Asciidoctor Maven Plugin 使用
Asciidoctor Maven Plugin 这一款 maven 插件可以使用 Asciidoctor 将 AsciiDoc 文档转变成可读文档。
Setup
<plugins>
<plugin>
<groupId>org.asciidoctor</groupId>
<artifactId>asciidoctor-maven-plugin</artifactId>
<version>1.5.6</version>
...
</plugin>
</plugins>
and
<plugin>
...
<executions>
<execution>
<id>output-html</id>
<phase>generate-resources</phase>
<goals>
<goal>process-asciidoc</goal>
</goals>
</execution>
</executions>
</plugin>
reference
威联通折腾篇十二:verysync 微力同步
很早之前有一款文件同步工具叫做 BtSync,后来改名字叫做 Resilio Sync,但是因为他太强大可以用来干很多坏事,比如曝光政府秘密文件啦,传播盗版啦,所以早早的就封了。墙内几乎是变的不可用了,所以后来有人(不太清楚是谁)搞了这个微力同步,可以支持多平台同步文件,速度快,点对点传输,并且支持的平台非常多,桌面版,移动端自不必说,NAS,路由器甚至也可以安装。
所以今天就把威联通装上了这个微力同步,因为不太确定其安全问题,所以目前只用来同步一些别人分享的公开文件。个人也建议先观察观察,再考虑是否用来同步私人文件。
这里提供两个 KEY
这是微信猪之芥末共享的 50 G 图书
B2QZAM7HGAP75K7UC265OHJ7K3WNHUN2MV4CGRGFPGFO7PC2Z26ZT6D2AF
这是高岩老师的共享
B25OMSTPXPNOAX62RAYKADUPGSJXQYONWAEBGROTVR7HSHFISGYQ6DTTAW
其他有任何好的同步 KEY,记得告诉我呀,https://t.me/einverne
reference
- https://mp.weixin.qq.com/s/cYc_U6ZlA5vLghAsp5CBGw
网站推荐之 usesthis.com
在一篇效率工具的文章中偶然获知此网站,就像其网站写的标语那样:
A collection of nerdy interviews asking people from all walks of life what they use to get the job done.
这个网站的唯一作用就是采访很多不同工作的人,看看他们在日常生活中使用的不同工具。
在这个网站上可以看到不同种类的人,screen writer, designer, engineer, web developer etc,也可以看到他们使用的工具从 windows ,linux,到 macOS,各种硬件设备,软件工具也都大不相同。每个人的使用习惯也都各不相同。
看到这些不同工作的人使用不同的工具来在保存灵感,提高效率,而我们竟然还在用微信来聊工作,用 Excel 来安排时间,有的时候想想也是很可怜了。
虽然有的时候好的工具并不能够带来一定的效率提升,但是如果有一个合适自己的使用的工具就能够提升生活的幸福感。
更多的新内容就从那个网站获取吧。
PCloud 加密同步 --Dropbox 代替
Dropbox 学 Evernote 强行变更了用户条款,只允许免费用户只能够在三个设备同步文件 1。虽然在 2019 年 3 月以前 link 到账户的设备不受到任何影响,可以继续使用,但是如果一旦超过 3 台设备,在添加新设备时就不能添加。
所以就找到了这个 PCloud 的同步应用。他满足我之前对选择软件的所有要求:
- 跨平台,各个桌面版(Windows,macOS,Linux),Web 版,移动端 (iOS,Android)
- 可分享
- 支持多人协作
更甚至有一些功能超出了我的想象,比如:
- 在桌面版中使用 virtual hard drive,可以从计算机本地任意一个文件夹同步文件,而不需要像 Dropbox 一样只能够存放到一个文件夹中
- 使用加密技术,在客户端加密文件,即使上传同步,即使文件泄露别人也无法获取同步的真正文件 2
- 使用 Upload links 可以从朋友那边接收文件,即使他们没有 pCloud 账户
- 下载文件使用密码保护,当然这其实是比较基础的功能
