想要 HestiaCP 来管理 [[DNS zone]] 可以配置
- Enable mail for this domain: 如果要使用该域名来发送邮件可以配置该选项
在高级选项中:
- Aliases: 默认你需要配置
www.yourdomain.com指向你的域名 - Proxy Support: HestiaCP 默认使用 Nginx 来代理静态文件
- Web Statistics: 是否开启数据记录,默认未开启,但是 HestiaCP 自带了强大的
AWStats,可以到其 官网 查看 - Custom document root: 默认是
/home/your_user/web/your_website/public_html/ - Enable SSL for this domain: 开启 SSL
- Additional FTP Accounts: 是否创建 FTP 账号
Nginx 模板设置
可以在 /usr/local/hestia/data/templates/web/nginx/ 目录下查看到默认的 Nginx 配置模板。其中的默认模板:
default.tpldefault.stpl
可以将默认的模板拷贝到新的文件修改:
cp original.tpl new.tpl
cp original.stpl new.stpl
cp original.sh new.sh
模板中支持的变量可以参考官网
Tips
修改面板的端口
默认情况下 HestiaCP 使用 8083 端口,当然在安装的时候也可以指定,但是如果安装完成之后想要调整端口,可以使用如下的命令:
v-change-sys-port 2083
重置 admin 密码
更改 admin 用户密码
v-change-user-password admin yourpass
或者更改其他任何用户的密码。
更改 hostname
v-change-sys-hostname your.hostname
强制主机 SSL
强制主机名使用 SSL
v-add-letsencrypt-host
v-add-web-domain-ssl-hsts 'admin' 'hcp.domain.com'
v.add-web-domain-ssl-force 'admin' 'hcp.domain.com'
删除不需要的主机方案
rm -fr /usr/local/hestia/install/rhel
rm -fr /usr/local/hestia/install/ubuntu
rm -fr /usr/local/hestia/install/debian/7
rm -fr /usr/local/hestia/install/debian/8
rm -fr /usr/local/hestia/install/debian/9
开放端口
touch /etc/iptables.up.rules
v-add-firewall-rule ACCEPT 0.0.0.0/0 22 TCP SSH
v-add-firewall-rule ACCEPT 0.0.0.0/0 5566 TCP HestiaCP
使用命令行工具
source /etc/profile
PATH=$PATH:/usr/local/hestia/bin && export PATH
修改控制面板的 IP
可以使用命令行:
v-update-sys-ip 1.2.3.4
v-rebuild-web-domains admin
v-rebuild-mail-domains admin
HestiaCP vs VestaCP
HestiaCP 是 VestaCP fork,VestaCP 开发和维护趋于停止,存在许多漏洞和安全性问题。VestaCP 是第一个 Nginx 的 GUI 控制面板。在 VestaCP 之前有很多 CLI-only 的管理工具。
- HestiaCP 支持 Debian 和 Ubuntu
- HestiaCP 添加了 CardDAV/CalDAV/ActiveSync 支持。1
related
- [[aapanel]]
- [[CyberPanel]]
- [[DirectAdmin]]
- [[Control Panel]]
reference
Elasticsearch 入门使用
[[Elasticsearch]] 是一款基于 [[Lucene]] 的开源的、分布式的搜索引擎。提供一个分布式、多租户的全文搜索引擎。提供 HTTP Web 界面和 JSON 格式接口。
Elasticsearch 由 Java 实现,是目前最流行的大数据存储、搜索和分析引擎。
GitHub:https://github.com/elastic/elasticsearch
大数据要解决三个问题:
- 存储
- 传统关系型数据库 MySQL,Oracle 遇到瓶颈,Google 提出 Map/Reduce 和 Google File System,Hadoop 作为开源实现在业界得到应用,但 Hadoop 存储无法实现数据实时检索和计算
- 检索
- [[Apache Hive]] 作为在 Hadoop 基础之上的数据仓库提供了查询分析的能力
- 展现
但 Elasticsearch + Kibana 的组合可以快速解决如上提到的问题。
Elasticsearch 是面向文档的,存储整个文档或对象,内部使用 JSON 作为文档序列化格式。
installation
在使用 Linux 安装之前设置 vm.max_map_count 至少是 262144.
使之生效:
sudo sysctl -w vm.max_map_count=262144
让系统重启之后也生效,需要编辑 /etc/sysctl.conf 添加一行:
vm.max_map_count=262144
通过 docker-compose 安装。
也可以下载手动安装。
我个人推荐在本地使用单节点安装启用。
默认情况,Elasticsearch 通过 9200 端口对外提供 REST API。Kibana 的默认端口是 5601。
如果遇到如下问题,请查看是否设置了 vm.max_map_count。
es03_1 ERROR: [1] bootstrap checks failed. You must address the points described in the following [1] lines before starting Elasticsearch.
