《阿加莎・克里斯蒂自传》读书笔记
怎么知道的这一本书
虽然很早就已经知道阿加莎·克里斯蒂,也曾经看过一些她的作品,比如《无人生还》、《尼罗河上的惨案》这类非常脍炙人口的作品,但是对其人一直不是非常了解,直到去年偶然间在路上听了一期关于阿加莎·克里斯蒂的播客,直到讲到她的生平,经历两次世界大战,有传奇的婚姻,才逐渐对她产生了兴趣。她是有怎么样的人生经历才能够塑造出如此精彩的虚构人物?她又是有怎么样的新奇的遭遇才能构造出如此出人意料的作案手法?
关于作者
阿加莎出生于 1890 年的伦敦德文郡托基,是英国著名的侦探小说家,剧作家。她在第一次世界大战期间志愿成为了一名护工,战争结束之后创作了第一步侦探小说《斯泰尔斯庄园奇案》,几经周折之后在 1920 年出版,从此开启了克里斯蒂传奇而辉煌的创作生涯。阿加莎克里斯蒂创作生涯持续五十余年,一共创作了八十部小说,作品畅销全世界,被称为继柯南·道尔之后最伟大的侦探小说家。
几句话总结书的内容
全书一共分成了十一个章节,涵盖了阿加莎从小成长,到青年,成熟直至垂暮的所有人生故事。阿加莎在写自传时已经有 60 岁的高龄,写了 15 年才最终定稿。这和她自己在写作侦探小说时文思泉涌,连续写作几天成一本书的写作方式完全不同。但也正是因为如此耗时的写作才使得这部自传内容翔实。
启发或想法
关于战争
关于第一次世界大战、第二次世界大战,我更多的是在影视作品中通过视觉化的方式看到,很少有机会通过一手的文字信息去了解那些年真正在发生的事情。就像大部分人看到的战争一样,突然之间就爆发了,而这也影响到了青年时期的阿加莎克里斯蒂。
关于婚姻
阿加莎的一生中经历了两次婚姻,在 1926 年母亲去世的那一年,第一段婚姻因为丈夫的婚外情而结束,这也使得阿加莎曾经一度离家出走失踪。但也正是因为命运的多舛,才让阿加莎独自一人向东旅行,在途中遇到了第二任丈夫。
关于自传
过去很长一段时间我都不喜欢读名人的自传,有意地避开了很多,但是最近几年却越来越喜欢读一些自传,读过富兰克林的自传,读过微软 CEO 萨提亚 纳德拉,读过 Linus Torvalds 的自传《Just for Fun》,也读了巴菲特的自传,过去我常常想去读自传,不如去读这些人物的其他专题性作品,但读过之后才渐渐地意识到这些名人的成就也好,思想也好,都脱离不开那个时代,那个环境,他们在生活中的遭遇,以及他们人生的转折都只能在自传中窥见。而这些名人的形象,也只有我读完全书之后才能在我的脑海中变得立体,而平时他们只能是维基百科上的一副二维照片,而通常也只是某个年龄拍下的,而我读完这些自传记住的是十几岁离家出走到处漂泊的富兰克林,记住的是因为自己的兴趣而发布在 FTP 上 Linux 内核的青年时期的 Linux,记住的是那个从印度移民美国拥抱文化开放、照顾患病孩子父亲形象的纳德拉。而在这一部阿加莎的自传中,我能看到那个幽默、命运坎坷的阿加莎,她人生的每一次转折都在塑造她对世界的认识,也正是她见到的每个人,遭遇的每一个时代变化,才让她能在战争期间学到药剂知识,才能让她在离婚之后去周游世界,才能让她为了生计几十年写作。
