Chatwoot Nignx 代理丢失 Header 信息
之前的一篇文章介绍过如何使用 Docker 自建 [[Chatwoot]],但是最近调用 API 的时候总是发现问题。在调用最普通的接口的时候,按照要求在 Header 中传了 api_access_token,但是接口返回 401 或者是
{"errors":["You need to sign in or sign up before continuing."]}
简单的查询了一下之后,发现问题出现在 Nginx 上,Nginx 默认情况下不允许带下划线的 Header,所以当请求到 Nginx,然后转发到后台 Chatwoot 的时候这个 api_access_token 就丢了。所以一直出现 401 和需要登录的状况。
解决办法非常容易,在 Nginx 的配置 server 块中增加如下的配置
underscores_in_headers on;
然后 Nginx 配置 reload 即可,因为我使用 [[HestiaCP]] 控制面板,所以后台修改一下配置模板即可。
reference
Proxmox VE 安装 Ubuntu Server 22.04
之前的时候,有一台小主机,在上面安装了 [[Proxmox VE]],然后在其中安装了 [[iKuai]] 和 [[OpenWrt]] 作为软路由使用。现在已经不需要再将其作为软路由代理使用,所以今天就拿出来整理一下,正好放在家里面作为一个 Linux 小服务器,跑一些小一点的程序,然后顺便挂载一个硬盘作为一个小型的媒体服务器。
因为之前在 Proxmox VE 上安装过很多次的系统,这里就不展开,把一些重要的配置和截图放在下面。
准备 ISO
在创建虚拟机之前,需要到 Ubuntu Server 官网 下载最新的 ISO 镜像,然后把镜像上传到 ISO Images 中:
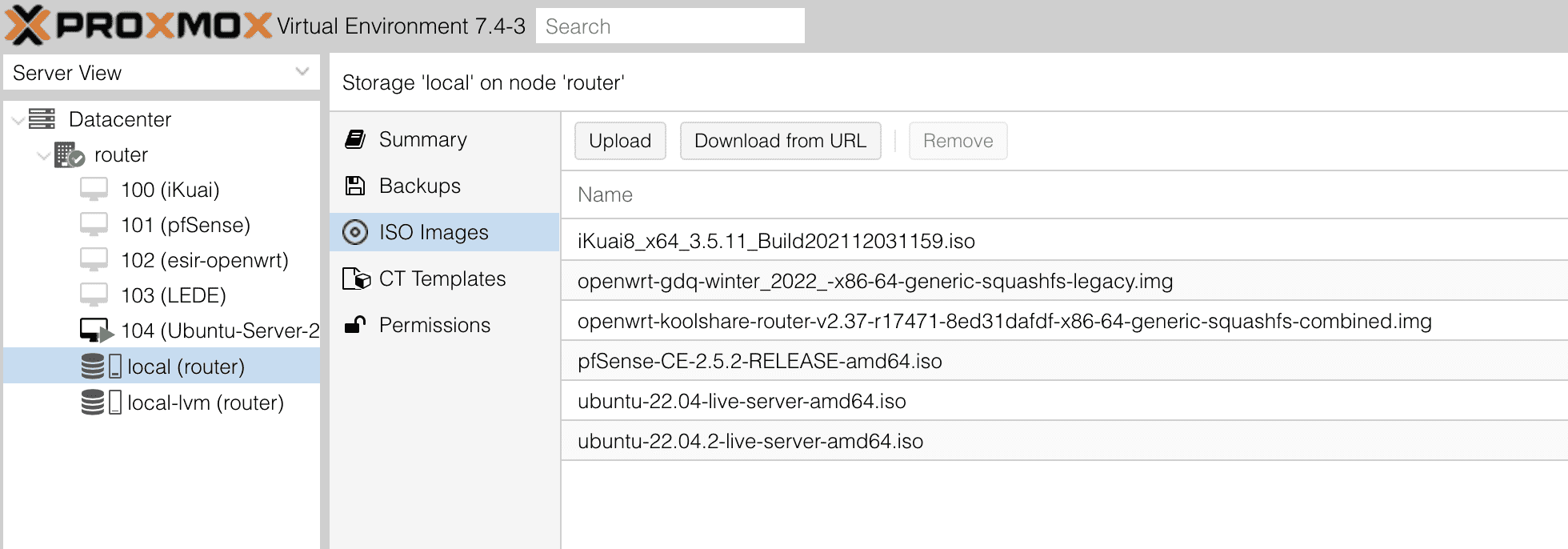
之后就可以开始创建 Ubuntu Server。具体的步骤如下。
创建虚拟机
首先第一步设置节点的名字(Name)
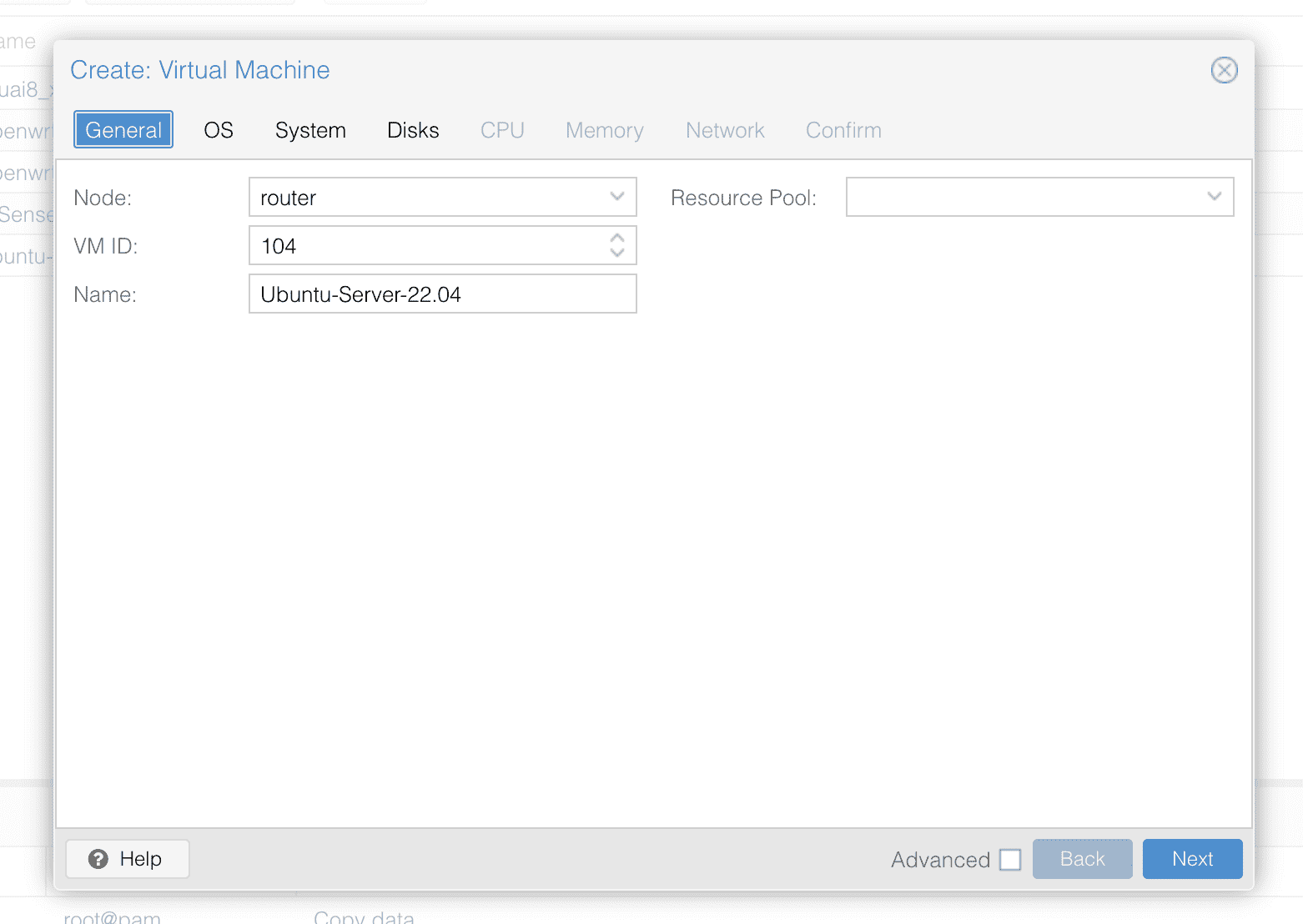
然后第二步选择需要挂载的镜像。
第三步配置 BIOS,保持默认即可。
第四步,选择磁盘,这里个地方可以根据自己的需要调整虚拟磁盘大小。
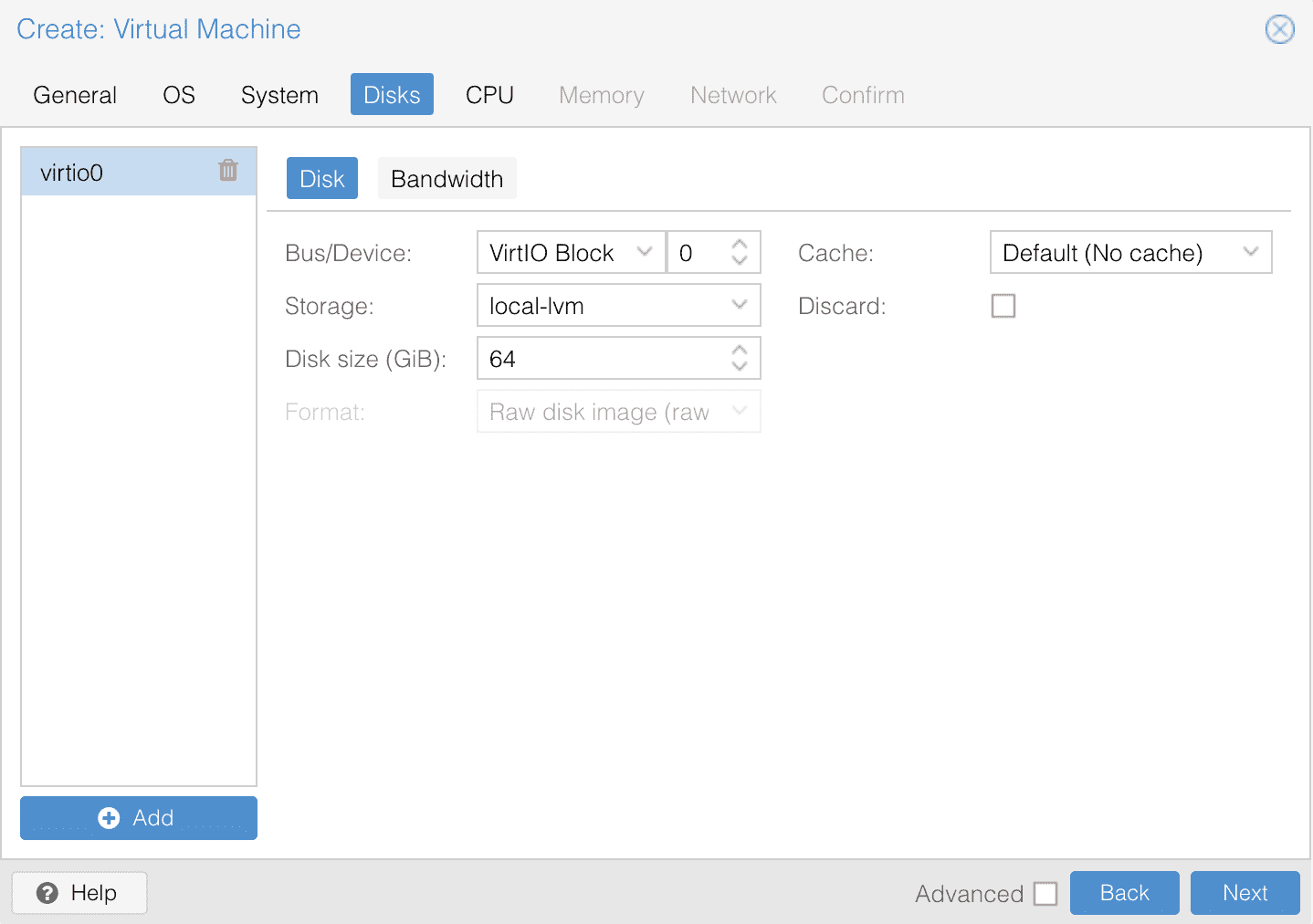
第五步,设置 CPU 核心,默认是不能超过物理 CPU 的数量的。
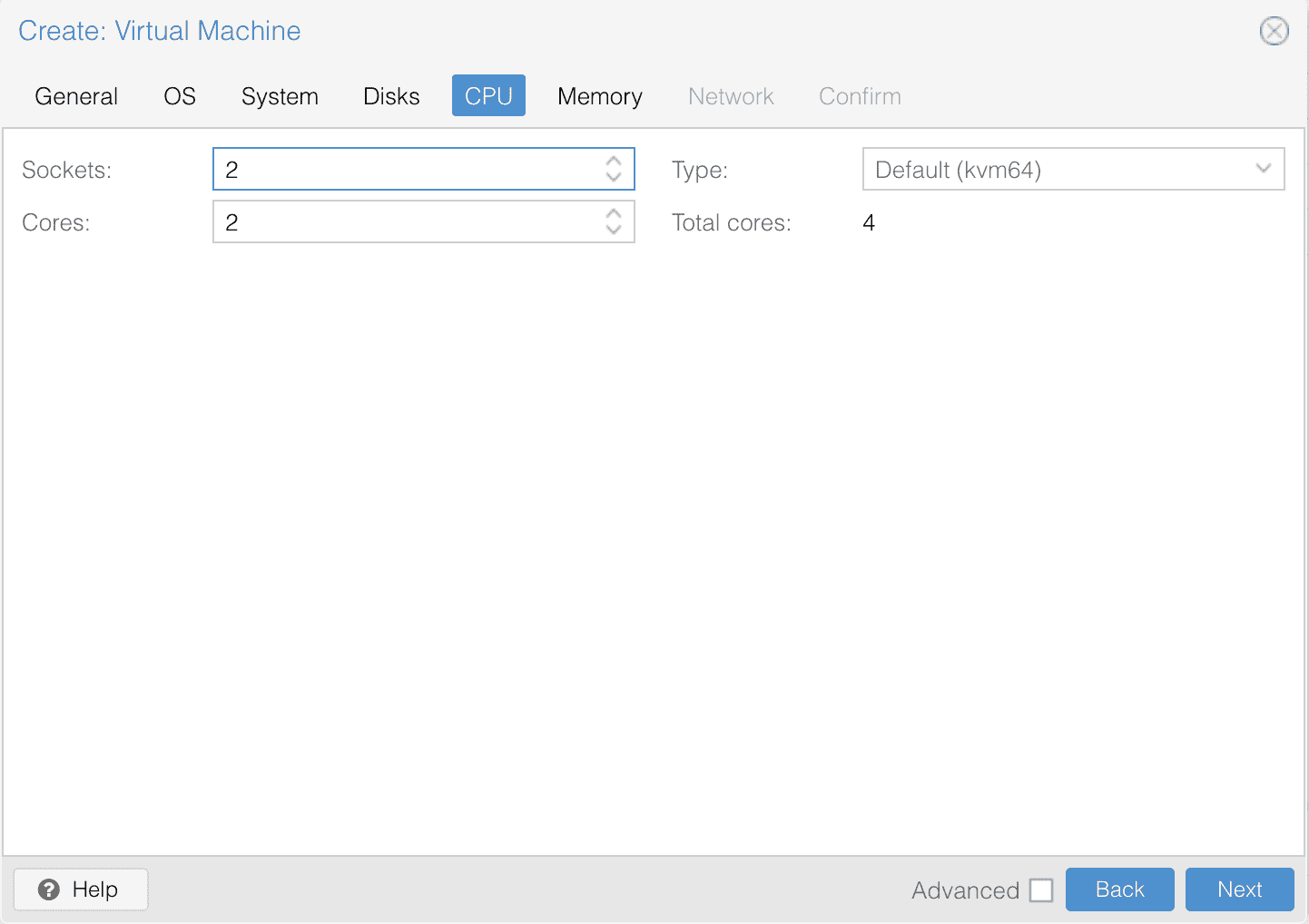
第六步,设置网络设备,我这边默认有一个 Linux 网桥(vmbr0),默认即可。
之后点击下一步,确认自己的配置,然后点击完成虚拟机的创建。
之后就可以开启虚拟机,第一次会使用设置 ISO 启动虚拟机,然后进入 Ubuntu Server 的安装界面。
安装 Ubuntu Server
第一次启动虚拟机之后会自动进入安装的程序,安装的过程比较简单,使用键盘选择,确认即可,基本上会分成如下几步:
- 选择语言,English
- 选择安装的类型,默认的 Ubuntu Server 即可
- 配置网络,这个地方需要注意
- 默认情况下安装程序会根据 DHCP 自动获取一个 IP 地址,如果这个 IP 地址不是你想要的,可以使用 Mannual 自动配置一个
- subnet 192.168.2.0/24
- IP 选择一个想要的,比如 192.168.2.30
- Gateway: 网关 192.168.2.1
- Name Server: 设置一个 DNS 解析服务器,比如 8.8.8.8
- Search Domain: 设置一个 Search Domain,Search Domain 的作用就是当本地网络的一个解析,比如设置了 Search Domain 是
einverne.info,那么在 Ubuntu Server 中解析webserver的时候会首先尝试去解析webserver.einverne.info
- 配置代理,不需要设置,但如果是在局域网,或者无法访问互联网的时候这个地方可以根据自己的需要设置一下
- Ubuntu Archive Mirror,默认即可
- 配置磁盘,可以根据自己的需求调整,我就按默认
- 创建用户名密码等
- 开启 SSH
- 选择是否要安装其他组件,比如 [[microk8s]], [[NextCloud]], [[weken]], [[Docker]] 等等
- 最后就是确认,等待安装完成
进入系统
等待安装程序安装完成之后就可以通过 IP 地址和端口,用户名和密码登录到 Ubuntu Server。
ssh username@ip
CoinPayments 加密货币支付网关
CoinPayments 是全球第一个加密货币支付网关,成立于 2013 年 8 月加拿大,CEO 是 Alex Alexandrov。商家可以借助 CoinPayments 来接受加密货币的支付订单。CoinPayments 接受非常多的加密货币,不仅支持流行的比特币(BTC),以太坊(ETH),还支持非常多的小众代币。CoinPayments 还提供了大量的购物车插件,以及定制的支付解决方案和商家工具。
CoinPayments 收取 0.5% 的固定佣金,相较于 Stripe 的 2~3%,以及信用卡更高的佣金,CoinPayments 非常有优势,但目前的问题就在于
- 加密货币波动大,无法在消费领域产生实际用途(稳定币除外)
