GraphQL 使用
很多人都知道 GraphQL 起源于 Facebook,但是似乎很少中文材料提到 GraphQL 出现的契机,我在看完这个纪录片 之后才对 GraphQL 的出现有更加深刻的了解。都知道当年 Facebook 的移动客户端都是网页,随着移动互联网发展,Facebook 网页实现的客户端性能和体验受到非常严重的影响,所以后来不得不去做原生的应用。那么这个时候就遇到了一个问题,原来直接使用网页,那么不同客户端用的接口都是给网页用的,最多做一下屏幕的适配,但是如果使用原生的应用,那么必然会需要设计不同的 API,而 Facebook 的工程师发现,对于复杂的 Feed 流,评论等等,用 RESTful 接口将是一个灾难,所以一帮人开始设计一种查询语言,这就是后来的 GraphQL。也应该纠正一下 Facebook 那帮工程师,只是开源了一份设计和一份实现,但他们万万没有想到开源社区的力量,就像片中 Nick Schrock 说的那样,他低估了社区的力量,在短短的几个月,几年时间中,GraphQL 就已经有了非常多语言的支持,周边应用也非常丰富。原来在脑海里的想法,都没有到生产环境中用过,就这样在所有社区的人的努力下成为了改变这个行业的一部分。
在了解 GraphQL 的过程中,看到一个非常有意思的比喻,经常有人会问起 GraphQL 和 RESTful 接口的区别,如果用去餐厅吃放,自助餐或者点餐来比喻,那么 GraphQL 就像是自助餐,你想要吃什么去餐盘中自己选择,而 RESTful 就像是点菜,需要看菜单,然后根据菜单选择。虽然两者都能吃饱,但是使用感受完全不同。1 当然这篇文章就不再继续讲 GraphQL 是什么,有什么用了,之前的 文章 也列了很多资料,差不多可以了解到它的具体使用场景了。这篇文章重点在于怎么把 GraphQL 用到实际项目中。
GitHub 上的 awesome-graphql 项目列举了太多的开源实现,从 c++, java, 到 python, nodejs, ruby 等等,这里我就选择上手最快的 python 更具体一些是 Django 来体验一下 GraphQL 和 Django 结合的效果。
先放上代码:
原始项目有些时间了,所以更新了一下,加了一些其他特性。
Python
主要借用的是这个项目:
Django 支持 https://github.com/graphql-python/graphene-django/
查询 Query
GraphQL 的查询语法。
Field
最常见的查询,请求方根据 Schema 定义结构,查询:
query {
allPeople {
id
username
}
}
结果和查询结构相同,包裹在 data 结构中:
{
"data": {
"allPeople": [
{
"id": "1",
"username": "steve"
},
{
"id": "2",
"username": "aholovaty"
},
{
"id": "3",
"username": "swillison"
},
{
"id": "4",
"username": "gvr"
},
{
"id": "5",
"username": "admin"
}
]
}
}
GraphQL 的接口是有类型定义的,对于上面的查询可以总结出
type RootQuery {
allPeople: Person
}
type Person {
id: int
username: String
}
条件查询 Arguments
官方的说法 叫做 Arguments,参数化请求。
比如查询条件为 id 为 5 的用户信息
query {
person(id: "5") {
id
username
email
}
}
结果是
{
"data": {
"person": {
"id": "5",
"username": "admin",
"email": "i@gmail.com"
}
}
}
结构
type RootQuery {
person(id: int) : Person
}
GraphQL 可以有不同的参数类型,这取决于你的类型定义,Schema 定义。2 并且你可以自定义你的参数类型,只要你能够序列化该参数,这就使得 GraphQL 扩展性大大增强。
Aliases
没有看到官方的翻译,暂且称之为“别名”好了 [^aliases],某些情况下想要重写结果的 KEY,可以使用改方式来实现。
假如查询的时候要查两个用户的信息
query {
person(id: "5") {
id
username
email
},
person(id: "4") {
id
username
email
}
}
这么查肯定是会返回两个 person 的 key 的 JSON,那么就会有问题,GraphQL 允许我们重命名
query {
p5: person(id: "5") {
id
username
email
},
p4: person(id: "4") {
id
username
email
}
}
返回值是这样的:
{
"data": {
"p5": {
"id": "5",
"username": "admin",
"email": "i@gmail.com"
},
"p4": {
"id": "4",
"username": "gvr",
"email": "gvr@dropbox.com"
}
}
}
[^Aliases](http://graphql.org/learn/queries/#aliases)
Fragments
Fragments Android 里面也用了这个名词,我也不知道怎么翻译,暂且叫做“片段”好了,为什么要有 Fragments 呢? 就是因为要重用,看到上面请求两个用户的 Query 语句了吗?其中每个用户都想要请求其 id, username, email,这些参数是不是每次都要手写,假如这个 Person 信息不仅包含着三个,还有很多,假如不止请求两个用户信息,难道还要复制 N 遍,这显然是不合理的,所以 GraphQL 引入了 Fragments 概念,可以定义片段,然后再复用。
{
p4: person(id: "4") {
...personFields
},
p5: person(id: "5") {
...personFields
}
}
fragment personFields on PersonType {
id
username
email
fullName
firstName
lastName
friends {
id
username
}
}
结果就是对应的
{
"data": {
"p4": {
"id": "4",
"username": "gvr",
"email": "gvr@dropbox.com",
"fullName": "Guido van Rossum",
"firstName": "Guido",
"lastName": "van Rossum",
"friends": [
{
"id": "2",
"username": "aholovaty"
},
{
"id": "3",
"username": "swillison"
}
]
},
"p5": {
"id": "5",
"username": "admin",
"email": "i@gmail.com",
"fullName": " ",
"firstName": "",
"lastName": "",
"friends": []
}
}
}
Use Variables in Fragments
如果再进一步,既然能够定义 Fragments 了,那么在其中定义变量也是可以的吧。
query person($first: Int = 2) {
p4: person(id: "4") {
...personFields
},
p5: person(name: "admin") {
...personFields
}
}
fragment personFields on PersonType {
id
username
email
fullName
friends(first: $first) {
id
username
}
}
结果是这样的
{
"data": {
"p4": {
"id": "4",
"username": "gvr",
"email": "gvr@dropbox.com",
"fullName": "Guido van Rossum",
"friends": [
{
"id": "2",
"username": "aholovaty"
},
{
"id": "3",
"username": "swillison"
}
]
},
"p5": {
"id": "5",
"username": "admin",
"email": "i@gmail.com",
"fullName": " ",
"friends": [
{
"id": "1",
"username": "steveluscher"
},
{
"id": "2",
"username": "aholovaty"
}
]
}
}
}
要使用变量,需要有三个步骤:
- 将静态变量替换为带
$操作符的$variableName变量名 - 将变量名作为某个查询 operation name 的参数
- 将
variableName: value参数以可以传输的格式(通常是 JSON) 传递给查询
变量在定义时需要注意会在后面跟着 : type 来表示该变量的类型。定义的变量只能是这些类型
- scalars 标量
- enums 枚举
- input object types
对于复杂变量,需要到 Schema 中知道该变量的内容。这部分可以参考 Schema.
