使用 PlanetScale 以及 Docker 搭建网站分析 Umami
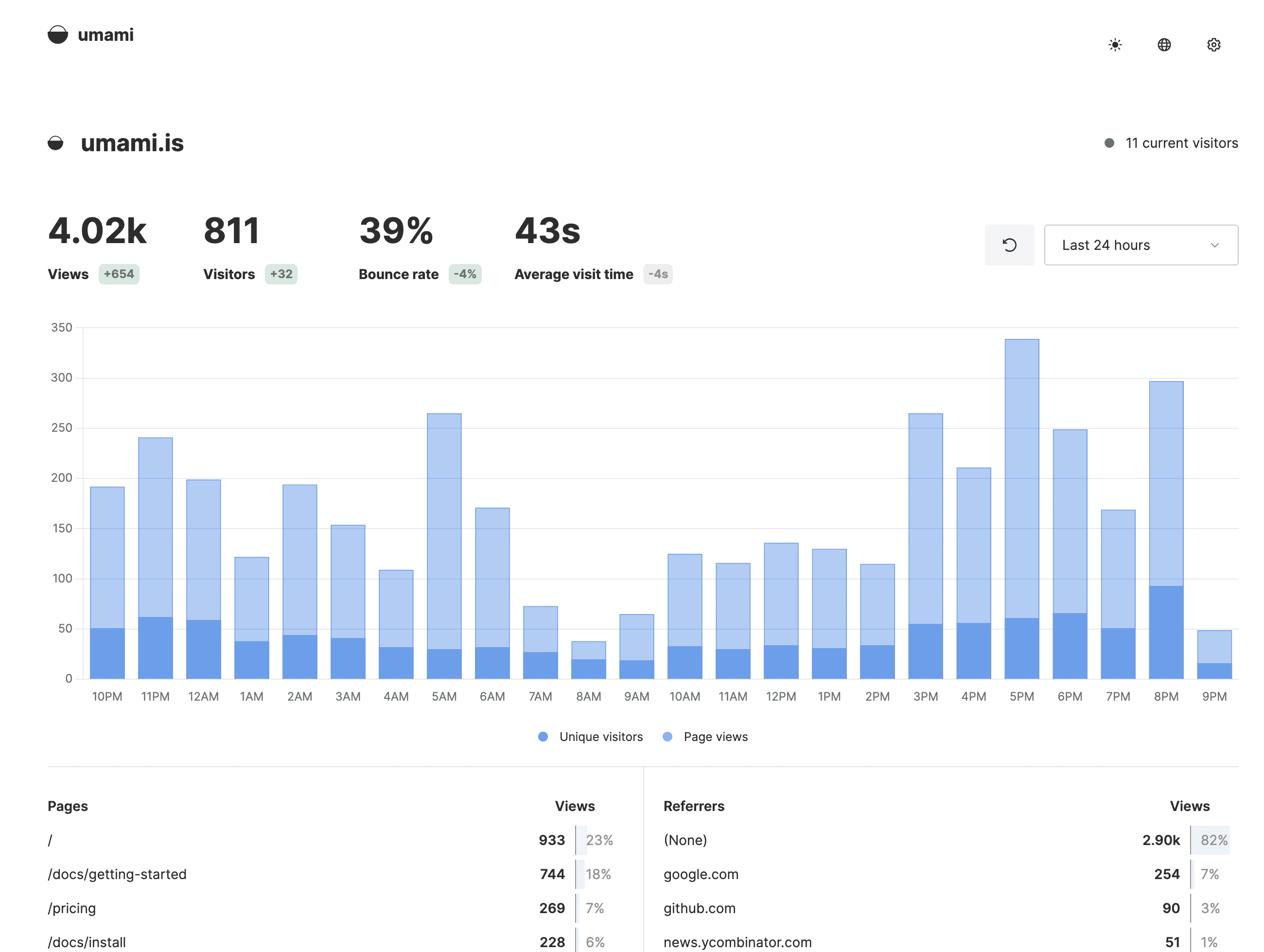
Umami 是一个可以自托管的数据统计服务,可以用来代替 [[Google Analytics]]。 “Umami”,源于 “Umai”,在日语里是“美味、鲜味”的意思。
安装
默认情况下官方推荐的是使用 [[PostgreSQL]] 来作为数据库,可以参照如下的安装。
apt -y update
apt -y install curl git nginx python-certbot-nginx
curl -sSL https://get.docker.com/ | sh
systemctl enable docker nginx
curl -L https://github.com/docker/compose/releases/download/1.27.4/docker-compose-`uname -s`-`uname -m` -o /usr/local/bin/docker-compose
chmod +x /usr/local/bin/docker-compose
git clone https://github.com/mikecao/umami.git
cd umami/
# edit docker-compose.yml
修改:
version: '3'
services:
umami:
image: ghcr.io/mikecao/umami:postgresql-latest
ports:
- "127.0.0.1:3000:3000" # 仅监听在本地
environment:
DATABASE_URL: postgresql://username:password@db-umami:5432/umami # 配置数据库用户和密码
DATABASE_TYPE: postgresql
HASH_SALT: replace-me-with-a-random-string
depends_on:
- db-umami
db-umami:
image: postgres:12-alpine
environment:
POSTGRES_DB: umami
POSTGRES_USER: username # 数据库用户
POSTGRES_PASSWORD: password # 数据库密码
volumes:
- ./sql/schema.postgresql.sql:/docker-entrypoint-initdb.d/schema.postgresql.sql:ro
- umami-db-data:/var/lib/postgresql/data
volumes:
umami-db-data:
然后执行:
docker-compose up -d
配置 Nginx 反向代理:
server {
listen 80;
server_name umami.yourdomain.com; # 换成你的域名
client_max_body_size 0;
location / {
proxy_pass http://127.0.0.1:3000;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
}
}
使用 PlanetScale
但是我为了避免再维护一套数据库,所以使用了之前介绍过的云端 MySQL 兼容数据库 PlanetScale 。
安装过程参考这里
git clone https://github.com/einverne/dockerfile.git
cd umami
cp env .env
# modify .env
docker-compose up -d
然后根据自己的需求,使用 Nginx ,或者直接 [[Nginx Proxy Manager]],配上域名就完成了。
related
- [[Plausible Analytics]]
我购买了一张免月租的英国手机卡 GiffGaff
giffgaff 是一家来自英国的低成本移动运营商,隶属于英国三大运营商之一的 O2 旗下。成立于 2009 年的 giffgaff,以无实体店面、无客服热线、灵活套餐等特色服务,为用户提供高性价比的移动体验。giffgaff 特别适合短期去英国的游客以及英国留学生,giffgaff 也支持全球漫游。
为什么要申请 Giffgaff
- 免费申请,免邮费,零月租使用,免费接受短信,维护成本比较低
- 支持全球激活和漫游
- 180 天消费一次即可一直使用
- 可以接受境外的短信,可以用来注册账号,也支持境外的银行短信
- 支持 eSIM 卡
缺点
- 通话和流量比较贵,通话 1 英镑每分钟,流量 0.2 英镑每兆,短信 0.3 英镑
- 挂断电话也是需要收费的
- 每 180 天需要发送一次短信进行保号
申请方式
- 直接官网申请,日本的地址一周左右收到
- 其他转运方式
激活
访问 https://giffgaff.com/activate 然后按照上面的提示,输入激活码。然后输入邮箱注册账号,进行到下面一步的时候,选择 Pay as you go。

激活时需要 Visa 或 Mastercard 来进行最低 10 英镑的充值。首次充值不支持 PayPal,后续可以使用。
充值成功之后会获得一个随机的号码,是一个 10 位的号码,一般首位为 0 。
英国的国际区号是 +44,所以如果要给此手机号发送短信,需要在前面添加。
如何保持手机号
180 天之内消费一次就可以一直使用该号码,最直接的就是每 180 天给 Google Voice 发送一次短信。
总结
如果觉得 GiffGaff 不错的话,可以点击我的邀请链接 ,使用我的邀请链接首次充值可以多 5 英镑。