- 加密货币支付对于普通人日常使用门槛较高,维护一个安全的加密货币钱包,以及如何认知加密货币钱包,[[钱包助记词]],私钥,网络,钱包地址等等,都需要有一些学习
CoinPayments 并没有将自己的业务限制在支付工具上,用户也可以通过 CoinPayments 构建一个在线商店,直接通过 CoinPayments 销售商品并接受加密货币支付,但看起来目前做得并不成功。
用户可以使用的另一个独特功能是 PaybyName 服务,它可以简化任何加密货币交易者或投资者的生活。通过创建一个帐户,用户可以获得一个用于发送或接收任所支持加密货币的地址。
特性
CoinPayments 的功能:
- 支持 2310+ 种币,包括比特币,莱特币,等等1
- 可以和现有的购物网站,[[WooCommerce]],[[Opencart]],[[Shopify]],[[OScommerce]],[[Magento]] 等等集成
- 礼品卡支持,可以购买带有加密货币的礼品卡
- 提供加密货币转换
- 多币种支持的钱包
费用
CoinPayments 对于所有支付的订单收取 0.5% 的交易手续费。2

对于存入钱包的,每个月前 15000 美元免费,之后收取 0.5%。
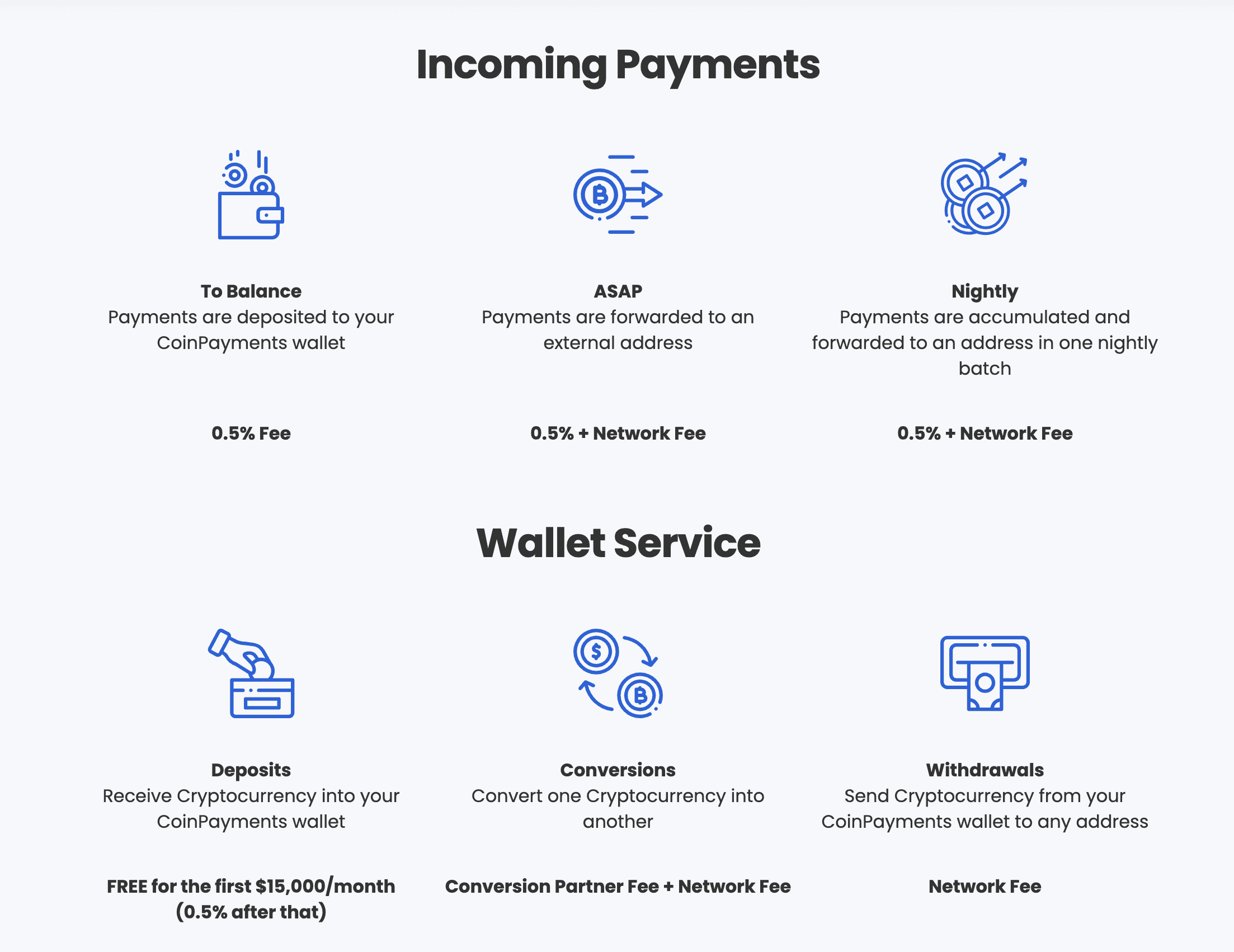
CoinPayments 不收取任何提现的手续费,但是如果要转账到其他钱包,根据不同的网络,需要支付不同的网络费用(Network Fees)。
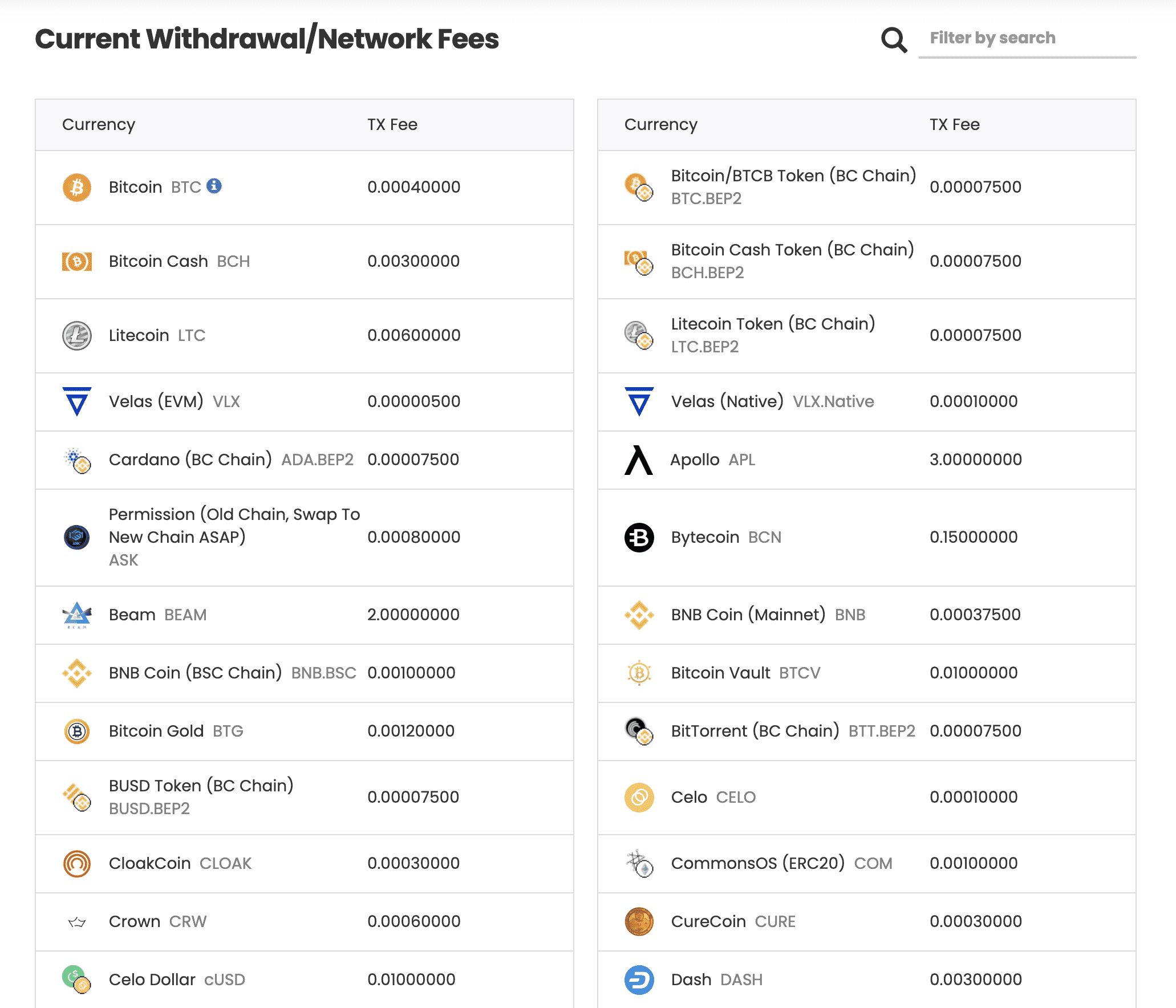
更多的网络费用可以在这里 查看。
注册使用
CoinPayments 的注册非常简单,只需要一个邮箱即可,但是 [[KYC]] (Know your customer) 的过程稍微有一些复杂。
注册使用 CoinPayments 的步骤:
- 准备一个邮箱,然后在 CoinPayments 上使用邮箱注册一个帐号
- 邮箱会收到一个验证码,然后通过验证码验证邮箱,进入 CoinPayments 后台
KYC
[[KYC]] 是 CoinPayments 验证注册用户身份的一种方式,在 KYC 的过程中至少需要准备:
- 护照原件(因为需要拍照)
- 居住证明(Bank statements ,三个月内的水电账单,有线电视账单 等等有住址的证明,只需要一份即可)
- 一个居住地的电话号码
然后按照网站给出的流程注册即可,但是需要注意的是,验证网站不能上传截图或者带反光的照片,在拍摄的时候要特别注意,否则可能验证失败。失败之后可以重新拍摄,重新提交进行验证。
身份验证完成之后就可以在 CoinPayments 后台访问设置,商家工具等等。
在注册后,您需要在您的 CoinPayments 账户中添加您要接受的加密货币。这涉及到为每种币种生成一个加密货币地址,客户可以向该地址发送付款,需要注意的是 USDT TRC-20 网络的地址需要提前向该地址发送 0.1 TRX 进行激活。
集成到您的网站:CoinPayments 提供了许多 API 和插件,可帮助您将其支付处理器集成到您的网站上。根据您的技术水平和需求,您可以选择使用 CoinPayments 提供的现成插件或自己编写代码。
接受付款:一旦 CoinPayments 已经被成功集成到您的网站上,您就可以开始接受加密货币付款了。当客户发送付款时,CoinPayments 会将资金保留在您的账户中,直到您将其提取到您的钱包中。
需要注意的是,使用 CoinPayments 需要您了解一些基本的数字货币概念,例如加密货币地址、钱包、Gas Fee 等等。如果您对此还不熟悉,建议您先学习一些相关基础知识。
提取资金
最后,您可以从 CoinPayments 账户中提取您接受的加密货币。提取的方式取决于您的需求和偏好,您可以选择将资金提取到您的加密货币钱包或将其转换为法定货币后提取到您的银行账户。
Non-Incorporated vs Incorporated
在 KYC 的过程中,你会看到 CoinPayments 要求用户选择是什么类型的账户,这个账户类型选择之后就不能修改了,除非联系人工客服。
Non-Incorporated 和 Incorporated 的区别在于
- non-incorporated 公司是归独立个人所有,验证流程是和个人账号一样的
- Incorporated 公司,例如法定公司,有限公司(公共或私人),一人一公司,合伙企业和非政府组织,可保护作为与所有者单独的法人实体的负债。
商家工具
API
CoinPayments 提供了一套完整的 API 接入方式,具体可查看这里。当用户完成支付时,也可以通过 IPN,Web Callback 的方式来通知系统。
最后
如果觉得文章内容对您有帮助,可以点击下方的支付按钮,支付 1 USDT 表示您的支持。
related
- [[Stripe]] 法币的支付网关
- [[Paypal Business]]
- [[Bitpay]]
- [[GoCoin]]
- [[CoinsBank]]
- [[Coinbase Commerce]]
- [[Asiabill]]
reference
Sieve 一个过滤邮件的语言
之前在搭建 Mailcow 邮件服务器的时候简单的了解到了 Sieve 这个可以用来编程过滤邮件的语言。刚好现在要充分利用起 Mailcow,所以系统地学习一下 Sieve 这个邮件过滤编程语言。
什么是 Sieve
Sieve 是由 RFC 5528 定义的一门专门用来处理电子邮件的语言。它被设计不仅可以用于邮件客户端的邮件过滤,也可以在邮件服务器端进行过滤。设计它的目的在于扩展性,且独立于邮件架构和操作系统。 它适合运行在不允许用户执行程序的邮件服务器上运行,例如在 IMAP 服务器上。因为 Sieve 中没有变量,没有循环,也不运行调用外部的 Shell。
