Ubuntu 从 16.04 升级 18.04
经常看到的 Ubuntu 16.04 或者 18.04 都是 Ubuntu 长期支持版本
A Long Term Support release or LTS release, means that Ubuntu will support the version for five years.
如果要从 16.04 升级到 18.04 包括两个部分,一是将当前安装的程序及 lib 升级到 18.04 兼容的版本,另外一个就是将系统升级到 18.04.
sudo apt update && sudo apt upgrade
sudo apt autoremove
sudo apt dist-upgrade
运行 apt dist-upgrade 会升级所有 packeges 到想要升到的 Ubuntu 版本,而 sudo do-release-upgrade 会将 Ubuntu 升级到新版本。大部分情况下不需要手动触发 sudo apt dist-upgrade,因为在运行 sudo do-release-upgrade 会自动先运行 dist-upgrade 。预先将所有的应用程序都更新到最新版本避免兼容性问题。
最后进行升级 Do upgrade
sudo do-release-upgrade
要注意該命令无法回滚,做好相应的备份工作,或者知道如何处理失败。
Install Cinnamon
sudo add-apt-repository ppa:embrosyn/cinnamon
sudo apt update && sudo apt install cinnamon
Remove
sudo apt-get install ppa-purge
sudo ppa-purge ppa:embrosyn/cinnamon
升级到非 LTS
编辑 /etc/update-manager/release-upgrades 并设置
Prompt=normal
然后再运行 sudo do-release-upgrade
记一次 fail2ban 启动失败
前两天重启服务器之后发现 fail2ban 启动失败,出现如下错误:
/etc/init.d/fail2ban restart
[....] Restarting fail2ban (via systemctl): fail2ban.service
Job for fail2ban.service failed because the control process exited with error code. See "systemctl status fail2ban.service" and "journalctl -xe" for details.
failed!
检查日志
journalctl -xe
查看具体错误
/usr/bin/fail2ban-client -v -v start
看到结果:
fail2ban.service: Failed with result 'start-limit-hit'.
具体错误一目了然。其实重要的就是 Debug 的内容。
Python 为什么需要 with 语法
Python 中的 with 语法经常被用来在管理资源的访问和清理中,常见的场景有文件的使用和关闭,锁的获取和释放等等。
with open("file.txt") as file:
data = file.read()
with 语法特别容易联想起 Java 中的 try-with-resources AutoCloseable,同样实现资源的自动释放。
基本格式
从基本使用开始了解 with,with 的结构如下:
with context_expression [as target(s)]:
content
With 工作原理
如果要聊 with 的实现,就不得不提到 Python 中的上下文管理:
with 语句执行过程:
- 执行 context_expression 生成上下文管理器 context_manager
- 调用 context manager 的 enter() 方法,如果使用 as 子句,将 enter 方法返回值赋值给 target(s)
- 执行 with-body
- 不管是否异常,执行 exit() 方法,exit() 方法负责清理工作
-
出现异常时, exit(type, value, traceback) 返回 False,重新抛出异常,让 with 之外的语句逻辑来处理异常;如果返回 True,这忽略异常,不再对异常处理
class Dummy: def enter(self): print “in enter” return “Foo” def exit(self, exc_type, exc_val, exc_tb): print “in exit”
def get_dummy(): return Dummy()
with get_dummy() as dummy: print “Dummy: “, dummy
除了上面这种实现 __enter__ 和 __exit__ 方法来生成 context manger 的方式,还可以使用 contextlib
from contextlib import contextmanager
@contextmanager
def open_file(name, mode):
f = open(name, mode)
yield f
f.close()
然后使用:
with open_file('file.txt', 'w') as f:
f.write("Hello, world.")