谁应该看这本书
对阿加莎·克里斯蒂的作品感兴趣的人
印象深刻的句子
- 人生中最大的错误莫过于所见所闻不得其时。大多数人是在学校里学习莎士比亚的,生生把名著毁了。
- 构思一部小说的过程是一种奇怪的感受,在六七年之久的时间里,你心里始终明白,自己终有一天会把它写出来。
- 我喜欢活着,我有时会绝望无比,会痛苦难耐,会饱受忧愁的折磨。可是当一切经历过去之后,我仍然很清楚地认识到,好好活着就是最了不起的事情。
推荐一款 macOS 上适合开发人员使用的开源工具集合 DevToysMac
DevToysMac 是一款 macOS 上的开发者常用工具集合,在 Windows 上有一款使用 C# 实现的开发者工具合集工具叫做 DevToys,但是在 macOS 上使用不了,于是 ObuchiYuki 就使用 Swift 编写了一个 macOS 上原生的应用。
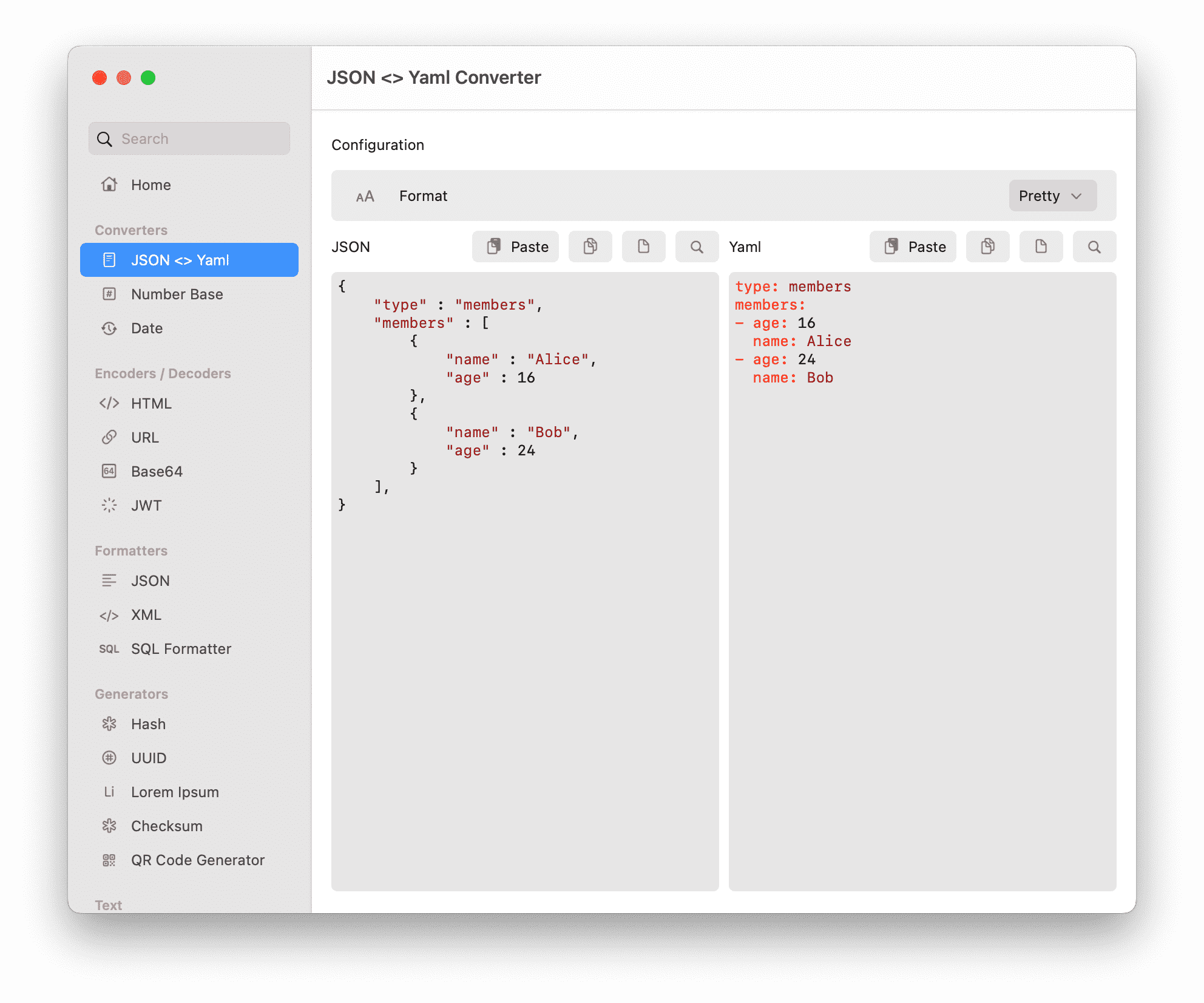
Installation
使用 Homebrew :
brew install --cask devtoys
Features
DevToysMac 提供的一些功能:
- JSON 和 YAML 相互转换
- 二进制,八进制,十进制,十六进制转换
- 日期,时间戳转换
编解码:
- HTML 编解码
- URL 编解码
- Base64 编解码
- JWT
格式化:
- JSON 格式化
- XML 格式化
- SQL 美化
生成器:
- Hash 生成
- UUID 生成
- Lorem Ipsum 生成器,Lorem ipsum 是一段常用于印刷和排版领域的拉丁文乱数文字,用作占位符来展示排版、字体和布局等视觉效果。它在设计、出版、网页开发等领域被广泛使用。
- Checksum
- QR Code 生成器
文本相关:
- 文本大小写
- 正则
- 文本差异
- Hyphenation
图像相关:
- PNG/JPEG 压缩
- PDF 生成器
- 图片格式转换
- 图标生成
- 二维码读取
媒体相关:
- 颜色拾取器
- 音频转码
- Gif 转换
related
- [[MooTool]] 一款使用 Java 编写的开源工具。
REST-assured 简单使用
REST-assured 是 Java 实现的一套 REST API 测试框架。在 Java 中测试和验证 REST 接口的难度要大于动态语言比如 Ruby 或 Groovy,而 REST Assured 将测试接口的能力大大简化了。
Maven:
<dependency>
<groupId>io.rest-assured</groupId>
<artifactId>rest-assured</artifactId>
<version>4.2.0</version>
<scope>test</scope>
</dependency>
导入静态类:
import static io.restassured.RestAssured.*;
使用:
given().
