日语输入法相关及 Rime 下输入日语
语言学习中最重要的就是与人交流,那么写(在互联网时代,就是输入)就变得非常重要了。这里就记录一下我使用 Rime 来输入日语的过程。
输入法选择
日语输入法有很多的选择,可以选择系统自带的,比如 Windows 和 macOS 都有不错的日语输入法,也可以选择收费的 ATOK 一个月需要花费几百日元,不过好处可能是可以在电脑和手机端保持一致的使用体验。
而我肯定使用 Rime 输入法的,之前也整理过关于如何用 Rime 来输入韩文的 文章 ,当时埋下的一个坑,本来想介绍一下韩文和日文在 Rime 中的使用,但日文部分因为当时不熟悉就空着了,这里正好填补一下该部分。关于我为什么选择 Rime 输入法也可以参考 这里 。
而在手机上 Android 自带的 GBoard ,iOS 系统自带的输入法也支持日文,就不多说了。
简单的搜索一下就发现了比较成熟的 Rime 下的日语输入方案 —- Rime Japanese
简单的看了一下,这个方案使用的是 Hepburn romanization 方案 ,平文式罗马字标注。
平文式罗马字是一种使用罗马字母来为日语的发音进行标注的方案。
平假名
清音
按照罗马拼音正常输入,对照五十音图。
あ い う え お /ア イ ウ エ オ a i u e o
か き く け こ /カ キ ク ケ コ ka ki ku ke ko
さ し す せ そ /サ シ ス セ ソ sa shi su se so
た ち つ て と /タ チ ツ テ ト ta chi tsu te to
な に ぬ ね の /ナ ニ ヌ ネ ノ na ni nu ne no
は ひ ふ へ ほ /ハ ヒ フ ヘ ホ ha hi fu he ho
ま み む め も /マ ミ ム メ モ ma mi mu me mo
や ゆ よ /ヤ ユ ヨ ya yu yo
ら り る れ ろ /ラ リ ル レ ロ ra ri ru re ro
わ を /ワ ヲ wa wo
ん /ン n
需要注意的是其中有几个
- し 是
shi而不是 si - ち 是
chi - つ 是
tsu
浊音
が ぎ ぐ げ ご \ ガ ギ グ ゲ ゴ ga gi gu ge go
ざ じ ず ぜ ぞ \ ザ ジ ズ ゼ ゾ za ji zu ze zo
だ ぢ づ で ど \ ダ ヂ ヅ デ ド da di du de do
ば び ぶ べ ぼ \ バ ビ ブ べ ボ ba bi bu be bo
半浊音
ぱ ぴ ぷ ぺ ぽ \ パ ピ プ ぺ ポ pa pi pu pe po
拗音
拗音的输入则是要记住 y 的位置。
きゃ きゅ きょ \ キャ キュ キョ kya kyu kyo
しゃ しゅ しょ \ シャ シュ ショ sha shu sho
ちゃ ちゅ ちょ \ チャ チュ チョ cha chu cho
にゃ にゅ にょ \ ニャ ニュ ニョ nya nyu nyo
ひゃ ひゅ ひょ \ ヒャ ヒュ ヒョ hya hyu hyo
みゃ みゅ みょ \ ミャ ミュ ミョ mya myu myo
りゃ りゅ りょ \ リャ リュ リョ rya ryu ryo
ぎゃ ぎゅ ぎょ \ ギャ ギュ ギョ gya gyu gyo
じゃ じゅ じょ ジャ ジュ ジョ ja ju jo
びゃ びゅ びょ ビャ ビュ ビョ bya byu byo
ぴゃ ぴゅ ぴょ ピャ ピュ ピョ pya pyu pyo
片假名转换
macOS 自带的输入法平假名和片假名切换是 F6 变成平假名,F7 变成片假名。在 Rime 里面这个方案使用的
片假名长音,按数字键 0 右方的 - 减号。
拨音输入
拨音输入 n,比如
- にほん nihon
促音输入
っ(促音)双打后一个假名的罗马字发音的第一个辅音,如“ちょっと”为“chotto”。输入两次 t 。
やっぱり yappari
小写
小写的输入,在前面加上 x 或者 _ 即可
输入字母 _ 或 x+a、i、u、e、o,输入 _a 得到ぁ,输入 xa 也得到ぁ,输入 _i 得到ぃ。
或者在 Rime 的日文方案里面,比如日语的派对(party)
パーティー
可以直接输入 pa-ti-
两个连续的小写
在一些日语单词中会出现连续的两个小写字母,比如
ファックス 传真
这个时候输入的时候 fakkusu。 促音的输入是和后面的音多输入一次 k。
しゅっきん出勤,输入shukkin
古语
古语假名ゐ和ゑ的输入
ゐ输入 wi ゑ输入 we
一些自定快捷键
comma/period用来翻页,前一页后一页
成果
结果
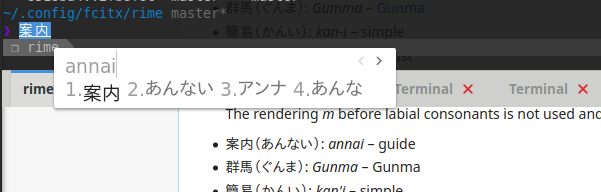
reference
- Google 开源的日语输入法 mozc 看起来上面的日语词库有部分就是取自于该项目
- GitHub Rime 项目讨论日语输入法方案
日语发音基础:五十音
这一篇记录一下学习日语基础发音。
学习路径:
- 发音,五十音图
- 平假名、片假名对应记忆
- 清音
- 浊音
- 长音
- 拗音
- 促音
- ん 拨音(n),不能单独使用
- [[日语音调]]
- [[日语五十音的书写]]
平假名作为发音标记,片假名标记(转写)外来语,这里的外来语不仅包括英语,还可能是世界其他地方的语言,比如荷兰语等等。