Sieve 不是什么
- Sieve 不计划独立成为一门成熟的编程语言
- Sieve 并不适用于过滤或处理除 RFC 822 消息以外的内容
- Sieve 也不打算代替现存的其他工具
Sieve 过滤器的格式
Sieve 没有特别复杂的结构,只是包含一组命令,比如 discard, if, fileinto 等等
require ["fileinto", "reject"];
# Daffy Duck is a good friend of mine.
if address :is "from" "daffy.duck@example.com"
{
fileinto "friends";
}
# Reject mails from the hunting enthusiasts at example.com.
if header :contains "list-id" "<duck-hunting.example.com>"
{
reject "No violence, please";
}
# The command "keep" is executed automatically, if no other action is taken.
第一行脚本(require 命令)告诉 Sieve 解释器将使用可选的命令文件。然后是两个过滤规则。第一个过滤规则将所有来自 “ daffy.duck@example.com” 的邮件存储到名为“friends”的邮箱中。第二个规则拒绝头部包含字符串“
如果脚本中没有匹配的条件,则应用默认操作,即隐式“保留”命令。该命令将邮件存储在默认邮箱中,通常是 INBOX。
Sieve 有两种注释写法
# Everything after # character will be ignored.
/* this is a bracketed (C-style) comment. */
和地址比较,From:, To:, Sender:
还有三个可选的参数可以用来比较
:localpart,@符号前面的部分:domain,@符号后面的部分:all,全部
# The two test below are equivalent;
# The first variant is clearer and probably also more efficient.
if address :is :domain "to" "example.com"
{
fileinto "examplecom";
}
if address :matches :all "to" "*@example.com"
{
fileinto "examplecom";
}
一个邮件地址通常是 "FirstName LastName" <localpart@domain> 这样组成的。
比较 Header 中其他字段。
# File mails with a Spamassassin score of 4.0 or more
# into the "junk" folder.
if header :contains "x-spam-level" "****"
{
fileinto "junk";
}
匹配类型
Sieve 提供了三种比较方法:
:is,比较两个字符串完全相等:contains,是否包含:matches,使用通配符?来匹配一个未知字符,使用*来匹配零个或多个未知字符
# Reject all messages that contain the string "viagra"in the Subject.
if header :contains "subject" "viagra"
{
reject "go away!";
}
# Silently discard all messages sent from the tax man
elsif address :matches :domain "from" "*hmrc.gov.uk"
{
discard;
}
List of Strings
匹配列表:
# A mail to any of the recipients in the list of strings is filed to the folder "friends".
if address :is "from" ["daffy.duck@example.com", "porky.pig@example.com", "speedy.gonzales@example.com"]
{
fileinto "friends";
}
如果要表达,from 或 sender 是某邮箱的时候,做什么
# Check if either the "from" or the "sender" header is from Porky.
if address :is ["from", "sender"] "porky.pig@example.com"
{
fileinto "friends";
}
如果要组合表达
# Match "from" or the "sender" file with any of Daffy, Porky or Speedy.
if address :is ["from", "sender"] ["daffy.duck@example.com", "porky.pig@example.com", "speedy.gonzales@example.com"]
{
fileinto "friends";