Single node
单节点的 Elasticsearch 可以使用 Docker 在本地启用,参考这里。
常用命令:
docker network create elastic
docker run --name es --net elastic -p 9200:9200 -p 9300:9300 -it docker.elastic.co/elasticsearch/elasticsearch:8.3.1
docker exec -it es /usr/share/elasticsearch/bin/elasticsearch-reset-password
概念
Node
Node,节点,Elasticsearch 运行实例,集群由多个节点组成。节点存储数据,并参与集群索引、搜索和分析。
Shard
Shard, 分片,数据中的一小部分,每一个分片是一个独立的 Lucene 实例,自身也是一个完整的搜索引擎。
索引会存储大量的数据,这些数据会超出单个节点的硬件限制,例如,占用 1TB 磁盘空间的 10 亿个文档的单个索引可能超出单个节点的磁盘容量,所以 Elasticsearch 提供了索引水平切分(Shard 分片)能力。
创建索引时只需要定义所需分片数量。每一个分片本身就是一个具有完全功能的独立「索引」,可以分布在集群中的任何节点上。
文档会被存储并被索引在分片中。但是当我们使用程序与其通信时,不会直接与分片通信,而是通过索引。
当集群扩容或缩小时,Elasticsearch 会自动在节点之间迁移分配分片。
分片分为:
- 主分片 primary shard
- 从分片 replica shard
从分片是主分片的副本,提供数据的冗余副本,在硬件故障时提供数据保护,同时服务于搜索和检索只读请求。
索引中主分片的数量在索引创建之后就固定了,但是从分片数量可以随时改变。
设置三个主分片和一组从分片
PUT /blogs
{
"settings" : {
"number_of_shards" : 3,
"number_of_replicas" : 1
}
}
分片很重要:
- 分片可以水平拆分数据,实现大数据存储和分析
- 跨分片进行分发和并行操作,提高性能和吞吐量
Index
Index, 索引。在 Elasticsearch 中,存储数据的行为叫做索引 Indexing,在索引数据值前,要决定数据存储在哪里。
单个集群中可以定义任意多索引。
一个 Elasticsearch 集群可以包含多个索引(数据库),可以包含很多类型(表),类型中可以包含很多文档(行),文档中包含很多字段(列)。
关系数据库 -> 数据库 -> 表 -> 行 -> 列 (column)
Elasticsearch -> 索引 -> 类型 -> 文档 -> 字段(field)
在 Elasticsearch 中索引有不同的含义。
作为名词
索引就是 Elasticsearch 提供的「数据库」。
作为动词
为文档创建索引,就是将文档存储到索引(数据库)中的过程,只有建立了索引才能被检索。
反向索引
在关系型数据库中为某一列添加索引,是在文件结构中使用 B-Tree 加速查询。在 Elasticsearch 和 Lucene 中使用 Inverted index (反向索引)的结构来实现相同的功能。
通常文档中的每一个字段都被创建了索引(有一个反向索引)
创建索引
假如要创建员工名单:
PUT /corp/employee/1
{
"first_name" : "John",
"last_name" : "Smith",
"age" : 25,
"about" : "I love to go rock climbing",
"interests": [ "sports", "music" ]
}
- 为每一个员工文档创建索引
- 文档被标记为
employee类型 - 这个类型会存放在
corp索引中
Document
Document 文档,可被索引的基本信息单元。文档以 JSON 表示。单个索引理论上可以存储任意多的文档。
副本
副本在分片或节点发生故障时提供高可用。
分片和对应的副本不可在同一个节点上
副本机制,可以提高搜索性能和水平扩展吞吐量,因为可以在所有副本上并行搜索。
默认情况下,Elasticsearch 中的每个索引都分配一个主分片和一个副本。集群至少需要有两个节点,索引将有一个主分片和一个完整副本。
Query DSL 搜索
Elasticsearch 提供了灵活的查询语言,可以完成更加复杂的搜索任务。
使用 JSON 作为主体:
GET /megacorp/employee/_search
{
"query" : {
"match" : {
"last_name" : "Smith"
}
}
}
Aggregation
Elasticsearch 有一项功能叫做 Aggregation,类似于 GROUP BY,但是更强大。结合查询语句可以实现非常多的聚合操作。
分布式
Elasticsearch 可以被扩展到上百成千台服务器来处理 PB 级别的数据。Elasticsearch 是分布式的。用户在使用的过程中不需要考虑到分片,集群等等,这些都是 Elasticsearch 自动完成的:
- 将文档分区到不同的容器,分片中
- 跨节点平衡集群中节点间的索引和搜索负载
- 自动复制数据提供冗余副本,防止硬件错误造成数据丢失
- 自动在节点之间路由
- 无缝扩展或恢复集群
集群健康状态查询:
GET /_cluster/health
{
"cluster_name": "elasticsearch",
"status": "green", <1>
"timed_out": false,
"number_of_nodes": 1,
"number_of_data_nodes": 1,
"active_primary_shards": 0,
"active_shards": 0,
"relocating_shards": 0,
"initializing_shards": 0,
"unassigned_shards": 0
}
其中 status 有三个状态:
- green 主分片和从分片都可以用
- yellow 主分片可用,但存在从分片不可用
- red 存在不可用的主分片
使用
集群健康状况:
GET /_cat/health?v
列出节点信息:
GET /_cat/nodes?v
列出集群中索引信息:
GET /_cat/indices?v
创建索引:
PUT /customer?pretty
GET /_cat/indices?v
编码 读书笔记
怎么知道的这一本书
之前在 Twitter 上看到一则帖子,有人求推荐书,如果要向一位学金融的朋友推荐一本计算机入门书籍,你会选择哪一本?在答复里面,我看到了有人推荐这一本《编码:隐匿在计算机软硬件背后的语言》。所以我把这一本书作为 [[20220627 21 天挑战计划]] 中要阅读的一本书。当时我没有想到的是,在豆瓣标记的时候我意外发现我早已经在 2018 年标记读过,但当时没有做笔记,也没有整理标记,4 年过去,就像没有读过一样。这更加坚定了我之后读书一定要整理书摘,用自己的语言撰写一下读书笔记的决心。
几句话总结书的内容
编码是一本由实体世界中信息传递,进而一步步带领读者进入计算机编码的通俗读物。作者会使用通俗易懂的语言,循序渐进地引领读者理解计算机是如何工作的。
什么是编码?