每天学习一个命令:高级日志查看工具 lnav
The Logfile Navigator 是一个高级的日志查看工具,后面简写为 lnav。
早上在看 [[Logdy]] 的时候(一款可以将终端的输出 (stdout)发送给浏览器 UI 界面,在可视化界面中检索浏览的开源工具),在作者发帖的讨论中,看到有人推荐 lnav 这一款工具,在本地开发的时候,用 lnav 来查看日志。1
在不知道 lnav 之前,我一直都是使用 tail -f, less, zless, more 来查看日志的,但是 less 这一些工具都是不带高亮的,所以每一次都需要通过搜索来找到自己的想要的内容,但看到 lnav 的介绍立即就看到了 lnav 的高亮显示,立马就尝试了一下。
特性
- 根据日志内容自动高亮 ERROR 等等关键字
- 自动滚动刷新
- 根据正则表达式过滤内容,比如查询 IP 地址等等情况
- 使用 SQL 查询
安装
Ubuntu 下
sudo apt install lnav
使用
完整的命令行参数
❯ lnav -h
usage: lnav [options] [logfile1 logfile2 ...]
A curses-based log file viewer that indexes log messages by type
and time to make it easier to navigate through files quickly.
Key bindings:
? View/leave the online help text.
q Quit the program.
Options:
-h Print this message, then exit.
-H Display the internal help text.
-I path An additional configuration directory.
-H Display the internal help text.
-I path An additional configuration directory.
-i Install the given format files and exit. Pass 'extra'
to install the default set of third-party formats.
-u Update formats installed from git repositories.
-C Check configuration and then exit.
-d file Write debug messages to the given file.
-V Print version information.
-a Load all of the most recent log file types.
-r Recursively load files from the given directory hierarchies.
-R Load older rotated log files as well.
-t Prepend timestamps to the lines of data being read in
on the standard input.
-w file Write the contents of the standard input to this file.
-c cmd Execute a command after the files have been loaded.
-f path Execute the commands in the given file.
-n Run without the curses UI. (headless mode)
-q Do not print the log messages after executing all
of the commands or when lnav is reading from stdin.
Optional arguments:
logfile1 The log files or directories to view. If a
directory is given, all of the files in the
directory will be loaded.
Examples:
To load and follow the syslog file:
$ lnav
To load all of the files in /var/log:
$ lnav /var/log
To watch the output of make with timestamps prepended:
$ make 2>&1 | lnav -t
Version: lnav 0.8.5
直接查看日志文件
lnav /path/to/file.log
进入 lnav 之后还有一些快捷键,可以使用 ? 呼出帮助。
和 Linux 下大部分交互的工具一样,lnav 也遵循了一直的交互逻辑
- g, 到文件第一行
- G, 到文件最后一行
- space, 下一页
- b/bs, 上一页
- j, 下一行
- k, 上一行
- h, 向左移
- l, 向右移动
- e/E, 上一个,下一个 error
- w/W, 上一个,下一个 warning
- f/F, 下一个,上一个文件
/,检索- n/N, 上一个下一个检索结果
可以看到上面的这些快捷,基本上和 Vim/less 的一致。
还有一些调整显示的选项
- i,开启显示日志直方图
- t,开启或关闭 text file view
检索语句
:<command>执行内部命令,具体的命令可以查看帮助文档,或者阅读?中的文档:goto 2 hour ago:goto 12:00