变量如果是必须的,那么需要在变量类型后面增加 ! 来表示
操作名 Operation name
在上面的例子中也能看到,在 Query 的时候,有些情况下可以省略最前面的 query 关键字,这个 query 关键字在 GraphQL 中叫做 operation type,之所以叫做 type,是因为这只是查询,到后面还有 mutation (修改), subscription 等等。这个操作类型隐含了此次操作的具体动作,比如说是查询,还是修改,还是订阅等等。
接在 query 关键字后面的是 operation name,操作名,该名字定义了此次查询的含义,比如上面的例子就是查询 person 信息。operation name 就像是大部分语言里面的方法,operation name 在获取多个文档时才是必须的,但是非常建议给予每一个查询一个名字,operation name 在调试服务端程序时非常有用,可以快速定位问题。
更改 mutation
插入或者更新数据,和查询类似,使用 mutation operation type, 后面接 operation name,再就是传参,以及定义返回值。
mutation createCategory {
createCategory(name: "Milk") {
category {
id
name
}
}
}
class CreateCategory(graphene.Mutation):
"""
"""
class Arguments:
name = graphene.String(required=True)
category = graphene.Field(CategoryType)
def mutate(self, info, **kwargs):
name = kwargs.get('name')
category = Category(name=name)
Category.save(category)
return CreateCategory(category=category)
class UpdateCategory(graphene.Mutation):
"""
mutation updateCategory {
updateCategory(id: "5", name: "MilkV2") {
category {
id
name
}
}
}
"""
class Arguments:
id = graphene.ID()
name = graphene.String(required=True)
category = graphene.Field(CategoryType)
def mutate(self, info, id, name):
ca = Category.objects.get(pk=id)
ca.name = name
ca.save()
return UpdateCategory(category=ca)
class Mutation(graphene.ObjectType):
create_category = CreateCategory.Field()
update_category = UpdateCategory.Field()
Mutation 和 Query 有一个显著的差异,Query Field 会同时查询,而 Mutation Field 只会顺序,一个接一个查询。
扩展阅读
其他 Python 实现的 GraphQL
用 node 实现第一个 GraphQL
GraphQL with Flask
JSON API
这里是一些已经实现 GraphQL 的公开的 API
reference
- https://graphql.org/learn/
- https://github.com/chentsulin/awesome-graphql
- https://www.apollographql.com
- https://www.apollographql.com/docs/apollo-server/getting-started/
- https://medium.com/airbnb-engineering/reconciling-graphql-and-thrift-at-airbnb-a97e8d290712
- 中文网站
- https://github.com/google/rejoiner
- 从 RESTful 迁移到 GraphQL
Drools 学习笔记之决策表: Guided Decision Table
Column
决策表的列定义。
Ruleflow-Group
A string identifying a rule flow group. In rule flow groups, rules can fire only when the group is activated by the associated rule flow. Example: ruleflow-group "GroupName"
Agenda-Group
A string identifying an agenda group to which you want to assign the rule. Agenda groups allow you to partition the agenda to provide more execution control over groups of rules. Only rules in an agenda group that has acquired a focus are able to be activated. Example:
agenda-group "GroupName"
Agenda Groups 是一种分区规则的方法,任何时候只有一组规则拥有 Focus,只有拥有 Focus 焦点的规则才会生效。
agenda-group 默认值 MAIN,类型是 String,可以如下方式定义:
rule "Is of valid age"
agenda-group "GroupA"
when
Applicant( age < 18 )
$a : Application()
then
$a.setValid( false );
System.out.println("GroupA fired age < 18");
end
Agenda-Group 像栈一样工作,当给定 Group 设置 Focus 时,该 Group 会被放到栈顶。
Metadata column
元数据列,默认情况下元数据列是隐藏的。可以在决策表的列属性中显示。
reference
使用 ripgrep 通过正则快速查找文件内容
ripgrep(简称 rg),是一个用 Rust 实现的命令行搜索工具,可以通过正则来搜索当前的目录。默认情况下 ripgrep 会遵循 .gitignore 的内容,并且自动跳过隐藏的文件目录,以及二进制文件。 ripgrep 原生支持 Windows, MacOS, Linux。ripgrep 和其他流行的搜索工具非常相似,比如 The Silver Searcher, ack 和 grep.
rg 的优势
目前 Linux 下可用的搜索工具非常多,GNU 中的 grep, ack-grep,The Silver Searcher 等等,而 rg 的优势在于快。
ripgrep是真正的快,我在一个有 26G 代码的目录中查找一个方法也可以在几乎秒级的速度找到,所以我经常用来搜索不确定调用关系,但代码又分布在不同项目中时使用ripgrep遵循.gitignore,在默认情况下会跳过二进制文件,隐藏的文件目录,不会追踪软链接,更进一步加快了速度ripgrep支持 Unicode, 可以搜索压缩文件,还可以自己选择正则表达式匹配引擎,比如 PCRE2
Installation
安装的内容直接参考官方页面 即可。
brew install ripgrep
Usage
来看看 rg 的通用格式
USAGE:
rg [OPTIONS] PATTERN [PATH ...]
rg [OPTIONS] [-e PATTERN ...] [PATH ...]
rg [OPTIONS] [-f PATTERNFILE ...] [PATH ...]
rg [OPTIONS] --files [PATH ...]
rg [OPTIONS] --type-list
command | rg [OPTIONS] PATTERN
最不用记忆的就是直接:
rg "keyword"
会显示当前目录下的搜索内容,会打印出文件名及关键字出现的行数。
和 grep 命令类似,也有三个打印出上下行的选项
-A NUM打印匹配行后面 after N 行-B NUM打印匹配行前面 before N 行-C NUM打印匹配行前后 N 行
用正则表达式搜索
使用 -e REGEX 来指定正则表达式
rg -e "*sql" -C2
搜索所有内容包括 gitignore 和隐藏文件
默认 rg 会忽略 .gitignore 和隐藏文件,可以使用 -uu 来查询所有内容:
rg -uu "word" .