作者在本书的开头引用了《美国传统英语词典》对编码(code)的解释:
- 3.1 a system of signals used to represent letters or numbers in transmitting messages
- 3.2 a system of symbols, letters, or words given certain arbitrary meanings, used for transmitting messages requiring secrecy or brevity
-
- a system of symbols and rules used to represent instructions to a computer
这其中可以看到两层含义,一种是表达在信息传输过程中用来表述字母或数字的信号,可以是直接的信号,也可以是加密的,或简练的信息;另外一层含义是由字符和规则组成的系统用来向计算机传达指令。
同样在《牛津高阶英汉词典》中的解释更为直接:
-
- a system of computer programming instructions
也就是,计算机编程指令系统。
而在本书中,编码特指的是在机器和人之间传递信息的方式。我们所编写的代码,需要让计算机可以理解执行。
莫尔斯编码
我们都知道一个国际求救信号 SOS,但为什么是 SOS 呢,是什么的缩写吗?是比较好读吗?其实都不是,而原因是因为在莫尔斯编码中,S 是三个点,而 O 是三个划(-),SOS 是一个比较容易记忆的编码序列,并且不容易和其他序列搞混。于是这个编码就作为国际通用的求救信号留了下来。
莫尔斯编码通过对字母进行点和划的编码以实现信息的传递,但这个效率无疑是比较低的,如果在手动操作的情况下,每分钟也只能传递各位数字的单词,而通过口头交流可以达到每分钟 100 个单词左右的速度。
布莱叶盲文
布莱叶盲文通过凸起的点编码文字,使得盲人可以阅读。布莱叶盲文通过三行两列的六个凸起的点编码信息,布莱叶盲文也是一种二进制编码方式,每一个凸起的点可以表示两种状态,通过不同的组合,六位的编码可以表达出 2^6,也就是 64 种不同的编码。
除了 24 个字母,为了使用的简便,后续人们还引入了字母组合,常用单词,充分利用这 64 种不同的变化。
手电筒
作者在介绍了莫尔斯编码和布莱叶盲文之后用了整整一章的内容介绍了手电,以及基本的电路知识,也许你会感到奇怪为什么在这个时候介绍了这么多电流、电压、电阻、功率的知识。但电气化的开始才是之后计算机时代来临的前提。
欧姆定律:
I = E / R
电流(I)等于电压(电动势 E)除以电阻(R)。
瓦特:
P = E * I
瓦特等于电压(E)乘以电流(I)。
但作者真正要介绍的并不是这些物理知识,而是控制电灯的开关,这一个开关,又可以将一个最简单的电路(手电)变成一个二进制的编码,开和关分别是两个状态。
电报机和继电器 电报系统
电报系统的诞生正式开启了全球即时通信的时代,但是电报是怎么来的呢?想想一想如果将一个简单的控制电灯开关的电路系统分别放到你和朋友的家中,那你们就可以分别通过开关来控制对方家中的电灯,那么就可以信息的传递。电路系统使用的原理就是如此:在线路的一端通过一些措施,使得线路的另一端发生某种变化。
[[萨缪尔 莫尔斯]] 通过电磁现象在 1836 年通过专利局,成功发明电报机,但直到 1843 年,才说服国会为其创建公共基金。1844 年 5 月 24 日,华盛顿特区和马里兰州巴尔迪摩市电报线路架设完成,完成了人类历史上第一条信息的传递:「What hath God wrought!」
电报机的发明标志着现代通信的开始,人们第一次能够在视线或听力之外的距离开始实时交流,信息的传递速度比骏马还有快。
但是电报机最大的问题是长导线带来的电阻,电报线路使用高达 300 伏的电压使得有效距离可以超过 300 英里,但线路还是无法无限延长。
于是人们发明了中继系统,每隔 200 英里设定一个中继,接收信息,然后再转发出去。于是人们发明了继电器。通过电路的方式将信息转发出去。
阿拉伯数字 十进制
全球通用的数字系统通常被称为阿拉伯数字,起源于印度,被阿拉伯数学家带入欧洲。波斯数学家穆罕默德·伊本穆萨·奥瑞兹穆(根据这个人的名字衍生出英文单词 algorithm)在公元 825 年写了一本关于代数的书,使用了印度计数系统。
- 阿拉伯数字系统和位置有关,一个数字的位置不同,表示计量不同
- 没有专门用来表示数字 10 的符号
- 比代表数字 10 的符号还有用得多嗯符号 0
这个 0,是数字和数学史上最重要的一个发明。0 的出现简化了乘法和除法。
十进制的代替
因为人类是有 10 个手指,所以适应了 10 进制,于是作者通过循序渐进的方式提问,如果是 4 指动物呢?于是进一步介绍了 8 进制,再如果是龙虾呢?两个大钳子,4 进制,再如果是海豚呢?两个鳍,2 进制。
当我们把数字系统减少到只有 0 和 1 的二进制系统时,我们无法找到比二进制系统更加简单的数字系统了。但是之前提到过的所有开关、电线、灯泡、继电器都可以用来表示二进制的 0 和 1。
二进制
1948 年,美国数学家约翰·威尔德·特克(John Wilder Turkey)意识到随着计算机的普及,二进制可能为发挥极大作用,所以发明了一个新的、更短的词语来替代不方便的 binary digital,选择了短小、简单、精巧的词 bit。
逻辑与开关
交换律:
A + B = B + A
A * B = B * A
结合律:
A + (B + C) = (A + B) + C
A*(B*C) = (A*B)*C
分配率:
A*(B+C) = A*B + A*C
传统代数是处理数字的,布尔的天才在于将代数从数的概念中抽离出来,更加抽象。在布尔代数中,操作数不是数字而是类(class),简单来说,一个类就是一个食物的群体(集合 Set)。
布尔代数中,符号 + 表示两个集合的并集,x 表示两个集合的交集。
但是布尔生活的那个时代,没有人把布尔代数用于电路。直到 20 世纪 30 年代的香农。
逻辑门
克洛德·艾尔伍德·香农在 1938 年,完成了《继电器和开关电路的符号分析》(A Symbolic Analysis of Relay and Switching Circuits)一篇著名的硕士论文,并在 10 年之后,发表《通信的数学原理》(The Mathematical Theory of Communication) 清晰尔严谨地阐述了,电子工程师可以运用布尔代数的所有工具去设计开关电路。如果简化了一个网络的布尔表达式,那么也可以简化相应的电路。
于是人们在简单的电路基础上抽象出了与门、或门、与非门、与或门等等。
字节与十六进制
8 比特表示一个字节(byte),8 比特在很多方面都比单独的比特更胜一筹。
全世界大部分书面语言(除了中日韩中使用的象形文字)的基本字符都少于 256 ,字节是一种理想的保存文本的手段。