- 使用 Chrome Extention 直接添加文件到 PCloud
pCloud 的免费用户,初始有 4G 空间,可以通过邀请 解锁最多 10 G 空间。至于在速度上,因为我大部分时间都是同步很小的文件,对速度要求不是那么高,而追求的是同步的稳定性,在一台电脑上拉进文件夹的内容,等我到家打开电脑,能够稳定的同步过来就已经满足了我的绝大部分需求。pCloud 的服务器明显没有在中国,上传和下载的速度也不是非常理想,但还能接受。3
每天学习一个命令:sort 排序
sort 命令用来对文件行进行排序,常用的一些参数
-n表示数字序号-r表示逆序-k,表示根据第几列-t,表示字段与字段之间的分隔符
使用
按第三列排序
sort -nk3 /path/to/file
解释:
-n表示的是按照字母序排-k3表示第三列
按列优先级排序
比如有一行数据包含多列,需要按照第一列排序,然后按照第三列排序
1 a 2
3 b 5
1 c 4
2 d 2
3 e 1
期望的结果是按照第一列先排序,然后第三列排序
1 a 2
1 c 4
2 d 2
3 e 1
3 b 5
那么可以使用命令
sort -n -k1,1 -k3,3 /path/to/file
严格意义来说,-k3 表示的是从第三个字段开始到行尾。
使用自定义分隔符
sort -t: -nk3 /etc/passwd
sort -t' ' -k3,3 file
-t 后面接 : 表示以 : 来分割列,最常见的比如 /etc/passwd 文件,以 : 来区分一行中的各个列
合并两个文件并且移除重复行
一个典型的 sort 应用场景
sort file1 file2 | uniq
排序日志中耗时最大的行
假设有日志
2020-02-02 11:20:20 requestId method=someGet param=param cost=100
2020-02-02 11:20:21 requestId1 method=someGet param=param cost=101
2020-02-02 11:20:22 requestId2 method=someGet param=param cost=103
现在要过滤出其中耗时最大的行,可以使用
sort -r -nk4 -t= log.txt
解释:
-t=split lines by=,so the string to sort is column 4-k4sort column 4-nnumberic order-rreverse order
MySQL 中索引相关 SQL 语句
索引是用来加快从数据库中查询数据的速度的。
需要注意的是索引的使用会增加插入和更新的时间,因为在插入数据的同时也会更新索引。所以在创建索引时确保只在那些频繁作为查询条件的列中增加。
创建索引
创建索引时有几个需要注意的点:
- 不要在频繁写,而读取频率较低的表上使用索引,和之前说的那样,索引提高了读速度,而损耗了写速度
- 不要在 low cardinality 的列上使用索引,Cardinality 直接翻译是基数,可以理解成为这一列取值的散列程度,如果一个列包含的值只有少数几个,那么索引的效果也无法达到
- 不要在固定大小的表上使用索引,小数量集的表增加索引并不会带来多大的性能提升,所以尤其需要注意的是那些可能随着时间数据量增长很快的表,比如
users表
在建表时
CREATE INDEX idx_name ON table_name(column1, column2);
ALTER TABLE `table_name` ADD INDEX idx_name (`column1`);
创建唯一索引
ALTER TABLE `table_name` ADD UNIQUE uni_name (`column1`)
显示查看索引
查看表索引
SHOW INDEX FROM table_name;
在查询的结果中可以看到索引的名字,列名,散列程度(Cardinality),索引类型(BTREE) 等等。
查询 Schema 中所有的索引
SELECT DISTINCT
TABLE_NAME,
INDEX_NAME
FROM INFORMATION_SCHEMA.STATISTICS
WHERE TABLE_SCHEMA = 'your_schema';
删除索引
DROP INDEX idx_name ON table_name;
ALTER TABLE table_name DROP INDEX idx_name;