目标:
先记平假名,每天记 3 行,3 天内记住全部的平假名。能够在 1~2 min 中内将所有的平假名默写完毕。最好是在 1 分钟以内能够完全默写出。
五十音图:
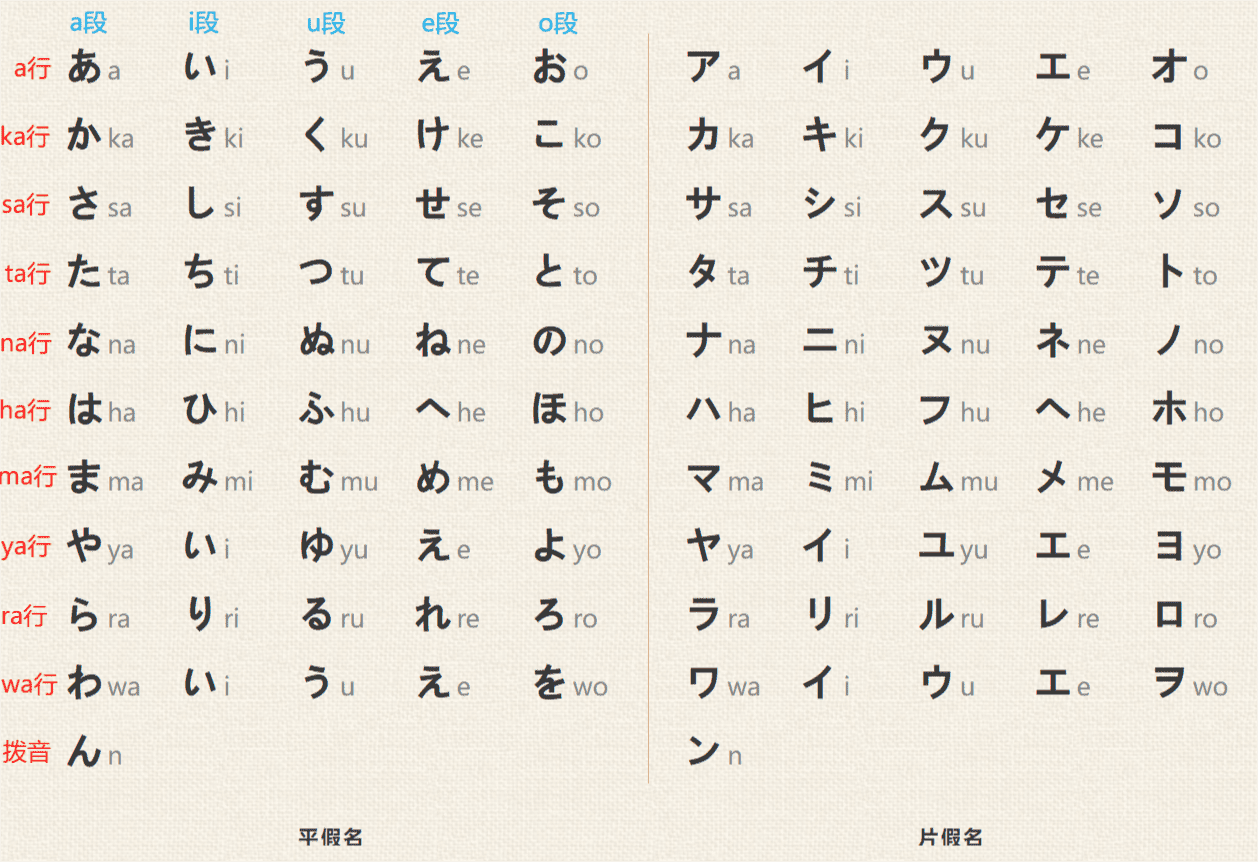
除了基础的五十音图之外,另外还推荐一张 汉字演化对应表 。
汉字演化对应表,在记忆平假名和片假名的时候有一些字用汉字去联想记忆还是非常直观的,至少这一点要比西方人来学日语要直观很多,比如 あ,な,や,せ 如果了解中文写法,写快了基本上就是日文的写法。也正好印证了平假名是从草书演化而来。而片假名中的 カ,ク,チ,ム 等等也基本上只要能想到中文读音,就能直接通过中文字形的部分来想起片假名的写法。
当然这里也要指正一下并不是所有的日语字形都必须通过汉字来记忆,有一些发音是日语本来的发音,和中文的发音完全不同,只是借助了中文的文字标记,有一些可能是古代发音,也有一些可能是当时汉语的发音,比如 チ 这个发音,罗马字标记写成 chi ,而我作为南方人,和我家乡(吴语地带)的发音「千」,几乎是一个发音。
或者是利用单词(图形)助记(从右往左)。
下面这些可可爱爱的图片都来自于如下网站
这些网站上的所有的内容都可以免费下载打印。
下面就随便展示两张,上面这些网站上有更多的选择。 平假名 片假名 平假名1 片假名2

浊音
当把基础的五十音图记住之后,就可以开始学习浊音。
日语没有送气音
g 行 如果在首字,只能发浊音 如果在非首字母,可以读作鼻浊音, no
りんご 苹果

同样片假名也有:

长音
あ 段后接 あ 需要拉长发音。
- い -> い
- う -> う
- え -> え/い
- お -> お/う
拉长发音。

拗音 よう おん
副元音 やゆよ
33 个拗音
- い + やゆよ
比如:
- にゃい 如意
促音 そくおん
促音使用小写的 つ
不要念出来,停半拍。
- けっこん
双打后面的辅音,kekkonn
语音语调 アクセント
[[日语音调]] (语调,声调 アクセント,accent)原则:
- 一个单语里,只能出现一个高音部
日语的声调是高低型,由高而低或由低而高,一个假名一拍,包括清音、浊音、半浊音、拨音和长音,但是不包括拗音中的小写 ゃ,ゅ,ょ,拗音整体看做一个音节,比如 きゅ 是一个音拍,而 きゅう 和 くう 则是两拍。
比如:
- 桜 さくら 升调,低高高
- 天気 てんき 降调 ,高低低
- 玉子 たまご 低高低
- 働きます はたらきます 低高高高高低
在学习日语单词时,出现在单词后面的数字表示该词的声调。比如 教科書「きょうかしょ」③,表示在单词第三个音拍上重读,在第四个音拍上降调。
为了简化说明,以东京音为标准音,一般声调可以分为
- 0 型,平板型,只有第一拍低,其他拍都高,无下降,是一个升调
- ⓵型,头高型,降调,第一个拍高
- ⓶型 ,声调,低高低
- ⓷型,第二拍,三拍高
- ⓸型,二至四拍高
- ⓹型,当两个单词组成一个合成词时,第二个单词的第一个假名常常用重读。 東京大学(とうきょう だいがく ⑤)
日语的音调可以用来区分同音词,比如:
- 箸 はし ⓵ 筷子
- 橋 はし ⓶ 桥
当学习了语调的基础内容之后就是需要多听发音,然后模仿学习。这个时候一个随时随地的「好老师」就非常有必要了,下面推荐几个不错的在线发音网站。
- OJAD 在线日语声调词典 面向日语老师和学习者的在线口音词典,支持 9000 多名词,3500 多动词,い形容詞,な形容詞,有超过 4 万条发音。甚至可以根据教材分类检索。缺点是需要一个不错的网络环境 并且也只有网页版本。

- 広辞苑無料検索 一个在线的日语查词网站,可以免费查询包括广辞苑,大辞林,大辞泉,新辞林,小学馆中日日中等等非常多的词典。该网站还支持 Google 登录,数据都会存储在用户 Google Drive 的 Soradict 文件夹中。界面也非常简洁。

这里先推荐这两个在线的网站,我个人更喜欢离线的字典,所以后面会再总结一篇使用 GoldenDict 来查日语词的文章。
最后补充一首歌
在浏览一些日语学习经验 的时候有人推荐了一首《sweets parade》,去网易云音乐搜出来听一下,哈哈,学习五十音的利器啊。
感悟
学习过程中的一些小小感悟,一门语言短期来看是不会有太大的变化的,但是放到历史的长河里面,与其他「语言」相互学习融合,最终会形成自己的语言和书写符号。虽然日语还没有学几个单词,但也知道日语有很多的外来词,但我没有想到的是有一些词和之前学的韩语是如此的像,比如
- 包,日语是 かばん,而韩语是 가방 ,两者的发音几乎都一样。
- 数字的三,日语是 さん,而韩语是 삼,发音也特别像,一个有点鼻音,一个最后需要闭嘴