当一个字节无法表示所有信息时,使用两个字节,也可以很好的表达。
从算盘到芯片
20 世纪 40 年代初期,真空管开始取代继电器,到 1945 年,真空管已经完全取代了继电器。
晶体管不再需要真空而是使用固体制造,体积比真空管更小,晶体管需要的电量更小,产生的热量更小,更持久耐用。
开发真空管的最初目的是为了放大电信号,但是同样可以应用于逻辑门的开关,作用和晶体管一样。
诺伊斯在 1957 年与其他 7 位科学家离开肖克利半导体创办仙童(Fairchild)半导体公司,并随后发明了集成电路。
1965 年摩尔(Moore)发现从 1959 年开始,同一块芯片上可以集成的晶体管数目每年番一倍。
到 20 世纪 70 年代,使用集成电路在一块电路板上制造一个完整的计算机处理器变得可能。
在比较微处理器时使用三个标准:
- 多少位处理器,表示数据宽度,能够处理加减的比特位数
- 最大时钟频率,单位 Hz,连接到微处理器并驱动运行的振荡器的最大频率,超过此时钟频率,微处理器将不能正常工作
- 可寻址存储器的字节数
到 1972 年 4 月,英特尔发布 8008 芯片,一个时钟频率位 200KHz,可寻址空间为 16 KB 的 8 位微处理器。
启发或想法
虽然看到介绍已经大致了解了这绝不是一本晦涩难懂的书,但还是惊讶于作者可以将电路,布尔代数等等复杂的概念如此深入浅出地描述给作者,并且中间穿插非常多的物理学、数学发展历史,以及历史上这种对计算机硬件发展起决定性作用的部件,继电器,晶体管等等,让这一本书不但在了解计算机组成部分之外还了解到了大量有趣的历史决定时刻,让我感受到了那个天才,英雄辈出的时代精神。
在读书的过程中,不断地有各个时期学过的课程浮现在眼前,物理中的电磁学,到大学时期的,电路,代数,汇编等课程,在阅读的过程中非常享受所有知识融为一体的感觉。
曾经有一个问题总是困扰着我,[[人类为什么在近 200 年发展如此快]]?在这一本书中我更进一步的体会到了如下的几点:
- 人类信息交换的速度变快了,这也就意味着[[波普尔]]所说的假设验证的速度变快了,在地球一端所提出的概念,可以在地球的另一端被验证。而这一过程恰恰是伴随着电路,电报,计算机,网络的发明而发生的
- 社会的分工和合作,知识的交换创造了更高的价值,知识的自由分享产生了巨大的复利,[[布尔]]多年前的代数理论,[[冯诺伊曼]]构想的计算机结构,等等一系列思想的发展总是以超前的姿态引领着人类科技的发展
谁应该看这本书
- 想要了解计算机是如何工作的人
- 想要了解计算机发展历史的人
印象深刻的 Quotes
在作者对芯片的描述中,作者总结出三点去描述微处理器,时钟频率,可寻址字节数,以及位数,而这三者则是作者铺垫了非常多章节的内容,当我读到时顿时感受到了作者清晰的写作思路。
Plex Media Server 备份恢复和数据迁移
这些年来逐渐将我的音乐库迁移到了 Plex Media Server 上,因为之前部署的 Plex 是用了 Docker,迁移到独立主机之后想直接安装,所以想将之前的 Plex 数据迁移出来,直接恢复使用。
备份
备份是一定要做的事情,为了数据安全。
通常 Plex 中的媒体文件都会用 [[Syncthing]] 来做一份备份冗余,但是 Plex Media Server 生成的媒体文件,包括 viewstates, metadata, settings 等等就需要直接去备份 Plex Media Server 的内容了。
在 Debian/Fedora/CentOS/Ubuntu 中:
/var/lib/plexmediaserver/Library/Application Support/Plex Media Server/
数据库地址
Plex 在本地使用 SQLite3 存储数据。
在 macOS 上:
~/Library/Application\ Support/Plex\ Media\ Server/Plug-in\ Support/Databases/com.plexapp.plugins.library.db
Windows 上:
"%LOCALAPPDATA%\Plex Media Server\Plug-in Support\Databases\com.plexapp.plugins.library.db"
在 Linux 上(包括 NAS):
$PLEX_HOME/Library/Application\ Support/Plex\ Media\ Server/Plug-in\ Support/Databases/com.plexapp.plugins.library.db
备份时不要对备份的数据进行任何修改,防止备份数据库出错。
如果修改了本地媒体文件的地址,需要更新数据库:
UPDATE `section_locations`
SET `root_path`=
REPLACE(`root_path`,
'/Old_PATH/',
'/NEW_PATH/')
WHERE `root_path` like '%Old_PATH%';
如果确定需要修改数据库中的路径,那么确保所有表中的路径都要修改。
移动媒体文件到另外的位置
如果只是升级磁盘,文件的目录没有变化,那么只需要在迁移之前停掉 Plex Media Server,然后升级完成之后再启动即可。
如果更改了媒体文件的路径,那么就需要多出几步。
- 首先停用 Emptying of Trash
- 在管理后台禁用
Empty trash automatically after every scan
- 在管理后台禁用
- 停止 Plex Media Server
- 将文件内容拷贝到新的位置
- 启动 Plex Media Server
- 启动 Plex Web App
- 编辑 Libraries ,添加新的位置到库中,暂时保留之前的文件路径,需要对每一个移动的库都操作一遍
- 更新库,在添加之后,执行一次
Scan Library Files,服务器会检查新位置的文件内容,然后和已经有的媒体文件做关联 - 等待完成扫描之后移除老的文件路径。
reference
使用 Owncast 搭建自己的在线视频串流直播间
Owncast 是一个开源,可自行架设的、去中心化的,单用户视频串流工具。Owncast 使用 Go 语言编写。支持简单的在线聊天,支持 HLS 和 S3 存储。
Owncast 可以很好的成为 Twitch,YouTube Live 等等在线直播平台的代替。用户可以完整地控制自己的内容以及服务器。
Prerequisite
- Ubuntu 20.04
- [[FFmpeg]] 4.2 以上版本,需带有 x264/var_stream_map
Docker 安装
Docker compose1 如下:
version: '3.3'
services:
owncast:
image: 'gabekangas/owncast:latest'