显示匹配的次数
使用 -c 来显示匹配的次数:
rg -c "word" .
结果会在文件名后面增加一个次数。
搜索指定的文件类型
可以使用 -t type 来指定文件类型:
rg -t markdown "mysql" .
支持的文件类型可以通过
rg --type-list
来查看。
看到这里,有些读者可能要问假如我要在两个文件类型中查找呢,这个时候 -t 参数就无法满足了,需要引入新的 -g 参数,man rg 看一下 -g 就知道该选项后面跟着一个 GLOB,正则表达式,包括或者去除一些文件或者目录。比如要在 md 文件或者 html 文件中查找 “mysql” 关键字
rg -g "*.{md,html}" "mysql"
注意这里是花括号。
只打印包含匹配内容的文件名
使用 -l 来打印文件名
rg -l -w "word" .
相反的是如果要打印没有匹配内容的文件名
rg --files-without-match -w "word" .
启用大小写敏感
使用 -s 选项来启用大小写敏感
rg -s "word" .
使用 -i 来关闭大小写敏感。
显示不包含关键字的行
使用选项 -v 来显示不包含关键字的行
rg -v "word" .
搜索单词
添加 -w 参数仅显示该单词的内容,该选项等同于在搜索 Pattern 前后加上 \b,这样可以避免因为模糊搜索而导致的不精确。
rg -w "myword" .
比如搜索 abc,可能有些单词包含 dabce ,那么也会被搜索出来,而加上 -w 就不会搜索出来了。
搜索文件名
如果只想要查找文件名中的关键字可以联合 --files 使用。
--files 选项会打印出 rg 将会搜索的所有文件名,包含路径,那如果想要查找文件名中是否包含某个关键字,就可以使用
rg --files | rg regular_expression
reference
有两个方法查看 rg 使用
man rgtldr rg- https://github.com/BurntSushi/ripgrep/blob/master/GUIDE.md
在 Vim 下使用 fzf
fzf 的介绍看这篇文章,这篇文章主要总结一下 Fzf 在 vim 下面的使用。
安装过程就不再说,安装后 :help fzf 可以查看所有帮助。
fzf-vim 安装之后, :FZF 命令会被添加。
" 在当前目录搜索"
:FZF
" 在 home 目录搜索"
:FZF ~
" fzf 全屏"
:FZF!
插件配置
常用的配置 :help 中都能看到。
" An action can be a reference to a function that processes selected lines
function! s:build_quickfix_list(lines)
call setqflist(map(copy(a:lines), '{ "filename": v:val }'))
copen
cc
endfunction
let g:fzf_action = {
\ 'ctrl-q': function('s:build_quickfix_list'),
\ 'ctrl-t': 'tab split',
\ 'ctrl-x': 'split',
\ 'ctrl-v': 'vsplit' }
" Default fzf layout
" - down / up / left / right
let g:fzf_layout = { 'down': '~40%' }
let g:fzf_history_dir = '~/.local/share/fzf-history'
Usage
常用命令
在当前目录下查找
Files :FZF
和 ctrip.vim 类似,使用回车, Ctrl-T, Ctrl-X 或者 Ctrl-V 可以分别在当前窗口,标签页,水平分隔或者垂直分隔窗口中打开。
FZF_DEFAULT_COMMAND 和 FZF_DEFAULT_OPTS 环境变量也会被使用。
Vim 内部 Buffers, Windows 查找
跳转到 Buffer 内的某一行
:Lines
或者是当前 Buffer 内的行
:BLines
查找 Buffers
:Buffers
查找 Windows:
:Windows
查找可用的命令
:Commands
Normal Mode Mappings
:Maps
reference
- vim 中
:help fzf - https://github.com/junegunn/fzf.vim
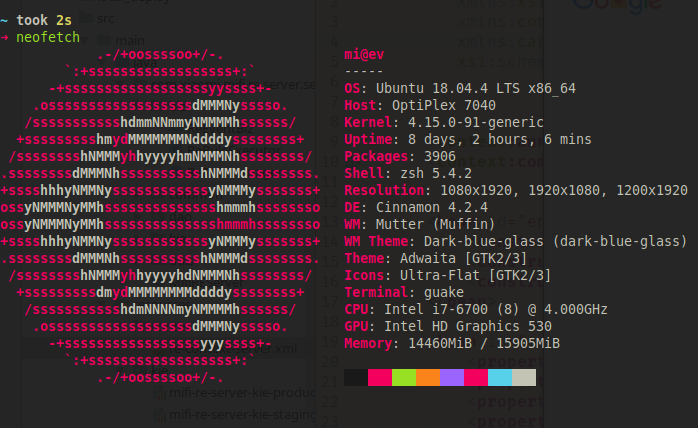
我的 Linux 环境及 Cinnamon 桌面配置记录
记录一下 Ubuntu 和 Linux Mint 的一些初始化设置,以便于快速恢复自己熟悉的工作环境。当然我更建议日常进行硬盘及文件的快照备份。Linux Mint 下可以是 timeshift 进行文件备份。而如果要对整块硬盘进行迁移和备份,切换到新的机器中,我推荐使用 clonezilla12 来备份与恢复。
桌面环境 Cinnamon
毕竟用了多年 GUI,我至今还没有接受完全的命令行,虽然有人非常推荐用 i3,但是至少在我熟悉目前这一套工作环境前,我还没有去尝试 i3,等某一天真的对目前的桌面非常熟悉了,并且能够希望通过快捷键来加速窗口管理了,我一定会去试试 i3 桌面环境。所以在剩下的桌面环境中,我选择了 Cinnamon。个人觉得是我用过所有桌面中最 User-Friendly 的。
当然如果是 Mint 默认就会选择 Cinnamon,而 Ubuntu 可以使用 PPA 安装:
sudo add-apt-repository ppa:embrosyn/cinnamon && sudo apt update
sudo apt install cinnamon
Prerequisite
这篇文章涉及到很多 Debian/Ubuntu/Linux Mint 下关于 /etc/apt/ 配置的内容。所以有必要先了解一下该配置目录。
sources.list
在该目录下有一个 /etc/apt/sources.list 目录,该目录配置了 Ubuntu 官方的软件源,一般可以用国内的镜像 来替换。
其次就是 sources.list.d 配置目录,其中放置了第三方软件源的配置,比如 Google Chrome 的源,Microsoft 的 vscode 软件源,在比如下方可能提到的其他软件源的配置都存放在这里。
save distUpgrade
在这些软件源的配置文件中可能看到 sources.list.save 和 sources.list.distUpgrade 这样的文件,打开文件查看,这些文件和 sources.list 文件差不多。其实这些文件都是一些备份文件。3
- 在添加一个 repository 后,Ubuntu 会自动生成
.save文件,以备份之前的配置,如果出现apt update时的问题,可以随时回退回去sudo cp /etc/apt/sources.list.save /etc/apt/sources.list .distUpgrade文件则是在运行了dist-upgrade之后生成的备份文件。
APT
安装必要工具:
