使用 Husky 来管理 git hook
今天在 GitHub 上看到一个 repo,在其根目录中包含了一个 .husky 的文件夹,好奇之下就去搜索了以,于是发现了 husky 这个项目,这是一个使用 JavaScript 实现的用来管理 Git hooks 的工具。
GitHub: https://github.com/typicode/husky
什么是 Git hook
首先要先了解一下 Git hooks,对于 git 已经是现代开发中必不可少的一个工具了,大家应该都比较熟悉,但是可能很多人在项目中并没有使用过 Git 的 hooks。
Git 的 hooks 允许用户在特定的时机执行用户自定义的脚本。
比如非常常见的,在提交之后自动对代码内容进行一些常规检查,如果失败则不允许提交等等。常用的 hook 有 pre-commit, commit-msg,pre-push 等。
Git hooks 是基于事件的,Scott Chacon 在 Pro Git 书中将 hooks 分成几个类型:
- 客户端 hook,在使用者自己的本地环境中被调用。
- 代码提交相关的 hook,在提交动作前后,通常用于检查完整性,生成提交信息,校验,发出通知等等
- Email 相关的 hook,主要用于 Email 提交的代码。像 Linux 内核使用 Email 提交补丁会使用到。工作方式和提交类 hook 相似
- 其他类,包括代码合并,check-out,rebase,rewrite,clean 等等
- 服务端 hook,一般在服务器端执行,用于接受推送,部署在 git 仓库的服务器上
- 触发类,在服务器接收到一个推送之前或之后执行动作,前触发用于检查,后触发用于部署
- 更新,类似前触发,更新的 hook 是以分支作为作用对象,在分支更新通过之前执行
hook 列表:
| hook 名称 | 触发命令 | 描述 | 参数个数描述 |
|---|---|---|---|
applypatch-msg |
git am |
编辑 commit 时提交的 message,通常用于验证或纠正提交的信息以符合项目标准 | 包含预备提交信息的文件名 |
pre-applypath |
git am |
变更 commit 之前,如果以非 0 退出,会导致 uncommit 状态,用于 commit 之前的检查 | |
pre-applypath |
git am |
commit 完成提交之后,主要用于通知 | |
pre-commit |
git commit |
获取 commit message 之前,非 0 退出会取消本次 commit,检查 commit 自身,而不是 commit message | |
prepare-commit-msg |
git commit |
接收默认 commit message 之后,启动 commit message 编辑器之前。 | |
commit-msg |
git commit |
message 提交之后修改 message 的内容或退回不合格的 commit | |
post-commit |
git commit |
commit 完成之后调用,主要用于通知 | |
pre-rebase |
git rebase |
执行 rebase 时,可用于中断不想要的 rebase | |
post-checkout |
git checkout 和 git clone |
更新工作树后调用 checkout 时,或执行 git clone 后,主要用于验证环境、显示变更、配置环境 | |
post-merge |
git merge or git pull |
合并之后调用 | |
pre-push |
git push |
推送远程之前 | |
pre-receive |
远程 repo 进行 git-receive-pack |
远程 repo 更新刚被 push 的 ref 之前调用,非 0 会中断本次 | |
update |
远程 repo 进行 git-receive-pack |
远程 repo 每一次 ref 被 push 的时候调用 | |
post-receive |
远程 repo 进行 git-receive-pack |
远程 repo 所有的 ref 更新之后 | |
post-update |
git-receive-pack |
所有 ref 被 push 后执行一次 | |
pre-auto-gc |
git gc --auto |
用于在自动清理 repo 之前做一些检查 | |
post-rewrite |
git commit --amend 或 git rebase |
git 命令重写 rewrite 已经被 commit 的数据时调用 |
在 .git 这个隐藏的文件目录下,有一个 hooks/ 文件夹,下面通常会有一些 sample 文件。如果要使其生效,去掉后缀 sample 即可
目录下的每一个文件都是可执行的文件,脚本通过文件名调用,内容的第一行必须有 Shebang #!,引用正确的脚本解析器,比如 bash, perl, python, nodejs 等。Git hooks 使用的脚本语言是没有限制的。
比如在 pre-commit 中执行代码检查:
#!/bin/sh
npm run lint
# 获取上面脚本的退出码
exitCode="$?"