restart: always
volumes:
- '${CONFIG_PATH}/data:/app/data'
ports:
- '8080:8080'
- '1935:1935'
启动容器之后,进入 /admin 页面,默认的用户名和密码是,admin 和 abc123。
手动安装
安装 FFmpeg
apt update
apt install ffmpeg
下载 owncast:
mkdir -p /opt/owncast && cd /opt/owncast
wget https://github.com/owncast/owncast/releases/download/v0.0.2/owncast-0.0.2-linux-64bit.zip
unzip owncast-0.0.2-linux-64bit.zip
修改配置文件:
vim config.yaml
修改自己的串流秘钥和信息,样例文件内容如下:
# See https://owncast.online/docs/configuration/ for more details
instanceDetails:
name: EV //名称
title: EV Live Stream //网站标题
logo:
small: /img/logo128.png
large: /img/logo256.png
tags:
- music
- software
- streaming
# https://owncast.online/docs/configuration/#external-links
# for full list of supported social links. All optional.
socialHandles:
- platform: github
url: http://github.com/owncast/owncast
- platform: mastodon
url: http://mastodon.something/owncast
videoSettings:
# Change this value and keep it secure. Treat it like a password to your live stream.
streamingKey: secret_key //串流秘钥
启动 owncast
./owncast
启动后查看日志文件 transcoder.log 如果没有报错着运行成功,如报错无法正常串流播放
可以使用 screen 或者 [[tmux]] 等工具在使用后台运行 owncast:
screen -S live //创建新的命令行
cd cd /opt/owncast //进入目录
./owncast //执行脚本
服务器需要开放端口 1935,8080
设置 OBS 串流
服务器 rtmp://127.0.0.1/live 串流秘钥 [secret]
播放地址 http://127.0.0.1:8080
成功运行之后,日志文件在 transcoder.log
自动安装
cd /your/own/path
curl -s https://owncast.online/install.sh | bash
执行成功之后会返回默认的端口和默认的 streaming key。
cd owncast
./owncast
# change port
./owncast -webserverport 8095
配置 Nginx 反向代理,如果熟悉 [[Nginx Proxy Manager]] 也可以直接使用这个反向代理。
添加配置文件 vi /etc/nginx/conf.d/owncast.conf:
server {
listen 80;
server_name 你的域名;
location / {
proxy_pass http://127.0.0.1:8080; #8080改为Owncast对外开放的端口,默认为8080
proxy_redirect off;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
}
}
测试:
nginx -t
使配置生效:
nginx -s reload
sudo systemctl start nginx
sudo systemctl enable nginx
# 获取证书
sudo certbot --nginx
配置 [[systemd]],修改文件 vi /etc/systemd/system/owncast.service:
[Unit]
Description=Owncast Service
[Service]
Type=simple
WorkingDirectory=/your/own/path/owncast #注意替换位置
ExecStart=/your/own/path/owncast/owncast #注意替换位置
Restart=on-failure
RestartSec=5
[Install]
WantedBy=multi-user.target
生效:
systemctl daemon-reload
systemctl enable owncast
systemctl start owncast
设置 OBS
在 OBS 官网 安装 OBS,在设置>服务中选择自定义(Custom),在管理员页面获取 RTMP 服务器链接和流密钥并填入 OBS 中,点击 Start Streaming 测试链接,开始推流。
FFmpeg
也可以直接从命令行使用 [[FFmpeg]] 来推流到 Owncast 服务器。
ffmpeg -re -i /path/to/video.mp4 -c copy -f flv rtmp://localhost:1935/live/secret_key
# or
ffmpeg -i "http://IP_OF_HDHR:5004/auto/vCH.N" -c:v libx264 -c:a aac -b:v 512K -maxrate 512K -bufsize 1M -f flv rtmps://OWNCAST_URL:PORT/live/STREAM_KEY
# or
ffmpeg -video_size 1280x720 -i $1 \
-c:v libx264 -b:v 512k -maxrate 1984k -bufsize 3968k \
-c:a aac -b:a 128k -ar 44100 \
-f flv rtmp://live.einvrne.info/live/KEY
或者:
ffmpeg -f alsa -ac 2 -i hw:1,0 -thread_queue_size 64 \
-f v4l2 -framerate 60 -video_size 1280x720 -input_format yuyv422 -i /dev/video2 \
