通过 Mighty Networks 构建专属在线社区
Mighty Networks 是一个为创作者和品牌提供可以共创和发展社区的专业平台。创作者可以通过 Mighty Networks 维系粉丝,举办活动和在线直播课程。
Mighty 为用户提供了一个平台,像创建电商独立站一样创建社区,和 Shopify 一样,Mighty Networks 也在为数字订阅和数字支付领域做贡献,只不过不是电商,而是从内容。
功能
- 社区创建,可以轻松创建和管理一个专属的社区网络,类似 Facebook 小组,但更具定制化和独立性
- 课程和培训,支持创建和销售在线课程,适用于教育者和培训师,可以包含视频,测验等
- 会员管理,提供会员订阅和收费功能,创作者可以通过会员制盈利
- 事件活动,支持在线和线下的活动组织和管理,包括活动通知,签到和互动
- 内容发布,支持发布文章,视频,播客等
- 支持 iOS 和 Android
Price
最低 41 USD 美元每月。

related
- [[Circle]]
- [[BetterMode]]
- [[Thinkific]]
- [[Kajabi]] 是一个在线课程平台
- [[Podia]]
记一次磁盘日志满导致 Redis AOF 文件格式错误的问题
记录一次 VPS 被日志写满,VPS 重启后,导致 Redis 备份文件格式错误的问题。
今天早上起来的时候就收到了一台服务器服务的告警,但是没怎么注意,还以为是网络波动,但是到中午发现服务无法访问了,上到管理面板看了一下,发现日志写到 99%,幸好此时还可以登录,所以赶紧 ssh 登录上去,使用 gdu 扫描一下,发现 /www/wwwlogs/ 文件占用了超过 60 GB,然后再一看网站的访问日志就写了超过 30GB,所以立马 less 排查一下没发现异常,就把文件清理了,但是 Ubuntu 下有一个问题,即使清理了文件,一时间系统也无法感知到文件被删除了,可能因为 Nginx 还在不断占用文件句柄写文件中,所以无奈只能临时重启一下服务器。
但是重启之后问题就出现了,首先是 Redis 无法启动
❯ sudo /etc/init.d/redis-server status
● redis-server.service - Advanced key-value store
Loaded: loaded (/lib/systemd/system/redis-server.service; enabled; vendor preset: enabled)
Active: failed (Result: exit-code) since Wed 2024-06-26 14:42:18 CST; 13s ago
Docs: http://redis.io/documentation,
man:redis-server(1)
Process: 6918 ExecStart=/usr/bin/redis-server /etc/redis/redis.conf (code=exited, status=0/SUCCESS)
Main PID: 6919 (code=exited, status=1/FAILURE)
Jun 26 14:42:18 gc4 systemd[1]: redis-server.service: Scheduled restart job, restart counter is at 5.
Jun 26 14:42:18 gc4 systemd[1]: Stopped Advanced key-value store.
Jun 26 14:42:18 gc4 systemd[1]: redis-server.service: Start request repeated too quickly.
Jun 26 14:42:18 gc4 systemd[1]: redis-server.service: Failed with result 'exit-code'.
Jun 26 14:42:18 gc4 systemd[1]: Failed to start Advanced key-value store.
然后我根据 Redis ,查看了 /var/log/redis/redis-server.log 之后发现,原来是 AOF 文件的问题。
8882:M 26 Jun 2024 14:43:42.161 * Reading RDB preamble from AOF file...
8882:M 26 Jun 2024 14:43:42.257 * Reading the remaining AOF tail...
8882:M 26 Jun 2024 14:43:42.935 # Bad file format reading the append only file: make a backup of your AOF file, then use ./redis-check-aof --fix <filename>
因为这一台服务器的 Redis 是直接通过 apt 安装,所以 AOF 文件默认被放在了 /var/lib/redis/appendonly.aof ,使用命令行
# back up aof file
cp appendonly.aof appendonly.aof.bak
redis-check-aof --fix appendonly.aof