}
allof, anyof
allof测试列表,如果列表中的每一个都是 true,则返回 true,逻辑上的 andanyof测试列表,只要其中一个满足,则返回 true,逻辑上的 or
# This test checks against Spamassassin's header fields:
# If the spam level ls 4 or more and the Subject contains too
# many illegal characters, then silently discard the mail.
if allof (header :contains "X-Spam-Level" "****",
header :contains "X-Spam-Report" "FROM_ILLEGAL_CHARS")
{
discard;
}
# Discard mails that do not have a Date: or From: header field
# or mails that are sent from the marketing department at example.com.
elsif anyof (not exists ["from", "date"],
header :contains "from" "marketing@example.com") {
discard;
}
过滤信息大小
可以使用 size 来检测
# Delete messages greater than half a MB
if size :over 500K
{
discard;
}
# Also delete small mails, under 1k
if size :under 1k
{
discard;
}
Example
一个简单的 Sieve 过滤器的例子是将所有来自特定发件人的邮件自动转发到另一个邮箱。下面是一个示例 Sieve 脚本:
if header :contains "From" "example@example.com" {
redirect "another@example.com";
}
这个脚本将检查邮件的发件人是否是”example@example.com”,如果是,则将邮件重定向到”another@example.com”。
Mailcow
在 Mailcow 中可以通过如下的路径设置 Sieve 过滤器。
Configuration -> Mail Setup -> Filters -> Add filter
另外如果有人想要创建自己的自定义域名邮箱,欢迎到 EV Hosting 订购使用。
reference
Raycast AI 使用体验
在之前的文章中就提到过 Raycast,前不久看到 [[Raycast]] 快速跟进了 OpenAI,现在推出了 Raycast AI,我没有想到的是,Raycast 的使用场景可以如此完美地和 AI 结合在一起。
Raycast 代替了如下我过去常常做的事情:
- 再不需要打开网页,或者 ChatGPT 客户端再输入问题
- 再不需要打开 Papago(或者 DeepL 等客户端)翻译段落(短句和单词基本靠 Chrome 插件和 [[GoldenDict]])
- 再不需要打开 OpenAI Translator 对文本进行润色
- 直接在 Obsidian 中让 Raycast AI 进行语法检查,改写,并一键替换原文
- 代替 [[Cursor.so]] 编辑器的自然语言编程,Raycast AI 可以用来解释代码,生成代码并直接插入编辑器