reference
Substratum Android 上的主题引擎
Substratum 是一款 Android 上的主题工具,能够不用 root 来达到系统级主题修改。并且在该工具下有一群爱好者和社区开发了无数的美观且实用的主题。Substratum 开始于以前非常流行的 CyanogenMod, Cyanogen 内置了该主题引擎,并使得修改主题异常简单。但是不幸的是,Cyanogen 没有继续下去, 但是 Substratum 死灰复燃。最初的时候 Substratum 还需要 Root 来使用,但是 Android Oreo 之后就可以不依赖于 Root 了。
Installation
如果想要正式版从 Play Store 下载:
如果要开发版可以在 Telegram channel 下载
Substratum Themes
Substratum 有非常多著名的主题,可以从 Play Store 搜索,或者到 xda 寻找
- Swift Black
- Flux White
- Victory
- VaLeRie youtube
- Transparent
Conclusion
最后,Swift theme 看起来不错,1.99 刀还可以,果断购入。
reference
Flask Babel 使用
Flask babel 是 Flask 的语言扩展,允许非常简单的方式让 Flask 支持多语言。
Installation
pip install flask-babel
安装时会安装依赖
- Babel, Python 国际化
- pytz 时区
- speaklater 辅助工具集
Configuration
在 python 文件中要使用多语言的文字时引入
from flask_babel import gettext
比如
gettext('author')
在 html 模板文件中
<pre>{\% trans \%\}Submit{\% endtrans \%\}</pre>
在项目目录中新建 babel.cfg
[python: **.py]
[jinja2: **/templates/**.html]
extensions=jinja2.ext.autoescape,jinja2.ext.with_,webassets.ext.jinja2.AssetsExtension
然后生成模板文件
pybabel extract -F babel.cfg -o translations/messages.pot .
文件 messages.pot 就是翻译模板文件
然后生成中文翻译文件
pybabel init -i translations/messages.pot -d translations -l zh_Hans_CN
复杂的项目可以借助 GUI 工具 poedit
编辑后编译
pybabel compile -d translations
如果更新了项目文件,新增了需要翻译的字段,在生成 messages.pot 之后可以使用如下方法将更新合并到需要翻译的文件中
pybabel update -i translations/messages.pot -d translations
Flask Babel 和 Flask WTF 一起使用
如果直接定义时使用 gettext 可能无法使用 babel 的翻译,需要使用 lazy_gettext('').
class LoginForm(Form):
username = TextField(gettext(u'Username'), validators=[validators.Required()])
Notice
translations 位置
translations 目录必须是跟你 Flask 的 app 应用对象在同一目录下,如果你的 app 对象是放在某个包里,那 translations 目录也必须放在那个包下。
如果使用自定义的目录那么,需要自己手动指定目录名字。
app.config['BABEL_TRANSLATION_DIRECTORIES'] = 'translation'
Other
可以使用 pybabel --list-locales 来查看本机语言编码。
reference
Android 内核中的 CPU 调频
CPU 调频模块主要分为三块:
