每天学习一个命令:perf 性能分析工具
Perf 全称Performance Event,是随着 Linux 2.6+ 一同发布的性能分析工具。通过它,应用程序可以利用 PMU,tracepoint 和内核中的特殊计数器来进行性能统计。它不但可以分析指定应用程序的性能问题 (per thread),也可以用来分析内核的性能问题,当然也可以同时分析应用代码和内核,从而全面理解应用程序中的性能瓶颈。
安装
perf 工具在 linux-tools 下面,安装如下三个包即可
apt-get install linux-tools-common linux-tools-generic linux-tools-`uname -r`
Perf 能触发的事件分为三类:
- hardware : 由 PMU 产生的事件,比如 cache-misses、cpu-cycles、instructions、branch-misses …等等,通常是当需要了解程序对硬件特性使用情况时使用
- software : 是核心程序产生的事件,比如 context-switches、page-faults、cpu-clock、cpu-migrations …等等
- tracepoint : 是核心中的静态 tracepoint 所触发的事件,这些 tracepoint 用來判断在程序执行时期核心的行为
使用
当通过非 root 用户执行 perf 时会遇到权限不足的错误,需要 sudo -i 切换到 root 用户来执行
打印出 perf 可触发的 event
perf list
实时显示当前系统的性能统计信息
perf top
通过概括精简的方式提供被调试程序运行的整体情况和汇总数据
perf stat ./test
perf 命令过于复杂,他有很多子命令集,更多的信息可以参考下面的链接。
reference
Spark 学习笔记
Spark 是一个依托于 Hadoop 生态的分布式内存计算框架,在吸收了 Hadoop MapReduce 优点的基础上提出以 RDD 数据表示模型,将中间数据放到内存,用于迭代运算,适用于实时计算,交互式计算场景。
什么是 Spark
简单的讲是一个通用计算引擎。
- A fast and general engine for large-scale data processing
- An open source implementation of Resilient Distributed Datasets (RDD)
- Support cyclic data flow and in-memory computing
快速入门
- 官方快速入门文档 了解 Spark 基本使用,下载包,本地执行,了解基本的命令
- RDD 编程文档 了解 RDD 编程
- 参考官方例子 实现完整 application
- 学习 Spark on Cluster
- Spark SQL 官方文档
性能对比
内存中比 Hadoop MapReduce 快 100 倍,磁盘中快 10 倍。
几个名词
- MapReduce 分布式数据处理模式和执行环境,运行于大型商用机集群
- HDFS 分布式文件系统
- HBase 分布式,列存储数据库,HBase 使用 HDFS 作为底层存储,同时支持 MapReduce 批量计算和点查询
- Zookeeper 分布式、高可用协调服务,提供分布式锁之类的基本服务用于构建分布式应用
- Hive 分布式数据仓库,Hive 管理 HDFS 中存储的数据,并提供基于 SQL 的查询语言(运行时翻译为 MapReduce 作业)用以查询数据
基本组件
Spark 是一个用来实现快速而通用的集群计算的平台。
- Spark core 主要功能 RDD 相关 API
- Spark SQL Spark 用来操作结构化数据的程序包
- Spark Streaming 是 Spark 提供的对实时数据进行流式计算的组件
- MLlib Spark 中用来进行机器学习和数学建模的软件包
- GraphX Spark 中进行图计算的函数库
- Cluster Managers 管理集群节点的平台,包括 YARN,Mesos 和 Standalone Scheduler
RDD 弹性分布式数据集
RDD 是 Spark 的核心概念,具有容错机制可以被并行操作的元素集合。RDD 可以通过并行化(parallelizing) 一个存在于 driver program 中的集合,或者引用外部存储系统上的数据集,比如共享文件系统,HDFS,HBase 或者任何提供了 Hadoop InputFormat 的数据源。
RDDs can be roughly viewed as partitioned, locality aware distributed vectors
基本使用
通过[官方快速入门文档][1],这个文档主要通过本地 shell 运行一些例子,通过例子可以初步的学习怎么使用 Spark,用 Spark 的思维方式思考。
看过基本的 Spark 之后可以进一步了解 [RDD 官方指南][2],
本机运行
Spark 本身是用 Scala 写的,运行在 Java 虚拟机 (JVM) 上。要在你的电脑或集群上运行 Spark, 你要做的准备工作只是安装 Java 6 或者更新的版本。如果你希望使用 Python 接口,你还需要一个 Python 解释器 (2.6 以上版本)。
每一个 Spark 应用都由一个驱动器(driver program)来发起集群上的各种并行操作。driver program 包含应用 main 函数,定义集群上的分布式数据集。driver program 通过 SparkContext 对象访问 Spark,这个对象代表对计算集群的一个连接。
shell 中已经默认创建了一个 SparkContext 对象 sc,SparkContext 可以用来创建 RDD。driver program 通常要管理多个执行器 (executor)。
实例
Scala 版本
val sparkConf = new SparkConf().setAppName("wordcount")
val sc = new SparkContext(sparkConf)
val lines = sc.textFile("hdfs://...")
val words = lines.flatMap(_.split(" "))
val wordsCount = words.map(x=>(x,1))
val counts = wordsCount.reduceByKey(_ + _)
val result = counts.collect()
Fluent Style:
val result = sc.textFile("hdfs://...")
.flatMap(_.split(" "))
.map(x=>(x,1))
.reduceByKey(_ + _)
.collect()
RDD
Spark 中的 RDD 是一个不可变的分布式对象集合,每个 RDD 都被分为多个分区,这些分区运行在集群中的不同节点上。
RDD 支持两种操作:转化(transforming)和动作(action)。转化操作会由一个 RDD 生成一个新 RDD,比如 map(), filter() 等:
linesWithJava = lines.filter(lambda line: "Java" in line)
动作操作(action)会对 RDD 计算结果,并将结果返回到 driver program 中,或者把结果存储到外部系统(HDFS 等)中,比如 first(), count() 等:
linesWithJava.first()
创建 RDD
Spark 提供如下方式创建 RDD:
- 读取外部数据集
- driver program 中对集合并行化
最简单的方式就是将集合传给 SparkContext 的 parallilize() 方法,这种方法需要将整个数据集存放到一台机器中,所以只适合学习使用。或者使用 textFile() 来从外部存储中读取。
RDD 操作
filter() 操作不会改变已有 inputRDD 数据,会返回一个全新的 RDD。
RDD transforming 操作都是惰性求值,被调用 action 操作之前 Spark 不会开始计算。不应当将 RDD 看做存放特定数据的数据集,最好把 RDD 当作通过转化操作构建出来的,记录如何计算数据的指令列表。把数据读取到 RDD 同样也是惰性的。当调用 sc.textFile() 时,数据并没有真正的被读取。
针对集合中每个元素的操作
最常用的就是 filter 和 map。filter 接受一个函数,将 RDD 中满足该函数的值放入新的 RDD,map 接受一个函数,函数作用于每一个元素,函数返回值作为结果。
如果希望对每一个输入的元素输出多个元素,该功能操作叫做 flatMap(),提供给 flatMap() 的函数分别应用到输入的每一个元素,返回的是一个返回值序列的迭代器。输出的 RDD 不是由迭代器组成,而是一个包含各个迭代器可访问的所有元素的 RDD。 flatMap 最简单的用途,将输入的字符串切分为单词。
Scala
val lines = sc.parallelize(List("hello world", "hi"))
val words = lines.flatMap(line => line.split(" "))
words.first() // 返回"hello"
flatMap 可以看作将返回的迭代器“压扁”,得到一个由各个列表中元素组成的 RDD,而不是一个由列表组成的 RDD。
伪集合操作
RDD 本身不是严格意义上的集合,但也支持许多数学意义的集合操作,比如合并和相交。需要注意的是 RDD 具有相同的数据类型。
- rdd.distinct() 转化为唯一元素的 RDD
- rdd.union(rdd2) 并集
- rdd.intersection(rdd2) 交集
- rdd.subtract(rdd2) rdd-rdd2
- rdd.cartesian(rdd2) 笛卡尔积