而我知道平假名书写的词是早就存在的,因此也能看出两种语言在过去百年中的交流融合。而日语五十音中的多个「字」都或多或少的受到汉语发音的影响,な(奈),や(也),て (天),等等一些字也能看出来相互交融的过程。而学五十音的过程中也恰好听了一档播客,其实汉语在过去的一百年里深受日语的影响,因为闭关锁国几百年,导致外来文化都是在清朝崩溃之后由留学生从日本带来,现代汉语中有一大部分词都是先由日本学者翻译成汉字,然后才融入到现代汉语中的,比如宪法,哲学,美学,漫画,派出所,电话,艺术,干部,否定,假设,海拔,法人,商业,防疫,人权,革命等等,可以看到的是这些词包括学习生活的方方面面,也几乎在任何学科中都会用到,涉及经济学,美学,哲学,科学,法学,医学等等。更甚至资本主义,社会主义,主义这两字也是由日本学者先行翻译使用再流传到大陆的。在学习的过程中了解到这些有趣的文化交流结果也让本来枯燥的背诵和记忆变得有趣起来。就像当年我学习韩语一样,最初的原因其实非常朴素,就是为了听韩语歌曲,源起是因为一首背景音乐我只知道一小段歌词,用听歌识曲识别不了,而我也不懂韩语,那时就变得非常难受,但后来只学习了发音就解决了我这一个问题,只要能通过发音输入韩语,那就能通过韩语歌词来搜索,进而找到歌曲名字,这也是一段非常奇妙的经历。
日语学习计划
这一期的 [[20221009 21 天挑战计划]] 中把日语列为一个阶段性的挑战目标,希望可以对日语这门语言有一个初步的了解以及能够进行简单的对话。因为之前在大学的时候只简单的了解过五十音,之后又在 YouTube 上看过唐盾老师的入门,但因为平时也不怎么看日剧,日综,渐渐基本上都忘记了,所以对日语可以算是什么都不了解的。
通过我的检索和提前准备,把日语学习的基本步骤列到下面。
- 发音,五十音图
- 平假名、片假名对应记忆
- 清音
- 浊音
- 长音
- 拗音
- 促音
- ん 拨音,不能单独使用
- [[日语发音]]
- [[日语音调]]
- [[日语输入法使用]]
- 单词
- [[日语的数字]]
- 汉字词(来自汉语),固有词,外来词
- 日语发音入门 5000 使用词汇分类记忆法
- 日语水平考试 JLPT 标准
- N5,100 汉字,800 单词
- N4,300 汉字,1500 单词
- N3,600, 3000
- N2,1000,6000
- N1,2000,10000
- 词法
- 词性
- 名词
- 动词
- 形容词
- 副词
- 连词
- 接续词
- 动词变形
- 进行
- 过去
- 否定
- 被动
- 假定
- 意志
- 使动词
- 命令
- 可能
- 词性
- [[日语文法]]
- 肯定句
- 否定
- 疑问
- 高频使用的句子
- 历史
- 相关书籍
- 文化
- 书籍
- 影视文化作品
- [[日语歌曲]]
- 艺术作品
视频课程
初级日语视频课程:
入门学习计划
入门学习日语我准备按照:
- 发音
- 单词
- 基本文法
这样三个步骤先学习。
五十音
五十音是日语的基本发音,虽然叫五十音但实际只有 40 多个发音,有一些行的发音是有重复的。但如果有了五十音的基础,再在此加上,浊音,拗音,促音等发音规则,就相对比较简单了。
所以希望能够在 21 天计划中能够实现看到平假名,或片假名都能直接反映出读音。或者看到平假名就能想到片假名,反之亦然。
每天背诵 3 行,在 7 天左右能够完全按照顺序默写出平假名和片假名。然后随机不按照行或列的顺序来背诵,辅助以 Kana 或 Duolingo 等应用做到随时随地背诵。
单词
单词是一项长期的任务,早期的单词,一来从发音课程中老师举的例子中学习,另一方面,从开心词场或者 Duolingo 这些应用上通过基础发音来学习相关的单词。
希望能对常见的高频单词,每天学习 10 个左右。目前主要以 Duolingo 为主。后期可以辅助以 Anki 这一类 Flash Card 来周期性记忆。
文法
以我目前的水平还无法独立通过书籍来阅读相关文法内容,所以还需要借助上面提到的两位老师,唐盾老师和出口仁老师,入门阶段通过视频讲解先了解基础的语法内容。等把视频可能看完,然后接着再看一下《新版中日交流标准日本语》初级。
相关教材
教材部分只做了一下简单的了解,这一期计划中可能只以上面提及的两个视频内容为主,辅以手机上的应用。教材部分本人并不是非常了解,如果有日语专业的朋友对这些教材比较熟悉也非常欢迎留言告诉我,对于入门,哪一本教材比较合适。
- 大家的日语,官方语言学校指定的日语入门教材
- 第一册 25 课
- 新标日语初级上下
- 新标日语中级上下
- 新完全掌握日语能力考试
- 考前对策
- Tae Kim 的语法书(Tae Kim’s Japanese Grammar Guide),这是一本面向英语母语者的日语语法书,就像导读 上提到的那样,如果你会英语,那就等于打开了一道巨大的门,市场上充满了非常多质量不错的内容,比如这一本。这也让我想起来我当时学韩语的时候知道的 Talk To Me in Korean,做了非常长时间的内容,当有一定基础之后再去听他们的播客不知不觉就学会了很多语法和搭配。
相关应用
- Kana,主要用来记忆五十音,按顺序或无序,以达到平假名、片假名和发音三个联想记忆
- Duolingo,入门基本的发音,单词和简单交流用语,点此连接你我都可以获得 7 天的 PLUS
- 附上 Duolingo 开启 Leaderboard(排行榜) 小贴士
- 不清楚 Duolingo 为什么要删除大陆区的排行榜功能,所以多邻国只要判断你在大陆就会自动将 Profile 和 Leaderboard 隐藏掉
- 多邻国判断的条件有:
- 手机号
- 设备的时区
- 设备的 IP