Single index vs Composite index
组合索引和单一索引一样,不过组合索引是需要组合多列。
假设有用户表 users
ID | first_name | last_name | class | position |
--------------------------------------------------------
1 | Teemo | Shroomer | Specialist | Top |
2 | Cecil | Heimerdinger | Specialist | Mid |
3 | Annie | Hastur | Mage | Mid |
4 | Fiora | Laurent | Slayer | Top |
5 | Garen | Crownguard | Fighter | Top |
然后在 class 和 position 列上创建组合索引
CREATE INDEX class_pos_index ON users (class, position);
然后数据库会创建一个组合索引的排序,类似:
class-position Primary Key
--------------------------------
AssassinMid -> 10
ControllerSupport -> 16
ControllerSupport -> 18
ControllerSupport -> 8
FigherTop -> 7
FigherTop -> 9
FighterJungle -> 13
FighterJungle -> 21
FighterJungle -> 23
假设需要查询班级中的 Top,那么会提升速度:
SELECT * FROM users
WHERE
class = 'Specialist'
AND
position = 'Top';
因为按照了 class-position 来排序,所以查询速度得到了提升。数据库能够在 O(log_2(n)) 时间内查找到 Specialist-Top 而不需要读取全表。
需要注意的是即使查询条件只有 class 字段,组合索引依然能够提升速度,因为class 在组合索引的第一个位置。
但是单纯的查询 position
SELECT * FROM users WHERE position = 'Top';
则享受不到组合索引带来的好处。所以组合索引的列顺序非常关键。
创建组合索引的一些注意点:
- 如果特定列固定的出现在查询条件中,那么对这些列创建组合索引比较好
- 如果要创建 field1 上的索引,也要创建 (field1, field2) 上的索引,那么只创建一个组合索引 (field1, field2) 已经足够
- 和 Single indexes 一样,组合索引的 Cardinality 一样重要。显然当两个 field 有高的 Cardinality,组合索引的 Cardinality 也会很高。但是某一些情况下低 Cardinality 的列也会有高的 Cardinality 组合索引
reference
再也不见 Google+
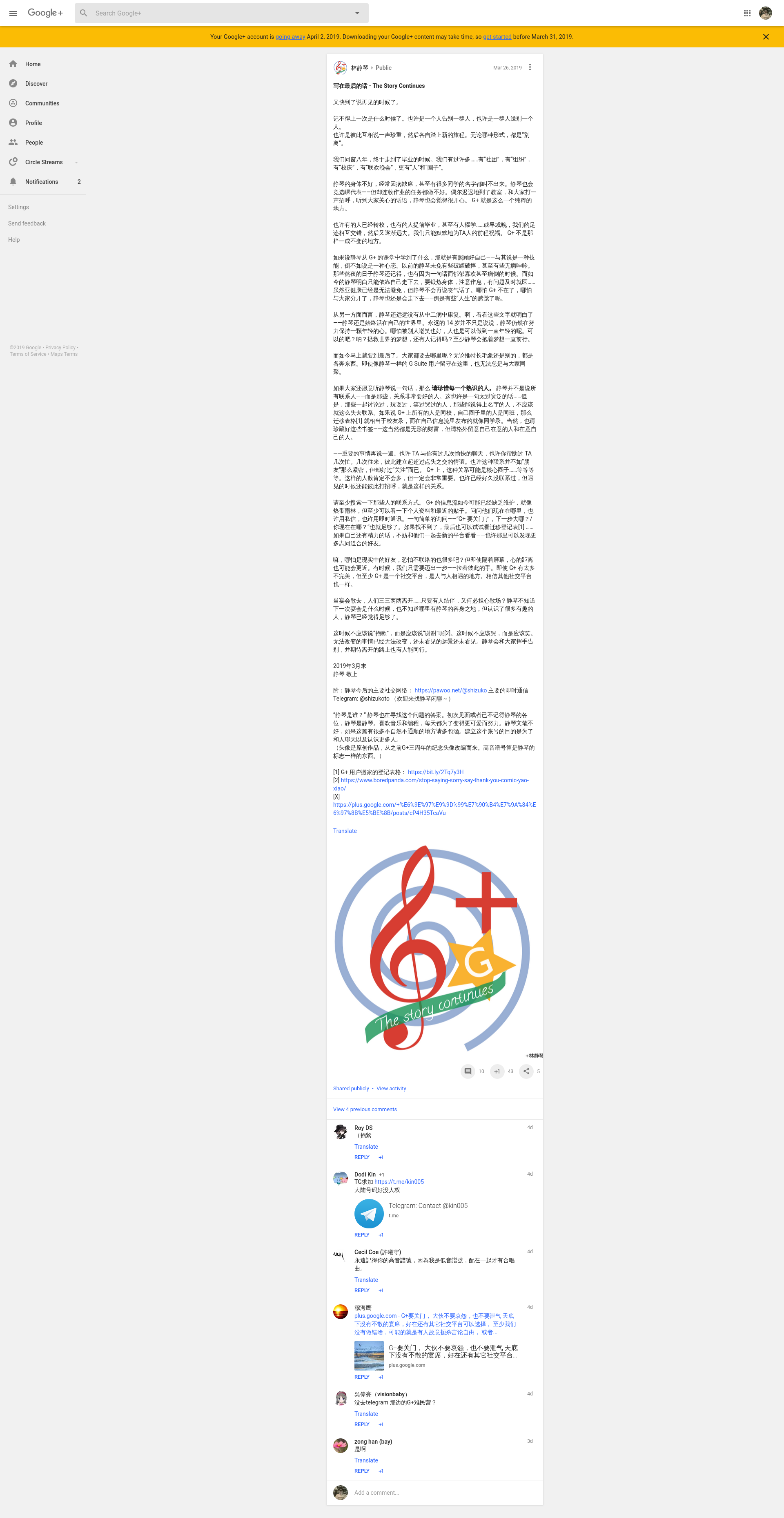
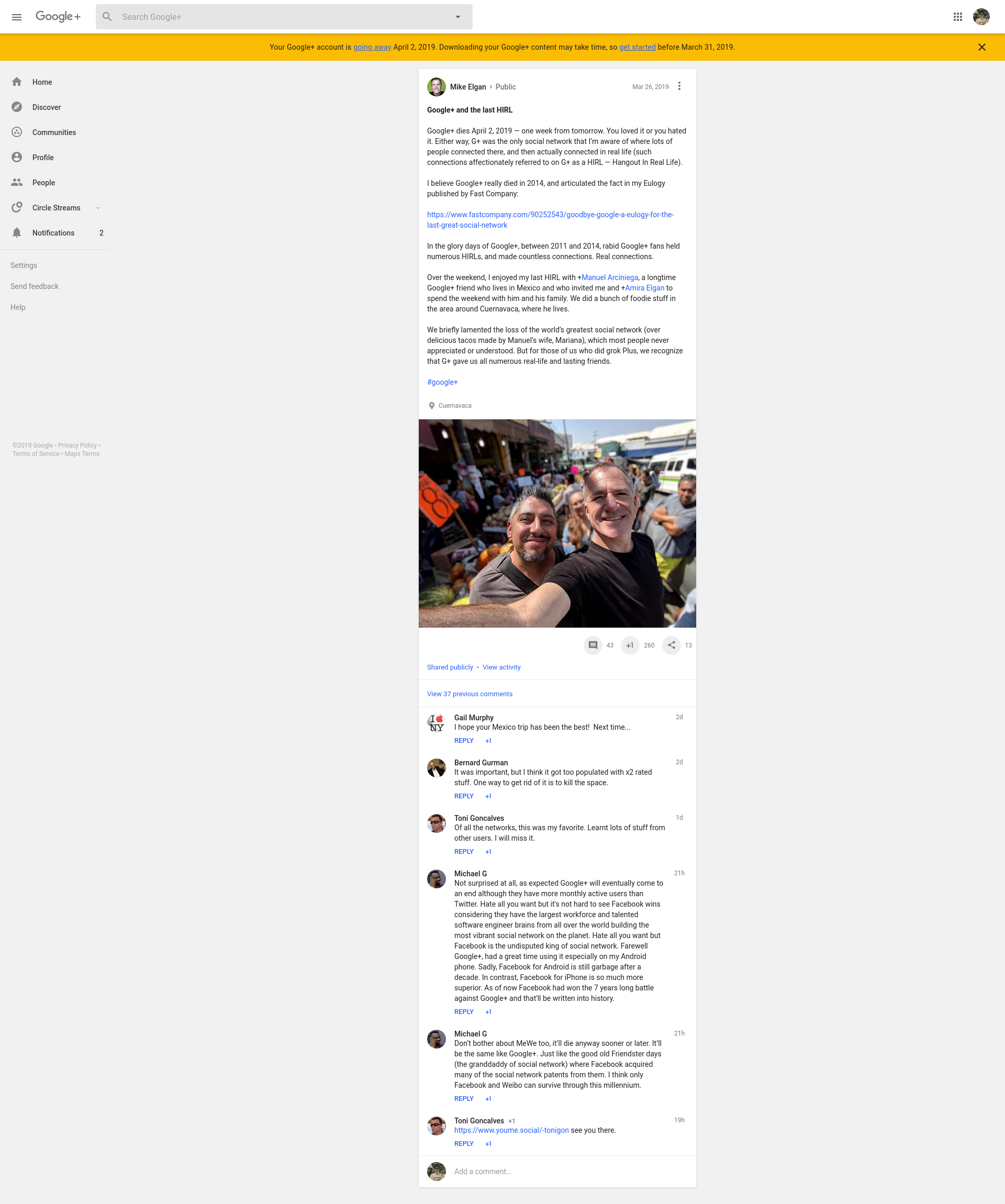
今天久违地登录上 Google+,终于在 2019 年 4 月 2 号,Google+ 就要全站关闭了,可是我依然还记得当年到处找邀请码,为 Google+ 的每一次新功能发布而欣喜若狂。然而我知道我自己也已经很久很久没有主动登录 G+ 了,原本每一次换系统,在手机首屏的 G+ 应用,也在得知 G+ 要关闭的当天就卸载,并且自此之后再没有发布任何更新,或许 Google+ 的死亡是一个漫长的过程,慢慢的,像癌症一样,步入死亡。我也不曾意识到,从某一个时刻开始就不曾频繁登录,但也渐渐的发现我关注的好友再也不来,就这样一个恶性循环之后,慢慢的就没有了平台的价值。

Social
很多人说 Google+ 是 social,而对于我来说,Google+ 是一个信息发布渠道,是我订阅的信息来源。自 Google Reader 关闭之后,Google+ 是我的一个重要信息来源,虽然这里的人大部分都陌生人,但却因为一些纯粹的原因聚集到一起,我们讨论共同的话题,分享最新的科技资讯,可以说 Google+ 开启了我人生的新一面,伴随着我从学校,到毕业,到社会,让我从被动的汲取知识,到主动获取信息。Google 的使用非常亲民,能够对感兴趣的内容进行很多的讨论,不管是 Google 的产品还是最新的动态,或者是哪里的美景,用起来都非常舒服。