action 操作
常见的 reduce,接收一个函数,函数操作两个元素并返回一个同样类型的元素。
fold() 和 reduce() 类似,接收一个与 reduce() 相同签名的函数,加上一个初始值来作为每一个分区第一次调用的结果。
aggregate() 函数不要求返回值类型必须和输入的 RDD 类型相同。比如用 aggregate 来计算 RDD 的平均值
Scala:
val result = input.aggregate((0, 0))(
(acc, value) => (acc._1 + value, acc._2 + 1),
(acc1, acc2) => (acc1._1 + acc2._1, acc1._2 + acc2._2)
)
val avg = result._1 / result._2.toDouble
collect() 可以将数据返回到 driver program 中,collect() 需要将数据复制到 driver program 所以要求所有数据都必须能一同放到单台机器内存中。
take(n) 返回 RDD 中 n 个元素,并且尝试只访问尽量少的分区,会得到一个不均衡的集合。
如果数据定义了顺序,可以使用 top() 从 RDD 中获取前几个元素,top 会使用默认的顺序,也可以提供比较函数。
takeSample(withReplacement, num, seed) 函数可以从数据中获取采样,并指定是否替换。
foreach() 操作对 RDD 中每个元素进行操作,而不需要把 RDD 发回本地。
| 函数名 | 目的 | 示例 | 结果 |
|---|---|---|---|
| collect() | 返回 rdd 中的所有元素 | rdd.collect() | {1, 2, 3, 3} |
| count() | rdd 中的元素个数 | rdd.count() | 4 |
| countByValue() | 各元素在 rdd 中出现的次数 | rdd.countByValue() | {(1, 1), (2, 1), (3, 2)} |
| take(num) | 从 rdd 中返回 num 个元素 | rdd.take(2) | {1, 2} |
| top(num) | 从 rdd 中返回最前面的 num 个元素 | rdd.top(2) | {3, 3} |
| takeOrdered(num)(ordering) | 从 rdd 中按照提供的顺序返回最前面的 num 个元素 | rdd.takeOrdered(2)(myOrdering) | {3,3} |
| takeSample(withReplacement, num, [seed]) | 从 rdd 中返回任意一些元素 | rdd.takeSample(false, 1) | 非确定 |
| reduce(func) | 并行整合 rdd 中所有数据 | rdd.reduce((x, y) => x + y) | 9 |
| fold(zero)(func) | 和 reduce() 一 样,但是需要提供初始值 | rdd.fold(0)((x, y) => x + y) | 9 |
| aggregate(zeroValue)(seqOp, combOp) | 和 reduce() 相似,但是通常返回不同类型的函数 | rdd.aggregate((0, 0))((x, y) =>(x._1 + y, x._2 + 1),(x, y) => (x._1 + y._1, x._2 + y._2)) | (9,4) |
| foreach(func) | 对 rdd 中的每个元素使用给定的函数 | rdd.foreach(func) | 无 |
Spark SQL
Spark SQL 用来操作结构化和半结构化的数据,Spark SQL 提供:
- 从结构化数据源(JSON,Hive,Parquet) 中读取数据
- 不仅支持 Spark 内部使用 SQL 查询,也支持从外部标准 JDBC/ODBC 连接中进行查询
- Spark SQL 支持 SQL 与常规 Python/Java/Scala 整合,包括连接 RDD 和 SQL 表、公开的自定义 SQL 函数接口等等
Spark SQL 提供特殊的 RDD,SchemaRDD,存放 Row 对象 RDD,每个 Row 对象代表一行记录。
Spark Stream
很多应用需要实时计算,比如可能有些应用需要实时追踪 page view, 然后将数据给 machine learning model 训练,来自动检测异常。Spark Streaming 就是提供这样的功能。
Spark 建立在 RDD 基础上, Spark Streaming 提供了 DStreams 抽象,叫做 discretized streams。DStreams 是一个不断输入的序列数据。在内部,每一个 DStreams 都是时间序列的 RDD,离散的数据。
Spark 运行方式
- 单机运行
- 伪分布式运行
- 分布式运行
在集群中运行 Spark
Spark 可以在各种各样的集群管理器(Hadoop YRAN,Apache Mesos )中运行。分布式环境下,Spark 集群采用主从结构,一个节点负责中央协调,中央协调节点被称为驱动器 (driver)节点,工作节点被称为执行器(executor)节点,驱动器节点可以和大量执行器节点进行通信,作为独立 Java 进程运行。驱动器节点和执行节点一起被称为一个 Spark 应用(application)。
驱动器节点
驱动器是执行程序 main() 方法的进程。它执行用户编写的 SparkContext,创建 RDD,RDD 转化和行动操作的代码。
驱动器程序在 Spark 下职责:
- 把用户程序转为任务,Spark 把逻辑转化为步骤(stage),每个步骤由多个任务组成,任务被打包送到集群,任务是 Spark 中最小的工作单位
- 为执行器节点调度任务,Spark 驱动器程序吧任务基于数据所在位置分配给合适的执行器进程,驱动器进程会跟踪缓存数据位置,利用这些位置信息来调度任务,减少数据的网络传输
执行器节点
执行器负责 Spark 作业运行任务,任务相互独立。执行器进程的作用:
- 负责运行组成 Spark 应用的任务,并将结果返回给驱动器进程
- 通过自身的块管理器(block Manager)为用户程序中要求缓存的 RDD 提供内存存储
spark-submit 提供工具
Spark 为各种集群管理器提供了统一的工具来提交作业,这个工具是 spark-submit
bin/spark-submit --master spark://host:7077 --executor-memory 10g my_script.py
--master标记指定要连接的集群 URL,spark:// 表示集群使用独立模式--executor-memory执行器进程使用的内存量,以字节为单位
Java 和 Scala 可以通过 spark-submit –jars 选项来提交独立的 JAR 包,因为通常都有非常复杂的依赖树,手动维护和提交全部的依赖太过麻烦,常规的做法是通过构建工具,生成单个大 JAR 包,包含应用所有的传递依赖。这个通常被称为超级 JAR(uber)或者组合 JAR(assembly)。Java 和 Scala 最广泛的构建工具是 Maven 和 sbt。
reference
Kerberos 使用
Kerberos 是一个网络验证协议,通过使用密钥来为 client/server 应用提供高强度的安全校验。一个开源的实现是由 Massachusetts Institute of Technology 实现。Kerberos 也在很多商业产品中被使用。
Kerberos 使用 UDP,默认使用 88 端口
在 Hadoop 生态中涉及到的安全问题可以大致归纳为两类,Authentication 和 Authorization:
- Authentication 认证用户身份,也就是证明 A 是 A 的问题
- Authorization 则是权限控制,A 用户能够做什么操作
Kerberos 解决的问题就是证明 A 是 A 的问题,也就是 Authentication。
Kerberos 中的概念
Kerberos 中必须要了解的概念:
- principle ,可以理解成认证主体,client 和 server 的名字
- realm 是空间, principle 需要在 realm 下
- password, 用户密码,可以存放在 keytab 文件中
- credential 凭据
- Long-term Key ,长期保持不变的 key,比如密码,可能长年不变。Long-term Key 在原则上不应当在网络传输,因为一旦被截获,破解者有足够的时间来破解该密码
- Master Key ,而一般情况下对于一个账户,密码仅限于该账户的所有者知道,这种情况下,通常将密码 Hash,得到一个 hash code,一般将这样的 hash code 叫做 Master key。因为 Hash 算法不可逆,同时能够保证密码和 Master Key 一一对应,既保证了密码的安全性,同时保证了 Master Key 和密码本身可以证明身份。
- Short-term Key or Session Key, 因为 Long-term Key 加密的数据包不能用于网络传输,所以出现了 Short-term Key 用来加密需要网络传输的数据,这一类型的 Key 只在短时间内有效,即使被加密的数据被截获,等将 Key 解密出来时,Key 也早已经过期
Kerberos 中有三种角色:
- KDC:负责分发密钥的密钥分配中心,在 Client 和 Server 之间担任共同信任的角色
- Client:需要使用 kerbores 服务的客户端
- Service:提供具体服务的服务端
认证原理
KDC 分发 Session Key 的过程