XXXX
when().
XXXX
then().
XXXX
行为驱动开发中定义的结构,Given-When-Then。
- Given 在某场景下
- 设置测试的初始内容,包括请求头,参数,请求体,cookie 等
- When 发生了什么事情
- 执行的操作,GET/POST/PUT/DELETE 等
- Then 产生了什么结果
- 解析结果,断言
GET
测试 GET 请求:
given().
queryParam("mobilephone","13323234545").
queryParam("password","123456").
when().
get("http://httpbin.org/get").
then().
log().body();
POST
测试 POST 请求:
表单:
given().
formParam("mobilephone","13323234545").
formParam("password","123456").
when().
post("http://httpbin.org/post").
then().
log().body();
JSON 参数:
String jsonData = "{\"mobilephone\":\"18023234545\",\"password\":\"23456456\"}";
given().
body(jsonData).contentType(ContentType.JSON).
when().
post("http://httpbin.org/post").
then().
log().body();
上传文件:
given().
multiPart(new File("D:\\file.png")).
when().
post("http://httpbin.org/post").
then().
log().body();
ChatGPT(OpenAI) 账号注册
本文总结一下注册 ChatGPT 的方法。
前提准备工作
- 一个代理,可以是韩国,日本,印度,新加坡,美国,可以到这里 注册使用
- 一个能够接受验证码的国外手机号,如果没有,用网上的虚拟接收验证码的服务也行,可以注册这个 sms-activate.org
- 一个浏览器,最好是 Chrome,Edge,[[Vivaldi]] 等
注册虚拟号接受验证码
打开虚拟号码接收验证码平台 sms-activate.org (带邀请 AFF),注册一个账号
注册完成之后,需要充值使用,接码平台使用的货币是卢布。
接收一次 OpenAI 的电话验证大约需要 11 卢布,换算成人民币大概是 1 块钱,平台充值的时候接收美元,可以先充值 1 美元。
注册 OpenAI 账号
打开浏览器的隐身模式,然后访问 ChatGPT(OpenAI) 的账户注册页面 。直接使用谷歌邮箱登录注册的成功率比较高,推荐直接通过 Google 登录注册。如果不想关联 Google,也可以直接使用邮箱注册。
使用邮箱注册后会收到一个验证邮件,再接受的邮件中点击验证链接,正式进入注册。如果遇到提示说不能在当前国家服务,那么就需要切换代理了。
另外需要注意的是,如果出现了当前国家不提供服务的错误,最好是清空 Cookie 之后再试。如果是在隐身模式下,那就关闭隐身模式,重新登录。