sudo apt install vim zsh wget git tree htop fcitx fcitx-rime vlc gimp inkscape shutter filezilla audacity exuberant-ctags iotop iftop nethogs
基础环境配置
基础环境配置,包括日常使用这一台机器需要用到的应用软件,必不可少的组成部分,包括终端,输入法,浏览器等等。
Terminal
guake
下拉式终端,F12 可以让终端无处不在,配合 tmux 基本上也实现了类似 i3 中对终端的管理。
sudo apt install guake
Terminator
日常也会装一个 Terminator,如果有第三块屏幕的话,放着看日志。
sudo add-apt-repository ppa:gnome-terminator
sudo apt-get update
sudo apt-get install terminator
输入法
有一段时间使用搜狗的 linux 版本,没啥大问题,直到有一天开始频繁崩溃 一怒之下换成了 fcitx-rime ,之后彻底的爱上了 Rime.
sudo apt install fcitx fcitx-rime im-config
Rime 配置放到 GitHub 托管。
Browser
Chrome
通过如下方式添加 Google Chrome 的源
wget -q -O - https://dl.google.com/linux/linux_signing_key.pub | sudo apt-key add -
sudo sh -c 'echo "deb [arch=amd64] http://dl.google.com/linux/chrome/deb/ stable main" >> /etc/apt/sources.list.d/google.list'
Package in this source:
- google-chrome-stable
- google-chrome-beta
- google-chrome-unstable
Vivaldi
Vivaldi 是另一个我长期关注的浏览器,和 Chrome 一样都源自 Chromium,都使用 Blink 渲染引擎,但是 Vivaldi 在界面显示和 UI 交互方面做的太贴心了,原来一直没有的同步功能,也加上了,并且可以直接使用 Chrome Web Store,可以做到无痛切换。
FireFox
一般都默认自带了,但基本上没怎么用。
Syncthing
同步工具,代替了我原来长期使用的 Dropbox
# Add the release PGP keys:
curl -s https://syncthing.net/release-key.txt | sudo apt-key add -
# Add the "stable" channel to your APT sources:
echo "deb https://apt.syncthing.net/ syncthing stable" | sudo tee /etc/apt/sources.list.d/syncthing.list
# Update and install syncthing:
sudo apt-get update
sudo apt-get install syncthing
除了 Syncthing,还有 NextCloud 作为备份。
笔记
笔记应用
- WizNote
字典
GoldenDict
Programming
开发环境配置
Java 开发环境
推荐使用 OpenJDK
sudo apt install openjdk-8-jdk
更多内容参考 OpenJDK 官网,进行手动安装。
安装 Java 9 及以后:
sudo apt install openjdk-11-jdk
如果不想使用 OpenJDK,使用 Oracle JDK:
sudo add-apt-repository ppa:webupd8team/java && sudo apt update
sudo apt install oracle-java8-installer
sudo update-alternatives --config java
sudo update-alternatives --config javac
更加详细的安装 JDK 的方式,可以参考这里
IDE
- IntelliJ IDEA
JD-GUI
Java Decompiler JD-GUI
Python
直接看这里 Pyenv
Database
MySQL
我使用 MySQL Workbench,虽然有点重,但不影响使用。IntelliJ 自带的 SQL 工具也是很好用的。
Redis
我使用 Redis Desktop Manager 客户端,当然直接用命令行也是可以的。
sudo snap install redis-desktop-manager
SmartGit
使用多年的 Git 客户端,日常命令行即可。
Others
Screenshot
之前都直接使用 Cinnamon 自带的截图工具 desktop-capture,这个工具非常轻便,并且自带截图,录屏,录制 GIF 等等工具,但是唯一的缺点是无法 mark,无法在截图后直接在图片上做标注。所以后来又发现了一款叫做 flameshot 的工具,相辅相成,很舒服。
sudo apt install flameshot
邮件客户端
sudo apt install evolution evolution-ews evolution-indicator evolution-plugins
SNAP
sudo snap install postman telegram-desktop
PDF 阅读器
Cinnamon 自己带这一个简易的 PDF 阅读器,日常使用本身也没有任何问题,不过如果要截取 PDF 内容,尤其是影印的 PDF,就需要 Okular
Best PDF reader ever
sudo snap install okular
下载
Transgui with Tranmission
MultiMedia
多媒体相关包括音视频播放器,解码器,转码,以及媒体信息查看。
Player
Windows 上有 PotPlayer,Linux 上自然也不输。
VLC
播放器 VLC
SMPlayer
SMPlayer 也非常好用。
sudo add-apt-repository ppa:rvm/smplayer
sudo apt-get update
sudo apt-get install smplayer smplayer-themes smplayer-skins
ffmpeg
大名鼎鼎的 ffmpeg 不得不拥有。(LGPL 2.14)
sudo apt install ffmpeg
MediaInfo
MediaInfo 用来查看音视频的各个详细参数,包括音视频编码格式信息,封装类型,字幕等等信息。(BSD 协议下开源 5)
命令安装:
sudo apt install mediainfo
或者安装界面:
Stacer
System Dashboard, Optimizer & Monitor.