- 所以与此同时要恢复排行榜,就必须接绑大陆的手机号,将设备时区调整到非 Beijing 或上海,如果在东八区可以尝试调整到香港,台湾和新加坡,并且操作的过程中全程需要使用非大陆的 IP 地址,这里可以推荐使用 VPN
- 当满足上面所有的条件之后 Duolingo 会自动打开排行榜
- 开心词场,主要是记忆单词。
- 烧饼日语,暂时没有使用。
Supabase 和 Appwrite 区别
在 Twitter 的时间线已经经常去的论坛上,[[Supabase]],[[Appwrite]],等等 Backend as a Service 的服务出现的频率越来越多,
Supabase 和 Appwrite 都是将自己称为 [[BaaS]] 来作为 Firebase 的代替。
Appwrite 在 2019 年 9 月首次发布,使用 PHP,TypeScript 编写。Supabase 首次发布于 2022 年 6 月,使用 TypeScript 编写。
Supabase 优点:
- 可以自托管
- 构建在关系型数据库 [[PostgreSQL]] 之上
- 支持对象存储 Object Storage
Appwrite 优点:
- [[Appwrite]] 可以自托管,支持多租户。这也就意味着单一的 Appwrite 实例可以支持无数账户和项目
- 可以通过 Docker 镜像快速启动
- Appwrite 不是用来代替当前的技术栈而是设计用来辅助,所以可以和当前的后端很好的融合
- Appwrite SDK 支持很多语言,接口设计也非常简洁
- 支持云函数
- 支持很多客户端,包括 Flutter, Android, iOS, Kotlin, Python, php, JavaScript 等等
- 支持超过 20 个 OAuth
- 无状态架构,所以可以非常轻松水平扩展
related
- [[Appsmith]]
reference
GitLab CI 提交代码 not allowe to upload code 问题解决
记录一下在 GitLab CI 中提交代码出现的错误。
在 CI 中 git push 提交代码,遇到如下的错误:
remote: You are not allowed to upload code.
fatal: unable to access 'https://gitlab-ci-token:[MASKED]@git.xxx.com/group/repo.git/': The requested URL returned error: 403
看起来是 403 权限不足,但是可以看到的是提交代码的时候,使用的 remote 地址是 https://gitlab-ci-token 开头的。这是因为 GitLab CI runner 在 HTTPS 协议下执行时,不支持 git push 操作。
必须配置使用 ssh 协议,然后需要使用 /root/.ssh 目录中配置的私钥,该私钥需要有代码访问权限。
解决方案
首先需要将 SSH KEY 配置到 GitLab 后台,然后将私钥放到 CI 的镜像中。
mkdir -p ~/.ssh
cp "${CI_GIT_SSH_KEY}" ~/.ssh/id_rsa
chmod 600 ~/.ssh/id_rsa
ssh-keyscan gitlab.com > ~/.ssh/known_hosts
在 CI 脚本中将仓库的地址修改为 SSH:
git remote rm origin && git remote add origin git@gitlab.com:$CI_PROJECT_PATH.git
然后再使用 git push 就没有问题了。
reference
BaaS 应用 Appwrite 体验和使用
在 Twitter 的时间线上能看到越来越多的 Backend-as-a-Service 的产品发布,包括 [[Firebase]], [[Supabase]], [[Railway]], [[Fly.io]], [[Okteto]], [[Nhost]] 等等,这两天又发现一款叫做 [[Appwrite]]。Appwrite 宣称自己的是 Firebase 的开源辅助,可以代替大部分的 Firebase 功能。
看来创始人起名字的时候也非常直截了当,Appwrite 就是一款为前端和移动开发人员提供的可以自行搭建的后端服务,使用 PHP 编写,提供了构建一款应用需要的最基础的一些功能,比如注册,登录,K-V 数据存储,云函数等等功能。并且 Appwrite 提供了非常多的客户端支持,包括常用的 iOS,Flutter,Android,Swift 等等,也包括了大部分的后端常用语言的 SDK,Python,Php,Ruby 等等。
Appwrite 是一个开源的、自托管的,Backend-as-a-Service(BaaS,后端即服务),可以快速构建安全的、现代的应用程序。Appwrite 提供了用户身份验证,授权,会话管理,角色访问控制,数据库,对象存储等等基础组件。
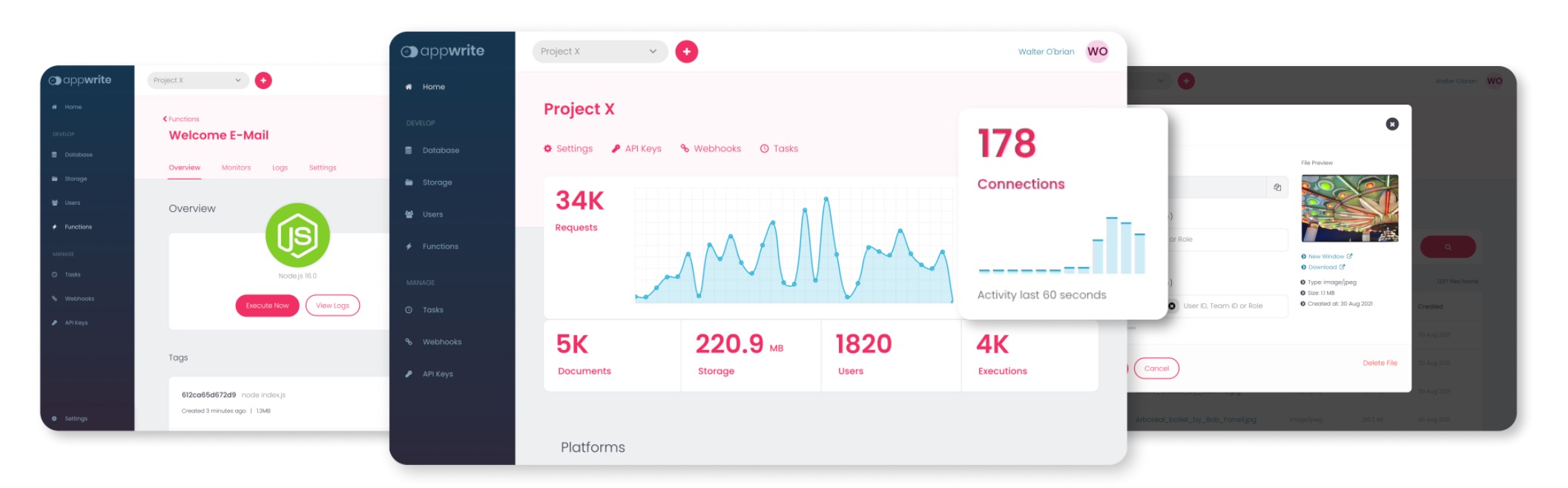
Installation
