Google 聊天机器人 Bard 逆向
昨天晚上申请了 Google Bard 试用,今天下班了看到很多人都是几个小时就拿到了试用体验,我想我怎么没有收到邮件呢,我反复确认了邮箱确实没有,然后我想着再去网页上看看呢,登录了一下 https://bard.google.com/ ,开始的时候没有使用代理,提示所在的地区暂时还不能用,然后加上美国的代理,刷新一下就进去了。
Bard 依托 Google 的一款大型语言模型,可以生成文字、撰写各种类型的创意内容,还可以根据它掌握的信息解答你的问题。
进去的第一个弹窗就是「警告」,Bard 是一个实验性的产品,可能不会一直都是正确的,并且 Google Bard 的每一条回复都会有赞同,否定,重新回答,或者直接 Google 的按钮。
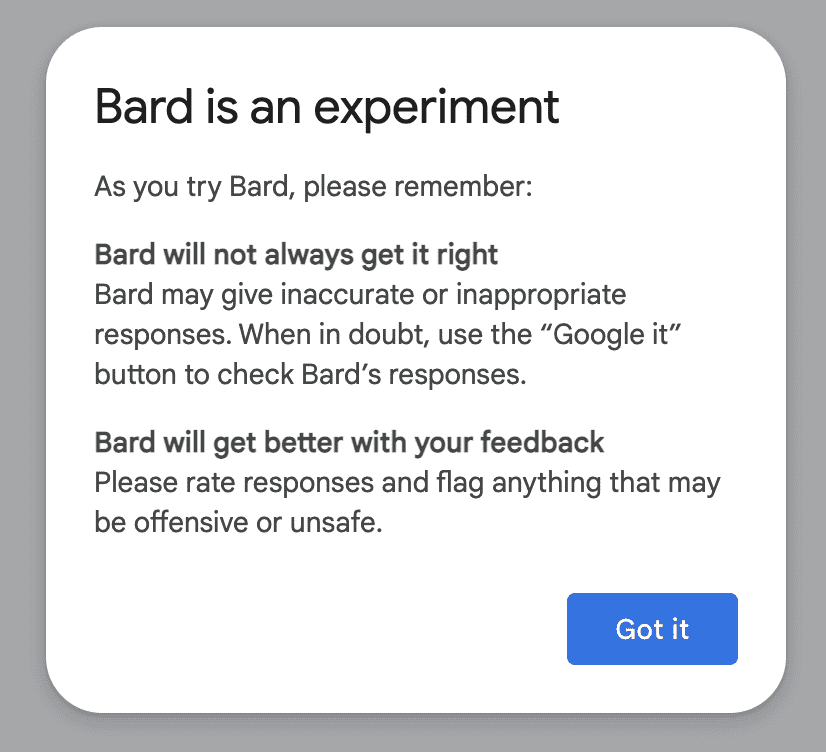
大型语言模型是会犯错的

说实话 Google 做这个产品确实非常小心了,在下方的输入框下也有明确的注意事项。

Python Lib
在调研的过程中发现已经有人逆向了 Google Bard。通过如下的方法,然后执行 Python 即可在命令行使用 Bard,不过记住需要使用美国的 IP。
Go to Google Bard
- F12 打开 console
- Copy the values
- 找到 Application → Cookies →
__Secure-1PSID复制这个 Cookie 值 - 然后在 Chrome Console 中输入
window.WIZ_global_data.SNlM0e,复制结果
给网站加上实时聊天对话框 tawk.to 使用记录
tawk.to 是一个可以在网页上添加客户聊天对话框的应用。用户可以通过 tawk.to 泡泡快速地得到支持。
tawk.to 是百分百免费的,创始人写了很长的一篇博客来介绍为什么我们是免费的
tawk.to 在文章中介绍其盈利的方式:
- 用户需要支付一个月 19$ 的费用来移除界面中的 tawk.to 的 Logo,如果用户选择不移除那么一直都是免费的。
- tawk.to 提供 1 小时 1 美元的代理客服服务,通过受过专业训练的客服来给用户提供 7 * 24 小时的客服支持
tawk.to 公司还推出了其他服务:
- Live Chat 最知名的服务,提供线上实时聊天
- Chat Pages,将链接转换成对话,适合没有网站的企业
- Knowledge Base,知识库,完全免费的帮助中心,客户可以通过知识库自己寻找答案
- Ticketing,票务系统,客户可以借助票务系统寻求帮助
- In-Chat Payments,在聊天小部件中直接进行支付
- CRM,管理所有联系人和事件
- Messaging,通过与 Facebook,Google RCS,Telegram,SMS 社交网络等即时聊天工具集成,响应所有消息通道的内容
- Phone,直接在仪表盘拨打语音电话
- Hire Chat Agents,雇佣聊天代理
- Virtual Assistants,虚拟助理
市场占用率
tawk.to 根据其官网的介绍已经占据市场 20% 左右,是目前企业实时聊天这个市场的第一名,接下来依次是 Zendesk(12.25%),Facebook(9.63%),Live Chat(6.36%),Tidio(5.44%),Intercom(4.34%),Zoho(3.6%),Pure Chat(3.49%),Drift(3.25%),Olark(3.11%)。
接入网站
就和其官网介绍的一样,接入 tawk.to 非常简单,我在我的Life in Japan 接入 tawk.to 的服务花费不到 5 分钟。稍微设置一下展示,和其位置,然后熟悉一下后台控制面板就能快速上手。
如果想看一下具体效果可以访问这里,在右侧看到的绿色聊天对话框就是 tawk.to,在其中留言,我就可以实时收到信息。
类似的工具
- [[crisp.chat]] Crisp 成立于 2015 年,目标是提供一个更低成本接入的 tawk.to 服务,在 tawk.to 的基础上提供了对话翻译,Chatbots 等新特性。1
下载 YouTube 视频方法总结
之前就简单地介绍过使用yt-dlp 来下载 YouTube 视频,yt-dlp 是自从 youtube-dl 不再更新之后有人接手开发的新工具。但这篇文章重点是在于下载 YouTube 视频,我会整理一下我目前了解的所有可视化,命令行,Telegram bot 等等工具。
界面
- [[Downie]] 是一个非常好用的付费下载视频的工具,不仅支持 YouTube, 还可以下载很多视频网站。
命令行工具
- yt-dlp 是一个 Python 编写的命令行工具,只要本地有 Python 环境就可以非常快速的安装。