Install:
sudo add-apt-repository ppa:oguzhaninan/stacer -y
sudo apt-get update
sudo apt-get install stacer -y
GitHub page:
电子书管理
Calibre
PPA
一些值得一提的 PPA。
sudo add-apt-repository ppa:noobslab/icons
sudo apt install arc-theme
sudo add-apt-repository ppa:noobslab/themes
sudo apt install flatabulous-theme
sudo add-apt-repository ppa:numix/ppa
sudo apt install numix-icon-theme
sudo add-apt-repository ppa:snwh/pulp
sudo apt install paper-icon-theme
# 同时也可以安装 GTK 和 Cursor 主题
sudo apt install paper-gtk-theme
sudo apt install paper-cursor-theme
sudo add-apt-repository ppa:papirus/papirus
sudo apt install papirus-icon-theme
sudo add-apt-repository ppa:atareao/telegram -y
sudo add-apt-repository ppa:atareao/atareao -y
wget https://launchpadlibrarian.net/292068009/indicator-sound-switcher_2.1.1ubuntu0-1_all.deb
wget http://ppa.launchpad.net/nilarimogard/webupd8/ubuntu/pool/main/s/syspeek/syspeek_0.3+bzr26-1~webupd8~zesty_all.deb
wget https://linux.dropbox.com/packages/ubuntu/dropbox_2015.10.28_amd64.deb
wget https://dl.google.com/linux/direct/google-chrome-stable_current_amd64.deb
wget https://jaist.dl.sourceforge.net/project/deadbeef/debian/deadbeef-static_0.7.2-2_amd64.deb
sudo apt install fcitx-module-cloudpinyin gtk2-engines-murrine:i386 libudev1:i386 i965-va-driver vainfo openshot classicmenu-indicator numix-gtk-theme shimmer-themes numix-icon* caffeine leafpad git unity-tweak-tool fcitx-mozc ibus-qt4 curl ctags vim-doc vim-scripts cscope fonts-dejavu indent psensor libluajit-5.1-2 python3-pip ubuntu-make ppa-purge jayatana compizconfig-settings-manager zsh wget papirus-folders papirus-icon-theme filezilla-theme-papirus exfat-fuse exfat-utils ttf-bitstream-vera -y
WPS
wget http://kdl1.cache.wps.com/ksodl/download/linux/a21//wps-office_10.1.0.5707~a21_amd64.deb wget http://kdl.cc.ksosoft.com/wps-community/download/fonts/wps-office-fonts_1.0_all.deb wget http://kr.archive.ubuntu.com/ubuntu/pool/main/libp/libpng/libpng12-0_1.2.54-1ubuntu1_amd64.deb sudo dpkg -i libpng12-0_1.2.54-1ubuntu1_amd64.deb sudo dpkg -i wps-office_10.1.0.5707~a21_amd64.deb sudo dpkg -i wps-office-fonts_1.0_all.deb
sudo apt-get install wqy-*
sudo gedit /etc/fonts/conf.avail/69-language-selector-zh-cn.conf
文泉译微米黑字体
sudo apt install fonts-wqy-microhei
sudo vim /usr/share/X11/xorg.conf.d/40-libinput.conf
Option “Tapping” “on” Option “NaturalScrolling” “true” Option “ClickMethod” “clickfinger” Option “DisableWhileTyping” “True”
sudo apt install sassc autoconf automake pkg-config libgtk-3-dev git -y
git clone https://github.com/andreisergiu98/arc-flatabulous-theme && cd arc-flatabulous-theme
./autogen.sh --prefix=/usr --disable-transparency
sudo make install
sudo apt-get install terminator
sudo update-alternatives --config x-terminal-emulator
gsettings set org.gnome.desktop.default-applications.terminal exec 'terminator'
sudo dpkg-reconfigure ca-certificates
sudo apt install shadowsocks-libev simple-obfs
sudo vim /etc/shadowsocks-libev/config.json
sudo vim /lib/systemd/system/shadowsocks-libev.service
sudo apt-get install tlp tlp-rdw tp-smapi-dkms acpi-call-dkms thermald powertop
sudo add-apt-repository ppa:gottcode/gcppa -y
sudo add-apt-repository ppa:nextcloud-devs/client -y
sudo add-apt-repository -u ppa:snwh/ppa -y
sudo add-apt-repository ppa:ubuntuhandbook1/shutter -y
sudo add-apt-repository ppa:kasra-mp/ubuntu-indicator-weather -y
sudo add-apt-repository ppa:ubuntu-toolchain-r/test -y
sudo add-apt-repository -u ppa:snwh/ppa -k
wget https://launchpadlibrarian.net/292068009/indicator-sound-switcher_2.1.1ubuntu0-1_all.deb
wget http://ppa.launchpad.net/nilarimogard/webupd8/ubuntu/pool/main/s/syspeek/syspeek_0.3+bzr26-1~webupd8~zesty_all.deb
wget https://www.dropbox.com/download?dl=packages/ubuntu/dropbox_2019.01.31_amd64.deb
wget https://dl.google.com/linux/direct/google-chrome-stable_current_amd64.deb
wget https://jaist.dl.sourceforge.net/project/deadbeef/debian/deadbeef-static_0.7.2-2_amd64.deb
wget https://launchpadlibrarian.net/330848294/libgtk2-appindicator-perl_0.15-1build5_amd64.deb
Hi Res 与蓝牙 LDAC