Appwrite 官方提供了直接通过 Docker 命令来安装 Appwrite 的方法,见这里。但本人觉得 docker-compose 的方式执行扩展性和可配置性都比较好,所以这里就使用 docker-compose 来安装 Appwrite。
环境变量的含义见官网。
功能
- 数据库
- 存储
- 本地化
- 功能
- 控制台
为什么用 appwrite 替代 Firebase?
- 是开源的
- 开发者社区不断扩张
- 专注于 Web/Flutter 开发者
- 简洁
功能
Appwrite OAuth
通过 Appwrite 提供的身份验证功能,可以轻松地集成三方的登录服务,包括 Facebook, GitHub, LinkedIn 等等。
借助 Appwrite 可以快速构建一个用户账户登录系统,并且 Appwrite 支持用户使用邮箱密码,Magic 链接等等方式来验证登录自己的账户。
Appwrite Tasks
Tasks 服务提供了定期执行任务的能力,不管是 contabs 或者长时间运行的守护程序都可以实现。
Appwrite Task 服务是设置定期计划作业的方法。无需使用复杂的 crontabs 或长时间运行的守护程序进行处理,不必担心诸如容错,监视和错误日志记录之类的事情,您所要做的就是提交带有任务的表单作为 HTTP 端点和类似 cron 的语法,以指示如何通常应该执行它。
Appwrite Webhooks
Webhooks 允许快速集成后端任务的触发,比如在新用户注册的时候发送邮件通知,或者在应用文档更新时清除缓存都可以通过 Webhooks 方式实现。
存储
Appwrite 存储服务是让您或您的应用程序用户,安全、简单地上传和管理文件的最简单方法。Appwrite Storage API 利用了与 Appwrite 数据库相同的简单读写权限机制。这使您可以轻松地决定是否所有用户,特定用户甚至用户团队都可以访问您的文件。 Appwrite Storage 服务提供的最有用的功能之一是能够预览文件内容并将其显示为应用程序或网站中的缩略图的功能。您还可以动态更改缩略图的大小,在不同的图像格式之间转换它们(支持 webp 格式),并更改其质量以改善网络性能。
团队管理
Appwrite Teams 服务允许您和您的用户创建团队并共享对不同 API 资源(如文件或文档)的许可。每个团队成员还可以担任不同的角色,以使开发者拥有更大的灵活性。
API
Account API vs Users API
Account API 在当前登录的用户下,通常是客户端集成。而 Users API 通常是集成到服务端,在管理员的权限下,用来操作所有用户。
当通过 JWT 验证的时候,Account API 中有一些方法也可以被服务端使用。这可以允许服务端来以用户的身份执行某些行为。
Git 对文件权限的控制
因为一直使用 assh 来管理我的 ssh config,整个 SSH config 都是用 Git 仓库来管理的,但是每次一更新了 config 文件,git pull 之后 config 的文件权限都会出错:
Bad owner or permissions on /path/to/.ssh/config
发现 git 拉取的文件丢失了权限,必须通过 sudo chmod 600 ~/.ssh/config 来修改才能使用。
于是就想要了解一下 Git 仓库中怎么来管理文件权限的。
Git 只有一 bit 位来用存储文件权限
Git 只有一位用来记录权限,可执行还是不可执行。
这意味着,下面的权限是不会被 Git 追踪的:
- 文件所有者的读写权限(write, read)
- 文件所有者外的其他权限都不会被追踪,包括 group, other 中的 execute, write, read 权限都不会被记录
有了这个前提知识就能够解释为什么我们使用 git diff 命令的时候,Git 有些时候会显示类似如下的文件权限:
old mode 100644
new mode 100755
说明:
- 755, owner 可以 read/write/execute, group/others 可以 read/execute
- 644, owner 可以 read/write, group/others 只能 read
Git 会给予一个没有执行权限的文件 file mode 为 100644 ,给一个可执行的文件 100755 ,如果将文件的权限从 7xx 修改成 6xx,或者反过来(调整可执行权限),那么 Git 就会追踪到这个修改。
Git 中可以通过如下配置来忽略文件 mode
git config core.fileMode false
如果要全局忽略,可以添加 --global 参数:
git config --global core.fileMode false
.info 域名涨价应对策略
之前收到 Google Domains 邮件,info 域名将在 10 月 26 号之后从 12 美元一年涨价到 22 美元一年,现在剩下的时间不多了,晚上回家处理一下。
刚收到 Google domain 的续费通知邮件,竟然发现 info 域名需要从 $12 涨价到 $22 ,域名注册局的生意一本万利啊!