通过了地区校验之后可以填写手机号,这里需要回到 sms-activate 接码平台上,在左侧边栏搜索 OpenAI,然后选择一个国家,可以选择一个手机号接码最便宜的国家,比如印度尼西亚,肯尼亚等
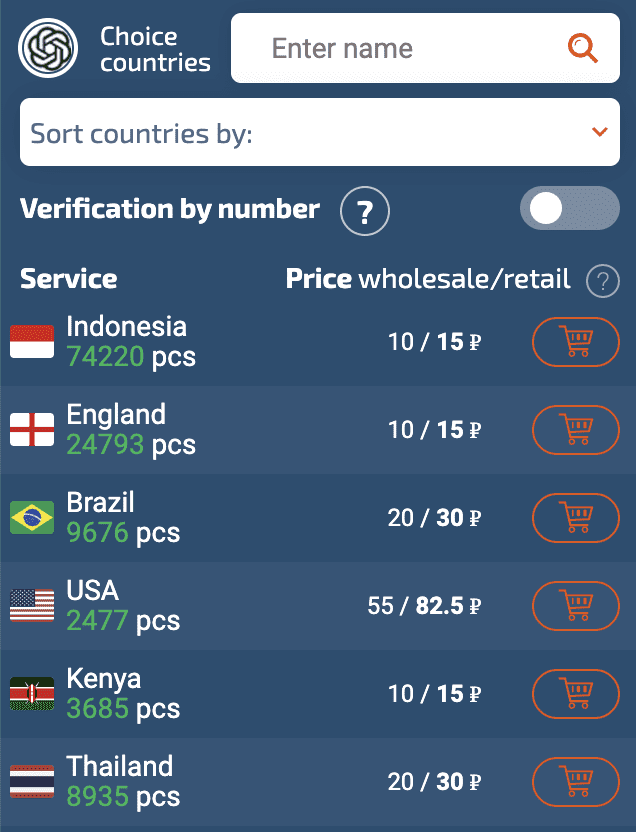
然后点击购物车,复制这个号码到 ChatGPT(OpenAI) 的注册页面,然后点击发送验证码,在接码网站会收到验证码。
最后就是完成 OpenAI 的注册。
然后就能访问 ChatGPT 了。新注册的 OpenAI 账号官方会赠送 5 美元的 API 调用额度。可以利用这个 API Key 做一些想做的事情。
如果不想自己注册,也可以到小店 里面购买共享的账号。
J3455 主板无法使用 PCIe 扩展 SATA 启动系统解决
把自己之前用 J3455-itx 主板组的 NAS 搬回了,但突然无法启动,这里就记录一下排错的过程。
最早启动的时候,无法进入系统,启动日志里面报错:
ata 7: COMRESET failed (errno=16)
开始怀疑是搬家的时候硬盘坏了。所以拆开主机,把其中的第四块硬盘 SATA 线拔掉了。重新启动主机,发现竟然能进入系统了。并且用 fdisk 查看,所有的其他硬盘都没有问题。
这个时候我仔细的检查了一下 SATA 的连线,J3455-itx 这块主板只有 4 个 SATA 口,但是我使用 PCIe 扩展了 2 个 SATA 口,一共接了 5 块硬盘,1 块 SSD 安装了系统,4 块 HDD 机械硬盘。
为了腾位置给 SSD,所以我将一块 HDD 的 SATA 线连接到了扩展卡的 SATA 接口,就是将这个接口拔掉,才能够进入系统。这个时候我开始怀疑是不是扩展卡在搬运的过程中损坏了。于是加紧在京东又下单了一个全新的 PCIe 转 SATA 扩展卡。
今天终于把全新的扩展卡安装上来,但是发现这一块机械硬盘还是无法读取。一度又让我怀疑真的是磁盘坏了,为了排除这个嫌疑,我拿出了之前买过的 SATA 转 USB 的设备,拿了 Linux Mint 发现能正常读取这一块硬盘,因为四块机械硬盘是通过 [[MergerFS]] 合并成一块逻辑硬盘使用的,所以这一块硬盘上也能读取到部分的数据,证明机械硬盘是没有问题的。
这个时候我已经排除了机械硬盘的问题,扩展卡的问题,我又在怀疑难道是 PCIe 接口坏了。这个时候我就把 SSD 拆了下来,然后把四块机械硬盘连接到了主板上的四个 SATA 接口,通过 USB 来启动 SSD,过程中我发现系统完全启动正常,并且能够在 [[Proxmox VE]] 下安装的 [[OpenMediaVault]] 下正常挂载 4 块硬盘,读写也完全没有问题。
启动系统的过程中还遇到了 soft lockup 问题,这个时候还以为是磁盘的 IO 造成的。但后来仔细想想应该是通过 USB 启动的系统在读写上存在瓶颈导致的。

那剩下的问题就肯定出在 PCIe 这个接口上。我又换回了之前的扩展卡,然后重新在 BIOS 中查看,调整配置。当我将 SSD 连接到扩展卡,并启动的时候 J3455-itx 主板无法找到可启动的设备,直接进入了 BIOS。
这个时候我突然想起来用 J3455 和扩展卡在 Google 搜索了一下。于是就看到了 这个帖子 其中的一句话惊醒了我。
主板 BOIS 里打开 CSM 试试
我在 BIOS 里面找到 CSM 设置,启用,然后重启系统,竟然能够从 SSD 启动了,扩展卡没有坏,硬盘没有坏,只是 BIOS 里面的一行配置变了!