Telegram Bot
- ytdlbot 是 BunnyThink 使用 Python 调用 yt-dlp 编写的一个 YouTube 下载机器人,可以自己 Self-hosted,然后改一下代码就可以下载大视频。
Tailscale 出口节点功能配置流量出口
之前的文章中介绍过 Tailscale ,是一个功能非常强大的虚拟组网的工具,底层使用更高级的 [[WireGuard]] 协议进行通信。之前的文章中只简单的介绍了一下 Tailscale 的使用,但是过去的时间里面 Tailscale 又更新了很多的新特性,这篇文章就介绍其中的一个特性 Exit Nodes。
Exit Nodes(出口节点)功能就是允许 Tailscale 组件的局域网中的节点通过一台 Exit Node(出口节点)来进行网络通信。路由流量的设备称为“出口节点”。
默认情况下,Tailscale 通常只会借助互联网进行节点和节点之间的通信,而用户正常的流量,比如访问 Google,Twitter 等的流量都是通过本机进行的,而存在部分情况,比如在一些对安全通信要求比较高的场景,需要加密访问,这个时候就可以让局域网中的节点经过一个可信的出口节点(Exit Node)来于外部互联网进行通信。
- 比如在咖啡厅,有一些敏感数据想要传输到公司,但是不想通过公共 WiFi 进行通信,那么就可以将电脑于公司网络中的一个节点组成 Tailscale 局域网,然后将公司的节点设置成 Exit Node,然后自己的电脑的通信通过公司节点作为出口。
- 再比如如果在国外不可信的网络中,想要自己的网络还是回到某个国家,就可以使用不同的国家的节点,然后设置出口节点来安全的访问;再比如在国内的节点,想要通过日本的节点来访问外部互联网,那就可以将日本的节点作为出口节点
如何配置出口节点
如果要配置出口节点,需要经过下面几步:
- 一个设备(节点)需要申明自己可以作为出口节点
- 网络管理员必须允许这个节点作为出口节点
- 然后网络中的其他设备才可以将此节点作为出口节点
出口节点使用的先决条件
如果要使用出口节点需要有一些必备的前提条件:
- Tailscale 网络中必须至少有两个节点
- 确保出口节点和使用出口节点的设备都在运行 Tailscale v1.20 或更高版本
- 确保出口节点是 Linux,macOS 或者是 Windows 设备
- 如果您的 tailnet 使用默认 ACL,则您的 tailnet 用户已经可以访问您配置的任何出口节点。如果您修改了 ACL,请确保您已创建一个 ACL 规则,该规则向您希望使用退出节点的用户授予对 autogroup:internet 的访问权限。他们不需要访问出口节点本身来使用出口节点。下面是添加到您的 ACL 的示例行,它允许所有用户通过出口节点访问互联网:
// All users can use exit nodes
// If you are using the default ACL, this rule is not needed because the
// default ACL allows all users access to the internet through an exit node
{ "action": "accept", "src": ["autogroup:members"], "dst": ["autogroup:internet:*"] },
将节点设置为出口节点
Linux 下
如果有 /etc/sysctl.d 目录:
echo 'net.ipv4.ip_forward = 1' | sudo tee -a /etc/sysctl.d/99-tailscale.conf
echo 'net.ipv6.conf.all.forwarding = 1' | sudo tee -a /etc/sysctl.d/99-tailscale.conf
sudo sysctl -p /etc/sysctl.d/99-tailscale.conf
如果没有:
echo 'net.ipv4.ip_forward = 1' | sudo tee -a /etc/sysctl.conf
echo 'net.ipv6.conf.all.forwarding = 1' | sudo tee -a /etc/sysctl.conf
sudo sysctl -p /etc/sysctl.conf
启用 IP 转发时,确保您的防火墙设置为默认拒绝流量转发。这是常见防火墙(如 ufw 和 firewalld )的默认设置,可确保您的设备不会路由您不想要的流量。
然后执行如下的命令将节点设置成出口节点:
sudo tailscale up --advertise-exit-node
在管理面板设置节点为 Exit Node