exit $exitCode
什么是 Husky
通过上面的简单了解也可能看到本地的 git hook 是保存在本地的 .git 文件夹中的,本地的 git hook 是不会被提交到版本控制中的。这就存在了一个问题,便是如何在项目中管理 Git hooks,这个时候就需要 Husky 登场了。
目前已经有非常多的项目在使用 husky 了,包括:
- webpack
- babel
- create-react-app
Husky 的原理就是在项目的根目录中使用一个配置文件,然后在安装 Husky 的时候把配置文件和 Git hook 关联起来,在团队之间共享。
安装
安装:
npm install husky --save-dev
在项目中安装:
npx husky install
配置 Husky
使用 Husky 之前确保安装了 npm。
npm install husky -D
Husky 支持如下几种格式配置:
- .huskyrc
- .huskyrc.json
- .huskyrc.yaml
- .huskyrc.yml
- .huskyrc.js
- husky.config.js
以 .huskyrc 为例:
{
"hooks": {
"pre-commit": "git restore -W -S dist examples/dist && eslint ."
}
}
这一个例子就是每次执行 git commit 之前把 dist 和 examples/dist 中的修改撤掉,不提交到仓库中,然后执行 EsLint。
Husky 原理
Husky 做了两件事情:
- 创建
~/.husky目录 husky install时设置~/.husky目录为git hooks目录。
创建 Hook
使用 husky add:
npx husky add .husky/commit-msg 'npx --no-install commitlint --edit "$1"'
卸载还原 Husky
npm uninstall husky
// 删除.husky文件夹,并且重置core.hooksPath
rm -rf .husky && git config --unset core.hooksPath
Husky 注意事项
Husky 不支持服务端 hooks。
包括 pre-receive、update、post-receive 。
如果想跳过所有的 hooks,可以使用:
HUSKY_SKIP_HOOKS=1 git rebase ...
不使用 Husky 同步 Git hooks
在 git 2.9 中引入了 core.hooksPath 配置,可以手动配置 git hooks 所在的目录。这也就使得我们可以在另外的目录中创建 Git hooks,然后手动设置 Hooks 目录来实现 hooks 脚本的同步。
reference
每天学习一个命令:tail 输出文件的最后部分内容
tail 命令是一个日常查看日志非常常用的命令,用来在终端显示文件的最后部分内容。
用例
tail 不加任何参数的情况下,默认显示文件最后 10 行内容。
tail /path/to/file.log
显示文件追加的内容
通常业务系统中以文件形式记录日志时会一直追加到文件末尾,可以使用 -f 来显示新追加的内容:
tail -f /path/to/file.log
显示文件结尾 100 行
tail -100 mail.log
tail -n 100 mail.log
显示文件第20行至末尾
tail -n +20 mail.log
显示结尾10个字符
tail -c 10 mail.log
Gatsby 静态站点使用入门
Gatsby 是一个基于 [[React]] 的、免费开源的、用于搭建静态站点的框架。Gatsby 虽然是一个静态站点框架,但其数据却可以从任何地方获取之后渲染。 Gatsby 是基于 React 和 [[GraphQL]]。 结合了 webpack, babel, react-router 等前端领域中最先进的工具。 对开发人员来说开发体验非常好。
Gatsby 采用数据层和 UI 层分离的现代前端开发模式。静态 HTML 访问快,对 SEO 非常友好。
数据来源多样化: Headless CMS, markdown, API 等多种方式获取数据。
之前学习的时候建的券商推荐网站 就是使用 Gatsby 搭建。
为什么使用 Gatsby
- 充分享受现代 Web 开发工具带来的便捷,GraphQL,React,Webpack
- 数据与界面的分离
- 丰富的插件生态系统
Gatsby 项目结构
/src/pages目录下的组件会被生成同名页面/src/templates目录下放渲染数据的模板组件,如渲染 Markdown 文章,在其它博客系统中一般叫 layout。/src/components公共可复用的组件/static静态资源, webpack 会跳过gatsby-config.js配置- siteMetadata 全局配置
- plugins 插件配置
gatsby-node.js可以调用 Gatsby node APIs- 添加额外的配置
gatsby-browser.js调用 Gatsby 浏览器 API
GraphQL
作为 Gatsby 在本地管理资源的一种方式,作为一个数据库查询语言,它有非常完备的查询语句。
在 src/pages 下的页面可以直接 export GraphQL 查询,在其它页面需要用 StaticQuery 组件或者 useStaticQuery hook。