;<sql>,执行 SQL 检索
关于 Duolingo 学语言的一点思考
关注我博客的人应该也知道,我最近在学日语, 今天早上打卡 [[Duolingo]] 发现还差一天完整一年,但其实去年因为搬家中途中断了几天,否则应该时间更长。
但其实我很早就使用 Duolingo,先后在上面学习过英语,韩语和日语。所以今天早上就来简单的讲一讲我的体验。
一句话总结的话就是,单纯使用 Duolingo 我个人的感觉是没有太大的用处的,最多能够对常用的句式,单词有一个基础的概念。但这并不表示 Duolingo 没有实际用处,相反我认为 Duolingo 可以很好的配合枯燥的语法课,以及可以克服初期学语言没有办法融入那个语言环境的问题。通过 Duolingo 对基础单词句式的反复记忆,让自己能达到对日常所见所听,日常会话能脱口而出的状态,不再需要在脑海里面做语言的转换。
学语言的两大困难
缺乏兴趣
如果对一个语言没有任何兴趣,是很难学进去的,相反如果对一门语言有兴趣,那么其实很快就可以入门,反而是如果要达到流利水平需要花费更多的时间。在我们的日常生活中不乏那种因为追星可以从零将韩语学到母语者水平的人,也不乏那种因为喜欢动漫以及日本文化自学日语到 N1 的人。找到关心的那个点,比如我最早其实就是为了听韩语歌,我就想知道怎么搜索我所听到的那个歌,所以想要去了解韩语的发音,韩语怎么输入。
那么 Duolingo 是怎么解决这个兴趣问题的呢?就是将语言学习的知识变成通关游戏,用户面临的选择只有一个就是去通关,不再会那种想要学习一门语言,困难扑面而来的感觉,没有复杂庞大的语法知识,只有一只可爱的猫头鹰每天督促学习。
无使用场景
语言学习的另外一大问题就是,缺乏使用的场景,如果你身处在一个陌生国度,陌生的语言环境,那种本能的生存问题会逼迫你快速的进入那个语言环境,从我自身的经验而言,从最初来日本一句日语不会,到能够识别一些单词,很多都是在日常生活中积累的,比如我学习「东南西北」四个方向,就是从地铁的站名中学到的,我刚来日本的时候,每天都会经过一个站叫做「北千住」 きたせんじゅ,我就学会了「北」叫做 きた,后来又路过了南千住,就又记住了みなみ,再后来因为住的地方搬到了一个包含了「西」的车站附近,正好对称,西边的叫做 にし,东边的叫做 ひがし。再后来,比如我对数字 7 和 8 总是分不清楚,直到我去了一次体检,我拿到的号正好是 174,なな 的发音就再也忘不掉了。
但说实话,Duolingo 在这一点上,并不能解决「说」的问题,但是能解决「听」的问题,并且是构建了一个语言的场景,从最初的见面打招呼,到去餐厅吃饭,到了解这个语言的文化,到政治等等,在打关卡的过程中,循序渐进式的学习。
当然 Duolingo 只能说是一个语言辅助工具,我下面说一说我的建议。
我的建议
所以综合我的经验来说,我的建议是,如果想学一门语言,首先使用 Duolingo 来先来体验一下这个语言,不需要花费很多的时间,就能够让你对这个语言有一个基础的了解。
然后每天坚持背单词,不需要刷很多,使用间隔空闲的时间记忆一下即可,为的是每一天能够唤醒记忆,将短时记忆变成长时记忆,即使每天只学习 10 个新单词,那么一年也能有 3650 个单词的量,那这已经是 N3 所要掌握的词汇量了。
当然背单词并不一定需要 Duolingo,我在我的笔记 中也曾经推荐过很多词典,比如桌面端的 GoldenDict,比如移动端的欧陆词典,MOJi 辞书等等,关键的是需要看到,查阅,再次看到,再了解,看到,知道。
Duolingo 可以很好的作为一个辅助工具,但和上面所说一样,我个人感觉只用 Duolingo 是不够的,尤其是在系统学习语言语法上来说。
所以我的建议是同时去其他地方补充语法知识,比如从视频教程中,和老师的一对一授课中。可以先将网络上那些已经整理好的知识点,在背诵 Duolingo 的时候,反复的问自己,这里是什么语法,然后我的经验就是,当发现 Duolingo 遇到瓶颈的时候,一般就是那个语法点没有掌握,这个时候赶紧补充点语法知识,如果语法知识超前了,那么我会发现我就能跳级了,在这样一个平衡过程中就能一点点的了解越来越多了。
最后分享一个因为语言发音而导致的搞笑视频。
使用 rclone 批量备份及备份到 Cloudflare R2
今天在了解 [[Hono]] 的时候直接使用了 Cloudflare Worker,然后快速实现了一个上传图片到 R2 的代码,回想之前我一直都是使用 [[Chevereto]] 来管理的我博客的配图,Chevereto 的图片都是存放在新加坡的一台机器上,这台机器虽然在国外访问没啥问题,但是在国内延迟略高,所以一想怎么不直接用 [[Cloudflare R2]] 免费的 10 GB 存储了,我自己用 Chevereto 近五年的数据才用了 700MB+,10 GB 已经完全足够我再用 20 多年了。
所以有了这个想法之后,我又不想让我的博客图片迁移完成之后立即挂掉,那么最好的办法就是保持访问的路径之前是类似 https://HOST/images/2023/09/08/IMAGE.png 这样的访问路径,而幸好 Chevereto 本地保存的路径也是类似的结构,存放在了相似的文件夹结构路径下。
那么我的需求就变得非常简单,直接将本地的文件拷贝到对应的 R2 bucket 中 /images 路径下即可。于是了解了一下,发现官方的 CLI 并不支持直接上传。但是官方提供了一个思路就是利用 rclone 工具。
这个工具我之前也介绍过 ,但是当时那篇文章重点在于使用 rclone 挂载磁盘,但是原理也是一样的,只是在这里我会使用 copy 命令,创建一个 remote (兼容 S3) ,然后将本地的文件夹所有的内容直接拷贝远端。
基础的 rclone 设置过程就不再赘述,直接运行 rclone config 进行初始化,并创建兼容 S3 的 remote,比如这里起个名字叫做 r2。