访问 Tailscale 控制面板,点击 Exit Node 节点后的设置,点击 Disable key expiry,禁用密钥过期。然后点击 Edit route settings,勾选 Use as exit node,之后启用。
使用出口节点
经过了上面两步网络中的其他节点就可以使用上面的出口节点,但是每个设备都需要单独启用出口节点。
其他节点需要运行:
sudo tailscale up --exit-node=<exit-node-ip>
可以从管理控制台或运行 tailscale status 找到设备的 IP 地址。
或者,将 --exit-node-allow-lan-access 设置为 true 以允许在通过出口节点路由流量时直接访问本地网络。
sudo tailscale up --exit-node=<exit-node-ip> --exit-node-allow-lan-access=true
然后就可以通过 在线 IP 检测工具 来查看本地流量是否已经由出口节点路由。
如果在命令行下可以使用 curl ip.gs 来查看 IP 信息。
reference
- https://tailscale.com/kb/1103/exit-nodes/?tab=linux
- 对于 macOS 的设置可以参考这里,Windows 的设置参考这里
- 如果想要同类型的产品,可以注册 OmniEdge
Porkbun 免费领取一年 app wiki 等域名
[[Porkbun]] 通常被人戏称为「猪肉包」,是一家新成立于美国俄勒冈州波特兰市的域名注册商,母公司是 Top Level Design,后者是 design, ink 和 wiki 三个顶级域名后缀的管理局。这家域名注册商虽然成立时间比较短,但是胜在价格实惠。短短几年时间就打开了知名度。
现在就讲一下 Porkbun 赠送的第一年免费的 app, wiki, ink, gay, uk, pt, website, site, it, mx 等等后缀的域名,可以第一年免费领取使用。
wiki 域名免费领取
- 首先访问 https://porkbun.com/tld/wiki,查询需要的域名
- 然后在结帐的时候输入促销码(Apply Coupon):GOOGWIKI
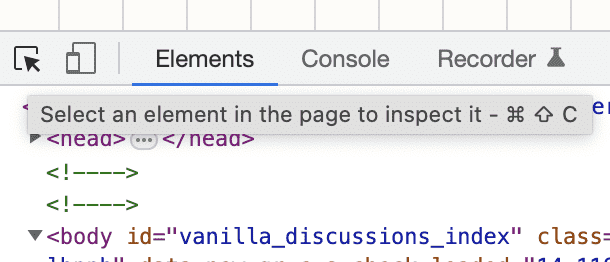
在结帐的时候需要注意,官方的验证方式是只能使用信用卡验证的,但是网页中预留了 Alipay 的验证方式,在 Chrome 浏览器中,右击选择 Inspect,或者使用快捷键调出,然后使用这里的箭头,选择图中的红色「New Card」
在页面代码中就能看到 Alipay 相关的字样,将右侧的 diaplay: none 取消掉,就能看到页面中的 Alipay 支付验证。
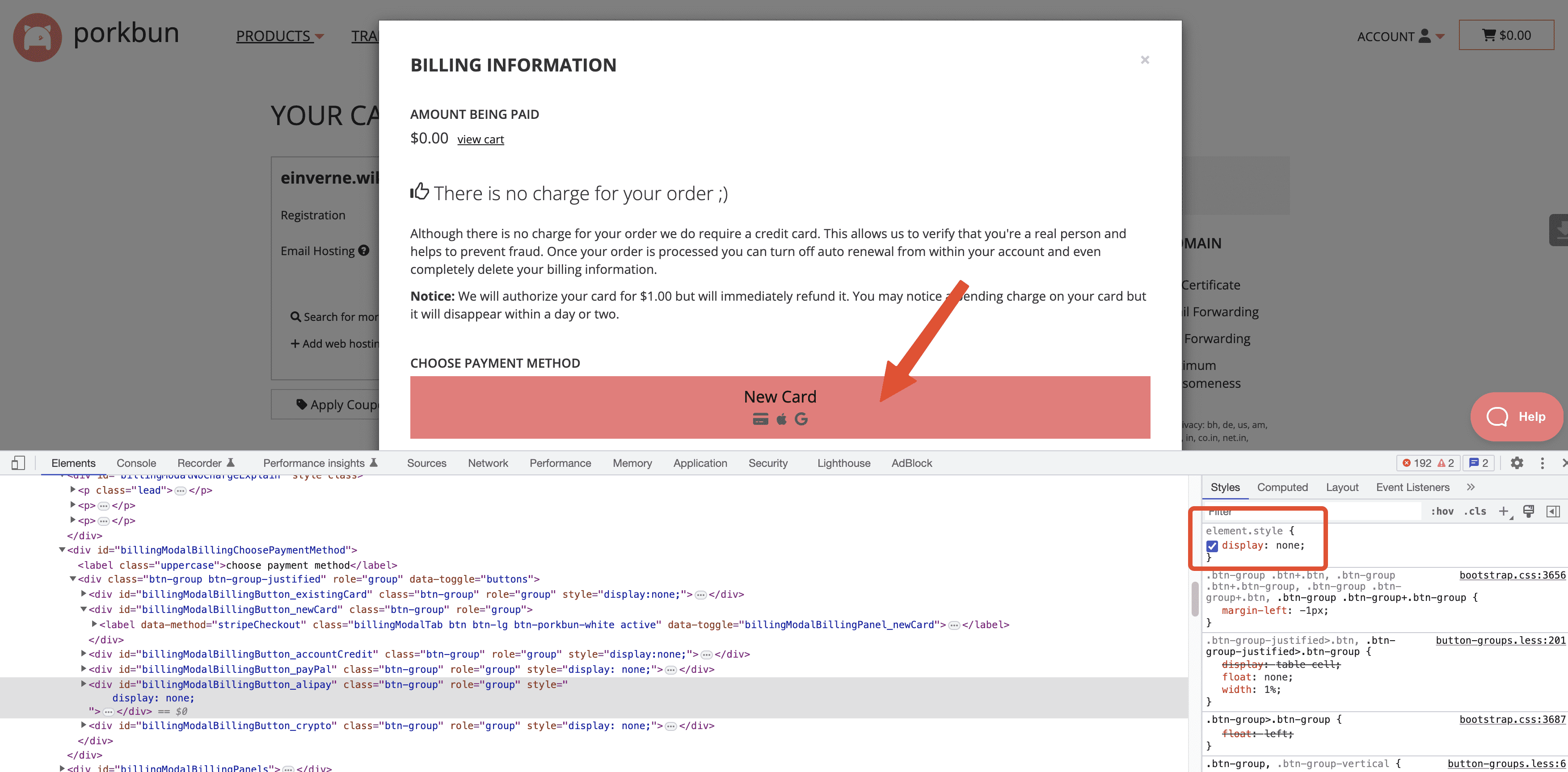
然后通过 Alipay 支付即可。
app 和 dev 域名领取
- 访问 https://porkbun.com/event/freeappdevdomain?coupon=TLDR23
- 然后输入想要的 app 或者 dev 域名,然后使用和上面一致的方法领取即可。
ink 域名领取
- 同样访问 < https://porkbun.com/tld/ink?coupon=GOOGINK>
- 使用优惠码:GOOGINK
.gay 域名领取
- 访问 https://porkbun.com 查询 gay 域名
- 使用优惠码:GAYPRIDE22
最后
附赠一些小彩蛋
免费的 .uk, .co.uk, .org.uk 域名,但是可能需要验证地理位置。
免费的 .pt, .website, .site 域名
注册也是可能被拒绝的。
免费的 .it 域名,可能需要验证地址
免费的 .mx 域名 (限时)
如果有兴趣讨论关于本文章,或者本博客的所有内容可以到 Telegram 群组。
《负动产时代》读书笔记
怎么知道的这一本书
很久以前想要了解世界各地房地产的时候,收集了不少的相关书籍,[[全球房地产]] 一书就写得太过学术,读起来有些枯燥,而这一本《负动产时代》应该就是那个时候加入的豆瓣待看列表。
关于作者
本书并没有一个单一作者,而是日本的《朝日新闻》采访组的一线记者走访了大量的房主,政府机构,不动产中介,并远赴德国、法国和美国,采访取材之后编写的一本描绘了日本房地产从狂热盲信时代到少子老龄化时代的巨大落差,房地产政策的滞后,以及带来了一系列严重的后果。
几句话总结书的内容
这本书读起来没有那么枯燥,作者引用了非常多的真实事例来展示当前房地产存在的问题,由这些问题再进一步得追问为什么会发生这些问题?为了解决这个问题又实地采访了亲历者,包括购房者,地产中介,相关政府部门。
存在的问题:
- 土地丈量的手册还是很多年以前的,错误百出