什么是 CSM
CSM 全称是 Compatibility Support Module,是 BIOS 用来启动旧版操作系统和其他旧软件的一种特性。可以让 UEFI BIOS 兼容 Legacy+MBR 启动模式。
我已经忘记了之前安装 Proxmox VE 的时候用的什么引导了,但启用了 CSM 的时候就能够找到磁盘上的引导程序,并成功启动系统了。
至此整个 Debug 的过程才算结束。没想到的是新年假期竟然花了半天时间 Debug 硬件,o<(=╯□╰=)>o
2022 年读书笔记
前两年对哲学,期权,投资等等分类下的书籍比较多,但是 2022 年看得书就比较杂,有一些是在书单中放了很久的书,正好有契机拿出来看看。
之前历年的记录:
传记
- [[康德传]] 是一本康德的传记,康德是一位我越了解越敬佩的人,不仅在于他的思想,当我知道他可以数年如一日一样每天坚持在固定时间去散步,作息非常规律的时候,我知道他是那个言行一致的人
- [[刷新]] 刷新 是微软现任 CEO [[萨提亚 纳德拉]] 的传记,在我的书评中我也曾提到过,微软近几年的变化,转型非常的亮眼,可以说全部归功于这一任新的领导人。
- 活法,是 [[稻盛和夫]] 的一本人生哲学,乐观地设想,悲观地计划,坚定地执行。为了实现理想,只有主动追求的东西才能到手。
- [[若为自由故 自由软件之父理查德 斯托曼传]] 若为自由故 是自由软件之父 [[Richard Stallman]] 的个人传记,先了解了[[自由软件]],然后又了解到了 [[自由会社]],进而知道了斯托曼的故事。虽然可能斯托曼的观点再一些人看来有些极端,但是尤其是在所有的软件设施都上云的今天,用户去掌握一个软件,去掌握自己的数据这件事情是变得如何重要不言而喻。斯托曼关于自由软件的定义至今未知都依然至关重要,运行,复制,分发,修改的自由。
- [[富兰克林自传]] 我对富兰克林的最初印象就是那个下雨天放风筝找闪电的小孩,看过这一本书,他的形象才立体起来,我后来知道他是美国的建国元勋,但是没有做过总统,我也知道他是一个发明家,但是看过了这一本「自传」我才知道富兰克林的人生远比我想象的要「精彩」很多,他不仅是一个政治家,科学家,还是一个外交家,出版商人,作者,外交家,更甚至在心理学上也有建树。
金融
- [[金融的本质]] 金融的本质 是美联储前主席 [[本 伯南克]] 的著作,是一部关于美联储历史,应对金融危机手段的一本科普读物,非常容易读,也是一本快速了解美联储的书。
- [[原则]] 原则 是一本久仰其名的书,因为是 [[瑞 达利欧]] 的著作,在那个 30 分钟理解经济原理的视频里面,我已经对这个名字如雷贯耳,这本书实际上是达利欧自己桥水基金公司创建,以及公司内部采用的决策原则,如何有效决策,如何解决分歧,如何创意择优,
社科
- [[自由软件 自由社会]] 自由软件 自由社会 这是自由软件之父斯托曼的一本著作,探讨了什么是自由软件, 什么是自由社会。什么是 Free software,这里的 Free 不是免费,而是和 free speech 中的 free 一个含义,自由。而自由社会,就是一个由法律来规范的社会,没有秘密法律。法律可以被监管,司法实践中,所有的诉状,判决意见都是公开的,论证过程也是公开的,所有的法官意见可以在之后的实践被引用,融合。美国的司法系统就是建立在「源代码」公开的基础和原则之上的,它对任何想使用它的人都是开放和自由的。
- [[工作、消费主义和新穷人]] 工作、消费主义和新穷人 很偶然的一次机会在书店看到的,因为读过 [[齐格蒙 鲍曼]] 的 [[现代性与大屠杀]] 所以立马就拿起来读了。鲍曼认为是人创造了「工作理论」,用来解决工业会生产所需要的劳动力。工作理论的本质是对自由的摒弃,目的是为了把人们所做的事情,认为值得做得事情,有意义的事情分离开来,把工作本身和任何切实的,可理解的目的分开。
- 法国大革命前夕的舆论和谣言 「谣言」两个字,在疫情期间是我非常厌恶的两个字,这一本书让我知道了什么是「谣言」,字面上谣言就是非官方的消息。谣言的诞生就是人民开始有了公民意识,了解政治的要求是合法的,对政治的知情权和批判权是必要的,更甚至说谣言也是必要的。因为在涉及公共事务时,只有人们不断地提出诉求,那么说活就不仅仅再是一个能力,而是一个权利,即使有可能说出来错误的言论,也要得到保护。
- [[谣言:世界最古老的传媒]] ,因为对谣言这两个字感兴趣,所以又看了这一本书,这一本书更是精炼地让我知道,谣言是消除不了的,只有不受监控、约束和强迫的信息交流才是真实的交流,哪怕其可靠性会受到影响。
- [[开放社会及其敌人]] 开放社会及其敌人 这本书非常「难读」,这是我很多次读,然后又放弃的一本,但是通过其他人慢慢对[[波普尔]]思想的论述,慢慢地可以知晓一二,这是波普尔在政治哲学领域的集大成之作。波普尔提出了开放社会的理念,也讨论了历史主义,极权主义,以及对柏拉图的批评,对黑格尔的批评等等,这是一本非常庞大复杂的著作。