在开发时默认的查询地址: http://localhost:8000
Installation
Gatsby 命令行:
npm install -g gatsby-cli
新建项目:
gatsby new gatsby-start
gatsby 默认会使用 gatsby-starter-default 来新建项目,你可以在后面加上其他 starter 的 GitHub 地址,来使用这个 starter 初始化项目。比如说:
gatsby new gatsby-start https://github.com/gatsbyjs/gatsby-starter-hello-world
启动项目:
cd gatsby-start
gatsby develop
# 或者
yarn develop
打开 localhost:8080 查看生成页面,可以打开 http://localhost:8000/__graphiql GraphiQL 调试界面。
几个常用的命令:
- gastby develop:开启热加载开发环境
- gastby build:打包到 public 下,构建生产环境用的优化过的静态网站所需的一切静态资源、静态页面与 js 代码
- gatsby serve:在打包之后,启动一个本地的服务,供你测试刚才”gatsby build”生成的静态网页
在 src/pages/` 目录下,新建一个 JS 文件即可。在 src/pages/ 目录下的页面,Gatsby 会自动添加路由,生成页面。
新建 about.js
import React from 'react'
export default () => (
<div>
<h1>About</h1>
<p>location: </p>
</div>
)
访问 http://localhost:8000/about 即可查看。
Plugins
在 Gatsby 中有三种类型的插件: 分别为数据源插件 ( source ), 数据转换插件 ( transformer ), 功能插件 ( plugin )
- 数据源插件负责从应用外部获取数据,将数据统一放在 Gatsby 的数据层中。
- 数据转换插件负责转换特定类型的数据的格式,比如我们可以将 markdown 文件中的内容转换为对象形式。
- 功能插件是为应用提供功能,比如通过插件让应用支持 Less 或者 [[TypeScript]]。
插件的命名是有规范的,数据源插件名称中必须包含 source,数据转换插件必须包含 transformer,功能插件名称必须包含 plugin。
所有插件的地址:https://www.gatsbyjs.org/plugins/
插件的使用
- 首先需要下载插件,npm install
- 在根目录的 gatsby-config.js 文件中配置插件,在 plugins 属性中添加我们的插件。
plugins 是一个数组,每一项都是一个插件,他支持字符串和对象两种类型,如果需要配置插件参数就是用对象,resolve 指明要配置什么插件,options 就是配置选项,name 表示资源类别,这个是自定义的这里写 json,path 是数据源文件路径。
modules.exports = {
plugins: [
{
resolve: "gatsby-source-filesystem",
options: {
name: "json",
path: `${__dirname}/data.json`
}
},
"gatsby-transformer-json"
]
}
gatsby-source-filesystem 他是用于将本地文件信息添加至数据层当中
第二个是 gatsby-plugin-sharp:他是用于提供本地图像的处理功能(调整图像尺寸, 压缩图像体积 等等) 第三个是 gatsby-transformer-sharp 是将 gatsby-plugin-sharp 插件处理后的图像信息添加到数据层。
最后我们要用到 gatsby-image,这是一个 React 组件, 优化图像显示, 他是基于 gatsby-transformer-sharp 插件转化后的数据。
gatsby-plugin-image
安装:
npm install gatsby-plugin-image gatsby-plugin-sharp gatsby-source-filesystem
- gatsby-plugin-sharp 处理图片
- gatsby-source-filesystem,从文件系统加载图片
通过 YAML 加载数据
-
https://www.gatsbyjs.com/docs/how-to/sourcing-data/sourcing-from-json-or-yaml/
- The
StaticImagecomponent is for static image sources, like a hard-coded file path or remote URL. In other words, the source for your image is always going to be the same every time the component renders. - The
GatsbyImagecomponent is for dynamic image sources, like if the image source gets passed in as a prop.
