解决 Clash for Windows 节点测速 timeout 问题
[[Clash for Windows]] 使用过程中一直没有什么问题,但是昨天心血来潮把 Clash for Windows 从 0.18.8 升级到了最新版本(0.20.5) ,然后发现节点全部 timeout。但可以排除的是这些节点肯定是可以用的,因为在手机上是完全没有问题的。
先是看 Logs 日志里面,timeout 的节点有大量的错误:
22:06:18 WRN [UDP] dial failed error=new vmess client error: dial xxxx:7830 error: 404 Not Found proxy=GLOBAL rAddr=114.114.114.114:53
查询了一通之后发现可能与 Clash Core 版本 升级 有关系,
查看了一下 Clash 的 Release Note ,在 1.90.0 的 Change Logs 中有一行:
注意vmess下的 ws-headers 和 ws-path 选项已更新
原来 Clash Core 新版本中把配置文件的 ws-headers 和 ws-path 改了个名字
ws-pathws-headers
这两个配置项变成了如下的结构:
ws-opts:
path: /path
headers:
Host: somehost.com
完整配置示例:
# VMess
- name: "v2ray"
type: vmess
server: xxx
port: 443
uuid: 8b0edc
alterId: 0
cipher: auto
# udp: true
tls: true
# skip-cert-verify: true
network: ws
ws-opts:
path: /xxx
headers:
Host: xxxx.com
JSON 格式:
proxies:
- { name: '美国', type: vmess, server: some.pw, port: 6000, uuid: ccfb9fb3, alterId: 0, cipher: auto, udp: true, network: ws, ws-opts: { path: /, headers: { Host: some.com } }, ws-path: /, ws-headers: { Host: some.com } }
如果不想自己配置,那么可以注册使用这个站点。
其他 timeout 原因
另外一个可能引起 timeout 的原因可能是 Clash 的配置中开启了 DNS
dns:
enable: true
ipv6: false
开启了 DNS 之后,clash 会将域名解析发送给配置的 nameserver 解析,如果域名解析失败也会发生 timeout 情况。
其他原因:
- 节点配置错误
- 节点无法访问
- 配置的 url-test 中的 url 设置错误
- 系统时间不同步
Arc 浏览器初印象
很早之前就在 Twitter 上看到有人分享了 Arc 浏览器的使用体验,说是非常惊艳,我就稍微的浏览了一下官网,抱持怀疑的态度先注册了一下体验,一直好奇到了 2022 年能够在浏览器上做出什么样的创新,自 Chrome 横空出世以来,快,安全迅速抢占了浏览器市场。剩下的一点点份额被 Firefox,Safari,Edge,[[Vivaldi]] 等等占据,早两年的时候我也写过一篇标题略微耸动的文章 —- 我可能要抛弃用了很多年的 Chrome 改用 Vivaldi ,但事实是 3 年多过去了,我日常用的还是 Chrome,虽然 Google 在浏览器插件,隐私等等问题上这两年来一直被诟病,但至少还没有彻底地激怒我这个用户。
但可能也是 Google 作为一家广告公司,这个背景实在会让人产生一些敬畏。所以这些年 Chrome 也面临了越来越多的挑战,不管是大企业的 Edge,Safari,亦或是初创企业的,比如本文的主角 Arc Browser ,或者注重隐私的 Orion ,或者在 UI 交互上做创新的 Sidekick , SigmaOS ,都给浏览器发展一些新的思路。这么多年过去 Chrome 还能克制能够抱持整体风格的简洁,并且让地址栏发展成为 Omnibox ,Chrome 几乎成为了我的 开机应用 ,并且借助 Chrome Extension 的生态,以及这些年 Web 技术的发展,在浏览器中能做的事情越来越多,很多 Native 的应用也越来越多地被替换成 Web 应用。这一次体验 Arc 最让我惊艳的就是一些应用,比如 Notion 在 Arc 中的体验就像是 Notion 本地应用一样(虽然 Notion 发布的本地应用就能就是套了一层壳而已)。
初上手
- 非常亮眼的视觉设计
- 友好的提示,正是因为交互元素上做出了一些调整,所以即使是用惯了传统浏览器的用户也需要经过导览才能使用,传统的在上方的地址栏被调整到侧边
新特性
Space
最开始让我想要了解的功能就是 Space,侧边栏通过双指滑动可以创建新的 Space, 也可以通过下方的 + 号来创建,但是使用之后体验上就感觉是分组的标签页。
Easel
Arc 内建了一个画板,可以做笔记,剪切网页图片,这就相当于内嵌了一个素材收集工具。在地址栏边上的截图小工具的交互设计做的确实不错,可以根据页面内容动态调整要截取的内容。
Easel

Library
在侧边栏还有一个 Library 的概念,在 Library 中会展示下载,桌面等等文件夹,其中还包括了 Arc 独有的 存储 Easel 画板的地方,存储在 Arc 中抓取的网页截图。
Library
分屏
一些快捷键
大部分的快捷键,和使用 Chrome 都是一致的,打开标签页 Cmd+T, 关闭标签页 Cmd+w,恢复关闭的标签页 Cmd+Shift+t, 更多
但 Arc 引入的新功能必然带来新的快捷键,这里就列举一些常见的,全部的快捷键还是查看其官网,或 Cmd+, 查看吧