- CPUFreq 核心模块,核心模块主要是公共的 API 和逻辑
- CPUFreq 驱动,处理和平台相关的逻辑,设置 CPU 频率和电压
- CPUFreq governor,频率控制器,CPU 调频的策略,CPU 在什么负载,什么场景下使用多少频率
最后第三部分 governor 也是本文重点。传统的 CPU governor 选择,以 Performance 和 Powersave 举例,就是一个让 CPU 跑在最高频率,一个让 CPU 跑在最低频率,所有动作都在初始化时设置。
调频器策略
OnDemand, Conservative 或者 Interactive 内部都含有一个计时器,每隔一段时间就会去对 CPU 负载采样。这是一种基于负载采样的调频器策略。
而另外一种策略是,从内核调度器中直接取得 CPU 负载,这就是基于调度器的 governor。基于调度器的 CPU 调频策略会通过 PELT(per entity load tracking) 来统计各个任务的负载,映射到一个范围。内核中负载均衡通过这些统计值来平衡 CPU 之间的任务,基于调度器的 governor 就是通过把各个 CPU 负载映射到 CPU 频率来完成调频动作,负载越高,CPU 频率也越高。内核社区中有个方案:
- ARM 和 Linaro 主导项目 cpufreq_sched
- Intel 主导的 shedutil
CPU 调频器
OnDemand
OnDemand 是一个比较老的 linux kernel 中的调频器,当负载达到 CPU 阈值时,调频器会迅速将 CPU 调整到最高频率。由于这种偏向高频的特性,使得它有出色的流动性,但与其他调频器相比可能对电池寿命产生负面影响。OnDemand 在过去通常被制造商选用,因为它经过了充分测试并且很可靠,但已经过时,并且正在被 Google 的 interactive 控制器取代。
对于 OnDemand 会启用计时器,定时去计算 CPU 负载,当负载超过 80% 时,OnDemand 会将 CPU 频率调到最高。
OndemandX
基本上是拥有 暂停、唤醒配置的 OnDemand,没有在 OnDemand 上做更多的优化。
Performance
Performance 调频器将手机的 CPU 固定在最大频率。
Powersave
与 Performance 调频器相反,Powersave 调频器将 CPU 频率锁定在用户设置的最低频率。
Conservative
该调速器将手机偏置为尽可能频繁地选择尽可能低的时钟速率。换句话说,在 Conservative 调频器提高 CPU 时钟速度之前,必须在 CPU 上有更大且更持久的负载。根据开发人员实现此调频器的方式以及用户选择的最小时钟速度,Conservative 调频器可能会引入不稳定的性能。另一方面,它可以有利于电池寿命。
Conservative 调频器也经常被称为“slow OnDemand”。原始的、未经修改的 Conservative 是缓慢并且低效的。较新版本和修改版本 Conservative(来自某些内核)响应速度更快,并且几乎可以用于任何用途。
和 OnDemand 一样,会通过定时器来检测 CPU 负载,对 Conservative ,当负载较高时,会以 5% 步增调高频率,当负载低于一个值时,以 5% 步伐递减。
Userspace
这种调频器在移动设备中极为罕见,它允许用户执行的任何程序设置 CPU 的工作频率。此调频器在服务器或台式 PC 中更常见,其中应用程序(如电源配置文件应用程序)需要特权来设置 CPU 时钟速度。
Min Max
Min Max 调频器会根据负载选择最低或者最高的频率,而不会使用中间频率。
Interactive
Interactive 会平衡内核开发人员(或用户)设置的时钟速度。换句话说,如果应用程序需要调整到最大时钟速度(CPU 100%负载),用户可以在调频器开始降低 CPU 频率之前执行另一个任务。由于此计时器,Interactive 还可以更好地利用介于最小和最大 CPU 频率之间的中间时钟速度。它的响应速度明显高于 OnDemand,因为它在调整到最大频率时速度更快。
Interactive 还假设用户打开屏幕之后很快就会与其设备上的某个应用程序进行交互。 因此,打开屏幕会触发最大时钟速度的斜坡,然后是上述的定时器行为。