- 税务部门的政策没有跟上时代
作者还走访了法国,美国,德国等地方,试图寻找解决方案其他国家类似情况的政策。
法国政府的政策:
- 调查不明土地的真实情况
- 放宽民法规定,推动登记
- 税收方面采取优惠措施
美国的情况:
- 土地银行,根据当地政府制定的目标,低价出售房地产,担负着中介功能
德国允许放弃土地所有权:
- 德国法律明确规定土地是可以扔掉的
在阅读本书的过程中,我不止一次的被震惊到,读起书中的事例,就像是在看一个魔幻的故事集。管理费和固定资产税已经超过房产价值,最后被 1 万日元拍卖的度假公寓;120 年没有变更户主的老房子,已经有几十个继承人;在当年房地产市场欣欣向荣的时候,把一块什么都没有的「原野」土地,高价卖出去,如今已经是原先的十分之一价格;多年失修的公寓,因为没有办法得到全部户主的同意而无法重修。
更甚至在作者调查房地产中介公司的时候,让我窥见了公司如何压榨劳工,因为政府会查公司车辆的使用记录,会查看公司电脑的使用情况,员工为了达成业绩,甚至隐瞒自己的工作证据,周末用自己的车办公,工作时关掉电脑的电源,故意少报工时。
启发或想法
在人口减少的国家,购买度假性房地产或者在地方性城市投资性房地产都要谨慎再谨慎。特别是以高价贷款购买上述类型房地产,更是要谨慎。如果是想要在持有房地产要交固定资产税和房屋管理费的国家,如日本,购买上述房地产,那真的是“投资有风险,入市需谨慎”。
谁应该看这本书
对日本,以及房地产这两个关键字感兴趣的人。
印象深刻的句子
在商品房的样板间里,销售人员常会说:“用您现在的房租做月供,就能买到一套同样格局的房子。”如果您听了很动心,就相当于迈出了通往“负动产地狱”——维护和管理费用不堪重负,想卖却又卖不出去 —— 的第一步。
日本的土地制度是以土地和房产永远不会失去资产价值的“土地神话”为前提制定的。
Visual Studio Code Server 搭建:构建一个属于自己的基于网页的开发环境
Code Server 是一个在 Web 浏览器中运行的开源代码编辑器。它是 Visual Studio Code 的开源版本,可以提供基本的代码编辑、语法高亮、智能感知、自动补全等功能,同时支持多人协作、远程开发等特性。
能够在浏览器运行的集成开发环境通常也被称为 Cloud IDE。
Code Server 可以在本地计算机或云服务器上运行,用户可以通过浏览器访问并使用其中的编辑器功能,不需要在本地安装 Visual Studio Code 等本地编辑器。这样可以方便地进行远程开发、多人协作、快速搭建开发环境等操作。同时,Code Server 也支持自定义插件和扩展,可以满足不同用户的需求。
Prerequisites
- 一台运行 Ubuntu 22.04 的服务器,至少有 2 core CPU, 2 GB 内存,拥有 root 权限或者能执行 sudo
- 一个域名
- 我个人是通过 [[HestiaCP]] 面板自带的 Nginx 配置域名转发的,直接使用 Nginx 也是可以的
安装
推荐通过 Docker 来安装,我使用的是 LinuxServer 提供的镜像 ,转成 docker-compose.yml 来使用。
具体见 docker-compose
使用
配置访问密码
创建 password hashed
echo -n "thisismypassword" | npx argon2-cli -e
$argon2i$v=19$m=4096,t=3,p=1$wst5qhbgk2lu1ih4dmuxvg$ls1alrvdiwtvzhwnzcm1dugg+5dto3dt1d5v9xtlws4
配置 HTTPS
官方文档 中已经有了如何使用 [[Nginx]] 和 Let’s Encrypt 的相关配置
server {
listen 80;
listen [::]:80;
server_name mydomain.com;
location / {
proxy_pass http://localhost:8080/;
proxy_set_header Host $host;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection upgrade;
proxy_set_header Accept-Encoding gzip;
}
}
但是因为我使用的是 [[HestiaCP]],这个面板自带了一个 Nginx 模板,可以参考我之前的文章 创建新的 code-server.tpl 和 code-server.stpl 然后修改相应的配置。
但是我在配置的过程中,访问 Code Server 遇到了如下的问题。
An unexpected error occurred that requires a reload of this page.