直接提问
翻译
选中文本,然后 Cmd+Space,translate 即可。

润色文本
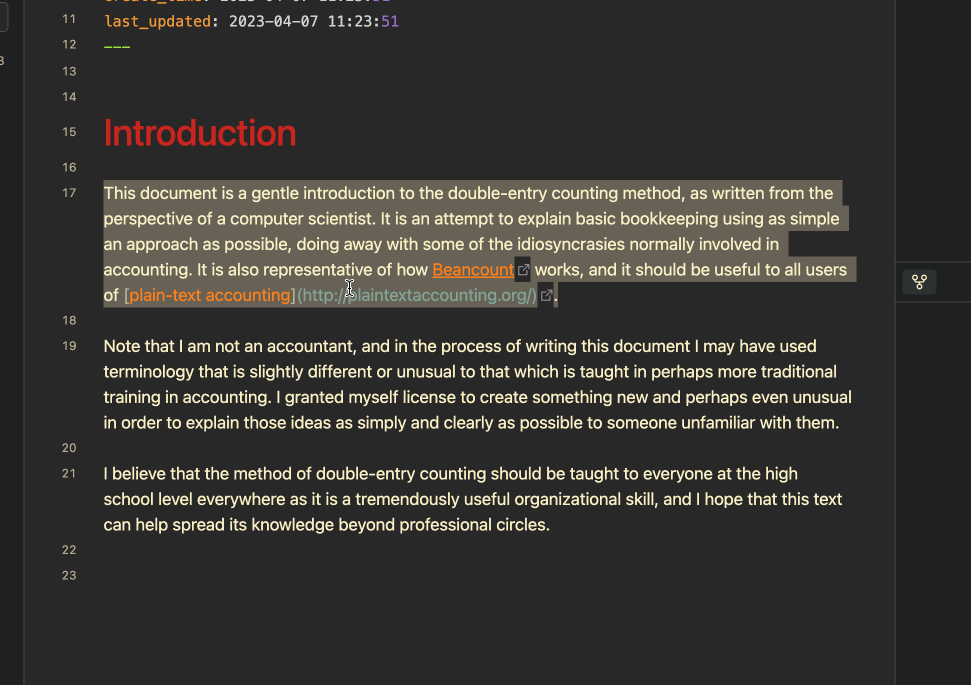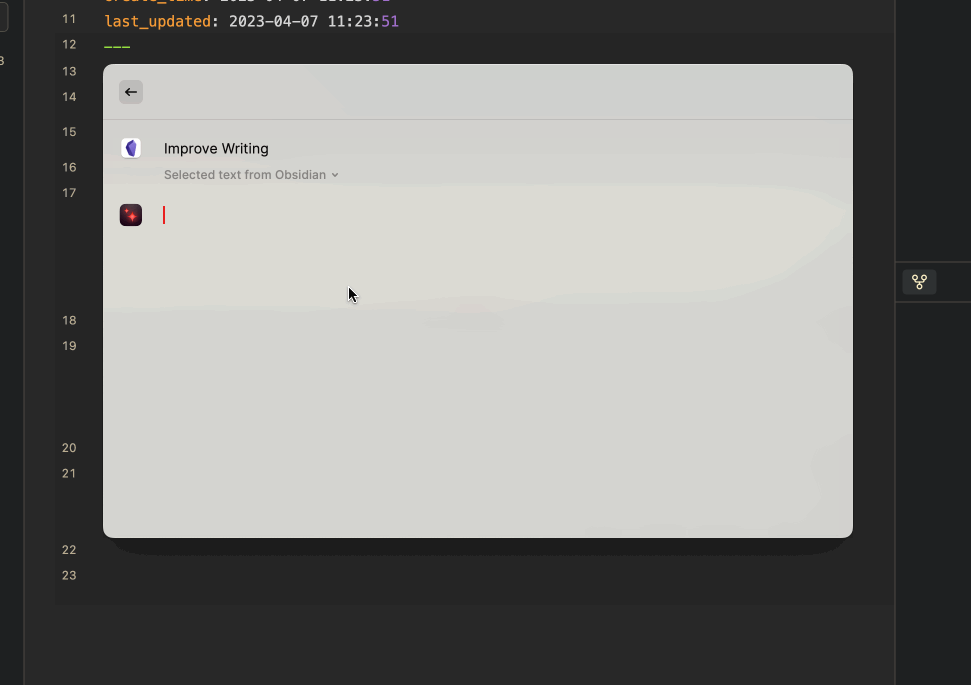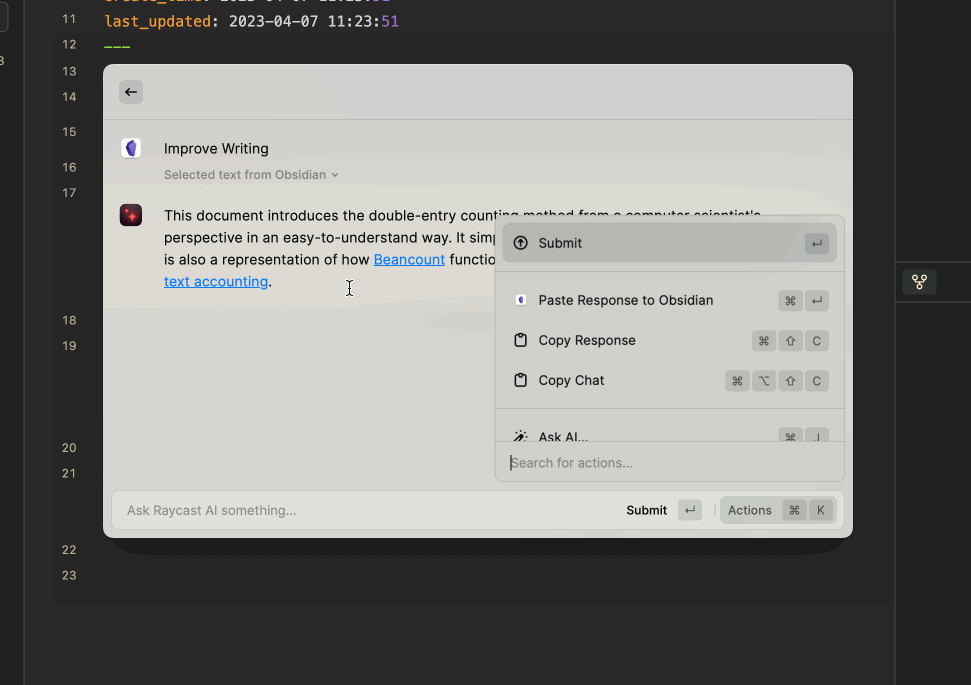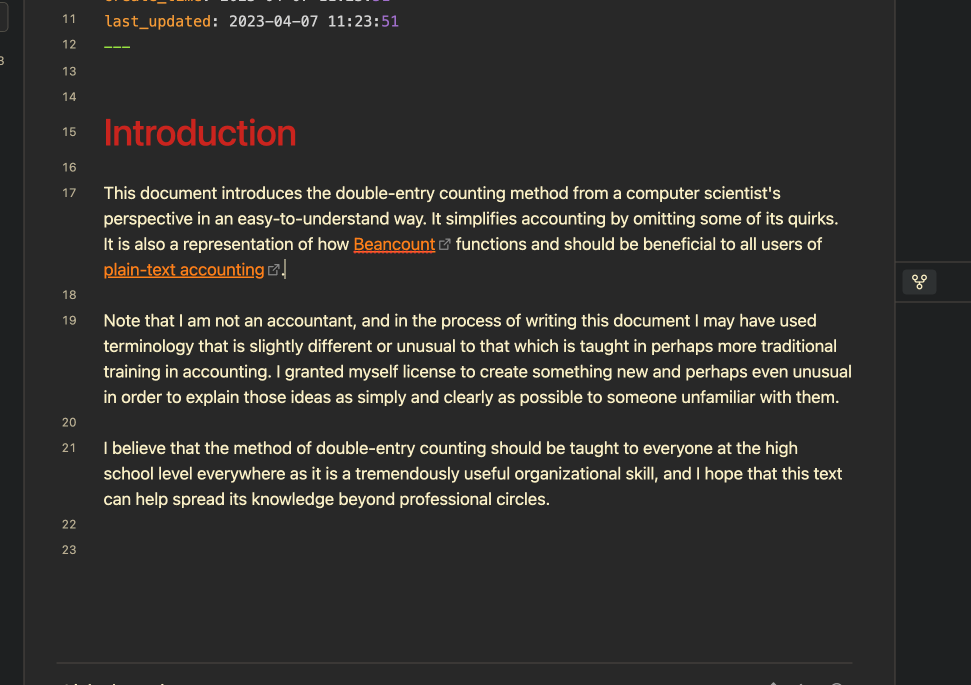
直接使用 Improve Writing,并将润色过的文本直接粘贴回 Obsidian。
总结
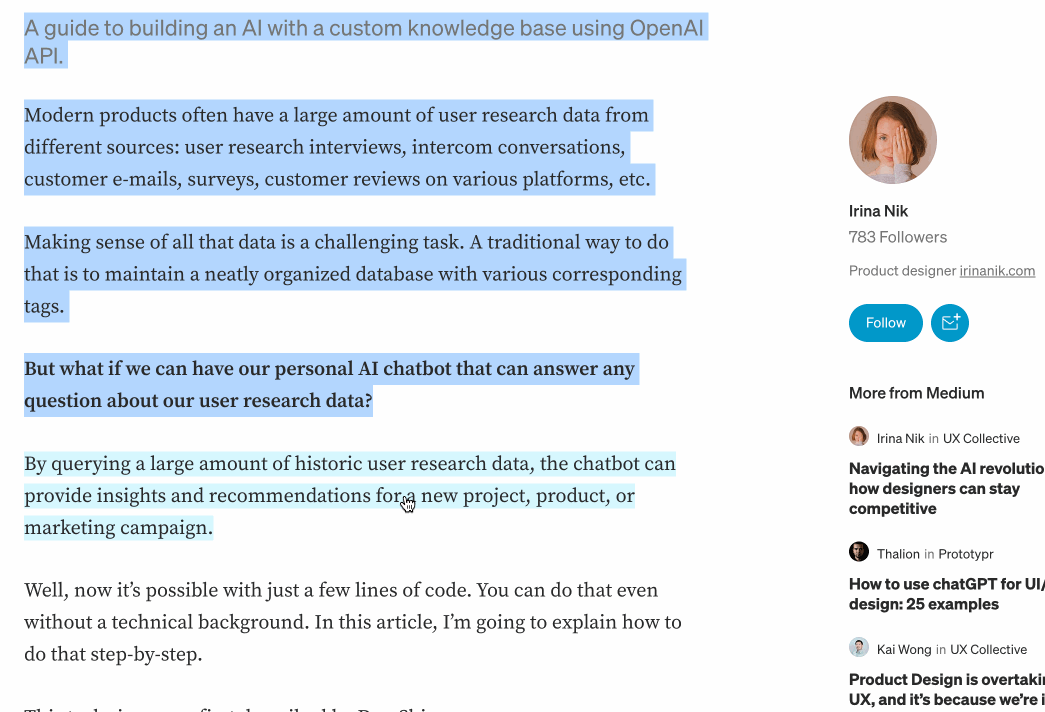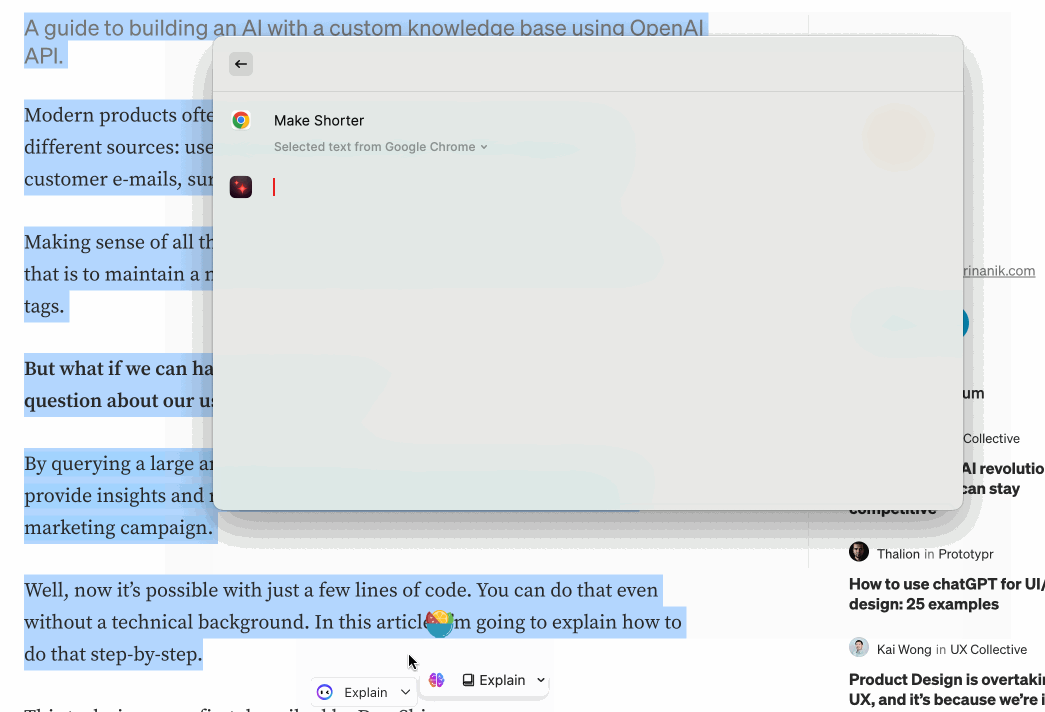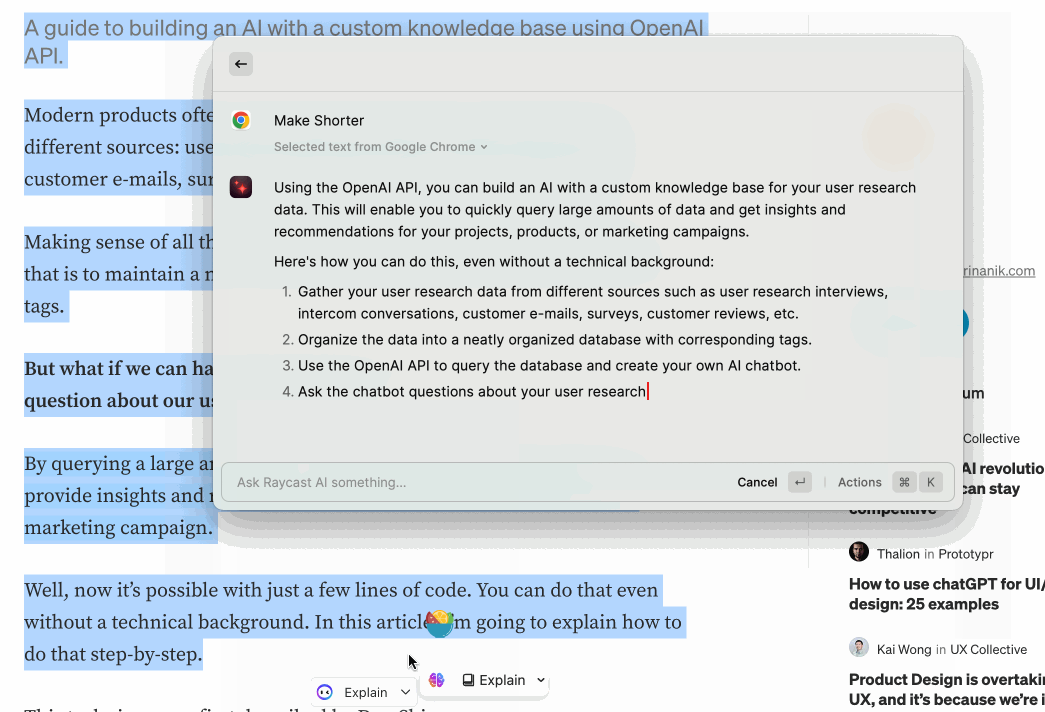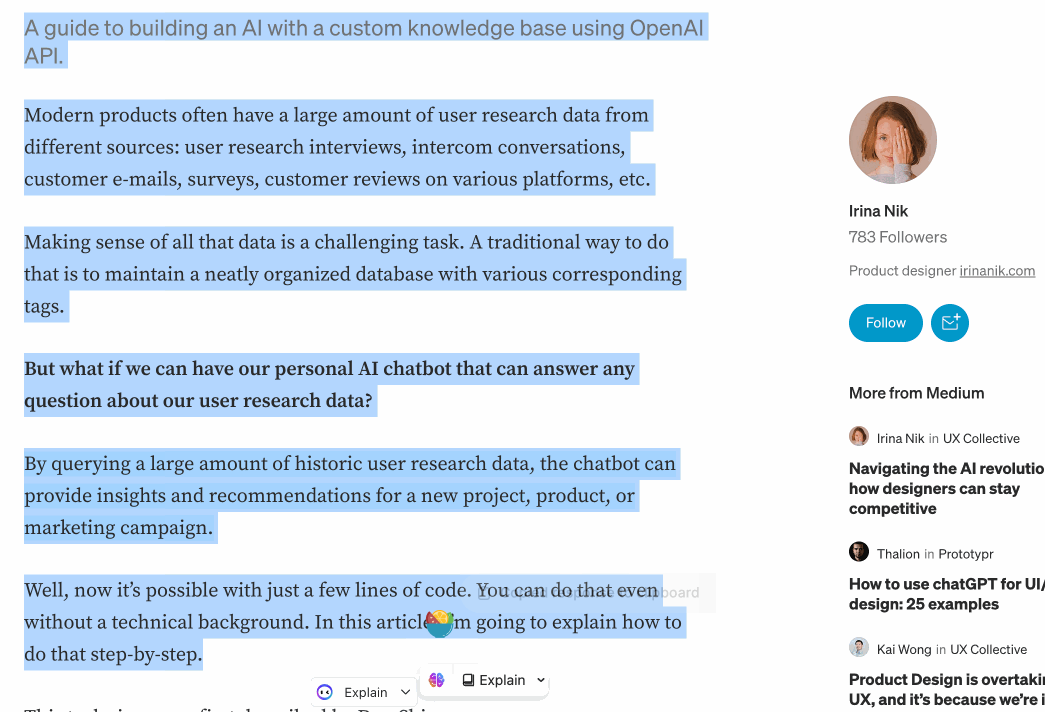
如果在网上看到一段非常长的文章,可以直接选中,然后让 Raycast 总结。
Create AI Command 创建自己的命令行
可以看到的是上面的所有的操作,大部分都是 Raycast AI 默认自己定义的,但是 Raycast AI 更强大的一点在于它可以自己创建 AI Command(prompt),也就是说可以利用 OpenAI 的上下文对话的能力,将一些固定的模式写道 Raycast 中,然后下次使用的时候就可以直接输入几个字母触发了。也可以利用 Raycast 自己的快捷键来一键呼出。
一些使用小 Tip
Raycast 本身已经非常强大了,但是有一些贴心的功能他没有展示出来,需要用户自己去发现,下面就是一些使用的小 Tip。
- 如果不满意 Raycast AI 的结果,可以直接按 Cmd+R 重新生成。
- 生成内容之后可以使用 Cmd+k 来对结果进行更多的操作,比如复制,比如粘贴回选中的地方
- Raycast AI 可以设置快捷键,比如可以将常用的 Ask AI,translate 等等设置一个单独的快捷键
alternative
如果还没有排到 Raycast AI,还可以试试 macOS 上的 MacGPT。
折扣码
Raycast AI 将会进入 Raycast Pro 的套餐,每个月 8 美元,目前可以使用 RAYFRIENDS10 来获取 10% 的折扣。
向量数据库及实现整理
什么是向量数据库
在介绍什么是向量数据库之前先来了解一下数据库的种类。
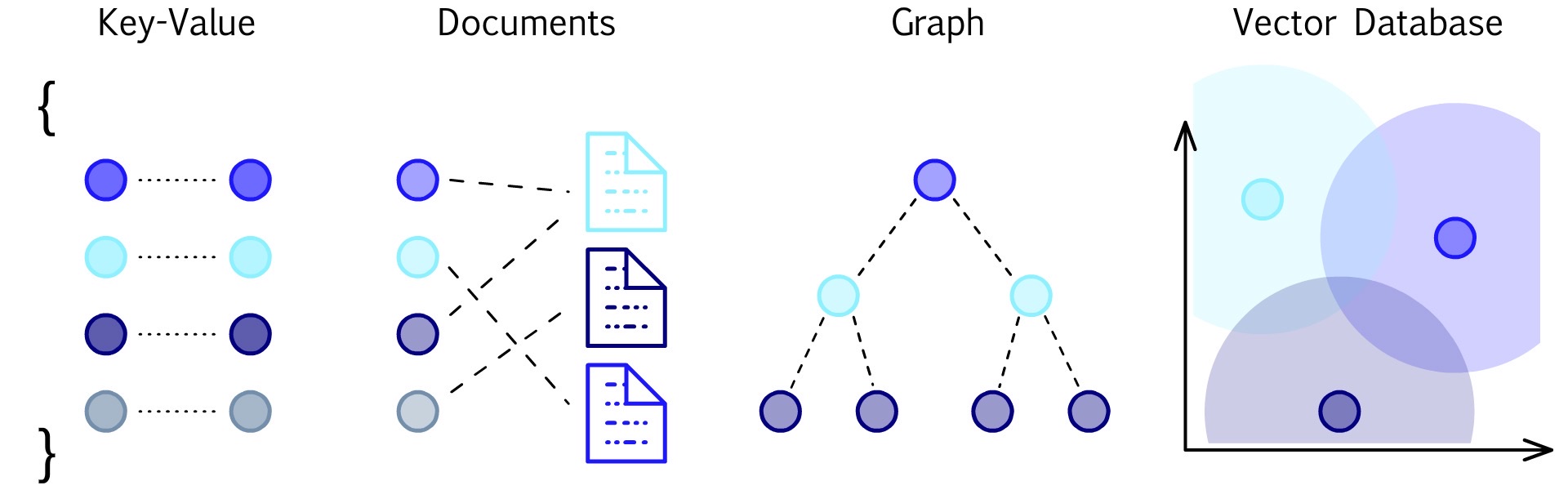
图上从左往右依次是 Key-Value 数据库([[Redis]],[[HBase]]),文档数据库([[MongoDB]],[[Cosmos DB]]),[[图数据库]]([[图数据库 Neo4j]],[[图数据库 Nebula Graph]]),向量数据库。
向量数据库就是用来存储,检索,分析向量的数据库。
向量数据库是一种专门用于存储和查询向量数据的数据库,其中向量数据指的是由数字组成的向量。向量数据库通常使用高效的相似度搜索算法,例如余弦相似度或欧几里得距离,来快速查询与目标向量最相似的向量。向量数据库在机器学习、计算机视觉、自然语言处理等领域中得到广泛应用。
The vectors are usually generated by applying some kind of transformation or embedding function to the raw data, such as text, images, audio, video, and others.