— Ein Verne (@einverne) September 27,2022
涨价原因
通常不同的域名注册商都会提供动态的注册费用,比如我一直使用的 Google Domains 自我开始使用起 info 域名就是 12 美元一年,很多年没有变化过,但是有一些其他的域名注册提供商会提供更加低廉的第一次注册费用,但是往往续费和转入的费用要更高。
一个域名的费用可以分成好几部分。
域名注册费用组成:1
- ICANN 费用(不是所有的域名都有此费用)
- Registry 费用,Registry 是维护一个顶级域名的公司,比如
.com,.net,.org等背后的公司。这些公司都从 ICANN 买断了对 TLD(顶级域名)的管理权,所以有权利决定以什么价格售卖域名。- 对于 Registry 他需要出售足够多的域名才能够盈利
- Registry 也需要维护一个顶级域名的价值,比如不让某些人利用一些域名来发垃圾信息
- 也需要维护一个顶级的 Name server 来提供该顶级域名的域名解析服务,不至于出现之前遇到过得 全球 club 域名宕机事件
- Premium domains,这是一些注册局觉得非常有价值的域名
- 其他费用,注册商可能对隐私保护,域名解析,转发,域名邮箱或注册商提供的其他增值服务收费
Verisign 是 .com 的域名注册局,在 2018 年的时候与美国商务部达成协议,允许他在之后的十年中每年将价格提高 7%。2 同样的各大域名注册商也相继提高了 .info, .mobi, .pro 等等域名的注册费用。34
解决方案
首先到 https://tld-list.com/ 网站上查询 .info 域名,然后发现对于 Transfer 来说 Google 提供的价格就是最便宜的。

综合来说,还是在 Google Domains 先续费 9 年再说吧。
-
https://news.gandi.net/en/2020/09/how-much-does-a-domain-cost-and-what-comes-with-it/ ↩
-
https://www.domainnameapi.com/blog/verisign-has-decided-to-increase-the-price-of-the-com ↩
-
https://news.gandi.net/en/2021/12/price-increase-on-info-mobi-and-pro-domains-on-january-14-2022/ ↩
-
https://www.techrepublic.com/article/youre-going-to-pay-more-for-org-and-info-domains-following-icanns-lifting-of-price-caps/ ↩
MP3 ID3 结构
ID3 是一个元数据(metadata) 的容器,通常和 MP3 文件一起。
ID3 有两个版本:
- ID3v1
- ID3v2
ID3v1
ID3v1 比较简单,存放在 MP3 文件末尾,占用 128 个字节,使用任意一个 16 进制编辑器打开 MP3,就可以看到。
V1 版本以 TAG 字符开始,记录了 MP3 文件的歌手名,标题,专辑名称,年代,风格等信息。
| 字节 | 长度 | 说明 |
|---|---|---|
| 1-3 | 3 | TAG 字符,说明 ID3v1 开始 |
| 4-33 | 30 | 歌曲名 |
| 34-63 | 30 | 歌手 |
| 64-93 | 30 | 专辑名 |
| 94-97 | 4 | 年份 |
| 98-127 | 30 | 附注 |
| 128 | 1 | 音乐类别,147 种1 |
ID3v2
ID3v2 版本位于 mp3 开头,长度可变。
ID3v2 有四个版本
- ID3v2.1
- ID3v2.2
- ID3v2.3
- ID3v2.4
因为在文件开头,所以对 ID3v2 版本的操作要比 ID3v1 慢。
以 ID3v2.3 为例,由一个标签头和若干标签帧组成,至少有一个标签帧,每个标签帧记录一种信息,比如标题,作曲家等等。
可以通过 vim 打开 mp3 文件,然后执行 %!xxd 以 16 进制查看。
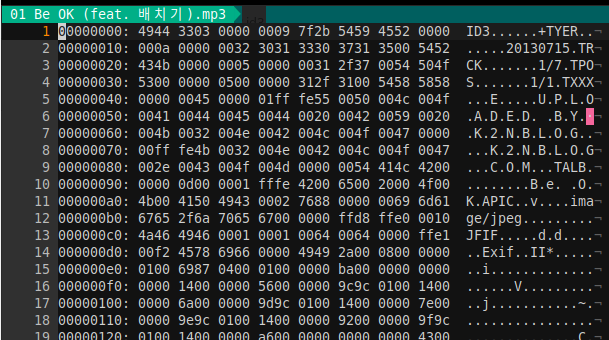
文件开头长度 10 字节,结构如下:
char Header[3]; /*必须为“ID3”否则认为标签不存在*/
char Ver; /*版本号ID3V2.3 就记录3*/
char Revision; /*副版本号此版本记录为0*/
char Flag; /*标志字节,只使用高三位,其它位为0 */
char Size[4]; /*标签大小*/
说明:
- Flag,一般使用高三位
- 第一位表示是否使用 Unsynchronisation
- 第二位表示是否有扩展头部
- 第三位是否是测试标签
- 标签大小是指包括标签头的 10 字节在内的所有标签帧的大小,每个字节只使用后 7 位,最高位为 0
- 计算大小时将最高位去掉,得到 28 位二进制数,就是标签大小
标签帧
每个标签帧都有 10 个字节的帧和至少一个字节的不固定长度的内容组成。
帧头部:
char FrameID[4]; /*用四个字符标识一个帧,说明其内容,稍后有常用的标识对照表*/
char Size[4]; /*帧内容的大小,不包括帧头,不得小于 1*/
char Flags[2]; /*存放标志,只定义了 6 位*/
说明:
- 帧标识,四个字符标识一个帧
- TIT2 歌曲标题
- 大小,每个字节的 8 位全部使用
- 标志,只定义了前 6 位
MP3 文件结构
大体上分三个部分:
- ID3v2
- 音频数据
- ID3v1
附录
0="Blues";