两篇怀念
和
功能
现在回过头来想当时 Google+ 发布的盛况,几乎每一个功能都能够独立作为一个产品,并且可以秒杀同类的产品。
好友关注
当时最引人瞩目的一个功能就是”圈子“,这个小小的功能,可以让用户单方面将一些人圈入圈子,而不想当时的 Facebook 一样需要对方同意为好友,也不像 Twitter 一直只能够单方面的关注而不能对关注的人分类。虽然推出轰轰烈烈,当却在后续的产品迭代中逐渐淡化了该功能,而如今站在 2019 年来看,这个功能被 Facebook 学习去了。
图片视频分享
比如图片分享,无损,原图,用户可以极好的控制照片分享的权限,公开,给自己的关注着,或者独立分享给一个圈子。这样的需求几乎满足了照片分享的方方面面,摄影师可以公开分享自己的高清原图,普通用户可以给自己的关注着发发自己的私人照片,也就是那个时候的”朋友圈“,而甚至家人的旅行照片,可以单独的分享给自己的家人圈子。我几乎找不到任何独立的代替品能够满足这些需求。更甚至你不需要为这些高清图片的存储付出任何代价,在 16MP 分辨率一下的图片完全不占用空间,而那时候的手机分辨率都还没有达到那么高。所以我也曾经关注过 Trey Ratcliff 这样的摄影师。
不知道多少人还记得 Google+ Photos 的在线编辑工具,记住这里是 Google+ Photos 而不是现在的 Google Photos,曾经的网页图片编辑工具是那么好用,就如一个在线的 Photoshop,这可是 Google+ 团队收购了专业滤镜团队 Nik Collection 之后发布的重要更新,可惜后来的更新中竟然失去了影踪。
视频聊天
说道视频聊天,很多人就会想起 Hangout,这个捆绑在 Google+ 中一同发布的聊天工具,不仅包含多人视频功能,也能够发送文字,表情,就是一个独立的 IM 服务,继承 Gtalk,能够在网页中,客户端,Gmail 等等端无痛接入,却在多年之后被 Facebook Message, Zoom 之类狠狠的甩在身后,无限唏嘘。
或许还有人曾记得 Hangout Air,在 Hangout 普通的多人视频聊天的功能上,能够实时直播自己的内容,公开的,向全世界的。这个功能甚至被 Obama 总统和教皇 Francis 使用过。但是这个功能只能在桌面端使用,当移动端视频直播的狂潮来过之后,Google 又错过了。1
评论
依稀记得 Google+ 强制安插到 YouTube, Blogger 等等平台中的情形,在 YouTube 中发布评论并分享,原本是一件很不错的,却因为 Google Push 太激进使得平台和用户都遭受了巨大损失。可惜。
Map
如果有一天在使用 Google Map 搜索一个地方的时候,发现朋友的一个好评餐厅,你是否会顺道去品尝一下,虽然 Google+ 曾经的产品中确实有点评的功能,却无奈无法继续推动。
Event
多少人还记得 Google+ 的 Event,当年和 Google Calendar 结合是多好的组织活动聚会的工具,多少次 Ingress 线下聚会通过 Event 来举办。可以对限定的圈子,或者全部关注着发布活动邀请,想要参加的人可以点击参加,那么活动的时间和地点会自动插入到参与者的 Google Calendar 中,又可惜了一个聚会神器。
想象一下没有广告的社交网络,想象一下每一个普通人都能平等交流的网站,想象一下通过同一个兴趣聚集到一起能够进行充分无障碍交流的地方,想象一下没有被算法过滤过的信息流,想象一下摄影师分享高清无损图片的社交网络,想象一下通过线上延伸到线下,真实的友谊的网络。曾经出现过,而如今却要惋惜他的消失。
期待
或许我们期待 Google+ 关闭之后,就像 Google Reader 关闭之后,源源不断的创新者涌现出来,InoReader 作为绝佳的代替品已经成为了我必备的应用,然而截至目前为止我依然还没有找到一个合适的 Google+ 代替品,FB 早已删除了所有资料,Twitter 始终无法习惯他的评论,而新出现的 Mastodon 倒是可以关注一下,分布式部署,各个节点之间也能够通信,夸张关注,甚至可以自定义 UI。而 Reddit 倒只像是论坛,Telegram 吧只是一个 IM,band.us 体验了一下觉得也不是个事。反正暂时先用回 豆瓣 好了,等找到合适的再说吧。
reference
-
https://youtu.be/edk2ZcW2GnQ ↩
Drools 语法规则
What is drools?