Client 如果要获取 Server 资源,先得通过 Server 认证,也就是 Client 需要向 Server 提供从 KDC 获取的带有 Server Master Key 加密的 Session Ticket(Session Key + Client Info). Session Ticket 是 Client 访问 Server 的一张门票,而这张门票需要从合法的 Ticket 发行机构(KDC)获取。同时这张票具有防伪标识(被 Server Master Key 加密过)。
简化一下上面描述的过程,当 Client 要获取 Server 资源时,首先要向 KDC 发送 Session Key 的申请,内容就是,我是某某 Client,我需要访问某某 Server 的 Session Key。KDC 在收到请求后,生成一个 Session Key,为保证 Session Key 仅仅限于发送请求的 Client 和它希望访问的 Server,KDC 会将这个 Session Key 生成两个拷贝,分别被 Client 和 Server 使用,并从数据库中提取 Client 和 Server 的 Master Key 对这两个拷贝进行对称加密,对于 Server 的拷贝还会将 Client 的信息保存到 Session Key。KDC 现在有两个加密过的 Session Key,Kerberos 将这两个拷贝一并发送到 Client。
这边会产生一些问题,比如 KDC 并没有验证这个请求的 Client 是否真的是他自己?但仔细想一下,假如 Client B 假装自己的是 A,那么会得到 Client A 和 Server 的 Session Key,而这时 B 并不知道 A 的 Master Key,所以获得的 Session Key 并不能拿来访问 Server。
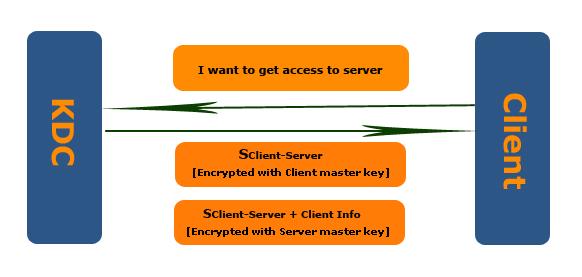
认证过程 Authenticator
经过 KDC 分发 Session Key,Client 获得了两个有效信息,一个通过自己的 Master Key 加密的 Session Key,一个被 Server 的 Master Key 加密的数据包(包含 Session Key 和 Client 的信息)
再此基础上,Server 如何认证 Client。首先 Client 通过自己的 Master Key 对 KDC 分发的 Session Key 解密从而获得 Session Key,随后创建 Authenticator(Client Info + Timestamp) 并用 Session Key 对其加密,最后连同从 KDC 获取的被 Server Master Key 加密过得数据包(Client Info + Session Key)一并发送到 Server 段。把通过 Server Master Key 加密过的数据包称为 Session Ticket。
当 Server 接受到两组数据后,用自己的 Master Key 对 Session Ticket 解密,得到 Session Key。然后用该 Session Key 解密 Authenticator,比较 Authenticator 中的 Client Info 和 Session Ticket 中的 Client Info 从而实现对 Client 的认证。Server 需要检查:
- Authenticator 中 Timestamp 是否在当前时间前后 5 分钟内
- 检查 内容是否一致
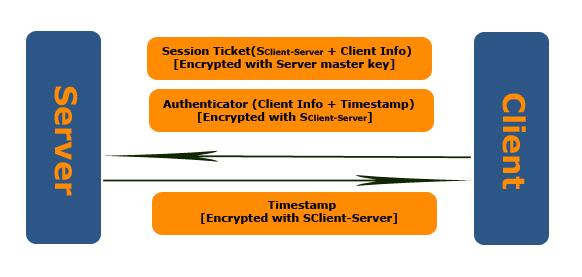
双向认证
Kerberos 的优势在于能够提供双向认证,Server 可以对 Client 认证,Client 也能够对 Server 进行认证。
如果 Client 需要对访问的 Server 认证,会在向 Server 发送的 Credentials 中设置是否需要认证的 Flag,Server 在对 Client 认证成功后,会把 Authenticator 中 Timestamp 提出来,通过 Session Key 加密发送到 Client,Client 接受并使用 Session Key 解密后,确认 Timestamp 是否一致,从而来判断 Server 是 Client 确定要访问的。
完整认证流程
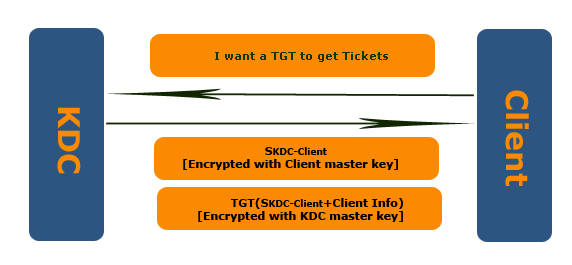
上面提及的认证流程每次 Client 都要使用自己的 Master Key,为了解决这个问题,Kerberos 引入新角色:Ticket Granting Service(TGS),给 Client 提供用于连接 Server 的票据。这样 Kerberos 就有四个角色。完整的认证流程:
- Client 向 KDC 发出请求,希望和 TGS 通信,请求内容分别为自身的 principle 和 TGS 的 principle
- KDC 收到请求后,通过 Client 和 TGS 的 Master Key 生成两份 Session Key,一份用 Client Master Key 加密的 SKDC-Client,一份 KDC master Key 加密的 TGT
- 客户端用自己的 Master Key 解开 Session Key,然后生成 Authenticator(Client Info + Timestamp),并给 TGS 发出请求。Client 会缓存 Session 和 TGT,有了 Session Key 和 TGT 之后,Client 就不在需要自己的 Master Key,此后 Client 可以使用 SKDC-Client 向 KDC 申请用来访问 Server 的 Ticker
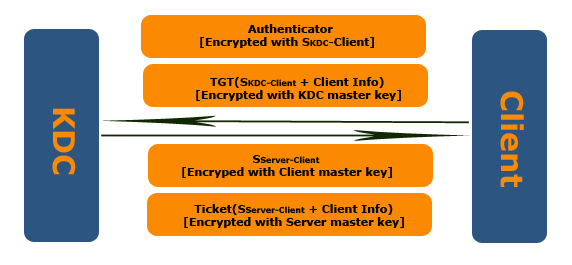
- TGS 收到 Client 的请求后,用自己的 Master Key 解密 Session Ticket,得到 Session Key,然后用 Session Key 解密 Authenticator 得到 Client Info 和 Timestamp ,校验客户端。通过认证之后,TGS 生成一个 Client 和 Server 的 Session Key,而在此处,TGS 将不再使用 Client 的 Master Key 进行对称加密,而是使用 Client 和 TGS 之间的 Session Key 加密
Ticker 是和具体 Server 相关,而 TGT 则是和具体 Server 无关的,Client 可以使用 TGT 从 KDC 获得不同 Server 的 Ticket。
reference
Linux 下自动更新 Chrome
最近使用 Gmail 竟然告诉我“即将不支持此版本浏览器”,于是看了一样 Chrome 版本号 —- v52 , 感觉还很新啊,查了一下发现 Chrome 版本已经更新到了 v56。 但是 Linux 下 Chrome 不会自动更新, chrome://help/ 来查看也不会自动更新。所以搜索了一下,发现 Google 其实维护了自己的 Linux Repository。
因为我是通过网站下载 GUI 安装的,所以没有自动更新的模块,添加 Chrome 的 source 即可。
添加 PPA 源
如果使用 PPA,则可以通过下面的命令,让 apt 每一次检查更新时将 Chrome 的更新带下来。
$ wget -q -O - https://dl-ssl.google.com/linux/linux_signing_key.pub | sudo apt-key add -
$ sudo sh -c 'echo "deb http://dl.google.com/linux/chrome/deb/ stable main" >> /etc/apt/sources.list.d/google-chrome.list'
# 如果是 64 位系统,则使用如下命令
$ sudo sh -c 'echo "deb [amd64] http://dl.google.com/linux/chrome/deb/ stable main" >> /etc/apt/sources.list.d/google-chrome.list'
如果已经安装过 Chrome,则使用如下命令更新:
$ sudo apt update
$ sudo apt install google-chrome-stable
每天学习一个命令:ln 创建链接
ln 它的功能是为某一个文件在另外一个位置建立一个同步的链接。当我们需要在不同的目录,用到相同的文件时,我们不需要在每一个需要的目录下都放一个必须相同的文件,我们只要在某个固定的目录,放上该文件,然后在 其它的目录下用 ln 命令链接(link)它就可以,不必重复的占用磁盘空间。非常类似于 Windows 系统中的快捷方式,但是又比超链接要强很多。
命令格式:
ln [OPTION] TARGET LINK_NAME
命令功能:
Linux 文件系统中,有所谓的链接 (link),我们可以将其视为档案的别名,而链接又可分为两种 : 硬链接 (hard link) 与软链接 (symbolic link),硬链接是一个档案可以有多个名称,而软链接的方式则是产生一个特殊的档案,该档案的内容是指向另一个档案的位置。硬链接存在同一个文件系统中,而软链接可以跨越不同的文件系统。
软链接 symbolic link
软链接是一个文件指向另一个文件的快捷方式 shortcut,软链接指向的内容是真正文件或者目录所在的地方。软链接的一个优势是可以跨越分区或者文件系统创建。
- 软链接,以路径的形式存在。类似于 Windows 操作系统中的快捷方式
- 软链接可以 跨文件系统 ,硬链接不可以
- 软链接可以对一个不存在的文件名进行链接
- 软链接可以对目录进行链接
硬链接 hard link
文件系统的每一个文件都被一个 inode 文件来记录,大多数时候并不需要关心 inode 的存在,但是当创建 hard link 时就需要注意到 inode 的存在。hard link 允许我们给同一个文件不同的名字,这个技术的关键就在于 inode number,硬链接几乎不会产生太多额外的空间占用。