1="ClassicRock";
2="Country";
3="Dance";
4="Disco";
5="Funk";
6="Grunge";
7="Hip-Hop";
8="Jazz";
9="Metal";
10="NewAge";
11="Oldies";
12="Other";
13="Pop";
14="R&B";
15="Rap";
16="Reggae";
17="Rock";
18="Techno";
19="Industrial";
20="Alternative";
21="Ska";
22="Deathl";
23="Pranks";
24="Soundtrack";
25="Euro-Techno";
26="Ambient";
27="Trip-Hop";
28="Vocal";
29="Jazz+Funk";
30="Fusion";
31="Trance";
32="Classical";
33="Instrumental";
34="Acid";
35="House";
36="Game";
37="SoundClip";
38="Gospel";
39="Noise";
40="AlternRock";
41="Bass";
42="Soul";
43="Punk";
44="Space";
45="Meditative";
46="InstrumentalPop";
47="InstrumentalRock";
48="Ethnic";
49="Gothic";
50="Darkwave";
51="Techno-Industrial";
52="Electronic";
53="Pop-Folk";
54="Eurodance";
55="Dream";
56="SouthernRock";
57="Comedy";
58="Cult";
59="Gangsta";
60="Top40";
61="ChristianRap";
62="Pop/Funk";
63="Jungle";
64="NativeAmerican";
65="Cabaret";
66="NewWave";
67="Psychadelic";
68="Rave";
69="Showtunes";
70="Trailer";
71="Lo-Fi";
72="Tribal";
73="AcidPunk";
74="AcidJazz";
75="Polka";
76="Retro";
77="Musical";
78="Rock&Roll";
79="HardRock";
80="Folk";
81="Folk-Rock";
82="NationalFolk";
83="Swing";
84="FastFusion";
85="Bebob";
86="Latin";
87="Revival";
88="Celtic";
89="Bluegrass";
90="Avantgarde";
91="GothicRock";
92="ProgessiveRock";
93="PsychedelicRock";
94="SymphonicRock";
95="SlowRock";
96="BigBand";
97="Chorus";
98="EasyListening";
99="Acoustic";
100="Humour";
101="Speech";
102="Chanson";
103="Opera";
104="ChamberMusic";
105="Sonata";
106="Symphony";
107="BootyBass";
108="Primus";
109="PornGroove";
110="Satire";
111="SlowJam";
112="Club";
113="Tango";
114="Samba";
115="Folklore";
116="Ballad";
117="PowerBallad";
118="RhythmicSoul";
119="Freestyle";
120="Duet";
121="PunkRock";
122="DrumSolo";
123="Acapella";
124="Euro-House";
125="DanceHall";
126="Goa";
127="Drum&Bass";
128="Club-House";
129="Hardcore";
130="Terror";
131="Indie";
132="BritPop";
133="Negerpunk";
134="PolskPunk";
135="Beat";
136="ChristianGangstaRap";
137="Heavyl";
138="Blackl";
139="Crossover";
140="ContemporaryChristian";
141="ChristianRock";
142="Merengue";
143="Salsa";
144="Trashl";
145="Anime";
146="JPop";
147="Synthpop";
reference
-
见附录 ↩
将字幕压制到视频中
本文总结一下将字幕文件压制到视频中的方式,(当然我个人是非常不喜欢直接将字幕压制到视频流中作为硬字幕压制的,但有些时候可能就是需要分享这样硬字幕的视频,比如视频网站,所以也会在下文总结一下)。
按照压制方式可以分成,将字幕嵌入视频流(也就是俗称的硬字幕)适合在视频网站分享,将字幕作为单独的字幕流和视频作为封装格式,需要用播放器播放。
压制方式(推荐程度从上到下):
- [[FFmpeg]] 适合熟悉命令行工具的人
- [[HandBrake]] 开源的全平台的视频编码工具(推荐)
- [[MKVToolNix]] 将字幕文件添加到视频中,但是作为软字幕,不改变视频流(推荐!)