在交互式命令行中,需要访问密钥,访问 Cloudflare 后台,创建 API Token 1
执行 config 命令之后,会写到本地配置文件中,如果交互式命令行有问题的时候,可以直接修改这个配置,或者自己可以直接编辑此配置来完成初始化。
❯ cat ~/.config/rclone/rclone.conf
[r2]
type = s3
provider = Cloudflare
endpoint = https://3f----------.r2.cloudflarestorage.com
access_key_id = db----------------------------b3
secret_access_key = bf------------------------------------------------------------1a
acl = private
完成配置之后,可以使用 rclone 命令来完成本地和 R2 之间的文件复制。
首先使用 rclone tree r2: 来列出 r2 中的所有内容,来验证配置没有问题。
然后可以指定 bucket 名字 rclone tree r2:bucket_name。
然后就是正式开始我的任务,大致看一眼 rclone 的帮助文档,然后执行:
rclone copy -P -v /path/to/image r2:bucket_name/images
执行的过程中会显示当前的进度,然后完成之后,所有的文件都会在 bucket_name 的 images 路径下。
reference
《首尔之春》一点观后感
《首尔之春》是一部很久之前就加入待看片单的电影,终于在昨天晚上看完了。
影片简介
《首尔之春》是韩国 2023 年的票房冠军,也是韩国电影史上首部根据双十二政变事件改编的影片,由《阿修罗》导演金性洙执导,黄晸珉、郑雨盛、李圣旻、朴海俊、金成均主演,2023 年 11 月 22 日在韩国上映。
看完直接先说几点感想吧。
人物关系
导演能够将这么庞大复杂的人物关系梳理并展开清楚,这一点非常了不起,和《1987 黎明到来的那一天》不一样的是,1987 中故事是分段进行的,虽然人物关系也非常复杂,出场人物也非常多,但划分到具体段落中观众只需要记简单的几个就行了。而在《首尔之春》中所有出场的人物全部都是围绕着这一件事情发展而展开的,从安保部,到青瓦台,从总长家到陆军总部,从反叛军地堡到首尔警备司令部,出场的人物一个接一个,地点也一个接着一个更换,但我在观察的过程中竟然没有一丝感觉到混乱,只是事后回想起来才发现出现的人物数量之多。不过我回想起来,可能也是我看韩影比较多,里面的主角配角,甚至只出现一两分钟镜头的演员都是老面孔,看的时候也是不停地被这个超豪华的演员阵容惊讶到。
关于历史
对于这一段历史的,其实我没有很了解,虽然我看了一两本韩国近代史的书,读过一两篇关于光州民主化运动(518 事件)的维基百科和文章,但具体 12 月 12 日那一天发生了什么,其实我还是不了解的,但现实的历史发生了什么我还是大致知道的。所以在观看的过程中,我明明知道黄政民饰演的全斗光就是全斗焕,他会成为改变韩国历史进程的人,但在前半段看到他遇到这种各样问题的时候,还是会不断地想要了解他是怎么一步步完成夺权的,这又是一个吸引我继续看下去的点。另外就是我看过太多的影片,1979 年那个时间前后发生的其他「故事」,所以理解这部分历史相关的倒也还好,比如讲述 1979 年发生的刺杀事件《南山的部长们》,比如 1980 年的光州民主化运动的《出租车司机》《华丽的假期》,以及 1987 年的《1987:黎明到来的那一天》,还有倒序方式讲述那一整段历史的《薄荷糖》,更不用说很多以那个时代为背景的电影《普通人》《南营洞 1985》《五月的青春》等等。
程序正当
程序正当,看电影的过程中其实我有一点我还挺想拿出来说说的,虽然我知道这个就是事实上的军事政变,但黄政民从始至终都需要总统的签字,这一条线索贯穿了全篇,从开始谋划抓捕总长开始这个就是一个必要条件,虽然过程中一直没有拿到「授权」,但最终一幕总统在被迫之下还是签署了。我看到这一个地方的时候其实还感觉停有意思的。在片中能明显的看到黄政民只有两颗星,但是总长我没有记错的话应该是 4 颗星,也就是说一个权力明显不对等的两个人,却发生了一个中层将军直接绑架总长的事件,谁授予的权力呢?其实这个地方也能看到韩国的制度设置里面,虽然经过了朴正熙几十年的独裁统治,但这样一套权力等级制度虽然还在但却错综复杂,尤其是当朴正熙这样一位独裁者突然被枪杀之后产生了权力的极度不平衡。这也是我之前曾经和朋友说过的,一个独裁的体制并不一定会产生极恶的状况,但是一旦权力真空那么发生灾难是必然的。黄政民的权力,武装力量来自于自己,但他却需要一个正当的理由,一个由表面政府首脑签署的文件,才能完成他的整个计划。当我想到这里的时候,不经回想起,韩国民主化运动一路过来的不易,但是也能想到他们成功的必然,在电影里面也非常简短地有出现,1979 年就已经有了完整的媒体监督(虽然还在被压制),已经拥有了非常完整的权力监督体制(虽然还能被颠覆),已经拥有了政治,军事不能混为一体的思想。当看到这里的时候,其实就已经能够预想到最后只要唤醒大部分的民众自然而然就得到了民主。
独裁当道
在看到电影一半的时候我就已经开始为所谓的「正义」一派捏一把冷汗了,而整部电影也用事实告诉普罗大众,如果对于一个「权力」放任不管,那么接下来就是迎接被放出全力牢笼的猛兽的作恶,接下来 1987 中提到的严刑逼供,光州事件中的大规模镇压,已经长达近 10 年的军政府统治,让韩国的民主化运动再次蒙上了一层阴影。