⌘+s锁定或隐藏侧边栏Ctrl+Tab切换标签页Ctrl+Shift++创建垂直分屏
一些问题
注册问题
如果在注册的时候遇到 「Unknown server error」 的错误

那么可能是网络无法访问 Arc 的服务,这个问题我在之前体验 Warp 终端 的时候也遇到了,现在出现的这些产品都喜欢在开篇的时候让用户注册账号使用,但是在国内的这种网络环境下就会遇到各种奇葩的问题。解决办法也非常简单,直接开启 系统全局代理 ,或者去一个没有 GFW 的地方。这里推荐使用 Clash for Windows
进度条问题
在 Chrome 中打开网页,我会看去 Tab 上状态,在加载的时候会有 Loading 的转圈,而在 Vivaldi 中则是更加明显的地址栏中会有色彩进度条,我会明确知道这个页面是正在加载的状态,而使用 Arc 第一个感到不适的就是当网络环境比较慢的时候,会有很长一段时间整个页面是空白状态,如果隐藏侧边栏最上方的地址栏就完全不知道是这个网站出错了还是网络有问题。虽然 Arc 刻意隐藏了所有「不必要」的内容,但却也带来了一些使用上的不便。
卡顿问题
相同的环境下,Chrome 从来没有发生过页面或交互中间出现卡顿的情况,但是 Arc 使用过程中隔一会儿就会出现。虽然看别人演示的时候都非常流畅,但是就我个人的使用来说这一点是无法忍受的,尤其是当我想打开标签页,快速输入一些内容进行查找时,这个延迟非常明显。
总结
今天花了一段时间体验了一下 Arc,总体来说视觉上,交互上确实带来了一些新鲜感,但似乎目前还不能被我设为默认浏览器,虽然分屏,Space 等等确实给浏览器交互带来了一些新的启发,但对于我而言这些功能并没有那么不可代替。所以短时间内我还是会继续用 Chrome,不过时常回来关心一下 Arc,看能不能带来一些划时代的革新。
如果你也想体验,可以去 官网 申请。或者使用我的邀请 1,邀请 2,邀请 3。
邀请码似乎有数量的限制,我虽然会定期更新邀请,但也会存在更新不及时的情况邀请码失效,所以如果有遇到邀请码失效的朋友,可以通过页面下方或者 About 页面联系到我,我会单独给你发邀请。
Javalin:一个轻量的 Web Framework
说起 Java 语言下的 Web 框架那就非 [[Spring Framework]] 不可了,但是今天在和别人在聊天的过程中发现了一个新奇的项目 Javalin。 Javalin 是一个轻量的 Web 框架。支持 [[WebSocket]], HTTP2 和异步请求。简单的看了一下官方的说明文档,确实非常轻量,几行代码就可以启动一个 HTTP 服务。
[[Javalin]] 最初是 [[SparkJava]] 的一个分支,后来受到 JavaScript 框架 koa.js 的影响,逐渐独立成一个新的项目发展。
首先来看看一个比 Hello World 稍微复杂一些的例子:
var app = Javalin.create(config -> {
config.defaultContentType = "application/json";
config.autogenerateEtags = true;
config.addStaticFiles("/public");
config.asyncRequestTimeout = 10_000L;
config.dynamicGzip = true;
config.enforceSsl = true;
}).routes(() -> {
path("users", () -> {
get(UserController::getAll);
post(UserController::create);
path(":user-id"(() -> {
get(UserController::getOne);
patch(UserController::update);
delete(UserController::delete);
});
ws("events", userController::webSocketEvents);
});
}).start(port);
验证路径参数
var myQpStr = ctx.queryParam("my-qp"); // 没有验证,返回字符串或空
var myQpInt = ctx.pathParam("my-qp", Integer.class).get(); // 返回一个整数或抛出异常
var myQpInt = ctx.formParam("my-qp", Integer.class).check(i -> i > 4).get(); // 整数 > 4
// 验证两个依赖的查询参数 :
var fromDate = ctx.queryParam("from", Instant.class).get();
var toDate = ctx.queryParam("to", Instant.class)
.check(it -> it.isAfter(fromDate), "'to' has to be after 'from'")
.get();
// 验证一个json消息体:
var myObject = ctx.bodyValidator(MyObject.class)
.check(obj -> obj.myObjectProperty == someValue)
.get();
handler
//前置handler
app.before(ctx -> {
// 在所有请求之前运行
});
app.before("/path/*", ctx -> {
// 在/path/*请求之前运行
});
//端点handler
app.get("/", ctx -> {
// 一些代码
ctx.json(object);
});
app.get("/hello/*, ctx -> {
// 捕获所有对/hello/子路径的请求