然后再重启 Redis
sudo /etc/init.d/redis-server start
即可。
Voicenotes 一款 AI 语音笔记应用
前两天偶然间收到一个推送,说有一款 AI 语音的笔记应用叫做 Voicenotes,今天终于有时间试用了一下,我的简单使用体验来说,这是一款通过语音来记录想法,备忘录的工具,它与其他笔记,备忘录的区别就在于 AI 的加持,Voicenotes 只允许通过语音输入,录音会通过识别转录成文字(AI),然后记录的所有内容都可以通过和 AI 提问的方式进行回顾,总结,或者进行 brainstorm。
Voicenotes 是跨平台的,目前提供了 Android 和 iOS 以及 Web 端,并且作者承诺之后会推出 Watch 版本。Voicenotes 的数据也是跨平台同步的。
功能介绍
每一个语音笔记都会自动生成一个标题
Voicenotes 会根据上一次的录音生成提问。
目前及未来 Voicenotes 将支持超过 55 种语言。
所有提及的名字都会被识别并记录下来以防止未来的误用。

为了给笔记爱好者保留习惯,Voicenotes 还是提供了标签功能,并且可以通过 AI 自动生成
可以通过搜索,快速检索所有录音笔记。
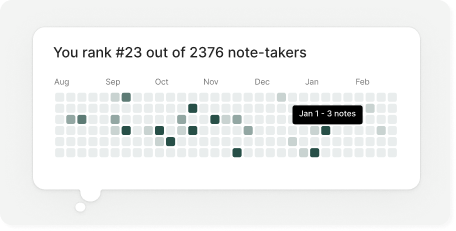
作者还提供了一个图表来记录每天的笔记,以及为了「炫耀」截图
简单地了解一下之后才发现,原来 Voicenotes 是 [[buymeacoffee]] 的作者 Jijo Sunny 和他妻子 Aleesa 的作品,他们目前也在官网进行了承诺,会保护用户的隐私,所有的音频内容及文字都不会被用来训练 AI,并且为了防止外部投资的影响,目前是通过 self-funded 方式来支持项目,并且作者也希望一直将项目进行下去。
目前 Voicenotes 免费用户可以每次都录制长达 1 分钟的录音,付费用户可以录制更长的录音。现在升级 Voicenotes 是 10 USD 每个月,现在可以 50 USD 购买终身授权。

特殊优惠码
在结帐时使用 z1CLp1,可以额外再获得 10% 的减免。
related
- [[alog]] 开源的语音转录应用
- Dinox 一款 iOS 语音转录笔记应用
- [[Whisper]]
- [[VOMO AI]]
- [[letterly]]
- [[Oasis]]
Apple silicon M 系列芯片区别及购买推荐
虽然日常一直在用 MacBook,但是说实话我是没有去了解 M 系列芯片的具体性能的,虽然之前从 Intel 转向 M 系列芯片的时候有看过几个视频,说 M 系列的芯片确实在散热,省电和性能上碾压了 Intel,但是之后也没有继续再关注,直到前段时间在小红书上看到有闲着没事干的人分享了一个图片,图片内容是历年了 Apple 在 WWDC 上说的和前一代相比 CPU 性能又提升了多少,于是他把 M1 芯片作为基数 1 ,然后依次给不同系列的芯片乘以倍数,得出了一个非常有意思的图。
| 芯片 | CPU | GPU | NPU | | ——– | —- | —- | — | | M1 | 1 | 1 | 1 | | M1 Pro | 1.7 | 2 | 1 | | M1 Max | 1.7 | 4 | 1 | | M1 Ultra | 3.4 | 8 | 2 | | M2 | 1.18 | 1.35 | 1.4 | | M2 Pro | 1.9 | 2.6 | 1.4 | | M2 Max | 1.9 | 5.2 | 1.4 | | M2 Ultra | 4.08 | 10.4 | 2.8 | | M3 | 1.35 | 1.65 | 1.6 | | M3 Pro | 2.21 | 2.8 | 1.6 | | M3 Max | 3.06 | 6 | 1.6 | | M4 | 1.77 | 1.65 | 3.4 | 免责声明,此基数及倍数全部由 WWDC 官方宣传图得来,但具体实际性能还需要实际使用才能知道。
Apple silicon 简短历史
Apple silicon 的故事可以追溯到 2010 年,Apple 推出了首款自主研发的芯片 (Soc) —- Apple A4 ,芯片使用 ARM 架构,出现在第一代 iPad 和 iPhone 4 中。这个是 Apple 设计芯片的开端。
之后 A 系列的芯片被用在 iPhone,iPad 以及 Apple TV 中,A 系列的芯片也出现在已经停产的 iPod Touch 以及 HomePod 中。随着 Apple 不断地改进,提升核心数量,集成图形硬件和速度,逐渐拥有了媲美笔记本和台式机的性能。
随着技术积累,苹果决定脱离自 2006 年以来为 Mac 提供处理器的 Intel。2020 年宣布 Mac 全系列转向自家设计的芯片,于是 M 系列处理器的时代展开了。
Apple 自从 2020 年 WWDC 宣布将 Mac 全系列切换成 Apple silicon 过去已经有 4 年了,第一台搭载了 M 系列芯片的 Apple M1 MacBook 在 2020 年 11 月 10 号发售,直至今天所有的 Mac 产品线已经全部更换为 Apple silicon 芯片。
M 系列芯片
Apple M 系列的芯片至今为止也已经迭代了 4 代,短短的几年时间里面 M 系列芯片性能提升也非常巨大,苹果也一跃称为了顶尖的芯片制造商。