电影到一半左右当黄政民开始策划政变开始,节奏逐渐加快,接下来的剧情发展非常快速,我也知道了为什么韩国年轻人有看这部电影的心率挑战,气愤值挑战,所谓正方的一切行为看起来都非常的懦弱,除了郑雨盛饰演的首尔警备司令官的角色还有一点气度,其他什么国防长官,一听到枪响就逃到了美军基地,还有陆军司令部反复变化的命令,更还有丝毫没有作用的总统,这一些人物的出现那故事的结局已经是必然。
缺点
说完了这么多,再来说一说我觉得这部片子的缺点吧。
首先有一个让我一下子出戏的特效镜头,就是有一个转场镜头,就是在光化门的李舜臣将军像那边,那个转场的画面特效实在太差了。
第二个缺点就是陆军总部,国防长官地刻画都太脸谱化了,虽然历史上的这些人物具体发生了什么很难去再现,但是电影中的表现都是太「简单」,当然可能也受限于篇幅,除了几个主角的刻画比较丰满之外,其他人都是非常潦草的一笔。
为什么叫《首尔之春》
大家可能会好奇为什么明明是发生在 12 月 12 号的事情,片名里面却带着「春」字,全斗焕凭借政变,登上政治最高位,武力镇压民主运动,迫害民主人士,推行军事独裁,结束了大家以为的朴正熙死亡可能带来的民主化春天。在电影的片尾有这样一行字幕。
찬란했던’서울의봄’은그렇게 끝났다 灿烂的「首尔之春」就这样结束了
reference
FocuSee 屏幕录制工具使用体验
在 macOS 下录制屏幕的工具有很多,可以使用系统自带的,也可以使用自带的 QuickTime Player,但是这两个自带的工具,可能都有一些限制,比如不能录制系统自带的声音。
后来我找到了一款用来起来比较舒服的录屏工具,也能够录制系统声音,Screen Recorder by Omi,但 Omi 在导出高清视频的时候有限制,当然如果比较愿意折腾也可以尝试一下 [[Open Broadcaster Software(OBS)]],但今天我来介绍一款新的,操作和使用都比较简单的录屏工具 —- [[FocuSee]]。
FocoSee
FocuSee 是一款专注于屏幕录制的工具,之前有一款支持点击放大效果的录屏软件 [[ScreenFlow]],FocuSee 同样也能达到。
特点:
- 自定义缩放特效,根据点击自动进行画面缩放
- 高亮内容,抓住用户的注意力
- 不同的点击特效
- 内置简易的视频剪辑以及速度编辑工具
- 自定义摄像头相框和滤镜
- 调整录制窗口的边距,圆角等
- 支持根据不同的社交媒体,导出不同的格式
启用权限
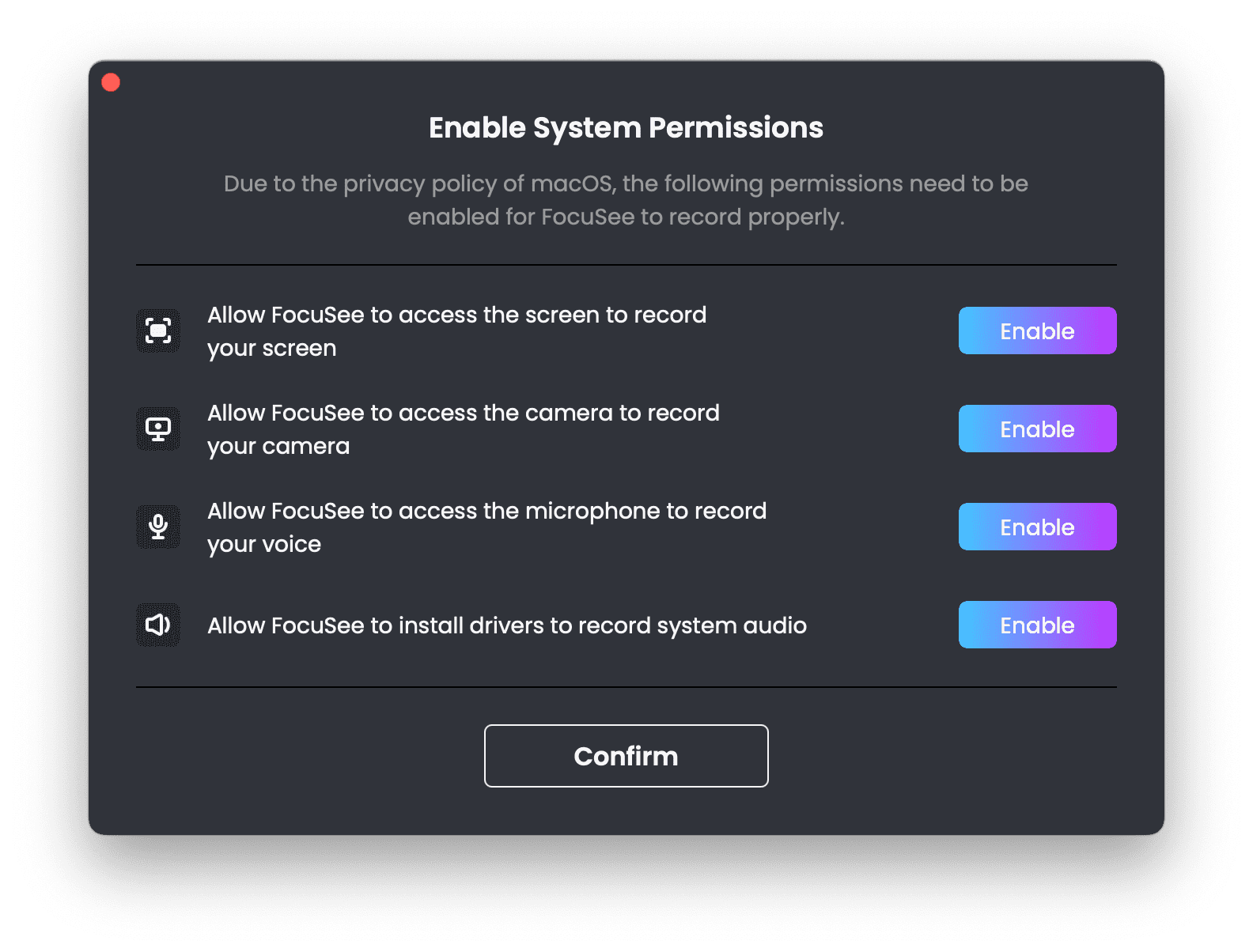
当完成录制之后会出现一个视频编辑器,在这个编辑器中可以做简单的编辑,还可以定义鼠标样式。
价格
FocuSee 的价格不低,但好在是买断制的。
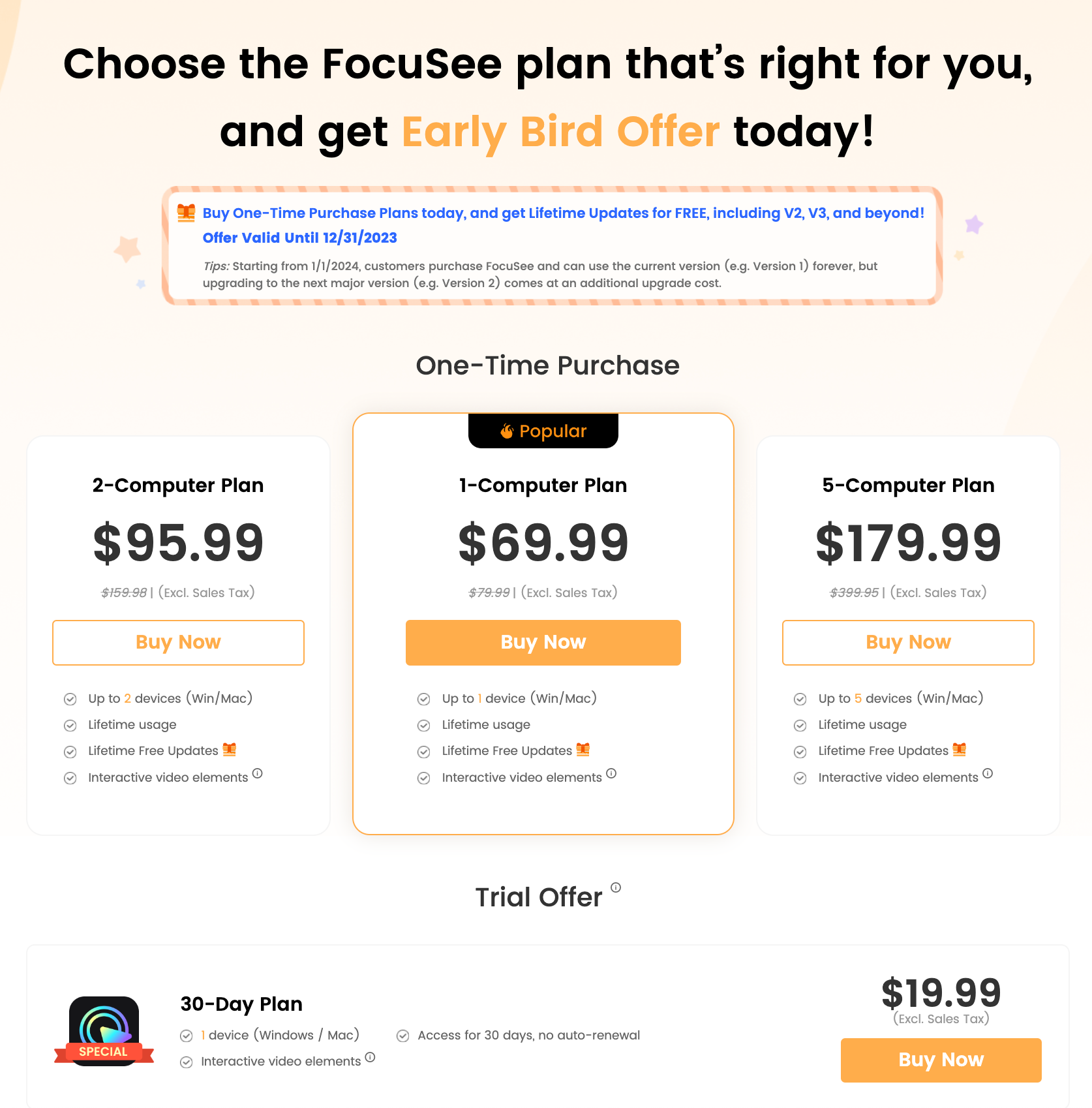
相较于 [[Screen Studio]] 稍微便宜一点点。
more
FocuSee 是一款收费的软件,如果你可以折腾那么,OBS 也有一个插件可以实现视频的缩放,可以使用 Python 脚本。可以参考这个教程。
related
- [[Screen Studio]]
- [[ScreenFlow]]
- [[Open Broadcaster Software(OBS)]]
MVP 最小可实行产品思想
[[MVP]],全称是 Minimum Viable Product ,最小化可实行产品。这个概念是 Eric Ries 在 [[精益创业]] 一书中关于精益创业(Lean Startup)的核心思想,意思是用最快、最简明的方式建立一个可用的产品原型,通过这个最简单的原型来测试产品是否符合市场预期,通过不断的快速迭代来修正产品,适应市场需求。
简单地说,就是在做一个新产品时,不要一下子做一个尽善尽美的产品,而是先花费最小代价做一个「可用」的产品原型,验证这个产品是否有价值,是否可行。通过迭代来完善细节。
那如何来定义「可用」呢?可以问自己如下的问题
- 这个产品是为谁解决什么问题,满足了这部分用户什么需求
- 产品要解决的解决的核心问题是什么
- 分析市场上的竞品,这些竞品哪些地方没有满足拥护的需求
- 分析这些产品主要流程,是否有可以优化的地方
- 列出必要功能,排出优先级
- 希望用户完成什么操作,用户能做什么
- 产品或者服务为用户提供什么
- 必须要的功能,有的话最好的功能,有没有都行的功能
- 严格划分资源和时间,来划定第一个版本
- 验证和迭代,用市场来验证项目,接收用户反馈
从需求推导出核心功能
发现用户的需求,然后根据这些需求从而确定出产品的核心功能,关键特性,这些功能是产品成功的基础。集中资源和时间来开发这些功能,而不是试图一次性实现所有的功能。
核心思想在于快
MVP 核心思想在于快,通过设定精确的目标,构建最小版本,快速发布,快速验证来构建产品。
这一步可以通过 [[Excalidraw]] Azure Figma 等等工具来快速构建自己的想法,交互流程,通过流程图,思维导图等等工具来构建用户交互界面。
如何验证
将产品推到市场获取潜在的客户之后,需要积极地手机用户反馈的数据,了解用户对产品的喜好,需求和问题。可以通过如下的方式来收集验证。
- 用户访谈,和真实用户沟通,这也是为什么欧美新创公司在产品测试阶段都喜欢直接和用户面对面聊天之后才开放试用权限
- 数据验证,埋点,转换率,观察用户是如何使用这个产品的,流程是否有优化的空间
- 使用 AB 测试
迭代
持续迭代是 MVP 思想另外一个重要的部分,持续改进和发展产品,逐步添加新功能和特性,来满足变化的用户需求。
我们从笔记软件的发展历程来看就能知道为什么迭代是如此重要。过去 10 年里面有一家成长为独角兽的公司 Evernote,但是随着互联网发的发展,协同编辑,以及 Markdown,双向链接的出现,即使是一款过去非常主流的笔记软件也会面临用户流失的问题。
MMF
与 MVP 类似的还有一个概念叫做 MMF,Minimum Marketable Feature,最小可销售特性。这个也是产品开发非常重要的一个概念,它强调的是在产品中添加最小限度可以被销售或交付的功能。与 MVP 不同,MMF 更侧重于产品的营销和销售能力,而不仅仅是验证产品概念和核心功能。