});
//后置handler
app.after(ctx -> {
// 在所有请求之后运行
});
app.after("/path/*", ctx -> {
// 在/path/*请求之后运行
});
使用 AccessManager 接口来实现验证和授权。
如果要部署 Javalin 应用程序,开发人员只需创建一个包含了依赖(使用 maven-assembly-plugin)的 jar,然后用 java -jar filename.jar 发布该 jar。Javalin 自带一个嵌入式 Jetty 服务器,无需额外的应用程序服务器。
Javalin 还有 专门为教育工作者准备的页面 ,该页面强调学生可以从 Javalin 受益,因为 Javalin 提供了嵌入式的 Jetty 服务器,所以不需要 Servlet Container/Application 服务器配置就可以开始编码。
有一系列教程可供使用,如 Running on GraalVM 和 Kotlin CRUD REST API 。可以在 教程页面 找到完整的列表。
文档页面 提供了有关 Javalin 的更多细节。用户可以通过 maven 或从手动 maven中央库 下载 Javalin。
部署执行
通过 mvn package 就可以打包一个 jar 文件,直接运行 java -jar xxx.jar 就可以启动。
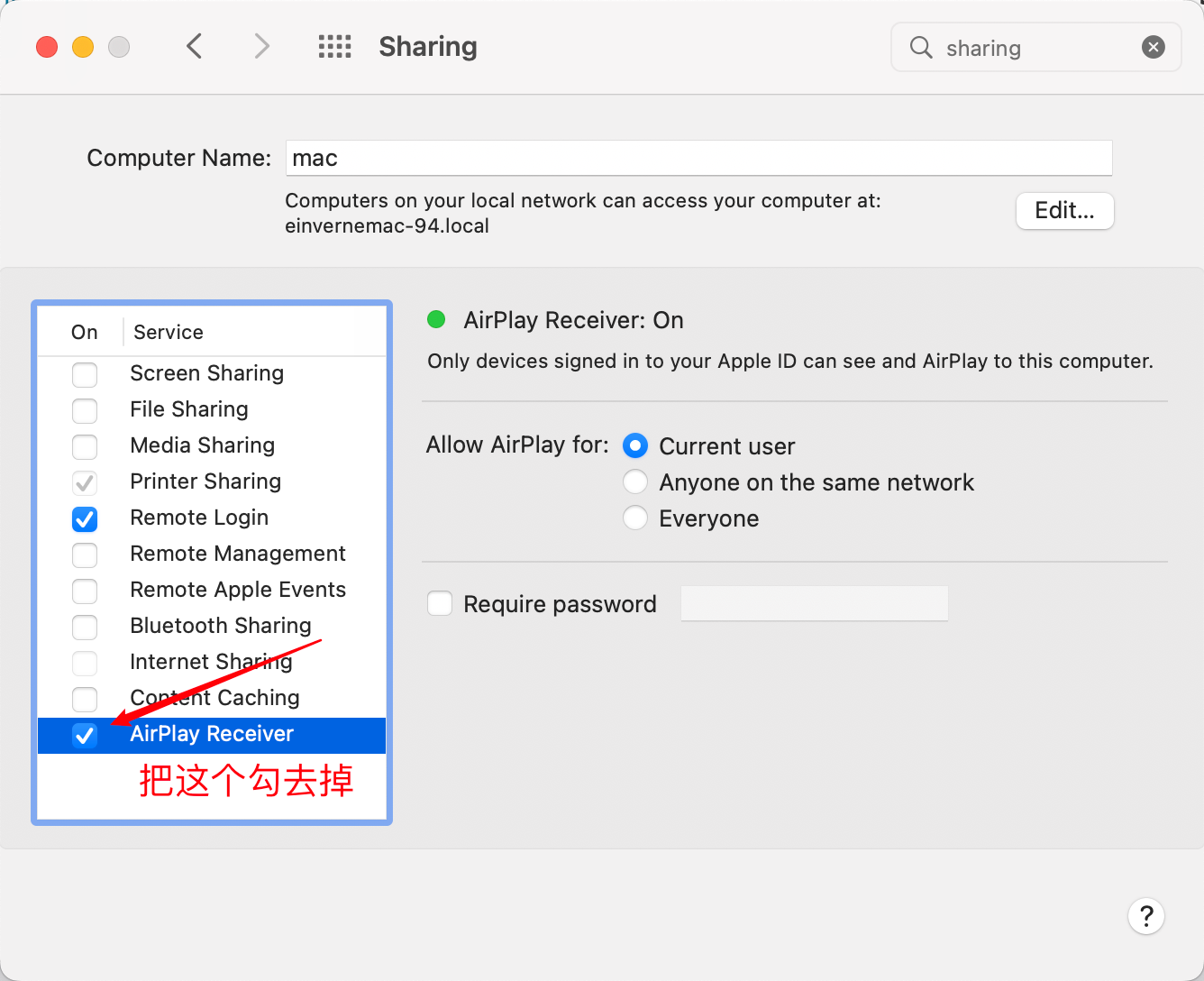
启动 7000 端口占用问题
因为我在 macOS 下启动 Javalin 程序,默认是使用的 7000 端口,但是起来的时候发现端口被占用了。
用 lsof 查看
❯ sudo lsof -nP -i4TCP |grep 7000
Password:
Swinsian 1563 einverne 36u IPv4 0xa107511eb4d4e74b 0t0 TCP 127.0.0.1:50677->127.0.0.1:7000 (CLOSED)
Swinsian 1563 einverne 37u IPv4 0xa107511eb4d4e74b 0t0 TCP 127.0.0.1:50677->127.0.0.1:7000 (CLOSED)
ControlCe 1578 einverne 29u IPv4 0xa107511eb42171fb 0t0 TCP *:7000 (LISTEN)
查看进程
❯ sudo ps aux | grep 1578
einverne 46918 0.7 0.0 34253900 968 s000 S+ 2:37PM 0:00.00 grep --color=auto 1578
einverne 1578 0.0 0.1 36594320 36324 ?? S Sun12PM 1:24.15 /System/Library/CoreServices/ControlCenter.app/Contents/MacOS/ControlCenter
发现竟然是系统的 ControlCenter 占用了本地 7000 端口,用如下的方法禁用。
[[javalin-database]]
reference
使用开源 Wakapi 代替 WakaTime 统计编码时间
之前折腾 GitHub Profile 的时候发现了 [[WakaTime]] 这样一款统计编码时间的工具,之后在读 waka-readme 项目的时候发现,还有两个完全开源的后端兼容版本,一个是 Golang 编写的 [[wakapi]] ,一个是 Huskell 编写的 hakatime 。这篇就来总结一下我使用 wakapi 的过程。
wakapi 是一个兼容 [[WakaTime]] 的可自行架设的后端程序,和 WakaTime 一样可以用来统计代码。
- GitHub: https://github.com/muety/wakapi
Installation
使用 docker-compose 安装。
直接 clone 项目,修改环境变量,然后启动即可。
git clone https://github.com/einverne/dockerfile.git
cd dockerfile/wakapi/
cp env .env
# edit .env setup SALT and WAKAPI_DATA
# SALT 可以执行命令 cat /dev/urandom | tr -dc 'a-zA-Z0-9' | fold -w ${1:-32} | head -n 1
# WAKAPI_DATA 配置一个本地可读写的路径
docker-compose up -d
我的配置中没有暴露 3000 端口,我是和 Nginx Proxy Manager 一起使用的,在 Nginx Proxy Manager 后台,配置一个 HOST,设置 wakapi:3000 ,然后去 [[Cloudflare]] 后台将域名 wakapi.einverne.info 设置一个 A 记录指向 Nginx 所在的服务器。等待 DNS 生效,访问后台 wakapi.einverne.info 后台即可。
我个人会一直使用 https://wakapi.einverne.info 服务,所以如果你感兴趣,也可以直接使用这个服务。
服务启动之后,注册登录,然后就可以配置编辑器插件,把 IntelliJ IEDA,[[VSCode]],[[Vim]] 先配置上。这部分可以直接查看 WakaTime 的官方文档。
编辑客户端配置 ~/.wakatime.cfg ,因为使用 Self-hosted 的后端,所以需要设置 api_url 。api_key 则从后台获取即可。
[settings]
api_url=https://wakapi.einverne.info/api
api_key=b5b0xxx
proxy=
debug=false
status_bar_enabled=true