在目前的 M 系列芯片中包含了如下型号
| 芯片 | 发售日期 |
|---|---|
| M1 | 2020.11.10~2024.05.07 |
| M1 Pro | 2021.1018~2023.01.17 |
| M1 Max | 2022.03.08~2023.06.05 |
| M2 | 2022.06.06~ |
| M2 Pro | 2023.01.17~ |
| M2 Max | 2023.01.17~ |
| M2 Ultra | 2023.06.05~ |
| M3 | 2023.10.30~ |
| M3 Pro | 2023.10.30~ |
| M3 Max | 2023.10.30~ |
| M4 | 2024.05.07 |
介绍
- M1,M2,M3 是标准版本,兼顾了性能和电量消耗
- M1 Pro,M2 Pro,M3 Pro,增加了额外的 CPU,M1 Pro 和 M2 Pro 芯片则相较于 M2 和 M3 芯片有更多的内存带宽(memory bandwidth)200 GB/s,M3 Pro 芯片则只有 150 GB/s
- M1 Max,M2 Max,M3 Max,则是在 GPU 上比 Pro 系列增强,并且比 M1 Pro ,M2 Pro 有两倍的内存带宽 400 GB/s,用更好的图形处理性能
- M1 Ultra 和 M2 Ultra 则是在 M1 MAX 和 M2 MAX 上同时提升了 CPU 和 GPU 性能,并且拥有 800GB/s 的内存带宽
产品线
| 芯片 | 标准版 | Pro | Max | Ultra |
|---|---|---|---|---|
| M1 | MacBook Air(2020) Mac mini(2020) MacBook Pro(13-inch 2020) iMac(2021) iPad Pro(2021) iPad Air(2022) |
MacBook Pro(14-inch and 16-inch, 2021) |
MacBook Pro (14-inch, 16-inch, 2021) Mac Studio(2022) |
Mac Studio(2022) |
| M2 | MacBook Air(2022, 2023) MacBook Pro(13-inch, 2022) iPad Pro(2022) Mac Mini(2023) Vision Pro(2024) |
MacBook Pro(14-inch, 16-inch, early 2023) Mac mini(2023) |
MacBook Pro(14-inch, 16-inch, early 2023) Mac Studio(2023) |
Mac Studio(2023) Mac Pro(2023) |
| M3 | MacBook Pro(14-inch, late 2023) iMac (2023) MacBook Air (13-inch, 15-inch, 2024) |
MacBook Pro (14-inch, 16-inch, late 2023) | MacBook Pro(14-inch, 16-inch, late 2023) |
核心数
CPU 和 GPU 的核心数影响了 Apple silicon 芯片的整体性能,以及多任务处理的能力。核心数越多在多任务处理,尤其是 CPU 和 GPU 资源消耗的任务来说有优势。
不同系列的芯片在核心数上也有不同的差别。
| 芯片 | 标准 | Pro | Max | Ultra |
|---|---|---|---|---|
| M1 | 4 高性能核心 4 高能效(energy efficient) 7, 8 核 GPU |
两个版本 6 个高性能核心 + 2 个高能效核心 + 14 核 GPU 8 个高性能核心 + 2 个高能效 + 16 核 GPU |
8 高性能 2 高能效 24 或 32 核 GPU |
16 高性能 4 个高能效 48 或 64 核 GPU |
| M2 | 4 高性能 4 高能效 8,10 核 GPU |
6 或 8 个高性能 4 个高能效 16 或 19 核 GPU |
8 高性能 4 高能效 30,38 核 GPU |
16 高性能 8 高能效 60 或 76 核 GPU |
| M3 | 4 高性能 4 高能效 8,10 核 GPU |
5,6 核高性能 6 高能效 14,18 核 GPU |
10,12 高性能 4 高能效 30,40 核 GPU |
单核性能
| 芯片 | (Standard) | Pro | Max | Ultra |
|---|---|---|---|---|
| M1 | 2,330–2,350 | 2,360–2,370 | 2,380–2,400 | 2,384 |
| M2 | 2,570–2,630 | 2,640–2,650 | 2,740–2,800 | 2,760–2,770 |
| M3 | 3,010 | 3,120 | 3,120 |
多核性能
| 芯片 | (Standard) | Pro | Max | Ultra |
|---|---|---|---|---|
| M1 | 8,250–8,390 | 10,300–12,200 | 12,180–12,430 | 17,810 |
| M2 | 9,630–9,650 | 12,100–14,250 | 14,500–14,810 | 21,180–21,320 |