sudo add-apt-repository ppa:eh5/pulseaudio-a2dp -y
sudo apt-get install pulseaudio-module-bluetooth
sudo vim /etc/pulse/daemon.conf
resample-method = soxr-vhq
default-sample-format = s32le
default-sample-rate = 192000
alternate-sample-rate = 96000
pulseaudio -k
pulseaudio --start
sudo vim /etc/pulse/default.pa
# LDAC Standard Quality
load-module module-bluetooth-discover a2dp_config="ldac_eqmid=sq"
# LDAC High Quality; Force LDAC/PA PCM sample format as Float32LE
#load-module module-bluetooth-discover a2dp_config="ldac_eqmid=hq ldac_fmt=f32"
粘贴板工具
sudo add-apt-repository ppa:hluk/copyq-beta
sudo apt install copyq
Theme
- flatabulous-theme
- communitheme
ICON
图标包我非常喜欢的是 Numix 这个系列的图标,特别是其中的 numix-icon-theme-circle。那么就安装 numix-icon-theme-circle 这套图标包了。
Numix-icon-theme-circle
sudoadd-apt-repository ppa:numix/ppa
sudo apt-get update
sudo apt-get install numix-icon-theme-circle
图标包安装好了设置使用上该套图标包还需要使用 Gnome Tweak,安装方法也是通过到 AppStore 中搜索 Gnome Tweak 即可,也可以通过 sudo apt-get install gnome-tweak-tool 来完成安装。由于系统是中文系统,该软件中文名叫做“优化”。
App List
- 4K Video Downloader 下载工具
- Anbox 在 Linux 上模拟 Android,可以安装安卓应用
- Anki 单词记忆
- Atom 文本编辑器
- Brasero
- Bustle
- Cerebro
- Character Map 字体工具
- Charles 抓包工具
- Cheese
- Chess
- Cinnamon Control Center
- Color
- Conky
- Conky Manager
- CopyQ
- CroseOver
- Dropbox
- Calibre 电子书管理器
- Electronic Wechat
- Emojione Picker
- Evolution
- Fcitx 输入法
- Firefox
- Five or More
- GHex
- GIMP
- GParted
- GPaste
- GVim
- GitKraken
- Gnote
- Goldendict**
- Google Chrome
- Gpick
- Guake
- Hiri
- Inkscape
- JD-GUI
- Joplin
- KeePassXC
- Meld
- MySQL Workbench
- Nemo
- NemoVim
- Netease Cloud Music
- NextCloud desktop sync client
- Okular
- Postman
- Remmina
- Rhythmbox
- Shadowsocks
- ShotWell
- Simple Scan
- Slack
- SmartGit**
- Stacer
- Syncthing
- SublimeText
- [[Teamviewer]]
- Telegram
- Terminator
- VLC
- VMware Workstation
- Vim
- Visual Studio Code
- Vivaldi
- WPS
- Wireshark
- Wiznote
- Zeal
- Zenmap
- zsh
- bmon
- Calibre
- haroopad
- pCloud
- mpv
- qBittorent
- tagspaces
- Zeal
全局快捷键
| 快捷键 | 说明 |
|---|---|
| F12 | Guake |
| Ctrl-c-c | GoldenDict 查词 |
| Ctrl-grave | Rime 切换输入方案 |
reference
在 Ubuntu 下为 Postman 创建 icon
Postman 早两年就不再更新 Chrome 版本的应用,转而发布 Native app,这个原生的应用非常完美,但唯一的不足就是没有启动 ICON,下载之后就只有一个 tar 包,解压到任意一个文件夹之后就能使用,但是在桌面上,或者启动器中是无法找到该应用的。
和之前说过的给 Wiznote 一样,可以使用 gnome 提供的工具来给 Postman 也提供一个 ICON
gnome-desktop-item-edit ~/.local/share/applications --create-new
然后填入应用图标,路径,等等就可以。然后去该目录下查看就能看到已经创建了一个 Postman.desktop 文件,当然你也可以手动创建该文件。
[Desktop Entry]
Encoding=UTF-8
Version=1.0
Type=Application
Name=Postman
Icon=postman.png
Path=/home/[your username]/Postman
Exec=/home/[your username]/Postman/Postman
StartupNotify=false
StartupWMClass=Postman
如果只想要展示在 Unity;GNOME 下可以配置:
OnlyShowIn=Unity;GNOME;
X-UnityGenerated=true
系统主题的大部分图标在该目录下:
/usr/share/icons/
reference
NTSC 和 PAL
之前折腾相机,剪视频的时候遇到这两个标准制式,就一直在待办事项中,这里就简单的记录一下。
制式
NTSC
NTSC 是 National Television Standard Committee,美国电视播放标准。
PAL
PAL 是 Phase Alternating Line,适用于其他国家的播放标准。
差异
播放速率
NTSC | PAL ———-|—————- 24 FPS | 24 FPS 30 FPS | 25 FPS 48 FPS | 48 FPS 60 FPS | 50 FPS
场
在搜索视频相关的内容时看到了有高场、地场的差别,联系到平时经常看到的一些词汇感觉到需要记录一下,这是两个经常能看到的词汇:
- 1080i
- 1080p
这里的 1080 都很熟悉就是视频分辨率,而这里的 i 和 p 分别指的是
- Interlace 隔行扫描
- Progressive 逐行扫描
在过去电视时代,要传输图像,根据人眼的视觉残留制定出 24 帧每秒的标准,当每秒有 24 帧及以上的静止图像连续出现时,人眼就认为是动影像,但是实现这个动影像效果,就需要电视画面传输时及考虑到传输带宽,也要考虑到画面质量。所以过去人们就发明了隔行扫描和逐行扫描,隔行扫描也就是画面在传输时,隔行传输,这样可以节省一半的带宽。
常见的帧率有:
- 24 frame/sec (film, ATSC, 2k, 4k, 6k)
- 25 frame/sec (PAL, used in Europe, Uruguay, Argentina, Australia), SECAM, DVB, ATSC)
- 29.97 (30 ÷ 1.001) frame/sec (NTSC American System (US, Canada, Mexico, Colombia, etc.), ATSC, PAL-M (Brazil))
- 30 frame/sec (ATSC)
为什么有这么多的帧率呢,这就要回到过去黑白电视时代,世界上不同地区的用电频率不一样,这就涉及到传输电视画面的频率问题,美国的电力是 60Hz 所以上面提到的 NTSC 用的是 30 FPS,而其他地区,欧洲, 中国等等用的是 50 Hz 电,所以是 25 FPS 的画面。当彩色电视被发明出来,电气工程师们为了向后兼容,所以他们把彩色信号做了一个小小的偏移,轻微地将帧率从 30 FPS 改成了 30 / 1.001 = 29.97 FPS,因此诞生了 NTSC 色彩标准。
reference
每天学习一个命令:fd find entries in the filesystem
Linux 下的 find 命令自身就比较复杂,想要查找本地文件时通常需要敲一系列的命令,这时候 fd 就出来解决这个问题了。
最简单的 fd 命令就只需要:
fd [pattern] [path...]