- 硬链接,以文件副本的形式存在。但不占用实际空间。
- 不允许给目录创建硬链接
- 硬链接只有在同一个文件系统中才能创建
这里有两点要注意:
第一,ln 命令会保持每一处链接文件的同步性,也就是,不论改动了哪一处,其它的文件都会发生相同的变化;
第二,ln 的链接又分软链接和硬链接两种,软链接就是 ln –s 源文件 目标文件,它只会在你选定的位置上生成一个文件的镜像,不会占用磁盘空间,硬链接 ln 源文件 目标文件,没有参数 -s, 它会在你选定的位置上生成一个和源文件大小相同的文件,无论是软链接还是硬链接,文件都保持同步变化。
ln 指令用在链接文件或目录,如同时指定两个以上的文件或目录,且最后的目的地是一个已经存在的目录,则会把前面指定的所有文件或目录复制到该目录中。若同时指定多个文件或目录,且最后的目的地并非是一个已存在的目录,则会出现错误信息。
命令参数:
必要参数:
-b 删除,覆盖以前建立的链接
-d 允许超级用户制作目录的硬链接
-f 强制执行
-i 交互模式,文件存在则提示用户是否覆盖
-n 把符号链接视为一般目录
-s 软链接(符号链接)
-v 显示详细的处理过程
可选参数:
-S “-S 字尾备份字符串 ”或 “--suffix= 字尾备份字符串 ”
-V “-V 备份方式 ”或“--version-control= 备份方式 ”
--help 显示帮助信息
--version 显示版本信息
使用实例:
给文件创建软链接
最常见的就是在 nginx 的配置中,创建一个软连接来 enable 一个站点,当在 sites-available 中配置好一个虚拟主机之后,使用软连接在 sites-enabled 中启用
命令:
ln -s /etc/nginx/sites-available/xxx.einverne.info /etc/nginx/sites-enabled/
此时会在 sites-enabled 中生成一个文件 xxx.einverne.info 来指向 sites-available 文件夹中的文件。
使用 ls -al 来查看时会有一个小箭头指向原来的文件。
linkfile -> originfile
给文件创建硬链接
命令:
ln TARGET LINK_NAME
文件各项属性相同
将文件链接为另一个目录中的相同名字
命令:
ln TARGET FOLDER
说明:
如果 ln 后面为文件夹的话,会在该文件夹内创建一个 TARGET 文件链接。
给目录创建软链接
注意目录只能创建软链接
命令:
ln -sv /home/username/test1 /home/username/test2
说明:
- 目录创建链接必须用绝对路径,相对路径创建会不成功,会提示:符号连接的层数过多
- 在链接目标目录中修改文件都会在源文件目录中同步变化
其他
删除和重建链接原文件对硬链接和软链接的影响
- 源文件被删除后不会影响硬链接文件;但是软链接文件提示源文件已经不存在
- 重建源文件后,软链接链接成功,找到了链接文件系统;重建后,硬链接文件并没有受到源文件影响,硬链接文件的内容还是保留了删除前源文件的内容,说明硬链接已经失效
每天学习一个命令: base64 编解码
Base64 是一种使用 64 个可打印的字符来表示二进制数据的方法,base64 中仅且包括字母 A-Za-z0-9+/ 共64个字符。Base64 通常处理文本数据,表示、传输、存储二进制数据。
Base64编码由来
有些网络传送渠道不支持所有字节,比如邮件发送,图像字节不可能全部都是可见字符,所以受到了很大限制。最好的解决办法就是在不改变传统协议的情况下,利用一种扩展方式来支持二进制文件的传送,把不可打印的字符用可打印字符来表示。 Base64 就是一种基于64个可打印字符来表示二进制数据的方法。
原理
Base64 索引中,64个字符使用 6 bit 位就可以全部表示,一个字节有 8 个bit位,所以在 Base64 编码中,使用3个传统字节(8bit位) 由4个 Base64 字符来表示,保证有效位数一致。
- Base64 按照字符串长度,每3个 8 bit 组成一组,正对每组,获取每个字符的 ASCII 编码
- 将 ASCII 码转成 8bit 的二进制,得到 3*8=24 bit 的字节
- 将 24 bit 划分为 4 个 6bit 的字节,每个 6 bit 的字节前填两个高位0,得到4个 8bit 的字节
- 将4个 8bit 字节转化成10进制,对照 Base64编码表,得到对应编码后的字符。
下面对 Tom 三个字符进行编码
T o m
ASCII: 84 111 109
8bit字节: 01010100 01101111 01101101
6bit字节: 010101 000110 111101 101101
十进制: 21 6 61 45
对应编码: V G 9 t
因此 Tom 在 Base64 编码之后变成了 VG9t
要求:
- 要求被编码字符是8bit, 所以要在 ASCII 编码范围内, \u0000-\u00ff 中文就不行
- 编码字符长度不是3倍数事,用0代替,对应的输出字符为
=,所以实际 Base64 有65 中不同的字符。
因此 Base64 字符串只可能末尾出现一个或者两个 = ,中间是不可能出现 = 的。
使用
Base64编码主要用在传输、存储、表示二进制等领域,还可以用来加密,但是这种加密比较简单,只是一眼看上去不知道什么内容罢了,当然也可以对Base64的字符序列进行定制来进行加密。
简单字符串的加密,图片文件二进制的加密。
常用方式
格式:base64
从标准输入中读取数据,按Ctrl+D结束输入。将输入的内容编码为base64字符串输出。
示例一
[root@web ~]# base64
hello
Ctrl+D
aGVsbG8K
[root@web ~]#
[root@web ~]#
[root@web ~]# base64 -d
aGVsbG8K
Ctrl+D hello
base64: invalid input
[root@web ~]#
你会发现,base64命令会输出 base64: invalid input,似乎它把按Ctrl+D后的空行也作为输入来处理了。
格式:echo "str" | base64
将字符串str+换行 编码为base64字符串输出。
格式: base64 <<< "hello"
将字符串 hello 编码为 base64 , bash 中 <<< 三个小于号意味着将右边的字符转为左边命令的输入
格式:echo -n "str" | base64
将字符串 str 编码为 base64 字符串输出。无换行。
在 zsh 中,无换行会以 % 百分号结尾,在bash中,命令提示符会直接跟在输出结果的后面 []$,而 zsh 会强制转换。
格式:base64 file
从指定的文件file中读取数据,编码为base64字符串输出。
格式:base64 -d
从标准输入中读取已经进行base64编码的内容,解码输出。
示例二
[root@web ~]# cat >1.txt
hello
world
Ctrl+D
[root@web ~]# base64 1.txt
aGVsbG8Kd29ybGQK
[root@web ~]# base64 1.txt >2.txt
[root@web ~]# base64 -d 2.txt
hello
world
base64: invalid input
[root@web ~]#
格式:base64 -d -i
从标准输入中读取已经进行base64编码的内容,解码输出。加上-i参数,忽略非字母表字符,比如换行符。
man base64 中
-i, --ignore-garbage
When decoding, ignore non-alphabet characters.
use --ignore-garbage to attempt to recover from non-alphabet characters (such as newlines) in the encoded stream.
格式:echo "str" | base64 -d
将base64编码的字符串str+换行 解码输出。
格式:echo -n "str" | base64 -d
将base64编码的字符串str解码输出。
格式:base64 -d file
从指定的文件file中读取base64编码的内容,解码输出。
[root@web ~]# echo "hello" | base64
aGVsbG8K
[root@web ~]# echo "aGVsbG8K" | base64 -d
hello
base64: invalid input
[root@web ~]# echo -n "aGVsbG8K" | base64 -d
hello
[root@web ~]#
使用echo输出字符串时,如果没有-n参数会自动添加换行符,这会令base64命令发晕。
reference
RESTful 接口
RESTful 为 Representational State Transfer 的缩写,拆分开这三个单词来就是:
- Representational - REST resources can be represented in virtually any form, include XML, JSON, or even HTML 表现层,资源的表现形式
- State - concerned with the state of a resource 状态,指的是互联网上资源的状态
- Transfer - transferring resource data 转换,服务端/客户端的转换
Put more succinctly, REST is about transferring the state of resources in a representational form that is most appropriate for the client or server from a server to a client (or vice versa).