https://www.gatsbyjs.com/docs/tutorial/part-7/#whats-the-difference-between-gatsbyimage-and-staticimage
https://www.gingerdoc.com/tutorials/how-to-handle-images-with-graphql-and-the-gatsby-image-api
https://www.labnol.org/code/gatsby-images-200607
Netlify
[[2018-03-24-netlify-to-host-static-website]]
reference
Nginx 中数据 Buffer size 相关配置
client_body_buffer_size
Nginx 分配给请求数据的 Buffer 大小,如果请求的数据小于 client_body_buffer_size ,那么 Nginx 会在内存中存储数据,如果请求的内容大小大于 client_body_buffer_size,但是小于 client_max_body_size,会先将数据存储到临时文件中。
默认的情况下,这个缓存大小是等于两个 memory pages,也就是在 x86 机器上是 8K,在 64-bit 平台上是 16K。
这个空间只有当请求有上传的时候才会被用到,一旦数据被传输到后端服务,内存就会被清空。这意味着你需要足够的内存空间来保存并发的上传,否则服务器会开始 swapping。
client_body_temp 指定的路径,默认是 /tmp/ 所配置的 client_body_temp 地址,一定让 Nginx 用户组有读写权限。否则当传输的数据大于 client_body_buffer_size 是写入临时文件会报错。
open() /nginx/client_body_temp/0000000019” failed (13: Permission denied)
在接口层面的表现为接口请求返回 403
client_max_body_size 默认大小是 1M,客户端请求服务器最大允许大小,如果请求正文数据大于 client_max_body_size 的值,那么 HTTP 协议会报错 413 Request Entity Too Large。 正文大于 client_max_body_size 一定是失败的,如果要上传大文件需要修改该值。
client_max_body_size 优先级
- 可以选择在
http{ }中设置:client_max_body_size 20m; - 也可以选择在
server{ }中设置:client_max_body_size 20m; - 还可以选择在
location{ }中设置:client_max_body_size 20m;
三者到区别是:http{} 中控制着所有nginx收到的请求。而报文大小限制设置在server{}中,则控制该server收到的请求报文大小,同理,如果配置在location中,则报文大小限制,只对匹配了location 路由规则的请求生效。
reference
Laravel 学习笔记:Blade Component
Blade 模板中的 Components 提供了和 section, layout 和 includes 相似的机制。都可以用来复用构造的 Blade 模板。
但 Component 更容易理解,提供了两种方式:
- class based components
- anonymous components
使用命令创建:
php artisan make:component Alert
创建的文件在 App\View\Components 目录。
make:component 命令会创建一个 template 在 resources/views/components 目录中。
也能在子目录中创建 Components:
php artisan make:component Forms/Input
如果传参 --view:
php artisan make:component forms.input --view
就不会创建 class,只会创建模板。
Laravel 学习笔记:部署到生产环境
在本地开发调试的时候使用了 Laravel 提供的 Sail 依赖本地的 Docker 环境,Sail 提供了 Nginx,MySQL,Redis,等等容器,还提供了一个用于测试的 SMTP mailhog,但是生产环境可以使用更加稳定的组件。
Requirements
Laravel 应用需要一些基础的系统依赖,需要确保Web 服务器有如下的最低要求:
- PHP >= 8.0
- BCMath PHP Extension
- Ctype PHP Extension
- cURL PHP Extension
- DOM PHP Extension
- Fileinfo PHP Extension
- JSON PHP Extension
- Mbstring PHP Extension
- OpenSSL PHP Extension
- PCRE PHP Extension
- PDO PHP Extension
- Tokenizer PHP Extension
- XML PHP Extension
Nginx
Web 服务器就用 Nginx。
记住 Web 服务器所有的请求都会先到 public/index.php 文件,千万不要将此文件放到项目的根目录,或者 Web 服务器的根目录,如果 Web 服务器可以访问项目根目录会造成带有敏感信息的配置文件泄漏。
server {
listen 80;
server_name example.com;
root /srv/example.com/public;
add_header X-Frame-Options "SAMEORIGIN";
add_header X-XSS-Protection "1; mode=block";
add_header X-Content-Type-Options "nosniff";
index index.php;
charset utf-8;
location / {
try_files $uri $uri/ /index.php?$query_string;
}
location = /favicon.ico { access_log off; log_not_found off; }
location = /robots.txt { access_log off; log_not_found off; }
error_page 404 /index.php;
location ~ \.php$ {
fastcgi_pass unix:/var/run/php/php7.4-fpm.sock;
fastcgi_param SCRIPT_FILENAME $realpath_root$fastcgi_script_name;
include fastcgi_params;
}
location ~ /\.(?!well-known).* {
deny all;
}
}
部署过程
这里使用 [[aapanel]] 来新建一个站点。
然后将代码 push 到 GitHub,然后到机器上 push 来下。
cp .env.example .env
根据自己的配置,修改数据库、Redis、SMTP 相关的配置。
执行:
sudo composer install
注意将站点的所有者修改为 www:
sudo chown -R www:www .