但如果需要使用 find 命令,那么需要:
find ./ -name '*test*' -type f
并且 fd 命令要比 find 命令快很多。
fd 由 Rust 实现。
GitHub: https://github.com/sharkdp/fd
Use case
List all files
fd 可以直接不添加任何参数执行,当想要快速查看目录下所有内容时非常有用,类似于 ls -R。
如果想要递归的显示目录下,包括子目录所有的内容,可以使用:
fd . /path/to/dir
查看包含关键字的文件
比如查看本地包含 mysql 的文件:
fd "mysql"
对于 ag 命令则需要
ag -g "mysql" .
而 find 则更加复杂
find ./ -name '*mysql*' -type f
搜索特定的文件后缀
使用 -e 选项来搜索目录下所有的 Markdown 文件(.md):
fd -e md
使用准确的搜索 PATTERN 搜索
使用 -g 选项:
fd -g libc.so /usr
找出目录下文件并删除
首先使用 fd 找出文件名,使用 xargs 发送给 rm(注意小心执行该该命令):
fd "keyword" -x rm -v
在很多情况下,我们不仅要找出搜索结果,还需要对搜索结果执行一些操作,上面提到的删除就是比较常见的,fd 提供了两种方式来对结果执行命令:
-x/--exec并行地对每一个结果执行额外的命令-X/--exec-batch只执行额外的命令一次,将所有的结果作为参数
比如更复杂一些的,递归地找到所有的 zip 文件,然后解压:
fd -e zip -x unzip
如果目录下有两个文件 file1.zip 和 backup/file2.zip ,那么这一行命令之后会并行执行 unzip file1.zip 和 unzip backup/file2.zip。
再比如将目录下所有的 *.jpg 转换成 *.png:
fd -e jpg -x convert {} {.}.png
这里,{} 是搜索结果的一个占位符,{.} 类似,表示文件名无后缀。
还有一个常见,比如要搜索目录下所有的 test_*.py 然后用 vim 打开:
fd -g 'test_*.py' -X vim
或者查看文件的权限、所有者、大小等等:
fd ... -X ls -lhd
-X 命令结合 rg 命令一起使用的时候也非常方便:
fd -e cpp -e cxx -e h -e hpp -X rg 'std::cout'
上面这句话的意思就是找到这些文件后缀的文件中包含 std::cout 的内容。
区分查找的类别
使用 -t 命令来区别要查找的内容
f, file 普通文件
d, directories 目录
l, symlink symbolic links
x, executable 可执行文件
e 空文件或者目录
在 Vim 中使用
installation
安装及配置参考官方:
reference
每天学习一个命令:fzf 使用笔记
今天在闲逛博客 的时候偶然发现 crispgm 所写的文章,其中推荐了 fzf 这款模糊搜寻工具,所以立马上手体验了一下。
fzf 是一个通用的命令行模糊搜索工具,用 golang 编写,大家的评价都是目前最快的 fuzzy finder,配合 ag 的使用,依靠模糊的关键词,可以快速定位文件。配合一些脚本,可以完全颠覆以前使用命令行的工作方式。
Installation
git clone --depth 1 https://github.com/junegunn/fzf.git ~/.fzf
~/.fzf/install
or upgrade
cd ~/.fzf && git pull && ./install
Demo
最直接的使用方式就是在终端输入:
fzf
或者 fzf 可以接受 stdin,比如使用命令
find * -type f | fzf
此时会进入 fzf 的交互窗口,在交互窗口中可以使用 Ctrl + n 或者 Ctrl + p 来上下移动光标。使用 Enter 选中条目
其他常用:
- Ctrl-j Ctrl-n 都能往下,不过 Ctrl-j 在我的配置中是切换到下 pane 所以我只用 Ctrl-n
- Ctrl-k Ctrl-p 都能往上,不过 Ctrl-k 在我的配置中是切换到上 pane 所以我只用 Ctrl-p
- Ctrl-c 或者 Ctrl-g 或者 Ctrl-q 或者 Esc 用来退出 abort
- Ctrl-h 退格键 backspace,不过这个键和 tmux vim 有冲突所以一般不用
- Ctrl-a 光标跳转到开头 Ctrl-e 跳转到行结尾
- Ctrl-w 向前删以 word
- Ctrl-u 删除所有输入
其实看到后面就发现很多快捷键其实是和 Bash/Shell 下一致的,其他更多的交互命令,可以参考 man fzf
Configuration
FZF_DEFAULT_COMMAND
fzf 默认查找文件使用的是系统的 find 命令,你可以通过自定义该环境变量来更改使用其他命令比如 ag 或者 fd
# 这行配置开启 ag 查找隐藏文件 及忽略 .git 文件
export FZF_DEFAULT_COMMAND='ag --hidden --ignore .git -l -g ""'
# or
export FZF_DEFAULT_COMMAND="fd --exclude={.git,.idea,.sass-cache,node_modules,build} --type f"
FZF_DEFAULT_OPTS
该环境变量定义了 fzf 的参数:
export FZF_DEFAULT_OPTS="--height 40% --layout=reverse --preview '(highlight -O ansi {} || cat {}) 2> /dev/null | head -500'"
常见的一些操作
fzf 最最常用的快捷键应该就是 Ctrl + r 和 Ctrl + t 了。Ctrl-r 用来在历史中搜索,Ctrl-t 用来搜索当前文件夹下的内容。
历史记录搜索
在没有使用 fzf 之前都是 Ctrl + r 来快速输入历史命令,用起来倒也没有太大的问题,fzf 使得 Ctrl-r 变得更加好用,按下 Ctrl-r 之后立即就能够显示之前的历史命令,通过模糊搜索能够展示一个列表,从列表中选择即可。
历史命令 Ctrl-r
在终端命令行下按下 Ctrl-r 会列出 history 命令目录,选中 Enter 离开 fzf 后,该条目会拷贝到命令行中。
搜索当前文件夹 Ctrl-t
在命令行中按下 Ctrl-t 会打开 fzf 窗口,此时如果找到某文件,并选择 Enter,那么该文件名会被拷贝到命令行中。比如说想要打开某文件但是忘记了名字,那么可以先输入 vi 然后按下 Ctrl-t 那么会出现 fzf 的搜索窗口,在窗口中可以模糊搜索文件,然后将文件路径及文件拷贝到命令行中。
同样的方式,如果要 mv 一个文件,同样先输入 mv 然后再 Ctrl-t 找到文件,继续输入目的地址即可。
如果想要更简单 fzf GitHub wiki 中展示了非常多的 Bash Shell 的配置 1,比如可以定义命令 fe
fe() {
local files
IFS=$'\n' files=($(fzf-tmux --query="$1" --multi --select-1 --exit-0))
[[ -n "$files" ]] && ${EDITOR:-vim} "${files[@]}"
}
那么在 shell 中直接输入 fe 然后回车会自动出现当前目录的 fzf,选择文件之后回车即可用默认 $EDITOR 打开文件。
多选
假如在 fzf 选择窗口中想要选择多个文件,那么可以使用 tab 来进行多选,使用 Ctrl-n, Ctrl-p 上下切换的时候,可以使用 Tab 来选中期望的文件进行多选操作。
比如移动,删除,或者编辑多个文件时可以使用。
更改路径
在 fzf 之前最原始的方法就是 cd 然后输入一个词,不断的按 Tab 直到完整的输入 Path,回车。但假如 path 比较长,那么可能需要费一些时间找到真正想要去的目录,而如果用 fzf 配置
fd() {
local dir
dir=$(find ${1:-.} -path '*/\.*' -prune \
-o -type d -print 2> /dev/null | fzf +m) &&
cd "$dir"
}
在终端输入 fd 然后搜索一下目录回车就能直接到该目录下,效率提升 x 倍。
Kill Process
再比如说 fkill 用来 kill process
# fkill - kill process
fkill() {
local pid
pid=$(ps -ef | sed 1d | fzf -m | awk '{print $2}')
if [ "x$pid" != "x" ]
then
echo $pid | xargs kill -${1:-9}
fi
}
Tmux
再比如创建 Tmux session 一般都是 tmux new -s new-session 创建,如果使用 tmuxinator 则可能 mux name 比较快,但是如果在 fzf 这里只需要 tm new-session