-c:v libx264 -preset veryfast -b:v 1984k -maxrate 1984k -bufsize 3968k \
-vf "format=yuv420p" -g 60 -c:a aac -b:a 128k -ar 44100 \
-f flv rtmp://<ip-of-your-server>/live/<your-streaming-key>
如果串流 MP4 遇到:
Codec mpeg4 is not supported in the official FLV specification,
解决方案:
ffmpeg -re -nostdin -i "$file" \
-vcodec libx264 -preset:v ultrafast \
-acodec aac \
-f flv rtmp://<your-server>/app/STREAM_KEY
说明:
-vcodec codec设置视频编码器,是-codec:v的别名-acodec codec设置音频解码器,是-codec:a的别名-nostdin表示禁止交互输入-preset:v表示使用 FFmpeg 默认的编码,按速度降序 ultrafast, superfast, veryfast, faster, fast, medium, slow, slower, veryslow, placebo-f fmt强制指定输入或输出的文件格式
ffmpeg -re -i ~/INPUT_FILE -vcodec libx264 -profile:v main -preset:v medium -r 30 -g 60 -keyint_min 60 -sc_threshold 0 -b:v 2500k -maxrate 2500k -bufsize 2500k -filter:v scale="trunc(oha/2)2:720" -sws_flags lanczos+accurate_rnd -acodec libfdk_aac -b:a 96k -ar 48000 -ac 2 -f flv rtmp://live.twitch.tv/app/STREAM_KEY
reference
修复突然断电后 git 仓库 corrupt
今天在 Ubuntu 下编译项目,突然负载飙升到 140 多,然后整个系统就卡住,所有 UI 卡死,无奈之下只能对系统强制重启,不过重启之后发生了一件更严重的问题,当我访问我的项目,执行 git status 之后,显示:
error: object file .git/objects/2b/ca69094c49050b232756d8d862c39be9d4fe55 is empty
error: object file .git/objects/2b/ca69094c49050b232756d8d862c39be9d4fe55 is empty
fatal: loose object 2bca69094c49050b232756d8d862c39be9d4fe55 (stored in .git/objects/2b/ca69094c49050b232756d8d862c39be9d4fe55) is corrupt
git 仓库损坏了!虽然之前把 git 仓库放到 Syncthing 中同步也曾经出现过一次 corrupt 的情况,但是之前修复的时候已经把全部代码 push 到了远端仓库,所以直接重新拉一下代码就可以。
但是这一次我本地的分支没有推送到远端所有的修改还在本地,但是这个时候已经无法访问本地的分支代码了!
这个时候立马去网上 Google 解决办法,大部分的回答都让我删除掉 .git 目录,然后重新去远端获取。但这个方法一定会丢掉本地的修改,所以没有尝试,等到最后实在没有办法的时候再试试吧。
rm -fr .git
git init
git remote add origin your-git-remote-url
git fetch
git reset --hard origin/master
git branch --set-upstream-to=origin/master master
然后继续查看解决办法的时候发现了,可以使用:
git repair
git repair --force
执行完成之后,发现分支回来了。然后赶紧拉一下代码 git pull。
之后在切换分支的时候发现本地的分支还在,所以基本完成修复。
另外一个项目也出现了相同的问题,不过本地分支名丢失了,不过还好之前合并过其他分支,在 git log 中找到之前的分支最后一次提交 commit id,重新 checkout 一个新分支即可。
深入 .git 目录 refs
Git 中大部分行为都会有一个 hash 来存储,可以使用 git show 52611da62ae41498fa186ec8b4913b5c7173a896 ,但是这需要用户记住所有的 hash 值,但 hash 值是一个随机的字符串,非常难以记忆,所以 Git 提供了一个 references(引用),或者简称 refs。
引用是存储在 .git/refs 目录下的文件,通常这个文件中包含一个 commit object 的 hash。
$ ls -F1 .git/refs
heads/
master
remotes/
tags/
v0.3
heads 目录中包含了所有本地分支,每一个文件都对应着一个分支名字,文件内容就是该分支最新的 commit hash。
在 Git 中,分支其实就是一个引用,修改 master 分支,其实 Git 只需要做的事情就是改变 /refs/heads/master 文件内容。而类似的,创建一个分支,其实就是将 commit hash 写到一个新的文件中。
而同样 tags 目录也是一样的,这个目录中包含标签的信息。
Special Refs
Git 也有一个特殊的引用,HEAD,这个一个当前分支的引用,而非对 commit hash 的引用。
cat .git/HEAD
ref: refs/heads/dev
可以看到的是当前正在 dev 分支。当然也可以将 HEAD 直接指向一个真实的 commit id,这个时候 Git 会提示 detached HEAD state,意味着你当前不是在一个分支上。
除了 HEAD 这个特殊的 refs,还有一些其他的:
FETCH_HEAD: 从远端最近一次拉取的分支ORIG_HEAD: A backup reference to HEAD before drastic changes to itMERGE_HEAD: The commit(s) that you’re merging into the current branch with git merge.CHERRY_PICK_HEAD: The commit that you’re cherry-picking.