These HTTP methods are often mapped to CRUD verbs as follows:
- Create — POST 新建资源,也可用于更新资源
- Read — GET 获取资源
- Update — PUT or PATCH 更新资源,PUT时客户端提供修改的完整资源,PATCH 为客户端提供改变的属性
- Delete — DELETE 删除资源
什么是RESTful架构:
- 每一个URI代表一种资源;
- 客户端和服务器之间,传递这种资源的某种表现层;
- 客户端通过四个HTTP动词,对服务器端资源进行操作,实现”表现层状态转化”。
看到这里便可以回答:”PUT 和 POST” 的区别了 —- POST 用来新建资源,而 PUT 和 POST 都可以用来更新资源提交更新。
对于一个 HTTP 请求可以分成一下部分:
VERB is one of the HTTP methods like GET, PUT, POST, DELETE, OPTIONS, etc
URI is the URI of the resource on which the operation is going to be performed
HTTP Version is the version of HTTP, generally “HTTP v1.1” .
Request Header contains the metadata as a collection of key-value pairs of headers and their values. These settings contain information about the message and its sender like client type, the formats client supports, format type of the message body, cache settings for the response, and a lot more information.
Request Body is the actual message content. In a RESTful service, that’s where the representations of resources sit in a message.
对于一个 Http Response 可以分成一下部分:
HTTP Version
Response Code
Response Header
Response Body contains the representation if the request was successful
一些常见问题
API版本控制
将API版本放入 URI
https://api.example.com/v1
或者将版本信息放入 HTTP 头信息中。
以下是读 《Oreilly REST API Design Rulebook》 的一些笔记。
A Web API conforming to the REST architectural style is a REST API.
URI
格式
RFC 3986 * defines the generic URI syntax as shown below:
URI = scheme "://" authority "/" path [ "?" query ] [ "#" fragment ]
建议:
- 使用前置的 “/” (forward slash separator) 来表达资源层级,在 URI 结尾不添加 “/”
- 使用 Hyphens “-” 来增加可读性,不使用 Underscores “_”
- 使用小写
- 不使用 File extensions
Resource Archetypes
A REST API 有 4 种不同的资源原型( Resource Archetypes ) : document, collection, store and controller. 下面四种资源类型翻译出来不伦不类,直接原文反而比较容易明白。
-
A document resource is a singular concept that is akin to an object instance or database record. A document’s state representation typically includes both fields with values and links to other related resources.
-
A collection resource is a server-managed directory of resources. 服务端托管资源的目录
-
A store is a client-managed resource repository. 客户端管理的资源
The example interaction below shows a user (with ID 1234) of a client program using a fictional Soccer REST API to insert a document resource named alonso in his or her store of favorites:
PUT /users/1234/favorites/alonso -
A controller resource models a procedural concept. Controller resources are like executable functions, with parameters and return values; inputs and outputs.
URI Path Design 路径设计
- 单数名词用于 document
- 复数名词用于 collection
- 复数名词用于 store
- 动词或者动词短语用于 Controller 名字
- Variable path segments may be substituted with identity-based values
- CRUD 名字不应该在URI中使用,而应该使用
DELETE /users/1234
URI Query Design 参数设计
-
The query component of a URI may be used to filter collections or stores
比如 GET /users?role=admin
-
用来分页
GET /users?pageSize=25&pageStartIndex=50
Interaction Design with HTTP
REST API 使用 HyperText Transfer Protocol , version 1.1 (HTTP/1.1) , 包括:
- request methods
- response codes
- message headers
RFC 2616 defines the Status-Line syntax as shown below:
Status-Line = HTTP-Version SP Status-Code SP Reason-Phrase CRLF
Request Methods
请求的方法区别:
The purpose of GET is to retrieve a representation of a resource’s state. HEAD is used to retrieve the metadata associated with the resource’s state. PUT should be used to add a new resource to a store or update a resource. DELETE removes a resource from its parent. POST should be used to create a new resource within a collection and execute controllers.
需要注意:
- GET and POST must not be used to tunnel other request methods
- GET must be used to retrieve a representation of a resource
- HEAD should be used to retrieve response headers
- PUT must be used to both insert and update a stored resource
- POST must be used to create a new resource in a collection
- POST must be used to execute controllers
- DELETE must be used to remove a resource from its parent
- OPTIONS should be used to retrieve metadata that describes a resource’s available interactions
Response Status Codes 返回码
Category Description 分组描述
1xx: Informational Communicates transfer protocol-level information.
2xx: Success Indicates that the client’s request was accepted successfully.
3xx: Redirection Indicates that the client must take some additional action in order to complete their request.
4xx: Client Error This category of error status codes points the finger at clients. 客户端请求错误
5xx: Server Error The server takes responsibility for these error status codes. 服务器内部错误
具体的状态码:
- 200 表明成功, response 需携带 response body
- 201 Create 表示资源创建成功
- 202 Accepted 用于表示成功开始了异步动作
- 204 No Content,通常用于 PUT,POST,和 DELETE 请求的response,如果 GET 返回结果为空,通常也用204
- 301 “Moved Permanently”,通常应该在返回结果 header 中包含 Location 重定向的请求地址
- 302 (“Found”) should not be used
- 303 “See Other” refer the client to a different URI
- 304 Not Modified preserve bandwidth , client already has the most recent version of the representation
- 307 Temporary Redirect tell clients to resubmit the request to another URI
- 400 Bad Request may be used to indicate nonspecific failure,客户端请求错误
- 401 Unauthorized,must be used 客户端无授权,令牌,密码等无验证
- 403 Forbidden,should be used to forbid access regardless of authorization state
- 404 Not found,must be used when a client’s URI cannot be mapped to a resource 不存在该记录
- 405 (“Method Not Allowed”) must be used when the HTTP method is not supported
- 406 Not Acceptable,must be used when the requested media type cannot be served
- 409 Conflict should be used to indicate a vialation of resource state
- 412 Precondition Failed should be used to support conditional operations
- 415 Unsupported Media Type must be used when the media type of a request’s payload cannot be processed
- 500 Internal Server Error should be used to indicate API malfunction
Metadata Design
HTTP Headers
-
Content-Type must be used
-
Content-Length should be used, Content-Length header 给出了整个 body bytes 大小,给出他的理由有两个:1. 客户端可以检查是否读取完整的大小 2. 客户端可以通过 HEAD 请求来得知整个body 的大小,而不同下载。
-
Last-Modified should be used in responses
-
ETag should be used in responses ETag是HTTP协议提供的若干机制中的一种Web缓存验证机制,并且允许客户端进行缓存协商。 这就使得缓存变得更加高效,而且节省带宽。 如果资源的内容没有发生改变,Web服务器就不需要发送一个完整的响应。 ETag也可用于乐观并发控制,作为一种防止资源同步更新而相互覆盖的方法。
-
Location must be used to specify the URI of a newly created resource
-
Cache-Control, Expires, and Date response headers should be used to encourage caching
Media Types
Media Type 有如下语法:
type "/" subtype *( ";" parameter )
type 的值可以有: application, audio, image, message, model, multipart, text 和 video.
A typical REST API will most often work with media types that fall under the application type.
text/plain
A plain text format with no specific content structure or markup. ‡
text/html
Content that is formatted using the HyperText Markup Language (HTML). §
image/jpeg
An image compression method that was standardized by the Joint Photographic
Experts Group (JPEG). ‖
application/xml
Content that is structured using the Extensible Markup Language (XML). #
application/atom+xml
Content that uses the Atom Syndication Format (Atom), which is an XML-based
format that structures data into lists known as feeds. *
application/javascript
Source code written in the JavaScript programming language. †
application/json
The JavaScript Object Notation (JSON) text-based format that is often used by
programs to exchange structured data. ‡
Media Type Design
Client developers are encouraged to rely on the self-descriptive features of a REST API.