The workbench failed to connect to the server (Error: WebSocket close with status code 1006)
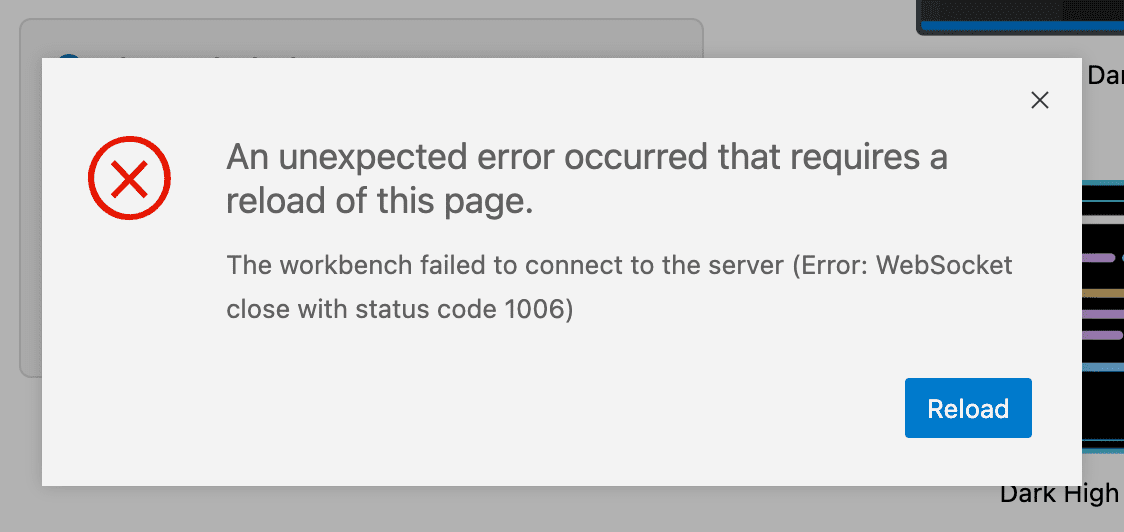
仔细的看了一下 Nginx 配置,才发现在 HestiaCP 默认的模板中后面有一个多余的配置
proxy_hide_header Upgrade;
把这个配置注释掉,然后在 HestiaCP 中重新关闭和启用该网站即可生效。
code server 配置同步
code server 下暂时还没有像 Visual Studio Code 一样内置的同步功能,但是 Shan Khan 的 Stttings Sync 可以作为一个不错的代替。
reference
如何在 Chrome 中使用 New Bing
拿到 New Bing 的体验,但是 Microsoft 却要让我下载 Edge 才能体验,这个体验真的很差,所以回去用 Google 搜了一下「如何在 Chrome 中使用 New Bing」,还在还是有方法的。
2023 年 5 月 9 号更新
5 月以后推荐 New Bing Anywhere 这款开源的 Chrome 插件。
HeaderEditor
安装 HeaderEditor 插件- 按下图的方式添加两条规则
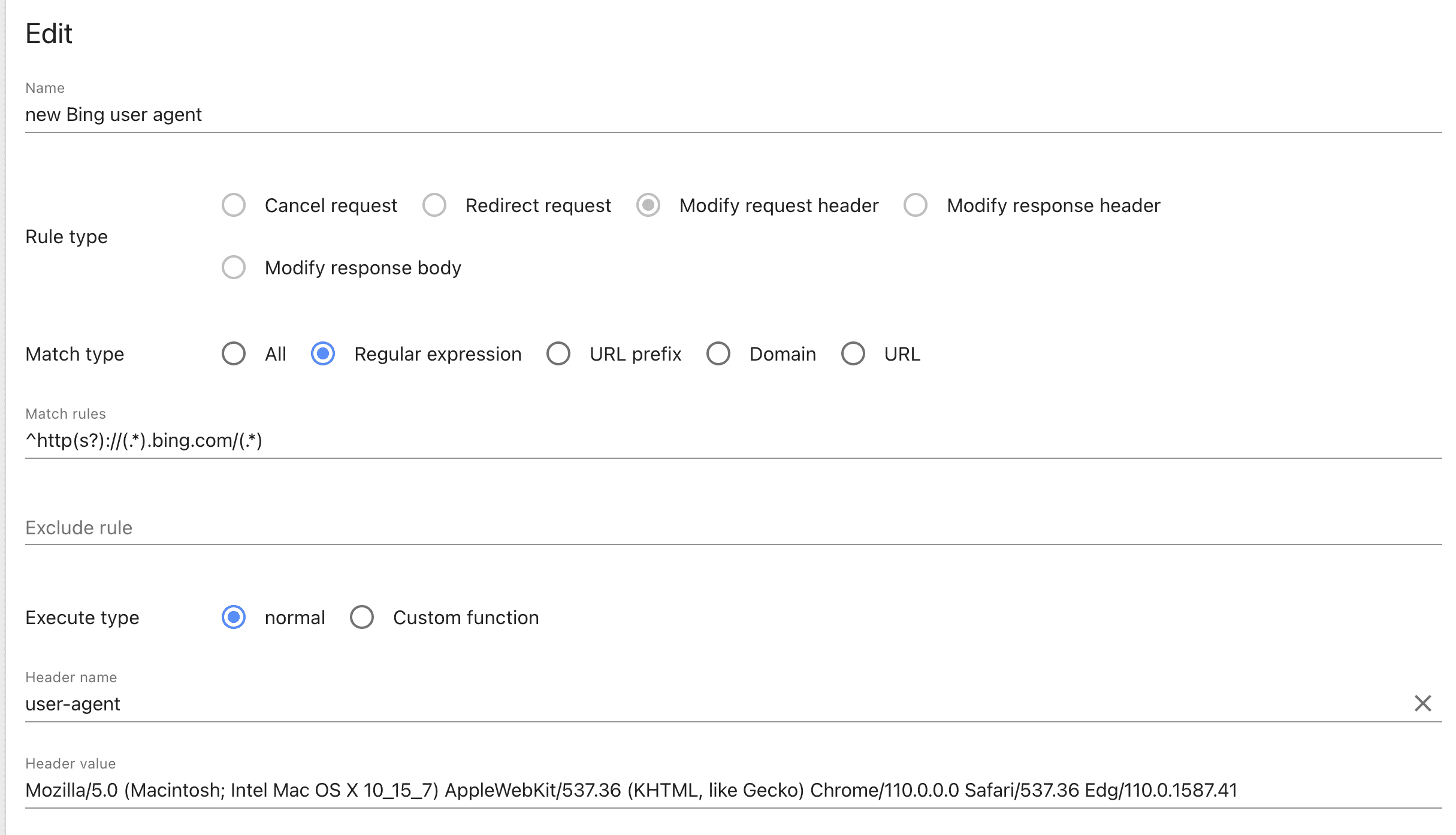
user-agent 规则,将user-agent 修改成 Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36 Edg/110.0.1587.41

将 x-forwarded-for 修改成 8.8.8.8。
然后访问 https://bing.com/new 就会从这个有着 「Download Microsoft Edge」 的页面
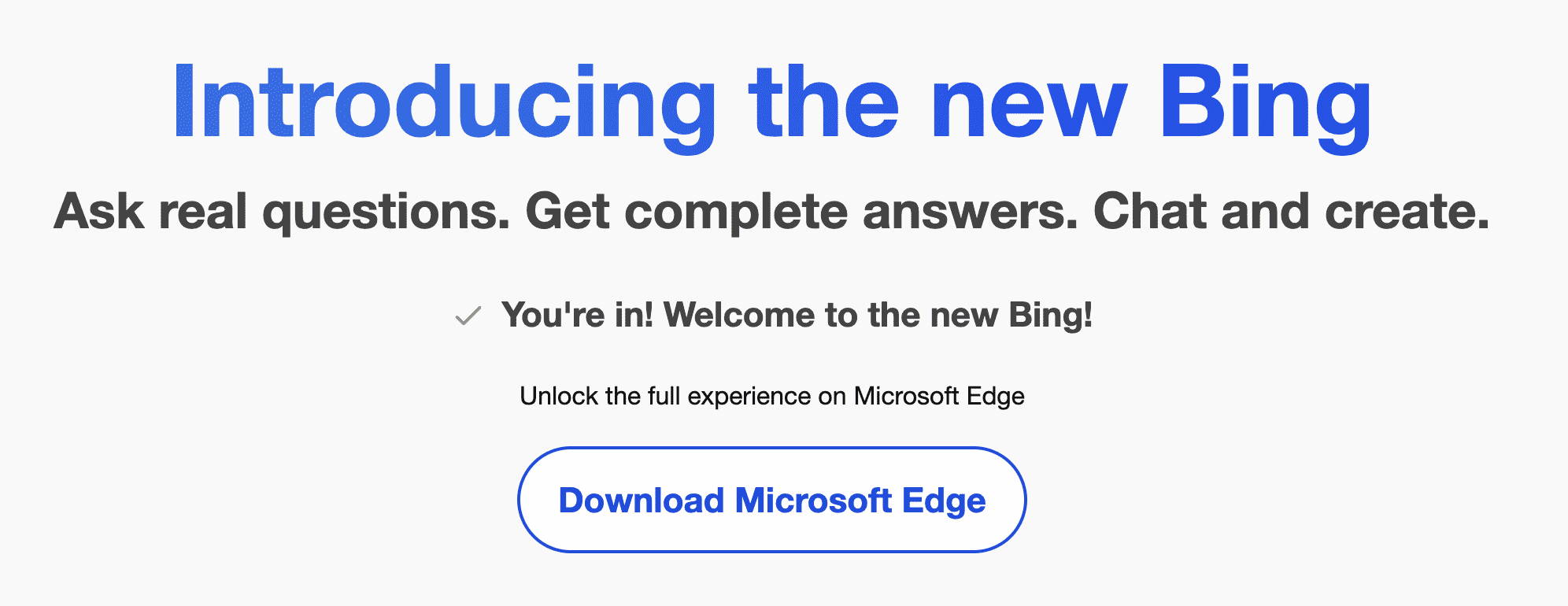
变成直接可以 Chat 的页面。
之后,在 New Bing 网页中的第一个问题就是问她「如何在 Chrome 中使用 New Bing」
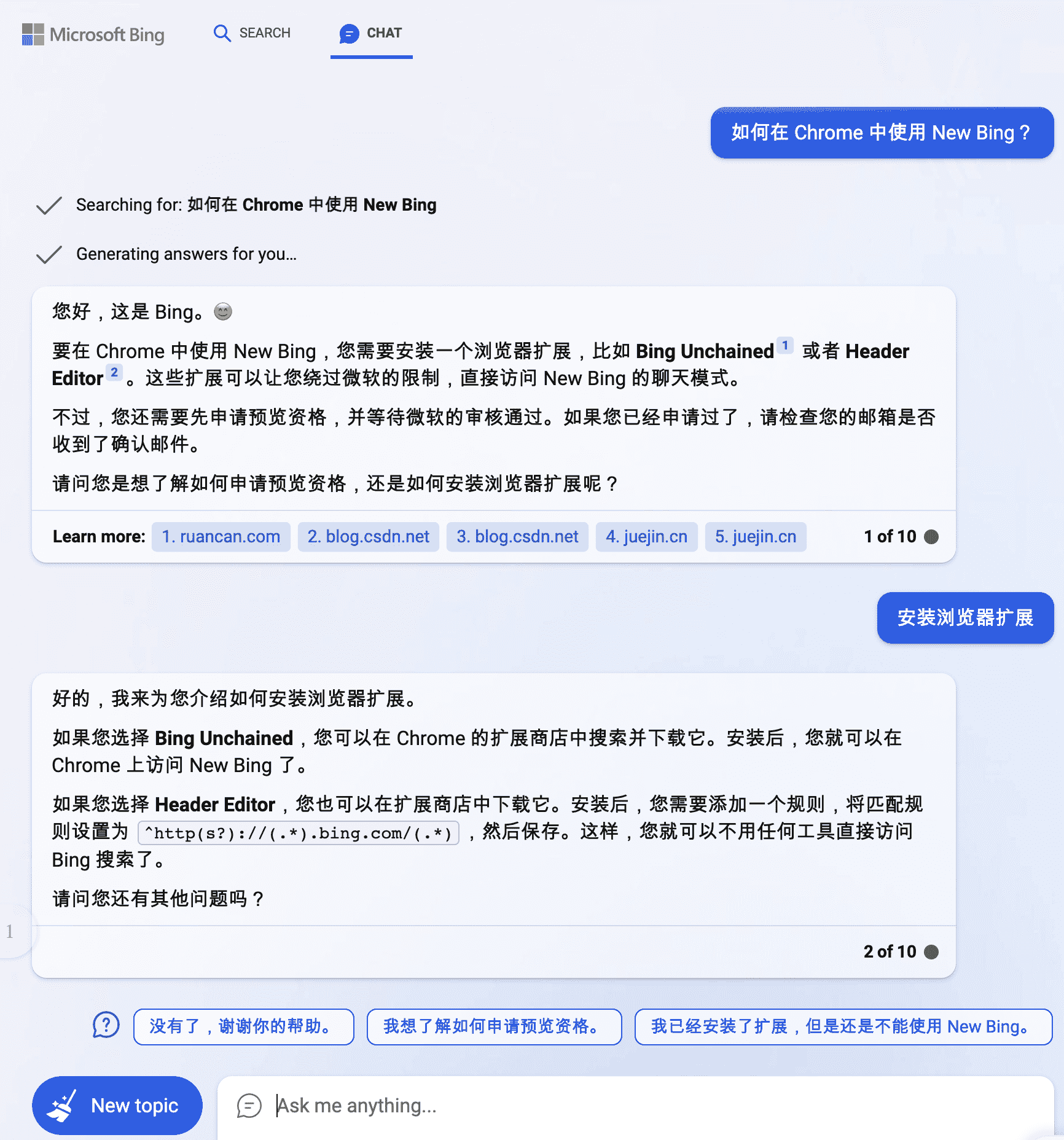
好在回答的还算比较准确。
Bing Unchained