为什么需要有向量数据库
解决两个问题:
- 高效的相似性检索 (similarity search)
- 相似文本检索
- 从图片检索图片,人脸匹配(支付),车牌号匹配,图片检测等
- 高效的数据组织和分析能力
- 人脸撞库,分析案发现场的人物图片
在机器学习领域,通常使用一组数值来表示一个物体的不同特征。比如我们去搜索图片的时候,数据库中存储和对比的并不是图片,而是去搜索算法提取的图片特征。
向量数据库的特点
向量数据库具有以下特点:
- 提供标准的 SQL 访问接口
- 高效的相似度搜索:向量数据库使用高效的相似度搜索算法,例如余弦相似度或欧几里得距离,来快速查询与目标向量最相似的向量。
- 支持高维向量:向量数据库可以存储和查询高维向量,例如在图像识别和自然语言处理中经常使用的特征向量。
- 高性能:向量数据库通常使用高性能的数据结构和算法,例如哈希表和树结构,以实现快速的查询和插入操作。
- 可扩展性:向量数据库可以通过添加更多的节点或服务器来实现横向扩展,以支持大规模的向量数据集。
- 支持多种数据类型:向量数据库通常支持多种数据类型,例如浮点数、整数和布尔值,以满足不同应用场景的需求。
和传统数据库的区别
- 数据规模上超过关系型数据库,分布式,扩展性
- 查询方式不同,计算密集型
- 传统数据库点查和范围查
- 向量数据库是近似查
- 搜索推荐
- 低延时高并发
向量数据库有哪些
目前比较流行的向量数据库包括:
- [[Milvus]]:一个开源的向量数据库,是全世界第一款向量数据库,也是目前最领先的云原生向量数据库,支持自托管,支持高维向量的存储和查询,提供了多种相似度搜索算法和多种客户端语言接口。构建在开源的 Faiss, HNSW, Annoy 之上
- zilliz 是一个 SaaS 版本的 Milvus 平台,提供在线托管的 Milvus 服务。
- [[Weaviate]] 开源,一个完全托管的向量数据库
- [[Vespa]] 开源,可自托管,提供托管服务
- [[Vald]]
- [[Redis]] Redis 也提供了向量距离的相关内容
- [[Qdrant]] 开源,Rust
- [[Faiss]]:一个由 Facebook 开发的向量数据库,支持高效的相似度搜索和聚类操作,提供了多种索引结构和查询算法。
- sqlite-vss 基于 Faiss 做了一个 SQLite Vector Similarity Search
- [[Pinecone]] 闭源,完全托管的向量数据库
- Annoy:一个开源的向量数据库,支持高维向量的存储和查询,使用随机化近似算法实现快速的相似度搜索。
- Hnswlib:一个开源的向量数据库,支持高维向量的存储和查询,使用基于图的相似度搜索算法实现高效的查询。
- NMSLIB:一个开源的向量数据库,支持多种相似度搜索算法和索引结构,可以用于高维向量和非向量数据的存储和查询。
- Vearch
- TensorDB
- Om-iBASE,基于智能算法提取需存储内容的特征,转变成具有大小定义、特征描述、空间位置的多维数值进行向量化存储的数据库,使内容不仅可被存储,同时可被智能检索与分析。使用向量数据库可有效实现音频、视频、图片、文件等非结构化数据向量化存储,并通过向量检索、向量聚类、向量降维等技术,实现数据精准分析、精准检索。
- Proxima
- VQLite 是一个基于 Google ScaNN 包装的轻量简单的向量数据库,Go 语言编写。
- pgvector 是为 [[PostgreSQL]] 数据库编写的一个向量近似度查询支持。
- [[SPTAG]] 是微软开源的一个近似向量搜索的库
- [[Elasticsearch]] 和 OpenSearch 的 GSI APU
相关的开源项目:
- pigsty 监控/数据库开箱即用 HA/PITR/IaC 一应俱全。Pigsty 可以让用户以接近硬件的成本运行企业级数据库服务。2.0.2 发布之后可以使用 pgvector 来存储向量。
- vearch Vearch 是一个分布式的向量搜索系统。
ChatGPT Embedding 后的内容相似度查询是用 Cosine 算法
托管的向量数据库 Fully managed vector database
相关工具
- docarray 是 Linux 基金会下的一个专门为多模态数据设计的 Python 工具包,一套数据结构就解决了表示、处理、传输和存储,存储这块儿提供了一套统一的向量数据库 API,包括 Redis、Milvus、Qdrant、Weaviate、ES 等等。
可学习的代码:
- https://github.com/GanymedeNil/document.ai 基于向量数据库与 GPT3.5 的通用本地知识库方案(A universal local knowledge base solution based on vector database and GPT3.5)
向量数据库的几个发展方向
- 过去的向量数据库是面向实时性要求高,数据规模小,可用性高的场景,但是随着图像,视频,无人驾驶,NLP 的发展,数据量已经从千万级别增长到百亿级别
- 单机想分布式云原生发展
- 不同的索引实现方式,Faiss 为代表的 IVF 统一到了 HNSW/NGT 为代表的图流派。图索引尽管性能相对差,内存消耗高,但是性能好,召回率高。Google 也发布了 ScaNN 技术
- 规范的查询语言,向量数据库还没有统一的查询接口,大多数是定制的 SDK 或 RESTful 接口
- 向量数据库和传统数据库融合
向量数据库的实现原理
- 存储
- 查询
- 相似度计算
- 欧式距离 L2
欧式距离 Euclidean distance L2
欧氏距离是计算两个点之间最短直线距离的方法。
$d(x,y) = d(y,x) = \sqrt{\sum_{i=1}^{n}(x_i-y_i)^2}$
其中 $x=(x_1, x_2, …, a_n)$ 和 $y=(y_1, y_2, …, y_n)$ 是 N 维欧式空间中的点。
内积 Inner product (IP)
两个向量内积距离计算公式
$\mathbf{a} \cdot \mathbf{b} = \sum_{i=1}^{n} a_i b_i$
其中,$n$ 是向量的维数,$a_i$ 和 $b_i$ 分别是向量 $\mathbf{a}$ 和 $\mathbf{b}$ 在第 $i$ 个维度上的分量。
内积更适合计算向量的方向而不是大小。如果要使用点积计算向量相似度,必需对向量作归一化处理,处理后点积与余弦相似度等价。
二维
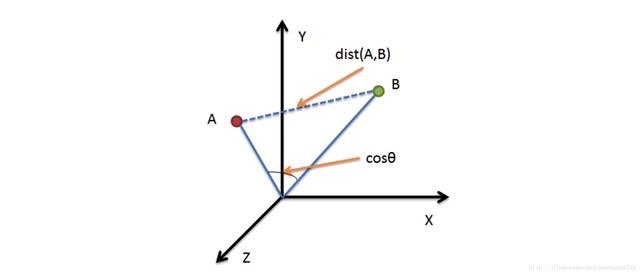
向量数据库的实际应用
- 相似文本检索
- 图片搜图片
- 搜索音频内容
- 搜索视频内容
一段代码演示向量数据库的用途
[[chatdoc]] 项目
related
- [[LlamaIndex]]
- [[LangChain]]
reference
LangChain 是什么
LangChain 是一个围绕大型语言模型 ([[LLM]])的应用开发框架,或者说是工具集,使用 Python 编写。LangChain 是由 Robust Intelligence 前的机器学习工程师 Chase Harrison 在 10 月底开源的工具库。众多 AI Hackathon 决赛项目使用 LangChain,它的 Github Star 迅速突破万,成为 LLM 应用开发者在选择中间件时最先想到的名字。
LangChain 能做什么?