总结
最后使用 [[Marc Lou]] 的话来做一个总结,「忘记 SaaS,Passive income,The perfect co-founder,从一个 Feature,One-time Payment,Repeated small wins 开始」。1这句话恰好印证了 MVP 思想,核心功能,收费,然后不断验证并迭代更新。
related
- [[MMF]]
我购买了一台 Apple TV
在家里面我一直使用我的斐讯 T1 电视盒子,自己刷了系统之后,不需要更新,也没有烦人的软件升级,而且整个系统没有广告,在这样的情况下,我使用了近 5 年,对于一个不到 100 元的电视盒子来说实在是太值了,并且用到如今并没有出现任何较大的问题,正常情况下我使用 Kodi 观看本地网络磁盘中的 10 GB 左右的 1080p H264 视频也完全没有问题,并且 Android 生态的丰富程度,让我可以直接在 T1 上安装 Bilibili 客户端,也可以安装 YouTube,自建的 Plex,更不用说还有国内非常多的视频网站,以及丰富的直播应用,但一般情况下我使用最多的还是 Kodi,Bilibili,YouTube 和 Plex,然后还会进行一些 [[DLNA]] 投屏和串流,基本满足了我 99% 的需求。
但为什么我又要买一台 Apple TV 呢?原因主要有这么几点。
- 编解码,以及对 HDR,H265 的支持,我的 T1 无法解码 H265 视频并播放,所以一旦遇到 H265 编码的时候就只能放弃或者下载 H264 编码的视频
- Kodi 崩溃,Kodi 是一个非常强大的播放器和本地音视频管理,但是不清楚是 Kodi 自身的问题还是我通过网络磁盘播放视频的问题,极少数的情况下会让 Kodi 闪退,虽然遇到的情况不多,但是也非常影响使用体验
我的选择
所以我决定更新一下 T1,我有几个选项
- Nvidia Shield TV
- Amazon Fire TV Stick 4K 7480 JPY
- Google Chromecast with Google TV 7450 JPY
- Apple TV
因为很早就开始关注 Nvidia Shield TV,但是当时 T1 一直非常棒,所以没有淘汰的理由,从 2017 年关注到 2024 年,竟然只在 19 年更新了一次,之后 4 年该产品没有任何更新,所以肯定第一时间放弃了,我还在 Reddit 上的发帖问 Nvidia 还会更新吗,得到的网友回答是没有任何消息。
而 Amazon 的 Fire TV 和 Google 的 Chromecast 也是很早就开始关注,因为同是 Android 系统,所以很多 APK 可以直接安装,但是当时人在大陆,所以用起来肯定有一些水土不服,需要网络代理,很多应用还无法使用,所以非常干脆的不考虑,但是去年到东京居住那么这两个选项又放到了考虑选项,我在 Yodibashi 线下曾经尝试了一下 Chromecast,说实话没有我想象的那么流畅,所以当时就放弃了。而 FireTV, Amazon 经常做五折促销,一度想要下单,但也是忍住了,在 YouTube 上看了几个测评之后感觉还是一台不错的电视盒子。
而最后一个 Apple TV 本来是没有在考虑范围的,生态不丰富,没有 Kodi(安装起来非常麻烦),没有 Bilibili 客户端,我 90% 时间用的应用都没有,并且投屏似乎还不支持 [[DLNA]],Apple 有自己的一套自己的协议 AirPlay。但看了几个测评视频之后发现这些问题似乎目前都还都有解,Kodi 可以用 Infuse,VidHub 等播放器,Bilibili 客户端也有几个三方的客户端 Miao Project,Cheers,也可以选择投屏。而投屏和苹果的生态协作使用体验比较良好。
选择哪一款
确定好 Apple TV 之后,就开始调查 Apple TV 的具体型号。
历史型号对比
| 型号 | Model | 日版制品番号 | 发布年份 | 颜色 | 容量 | 视频输出 | 无线网络 | 蓝牙 | 发售价格 (¥) |
|---|---|---|---|---|---|---|---|---|---|
| Apple TV (第 1 代) | A1218 | MA711J/A(40GB) MB189J/A(160GB) | 2007 年 3 月 | 铝色 | 40GB | 720p | 802.11b/g | 无 | - |
| Apple TV(第 2 世代) | A1378 | MC572J/A | 2010 年 9 月 | 黑色 | 8GB | 1080p | 802.11n | 有 | 8,200 円+税 |
| Apple TV (第 3 代) | A1427 A1469(Rev A) |
MD199J/A | 2012 年 3 月 | 黑色 | 8GB | 1080p | 802.11a/b/g/n | 有 | 8,200 円+税 |
| Apple TV HD (第 4 世代) | A1625 | MHY93J/A 32 GB MGY52J/A(32GB) MLNC2J/A(64GB) |
2015 年 10 月 | 黑色 | 32GB 或 64GB | 1080p | 802.11ac | 有 | 32GB:18,400 円+税 64GB:24,800 円+税 |
| Apple TV 4K (第 1 代) | A1842 | MQD22J/A(32GB)MP7P2J/A (64GB) | 2017 年 9 月 | 黑色 | 32GB 或 64GB | 2160p (4K) | 802.11ac | 有 | 32GB:21,780 円(税込) 64GB:23,980 円(税込) |