Drools is a business rule management system with a forward and backward chaining inference based rules engine, more correctly known as a production rule system, using an enhanced implementation of the Rete algorithm.1
基础 API
在 Drools 当中,规则的编译与运行要通过 Drools 提供的各种 API 来实现,这些 API 总体来讲可以分为三类:规则编译、规则收集和规则的执行。
在 drools 6.x 以后这些 API 都整合到 kie API 中了
KIE 定义的接口可以在 GitHub droolsjbpm-knowledge 这个项目中查看。
KnowledgeBuilder
KnowledgeBuilder 在业务代码当中整理已经编写好的规则,对这些规则文件进行编译,最终产生编译好的规则包(KnowledgePackage)给其它的应用程序使用。
KnowledgeBase
KnowledgeBase 是 Drools 提供的用来收集应用当中知识(knowledge)定义的知识库对象,在一个 KnowledgeBase 当中可以包含普通的规则(rule)、规则流 (rule flow)、函数定义 (function)、用户自定义对象(type model)等。KnowledgeBase 本身不包含任何业务数据对象,业务对象都是插入到由 KnowledgeBase 产生的两种类型的 session 对象当中,通过 session 对象可以触发规则执行或开始一个规则流执行。
StatefulKnowledgeSessions
StatefulKnowledgeSession 对象是一种最常用的与[[规则引擎]]进行交互的方式,它可以与规则引擎建立一个持续的交互通道,在推理计算的过程当中可能会多次触发同一数据集。在用户的代码当中,最后使用完 StatefulKnowledgeSession 对象之后,一定要调用其 dispose() 方法以释放相关内存资源。
public interface StatefulKnowledgeSession
extends
KieSession, KieRuntime {
KieBase getKieBase();
}
StateLessKnowledgeSession
StatelessKnowledgeSession 的作用与 StatefulKnowledgeSession 相仿,它们都是用来接收业务数据、执行规则的。事实上,StatelessKnowledgeSession 对 StatefulKnowledgeSession 做了包装,使得在使用 StatelessKnowledgeSession 对象时不需要再调用 dispose() 方法释放内存资源了
调用 execute(...) 方法会在内部实例化 StatefulKnowledgeSession 对象,添加用户数据,执行命令,调用 fireAllRules,最后自动调用 dispose().
public interface StatelessKnowledgeSession
extends
StatelessKieSession {
}
FACT 对象
Fact 是指在 Drools 规则应用当中,将一个普通的 JavaBean 插入到规则的 WorkingMemory 当中后的对象。
Drools 规则可以对 Fact 对象进行任意的读写操作,当一个 JavaBean 插入到 WorkingMemory 当中变成 Fact 之后,Fact 对象不是原来的 JavaBean 对象的 Clone,而是原来 JavaBean 对象的引用。
规则文件
一个标准的 Drools 规则文件就是一个以“.drl”结尾的文本文件。
Drools 规则文件包含一个或多个 rule 声明,每一个 rule 由一个或多个条件以及要执行的动作(Action)组成。一个规则文件还可以有 0 个或多个 import 声明,global 声明和 function 声明。
Drools 规则文件大致可以包含这些部分:
package package-name
imports
globals
functions
queries
rules
package 是必须的,除 package 之外,其它对象在规则文件中的顺序是任意的,也就是说在规则文件当中必须要有一个 package 声明,同时 package 声明必须要放在规则文件的第一行。
package
package 是一系列 rule 的一个命名空间,这个空间中所有的rule 名字都是唯一的。package-name 必须遵守 Java 命名规范。
import
Drools 文件中的 import 语句和 Java 的 import 语句类似,引入指定对象的路径及全称。
global
global 用于定义全局变量。
- 全局变量不会插入到
Working Memory - 全局变量的改变不会通知规则引擎,规则引擎不会追踪全局变量的变化
- 多个包中同时定义相同标识符的全局变量,全局变量必须是相同类型,并引用一个相同的全局值
function
function 提供了一种在规则源文件中插入语义代码的方式。在规则中使用函数的优点是可以把逻辑放在一个地方。
function String hello(String name) {
return "hello " + name + "!";
}
注意这里的,function 并不是 java 语法的一部分。Drools 支持函数的导入:
import function my.package.Foo.hello
Type declaration
规则引擎中,可以:
- 允许新的类型声明
- 允许元数据类型的声明
类型声明
declare Address
number : int
streetName : String
city : String
end
定义一个新的类型 Address, 有三个属性,每个属性的类型都是 Java 中有效的数据类型。
定义 Person
import java.util.Date
declare Person
name : String
dateOfBirth : Date
address : Address
end
定义该新类型后,Drools 会在编译期间生成对应的 Java 类字节码。
声明枚举类型
declare enum DaysOfWeek
SUN("Sunday"),MON("Monday"),TUE("Tuesday"),WED("Wednesday"),THU("Thursday"),FRI("Friday"),SAT("Saturday");
fullName : String
end
声明后可以直接应用于规则中:
rule "Test Enum Rule"
when
$p: Employee( dayOff == DaysOfWeek.MONDAY )
then
...
end
声明云数据 (metadata)
@metadata_key( metadata_value )
Rule
一条规则的大致框架包括如下几部分:
rule "name"
attributes
when
LHS
then
RHS
end
一个规则通常包括三个部分:
- 属性部分(attribute),非必须,最好写在一行,关于规则属性部分,后文有更详细的介绍
- 条件部分(LHS)
- 结果部分(RHS)
对于一个完整的规则来说,这三个部分都是可选的(可以为空),也就是说如下所示的规则是合法的:
rule "name"
when
then
end
注释
drl 文件中对规则进行注释,和 Java 一样可以使用
- 单行注释
// - 多行注释
/* xxx */
Drools 5 中定义了 hard 和 soft 关键字,Hard 关键字是保留字,不能够在规则中自定义随意使用
true
false
accumulate
collect
from
null
over
then
when