Reflog
Reflog 是 Git 的安全网,他会记录在仓库中所有的操作。可以将其想象成一个本地仓库修改的时序历史记录.
Git reflog 是一个你对本地仓库所作的所有修改的记录。每一次提交,每一次切换分支,都会在 reflog 中留下记录。
在 Git 仓库中执行:
git reflog
ceb40ab HEAD@{0}: commit: messsage
reference
金融的本质 读书笔记
《金融的本质》是美联储主席[[本 伯南克]]关于美联储历史,以及在 2008 年应对金融危机手段的一本科普读物。本伯南克以非常通俗的语言讲述了美联储的历史,以及央行的职能。每一章节后面都有一个答学生的提问,所以看起来就像是一本写给学生的科普读物,读完可以对美联储是做什么的?为什么要成立美联储?以及当危机来临时美联储能够做什么?有非常详细的介绍和解释。
怎么知道的这一本书
在和朋友聊天的时候,说到美联储,于是朋友给推荐了这一本。
几句话总结书的内容
- 美联储的起源与历史,以及美联储调整经济的手段
- 本 伯南克应对金融危机的应对措施和后续影响
- 危机之后有什么弥补手段
启发或想法
美联储的作用
美联储作为美国的央行,其决定对全世界的经济都会产生一定的影响,这两天美联储加息,股市暴跌,成为了日常的新闻。而美联储为什么要这么做呢?很多报道都会提到为了压制美国的通货膨胀,而为什么美联储能够通过调整利率来影响通货膨胀呢?这一本书里面都有详细的说明。
中央银行的职能:
- 维持金融稳定,保证金融体系正常运行,缓解或阻止金融危机或金融恐慌
- 维持经济稳定,保持经济增长,保持低通胀,避免大幅波动
美联储的影响经济的手段
显然为了实现央行的职能,美联储能够使用一些工具来调整经济运行。
- 维持金融稳定,央行的工具是成为最后贷款人角色,为金融机构提供短期流动性和资金支持。
- 为了维持经济稳定,央行最重要的工具是货币政策,在正常时期,货币政策主要体现为短期利率的调整。在通常情况下美联储可以通过在公开市场买卖证券(通常是短期政府债券),来降低或提高短期利率。当经济增长过缓或通胀水平过低时,美联储可以通过降息来刺激经济发展。
这里提到的短期利率,主要是对隔夜拆借利率的管理。也就是调整各银行向美联储借钱的成本,隔夜利率又称联邦基金利率。通过提高或降低短期利率,美联储可以影响更大范围的利率。
在最极端的情况下,如果调整货币政策已经无法影响经济,美联储还可以实行大规模资产购买计划,即媒体和其他地方所说的量化宽松。
基本工具:
- 货币政策,隔夜拆借利率
- 流动性供给(最后贷款人)
金本位的问题
什么是金本位呢?相信大部分人在教科书上曾经学过,简单来说就是一个国家的货币发行和黄金储备挂钩,央行有多少黄金才能发行多少货币,金本位是一种货币体系,在这个体系中,货币的价值以黄金的重量来衡量。这也就意味着手上的货币可以到央行兑换黄金。
但是也相信大部分人都知道金本位在上世纪已经破产了,大部分的国家已经抛弃了金本位。
金本位的缺点:
- 资源浪费,开采,运输成本
- 限制了货币供给,央行不能灵活地调整利率(在经济不景气时下调利率,在通胀时上调利率)
- 金本位的国家货币之间形成一个固定汇率体系,一个国家货币供应量出现问题,会传导到另一个国家,从而剥夺另一个国家独立管理其本国货币政策的权力
- 投机,短期的投机行为,挤兑银行
金本位的优点:
- 维持货币价值的稳定,让通胀维持在一定水平(长期如此),但是短期会经常发生通货膨胀或通货紧缩
通货膨胀的本质
通货膨胀无论在何时何地都是一个货币现象。通过货币政策来维持过底的失业率,最终会引发通货膨胀。 价格是经济的温控器,是经济赖以运行的机制。所以,管控工资和物价意味着整个经济体存在短缺及其他各种问题。 低通胀是一件非常好的事情,长时间低而稳定的通胀率会使经济更加稳定,有利于保持健康的增长率和生产率以维持经济活动。
大而不倒
[[大而不倒]],有一部同名的纪录片讲述的就是 08 年金融危机之后,美国财政部长,联合美联储,巴菲特等等在经济中扮演重要角色的人物拯救华尔街金融机构的故事。而大而不倒也成为了经济中一个潜在的问题,如果一家机构大到足够影响经济,那么就不会让其轻易地倒闭,显然长期来看对于整个宏观经济是不利的。如果一个体系中存在一些企业“大而不倒”(too big to fail),那么这个体系一定存在某些根本性缺陷。
想要确保金融体系有所变革,为的是以后再有类似美国国际集团这样的系统重要性机构面临此类压力时,能够以一种安全的方式倒闭。
若为自由故 读书笔记
《若为自由故:自由软件之父理查德·斯托曼传》是 [[Richard Stallman]] 的个人传记,在读完 [[自由软件 自由社会]] 的时候就把这一本书加入了待看列表。《自由软件 自由社会》中只介绍了 Stallman 关于自由软件的哲学思考,没有涉及到 Stallman 是怎么形成自己的思想的原由。而这一本传记能够更清楚的看到 Stallman 如何争取一台打印机驱动,到对争取软件自由运动的全部过程。
虽然站在 2022 年再去回顾这位传奇黑客有一点晚,并且 Stallman 固执的性格也常常出现在新闻中,但是这一切都无法抹去他在自由软件运动,在 GNU 项目,在自由软件基金会的贡献。
Richard Stallman 是谁?