- 个人助理,记住用户的行为数据并提供建议
- 聊天机器人,语言模型天然擅长生成文本
- 生成式问答
- 文档回答,针对特定的问题回答
- 文本摘要,从文本中提取信息
- 代码理解,理解代码的意图
- 文本总结,从较长的文本中总结信息
模块
LangChain 主要提供如下的模块来支持快速开发:
- Models 支持各种模型及集成
- LLMs,LLM 通用接口,LLM 相关常用工具
- Prompt,Prompts 管理,提示优化,提示序列化
- Document Loaders,文档加载的标准接口,与各种格式的文档及数据源集成
- Chains,包含一系列的调用,可能是一个 Prompt 模板,一个语言模型,一个输出解析器,一起工作处理用户的输入,生成响应,并处理输出
- Agents,Agent 作为代理人去向 LLM 发出请求,采取形同,检查结果,直到工作完成。
- Memory,是在 Chains 和 Agent 调用之间的持久化状态
- Indexes 将自己的文本做索引
用不到 50 行代码实现一个文档对话机器人
我们都知道 [[ChatGPT]] 训练的数据只更新到 2021 年,因此它不知道最新在互联网上产生的内容。而且 ChatGPT 的另一个缺点就是当他不知道的时候就会开始一本正经的胡说。但是利用 LangChain 可以用不到 50 行的代码然后结合 ChatGPT 的 API 实现一个和既存文本的对话机器人。
假设所有 2022 年更新的内容都存在于 2022.txt 着一个文本中,那么通过如下的代码,就可以让 ChatGPT 来支持回答 2022 年的问题。
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import os
import jieba as jb
from langchain.chains import ConversationalRetrievalChain
from langchain.chat_models import ChatOpenAI
from langchain.document_loaders import DirectoryLoader
from langchain.embeddings import OpenAIEmbeddings
from langchain.text_splitter import TokenTextSplitter
from langchain.vectorstores import Chroma
def init():
files = ['2022.txt']
for file in files:
with open(f"./data/{file}", 'r', encoding='utf-8') as f:
data = f.read()
cut_data = " ".join([w for w in list(jb.cut(data))])
cut_file = f"./data/cut/cut_{file}"
with open(cut_file, 'w') as f:
f.write(cut_data)
def load():
loader = DirectoryLoader('./data/cut', glob='**/*.txt')
docs = loader.load()
text_splitter = TokenTextSplitter(chunk_size=1000, chunk_overlap=0)
docs_texts = text_splitter.split_documents(docs)
api_key = os.environ.get('OPENAI_API_KEY')
embeddings = OpenAIEmbeddings(openai_api_key=api_key)
vectordb = Chroma.from_documents(docs_texts, embeddings, persist_directory='./data/cut/')
vectordb.persist()
openai_ojb = ChatOpenAI(temperature=0, model_name="gpt-3.5-turbo")
chain = ConversationalRetrievalChain.from_llm(openai_ojb, vectordb.as_retriever())
return chain
chain = load()
def get_ans(question):
chat_history = []
result = chain({
'chat_history': chat_history,
'question': question,
})
return result['answer']
if __name__ == '__main__':
s = input('please input:')
while s != 'exit':
ans = get_ans(s)
print(ans)
s = input('please input:')
reference
介绍一下新推出的 EV Hosting 网络共享托管服务
因为自己之前买过一些 VPS,但是一直空闲很多,所以想着是否能够充分利用起来。最近正好看到可以免费使用 [[Clientexec]] 管理 Web Hosting 账单,所以隆重介绍一下刚刚推出的新服务 EV Hosting,目前上线了两个功能,共享网站托管服务和自定义域名邮箱服务。
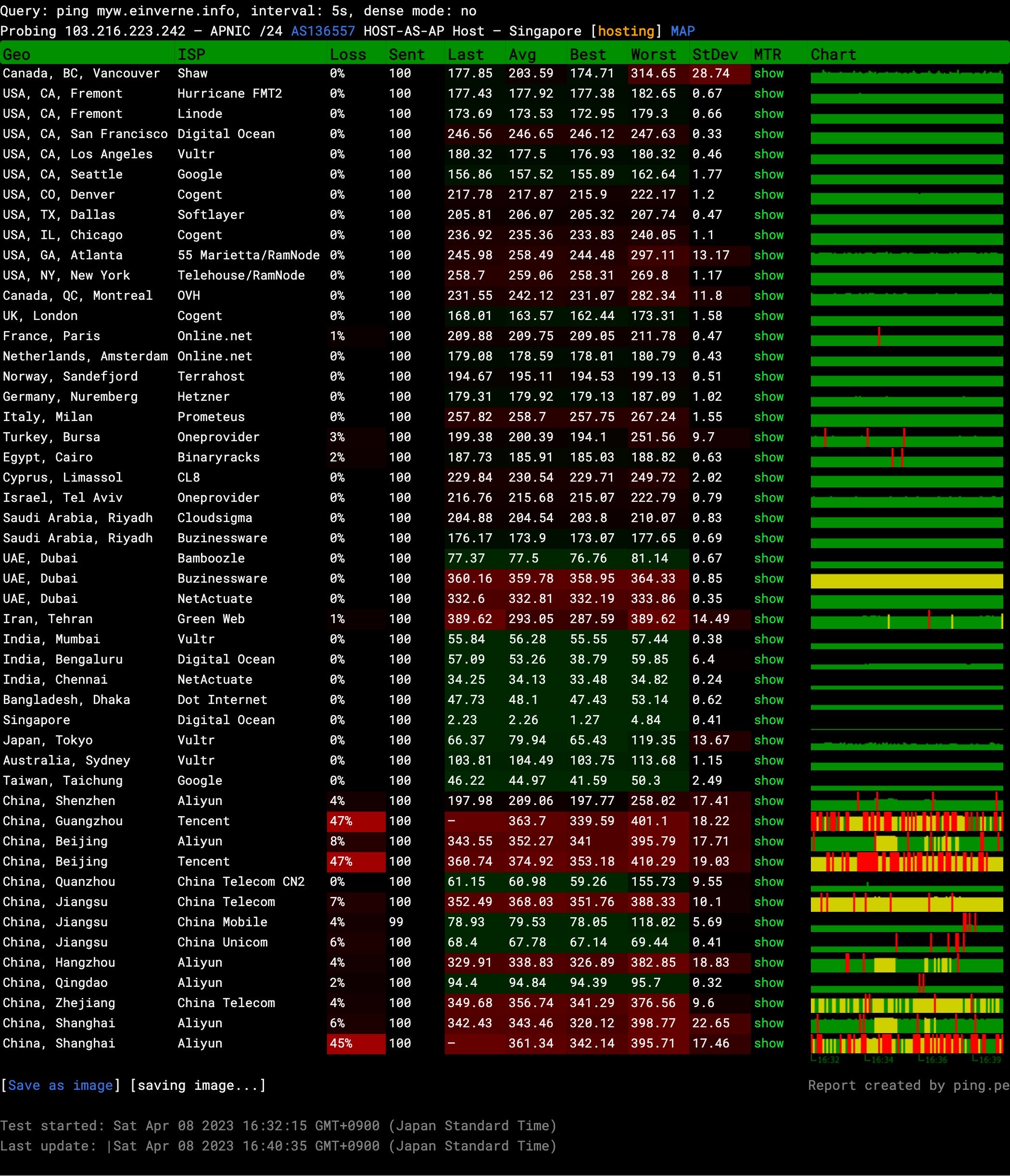
新加坡 共享网站托管服务
共享网站托管服务(Shared Web Hosting) 是一种网站托管服务,是将多个网站存储在同一台服务器上,并共享服务器上的 CPU、内存和带宽。这种类型的托管服务通常是最便宜和最受欢迎的选择,特别适合个人和小型企业。
如果你是一个不懂技术的个人但想在网络上有一片属于自己的空间,或者你想以最低的成本开展在线商城,欢迎来订购使用。
本站提供的托管服务,服务器位于新加坡,CPU 是 AMD Ryzen 9 3900X 12-Core Processor,服务器共 128 GB 内存。
一键安装超过 400 种应用
目前该服务托管于新加坡的服务器,使用 [[DirectAdmin]] 面板,装有 [[Softaculous]],可以一键安装包括 [[WordPress]],[[Joomla]],[[NextCloud]],[[Tiny Tiny RSS]],[[miniflux]],[[FreshRSS]],[[phpmyadmin]] 等等超过 450 种的应用程序1,不少的应用我之前也是介绍过的,并且还一直在用,比如 [[NextCloud]] 这个文件同步工具,[[miniflux]] 这个 在线的 RSS 阅读器。Softaculout 非常强大,很多功能和特性有待你去发现。
DirectAdmin 后台也有一个在线的文件管理器,可以直接基于网页对网站内容进行管理。
自定义域名邮箱
另外订购所有的套餐都可以在后台配置自定义邮箱,每一个邮箱每个小时可以发送至多 200 封邮件。请不要滥用发件发送恶意、垃圾邮件。
也可以使用后台提供的 Roundcube 网络邮箱界面来管理自己的邮件。
MySQL 数据库
购买套餐之后可以在后台创建响应的 MySQL 数据库供应用程序保存数据使用。所有的数据库内容及网站内容都会定期通过备份来保证安全。
附加功能
可以通过附加功能,来设置 Node.js,PHP,Python 等应用程序。
为了庆祝上线,在订购所有年付套餐的时候输入 EVHOSTING 则可以享受 5 折的优惠(优惠截止 4 月末)。最低可以以 8 元购买一年 Bronze 套餐(限量 10 个,如果看到界面显示优惠券代码无效则表示优惠码用完或已经过期)。
加利福尼亚 网络优化 共享空间
加利福尼亚的共享空间是大陆网络优化空间,到大陆的网络延迟非常文档。
自定义域名邮箱服务
如果你只需要发送邮件的服务,那么也可以订购这个自定义域名邮箱的服务,订购服务之后需要我手工启用,后台使用的是 Mailcow,我再添加了域名之后会给你的邮箱发送相应管理后台的信息。
所有在线购买的产品都可以通过在线提交工单的方式获得支持,并且后续会陆陆续续更新更多相关的使用技巧,欢迎关注。另外服务刚刚上线,如果有任何使用的问题,反馈并且到的验证的都可以免费获取一年的 Bronze 套餐。
记录一下 Clientexec 中配置 SMTP 时的一些问题
本文记录一下在配置 Clientexec 中的 SMTP 发送邮件的时候遇到的一些错误。添加了 [[mailcow]] 的 SMTP 配置,但是测试发送邮件总是报如下的错误。
验证 SMTP 配置
SMTP Error: The following recipients failed: email-test@clientexec.com: : Sender address rejected: not owned by user admin@mailcow.email
这就非常奇怪, 为了验证我的 SMTP 配置是没有问题的,我还直接写了一段 Python 发送邮件的程序,邮件是可以正常的发送出去的。所以我把怀疑点移动到了 Clientexec 面板。开始怀疑是不是 [[Clientexec]] 在 SMTP 配置的地方有什么 BUG。
Python
import smtplib
from email.mime.text import MIMEText
from email.mime.multipart import MIMEMultipart
def send_email(sender_email, recipient_email, subject, body, smtp_server,
smtp_port, username, password):
# Create a message object
message = MIMEMultipart()
message['From'] = sender_email
message['To'] = recipient_email
message['Subject'] = subject
# Add the body of the message as a MIMEText object
message.attach(MIMEText(body, 'plain'))
# Connect to the SMTP server and send the message
with smtplib.SMTP(smtp_server, smtp_port) as server:
server.starttls()
server.login(username, password)
server.sendmail(sender_email, recipient_email, message.as_string())
sender_email = ''
recipient_email = ''
subject = 'Test Email'
body = 'This is a test email sent from Python!'
smtp_server = ''
smtp_port = 587
username = ''
password = ''
if __name__ == '__main__':
send_email(sender_email, recipient_email, subject, body, smtp_server,
smtp_port, username, password)
验证 Clientexec 后台 SMTP 设置
为了验证 Clientexec 后台的 SMTP 设置是可以正常工作的,我看到官方的文档上提供了 Gmail SMTP 设置的说明,所以我直接用之前的 Gmail 的 SMTP 设置,在 Clientexec 后台配置了一下。测试是可以正常发送邮件的。唉,难道还是我的 SMTP 配置不正确。
为了验证不是 Clientexec 只优化了 Gmail 的发送邮件,我又把域名添加到 [[MXRoute]] 生成了一个 SMTP 的用户名和密码。然后在 Clientexec 后台添加了配置,测试,发现竟然也发送成功了。那么到此时我只能怀疑是不是 Mailcow 在发信的时候有一些限制。
开启 Clientexec 调试日志
编辑 config.php
// *** LOG_LEVELS (each level adds additional information) ***
// 0: No logging
// 1: Security attacks attempts, errors and important messages (recommended level)
// 2: Reserved for debugging
// 3: + Warnings and EventLogs, VIEW/ACTION and Request URIs and URI redirections and POST/COOKIE values
// 4. + plugin events, curl requests, some function calls with their parameters, etc.
// (use this when sending logs to support)
// 5: + include suppressed actions
// 6: + Action responses (ajax,serialized,XML (as array)
// 7: + SQL queries
define('LOG_LEVEL', 6);
// To activate text file logging, replace the 'false' with the file full path. Do not use relative paths.