规则举例
rule "validate holiday by eval"
dialect "mvel"
when
h1 : Holiday( )
eval( h1.when == "july" )
then
System.out.println(h1.name + ":" + h1.when);
end
或者
rule "validate holiday"
dialect "mvel"
when
h1 : Holiday( `when` == "july" )
then
System.out.println(h1.name + ":" + h1.when);
end
条件部分
条件部分又被称之为 Left Hand Side,简称为 LHS。 在 LHS 当中,可以包含 0~n 个条件,如果 LHS 部分没空的话,那么引擎会自动添加一个 eval(true) 的条件,由于该条件总是返回 true,所以 LHS 为空的规则总是返回 true。LHS 部分是由一个或多个条件组成,条件又称之为 pattern(匹配模式),多个 pattern 之间用可以使用 and 或 or 来进行连接,同时还可以使用小括号来确定 pattern 的优先级。
绑定对象语法
[ 绑定变量名 ]: Object([field 约束 ])
绑定变量是可选的,如果当前规则 LHS 部分的其他规则需要使用到这个对象,可以通过为该对象设定一个绑定变量名来实现对其引用,对于绑定变量,通常在其变量名前增加 $ 符号来和 Fact 区别。field 约束表示的是对对象中 field 的约束。
比如对于该规则
rule "rule1"
when
$customer:Customer(age>20, gender=="male")
Order(customer==$customer, price>1000)
then
<action>
End
规则含义:包含两个 pattern,第一个 pattern 有三个约束,分别是:
- 对象类型必须是 Customer;
- 同时 Customer 的 age 要大于 20
- 且 gender 要是 male;
第二个 pattern 也有三个约束,分别是:
- 对象类型必须是 Order,
- 同时 Order 对应的 Customer 必须是前面的那个 Customer
- 且当前这个 Order 的 price 要大于 1000。
在这两个 pattern 没有符号连接,在 Drools 当中在 pattern 中没有连接符号,那么就用 and 来作为默认连接,所以在该规则的 LHS 部分中两个 pattern 只有都满足了才会返回 true。默认情况下,每行可以用“;”来作为结束符(和 Java 的结束一样),当然行尾也可以不加“;”结尾。
操作符
Drools 中的操作符有很多种类:
- Arithmetic operators (
+, -, *, /, %) 算数操作符 - Relational operators (
>, >=, ==, !=) 关系操作符 -
Logical operators 逻辑操作符
- conjunction (
and, &&, ",") 与 - disjunction (
or, ||) 或 - negation (
!, do not confuse with not) 取反 (!, 不要和 not 混淆)
- conjunction (
-
Drools operators (in, matches, etc…) Drools 操作符 (in, matches, 等等…)
一些操作符都非常通俗易懂,这里有几个需要特别注意
约束连接
对象内部多个约束连接,可以使用 &&, || 或者 ,(and) 。优先级 && > ||
, 与 && || 不能混用,在 && 和 || 出现的语句中不能出现 ,
比较操作符
Drools 中一共提供了 12 种类型的比较操作符,>, >=, <, <=, ==, != ,contains, not contains, memberof, not memberof, matches, not matches 。前六个比较常用,不介绍了,现在结束一下后几个。
contains 举例:
when
$order:Order();
$customer:Customer(age >20, orders contains $order);
then
System.out.println($customer.getName());
End
in 操作符
-
in 操作符是表示值在一个集合内部,集合中的数据需要单独列出
when e : Emp (deptno in (10,20))
等效于
e : Emp(deptno == 10 || deptno == 20)
e : (Emp(deptno == 10) or Emp(deptno == 20))
matches 操作符
matches 是某个字段和 Java 正则匹配
when
$customer:Customer(name matches "吴.*");
then
System.out.println($customer.getName());
end
matches 操作符匹配是否匹配 Java 正则表达式。
. 匹配单一字符
.* 匹配任何字符,包括空字符串
不匹配需要这么写
when
e: Emp(name not matches "B.*")
下面的写法是错误的!!!
when
e: Emp(name ! matches "B.*")
e: ! Emp(name matches "B.*")
操作符优先级
(nested) property access .
List/Map access [ ]
constraint binding :
multiplicative * / %
additive + -
shift << >> >>>
relational < > <= >= instanceof
equality == !=
bit-wise non-short circuiting AND &
bit-wise non-short circuiting exclusive OR ^
bit-wise non-short circuiting inclusive OR |
logical AND &&
logical OR ||
ternary ? :
Comma separated AND ,
Drools 还支持一些高级语法规则,更多可以参考这里
结果部分
Right Hand Side,又被称为结果部分,RHS,规则中 then 后面部分就是 RHS,只有在 LHS 所有条件都满足时 RHS 部分才会执行。
RHS 部分是规则真正要做的事情,将条件满足而触发的动作写在该部分中,RHS 中可以使用 LHS 中定义的绑定变量名、设置的全局变量,或者直接编写 Java 代码(需要 import 相应的类)
RHS 中,提供了对当前 Working Memory 实现快速操作的宏函数和宏定义,比如 insert/insetLogical, update 和 retract,实现对当前 Working Memory 中 Fact 对象的新增、删除或者修改。
insert
insert(new Object());
一旦调用 insert 函数, Drools 会重新与所有规则再重新匹配一次,对于没有设置 no-loop 属性为 true 的规则,如果条件满足,不管之前是否执行过都会再执行一次,这个特性不仅存在于 insert 函数,update,retract 宏函数都有该特性,所以某些情况下考虑不周可能造成死循环。
update
对 Fact 进行更新,比如更新 Fact 中的某个字段,对应的相关的 Fact 都会更新,然后会通知 Drools 引擎该修改。
retract
用来将 Working Memory 中某个 Fact 对象删除。
modify
对 Fact 对象多个属性修改,修改完成后自动更新到当前 Working Memory 中。
modify ( <fact-expression> ) {
<expression>,
<expression>,
...