感谢 Zealer Chan 在评论中补充了一种方法,可以直接安装 Bing Unchained 即可。
Vivaldi
另外一种使用方法就是在 [[Vivaldi]] 浏览器中访问 Bing,然后可以直接使用。
IRC 使用
[[IRC]],全称是 Internet Relay Chat,中文名是互联网中继聊天,是一种在全世界范围内被广泛应用的网络聊天协议,用户可使用 IRC 聊天软件连接到 IRC 服务器,与其他连接到这一服务器上的用户交流。由于所有的信息交流沟通都未曾经过第三方服务器,且采用了 SSL 加密,因此具有很高的安全性。
- IRC 可以提供安全、私密的聊天环境
- 一些 PT 站点会通过 IRC 单独的频道提供自动下载功能
名词介绍
IRC 的使用过程中会常常遇到这么一些概念,提前先了解一下。
Nickname(nick) 昵称,是用户的昵称,表示身份的昵称。
Channel,频道 #channel 通常会以 # 开头,是聊天室、频道的意思。
IRC 客户端
常见的 IRC 客户端有很多,比如 Hexchat, irssi, MIRC 等等。
桌面客户端 desktop client
- [[Hexchat]] Windows, Linux (free) 官网
- [[LimeChat]] macOS(free) 官网
- Konversation - Windows, Linux (free)
- mIRC - Windows 收费
- Textual 7 macOS 收费
mobile client
移动端客户端:
- AndroIRC Android (free)
- IRCCloud - iOS
- LimeChat - iOS (paid)
- Palaver - iOS (paid)
- RevolutionIRC - Android, also on F-Droid (free)
- The Lounge 是一个基于网页的 self-hosted IRC 客户端,跨平台
终端客户端 Terminal client
终端或者基于文本的客户端通常是主要使用键盘快捷键来使用的用户,通常不需要使用鼠标来移动,非常适合于服务器或者远程使用:
IRC 服务器使用
通常 IRC 服务器会提供一个连接地址和一个端口,需要注意的是有些服务器必须使用 SSL 端口才能连入。
连接之后会有很多 IRC 频道。
使用
加入频道