然后执行:
sudo php artisan key:generate
sudo php artisan migrate
禁用 php 方法:
proc_opensymlinkpcntl_signalpcntl_alarm
Composer
安装 Composer:
wget https://getcomposer.org/download/1.8.0/composer.phar
mv composer.phar /usr/local/bin/composer
chmod u+x /usr/local/bin/composer
composer -V
自动加载优化:
composer install --optimize-autoloader --no-dev
优化配置加载,将配置文件压缩到一个缓存中
php artisan config:cache
优化路由加载:
php artisan route:cache
优化视图加载
php artisan view:cache
问题
如果遇到如下问题:
PHP Fatal error: Uncaught Error: Call to undefined function Composer\XdebugHandler\putenv() in phar:///usr/local/bin/composer/vendor/composer/xdebug-handler/src/Process.php:101
Stack trace:
#0 phar:///usr/local/bin/composer/vendor/composer/xdebug-handler/src/Status.php(59): Composer\XdebugHandler\Process::setEnv()
#1 phar:///usr/local/bin/composer/vendor/composer/xdebug-handler/src/XdebugHandler.php(99): Composer\XdebugHandler\Status->__construct()
#2 phar:///usr/local/bin/composer/bin/composer(18): Composer\XdebugHandler\XdebugHandler->__construct()
#3 /usr/local/bin/composer(29): require('...')
#4 {main}
thrown in phar:///usr/local/bin/composer/vendor/composer/xdebug-handler/src/Process.php on line 101
Fatal error: Uncaught Error: Call to undefined function Composer\XdebugHandler\putenv() in phar:///usr/local/bin/composer/vendor/composer/xdebug-handler/src/Process.php:101
Stack trace:
#0 phar:///usr/local/bin/composer/vendor/composer/xdebug-handler/src/Status.php(59): Composer\XdebugHandler\Process::setEnv()
#1 phar:///usr/local/bin/composer/vendor/composer/xdebug-handler/src/XdebugHandler.php(99): Composer\XdebugHandler\Status->__construct()
#2 phar:///usr/local/bin/composer/bin/composer(18): Composer\XdebugHandler\XdebugHandler->__construct()
#3 /usr/local/bin/composer(29): require('...')
#4 {main}
thrown in phar:///usr/local/bin/composer/vendor/composer/xdebug-handler/src/Process.php on line 101
需要禁用 php 的 putenv 方法。
Laravel 学习笔记:本地化
通过 Laravel 的样例项目也应该能看到 Laravel 对本地化多语言的支持代码了。
观察一下项目的目录结构就能猜出来语言文件在 resources/lang 中。目录结构需要按照 ISO 15897 标准来命令,简体中文 zh_CN
/resources
/lang
/en
messages.php
/es
messages.php
可以看到所有的语言文件都是返回一个 key-value 结构。
JSON 文件
Laravel 还可以定义 JSON 文件,存放在 resources/lang 下,如果是中文则是 resources/lang/zh_CN.json 文件:
{
"welcome": "欢迎来到 EV 的 Blog"
}
配置 Locale
在 config/app.php 中可以配置网站语言。
使用翻译
可以使用 __ 辅助函数来从语言文件中获取翻译。
echo __('welcome')
在 Blade 模板引擎中,可以直接在 `` 中使用:
如果翻译字符不存在,则直接返回字符串。
翻译占位符
如果翻译字符串中有需要变动的变量,可以使用 : 来将其定义为占位符:
'welcome' => 'Welcome, :name',
然后在获取的时候传入一个数组用于替换:
echo __('welcome', ['name' => 'laravel']);
利用 Cloudflare 和 Gmail 配置域名邮箱的收发
早在 2022 年年初的时候 Cloudflare 就推出了 Email Routing 的服务,在第一时间就从 Google Domains 中迁移到了 Cloudflare,中间好像也没有遇到什么问题,正常的收到域名邮箱的邮件,转发到 Gmail。
Cloudflare Email Routing (beta) is designed to simplify the way you create and manage email addresses, without needing to keep an eye on additional mailboxes. With Email Routing, you can create any number of custom email addresses that you can use in situations where you do not want to share your primary email address, such as when you subscribe to a new service or newsletter. Emails are then routed to your preferred email inbox, without you ever having to expose your primary email address.
Email Routing is free and private by design. Cloudflare will not store or access the emails routed to your inbox.