- 邻家的百万富翁 这是一本畅销书,所以非常好读,书中阐释的观点也非常有意思,这本书可以算是一个观察思考,作者通过观察,思考,百万富翁有什么特质,进而引发我们的思考。如何看待收入和财富的关系,如何累积财富,尊重金钱,什么是消费自由,如何守住财富,如何投资,读起来非常轻松,不妨在闲暇时刻随便挑一章感兴趣的读下去。
- 现代性与大屠杀 这本书可以说是影响我最大的书,在阅读这一本书的过程中,我将所有通过关键字 [[现代性]] 检索出来的视频,播客全部听了一遍,虽然现代性一词并不是本书作者 [[齐格蒙 鲍曼]] 提出的,但是这本书将为什么会发生犹太人大屠杀,部分原因归咎于现代性,是让我思想转折的一个重要影响。
- 大法官说了算-美国司法观察笔记 [[何帆]] 的著作,非常适合想要了解最高法院的人去阅读,是一本非常轻松易读的书。
- [[法官能为民主做什么]] 法官能为民主做什么 是最高法院 [[斯蒂芬-布雷耶大法官]] 的最高法院观察记录,全书主要分成几个部分,第一个部分就是最高法院通过几个案件建立起了民众对其的信任,第二部分是布雷耶大法官的实用主义宪法解释方法,第三部分是解释了价值判断和比例原则。
- [[纳瓦尔宝典]] 很早很早之前就知道了 [[Naval Ravikant]],尤其是他的 Twitter Storm [[How to Get Rich Without Getting lucky]],也看过一点英文原著,中文版本出版之后也拿起来读了一下。这也是一本对我影响非常大的著作,虽然这这本书只是对 Naval 只言片语观点的总和,但是却真实地改变了我的很多思考方法,和想法。金钱和财富的区别,资本杠杆。对技能的理解。
- 天朝的崩溃:鸦片战争再研究 这是一本研究鸦片战争的集大成之作,还原了战争前后的相关人物,历史事件。作者用非常翔实的材料,描绘了一个非常精彩的故事。而在疫情政策反复的 2022 年阅读了这一本书,更是觉得 200 多年了,我们还是没有吸取教训
计算机
- [[编码]] 编码 正如其名,就是讲述编码的历史,从编码的角度非常通俗易懂的方式来介绍计算机中的编码。
- [[现代政治的正当性基础]],因为作者 [[周濂]] 而看了这一本书,作者在这本书中论证什么是国家,国家的正当性基础,我们为什么要国家。 最初知道周老师是因为他的哲学播客,也是非常通俗易懂,单这本书其事写的有一些深奥。
心理学
- [[也许你该找个人聊聊]],这是一本挺有意思的书籍,作者 Gottlieb 是一位心理治疗师,而这一本书就是他的回忆录,几位来访者的故事。
.idea 文件夹的内容梳理
使用 JetBrains 旗下的 IDE 创建项目都会在项目的根目录中自带一个隐藏的 .idea 文件夹,每一次遇到这个文件夹的时候都会犹豫一下是否需要下面的内容全部放入到 .gitignore 文件中,大部分的时候就直接全部忽略了。现在想过来再了解一下这个文件夹下的每个文件都代表什么内容,因为有一些数据库配置,还有一些插件的临时信息都会存放在这个目录下。
.idea 文件夹存放的内容都是 JetBrains 旗下的 IDE,比如 IntelliJ 等等项目独有的配置文件。这些文件包括项目独有的 VCS mapping 或运行或调试的配置文件,还有一些用户操作相关的文件,比如用户当前打开的文件,浏览历史记录,当前的配置等。
文件夹:
codeStyles文件夹,包含项目所使用的代码风格dictionaries文件夹包含用户自定义的词典,IDE 用来检查单词拼写的时候会引用,文件下的内容以用户分隔,不应该提交版本控制,除非明确知道自己想做什么dataSources文件夹,数据库连接信息,不应该提交版本控制libraries文件夹,包含一系列的 XML 文件,不应该提交到版本控制,这些文件会从项目中自动生成
文件:
dataSources.xml包含 IDE 中使用 Database 的数据库连接信息encodings.xml项目编码vcs.xml文件用来记录 VCS 相关的内部信息,启用了哪一个 VCSindexLayout.xml该文件是用来记录项目外包括的文件夹的。这些文件夹可以通过Attach Existing Folder...来加入modules.xml基于 Gradle 或 Maven 的项目生成的信息,可以被排除,会在导入的时候自动生成vcs.xml文件用来记录 VCS 相关的内部信息,启用了哪一个 VCSrunConfigurations文件夹是用来存储 shared run configurations 的。indexLayout.xml该文件是用来记录项目外包括的文件夹的。这些文件夹可以通过Attach Existing Folder...来加入
有一些文件应该被提交到版本控制中,而有一些是需要被排除的。个人的习惯是直接排除掉 .idea 整个目录,貌似到目前为止还没有产生任何问题。
gitignore
如果不知道要在 gitignore 中填写什么什么,我一般会用如下的方式自动产生 .gitignore:
- 使用 IDE 自带的功能,在项目上右击,选择 New ->