| Apple TV 4K (第 2 代,MQD22J/A 32GB MXH02J/A 64GB) | A2169 | MXGY2J/A(32GB) MXH02J/A(64GB) |
2021 年 4 月 | 黑色 | 32GB 或 64GB | 2160p (4K) | 802.11ax (Wi-Fi 6) | 有 | 32GB:21,800 円(税込) 64GB:23,800 円(税込) |
| Apple TV 4K (第 3 代 ) | A2737(64GB) A2843(128GB) |
MN873J/A(64GB) MN893J/A(128GB) MN893X/A 64 澳洲版本 |
2022 年 4 月 | 黑色 | 64GB 或 128GB | 2160p (4K) | 802.11ax (Wi-Fi 6) | 有 | 64GB:19,800 円(税込) 128GB:23,800 円(税込) |
在简单的了解一下之后 Apple TV 4K 目前推出到了第三代(2022 年版本)
Apple TV 4K 第 2 代 -> 第 3 代升级
- CPU:A12 Bionic -> A15 Bionic
- 重量更轻 425g -> 208g/214g
- 遥控器接口 Lighting -> USB Type-C
- 最大容量 64GB -> 128 GB
- 增加了 HDR10+ 支持

综合上面的所有的升级内容,我个人判断这些升级对我目前的使用影响不大,所以就开始在 Mercari 订阅了关键字,正好这两天看到第二代 Apple TV 13410 JPY,看上去价格也合适就下单了。
使用
开机设置非常简单,直接按照指示手机靠近 Apple TV 就能关联上自动通过手机来进行初始化,这一点 Apple 的一贯性还是做的不错的。
应用
进入系统之后就是开始安装必要的初始化应用,来先满足我的基本需要,但是让我感到惊讶的是因为我已经通过 iOS 下载过 VidHub 所以 Apple TV 里面通过 iCloud 同步将我的配置都同步过去了,这一点还是非常舒服的。
- 本地播放器
- [[Infuse]] Infuse 是一款非常强大的 iOS 和 tvOS 视频播放器应用程序,它可以播放多种格式的视频文件,并从网络资源中流式传输视频内容。它还集成了 Trakt.tv 支持来跟踪你的观看历史记录,并具有美丽而简单的用户界面。
- [[VidHub]] 新晋本地播放器,缺点不支持杜比
- Fileball,本地播放器,可以连接网络共享,支持 SMB,FTP,SFTP,Synology,NFS,WebDAV 等,支持 Emby Jellyfin 等,还可以连接百度网盘,Box,Dropbox,Google Drive,OneDrive,pCloud 等,可以作为 Infuse 平替,高级版本价格也比较合适
- IIVA TestFlight 播放器
- Conflux
- Yunbox 点击下载,是一款支持阿里云盘、夸克网盘、WebDAV 等协议的多媒体播放器,支持多种云盘订阅管理,以原画质量播放媒体文件,支持各种高清视频格式如 MP4、MKV、AVI、FLV 等,支持 ass、ssa、sup 等多种格式字幕等。
- 在线影音库
- [[Plex]] / [[Emby]]
- 流媒体
- YouTube
- Netflix
- Disney+
- Amazon Prime Video
- VOD
- XPTV,TestFlight 已满
- CMSPlayer,UI 比较简陋的 VOD 播放器
- SyncNext,VOD 播放器
- VidPlay,支持 WebDAV,Alist,VOD 等协议
- 音乐播放器
- Musify,Yunbox 作者开发的音乐播放器,售价 3.99 USD,限免过,可以在 tvOS 上通过 WebDAV 播放音乐
- Vibefy TestFlight ,一款网易云播放器。
- 直播
- Simple Live GitHub
- Turnip Live TestFlight 直播
- Dazzle
- Bilibili
- 弹幕播放器 点击下载 Apple TV 上的 B 站客户端,限免过
- Miao Project,一款 Bilibili 第三方客户端,收费
- Cheers,Bilibili 客户端
- m3u
- BestTV 下载 Live Stream Player,售价 4.99 USD,限免过
- APTV,一款用于观看 IPTV 的应用,需要自行配置直播源
- 投屏,支持在 Android 设备上投屏
- UnPlay,支持 [[DLNA]] 协议
- DLPlay,支持 DLNA 投屏协议,1.99 USD/ 300JPY
- 工具
- SpeedTest 测试外网速度
- iPerf 测试内网速度
- TOP 查看当前 Apple TV 资源占用情况
- 网络
- [[Tailscale]]
- Shadowrocket
- Quantumult
- Surge
- sing-box
- Stash
- Loon
- Puff Glide
- Maomi
列举了上面这么多的应用,我实际使用最多,比较推荐的几个应用
- 本地视频播放 VidHub ,Fileball,Conflux
- 在线视频,YouTube,弹幕播放器
- 在线媒体库,Plex
- 投屏,DLPlay
VidPlay
VidPlay 一款 可高级玩法的 VOD 播放器
功能简介
- 支持 WebDAV 播放
- 支持 VOD 播放
- 支持 TVBOX json
- 支持 Alist
- 支持 小雅 玩偶 小纸条 JOJO 等高级玩法
▎ 目前 iOS 端正在开发适配中