Representation Design
REST API 通常使用 response message 的 body 来传递资源的状态。 REST APIs 通常使用文本格式来表示资源。
- JSON should be supported for resource representation
Client Concerns
Versioning
- 使用新的 URIs
- Schemas
- Entity tags
Security
- OAuth
CORS(Cross-origin resource sharing 跨域资源共享) should be supported to provide multi-origin read/write access from JavaScript,克服了 AJAX 只能同源使用资源的限制。
Access-Control-Allow-Origin
该字段是必须的。它的值要么是请求时Origin字段的值,要么是一个*,表示接受任意域名的请求。
Access-Control-Allow-Credentials
该字段可选。它的值是一个布尔值,表示是否允许发送Cookie。默认情况下,Cookie不包括在CORS请求之中。设为true,即表示服务器明确许可,Cookie可以包含在请求中,一起发给服务器。这个值也只能设为true,如果服务器不要浏览器发送Cookie,删除该字段即可。
Access-Control-Expose-Headers
该字段可选。CORS请求时,XMLHttpRequest对象的getResponseHeader()方法只能拿到6个基本字段:Cache-Control、Content-Language、Content-Type、Expires、Last-Modified、Pragma。如果想拿到其他字段,就必须在Access-Control-Expose-Headers里面指定。上面的例子指定,getResponseHeader(‘FooBar’)可以返回FooBar字段的值。
CORS 请求默认不发送 Cookie 和 HTTP 认证信息,如果想要把 Cookie 发送到服务器,一方面要服务器同意,指定 Access-Control-Allow-Credentials 为 true。
调试 RESTful 接口
接口调试工具 Postman https://www.getpostman.com/
其他工具
- curl https://curl.haxx.se/
- DHC https://chrome.google.com/webstore/detail/dhc-restlet-client/aejoelaoggembcahagimdiliamlcdmfm
- Advanced rest client https://chrome.google.com/webstore/detail/advanced-rest-client/hgmloofddffdnphfgcellkdfbfbjeloo
- Java 版本 rest-client https://github.com/wiztools/rest-client/releases
- 在线 RESTful 测试 https://httpbin.org/
每天学习一个命令:lscpu 查看 CPU 信息
lscpu 显示 CPU 的架构信息
lscpu 从 sysfs 和 proc/cpuinfo 中收集信息。这个命令的输出是规范的可以用来解析,或者给人来阅读。该命令显示的信息包括,CPU 的数量,线程 (thread),核心 (core),Socket 还有 Non-Uniform Memory Access (NUMA) 节点数。
- Socket 具体是指的主板上 CPU 的插槽数量,一般笔记本只有一个,而服务器可能会有多个。如果有两个插槽,通常称为两路
- Core 具体是指 CPU 的核心,也就是平常说的几核,比如八核之类
- thread 是指的每个 Core 的硬件线程数,超线程
举例来说,如果某个服务器”2 路 4 核超线程”,也就是 2 个插槽,4 核心,默认为 2 thread,也就是 242 是 16 逻辑 CPU。对操作系统来说,逻辑 CPU 的数量就是 Socket * Core * Thread。
比如下面我的台式机,1 Sockets, 4 Cores,2 Threads,那么就是 4 核 8 线程。
如下示例:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 8
On-line CPU(s) list: 0-7
Thread(s) per core: 2
Core(s) per socket: 4
Socket(s): 1
NUMA node(s): 1
Vendor ID: GenuineIntel
CPU family: 6
Model: 94
Model name: Intel(R) Core(TM) i7-6700 CPU @ 3.40GHz
Stepping: 3
CPU MHz: 1075.117
CPU max MHz: 4000.0000
CPU min MHz: 800.0000
BogoMIPS: 6816.61
Virtualization: VT-x
L1d cache: 32K
L1i cache: 32K
L2 cache: 256K
L3 cache: 8192K
NUMA node0 CPU(s): 0-7
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc art arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc aperfmperf eagerfpu pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch epb invpcid_single intel_pt retpoline kaiser tpr_shadow vnmi flexpriority ept vpid fsgsbase tsc_adjust bmi1 hle avx2 smep bmi2 erms invpcid rtm mpx rdseed adx smap clflushopt xsaveopt xsavec xgetbv1 dtherm ida arat pln pts hwp hwp_notify hwp_act_window hwp_epp
Byte Order
Big endian vs Little endian 大端和小端,对于整型、长整型等数据类型,Big endian 认为第一个字节是最高位字节(按照从低地址到高地址的顺序存放数据的高位字节到低位字节);而 Little endian 则相反,认为第一个字节是最低位字节(按照从低地址到高地址的顺序存放据的低位字节到高位字节)。
一般来说,x86 系列 CPU 都是 little-endian 的字节序,PowerPC 通常是 big-endian,网络字节顺序也是 big-endian 还有的 CPU 能通过跳线来设置 CPU 工作于 Little endian 还是 Big endian 模式。
扩展
Linux 有很多命令可以用来查看 cpu 的信息,如果不使用 lscpu 那么可以直接查看 less /proc/cpuinfo 文件。
或者使用 sudo lshw -class processor
或者
sudo dmidecode -t 4 | less
或者
sudo apt install hardinfo
hardinfo | less
或者
sudo apt install cpuid
cpuid
或者
sudo apt install inxi
inxi -C
reference
每天学习一个命令:tree 生成目录结构
tree 命令,是一个列出树型目录结构的命令。同时也能够统计出目录下的文件数量和目录数量。
生成目录结构的输出,可以是纯 ASCII 字符,也可以是 html
tree -H baseHREF
根据手册
tree 命令是用来以树的方式 list 目录下的所有文件
tree -s -v --du -T "目录索引 - Kindle 伴侣每周一书(往期)(更新:06 月 05 日)" -I "Z.*|index*" -h -H ./ -o index.html
说明:
-s列出文件或者目录大小-v按照字母序排序--du在目录前显示整个目录的大小-T title用参数后面的文字替换生成的默认标题-I pattern用该参数来排除一些目录-h表示打印出可读的文件大小-H表示打印 HTML-o file.html表示打印到文件而不是标准输出
得到如下的 Tree 图:

参数解释
全部参数解释
tree --help
usage: tree [-acdfghilnpqrstuvxACDFQNSUX] [-H baseHREF] [-T title ] [-L level [-R]]
[-P pattern] [-I pattern] [-o filename] [--version] [--help] [--inodes]
[--device] [--noreport] [--nolinks] [--dirsfirst] [--charset charset]
[--filelimit[=]#] [--si] [--timefmt[=]<f>] [<directory list>]
------- Listing options -------
-a All files are listed. 显示所有文件和目录,默认情况下不打印隐藏文件(以点开始的文件)。
-d List directories only. 显示目录名称。
-l Follow symbolic links like directories. 如遇到性质为符号连接的目录,直接列出该连接所指向的原始目录。
-f Print the full path prefix for each file. 在每个文件或目录之前,显示完整的相对路径名称。
-x Stay on current filesystem only. 将范围局限在现行的文件系统中,若指定目录下的某些子目录,其存放于另一个文件系统上,则将该子目录予以排除在寻找范围外。
-L level Descend only level directories deep. 目录深度
-R Rerun tree when max dir level reached.
-P pattern List only those files that match the pattern given. 只显示符合范本样式的文件或目录名称。
-I pattern Do not list files that match the given pattern. 不显示符合范本样式的文件或目录名称。
--noreport Turn off file/directory count at end of tree listing.
--charset X Use charset X for terminal/HTML and indentation line output. 指定字符集
--filelimit # Do not descend dirs with more than # files in them.
--timefmt <f> Print and format time according to the format <f>.
-o filename Output to file instead of stdout. 输出到文件,而不是直接输出到标准输出设备
-------- File options ---------
--du 在目录前显示整个目录的大小。
-q Print non-printable characters as '?'. 用"?"号取代控制字符,列出文件和目录名称。
-N Print non-printable characters as is. 直接列出文件和目录名称,包括控制字符。
-Q Quote filenames with double quotes.
-p Print the protections for each file. 列出权限标示。
-u Displays file owner or UID number. 列出文件或目录的拥有者名称,没有对应的名称时,则显示用户识别码。
-g Displays file group owner or GID number. 列出文件或目录的所属群组名称,没有对应的名称时,则显示群组识别码。
-s Print the size in bytes of each file. 列出文件或目录大小。
-h Print the size in a more human readable way. 打印出可读的文件大小, M,G
--si Like -h, but use in SI units (powers of 1000).
-D Print the date of last modification or (-c) status change. 列出文件或目录的更改时间。
-F Appends '/', '=', '*', '@', '|' or '>' as per ls -F. 在执行文件,目录,Socket,符号连接,管道名称名称,各自加上"*","/","=","@","|"号。
--inodes Print inode number of each file.
--device Print device ID number to which each file belongs.
------- Sorting options -------
-v Sort files alphanumerically by version. 字母序排序
-r Sort files in reverse alphanumeric order. 字母序逆序
-t Sort files by last modification time. 最后一次修改时间排序
-c Sort files by last status change time.
-U Leave files unsorted. 不排序
--dirsfirst List directories before files (-U disables).
------- Graphics options ------
-i Don't print indentation lines. 不以阶梯状列出文件或目录名称。
-A Print ANSI lines graphic indentation lines.
-S Print with ASCII graphics indentation lines.
-n Turn colorization off always (-C overrides). 不在文件和目录清单加上色彩。
-C Turn colorization on always. 在文件和目录清单加上色彩,便于区分各种类型。
------- XML/HTML options -------
-X Prints out an XML representation of the tree.
-H baseHREF Prints out HTML format with baseHREF as top directory.
-T string Replace the default HTML title and H1 header with string.
--nolinks Turn off hyperlinks in HTML output.
---- Miscellaneous options ----
--version Print version and exit.