| M3 | 11,763 | 14,010–14,410 | 19,160–21,215 |
M1、M2 和 M3 芯片在单核和多核任务中的性能逐步提升,尤其是 M3 芯片在各方面表现出更高的性能。然而,值得注意的是,基准测试并不能完全反映实际使用情况。基准测试专注于特定任务和合成负载,无法准确捕捉真实世界的使用场景和变化。
统一内存架构
Apple Silicon 芯片采用统一内存架构,意味着内存直接与处理器相连,以实现最大速度和效率。这意味着所选的芯片决定了可用的内存选项,且内存无法在后期进行升级。
| 芯片 | (Standard) | Pro | Max | Ultra |
|---|---|---|---|---|
| M1 | 8GB 16GB |
16GB 32GB |
32GB 64GB |
64GB 128GB |
| M2 | 8GB 16GB 24GB |
16GB 32GB |
32GB 64GB 96GB |
64GB 128GB 192GB |
| M3 | 8GB 16GB 24GB |
18GB 36GB |
36GB 48GB 64GB 96GB 128GB |
决定需要多少内存取决于你的具体任务和使用模式。对于大多数用户来说,8GB 内存已经足够,但如果有更高强度的多任务需求,升级到 16GB 或 24GB 是合理的。超过 32GB 的内存通常适用于非常高要求的工作流程。
总结
总体来说,如果是 Apple Silicon 的新用户,还不确定选择哪款芯片,可以参考以下原则:
- 如果需要良好的价格、性能和电池寿命平衡,并且有日常计算需求,选择 M1、M2 或 M3。
- 如果需要专注性能以应对稍强的工作,比如编程,设计做图,选择 M1 Pro、M2 Pro 或 M3 Pro。
- 如果需要额外的图形性能来处理图像、视频、图形设计或游戏,比如视频剪辑,渲染视频,选择 M1 Max、M2 Max 或 M3 Max。
- 如果需要最高的整体性能以应对极高强度的专业工作,选择 M1 Ultra 或 M2 Ultra。
通常来说,从任一 M1 芯片升级到其直接继任者并不值得。如果你已经是 M2 用户,可能更好等到 Apple 在未来几年推出 M4 系列芯片再进行升级。
Felo 一款实时同声传译应用
很早就在 Twitter 上知道了 Felo 这样一款同声传译的工具,这个工具让我在刚来日本,拨打日语客服的时候起到了非常重要的作用,我用一个手机拨打客服电话,然后用另外一个手机实施翻译客服说的内容,最近也为我解决了乐天银行无法登录的问题。
这两天又发现一款语音转文字的应用 Voicenotes 就又想起了 Felo 这一款翻译工具,语音转文字这一个领域在最近非常火热,可能是因为 OpenAI [[Whisper]] 的原因,让语音识别在准确率,以及上下文识别中的可用率提升了非常多,
一句话说明 Felo 的功能的话,就是可以选择两种语言,然后实时在两种语言之间做语音识别转文字,然后进行翻译。
Felo 团队还开发了一个网页版本
缺点
如果说缺点的话就是 Felo 的定价,普通人使用起来确认比一般的订阅制应用要高,在日区一年的订阅费用是 37000 日元,美元也接近 240 美元了。但是翻译的需求普通人也不是每天都存在,所以可能 Felo 还是定位成 ToB ,在跨国会议,多地区人交流沟通的高频度场合比较适合。
如果你看到这里对 Felo 感兴趣,可以点击我的邀请 注册账号之后,你我都可以体验 60 分钟的 Felo 转译。
related
- [[Glarity]]
- Felo 字幕 ChatGPT 跨语言实施翻译视频字幕 可以给 YouTube 和会议提供实时双语字幕
- YouTube 双语字幕
- [[通义听悟]]
期权策略:Bull Call Spread
Bull Call Spread,可以翻译成牛市看涨价差策略,这是一个期权交易策略。
Bull Call Spread
这个交易策略由两个看涨期权(call option)组成,购买一个远期看涨期权,同时卖出一个相同到期日但是执行价更高的看涨期权。
使用这个策略的交易员期望投资标的以一个缓慢的趋势看涨。
优点
- 该期权交易策略可以避免持有资产并且资产大幅下跌的风险
- 可以认为是以打折的价格购买一个看涨期权,减少了部分买入看涨期权所花费的期权费
- 适合在远期(几周,几个月)看好的标的上进行操作。
- 该期权最适合在那些稳步上涨的股票中进行操作,在不持有正股的情况下也可以享受上涨的收益
- 牛市看涨价差期权比仅购买看涨期权更便宜
- 该策略将拥有资产的最大损失限制为策略的净成本
最大风险
- 股价跌落,丧失期权购买费用
- 另外就是如果股价突然上涨很多,那么该策略的最大收益也是封顶的,不会跟随着股价上涨而增加
如何构建牛市看涨价差策略
为了构建一个牛市看涨价差策略需要执行以下的一些操作
- 首先要确定一个资产,这个资产最好是会稳步上涨的,并且提供足够的期权交易市场(期权交易流动性好),这个资产可以是股票,指数或者是现物(Currency)
- 购买一个看涨期权,首先购买一个价内的看涨期权,这个期权可以是一个价内(In the money),具有内在价值的看涨期权。
- 卖出一个同样到期时间的,价外看涨期权,重点在于同样到期时间,并且行权价更高的看涨期权。该看涨期权的价格肯定没有买入的看涨期权价格高,只能抵掉一部分(相当于一个折扣)