在 Obsidian 中使用 WakaTime
今天偶然在浏览 Obsidian 插件库的时候发现了 WakaTime 的插件,安装之后就和编程 IDE 一样,会直接使用 HOME 目录下的配置。所有的数据都可以完美的上传到 Wakapi 的后台。
GitHub Actions
使用 WakaTime 统计编码时间
[[WakaTime]] 是为程序员打造的编码统计 Dashboard,可以同来统计项目,编程语言,IDE,编码时间等等内容。 之前在折腾 GitHub Profile 的时候发现的,可以在 GitHub Profile 页面中动态的展示最近的编程状态。
WakaTime 可以统计的内容包括:
- 每天在每个项目上的编码的时间
- 使用的编辑器
- 编程语言占比
- 所使用的操作系统
- 所在的项目
Price
WakaTime 基础使用是免费的,但有如下限制:
- 只包含两个星期的历史
- 有限的整合
- 3 位朋友之间的 Leaderboards
对于 Premium 可以解锁更多的 功能 。
Config
WakaTime 的配置文件在 HOME 目录下的 .wakatime.cfg 文件中。
cat ~/.wakatime.cfg
[settings]
api_key=
proxy =
debug = false
status_bar_enabled = true
IntelliJ IDEA (JetBrains 系列)
插件 Market 中搜索 wakatime,重启 IDEA,在弹出的 WakaTime Settings 中填入 API key。
如果要设置 proxy,可以在下面填入 http_proxy 类似:http://localhost:1080
Vim
在 Vim 的配置中增加如下配置,Vim 下使用 vim-plug 来管理插件:
Plug 'wakatime/vim-wakatime'
Self-hosted
- [[wakapi]] 是一个可以自己架设的 WakaTime 兼容后端管理平台,可以完美的作为 WataTime 的开源代替存在。
使用 yt-dlp 下载 YouTube 视频
yt-dlp 是 YouTube-DL 的进阶版本,延续了 YouTube-DL 的开发和维护。
如果想要下载哔哩哔哩 (Bilibili) 的视频,可以看看 lux 这款工具。
如果在 macOS 上还有一款不错的收费应用叫做 [[Downie]] 也可以用来下载 YouTube 视频。数码荔枝 上有正版授权,可以选择购买。
安装
安装 [[FFmpeg]]:
sudo apt install ffmpeg
安装 yt-dlp:
sudo curl -L https://github.com/yt-dlp/yt-dlp/releases/latest/download/yt-dlp -o /usr/local/bin/yt-dlp
sudo chmod a+rx /usr/local/bin/yt-dlp
sudo ln -s /usr/local/bin/yt-dlp /usr/local/bin/yt
使用
基础使用:
yt-dlp -F --proxy socks5://127.0.0.1:8080 https://www.youtube.com/watch?v=3Hq-cgsV7Og
下载最佳画质:
yt-dlp -f best URL
下载最高视频和音频并合并:
yt-dlp -f bestvideo+bestaudio URL
下载最高视频和音频分开两个文件:
yt-dlp -f 'bestvideo,bestaudio' URL
将视频缩略图嵌入到视频文件:
yt-dlp -f 'bv[height=1080][ext=mp4]+ba[ext=m4a]' --embed-thumbnail --merge-output-format mp4 https://www.youtube.com/watch?v=1La4QzGeaaQ -o '%(id)s.mp4'
下载播放列表:
yt-dlp -f 'bv*[height=1080]+ba' --download-archive videos.txt https://www.youtube.com/playlist?list=PLlVlyGVtvuVnUjA4d6gHKCSrLAAm2n1e6 -o '%(channel_id)s/%(playlist_id)s/%(id)s.%(ext)s'
下载整个 YouTube Channel,保存为平台加视频名称
yt-dlp -f 'bv*[height=720]+ba' --download-archive videos.txt https://www.youtube.com/c/FootheFlowerhorn/videos -o '%(channel)s/%(title)s.%(ext)s'
折腾一下 GitHub Profile
虽然很早就知道 GitHub 发布了 Profile 功能,可以使用 README 来丰富 Profile 页面。但是一直以来没啥动力,大多数时候都不会去到主页去访问。但现在有些时候逛 GitHub 的时候会点到 其他人 的主页去看,发现有一些主页虽然只有寥寥几句,但却可以清楚的知道「他/她」最近在贡献什么内容,擅长什么技能。虽然我在 GitHub 上还是观摹大佬居多,但也想着通过这个契机在整理 GitHub Profile 的时候加深一下对自己的认知。
至于如何建立同名的 repository,如果提交代码就先略过了,官方的帮助和其他文章的内容都非常详细。
刚开始去 Google 「GitHub Profile」 就发现了如下的页面生成器 GitHub Profile Generator ,可以用这个生成器生成一个初始版本,然后在其基础上修改。