鉴于可能有人不认识 Stallman,那么就从他的作品,Emacs 说起,这是一款可以并肩 Vim 的编辑器,Stallman 就是 Emacs 的原始作者,Stallman 还凭借一己之力创造了 GCC 编译器,GNU 项目,并且在专业律师的帮助下制定了 [[GNU General Public License]] GNU 通用许可证。
自由软件运动
Stallman 发起的自由软件运动,无疑也蕴含着一定的哲学思考,软件代码不可能完美无缺,所以最好的办法就是通过共享代码,通过不断地修改来逐渐完善。
没有人可以写出没有错误的代码。通过共享软件代码,黑客们把不断改进程序作为终极的目标,甚至超越了个人野心。
「自由」是一个抽象的名词,多少哲学家通过不同的角度去讨论自由,社会学的自由,个人的自由,[[消极自由]],[[积极自由]],而随着计算机,软件工程的发展,在数字领域如何获得个人的自由?Stallman 无疑给了我们一种思考的路径。尤其是伴随着互联网成长的我们,见证了太多的互联网服务关闭,见证了太多的软件停止维护,最后我们自己产生的数据变得不再是属于我们自己,曾经试过的软件再也无法打开。Stallman 个人的经历告诉我们,即使互联网服务给予了我们更多的便利,即使某些软件可以让我们更快的实现目标,我们也要时刻警惕,因为我们随时会失去自由。就像哈耶克曾经说得那样,「愿意放弃自由来换取保障的人,他最终既得不到自由,也得不到保障。」
Stallman 发起的自由软件运动究竟是什么呢? 可以参考 Stallman 关于 [[自由软件]] 的四大自由定义:
- 基于任何目的、按自己的意愿运行软件的自由
- 学习软件如何工作的自由,按意愿修改软件以符合自己需求的自由
- 分发软件副本的自由
- 将修改过的软件版本再分发给其他人的自由,这样整个社区就有机会共享你对软件的修改
简单来说就是运行、复制、学习、分发、修改的自由。
大教堂与集市
之前在阅读 [[大教堂与集市]] 的时候一直以为作者 [[Eric Raymond]] 是以商业公司开发模式和开源社区开发模式作为对比才写下的[[大教堂与集市]],但看完这本书,才知道原来 Raymond 在书中所指的大教堂模式指的是在 Stallman 领导下的 GNU 项目。整个 GNU 项目就是“大教堂”的开发模式,有计划地修建而成的宏伟的黑客精神的纪念碑,经得起时间的考验。另一方面,Linux 则更像是一个“嘈杂的大集市”,它是在 Internet 去中心化的松散组织结构中开发出来的。[[Linus Torvalds]] 所创建的这种「集市」开发模式反映了 Linus 的个性,作者写到,「从 Linus 的观点来看,最好的管理工作不是要加强对事情的控制,而是要保持思维的活跃度。」
自由软件和开源
在此之前,我几乎把自由软件和开源混为一谈,但显然如果代指同一个东西,人类没有必要发明两个名字,自由软件(Free software)和开源 (Open Source),显然 Stallman 是自由软件运动的发起者,他当然更支持自由软件,他在描述二者的区别时说道,「开源软件的观念更偏向于实用主义;而自由软件的观念则更强调用户自由。」当然自由软件和开源两者有很多共性的地方,支持 Open Source 的一派,部分原因是为了避免使用 Free 一词,
谁应该看这本书
想要了解计算机,尤其是自由软件发展历程的人。
Quotes
我希望每个人都能珍视自由,也能拥有自由。 没有人可以写出没有错误的代码。通过共享软件代码,黑客们把不断改进程序作为终极的目标,甚至超越了个人野心。
文章分类
最近文章
- AI Shell 让 AI 在命令行下提供 Shell 命令 AI Shell 是一款在命令行下的 AI 自动补全工具,当你想要实现一个功能,敲一大段命令又记不住的时候,使用自然语言让 AI 给你生成一个可执行的命令,然后确认之后执行。
- 最棒的 Navidrome 音乐客户端 Sonixd(Feishin) Sonixd 是一款跨平台的音乐播放器,可以使用 [[Subsonic API]],兼容 Jellyfin,[[Navidrome]],Airsonic,Airsonic-Advanced,Gonic,Astiga 等等服务端。 Sonixd 是一款跨平台的音乐播放器,可以使用 [[Subsonic API]],兼容 Jellyfin,[[Navidrome]],Airsonic,Airsonic-Advanced,Gonic,Astiga 等等服务端。
- 中心化加密货币交易所 Gate 注册以及认证 Gate.io 是一个中心化的加密货币交易所。Gate 中文通常被称为「芝麻开门」,Gate 创立于 2013 年,前身是比特儿,是一家致力于安全、稳定的数字货币交易所,支持超过 1600 种数字货币的交易,提供超过 2700 个交易对。
- 不重启的情况下重新加载 rTorrent 配置文件 因为我在 Screen 下使用 rTorrent,最近经常调试修改 rtorrent.rc 配置文件,所以想要找一个方法可以在不重启 rTorrent 的情况重新加载配置文件,网上调查了一下之后发现原来挺简单的。
- Go 语言编写的网络穿透工具 chisel chisel 是一个在 HTTP 协议上的 TCP/UDP 隧道,使用 Go 语言编写,10.9 K 星星。