- 监控持仓和市场,Bull Call Spread 策略建立之后,交易者可以监控期权的价格。
- 结束持仓,如果行权日期临近,可以决定是否行权,或者通过卖出 Long Call 和买入 Short Call Option 的方式来关闭此策略。如果行权日时,股票的价格在卖出去的看涨期权行权价之上,那么此策略可以获得最大的收益。
需要注意的是,Bull Call Spread 策略的最大收益受限于两个看涨期权中间的价差减去期权价格,而最大的风险就是损失构建策略的期权购入价格。
一个例子
假如有一个股票叫做 ABC,当前的价格是 50 USD,交易者认为该股票会在下个月上涨,所以想要建立一个 Bull Call Spread。
首先购买一个在下个月到期的 50 USD 行权价的看涨期权,这个看涨期权叫做 at-the-money option,因为行权价就是当前的交易价格,期权的价格是每股 3 USD。
同时卖出了相同行权日,行权价 55 USD 的看涨期权,这个期权叫做 out-of-the-money 期权(价外期权),因为价格高于当前交易价格。
完成交易后,就构成了 Bull Call Spread。
波动性对牛市看涨价差的影响
因为同时买入和卖出了看涨期权,一定程度上波动性被抵消了。
当波动性上升时,两种期权的价格都会上涨,这意味着多头看涨期权的价值会增加,同时空头看涨期权的价值也会增加。但是由于这个策略是做多一个期权,并做空另外一个看涨期权,波动率在一定程度上被相互抵销了。
用期权的语言来说,这通常被称为「near-zero vega」,Vega 衡量期权价格对波动性变化的敏感度,接近于零的 Vega 意味着,假设其他因素保持不变,波动性发生变化时,Bull Call Spread 的价格变化很小。
但是需要指出的是,牛市看涨价差并不完全不受到波动性变化的影响,确切的影响可能还取决于其他因素,包括期权处于价内或价外的程度,以及距离到期的时间。
时间对牛市看涨价差的影响
时间对 Bull Call Spread 的影响,也称为时间衰减或 theta,这个有点复杂,该策略包含两种看涨期权,这两种期权对时间的流逝都有不同的反应。
期权总价值的时间价值部分随着行权日期临近而减少,这个称为时间侵蚀(time erosion)或时间衰减(time decay)。
对于多头看涨期权来说,时间衰减是有害的,随着时间推移,在其他条件相同的情况下,所购买的期权的价值会下降。这是因为该期权实现盈利的时间较少,价值较低。
另外一方面,对于空头看涨期权,时间衰减对卖出方有利,随着时间推移,出售的期权价值会下降,交易者对该期权负有义务,如果空头看涨期权到期时一文不值,交易者将保留出售该期权所获的全部权利金。
时间衰减对牛市看涨价差策略的总体影响取决于股票价格与价差执行价格的关系。如果股票价格接近或低于多头看涨期权(即执行价格较低的看涨期权)的执行价格,那么牛市看涨价差策略的价格会随着时间的推移而下降,发生亏损。多头看涨期权最接近交易价格,并且比空头看涨期权价值下降更快。
如果股票价格接近或高于空头看涨期权(即执行价格较高的看涨期权)的执行价格,那么牛市看涨价差策略的价格会随着时间的推移而增加,发生盈利。空头看涨期权现在比多头看涨期权更接近交易价格,价值下降得更快。
最后,如果股价处于执行价格的中间,那么时间侵蚀对牛市看涨价差的价格几乎没有影响,因为多头和空头看涨期权以大致相同的速率衰减。
资产标的价格变化对牛市看涨价差的影响
标的资产的价格变化对牛市看涨价差有重大的影响,当标的资产的价格上涨时,会获利。
如果资产价格大幅上涨并超过空头看涨期权的行权价,那么策略达到最大利润。多头看涨期权的价值增加,空头看涨期权则被标的资产价格的上涨所抵消。
另外一方面,如果标低价格温和上涨,并且在到期时处于多头看涨期权行权价和空头看涨期权行权价价格之间,该策略仍然会获利,但是不是最大收益。多头看涨期权的价值增加了,但是空头看涨期权的价值也开始增加,降低整体利润。
最后,如果标的资产价格下跌,或者没有涨幅,该策略产生净损失。如果到期时价格低于多头看涨期权的执行价,那么两个期权将在到期时毫无价值,并且建立策略时的权利金。
其他考虑和风险
该策略还有一些隐含的需要考虑的内容
- 提前行权风险,美式期权可以在到期前任何时间行权,空头期权的持有者无法控制时间,随时都可能被要求履行义务。该策略中的空头看涨期权面临提前转让的风险,特别是当其接近到期日,且标的资产价格高于空头看涨期权的执行价格时。如果发生转让,交易者可能需要以空头看涨期权的执行价格出售标的资产
- 股息,如果标的资产支付股息,可能会影响空头看涨期权提前分配的可能性,时间价值小于股息的实值看涨期权可能被提前分配
- 不可避免的交易成本,买卖期权的成本可能会增加,特别是在交易者使用少量期权的情况下,成本可能会侵蚀交易的利润
- 市场条件,牛市看涨价差最适合在适度看涨的市场中使用,如果市场波动很大或看跌,那么该策略可能不是最佳的选择
- 到期日的选择,到期日的选择可以显著地影响牛市看涨价差的结果,如果到期日太早,标的资产可能没有足够的时间来实现预期的价格变动,如果到期日太远,期权费用可能很贵,构建该策略可能需要更多的资金。
- 执行价格的选择,多头和空头看涨期权执行价格的选择也很重要,执行价格之间的价差越大,潜在的利润也越高,但是潜在的损失也越大。
Bull Call Spread 策略可以限制风险,最大的可能损失就是构建策略的成本,但是这个策略也限制了潜在的利润。