在调研的过程中基本发现了两大类主流的用法,一类是通过 GitHub 的 API ,或者其他服务的 API,生成一个 Badge 展示,另外一类就是通过 [[GitHub Actions]] 通过定时任务动态的使用代码聚合一些内容,然后再动态地展示到页面中。
因为 README 中可以直接写 HTML,所以如下的 HTML 也可以直接使用,注意替换其中的链接。
<h3 align="left">Connect with me:</h3>
<p align="left">
<a href="your link" target="blank"><img align="center" src="https://cdn.jsdelivr.net/npm/simple-icons@3.0.1/icons/twitter.svg" alt="" height="30" width="40" /></a>
<a href="your link" target="blank"><img align="center" src="https://cdn.jsdelivr.net/npm/simple-icons@3.0.1/icons/linkedin.svg" alt="" height="30" width="40" /></a>
<a href="your link" target="blank"><img align="center" src="https://cdn.jsdelivr.net/npm/simple-icons@3.0.1/icons/instagram.svg" alt="" height="30" width="40" /></a>
<a href="your link" target="blank"><img align="center" src="https://cdn.jsdelivr.net/npm/simple-icons@3.0.1/icons/youtube.svg" alt="" height="30" width="40" /></a>
</p>
或者使用外部的 Readme-stats 来生成一个数据卡:
<p>
<a href="https://github.com/einverne/">
<img margin-top="-30px" width="55%" align="right" alt="einverne's github stats" src="https://github-readme-stats.vercel.app/api?username=einverne&show_icons=true&include_all_commits=true&count_private=true&layout=compact&hide_border=true" />
</a>
</p>
图标
如果要在页面中放入图标可以到如下的网站寻找。
- Simple Icons 是一个开源的 SVG 图标库,包含了上百个品牌的图标。
- Skill Icons 是一组可以用来展示技能的图标。
- Flaticon 提供了很多彩色的图标,也提供很多收费的图标,可以根据需要选择。
- Icons8 同样是一个图标库,但是也包含一些收费的图标
- Wikimedia Commons 是另一个不错的选择,可以找到很多官方的图标,并且可以自由使用。
另外一个寻找 icon 的方式就是利用 https://cs.github.com GitHub 的 Code Search,然后直接搜索,比如我想要找到豆瓣的 svg ,输入 douban.svg 然后就能找到。
其他徽章
github-readme-stats
github-readme-stats 是一个用来生成 GitHub 统计数据的工具,可以在页面上展示获得的⭐,提交的次数,总共的 PR 等等。

徽章
生成从构建,代码覆盖率,开源协议,到社交网络等等,非常多的徽章。
统计页面访问量
如果想要统计访问 GitHub Profile 的数量,可以使用 GitHub Profile Views Counter 这个项目。
显示奖杯
样例:

github-readme-streak-stats
https://skyline.github.com/
GitHub Actions
基于 GitHub Actions 动态生成内容展示在 Profile 页面。
因为有 GitHub Actions,所以简单的用脚本可以展示
- 最近在阅读的图书
- 最近分享的文章
- 当前正在听的音乐
等等。
显示最近博客内容
可以使用 blog-post-workflow 来显示最近更新的博客内容。通过定时读取 Feed ,来在页面动态展示内容。
GitHub 最近动态
GitHub Activity Readme 可以在页面上显示最近在 GitHub 上的动态。
Waka
如果你使用 [[WakaTime]] 来统计编码时间,那么可以使用 waka-readme-stats 来展示。
总结
最终的效果见 https://github.com/einverne/
reference
现代政治的正当性基础 读书笔记
怎么知道的这一本书
似乎是在豆瓣的推荐流中第一次发现这一本。
关于作者
作者是[[周濂]],我还是在有关哲学的播客中第一次知道这一位人大的教授,首先接受的是他的声音,然后在豆瓣纪念[[江绪林]] 的文章中再一次看到了周濂教授,最后是在刘擎的 [[西方现代思想讲义]] 中又一次读到周濂。
几句话总结书的内容
什么是正当性 legitimacy
关于国家正当性的问题,要回答的问题是「在国家诞生的过程中需要满足哪些限制条件?」
legitimacy 正当性,合法性。怎么样产生的国家才在道德上是可以被接受的。正当性是一个「回溯」的概念,从「发生」追问国家的谱系、来源。
什么是证成性 justification
关于国家证成性的问题,要回答的问题是,「为什么需要国家」,国家这种制度存在的目的是什么?为什么一定要建立国家?无政府状态会更好吗?国家作为工具或手段能为公民提供什么样的好处?