.ignore File->.gitignore文件,然后会弹出选框,选择自己的系统,语言,IDE 就会自动产生 - https://www.gitignore.io/ 在网站中根据自己的需要,输入系统,编程语言,IDE 等等,然后会自动生成一段
.gitignore,复制粘贴即可
reference
Java 11 新特性学习
Java 11 在 2018 年 9 月 25 日发布。这是 Java 8 之后首个长期版本。
安装
因为我本地使用 asdf 来管理 Java 的多个版本,所以直接使用 asdf 来安装:
asdf install java adoptopenjdk-11.0.17+8
asdf global java adoptopenjdk-11.0.17+8
java -version
HTTP Client 升级
Http Client 几乎被重写,支持异步非阻塞。
包名从 jdk.incubator.http 改为 java.net.http,通过 CompleteableFutures 提供非阻塞请求。新的 HTTP Client 提供了对 HTTP/2 的支持,兼容 HTTP/1.1 ,与主流的开源库(Apache HttpClient,Jetty, OkHttp)性能相差无几。
Java 在 Reactive-Stream 的实践,广泛使用了 Java Flow API。
模拟 GET 请求:
HttpClient client = HttpClient.newHttpClient();
HttpRequest request = HttpRequest.newBuilder()
.uri(URI.create("http://openjdk.java.net/"))
.build();
client.sendAsync(request, BodyHandlers.ofString())
.thenApply(HttpResponse::body)
.thenAccept(System.out::println)
.join();
Epsilon 低开销垃圾回收器
Epsilon 目标是开发一个内存控制器,不执行任何垃圾回收,提供完全消极的 GC 实现,最大限度降低内存占用和内存吞吐延迟时间。
通过 JVM 参数 -XX:+UseEpsilonGC 来开启。
为什么要开发一个不回收内存的垃圾回收器
一些特殊的场景可以不开启垃圾回收以方便进行比如性能测试,内存压力测试等等。
简化单个源代码文件的启动方法
Java 11 可以直接运行一个单一的源码文件,Java 解释器可以直接在内存中编译,然后执行。所有的类都必须定义在同一个 Java 文件中。
这个功能特别适合想要简单了解一下 Java,写一些脚本文件的时候非常有用。
本地变量类型推断
Lambda 参数的局部变量语法
Java 10 开始就引入了 var 关键字,允许局部变量推断。
但在 Java 10 中有几个限制:
- 只能用于局部变量
- 声明时必须初始化
- 不能用于方法参数
- 不能在 Lambda 表达式中
Java 11 中允许开发者直接在 Lambda 表达式中使用 var 进行参数声明。
低开销的 Heap Profiling
Java 11 中提供了一种低开销的 Java 堆分配采样方法,能够得到堆分配的 Java 对象信息,并能够通过 JVMTI 访问堆信息。
- 低开销,可以默认开启
- 定义好的程序接口访问
- 堆所有堆分配区域进行采样
- 给出正在和未被使用的 Java 对象信息
ZGC 可伸缩低延迟垃圾收集器
ZGC 是 Z Garbage Collector ,GC 停顿时间短,不超过 10ms,能处理 T 级别堆大小。
实验阶段,只在 Linux/x64 上可用,在编译时加入参数才可以启用,并且使用时需要增加 JVM 参数。
飞行记录器
低开销的事件信息收集框架。
启用参数:
-XX:StartFlightRecording
reference
项目管理工具 Backlog 使用介绍
Backlog 是一个在日本非常流行的项目管理工具,用于追踪项目进度,查看甘特图,查看进度消费图。
Backlog 的英文原意指的是积压的工作,一系列的任务,或者待完成的事情。这个词通常被用在项目管理,软件开发中。
相关的术语
Backlog 上有一系列的术语
- スペース(Space),空间,为每一个 Backlog 组织提供的 URL 划分的共享空间。一个空间由多个项目组成。
- プロジェクト(Project)项目,包含每个组的任务、文件、团队成员等
- プロジェクトの例(工程实例)
- 課題,Backlog 中需要负责人处理的事项、任务,被称为「課題」,課題 可以设置开始时间、结束时间、负责人、内容、主题等等信息
每一个任务都有四种状态:
- 未対応,还没有开始
- 処理中,进行中
- 処理済み,工作完成,等待确认
- 完了,确认并完成
这个任务状态也可以通过后台的设置进行自定义。