}
属性部分
规则属性是用来控制规则执行的重要工具,显示地声明了对规则行为的影响。
规则的属性有 13 个
- activation-group
- agenda-group
- auto-focus
- date-effective
- date-expires
- dialect
- duration
- enabled
- lock-on-active
- no-loop
- ruleflow-group
- salience
- when
salience
salience 用来设置规则执行的优先级,salience 属性值是一个数字,数字越大优先级越高,可以是负值。salience 表示规则的优先级,值越大在激活队列中优先级越高。
- 默认情况下,规则的 salience 是 0
- type: Integer
所以不手动设置规则的 salience 属性情况下,执行的顺序是随机的。
rule "rule1"
salience 1
when
eval(true)
then
System.out.println("rule1");
End
no-loop
no-loop 属性的作用是用来控制已经执行过的规则在条件再次满足时是否再次执行。默认情况下规则的 no-loop 属性的值为 false,如果 no-loop 属性值为 true,那么就表示该规则只会被引擎检查一次。
当规则的 RHS 改变了 LHS 条件会导致该规则重新匹配执行,可以合理地使用来避免 Drools 规则进入死循环。
- 默认值:false
- type: Boolean
在上面提到的 insert 后,如果没有设置 no-loop 的规则会再检查一次。
date-effective
控制规则只有在到达指定时间后才会触发。只有当系统时间 >=date-effective 设置的时间值时,规则才会触发执行,否则执行将不执行。在没有设置该属性的情况下,规则随时可以触发,没有这种限制。
date-effective 可接受的日期格式为 “dd-MMM-yyyy”
rule "rule1"
date-effective "25-Sep-2019"
when
eval(true);
then
System.out.println("rule1 is execution!");
End
date-expires
该属性的作用与 date-effective 属性恰恰相反, date-expires 的作用是用来设置规则的有效期。如果 date-expires 的值大于系统时间,那么规则就执行,否则就不执行。
enabled
设置是否可用
dialect
该属性用来定义规则当中要使用的语言类型,目前 Drools 版本当中支持两种类型的语言:mvel 和 java,默认情况下,如果没有手工设置规则的 dialect,那么使用的 java 语言。
- type: String
想要了解 mvel 和 java 这两个方言的区别可以参考:[[Drools 规则中 mvel 和 java 的差别]],一句话总结一下就是 MVEL 是 Java 实现的一套表达式解析语言。
duration
如果设置了该属性,那么规则将在该属性指定的值之后在另外一个线程里触发。该属性对应的值为一个长整型,单位是毫秒。
rule "rule1"
duration 3000
when
eval(true)
then
System.out.println("rule thread
id:"+Thread.currentThread().getId());
end
lock-on-active
确认规则只执行一次。 将 lock-on-action 属性的值设置为 true,可能避免因某些 Fact 对象被修改而使已经执行过的规则再次被激活执行。lock-on-active 是 no-loop 的增强版属性。
一个组里面的多条规则都可以设置这个标志,当使用了这个标志的规则中的一条被成功触发后,会阻止其他规则的触发。
- lock-on-active 属性默认值为 false
- type: Boolean
不管何时 ruleflow-group 和 agenda-group被激活,只要其中的所有规则将 lock-on-active 设置为 true,那么这些规则都不会再被激活。
宏函数 insert, update, retract 都可以对 fact 进行操作,这些动作都可以导致 rule 重新匹配。
activation-group
该属性的作用是将若干个规则划分成一个组,用一个字符串来给这个组命名,这样在执行的时候,具有相同 activation-group 属性的规则中只要有一个会被执行,其它的规则都将不再执行。
- type: String
在一组具有相同 activation-group 属性的规则当中,只有一个规则会被执行,其它规则都将不会被执行。当然对于具有相同 activation-group 属性的规则当中究竟哪一个会先执行,则可以用类似 salience 之类属性来实现。
rule "rule1"
activation-group "test"
when
eval(true)
then
System.out.println("rule1 execute");
end
rule "rule 2"
activation-group "test"
when
eval(true)
then
System.out.println("rule2 execute");
End
rule1 和 rule2 这两个规则因为具体相同名称的 activation-group 属性,所以它们只有一个会被执行。
agenda-group
Agenda Group 是用来在 Agenda 的基础之上,对现在的规则进行再次分组,具体的分组方法可以采用为规则添加 agenda-group 属性来实现。
- 默认值: MAIN
- type: String
agenda-group 属性的值也是一个字符串,通过这个字符串,可以将规则分为若干个 Agenda Group,默认情况下,引擎在调用这些设置了 agenda-group 属性的规则的时候需要显示的指定某个 Agenda Group 得到 Focus(焦点),这样位于该 Agenda Group 当中的规则才会触发执行,否则将不执行。
rule "rule1"
agenda-group "001"
when
eval(true)
then
System.out.println("rule1 execute");
end
rule "rule 2"
agenda-group "002"
when
eval(true)
then
System.out.println("rule2 execute");
End
java 代码
//getSession 获取 KieSession 的方法自己写的。
KieSession ks = getSession();
// 设置 agenda-group 的 auto-focus 使其执行
ks.getAgenda().getAgendaGroup("group1").setFocus();
当这个 group 被 setFocus 的时候,会将整个组压入栈中,执行的时候再取出来。
在 Drool 的规则 RHS 中还可以
kcontext.getKieRuntime().getAgenda().getAgendaGroup("Route-AgeRange").setFocus();
auto-focus
在已设置了 agenda-group 的规则上设置该规则是否可以自动独取 Focus,如果该属性设置为 true,那么在引擎执行时,就不需要显示的为某个 Agenda Group 设置 Focus,否则需要。
- 默认:false
- type: Boolean
对于规则的执行的控制,还可以使用 Agenda Filter 来实现。在 Drools 当中,提供了一个名为 org.drools.runtime.rule.AgendaFilter 的 Agenda Filter 接口,用户可以实现该接口,通过规则当中的某些属性来控制规则要不要执行。org.drools.runtime.rule.AgendaFilter 接口只有一个方法需要实现,方法体如下:
public boolean accept(Activation activation);
在该方法当中提供了一个 Activation 参数,通过该参数我们可以得到当前正在执行的规则对象或其它一些属性,该方法要返回一个布尔值,该布尔值就决定了要不要执行当前这个规则,返回 true 就执行规则,否则就不执行。
在引擎执行规则的时候,我们希望使用规则名来对要执行的规则做一个过滤,此时就可以通过 AgendaFilter 来实现,示例代码既为我们实现的一个 AgendaFilter 类源码。
import org.drools.runtime.rule.Activation;
import org.drools.runtime.rule.AgendaFilter;
public class TestAgendaFilter implements AgendaFilter {
private String startName;
public TestAgendaFilter(String startName){
this.startName=startName;
}
public boolean accept(Activation activation) {
String ruleName=activation.getRule().getName();
if(ruleName.startsWith(this.startName)){
return true;
}else{
return false;
}
}
}
过滤方法是规则名的前缀,通过 Activation 得到当前的 Rule 对象,然后得到当前规则的 name,再用这个 name 与给定的 name 前缀进行比较,如果相同就返回 true,否则就返回 false。
java:
TestAgendaFilter filter = new TestAgendaFilter("activation")
int count = ks.fireAllRules(filter)
ruleflow-group
在使用规则流的时候要用到 ruleflow-group 属性,该属性的值为一个字符串,作用是用来将规则划分为一个个的组,然后在规则流当中通过使用 ruleflow-group 属性的值,从而使用对应的规则。
- type: String
简单的来说,只有当被 ruleflow-group 圈定的组被激活时,ruleflow-group 中的规则才能被命中。
函数
代码块,封装多个规则中可能共享的相同规则代码
function void/Object functionName(Type arg ...) {
}
使用定义的 function,则需要 import function,通过 import 语句,实现将 Java 类中静态方法引入到一个规则文件中,使得该文件中规则可以像普通 Drools 函数一样来使用 Java 类中的静态方法
import function test.RuleTools.printInfo;
调用
RuleTools.printInfo(...)