Prerequisites
- 首先需要将域名添加到 Cloudflare
- Cloudflare 已经开通 Email Routing 功能
- 一个可以接收 Email Routing 的 Gmail 邮箱
接收邮件
Cloudflare 接收邮件的设置非常简单,在页面中可以创建自定义地址的域名邮箱,然后自动转发至指定的首选邮箱。也可以设置 Catch-all 将所有发送至域名邮箱的邮件,即使没有定义前缀也全部转发到指定邮箱。
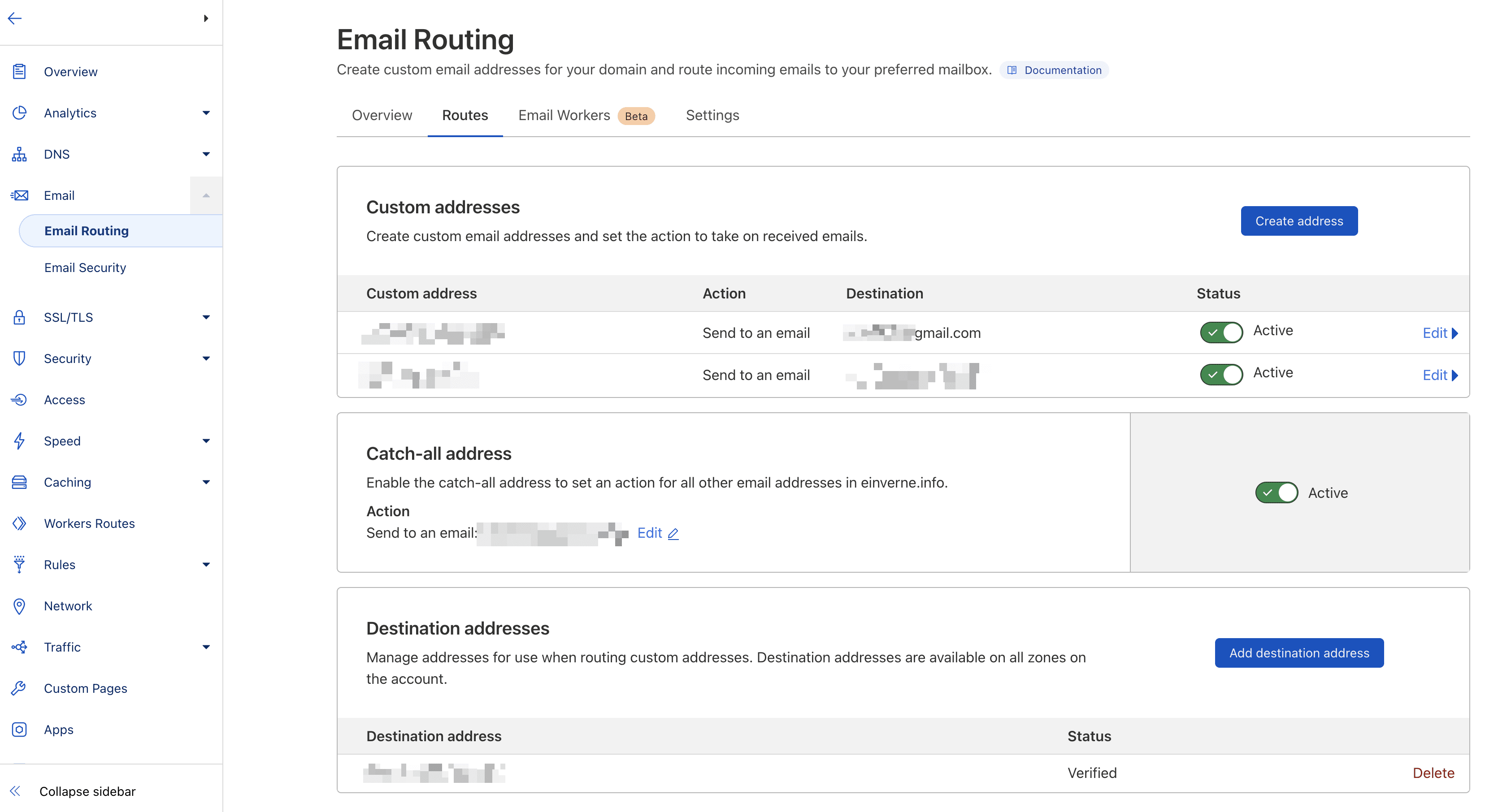
具体步骤:
- 点击电子邮件 -> 开始使用
- 创建自定义邮件地址
- 会收到一封验证电子邮件路由地址邮件,点击验证电子邮箱地址,验证成功后会提示启用电子邮件路由,点击添加记录并启用
- Cloudflare 会自动设置 DNS 记录
随后发往该域名邮箱的所有邮件都会通过 Cloudflare 转发到指定的 Gmail 中。
发送邮件
使用 Cloudflare 的域名邮箱发送邮件则需要用到 Gmail 中的设定。Cloudflare Email Routing 自身是不支持发送邮件的。但可以通过如下方法实现域名邮箱的发送:
- Gmail SMTP
- [[sendinblue]] 等等第三方邮件发送服务提供商
- [[AWS SES]] 邮件发送服务
首先要生成应用专用密码,主要用来代替密码来登录 Gmail,如下图,记住生成的密码。
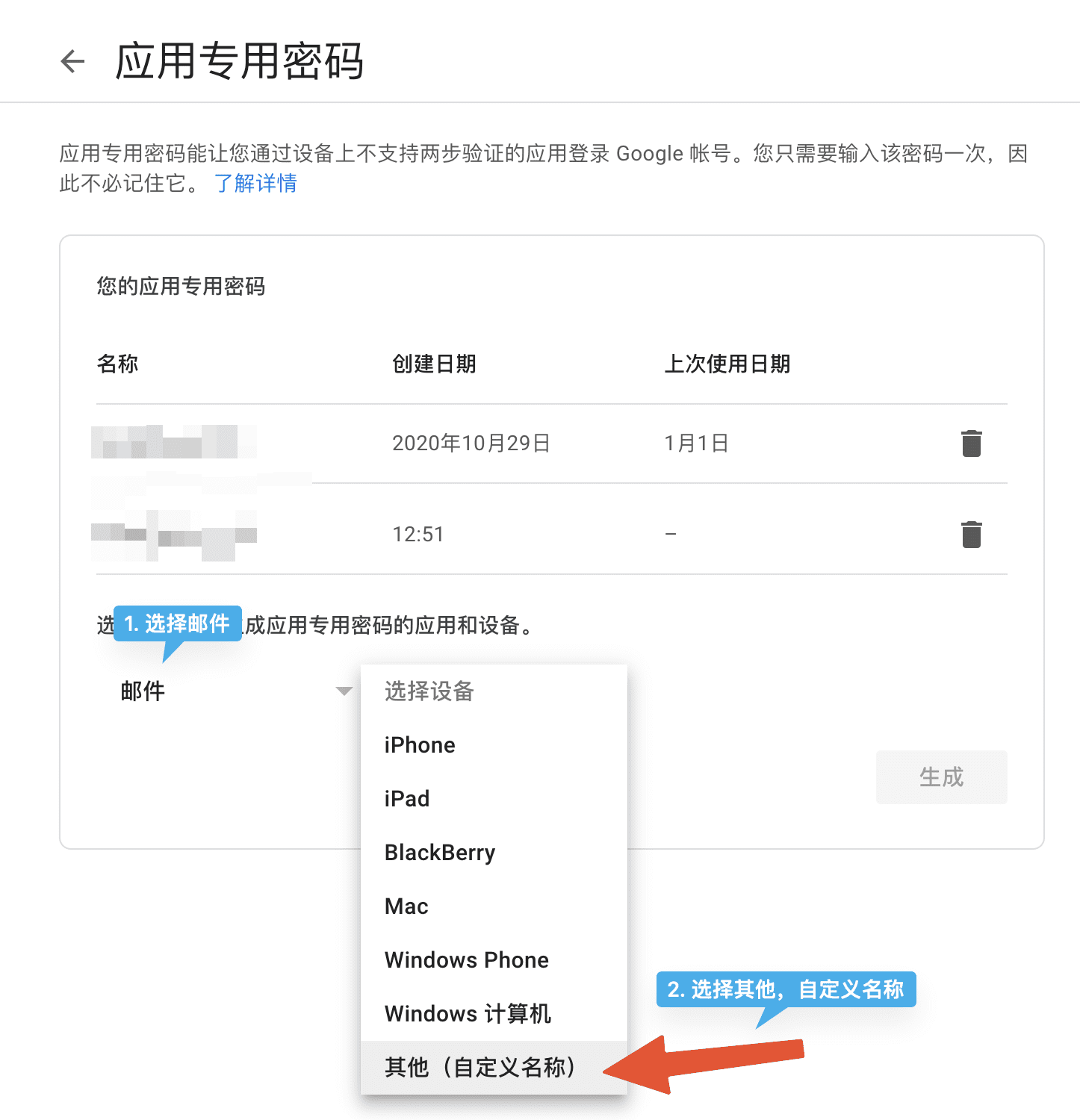
然后打开 Gmail,点击「Settings」,在所有的设置中,找到 「Accounts and Import」,在「Send mail as」中,点击「Add another email address」。
在弹出的对话框中设置「Name」和 「Email address」:
- 邮箱名字用于发送邮件的默认名,会显示在邮件上
- 域名邮箱地址填写 Cloudflare 中配置的邮箱,确保可以接收邮件
然后进入下一步:
- SMTP 填写
smtp.gmail.com - port 端口默认
- username 填写 Gmail 账号
- password 填写之前获取的专属应用密码
填写成功之后,需要填入验证码,域名邮箱会收到一份邮件,包含验证码,在页面上填入即可。
完成配置之后,在发送邮件的时候就可以选择自定义的邮箱了。
不过需要注意的是,通过 Gmail 代发的邮件在 QQ 邮箱,163 邮箱等邮箱中会显示代发邮箱本身,并且会出现「此地址未验证,请注意识别」等等字样。如果介意这一点,可能还是需要找一家正规的域名邮箱服务提供商比较合适。我也在提供付费的域名邮箱服务,如果感兴趣可以点击这里。