- AppStore (https://apps.apple.com/us/app/vidplay/id6467240929)
- TestFlight (https://testflight.apple.com/join/EMf4MhpG)
VidPlay 交流群 (https://t.me/CubePlayer) VidPlay 高级玩法交流群 (https://t.me/+XHhN9aAZ8j5hZGY5)
UnPlay
UnPlay 是一款创新的时钟/投屏应用,为用户提供多样化的场景体验。不仅可以作为时钟, 还能使用 DLNA 协议推送流媒体到 Apple TV 上增加大屏体验
- 下载地址 https://apps.apple.com/us/app/unplay/id6450034641
- UnPlay 交流群 (https://t.me/yunatv123)
使用
Bilibili 投屏 Apple TV
- 确保您的 Apple TV 和手机/平板电脑(苹果设备)连接在同一个 Wi-Fi 网络下
- 在您的 iOS 设备上,下载并安装 Bilibili 客户端
- 打开 Bilibili 客户端,并找到您想要投屏的视频
- 下拉菜单,选择屏幕镜像(Mirror)
- 在弹出的菜单中,选择您的 Apple TV 设备,然后等待连接
- 连接成功后,您的视频将会自动开始在 Apple TV 上投屏播放
需要注意的是,如果您的 Apple TV 和苹果设备没有连接在同一个 Wi-Fi 网络下,投屏可能会失败。
其他未研究
- TrollDecrypt-tvOS 从 tvOS 中提取 ipa
Datadog 日志搜索语法总结
Datadog 成立于 2010 年,是一家面向开发者、IT 运维团队及业务人员的云监控平台公司,致力于为企业客户提供底层系统和上层应用的实时监控、分析能力。
日志管理产品,可观测数据 log, metric, trace 集一身的方案。Datadog 的日志查询有一套自己的语法,但是都比较好了解,所以这里也整理一下。
概述 Overview
查询过滤器由两部分组成 terms (术语) 和 operators(运算符)。
两种类型的术语:
- single term 是一个单词,比如
test - sequence 是一组通过双引号包围的短语,比如
hello world
将多个术语通过如下的操作符组成形成复杂的查询语句。
- AND,满足所有条件
- OR,任意术语包含
- -,术语不包含
Escape special characters and spaces
下面这一些是特殊字符
+ - = && || > < ! ( ) { } [ ] ^ " “ ” ~ * ? : \
如果要查询这些特殊字符需要使用 \ 来转义。
属性搜索
按照特定的属性进行搜索,可以使用 @ 指定。
比如想要查询 url 是 example.com 的记录
@url:example.com
更多例子
@http.url_details.path:"/api/v1/test"搜索 http.url_details.path 中与/api/v1/test匹配的所有日志@http.url:\/api\/v1\/*搜索包含以/api/v1开头的http.url属性中的值的所有日志@http.status_code:[200 TO 299] @http.url_details.path:\/api\/v1\/*包含范围 code 和以/api/v1开头的属性的日志-@http.status_code:*搜索不包含属性的日志
通配符
?匹配单个字符*通配
数值
比如所有的接口请求都有延迟
@http.response_time:>1000
或者搜索特定的范围
@http.status_code:[400 TO 499]
标签 Tags
匹配带有标签 env:prod 或标签 env:test 的所有日志
env:(prod OR test)
匹配包含标签 env:prod 且不包含标签 version:beta 的日志
(env:prod AND -version:beta)
文章分类
最近文章
- AI Shell 让 AI 在命令行下提供 Shell 命令 AI Shell 是一款在命令行下的 AI 自动补全工具,当你想要实现一个功能,敲一大段命令又记不住的时候,使用自然语言让 AI 给你生成一个可执行的命令,然后确认之后执行。
- 最棒的 Navidrome 音乐客户端 Sonixd(Feishin) Sonixd 是一款跨平台的音乐播放器,可以使用 [[Subsonic API]],兼容 Jellyfin,[[Navidrome]],Airsonic,Airsonic-Advanced,Gonic,Astiga 等等服务端。 Sonixd 是一款跨平台的音乐播放器,可以使用 [[Subsonic API]],兼容 Jellyfin,[[Navidrome]],Airsonic,Airsonic-Advanced,Gonic,Astiga 等等服务端。
- 中心化加密货币交易所 Gate 注册以及认证 Gate.io 是一个中心化的加密货币交易所。Gate 中文通常被称为「芝麻开门」,Gate 创立于 2013 年,前身是比特儿,是一家致力于安全、稳定的数字货币交易所,支持超过 1600 种数字货币的交易,提供超过 2700 个交易对。
- 不重启的情况下重新加载 rTorrent 配置文件 因为我在 Screen 下使用 rTorrent,最近经常调试修改 rtorrent.rc 配置文件,所以想要找一个方法可以在不重启 rTorrent 的情况重新加载配置文件,网上调查了一下之后发现原来挺简单的。
- Go 语言编写的网络穿透工具 chisel chisel 是一个在 HTTP 协议上的 TCP/UDP 隧道,使用 Go 语言编写,10.9 K 星星。