如何实施
Bull Call Spread 策略可以选择未来一段时间(几天,几周或几个月)小幅升值的资产来实现。
related
- [[牛市看涨期权价差策略]]
- [[牛市看跌期权价差]]
- [[熊市看跌期权价差]]
- [[熊市看涨期权价差]]
如果你也对交易,期权感兴趣,可以加入群组一起讨论呀。
相关工具
如果你在日本
使用 Quartz 发布 Obsidian 笔记库
自从使用 [[Obsidian]] 以来就一直想要有一个开源版本的 [[Obsidian Publish]] 代替,过去这几年也尝试了不少方案,比如 Jekyll 静态网站生成,比如使用 [[Logseq]] 生成网站, 然后还想过从 Obsidian 同步到 Notion 里面,然后再使用 [[NotionNext]] 来生成网站。
下面是所有我尝试过的方案
- [[Nolebase]] 一款基于 VitePress 的在线知识库
- [[Obsidian Digital Garden Plugin]] 一款 Obsidian 插件,结合 GitHub 仓库可以实现快速分享笔记
- [[Digital Garden Gatsby Template]] 一款 Gatsby 模板
- [[Digital Garden Jekyll Template]] 一个 Jekyll 模板
- [[Gatsby Theme Primer Wiki]]
- [[MindStone]]
- [[Obsidian-mkdocs template]] 基于 [[mkdocs]] 的知识库
- [[Obsidian PKM]]
- [[Jekyll Garden Template]]
- [[Perlite]]
- [[Pubsidian]]
- [[flowershow]]
但是以上的方案我尝试之后都不是一个我认可的完善的方案,或多或少有一些问题,也不能和我自己的工作流程结合起来。
但是很多年前看到过一个静态网站分享的方案 Quartz,没想到发展了几年之后发布的 v4 版本,可以完美的融合到我的工作流中,并且可以非常方便地分享我的本地 Obsidian Vault。
什么 Quartz
Quartz 是一个静态网站生成工具,可以用来发布 Markdown 的笔记,和 Obsidian 搭配使用绝佳。
Quartz 发布 4.x 版本之后可用度大大提高,并且可以直接作为 Obsidian Publish 的开源代替存在。
Quartz 需要 Node v18.14 以及 npm v9.3.1
功能
- 自动生成双向链接 Automatically generated backlinks
- 支持 wikilinks,backlinks, Latex, 语法高亮
- 支持 Graph View
- 链接预览 Link Previews
- 本地关联图 Local graph
- 支持两种链接 Markdown and WikiLinks
- 支持 Table of Content
- Dark & light mode
Cons:
- No sidebar Navigation
界面

安装
通过克隆代码本地安装
git clone https://github.com/jackyzha0/quartz.git
cd quartz
npm i
npx quartz create
在执行了上面的命令之后,会在命令中选择是否要创建一个全新的仓库,还是直接使用 ln -s 来软链接一个既存的文件夹。
然后再运行
npx quartz build --serve
就可以直接启用一个本地的在线预览。
最后效果可以参考这里。
reference
爱沙尼亚电子居民申请记录
在网上逛论坛的时候,偶然看到有人提到了一个爱沙尼亚电子公民的电子居民卡,看起来挺有意思的,之前就看到过 [[帕劳数字居民身份证]],去检索了一下发现帕劳已经涨价到了 248 欧元,爱沙尼亚电子公民感觉上类似,所以就简单的记录一下。
爱沙尼亚的数字居民(E Resident)计划是由爱沙尼亚在 2014 年推出的一项电子公民计划。爱沙尼亚成为了第一个推出电子公民计划 E Residency 的国家。
爱沙尼亚目前是欧盟和北约的成员国,国旗是蓝黑白三色,国家域名是 .ee 电话号码的国际区号是 +372。
爱沙尼亚位于欧洲东北部,由大陆部分和波罗的海的 2222 个岛屿组成。它西临波罗的海,北濒芬兰湾,东靠楚德湖,南面和东面分别与拉脱维亚和俄罗斯接壤,总面积为 42,388 平方公里。该国属于温带大陆性湿润气候,主要民族是爱沙尼亚人,他们属于波罗的芬兰人。爱沙尼亚是北欧理事会、欧洲联盟、欧元区、申根区、北大西洋公约组织以及经济合作与发展组织的成员国之一,也是世界高收入经济体之一。
自上世纪 90 年代开始,爱沙尼亚就致力于成为互联网强国。所有的小学生都需要接受编程教育,并且将接入互联网视为基本人权之一。早在 2002 年,爱沙尼亚就已经完成了对境内大部分地区的 WiFi 覆盖。如今,几乎所有政府服务,包括投票选举、工商注册、报税等等,都可以在线办理,覆盖率高达 99%。爱沙尼亚发达的互联网也造就了很多互联网公司,比如 Skype,Hotmail 以及 [[Wise]]。
爱沙尼亚电子公民
爱沙尼亚电子公民不是签证,也不是居留权,所以如果要去爱沙尼亚旅游,还是需要申请申根区的签证。电子公民也不会影响原来国籍。
那么电子公民有什么好处?