国家具有哪些性质,使得它的存在是值得的。
国家证成性问题是一个「前瞻性」的概念,评价国家的功能,和国家的产生没有关系。
义务
- 义务是通过履行某些自愿的行动(或者不作为)创造出来的道德要求
- 义务是某类特殊的人对另一类特殊人的欠负
- 每项义务都与一项权利相关联
- 一个行动之所以是一种义务,是因为债权人和债务人所参加的互动或关系而形成,而不是因为被要求的行为在道德上的属性
政治义务
- 特殊的道德义务,履行自愿的行为创造出来的道德要求
- 特定政治共同体的公民,成员,或参与者
- 政治义务的形成乃是因为国家和公民之间的互动或关系的本质所导致的
- 公民负有政治义务与统治者拥有的统治权利相对应,也因此与国家拥有的正当性具有逻辑关联性
- 代价很大,成本极高的义务
启发或想法
国家和政府首先是一个目的性的存在,人们建立国家和政府是为了促进自由正义、保障社会稳定和提高人民福祉,一旦一个民选政府或民主国家无法实现这些基本目的,那么人们就会收回当初的认可,这个国家和政府也就丢失了正当性。
谁应该看这本书
- 想了解什么是[[国家]]的人
- 想知道[[国家]]是怎么诞生的人
- 想回答「我们是否有道德义务遵守法律」
印象深刻的句子
- 「因为没有一个现存国家和政府拥有百分百的正当性,并不能推出所有现存的国家都不具有正当性,这就好象没有一个现实中的三角形是完美的,并不能推出所有现实中的三角形都不是三角形。」
Plex 内嵌的 SQLite 数据表字段解析
Plex Media Server 是一个媒体服务器,可以用来管理和串流电影、电视剧、音乐、照片等等媒体格式。
因为 Plex Media Server 运行在本地,所以几乎所有的信息都在本地的一个 SQLite 中,包括了 Library 的信息,多媒体的 meta 信息等等。
Plex Database 的位置
在 Linux 上(包括 NAS):
$PLEX_HOME/Library/Application\ Support/Plex\ Media\ Server/Plug-in\ Support/Databases/com.plexapp.plugins.library.db
在 Debian/Ubuntu 下 Plex 数据在
/var/lib/plexmediaserver/Library/Application Support/Plex Media Server/
在 macOS 上:
~/Library/Application\ Support/Plex\ Media\ Server/Plug-in\ Support/Databases/com.plexapp.plugins.library.db
Windows 上:
"%LOCALAPPDATA%\Plex Media Server\Plug-in Support\Databases\com.plexapp.plugins.library.db"
Plex SQLite3
分析的时间是在 2022 年 10 月 8 号,未来 Plex 可能对表名和表结构有所改变,请注意。
目前一共有 81 张表,7 张虚拟表。有一些表可以通过名字猜测出来,比如 accounts 表就是 Plex 登录账号的表。
accounts # 登录的账户
activities # Plex 活动记录,比如更新 metadata, scanning
blobs
cloudsync_files # 看起来像是很多年前 Plex 就关闭了的 Cloud Sync 功能遗留下来的表
devices # 记录 Plex 登录的设备,包括 Chorme,Phone 等等
directories # Plex 能够扫描的文件夹列表
external_metadata_items
external_metadata_sources
fts4_metadata_titles_docsize
fts4_metadata_titles_icu_docsize
fts4_metadata_titles_icu_segdir
fts4_metadata_titles_icu_segments
fts4_metadata_titles_icu_stat
fts4_metadata_titles_segdir
fts4_metadata_titles_segments
fts4_metadata_titles_stat
fts4_tag_titles_docsize
fts4_tag_titles_icu_docsize
fts4_tag_titles_icu_segdir
fts4_tag_titles_icu_segments
fts4_tag_titles_icu_stat
fts4_tag_titles_segdir
fts4_tag_titles_segments
fts4_tag_titles_stat
hub_templates
library_section_permissions
library_sections # 仓库的设置
library_timeline_entries
locatables
location_places
locations_node
locations_parent
locations_rowid
media_grabs
media_item_settings
media_items
media_metadata_mappings
media_part_settings
media_parts # 包含了重要的媒体文件的路径
media_provider_resources
media_stream_settings
media_streams
media_subscriptions
metadata_item_accounts
metadata_item_clusterings
metadata_item_clusters
metadata_item_setting_markers
metadata_item_settings
metadata_item_views
metadata_items
metadata_relations
metadata_subscription_desired_items
play_queue_generators
play_queue_items
play_queues
plugin_permissions
plugin_prefixes
plugins
preferences
remote_id_translation
schema_migrations
section_locations
spellfix_metadata_titles_vocab
spellfix_tag_titles_vocab
sqlite_master
sqlite_sequence
sqlite_stat1
statistics_bandwidth