join #channel
查看某昵称的资料(用户的 IP 或加入的频道)
/whois nickname
查看某 IP 登录的所有用户:
/who IP-Address
离开频道,并留下原因
/part #channel reason
退出服务器
/quit reason
私信某人
/msg nickname the-words-to-say
列出所有频道列表
/list
电子销售平台:Lemon Squeezy 简单介绍
Lemon Squeezy 是一个面向开发者的在线收款平台,开发者可以集成 [[Lemon Squeezy]] 来在线销售数字产品,快速实现订阅软件许可等等。
Lemon Squeezy 支持 Visa/Master 信用卡,还支持支付宝,微信等。
Lemon Squeezy 还提供了 WordPress 插件,用户可以安装之后在 WordPress 上销售其产品。Lemon Squeezy 本质上还是对 [[Stripe]] API 的封装,在 Stripe 的基础上提供给了用户一套立即可用的销售平台。
什么时候需要 Lemon Squeezy?
- Lemon Squeezy 可以让用户在几分钟时间内创建一个在线电子商务网站,如果你不想自己接触复杂的支付接入流程,只想专注于在线购物体验,那么 Lemon Squeezy 是一个不错的入门选择
- 销售独立开发的应用,给产品添加订阅功能
- 在线销售课程,管理付费会员
- Lemon Squeezy 还提供了电子邮件营销工具,可以直接通过电子邮件与客户进行沟通,并提供了智能数据分析,使得营销自动化。
- Lemon Squeezy 还会记录销售,保留财务记录并自动计算销售税以及欧盟增值税,在页面中就可以生成发票
- 通过 [[Wise]] 和 [[Paypal]] 支持 270 多个国家和地区的支付
- Lemon Squeezy 支持个人或者商家两种申请主体。
Lemon Squeezy 的缺点
- Lemon Squeezy 是一家初创企业,其安全性和可靠性需要进一步的考量
- Lemon Squeezy 的收费模式对于小额的支付非常不友好,相较于 Stripe 收费更高
收费及支付费用 Price