- 无需到爱沙尼亚,就可以注册一家爱沙尼亚的公司,之后可以完全线上经营,同时也可以开设爱沙尼亚银行账户,用于境外投资和交易
- 爱沙尼亚公司启动成本低,注册公司仅需要 190 欧元,营收税率 0%,并且信誉高
- 但需要注意,如果公司要进行分红或者开工资时,需要缴纳 20% 的税款
申请流程
要成为爱沙尼亚电子公民非常简单,只需要准备好如下材料
- 护照照片或复印件
- 使用英文准备好申请的目的和动机,至少 1000 个字母,不超过 2000 个字母
- 支持支付 120 欧元的国际信用卡(Visa or Mastercard)
- 一张近期拍摄的至少 1300 x 1600 像素的照片,但不大于 6000 x 7380 像素,至少 1MB,最大 5MB
登录爱沙尼亚电子公民计划官网,点击网页右上角的 「Apply Now」,根据提示填写个人信息,然后选择 Pick-up Location (领取卡片的地方)然后爱沙尼亚的边境管理部分会审核材料,通过之后就可以去大使馆领取电子公民卡。
北京领取卡片的地方在大使馆,北京市朝阳区亮马桥北小街 1 号(天泽路东门入口),只需要带上护照即可。如果是在东京,那么到东京的大使馆领取即可。其他地方可以根据官网 的内容进行选择。
最后会问为什么要申请爱沙尼亚的电子公民,根据自己的实际需求填写就行,这里推荐可以自己先写中文,然后借助 ChatGPT,Gemini(Bard) 等工具翻译成英文。
申请的几个步骤
- Reason for applying 申请理由,目的,如果是开设公司则需要提供一些公司信息,这个地方我直接选择了 I do not have clear plans but I would like to be a member of the community of e-residents
- Personal and contact details 填写个人信息,包括姓名,出生日期,国籍等
- Identification details 护照信息 联系信息
- CV, social media and bank accounts,简历,社交媒体主页链接,银行账号
- Trade bans and criminal background 申明
- Pick-up location,选择领取卡片的领事馆,选择一个就近的前往即可
- Review your information,检查填写的信息是否正确
- Terms & conditions,同意条款
- Confirmation 提交申请并支付费用
申请注意
准备材料的时候所有文件都使用英文名命名,在上传的文件名中不要包含中文,日文或其他语言文字。
另外照片需要大于 1MB,可以使用 macOS 的 preview 然后放大照片的解析度。
另外申请的时候需要
时间
等待线上申请提交之后,会进入审核阶段。
- 申请表单会保存 2 个月,如果 两个月内没有,申请表单会过期。
- 申请提出到处理大约需要 30 天
- 从账户审核完成到寄送到目的地大约需要 2 个月时间
所以总体下来,如果从网站申请,到审批签发,大约需要 1 个月到 2 个月左右时间。
费用
手续注册需要 120 欧元费用,后续 renew 也需要 100~120 欧元费用。
设置 e-ID
拿到 E-Residency Kit 之后不能马上使用,需要等待大约 24 小时等大使馆将信息传回爱沙尼亚,然后收到邮件通知之后,就表示被激活可以使用了。
e-Residency Kit 包含了
- 电子芯片卡
- USB 读卡器
- 密码信封,PIN,PUK 码
- 使用说明书
注册爱沙尼亚公司
如果想要使用这个电子居民身份开公司,有一家服务提供商 Xolo 提供,也可以直接参考 官方如何 run a company 获取其他信息。
e-Residency 官网提供了一个市场 上面列出了所有支持 e-Residency 的公司,比如提供公司注册的 Xolo,1Office,e-Residency Hub, 有提供银行开户的 LHV,Wise,Payoneer,Stripe 等等。
开设银行
爱沙尼亚也有一些银行支持电子居留卡登录和管理
- SEB(瑞典),在爱沙尼亚有业务
- 瑞典银行(瑞典)
- LHV(爱沙尼亚),一家中等规模的现代爱沙尼亚银行,LHV 实际上是 Transferwise 使用的所有 SEPA 欧元交易的银行
- 两家分行,塔林和塔尔图
related
- [[拉脱维亚数字居民]]
- 立陶宛电子居民
- [[帕劳数字居民身份证]]
- [[爱沙尼亚开公司]]
DNS 泄漏以及如何防止
什么是 DNS 泄漏
DNS 泄露(DNS Leak)是指当使用虚拟专用网络(VPN)或其他匿名工具时,域名系统(DNS)查询数据绕过加密隧道,直接通过用户的本地 ISP(互联网服务提供商)进行解析。这意味着用户的浏览活动可能被 ISP 监视或记录,进而暴露了用户的实际 IP 地址和在线活动。
在深入探讨 DNS 泄露之前,有必要了解 DNS 的基本工作原理。DNS 是互联网的电话簿,当用户输入一个域名(如www.example.com)时,DNS将其转换为对应的IP地址(如192.0.2.1),以便计算机能够理解和访问该网站。
通常情况下,用户的设备会向 ISP 的 DNS 服务器发送请求进行解析。然而,当用户使用 VPN 时,所有的流量应通过加密的 VPN 隧道传输,并由 VPN 提供商的 DNS 服务器处理 DNS 请求。
DNS 泄露的原因 DNS 泄露可能由于以下几个原因发生:
操作系统配置问题:一些操作系统可能会忽略 VPN 设置,继续使用本地 DNS 服务器。 VPN 设置不当:不正确的 VPN 配置可能导致 DNS 请求未能通过 VPN 隧道传输。 VPN 软件缺陷:某些 VPN 软件存在缺陷,无法正确处理 DNS 请求。 IPv6 配置问题:如果 VPN 只处理 IPv4 流量,而未配置 IPv6,IPv6 流量可能会直接泄露。