使用 ed25519 SSH Key 代替 RSA 密钥
什么是 ed25519
ed25519 是一个相对较新的加密算法,实现了 Edwards-curve Digital Signature Algorithm(EdDSA)。但实际上 ed25519 早已经在 5 年前就被 OpenSSH 实现,并不算什么前沿科技。但很多人,即使是每天都使用 SSH/SCP 的人可能并不清楚这个新类型 key。
不过要注意的是并不是所有的软件目前都实现了 ed25519,但是大多数最近的操作系统 SSH 都已经支持了。
ed25519 的好处
- 相较于 RSA key,最明显的一个好处就是 ed25519 key 非常短,这就非常方便存储以及传输 key
- 另外就是产生和校验更快
- collision resilience,这意味着可以有效的避免 hash 碰撞攻击
生成 ed25519 SSH key
ssh-keygen -t ed25519 -C "your@gmail.com"
可以检查 ~/.ssh 目录下的 key,会发现 ed25519 的公钥只有简短的一行:
ssh-ed25519 AAAACxxxx your@gmail.com
Laravel 学习笔记:Model Factoris 批量创建假数据
在开发环节要测试的时候,如果想要在数据库中批量插入一些假数据,这个时候就可以使用 model factories。
在 database/factories/ 目录下面默认定义了一个 UserFactory.php
namespace Database\Factories;
use Illuminate\Database\Eloquent\Factories\Factory;
use Illuminate\Support\Str;
class UserFactory extends Factory
{
/**
* Define the model's default state.
*
* @return array
*/
public function definition()
{
return [
'name' => $this->faker->name(),
'email' => $this->faker->unique()->safeEmail(),
'email_verified_at' => now(),
'password' => '$2y$10$92IXUNpkjO0rOQ5byMi.Ye4oKoEa3Ro9llC/.og/at2.uheWG/igi', // password