Interactive 是当今智能手机和平板电脑制造商的首选默认调频器。
InteractiveX
由内核开发人员“Imoseyon”创建,InteractiveX 调频器主要基于交互式调频器,增强了调整计时器参数,以更好地平衡电池与性能。但是,InteractiveX 调频器的定义功能是在屏幕关闭时将 CPU 频率锁定到用户最低定义的速度。
Smartass
基于 Interactive,表现和之前的 minmax 一致,smartass 相应更快。电池寿命很难精确量化,但它确实在较低频率下可以使用更长。
当睡眠时调整到 352Mhz ,Smartass 还会限制最大频率(或者如果您设置的最小频率高于 352,它将限制到您设定的最小频率)。
该调频器会在屏幕关闭时缓慢的降低频率,甚至它也可以让手机 CPU 频率降至一个让手机无法正常使用的值(如果最小频率没有设置好的话)。
SmartassV2
从 Erasmux 中而来的 Version 2 版本,该调频器的目标是“理想的频率”,并且更加积极地向这个频率增加,并且在此之后不那么激进。它在屏幕开启或者关闭时使用不同的频率,即 awake_ideal_freq 和 sleep_ideal_freq。 当屏幕关闭时,此调频器非常快地降低 CPU(快速达到 sleep_ideal_freq )并在屏幕开启时快速向上调整到 awake_ideal_freq。 屏幕关闭时,频率没有上限(与 Smartass 不同)。因此,整个频率范围可供调频器在屏幕开启和屏幕关闭状态下使用。这个调频器的主打功能是性能和电池之间的平衡。
Scary
Scary 基于 Conservative 并增加了一些 smartass 的特征,它相应地适用于 Conservative 的规则。所以它将从底部开始,采取一个负载样本,如果它高于上限阈值,一次只增加一个梯度,并一次减少一个。 它会自动将屏幕外的速度限制为内核开发人员设置的速度,并且仍然会根据保守法律进行调整。 所以它大部分时间都花在较低的频率上。 这样做的目的是通过良好的性能获得最佳的电池寿命。
schedutil
schedutil 是最新版本 Linux 内核(4.7+)中的 EAS 调控器,旨在更好地与 Linux 内核调度程序集成。它使用内核的调度程序来接收 CPU 利用率信息并根据此输入做出决策。作为结果,schedutil 可以比依赖于定时器的 Interactive 等常规调控器更快,更准确地响应 CPU 负载。
更多的 governor 可以访问下方的 xda 链接。
reference
Vim 插件之注释
Vim 下的注释插件有很多个
- tpope/vim-commentary
- scrooloose/nerdcommenter
- tomtom/tcomment_vim
这三个插件各有特色。
QQ 音乐 qmcflac 文件解密
首先说重点,代码来自:
Build
按照项目主页的方式 Build,生成 decoder 二进制可执行文件即可。
这个二进制可以实现 qmc0、qmc3、qmcflac 格式转换,生成普通未加密的 mp3, 或者 flac 文件。
Result
运行

结果

外延
C++ 实现的另外一个版本
如果熟悉 Java 也可以参考这个项目
如果熟悉 C# 那么可以看看这个项目
Linnx Mint 上使用触摸板手势
都知道 Mac 上的触摸板非常好用,简单的手势就能实现十几种操作,从单指,双指,三指,到四指,甚至五指,从轻点,按压,到滑动,到捏合,组合起来能实现非常多的操作。
Mac 下手势
通过不同的组合可以得到非常多的功能。一些比较重要的操作列在了下面。
单指
一个手指轻轻点击,可以选中目标;
双指
- 两个手指同时点击,鼠标右键功能;
- 两个手指轻点,Smart zoom,可以快速缩放;
- 两个手指分开或捏合,可以放大缩小图片、网页等内容;
- 两个手指上下拖移滑动,即可实现翻页;
- 两个手指旋转,可以旋转图片等对象;
- 两个手指从触控板右侧边缘向左滑动,可以调出通知窗口;
- 两个手指在网页中左右滑动,可以倒退或前进网页;
三指
- 三个手指可以调用 Look Up
- 三个手指左右滑动,可以在全屏应用桌相互切换;
- 三个手指向上滑动,可以打开所有正在使用的软件窗口;
- 三个手指向下滑动,可以打开同一个软件的不同窗口;