--help Print usage and this help message and exit.
reference
每天学习一个命令:nmap 扫描开放端口
nmap 是一个网络探测和安全审核工具,能够扫描主机开放端口。nmap 全称 network mapper 网络映射器,设计的目标是快速扫描大型网络。
nmap 以原始 IP 报文来检测网络上有哪些主机,主机运行哪些操作系统(包括版本),主机提供哪些服务(应用程序名和版本),主机使用什么类型的报文过滤器 / 防火墙,以及一堆其它功能。虽然 Nmap 通常用于安全审核,许多系统管理员和网络管理员也用它来做一些日常的工作,比如查看整个网络的信息,管理服务升级计划,以及监视主机和服务的运行。
Nmap 输出的是扫描目标的列表,以及每个目标的补充信息,至于是哪些信息则依赖于所使用的选项。 “所感兴趣的端口表格”是其中的关键。结果列出端口号,协议,服务名称和状态。状态可能是 open(开放的),filtered(被过滤的),closed(关闭的),或者 unfiltered(未被过滤的)。
- Open(开放的)意味着目标机器上的应用程序正在该端口监听连接 / 报文。
- filtered(被过滤的) 意味着防火墙,过滤器或者其它网络障碍阻止了该端口被访问,Nmap 无法得知 它是 open(开放的) 还是 closed(关闭的)。
- closed(关闭的) 端口没有应用程序在它上面监听,但是他们随时可能开放。
- unfiltered(未被过滤的)当端口对 Nmap 的探测做出响应,但是 Nmap 无法确定它们是关闭还是开放时
| 如果 Nmap 报告状态组合 open | filtered 和 closed | filtered 时,那说明 Nmap 无法确定该端口处于两个状态中的哪一个状态。当要求进行版本探测时,端口表也可以包含软件的版本信息。当要求进行 IP 协议扫描时 (-sO),Nmap 提供关于所支持的 IP 协议而不是正在监听的端口的信息。 |
除了所感兴趣的端口表,Nmap 还能提供关于目标机的进一步信息,包括反向域名,操作系统猜测,设备类型,和 MAC 地址。
简单例子
nmap -A -T4 scanme.nmap.org
端口状态
open 开放的
应用程序正在该端口接收 TCP 连接或者 UDP 报文。发现这一点常常是端口扫描的主要目标,安全意识强的人们知道每个开放的端口都是攻击的入口。攻击者或者入侵测试者想要发现开放的端口。而管理员则试图关闭它们或者用防火墙保护它们以免妨碍了合法用户。非安全扫描可能对开放的端口也感兴趣,因为它们显示了网络上那些服务可供使用。
closed 关闭的
关闭的端口对于 Nmap 也是可访问的(它接受 Nmap 的探测报文并作出响应), 但没有应用程序在其上监听。 它们可以显示该 IP 地址上(主机发现,或者 ping 扫描)的主机正在运行 up 也对部分操作系统探测有所帮助。 因为关闭的关口是可访问的,也许过会儿值得再扫描一下,可能一些又开放了。 系统管理员可能会考虑用防火墙封锁这样的端口。 那样他们就会被显示为被过滤的状态,下面讨论。
filtered 被过滤的
由于包过滤阻止探测报文到达端口,Nmap 无法确定该端口是否开放。过滤可能来自专业的防火墙设备,路由器规则 或者主机上的软件防火墙。这样的端口让攻击者感觉很挫折,因为它们几乎不提供任何信息。有时候它们响应 ICMP 错误消息如类型 3 代码 13 (无法到达目标:通信被管理员禁止),但更普遍的是过滤器只是丢弃探测帧,不做任何响应。这迫使 Nmap 重试若干次以访万一探测包是由于网络阻塞丢弃的。这使得扫描速度明显变慢。
unfiltered 未被过滤的
未被过滤状态意味着端口可访问,但 Nmap 不能确定它是开放还是关闭。 只有用于映射防火墙规则集的 ACK 扫描才会把端口分类到这种状态。 用其它类型的扫描如窗口扫描,SYN 扫描,或者 FIN 扫描来扫描未被过滤的端口可以帮助确定 端口是否开放。
open filtered 开放或者被过滤的
当无法确定端口是开放还是被过滤的状态。开放的端口不响应就是一个例子,没有响应也可能意味着报文过滤器丢弃了探测报文或者它引发的任何响应。因此 Nmap 无法确定该端口是开放的还是被过滤的。UDP,IP 协议,FIN,Null,和 Xmas 扫描可能把端口归入此类。
closed filtered 关闭或者被过滤的
Nmap 不能确定端口是关闭的还是被过滤的。它只可能出现在 IPID Idle 扫描中。
常用端口 Common Ports
端口号从 1 到 65535
- 小于 1024 的端口号通常和 Linux 和 Unix-Like 系统内置服务关联,通常不单独使用,一般需要 root 才能开启
- 1024 到 49151 的端口,被认为是 registered. 通常特定的服务可以向 IANA (Internet Assigned Numbers Authority) 来申请使用。 - 在 49152 到 65535 之间的端口不能被注册使用,并且推荐作为私有用途
常见的端口
20: FTP data
21: FTP control port
22: SSH
23: Telnet <= Insecure, not recommended for most uses
25: SMTP
43: WHOIS protocol
53: DNS services
67: DHCP server port
68: DHCP client port
80: HTTP traffic <= Normal web traffic
110: POP3 mail port
113: Ident authentication services on IRC networks
143: IMAP mail port
161: SNMP
194: IRC389: LDAP port
443: HTTPS <= Secure web traffic
587: SMTP <= message submission port
631: CUPS printing daemon port
666: DOOM <= This legacy FPS game actually has its own special port
其他常见的端口可以通过
less /etc/services
来查看。
查看本地端口
sudo netstat -plunt
netstat 命令用来查看本地端口和服务。
使用 Nmap
安装
sudo apt-get update
sudo apt-get install nmap
nmap 的创建者提供了一个测试服务器
scanme.nmap.org
扫描类型
-sT TCP connect() 扫描,这是最基本的 TCP 扫描方式。这种扫描很容易被检测到,在目标主机的日志中会记录大批的连接请求以及错误信息。
-sS TCP 同步扫描 (TCP SYN),因为不必全部打开一个 TCP 连接,所以这项技术通常称为半开扫描 (half-open)。这项技术最大的好处是,很少有系统能够把这记入系统日志。不过,你需要 root 权限来定制 SYN 数据包。
-sF,-sX,-sN 秘密 FIN 数据包扫描、圣诞树 (Xmas Tree)、空 (Null) 扫描模式。这些扫描方式的理论依据是:关闭的端口需要对你的探测包回应 RST 包,而打开的端口必需忽略有问题的包(参考 RFC 793 第 64 页)。
-sP ping 扫描,用 ping 方式检查网络上哪些主机正在运行。当主机阻塞 ICMP echo 请求包是 ping 扫描是无效的。nmap 在任何情况下都会进行 ping 扫描,只有目标主机处于运行状态,才会进行后续的扫描。
-sU UDP 的数据包进行扫描,如果你想知道在某台主机上提供哪些 UDP(用户数据报协议,RFC768) 服务,可以使用此选项。
-sA ACK 扫描,这项高级的扫描方法通常可以用来穿过防火墙。
-sW 滑动窗口扫描,非常类似于 ACK 的扫描。
-sR RPC 扫描,和其它不同的端口扫描方法结合使用。
-b FTP 反弹攻击 (bounce attack),连接到防火墙后面的一台 FTP 服务器做代理,接着进行端口扫描。
通用选项
-P0 在扫描之前,不 ping 主机。
-PT 扫描之前,使用 TCP ping 确定哪些主机正在运行。
-PS 对于 root 用户,这个选项让 nmap 使用 SYN 包而不是 ACK 包来对目标主机进行扫描。
-PI 设置这个选项,让 nmap 使用真正的 ping(ICMP echo 请求)来扫描目标主机是否正在运行。
-PB 这是默认的 ping 扫描选项。它使用 ACK(-PT) 和 ICMP(-PI) 两种扫描类型并行扫描。如果防火墙能够过滤其中一种包,使用这种方法,你就能够穿过防火墙。
-O 这个选项激活对 TCP/IP 指纹特征 (fingerprinting) 的扫描,获得远程主机的标志,也就是操作系统类型。
-I 打开 nmap 的反向标志扫描功能。
-f 使用碎片 IP 数据包发送 SYN、FIN、XMAS、NULL。包增加包过滤、入侵检测系统的难度,使其无法知道你的企图。
-v 冗余模式。强烈推荐使用这个选项,它会给出扫描过程中的详细信息。
-S <IP> 在一些情况下,nmap 可能无法确定你的源地址 (nmap 会告诉你)。在这种情况使用这个选项给出你的 IP 地址。
-g port 设置扫描的源端口。一些天真的防火墙和包过滤器的规则集允许源端口为 DNS(53) 或者 FTP-DATA(20) 的包通过和实现连接。显然,如果攻击者把源端口修改为 20 或者 53,就可以摧毁防火墙的防护。
-oN 把扫描结果重定向到一个可读的文件 logfilename 中。
-oS 扫描结果输出到标准输出。
--host_timeout 设置扫描一台主机的时间,以毫秒为单位。默认的情况下,没有超时限制。
--max_rtt_timeout 设置对每次探测的等待时间,以毫秒为单位。如果超过这个时间限制就重传或者超时。默认值是大约 9000 毫秒。
--min_rtt_timeout 设置 nmap 对每次探测至少等待你指定的时间,以毫秒为单位。
-M count 置进行 TCP connect() 扫描时,最多使用多少个套接字进行并行的扫描。 ```
扫描目标
目标地址可以为 IP 地址,CIRD 地址等。如 192.168.1.2,222.247.54.5/24
-iL filename 从 filename 文件中读取扫描的目标。
-iR 让 nmap 自己随机挑选主机进行扫描。
-p 端口 这个选项让你选择要进行扫描的端口号的范围。如:-p 20-30,139,60000
-exclude 排除指定主机。
-excludefile 排除指定文件中的主机。
常用命令
做一次简单的扫描
快速的扫描,而不在乎端口是否开放,可以执行:
nmap -sn 192.168.2.0/24
需要注意的是 -sn 选项和 -sP 一致,-sP 选项是为了兼容老版本的 Nmap。
寻找网络中所有在线主机
通过如下命令可以查看在同一个网络的在线主机。
sudo nmap -sP 192.168.0.0/24
获取远程主机系统类型和开放端口
nmap -sS -P0 -sV -O [target]
这里的 target 可以是单一 IP, 或主机名,或域名,或子网
-sS TCP SYN 扫描 (又称半开放,或隐身扫描)
-P0 允许你关闭 ICMP pings.