'remember_token' => Str::random(10),
];
}
}
可以看到在这个类中给 User 的每一个字段都设置了一个 faker 方法。
产生 Factories
通过命令:
php artisan make:factory UserFactory
这个时候在 database/factories 下面就会有一个 UserFactory,你需要按照 faker 的方式给 Model 每一个自定义的字段都加上 fake 方式。
tinker
然后执行 tinker:
php artisan tinker
进入交互式命令行之后:
use App\Models\User;
User::factory(10)->create();
执行完成之后就会往数据库中插入 10 条假数据。
文章分类
最近文章
- AI Shell 让 AI 在命令行下提供 Shell 命令 AI Shell 是一款在命令行下的 AI 自动补全工具,当你想要实现一个功能,敲一大段命令又记不住的时候,使用自然语言让 AI 给你生成一个可执行的命令,然后确认之后执行。
- 最棒的 Navidrome 音乐客户端 Sonixd(Feishin) Sonixd 是一款跨平台的音乐播放器,可以使用 [[Subsonic API]],兼容 Jellyfin,[[Navidrome]],Airsonic,Airsonic-Advanced,Gonic,Astiga 等等服务端。 Sonixd 是一款跨平台的音乐播放器,可以使用 [[Subsonic API]],兼容 Jellyfin,[[Navidrome]],Airsonic,Airsonic-Advanced,Gonic,Astiga 等等服务端。
- 中心化加密货币交易所 Gate 注册以及认证 Gate.io 是一个中心化的加密货币交易所。Gate 中文通常被称为「芝麻开门」,Gate 创立于 2013 年,前身是比特儿,是一家致力于安全、稳定的数字货币交易所,支持超过 1600 种数字货币的交易,提供超过 2700 个交易对。
- 不重启的情况下重新加载 rTorrent 配置文件 因为我在 Screen 下使用 rTorrent,最近经常调试修改 rtorrent.rc 配置文件,所以想要找一个方法可以在不重启 rTorrent 的情况重新加载配置文件,网上调查了一下之后发现原来挺简单的。
- Go 语言编写的网络穿透工具 chisel chisel 是一个在 HTTP 协议上的 TCP/UDP 隧道,使用 Go 语言编写,10.9 K 星星。