Lemon Squeezy 不收取平台使用费用,但是会从用户支付的每一笔费用中抽取 5% + 50¢。所以相对来说小额支付使用 Lemon Squeezy 是非常不划算的。如果您在 Lemon Squeezy 上销售了一件商品,售价为 100 美元,那么您将会收到 94.50 美元的实际收益(即 100 – 5% – 50¢)。
相较于 [[Stripe]] 的收费,Lemon Squeezy 也相对比较贵,每笔支付抽成的比例甚至是 Stripe 的两倍。但好在 Lemon Squeezy 比 Stripe 要好申请一些,并且为个人开发者 SaaS 提供了一站式的服务。
另外对于国际支付(美国以外),在进行跨币种交易时 Lemon Squeezy 也可能会收取额外的 1.5% 左右的费用。
文章分类
最近文章
- AI Shell 让 AI 在命令行下提供 Shell 命令 AI Shell 是一款在命令行下的 AI 自动补全工具,当你想要实现一个功能,敲一大段命令又记不住的时候,使用自然语言让 AI 给你生成一个可执行的命令,然后确认之后执行。
- 最棒的 Navidrome 音乐客户端 Sonixd(Feishin) Sonixd 是一款跨平台的音乐播放器,可以使用 [[Subsonic API]],兼容 Jellyfin,[[Navidrome]],Airsonic,Airsonic-Advanced,Gonic,Astiga 等等服务端。 Sonixd 是一款跨平台的音乐播放器,可以使用 [[Subsonic API]],兼容 Jellyfin,[[Navidrome]],Airsonic,Airsonic-Advanced,Gonic,Astiga 等等服务端。
- 中心化加密货币交易所 Gate 注册以及认证 Gate.io 是一个中心化的加密货币交易所。Gate 中文通常被称为「芝麻开门」,Gate 创立于 2013 年,前身是比特儿,是一家致力于安全、稳定的数字货币交易所,支持超过 1600 种数字货币的交易,提供超过 2700 个交易对。
- 不重启的情况下重新加载 rTorrent 配置文件 因为我在 Screen 下使用 rTorrent,最近经常调试修改 rtorrent.rc 配置文件,所以想要找一个方法可以在不重启 rTorrent 的情况重新加载配置文件,网上调查了一下之后发现原来挺简单的。
- Go 语言编写的网络穿透工具 chisel chisel 是一个在 HTTP 协议上的 TCP/UDP 隧道,使用 Go 语言编写,10.9 K 星星。