如何检测 DNS 检测
检测 DNS 泄漏有很多方法,最简单的方法就是找一个在线的检测工具。
在线检测 DNS 泄漏的工具,通过用户访问网页的时候,在网站上生成多个域名解析请求,通过用户的设备发起,网站通过脚本捕获并记录这些域名请求结果,这些网站根据 DNS 响应,判断是哪个 DNS 服务器处理的,然后通过对比 DNS 服务器 IP 地址与公共 DNS 服务器 ISP DNS 服务器进行匹对。
如果检测的 DNS 服务器属于用户的 ISP 或者其他不安全的 DNS 服务器,而非用户期待的 DNS 服务器,则说明了 DNS 泄漏。
DNS 泄漏会造成什么影响
暴露用户的真实 IP 地址
即使用户使用 VPN 或者其他匿名网络访问工具来隐藏其真实的 IP 地址,但是如果 DNS 请求没有通过 VPN 隧道,而是通过用户自己的 ISP 解析,那么 ISP 和其他潜在的监听者仍然可以看到用户的真实 IP 地址,这意味着用户的地理位置和身份可能被暴露。
DNS 请求包含了用户访问的域名,如果这些请求通过 ISP 解析,ISP 可以记录和分析用户的浏览历史,这使得用户的在线活动变得不再私密,并且可能被用户于广告投放,数据挖掘,甚至在某些国家可能被政府监控。
潜在的网络攻击
DNS 泄漏还可能使得用户更容易成为攻击的目标,比如,攻击者可以利用 DNS 请求来识别用户网络行为,实施 DNS 劫持或中间人攻击,将用户引导至伪造的网站或恶意服务器,从而窃取敏感信息或传播恶意软件。
信息过滤和审查
某些政府或地区,政府或 ISP 会对用户访问的内容进行过滤和审查。通过 DNS 泄漏,政府或 ISP 可以轻松跟踪和组织用户访问被审查或禁止的网站,从而限制用户的互联网自由。
如何防止 DNS 泄漏
- 使用可靠的 VPN 服务,并且配置 VPN 的 DNS,将所有的网络请求通过 VPN 进行
- 手动配置 DNS 服务器
- 如果 VPN 不支持 IPv6,则禁用 IPv6
- 操作系统和路由器配置静态路由,或自行搭建安全的 DNS 服务器,比如 AdGuard Home [[PiHole]] 等
从内地到香港出金最佳的方法
银行汇款
汇丰银行内地转汇丰银行香港
汇丰银行卓越及以上等级的用户可以免手续费汇款到汇丰银行香港。
内地中行到中银香港
中国银行的购结汇中,如果是境外中行,可以免除手续费以及电讯费的。
中行国内的普通借记卡即可。
中行对全球设有境外支行的当地中行都可以进行汇款,并且享受手续费减免,对日本汇款是 300 万日元内 1500 手续费,到香港是免除手续费的。
需要注意的是尽量到业务量比较大的支行办理开卡,业务量小的支行可能会为了揽储或完成 KPI 等,在汇出时各种阻拦
0 手续费兴业银行到汇丰银行
兴业银行寰宇人生借记卡可以以比较优惠的现汇利率购汇,然后也可以零手续费
直接到香港线下存款
优点是不占用每年 5 万的外汇限额,但是不方便,并且出境也有现金的限制。
境外赚取美元
比如在 AdSense,YouTube,X 等平台赚取美元,如果可以开设香港的账户,可以直接打款到香港的账户,然后不过国境。
对敲
如果有朋友需要港币换人民币,或者日元换人民币,那么可以通过朋友的账户直接进行(小额的)转账,国内通过银行到银行人民币转账,境外通过香港银行到香港银行的转账。
文章分类
最近文章
- Dinox 又一款 AI 语音实时转录工具 前两天介绍过 [[Voicenotes]],也是一款 AI 转录文字的笔记软件,之前在调查 Voicenotes 的时候就留意到了 Dinox,因为是在小红书留意到的,所以猜测应该是国内的某位独立开发者的作品,整个应用使用起来也比较舒服,但相较于 Voicenotes,Dinox 更偏向于一个手机端的笔记软件,因为他整体的设计中没有将语音作为首选,用户也可以添加文字的笔记,反而在 Voicenotes 中,语音作为了所有笔记的首选,当然 Voicenotes 也可以自己编辑笔记,但是语音是它的核心。
- 音流:一款支持 Navidrom 兼容 Subsonic 的跨平台音乐播放器 之前一篇文章介绍了Navidrome,搭建了一个自己在线音乐流媒体库,把我本地通过 [[Syncthing]] 同步的 80 G 音乐导入了。自己也尝试了 Navidrome 官网列出的 Subsonic 兼容客户端 [[substreamer]],以及 macOS 上面的 [[Sonixd]],体验都还不错。但是在了解的过程中又发现了一款中文名叫做「音流」(英文 Stream Music)的应用,初步体验了一下感觉还不错,所以分享出来。
- 泰国 DTV 数字游民签证 泰国一直是 [[Digital Nomad]] 数字游民青睐的选择地,尤其是清迈以其优美的自然环境、低廉的生活成本和友好的社区氛围而闻名。许多数字游民选择在泰国清迈定居,可以在清迈租用廉价的公寓或民宿,享受美食和文化,并与其他数字游民分享经验和资源。
- VoceChat 一款可以自托管的在线聊天室 VoceChat 是一款使用 Rust(后端),React(前端),Flutter(移动端)开发的,开源,支持独立部署的在线聊天服务。VoceChat 非常轻量,后端服务只有 15MB 的大小,打包的 Docker 镜像文件也只有 61 MB,VoceChat 可部署在任何的服务器上。
- 结合了 Google 和 AI 的对话搜索引擎:Perplexity AI 在日本,因为 SoftBank 和 Perplexity AI 开展了合作 ,所以最近大量的使用 Perplexity ,这一篇文章就总结一下 Perplexity 的优势和使用技巧。