四指
- 四个手指同时捏合,可以调出应用程序窗口;
- 四个手指同时张开,可以显示桌面;
Linux 下手势
日常使用 Linux Mint 对手势要求倒也没有那么高,很多上面列举的功能都能用快捷键来实现,比如查词,我就是用 GoldenDict 的全局快捷键 Ctrl+C Ctrl+C,不过倒是要事先选中。比如切换 Workspace,我是用 Alt + 1/2/3/4 来控制的,其他切换应用倒也都有对应的快捷键,不过有时候确实感觉到 Mac 上触摸板在浏览网页时非常舒服,虽然我用 Vimium 映射了一些快捷键,H/L 但有时候就是没触摸板方便。
准备工作
安装必要的工具
第一步安装必要的依赖:
sudo apt install python3 python3-setuptools python3-gi libinput-tools python-gobject xdotool wmctrl
将当前用户加入 input 用户组:
sudo gpasswd -a $USER input
安装 libinput-gestures
然后安装 libinput-gestures
需要到 GitHub 项目页面手工安装 libinput-tools。
git clone https://github.com/bulletmark/libinput-gestures.git
cd libinput-gestures
sudo make install (or sudo ./libinput-gestures-setup install)
安装后执行
libinput-gestures-setup autostart
libinput-gestures-setup start
默认的手势配置在 /etc/libinput-gestures.conf 下,如果要创建自定义的配置,可以将配置内容拷贝到 ~/.config/libinput-gestures.conf 然后编辑该文件。更多 libinput-gestures 的说明可以参考 GitHub 页面
安装 GUI 配置
再安装 gestures 图形化安装界面
git clone https://gitlab.com/cunidev/gestures.git
cd gestures
sudo python3 setup.py install
然后从菜单中搜索 gestures 就能打开。
当然如果想用配置文件来配置,直接编辑 ~/.config/libinput-gestures.conf 文件也可以。
配置
Gestures 实现的强大功能都依赖于 Cinnamon 中非常丰富的快捷键功能,在设置中能看到非常丰富的快捷键设置,在此定义好快捷键就能在 xdotool 中使用。Linux Mint 默认的快捷键可以在此查看
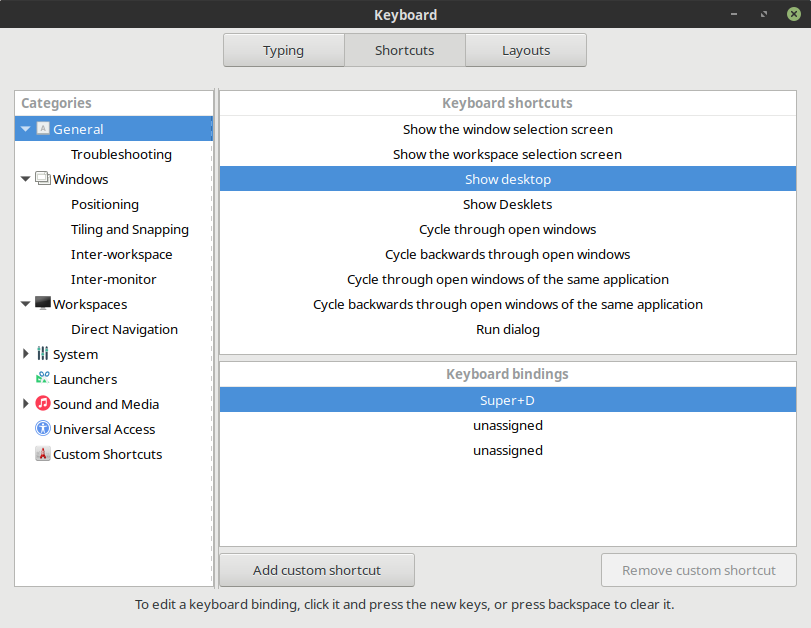
折腾一番后可以实现这些功能。
三指上滑显示所有打开的窗口
Cinnamon 中 Toggle Scale view (display all windows on current Workspace) 的快捷键是 Ctrl + Alt + Down,所以:
xdotool key Ctrl+Alt+Down
三指下滑切换桌面与当前应用
Cinnamon 的桌面我的快捷键是 Super+d 来显示桌面,所以可以设置:
xdotool key super+d
三指切换工作区
xdotool key Ctrl+Alt+Left
xdotool key Ctrl+Alt+Right
其他组合同理。
更多的按键代码可以在这里 看到。
Extend
外延,如果喜欢使用鼠标手势,Linux 下可以尝试一下 EasyStroke,个人不太喜欢使用鼠标,所以就暂时列在这里,暂不使用。
reference
Vim 插件之全局搜索:ack.vim
这篇文章看开始陆陆续续记录一下用过的 Vim Plugin,虽然有些一直也在用但从没有好好整理过,正好这篇开一个计划吧。
Ack.vim 在 vim 中使用 ack 或者 ag 来搜索,通过 Quickfix 来提供所搜结果
首先放上链接
我使用 Vundle 管理,安装更新就不展开,这里重点介绍一下该插件。这里需要注意 ack.vim 需要依赖 ack >= 2.0 及以上版本。