reference
- https://training-course-material.com/training/Category:Drools
- https://docs.jboss.org/drools/release/5.2.0.CR1/drools-expert-docs/html/ch05.html
- https://docs.jboss.org/drools/release/7.35.0.Final/drools-docs/html_single/#_droolslanguagereferencechapter
- http://support.streamx.co/intro/basic-drools-rule-language-syntax-cont
- https://shift8.iteye.com/blog/1915351
- http://holbrook.github.io/2012/12/06/rule_language.html
- https://blog.csdn.net/u012373815/article/details/53872025
JSON 反序列化重命名
Java 中有很多 JSON 相关的类库,项目中也频繁的使用 Jackson, fastjson, gson 等等类库。不过这些类库在反序列化 JSON 字符串到 Object 并且进行重命名字段的方法都不太一致,这里就列一下做个参考。
假设有原始字符串
String originStr = "{\"familyName\":\"Ein\",\"age\":20,\"salary\":1000.0}";
反序列化到类 Employee 上。
GSON
类定义
@Data
public class EmployeeGson {
@SerializedName(value = "fullname", alternate = {"Name", "familyName"})
private String name;
private int age;
@SerializedName("salary")
private float wage;
}
测试方法
@Test
public void testRenameFieldGson() {
String originStr = "{\"familyName\":\"Ein\",\"age\":20,\"salary\":1000.0}";
EmployeeGson employee = new Gson().fromJson(originStr, EmployeeGson.class);
System.out.println(employee);
}
Fastjson
类
@Data
public class EmployeeFastjson {
@JSONField(name = "familyName")
private String name;
private int age;
@JSONField(name = "salary")
private float wage;
}
测试方法
@Test
public void testRenameFieldFastjson() {
String originStr = "{\"familyName\":\"Ein\",\"age\":20,\"salary\":1000.0}";
EmployeeFastjson employee = JSON.parseObject(originStr, EmployeeFastjson.class);
System.out.println(employee);
}
Jackson
@Data
public class EmployeeJackson {
@JsonProperty("familyName")
private String name;
private int age;
@JsonProperty("salary")
private float wage;
}
测试方法
@Test
public void testRenameFieldJackson() throws IOException {
String originStr = "{\"familyName\":\"Ein\",\"age\":20,\"salary\":1000.0}";
EmployeeJackson employeeJackson = new ObjectMapper()
.readValue(originStr, EmployeeJackson.class);
System.out.println(employeeJackson);
}
Function 计算
函数计算,阿里云叫做 Function Compute,Aws 叫做 lambda 函数,GCP 叫做 Cloud Functions,各家都有各家的产品。就如同 AWS 页面介绍的那样,函数计算是一个无服务计算,可以用代码来响应事件并自动管理底层计算资源,比如通过 Amazon Gate API 发送 HTTP 请求,在 S3 桶中修改对象等等。
Serverless
抽象的 Serverless 很难概括,不过 Serverless 也经常被人叫做 Function as a Server(FaaS),这就比较好理解了,比如最常见的存储服务,原来的方式是用户租用云服务器,这种方式需要用户自行部署存储服务,磁盘上的数据也不能共享,于是后来发展出来对象存储,文件存储,消息服务等等,这些服务不再有机器的概念,用户可以轻松的扩容和负载均衡,通过平台提供的 API 进行数据的读写,共享。按照实际存储的数量和访问次数付费,这种就是所谓的 Serverless。
FaaS 的特征就是时间驱动,细粒度,弹性收缩,无需管理服务器等底层资源。
拆分微服务有三个考量,组织结构(参考康威定律),运维发布频率(比如将每周发布两次的服务与每两个月发布一次的服务进行拆分)和逻辑调用频度(将高频调用逻辑和低频调用逻辑分开,在 Serverless 架构下能够进一步降低成本)。
Serverless 适用的两大场景
- 应用负载有显著的波峰波谷
- 典型用例 - 基于事件的数据处理
函数计算的优势
- 不需要管理服务器等基础设施,开发者只需要关注于逻辑开发
- 事件驱动
- 可以快速扩容
- 按需付费
- 将监控,日志,报警等等繁琐的事务隔离开
reference
文章分类
最近文章
- AI Shell 让 AI 在命令行下提供 Shell 命令 AI Shell 是一款在命令行下的 AI 自动补全工具,当你想要实现一个功能,敲一大段命令又记不住的时候,使用自然语言让 AI 给你生成一个可执行的命令,然后确认之后执行。
- 最棒的 Navidrome 音乐客户端 Sonixd(Feishin) Sonixd 是一款跨平台的音乐播放器,可以使用 [[Subsonic API]],兼容 Jellyfin,[[Navidrome]],Airsonic,Airsonic-Advanced,Gonic,Astiga 等等服务端。 Sonixd 是一款跨平台的音乐播放器,可以使用 [[Subsonic API]],兼容 Jellyfin,[[Navidrome]],Airsonic,Airsonic-Advanced,Gonic,Astiga 等等服务端。
- 中心化加密货币交易所 Gate 注册以及认证 Gate.io 是一个中心化的加密货币交易所。Gate 中文通常被称为「芝麻开门」,Gate 创立于 2013 年,前身是比特儿,是一家致力于安全、稳定的数字货币交易所,支持超过 1600 种数字货币的交易,提供超过 2700 个交易对。
- 不重启的情况下重新加载 rTorrent 配置文件 因为我在 Screen 下使用 rTorrent,最近经常调试修改 rtorrent.rc 配置文件,所以想要找一个方法可以在不重启 rTorrent 的情况重新加载配置文件,网上调查了一下之后发现原来挺简单的。
- Go 语言编写的网络穿透工具 chisel chisel 是一个在 HTTP 协议上的 TCP/UDP 隧道,使用 Go 语言编写,10.9 K 星星。