技术栈
- [[Phaser]]
related
- [[Linear]]
- [[Trello]]
- [[ClickUp]]
- [[Asana]]
- [[Hive]]
- [[Jira]]
《天朝的崩溃:鸦片战争再研究》读书笔记
《天朝的崩溃:鸦片战争再研究》 是茅海建教授对于鸦片战争研究的集大成之作,是系统研究鸦片战争十余年所得的成果。在阅读之前,我本以为是一部非常学术的类似论文一样的著作,然而我只阅读了一章就改变了我的观点,作者以人物为核心,将历史事件以人物为核心串联,并收集各方面的文献材料,去还原历史的本来面貌,去摆正对一个历史人物的是非判断。并且作者的笔法流畅通顺,非常易读。
怎么知道的这一本书
这本书很早就在待看列表中,不断地有人在不同的场合曾经提到过,在豆瓣的时间线看到过,在 Twitter 上看到过有人推荐。鸦片战争几乎是中国人尽皆知的近代耻辱的开始,1840 年就像是一个烙印,相信很多人都记得。但唯独很多人不知道的是鸦片战争究竟是如何爆发的,又是如何一步步战败的。我们的教科书只是让我们对鸦片战争有了一个大概的印象,但每一个细节都缺失了。这也是让我对这一本副标题为「鸦片战争再研究」的书产生兴趣的一个原因。
关于作者
[[茅海建]],我还是第一次读这位教授的书,同样看介绍,这一本《天朝的崩溃》也是茅海建教授的成名之作。茅海建是华东师范大学历史系教授、北京大学历史学系兼职教授,师从陈旭麓教授。
几句话总结书的内容
这是一本还原鸦片战争前后相关人物、相关事件的历史著作,作者以翔实的文献材料,理性中立的评价,使得鸦片战争中的道光帝、林则徐、琦善、奕山等等人物形象跃然纸上。每次读到中途放下,就像是看电视剧中途休息,意犹未尽。
启发或想法
这本是一本讲述近 200 年前清王朝和英国的战争前因后果的历史著作,却不时的让我回想起过去三年的新冠疫情,主「剿」和主「抚」和如今的清零和开放;道光皇帝的优柔寡断,坚信祖宗留下来的制度尽善尽美只是朝廷存在诸多腐败的问题和如今左右摇摆的政策变化,动辄就以腐败问题查处高官,却从来似乎不曾真正解决问题;各地大臣欺瞒,克扣军饷和如今各地防疫政策,防疫数据以及通过疫情大赚核酸检测的钱。这一系列已经发生了近 200 年的事情再一次因为病毒而重新在这片大地上演,虽然因为科技发展,生活的变化,大多数事情的发生已经改变了其面貌,以前从广州到北京的一封奏折需要一个月,现在的通信技术发展只需要几毫秒,但欺瞒的手法却如此相同,知情不报,顾左右而言他。
另外一个让我非常敬佩的是作者在文献、参考资料上的引用数量,往往看完一个章节才意识到作者的脚注竟然会多达上百个。如此翔实,具体的,从这个方面收集的材料也使得这本历史著作在学术和可信度上更加可靠。
谁应该看这本书
所有想要更进一步了解鸦片战争的人。
印象深刻的句子
- 这里绝无意为伊里布的谎言辩护,而是指出,对促发这种谎言的体制和君主也也应当批判。
- 道德的批判最是无情。而批判一旦上升至道德的层面,事情的细节便失去了原有的意义,至于细节之中所包含的各种信息、教训更是成了毫无用处的废物。
- 战争的现实就是这么冷酷,丝毫也不照顾正义的一方。
- 战争的权威性,就在于强迫对方顺从。
- 知识给人以力量,愚昧也给人以力量,有时甚至是更大的力量。
文章分类
最近文章
- AI Shell 让 AI 在命令行下提供 Shell 命令 AI Shell 是一款在命令行下的 AI 自动补全工具,当你想要实现一个功能,敲一大段命令又记不住的时候,使用自然语言让 AI 给你生成一个可执行的命令,然后确认之后执行。
- 最棒的 Navidrome 音乐客户端 Sonixd(Feishin) Sonixd 是一款跨平台的音乐播放器,可以使用 [[Subsonic API]],兼容 Jellyfin,[[Navidrome]],Airsonic,Airsonic-Advanced,Gonic,Astiga 等等服务端。 Sonixd 是一款跨平台的音乐播放器,可以使用 [[Subsonic API]],兼容 Jellyfin,[[Navidrome]],Airsonic,Airsonic-Advanced,Gonic,Astiga 等等服务端。
- 中心化加密货币交易所 Gate 注册以及认证 Gate.io 是一个中心化的加密货币交易所。Gate 中文通常被称为「芝麻开门」,Gate 创立于 2013 年,前身是比特儿,是一家致力于安全、稳定的数字货币交易所,支持超过 1600 种数字货币的交易,提供超过 2700 个交易对。
- 不重启的情况下重新加载 rTorrent 配置文件 因为我在 Screen 下使用 rTorrent,最近经常调试修改 rtorrent.rc 配置文件,所以想要找一个方法可以在不重启 rTorrent 的情况重新加载配置文件,网上调查了一下之后发现原来挺简单的。
- Go 语言编写的网络穿透工具 chisel chisel 是一个在 HTTP 协议上的 TCP/UDP 隧道,使用 Go 语言编写,10.9 K 星星。