statistics_media
statistics_resources
stream_types
sync_schema_versions
synced_ancestor_items
synced_library_sections
synced_metadata_items
synced_play_queue_generators
synchronization_files
taggings
tags
versioned_metadata_items
view_settings
几张重要的表
专辑的打分,单曲的打分。
metadata_items
表 metadata_items 记录了所有媒体文件的 metadata 信息
表结构:
create table metadata_items
(
id INTEGER not null
primary key autoincrement,
library_section_id integer,
parent_id integer,
metadata_type integer,
guid varchar(255),
media_item_count integer,
title varchar(255),
title_sort varchar(255) collate NOCASE,
original_title varchar(255),
studio varchar(255),
rating float,
rating_count integer,
tagline varchar(255),
summary text,
trivia text,
quotes text,
content_rating varchar(255),
content_rating_age integer,
"index" integer,
absolute_index integer,
duration integer,
user_thumb_url varchar(255),
user_art_url varchar(255),
user_banner_url varchar(255),
user_music_url varchar(255),
user_fields varchar(255),
tags_genre varchar(255),
tags_collection varchar(255),
tags_director varchar(255),
tags_writer varchar(255),
tags_star varchar(255),
originally_available_at dt_integer(8),
available_at dt_integer(8),
expires_at dt_integer(8),
refreshed_at dt_integer(8),
year integer,
added_at dt_integer(8),
created_at dt_integer(8),
updated_at dt_integer(8),
deleted_at dt_integer(8),
tags_country varchar(255),
extra_data varchar(255),
hash varchar(255),
audience_rating float,
changed_at integer(8) default 0,
resources_changed_at integer(8) default 0,
remote integer,
edition_title varchar(255)
);
metadata_item_settings
metadata_item_settings 表中记录了媒体文件的打分 (rating),播放次数(view_count),播放位置(view_offset),最后一次播放时间(last_viewed_at)。1
对于音乐库,专辑的 rating 在 metadata_items 表中,对于单曲的打分才在这张 metadata_item_settings 中。
SELECT mi.title, mi.rating album, mis.rating track
FROM metadata_item_settings mis
JOIN metadata_items mi on mis.guid = mi.guid
WHERE mi.parent_id = (SELECT id FROM metadata_items WHERE title LIKE '%<partial album title here>%');
用例
查看 playlists
metadata_type = 15 的时候表示该记录是 Playlist。
select title from metadata_items where metadata_type = 15;
查看某一个播放列表中的文件路径:
select file from media_parts as p left join media_items mi on mi.id = p.media_item_id
left join play_queue_generators as pqg on pqg.metadata_item_id = mi.metadata_item_id
left join metadata_items on metadata_items.id = pqg.playlist_id
where metadata_items.title = 'Playlist title';
查看所有条目
SELECT library_sections.name AS Libary, metadata_series.title as Series, metadata_season.'index' AS Season, metadata_media.title AS Title FROM media_items
INNER JOIN metadata_items as metadata_media
ON media_items.metadata_item_id = metadata_media.id
LEFT JOIN metadata_items as metadata_season
ON metadata_media.parent_id = metadata_season.id
LEFT JOIN metadata_items as metadata_series
ON metadata_season.parent_id = metadata_series.id
INNER JOIN section_locations
ON media_items.section_location_id = section_locations.id