- [[MeGUI]] 只支持 Windows AVS 脚本生成器
- 小丸工具箱 只支持 Windows
- [[Arctime Pro]] Windows/macOS
如果要知道如何从 mkv 文件格式中提取字幕,可以参考 这篇文章 。
字幕类型
- 外挂字幕:一般是一个外部的独立文件,一般有 srt, ass 等格式,播放视频时如果字幕文件与视频文件名一致,大部分的播放器会自动加载
- 软字幕:也叫内挂字幕、封装字幕、内封字幕,字幕流等,就是把字幕文件嵌入到视频中,作为流的一部分,在播放视频文件时播放器会加载字幕,由用户选择使用哪一个字幕
- 硬字幕:将字幕嵌入到视频流中合成一个文件,此时字幕成为视频画面的一部分,在任何播放器中都会显示该字幕,且用户无法关闭字幕。硬字幕存在的原因在于用户端播放器兼容问题,适合在所有播放器上播放,但缺点也是无法去除字幕
软字幕
作为字幕流(内封字幕、软字幕)嵌入到视频容器中。字幕流和视频和音频流具有相同的地位。视频格式中的 mkv 就是一种封装格式,通过 ffmpeg -i video.mkv 就能在输出结果中看到视频流和字幕流是属于不同的 stream 的。
MKVToolNix
MKV 封装工具:[[MKVToolNix]] MKV 提取工具:gMKVExtractGUI、MKVExtractGUI
借助 MKVToolNix 提供的界面操作即可。
FFmpeg
介绍一下如何使用 FFmpeg 将字幕作为单独的字幕流压制到视频中。
ffmpeg -i input.mkv -i subtitles.srt -c copy -c:s mov_text output.mp4
ffmpeg -i input.mkv -i subtitles.srt -c copy -c:s srt output.mkv
说明:
-c copy -c: s mov_text告诉 FFmpeg 对于视频,音频,和字幕文件都直接 copy- 选项的顺序不能搞错,如果要随意顺序,那么可以显示指定
-c: v copy -c: a copy -c: s mov_text
假设原始输入文件没有字幕的情况下,也可以直接
ffmpeg -i input.mkv -i subtitles.srt -c copy output.mkv
FFmpeg 会自动识别字幕文件并做映射。
ffmpeg -i input.mp4 -sub_charenc 'UTF-8' -f srt -i input.srt -map 0:0 -map 0:1 -map 1:0 -c:v copy -c:a copy -c:s mov_text output.mp4
ffmpeg -i input.mp4 -sub_charenc 'UTF-8' -f srt -i input.srt -map 0:0 -map 0:1 -map 1:0 -c:v copy -c:a copy -c:s srt output.mkv
如果要指定语言:
ffmpeg -i input.mp4 -i subtitle.en.srt -c copy -c:s mov_text -metadata:s:s:0 language=eng ouptut_english.mp4
-metadata: s: s:0设置 metadata 格式Stream: Subtitle: Number从 0 开始language=eng设置字幕的语言,使用 ISO 639 3 位英文表示
如果要设置多个字幕:
ffmpeg -i ouptut_english.mp4 -i subtitle.chi.srt -map 0 -map 1 -c copy -c:s mov_text -metadata:s:s:1 language=chi output_chi.mp4
在之前的基础之上,再添加一个中文字幕。
或者直接使用一行命令:
ffmpeg -i input.mp4 -i subtitle.en.srt -i subtitle.chi.srt -map 0 -map 1 -map 2 -c copy -c:s mov_text -metadata:s:s:0 language=eng -metadata:s:s:1 language=chi output_eng_chi.mp4
硬字幕
FFmpeg
使用硬编码将字幕嵌入视频的方式会更加耗时,需要重新编码文件。
[[FFmpeg]] 要在视频流上面加上字幕,需要用一个叫做 subtitles 的滤镜,要使用这个滤镜,在命令中写上 -vf subtitles=字幕文件名 ,推荐不管文件名如何都在字幕文件两边加上双引号,比如 -vf subtitles="字幕 文件名",因为如果文件名中包含空格或其他特殊字符,在不使用双引号的情况下 Shell 会解析失败。
# 使用 subtitles 滤镜为视频添加字幕,字幕文件在视频流中,输出文件不含字幕流
ffmpeg -i input.mkv -vf subtitles="subtitles.srt" output.mkv
说明:
-vf是-filter: v参数的缩写subtitles="subtitle.srt"则是 filter 的名字,后面是字幕文件
将 mkv 文件中的字幕压制到 mp4
# 将 input.mkv 中的字幕(默认)嵌入到 output.mp4 文件
ffmpeg -i input.mkv -vf subtitles=input.mkv output.mp4
如果要将其他的字幕,可以指定,比如第二个字幕:
ffmpeg -i input.mkv -vf subtitles=input.mkv:si=1 output.mkv
subtitle 更多 用法
ass 格式
如果要处理 ass 格式的字幕文件,那么需要 FFmpeg 启用 libass ,可以通过执行 ffmpeg —version 来查看输出中是否有 --enable-libass,如果没有这个选项那么可能需要重新安装,或者重新编译安装 FFmpeg 。
如果要嵌入 ass 格式字幕,可以:
brew install ffmpeg --with-libass
ffmpeg -i path/to/video.mp4 -vf "ass=subtitle.ass" out.mp4
ass 格式字幕文件提供了更多的格式选择,比如加粗,斜体,字体,颜色等等,可以使用更加专业的字幕制作软件生成。
reference
文章分类
最近文章
- AI Shell 让 AI 在命令行下提供 Shell 命令 AI Shell 是一款在命令行下的 AI 自动补全工具,当你想要实现一个功能,敲一大段命令又记不住的时候,使用自然语言让 AI 给你生成一个可执行的命令,然后确认之后执行。
- 最棒的 Navidrome 音乐客户端 Sonixd(Feishin) Sonixd 是一款跨平台的音乐播放器,可以使用 [[Subsonic API]],兼容 Jellyfin,[[Navidrome]],Airsonic,Airsonic-Advanced,Gonic,Astiga 等等服务端。 Sonixd 是一款跨平台的音乐播放器,可以使用 [[Subsonic API]],兼容 Jellyfin,[[Navidrome]],Airsonic,Airsonic-Advanced,Gonic,Astiga 等等服务端。
- 中心化加密货币交易所 Gate 注册以及认证 Gate.io 是一个中心化的加密货币交易所。Gate 中文通常被称为「芝麻开门」,Gate 创立于 2013 年,前身是比特儿,是一家致力于安全、稳定的数字货币交易所,支持超过 1600 种数字货币的交易,提供超过 2700 个交易对。
- 不重启的情况下重新加载 rTorrent 配置文件 因为我在 Screen 下使用 rTorrent,最近经常调试修改 rtorrent.rc 配置文件,所以想要找一个方法可以在不重启 rTorrent 的情况重新加载配置文件,网上调查了一下之后发现原来挺简单的。
- Go 语言编写的网络穿透工具 chisel chisel 是一个在 HTTP 协议上的 TCP/UDP 隧道,使用 Go 语言编写,10.9 K 星星。