# tm - create new tmux session, or switch to existing one. Works from within tmux too. (@bag-man)
# `tm` will allow you to select your tmux session via fzf.
# `tm irc` will attach to the irc session (if it exists), else it will create it.
tm() {
[[ -n "$TMUX" ]] && change="switch-client" || change="attach-session"
if [ $1 ]; then
tmux $change -t "$1" 2>/dev/null || (tmux new-session -d -s $1 && tmux $change -t "$1"); return
fi
session=$(tmux list-sessions -F "#{session_name}" 2>/dev/null | fzf --exit-0) && tmux $change -t "$session" || echo "No sessions found."
}
如果 session 不存在则会自动创建,使用 fs 可以快速选择目前可用的 session.
# fs [FUZZY PATTERN] - Select selected tmux session
# - Bypass fuzzy finder if there's only one match (--select-1)
# - Exit if there's no match (--exit-0)
fs() {
local session
session=$(tmux list-sessions -F "#{session_name}" | \
fzf --query="$1" --select-1 --exit-0) &&
tmux switch-client -t "$session"
}
Alt-c
命令行中按下 Alt-c,会列出当前文件夹下的目录,选择后会直接进入该文件夹。
搜索语法
在上面一系列的基础操作后,对 fzf 应该有了一定的了解,那么知道 fzf 的搜索语法其实非常强大,在熟悉正则的基础上,用 fzf 搜索语法可以实现很多的组合,比如使用 ! 来表示不包含,比如 !word 不包含 word 的结果。
比如:
^music以 music 开头mp3$以 mp3 结尾'word严格匹配!word不包含 word!.mp3$不以.mp3结尾
等等,可以在官方网站上看到。
扩展阅读
一些比较高效的搜索工具
reference
禁用 fcitx 额外键切换输入法
之前有提到过在 Linux 下全面切换成了 Rime 输入法,用的是 fcitx-rime 版本的,但是 fcitx 默认自己有一个设置是 Extra key for trigger input method,而这个设置默认的是 Shift both,也就是两边的 Shift 键默认都是切换输入法,那么这就和我的习惯非常不一致。
我习惯于左 Shift 将输入的内容非候选词上屏,也就是当我输入一个英文,但是忘记切换中文输入法时,我可以快速按下左 Shift 来上屏,或者我可以直接 Enter 来上屏,但是如果 fcitx 的话可能机会造成切换输入法,而导致所有输入的内容都丢失。
所以可以安装 fcitx config 工具,在 GUI 中修改,或者可以直接修改配置文件
vi ~/.config/fcitx/config
找到如下一行
SwitchKey=SHIFT Both
然后替换成
SwitchKey=Disabled
然后查看这个配置能看到其他很多有趣的配置,自行调整即可。如果发现这一行配置经常在重启之后又恢复到了默认状态那么可以给这个文件设置一个权限
sudo chmod 444 ~/.config/fcitx/config
另外 fcitx 的扩展配置也在同一级别的目录中,可以查看
ls ~/.config/fcitx/conf
文章分类
最近文章
- AI Shell 让 AI 在命令行下提供 Shell 命令 AI Shell 是一款在命令行下的 AI 自动补全工具,当你想要实现一个功能,敲一大段命令又记不住的时候,使用自然语言让 AI 给你生成一个可执行的命令,然后确认之后执行。
- 最棒的 Navidrome 音乐客户端 Sonixd(Feishin) Sonixd 是一款跨平台的音乐播放器,可以使用 [[Subsonic API]],兼容 Jellyfin,[[Navidrome]],Airsonic,Airsonic-Advanced,Gonic,Astiga 等等服务端。 Sonixd 是一款跨平台的音乐播放器,可以使用 [[Subsonic API]],兼容 Jellyfin,[[Navidrome]],Airsonic,Airsonic-Advanced,Gonic,Astiga 等等服务端。
- 中心化加密货币交易所 Gate 注册以及认证 Gate.io 是一个中心化的加密货币交易所。Gate 中文通常被称为「芝麻开门」,Gate 创立于 2013 年,前身是比特儿,是一家致力于安全、稳定的数字货币交易所,支持超过 1600 种数字货币的交易,提供超过 2700 个交易对。
- 不重启的情况下重新加载 rTorrent 配置文件 因为我在 Screen 下使用 rTorrent,最近经常调试修改 rtorrent.rc 配置文件,所以想要找一个方法可以在不重启 rTorrent 的情况重新加载配置文件,网上调查了一下之后发现原来挺简单的。
- Go 语言编写的网络穿透工具 chisel chisel 是一个在 HTTP 协议上的 TCP/UDP 隧道,使用 Go 语言编写,10.9 K 星星。