INNER JOIN library_sections
ON library_sections.id = section_locations.library_section_id;
富兰克林自传 读书笔记
怎么知道的这一本书
已经被不止一遍的推荐过,[[芒格]] 非常喜欢这本书,在《穷查理宝典》里面推荐过,巴菲特也曾推荐过,在之前看过的 [[法官能为民主做什么]] 中也能读到美国最高法院法官对富兰克林的尊敬,再到国内,罗辑思维也在视频中推荐过。上一本读过的 [[新教伦理与资本主义精神]] 中[[马克思 韦伯]] 也列举了 [[富兰克林]] 作为例子,有意思的是我在我的笔记库中搜索的时候,一本讲述德州扑克的树中作者也援引了富兰克林的观点,可见富兰克林在美国人心中的地位。
而我对富兰克林的印象停留在了那个雷雨天放风筝的小孩,以及 100 美元上的人物了,其他零星的记忆就是看美国建国那段历史的时候偶然出现的形象。所以正好借由这一本自传来完整地了解一下富兰克林。
关于作者
富兰克林的自传,自然作者就是富兰克林,全名是本杰明•富兰克林,打开他的维基百科,能看到不少的头衔,除了我们熟悉的科学家,政治家,他同样还是杰出的外交家,发明家,出版商,记者,作者等等,甚至在心理学上也有建树。作为政治家,共同起草了独立宣言,作为外交家,结盟法国,赢得了独立战争。
几句话总结书的内容
这是一本富兰克林所写的自传,写于 1771 年。
全书共分为 4 个部分,正传,正传续篇,续传和补编,但观看的过程中明显能感觉到在正传部分花的篇幅比较多。从家庭,青年事情开始写起,尤其是富兰克林的青年时期令人印象深刻。
启发或想法
读书的习惯
在书中都知道富兰克林是一个印刷商人,但也能从中看到富兰克林对书的痴迷,在 17 岁时就读了洛克的[[人类理解论]],波特洛亚尔派的会员们所著的《思维的艺术》,从小就接受了不同的哲学思想。不仅自己有着良好的阅读习惯,也在之后成立图书俱乐部,名之曰“讲读俱乐部”,成立图书馆,通过书让更多人获益。
尽可能多的读书,书籍是智慧的源泉。
「图书馆使我得以有恒地研习增进我的知识,每天我停留在里面一两个钟头,用这个办法相当地补足了我失掉的高等教育」
学习写作
富兰克林在书中写道,「散文写作对我的一生十分有用,而且还是我走向成功的重要手段之一」,有意思的是,富兰克林是在和别人「吵架」中意识到自己的行文不足的,「但在辞句优雅、条理明晰方面我却不如对方。在这些方面,他举出几个例子使我信服。我知道他的意见是公平的,从此对于文体更加注意,且决心努力改进。」
学习写作的方法:
- 模仿,「如果可能的话,我还很想模仿它。抱着这个念头,我取出其中的几篇,把每句的大意摘要录出,放置几天以后,再试着不看原书,用自己想到的某些合适的字,就记下的摘要加以引申复述,要表现得跟原来的一样完整,把原篇重新构建完成。」
- 学习不同的表达,「因为为了合律和协韵,写诗常常需用意义相同而长短不同、声调不同的字,这样就会把我摆到继续不断搜求大量词汇的需要下,也会帮助我记住它们而能运用自如。」
写作的另外一个长处便在富兰克林之后的人生中起了很大的作用,撰文倡导自己的政治主张,通过印刷品影响人民进而影响议会,书中提到的纸币增发议案就是一典型的案例。
广交好友
从和哥哥交恶,富兰克林离开波士顿,独自一人前往费城,在书中能看到富兰克林结交的朋友并非都是善人,那个为人热情的威廉总督,空给人了希望,将富兰克林骗到伦敦。但大部分的朋友都在人生的不同阶段给过富兰克林帮助。
当具备一定的阅历、智慧并坚持学习思考,人就会像超重体一样,吸引更多的有思想有价值的人来到你的身边。
做一个可行的自我提高计划,如何坚持并实施它
人的一生所经历的大多数事情是无法预知的,即使这样,计划也是必须的。因为,只要坚持执行计划,未知的事情会围绕着计划发生。
为人谦逊
「因为要巩固商人的信用和声望,我不但注意到勤劳和节俭的实际情形,也要避免那种趾高气扬的形象。我穿得很朴素,从来不在消闲的娱乐场所出现。我从不出去钓鱼和打猎。」
这一段文字立即让我想到了韦伯的 [[新教伦理与资本主义精神]],书中也恰恰列举了富兰克林作为例子。
这也是 13 条道德中的最后一条。
谁应该看这本书
所有人都应该看一看。
印象深刻的句子
- 想要说服别人,要诉诸利益而非诉诸理性。
- 在获得第一桶金之后,再去获得第二桶就容易多了。因为钱是可以生钱的。
13 条道德原则
- 节制:食不过饱,饮不过量
- 沉默:于人于己不利之言不谈,避免闲言碎语
- 秩序:放东西各归其位,办事情各按其时
- 决断:决定做你该做的事,做好你决定做的事
- 节俭: 不花于己于人没有益处的闲钱,杜绝浪费
- 勤奋:珍惜时间,做有用的事,弃掉一切不需要的举动
- 诚信:不害人,不欺诈,勿思邪念,言必信,行必果
- 正直:不作恶,不要以德报怨
- 中庸:避免走极端,忍让化冤仇
- 清洁:身体、衣着、居所,不许不洁
- 平静:不可为小事、常事或难免之事搅乱了方寸。
- 贞洁:少行房事,除非为了身体健康或传宗接代,不做一味,衰弱或者损害自己或别人的安宁和名誉
- 谦卑:效法耶稣和苏格拉底。
文章分类
最近文章
- AI Shell 让 AI 在命令行下提供 Shell 命令 AI Shell 是一款在命令行下的 AI 自动补全工具,当你想要实现一个功能,敲一大段命令又记不住的时候,使用自然语言让 AI 给你生成一个可执行的命令,然后确认之后执行。
- 最棒的 Navidrome 音乐客户端 Sonixd(Feishin) Sonixd 是一款跨平台的音乐播放器,可以使用 [[Subsonic API]],兼容 Jellyfin,[[Navidrome]],Airsonic,Airsonic-Advanced,Gonic,Astiga 等等服务端。 Sonixd 是一款跨平台的音乐播放器,可以使用 [[Subsonic API]],兼容 Jellyfin,[[Navidrome]],Airsonic,Airsonic-Advanced,Gonic,Astiga 等等服务端。
- 中心化加密货币交易所 Gate 注册以及认证 Gate.io 是一个中心化的加密货币交易所。Gate 中文通常被称为「芝麻开门」,Gate 创立于 2013 年,前身是比特儿,是一家致力于安全、稳定的数字货币交易所,支持超过 1600 种数字货币的交易,提供超过 2700 个交易对。
- 不重启的情况下重新加载 rTorrent 配置文件 因为我在 Screen 下使用 rTorrent,最近经常调试修改 rtorrent.rc 配置文件,所以想要找一个方法可以在不重启 rTorrent 的情况重新加载配置文件,网上调查了一下之后发现原来挺简单的。
- Go 语言编写的网络穿透工具 chisel chisel 是一个在 HTTP 协议上的 TCP/UDP 隧道,使用 Go 语言编写,10.9 K 星星。