Installation
brew install the_silver_searcher
sudo apt install silversearcher-ag
在 ~/.vimrc 中 Vundle 安装
Plugin 'mileszs/ack.vim'
let g:ackprg = 'ag --nogroup --nocolor --column'
Introduction
ack.vim 的功能是给 Vim 提供 ack 的功能,可以在编辑器中调用 ack 工具来进行搜索,并友好的展示。
Usage
在 Vim 中直接
:Ack [options] {pattern} [{directories}]
说明:
- 默认情况下会递归搜索当前目录
- pattern 支持正则
搜索的结果会显示在窗口中,显示的格式是文件名,内容在文件中的行数以及内容。在该窗口中回车 Enter 会直接跳到该文件中。
? a quick summary of these keys, repeat to close
o to open (same as Enter)
O to open and close the quickfix window
go to preview file, open but maintain focus on ack.vim results
t to open in new tab
T to open in new tab without moving to it
h to open in horizontal split
H to open in horizontal split, keeping focus on the results
v to open in vertical split
gv to open in vertical split, keeping focus on the results
q to close the quickfix window
Config
" ack.vim
" 使用 leader + a search
cnoreabbrev Ack Ack!
nnoremap <Leader>a :Ack!<Space>
if executable('ag')
let g:ackprg = 'ag --vimgrep --nogroup --column'
endif
" 高亮搜索关键词
let g:ackhighlight = 1
更多可以使用 :help ack 来查看
更多可以参考我的 dotfiles
reference
文章分类
最近文章
- AI Shell 让 AI 在命令行下提供 Shell 命令 AI Shell 是一款在命令行下的 AI 自动补全工具,当你想要实现一个功能,敲一大段命令又记不住的时候,使用自然语言让 AI 给你生成一个可执行的命令,然后确认之后执行。
- 最棒的 Navidrome 音乐客户端 Sonixd(Feishin) Sonixd 是一款跨平台的音乐播放器,可以使用 [[Subsonic API]],兼容 Jellyfin,[[Navidrome]],Airsonic,Airsonic-Advanced,Gonic,Astiga 等等服务端。 Sonixd 是一款跨平台的音乐播放器,可以使用 [[Subsonic API]],兼容 Jellyfin,[[Navidrome]],Airsonic,Airsonic-Advanced,Gonic,Astiga 等等服务端。
- 中心化加密货币交易所 Gate 注册以及认证 Gate.io 是一个中心化的加密货币交易所。Gate 中文通常被称为「芝麻开门」,Gate 创立于 2013 年,前身是比特儿,是一家致力于安全、稳定的数字货币交易所,支持超过 1600 种数字货币的交易,提供超过 2700 个交易对。
- 不重启的情况下重新加载 rTorrent 配置文件 因为我在 Screen 下使用 rTorrent,最近经常调试修改 rtorrent.rc 配置文件,所以想要找一个方法可以在不重启 rTorrent 的情况重新加载配置文件,网上调查了一下之后发现原来挺简单的。
- Go 语言编写的网络穿透工具 chisel chisel 是一个在 HTTP 协议上的 TCP/UDP 隧道,使用 Go 语言编写,10.9 K 星星。