-sV 打开系统版本检测
-O 尝试识别远程操作系统
其它选项:
-A 同时打开操作系统指纹和版本检测
-v 详细输出扫描情况。
扫描指定端口
如果要扫描指定的端口,比如 22, 80, 443 等,可以执行:
nmap -sV -p 22,80,443 192.168.2.0/24
扫描一个 Host 所有的端口:
nmap -T4 -p 1-65535 192.168.1.1
如果要扫描一个IP段,也可以使用:
nmap -p 54-100 192.168.2.0/24
参数
Usage: nmap [Scan Type(s)] [Options] {target specification}
TARGET SPECIFICATION:
Can pass hostnames, IP addresses, networks, etc.
Ex: scanme.nmap.org, microsoft.com/24, 192.168.0.1; 10.0-255.0-255.1-254
-iL <inputfilename>: Input from list of hosts/networks
-iR <num hosts>: Choose random targets
--exclude <host1[,host2][,host3],...>: Exclude hosts/networks
--excludefile <exclude_file>: Exclude list from file
HOST DISCOVERY:
-sL: List Scan - simply list targets to scan
-sP: Ping Scan - go no further than determining if host is online
-P0: Treat all hosts as online -- skip host discovery
-PS/PA/PU [portlist]: TCP SYN/ACK or UDP discovery probes to given ports
-PE/PP/PM: ICMP echo, timestamp, and netmask request discovery probes
-n/-R: Never do DNS resolution/Always resolve [default: sometimes resolve]
SCAN TECHNIQUES:
-sS/sT/sA/sW/sM: TCP SYN/Connect()/ACK/Window/Maimon scans
-sN/sF/sX: TCP Null, FIN, and Xmas scans
--scanflags <flags>: Customize TCP scan flags
-sI <zombie host[:probeport]>: Idlescan
-sO: IP protocol scan
-b <ftp relay host>: FTP bounce scan
PORT SPECIFICATION AND SCAN ORDER:
-p <port ranges>: Only scan specified ports
Ex: -p22; -p1-65535; -p U:53,111,137,T:21-25,80,139,8080
-F: Fast - Scan only the ports listed in the nmap-services file)
-r: Scan ports consecutively - don't randomize
SERVICE/VERSION DETECTION:
-sV: Probe open ports to determine service/version info
--version-light: Limit to most likely probes for faster identification
--version-all: Try every single probe for version detection
--version-trace: Show detailed version scan activity (for debugging)
OS DETECTION:
-O: Enable OS detection
--osscan-limit: Limit OS detection to promising targets
--osscan-guess: Guess OS more aggressively
TIMING AND PERFORMANCE:
-T[0-6]: Set timing template (higher is faster)
--min-hostgroup/max-hostgroup <msec>: Parallel host scan group sizes
--min-parallelism/max-parallelism <msec>: Probe parallelization
--min-rtt-timeout/max-rtt-timeout/initial-rtt-timeout <msec>: Specifies
probe round trip time.
--host-timeout <msec>: Give up on target after this long
--scan-delay/--max-scan-delay <msec>: Adjust delay between probes
FIREWALL/IDS EVASION AND SPOOFING:
-f; --mtu <val>: fragment packets (optionally w/given MTU)
-D <decoy1,decoy2[,ME],...>: Cloak a scan with decoys
-S <IP_Address>: Spoof source address
-e <iface>: Use specified interface
-g/--source-port <portnum>: Use given port number
--data-length <num>: Append random data to sent packets
--ttl <val>: Set IP time-to-live field
--spoof-mac <mac address, prefix, or vendor name>: Spoof your MAC address
OUTPUT:
-oN/-oX/-oS/-oG <file>: Output scan results in normal, XML, s|<rIpt kIddi3,
and Grepable format, respectively, to the given filename.
-oA <basename>: Output in the three major formats at once
-v: Increase verbosity level (use twice for more effect)
-d[level]: Set or increase debugging level (Up to 9 is meaningful)
--packet-trace: Show all packets sent and received
--iflist: Print host interfaces and routes (for debugging)
--append-output: Append to rather than clobber specified output files
--resume <filename>: Resume an aborted scan
--stylesheet <path/URL>: XSL stylesheet to transform XML output to HTML
--no-stylesheet: Prevent Nmap from associating XSL stylesheet w/XML output
MISC:
-6: Enable IPv6 scanning
-A: Enables OS detection and Version detection
--datadir <dirname>: Specify custom Nmap data file location
--send-eth/--send-ip: Send packets using raw ethernet frames or IP packets
--privileged: Assume that the user is fully privileged
-V: Print version number
-h: Print this help summary page.
EXAMPLES:
nmap -v -A scanme.nmap.org
nmap -v -sP 192.168.0.0/16 10.0.0.0/8
nmap -v -iR 10000 -P0 -p 80
reference
文章分类
最近文章
- Glance 个人自定义 Dashboard Glance 是一个可以自行架设的个人 Dashboard 以及 RSS 订阅信息面板。
- Fileball 一款 iOS tvOS 上的媒体播放器及文件管理器 Fileball 是一款 iOS,tvOS 上的本地文件管理器,本地音乐播放器,本地视频播放器,以及文本编辑器,Fileball 可以在 iPhone,iPad,Apple TV 上使用。Fileball 可以连接网络共享,支持 SMB,FTP,SFTP,Synology,NFS,WebDAV 等,支持 Emby,Jellyfin 等,还可以连接百度网盘,Box,Dropbox,Google Drive,OneDrive,pCloud 等,可以作为 [[Infuse]] ,[[VidHub]] 等播放器的平替,高级版本价格也比较合适。Fileball 也支持 [[IPTV]]。
- 在日本申请入台证材料及在线提交注意事项 本文记录入台证办理的材料及提交手续,以及在使用线上提交系统的时候需要注意的点。入台证是中华民国台湾地区出入境许可证的俗称,所有进入台湾的人都需要申请此许可证。
- 从 Buffer 消费图学习 CCPM 项目管理方法 CCPM(Critical Chain Project Management)中文叫做关键链项目管理方法,是 Eliyahu M. Goldratt 在其著作 Critical Chain 中踢出来的项目管理方法,它侧重于项目执行所需要的资源,通过识别和管理项目关键链的方法来有效的监控项目工期,以及提高项目交付率。
- AI Shell 让 AI 在命令行下提供 Shell 命令 AI Shell 是一款在命令行下的 AI 自动补全工具,当你想要实现一个功能,敲一大段命令又记不住的时候,使用自然语言让 AI 给你生成一个可执行的命令,然后确认之后执行。