// Use absolute paths(e.g. /home/yourinstallationpath/ce.log, instead of ce.log)
// The log may show passwords, so please use a file outside the web root, but writable by the web server user.
define('LOG_TEXTFILE', 'ce.log');
然后将日志等级调整到 6,将日志写到文件中方便查看。
然后在页面操作的时候查看日志 less ce.log。
于是我又将 Mailcow 的 SMTP 配置添加到后台,进行测试。同时观察日志。
(4) 04/05/23 07:35:42 - Starting to send Test Email with subject "Clientexec Test Email"...
(5) 04/05/23 07:35:43 - CLIENT -> SERVER: EHLO client.einverne.info
(5) 04/05/23 07:35:43 - CLIENT -> SERVER: STARTTLS
(5) 04/05/23 07:35:44 - CLIENT -> SERVER: EHLO client.einverne.info
(5) 04/05/23 07:35:44 - CLIENT -> SERVER: AUTH LOGIN
(5) 04/05/23 07:35:44 - CLIENT -> SERVER: [credentials hidden]
(5) 04/05/23 07:35:44 - CLIENT -> SERVER: [credentials hidden]
(5) 04/05/23 07:35:45 - CLIENT -> SERVER: MAIL FROM:<admin@client.einverne.info>
(5) 04/05/23 07:35:45 - CLIENT -> SERVER: RCPT TO:<email-test@clientexec.com>
(5) 04/05/23 07:35:45 - SMTP ERROR: RCPT TO command failed: 553 5.7.1 <admin@client.einverne.info>: Sender address rejected: not owned by user admin@mailcow.mail
(5) 04/05/23 07:35:45 - CLIENT -> SERVER: QUIT
(5) 04/05/23 07:35:45 - SMTP Error: The following recipients failed: email-test@clientexec.com: <admin@client.einverne.info>: Sender address rejected: not owned by user admin@mailcow.mail
发现了 SMTP Error。
验证 Mailcow
因为排除了 Clientexec 后台配置的问题,于是我使用 Mailcow 加上 Sender address rejected 关键字进行搜索,这才发现 Mailcow 相关的问题出现过很多次, 原来是 Mailcow 默认开启了 Sender Addresses Verification,必须要手动关闭这个验证 才能代替发送邮件。
从错误日志中就能发现原来 Clientexec 在测试发送邮件的时候是使用的 admin@clientexec-domain.com 来发送邮件的。而我的 SMTP 配置的发件邮箱是 no-reply@domain.com 这样的,Mailcow 默认情况下是不允许用户以别人的身份发送邮件的(当然这也是能理解的,我不理解的是 Clientexec 后台明明是有 Override From 这样的选项的,却在测试邮件的功能里用其他邮箱来测试),所以才会报错。
解决问题的方法
本来只是想简单的总结一下解决问题的过程,但这个解决问题的思维过程正好可以提炼成一个思考问题的方式。而以上解决问题的思考方式就是非常简单的排除法。
- 首先是验证 SMTP 配置是否有问题,用 Python 写了一段发信程序
- 然后是验证 Clientexec 后台 SMTP 配置是否有 BUG,通过尝试其他的 SMTP 配置,发现没有问题
- 那是不是 SMTP 提供服务的 Mailcow 有问题,通过日志和错误信息查询到原因
《我们为什么要睡觉》读书笔记
怎么知道的这一本书
最早听说这一本《我们为什么要睡觉》,还是在有一年 Bill Gates 的年度读书单中看到的,后来又在关注的博主的推荐图书中第二次看到,并且这个博主给了一个非常不错的评价,再到最近就是和一个朋友聊天的时候提到睡眠的问题,朋友常常不能在深夜快速的入睡,平时又起得不规律,所以我又想起了这一本很久都没有看的书。
关于作者
“Why We Sleep” 的作者是 Matthew Walker,他是加州大学伯克利分校的神经科学和心理学教授,也是 Sleep and Neuroimaging 实验室的主任。他的研究集中在睡眠、梦境和意识的神经科学机制上。Walker 自己也上过 TED,也会到各地演讲,在 YouTube 上能找到他很多资料。他自己也有一档播客,讲述的内容就是有关于睡眠的。
几句话总结书的内容
人类的一生中有三分之一的时间都是在睡眠,但是却从来没有人解释为什么人类需要睡觉,如果不睡觉会发生什么。作者通过对睡眠的层层剖析,通过大量的实验去研究睡眠,来解释我们为什么要睡觉。
- 睡眠是什么
- 睡眠的几个特征
- 处于睡眠中的生物体通常是平躺
- 熟睡的生物体的肌肉张力降低
- 睡觉的人不会表现出明显的交流或反应
- 状态很容易逆转(惊醒),与昏迷、麻醉、冬眠和死亡区别开来
- 睡眠在 24h 内遵循一种可靠的定时模式,昼夜交替
- 外部意识的丧失,停止感知外部世界,但是耳朵仍然在听,鼻子可以闻到,舌头和皮肤也有感觉
- 睡眠状态会丧失对时间的感知
- 两种睡眠
- 眼睛运动的睡眠
- 眼睛不运动的睡眠
- 睡眠的周期,两个阶段,交替出现
- 非快速眼动睡眠
- 快速眼动睡眠
- 睡眠的不同模式
- 单相睡眠,在晚上进行很长时间的睡眠
- 双相睡眠,在晚上睡 7~8 小时,下午进行 30~60 分钟小睡
- 人类一生中不同阶段睡眠不一样
- 出生之前,几乎所有时间都处于一种类似睡眠的状态
- 缺乏快速眼动睡眠与孤独症谱系障碍(ASD,自闭症)有关联
- 童年的睡眠,婴幼儿显示多相睡眠,许多短的睡眠片段
- 青春期,深度非快速眼动睡眠在青春期之前达到顶峰,然后开始减弱
- 深度睡眠也许才是大脑成熟的驱动力
- 理性在青少年中最后才会出现,因为它是接受睡眠成熟改造的最后一个大脑区域
- 中年和老年的睡眠,睡眠出现问题,睡得越来越早
- 出生之前,几乎所有时间都处于一种类似睡眠的状态
- 睡眠的几个特征
- 睡眠的好处和睡眠不足的坏处,为什么需要睡眠
- 可以让寿命更长吗?
- 学习之后的睡眠具有加强记忆和避免遗忘的力量
- 睡眠有助于帮助恢复神经
- 熟睡的大脑通过清醒时大脑不会尝试的方法,将不同的知识集合起来,形成问题解决能力
- 睡眠和阿兹海默,心血管疾病等等都有关系
- 梦的科学解释
- 瓦解了 [[弗洛伊德]] 关于梦是愿望的满足的非科学理论
- 梦的意义和内容,[[亚里士多德]],在《自然诸短篇》,坚持基于自身经验的信念,相信梦起源于最近清醒时经历的事件
- 弗洛伊德认为梦来自没有实现的无意识愿望,弗洛伊德的理论缺乏明确的预测,科学家无法设计出实验来检验他的理论中的任何论点
- 梦的创造性和对梦的控制
- 深度非快速眼动睡眠可以增强个体的记忆
- 快速眼动睡眠提供了精湛的、补足性的好处,以抽象且新奇的方式,将记忆的元素相互混合 [[门捷列夫]] 发现元素周期表
- 从安眠药到社会变革,通过具体的实验,对睡眠障碍进行解释
- 梦游症
- 有睡眠及其疾病引起的非意志行为具有非常现实的法律、个人和社会后果
- 失眠症
- 代谢率高,导致核心体温更高,而睡眠需要降低体内温度
- 提高警觉水平的激素皮质醇,神经化学物质肾上腺素,去升上腺素升高,心率很高
- 大脑活动模式改变
- 嗜睡症
- 致死性家族性失眠症
- 睡眠剥夺 VS 食物剥夺
- 梦游症
启发或想法
在知道这一本书之前,我甚至没有想过这个问题「我们为什么要睡觉」? 我个人的睡眠一直非常不错,从来就是到点身体就会告诉眼睛要闭起来了,到了网上 11 ,12 点左右就不自觉的没有精力做任何的事情,而每天早上到点(7 点到 8 点之前) 就会自然而言睁开眼睛。甚至过去的几年时间里面我连闹钟也不需要设置,我的生物钟比闹钟都准,更甚至有几次本来就定好要早起一会儿出门,当我醒来睁开眼睛的时候,过一分钟就是定好的闹钟。而我一旦早上起床之后就再也睡不着了,虽然我感觉挺好,但是有些假期或者周末想多睡一会儿的时候却也是睡不着。用这本书中的话来说就是人的身体已经觉得睡眠足够了,所以再睡也只是闭目养神而已。
与我而言,还有一个更加神奇的事情是我从来不做梦,或者说我从来不记得我做过梦。有朋友总是会对自己的梦境非常清楚,甚至能描述出梦境中发生的事情,像是上演了一部大片一样。但每一次我听到都感觉非常神奇,我自己没有任何的感受,书中第三部分解释了很多梦形成的原因,但我还是没有办法给我自己的经历一个很好的解释。
兼听则明 偏信则暗
在读完这本书之后,大概率会被书中「严谨」的科学实验所说服,但我在浏览相关介绍的时候,在 HackerNews 上也看到一篇反驳的文章。
我把这篇反驳文章的几个子标题放在这里:
- 不,较短的睡眠并不意味着较短的寿命
- 对于抑郁症患者而言,睡个好觉并不总是有益的
- 睡眠不足不会直接杀死你
- 不,世界卫生组织从未宣布失眠是一种流行病
- 不,发达国家中三分之二的成年人并未未能获得建议的睡眠量
作者在文章中也引用了一些实验数据来论证自己的观点,当然在这个地方,我是没有办法去判断他们谁对与谁错的。两方不同的观点都有各自详细的数据佐证。
但我想说的是,科学不就是在这样提出假设,修正理论中的错误,发布自己新的理论,再进行更进一步的研究批判,从而螺旋式的上升的嘛。这又不得不提到自由派哲学家[[洛克]],[[波普尔]]所说的 [[人类认识的可错性]],抱持开放的心态,不盲目相信任何一本书、任何一个人、任何一个观点。科学的精神就是开放和质疑。读书要抱着追求「普遍的共识」,在这个基础之上跟阅读更多新的理论,但永远不排除自己出错的可能性,这样才能进步。
谁应该看这本书
推荐所有睡眠不好的朋友阅读,了解一下睡眠是什么。虽然上问题到人类不一定需要 8 个小时的睡眠时间,但是休息好,能够有充分的睡眠对个人也是很好的。
文章分类
最近文章
- AI Shell 让 AI 在命令行下提供 Shell 命令 AI Shell 是一款在命令行下的 AI 自动补全工具,当你想要实现一个功能,敲一大段命令又记不住的时候,使用自然语言让 AI 给你生成一个可执行的命令,然后确认之后执行。
- 最棒的 Navidrome 音乐客户端 Sonixd(Feishin) Sonixd 是一款跨平台的音乐播放器,可以使用 [[Subsonic API]],兼容 Jellyfin,[[Navidrome]],Airsonic,Airsonic-Advanced,Gonic,Astiga 等等服务端。 Sonixd 是一款跨平台的音乐播放器,可以使用 [[Subsonic API]],兼容 Jellyfin,[[Navidrome]],Airsonic,Airsonic-Advanced,Gonic,Astiga 等等服务端。
- 中心化加密货币交易所 Gate 注册以及认证 Gate.io 是一个中心化的加密货币交易所。Gate 中文通常被称为「芝麻开门」,Gate 创立于 2013 年,前身是比特儿,是一家致力于安全、稳定的数字货币交易所,支持超过 1600 种数字货币的交易,提供超过 2700 个交易对。
- 不重启的情况下重新加载 rTorrent 配置文件 因为我在 Screen 下使用 rTorrent,最近经常调试修改 rtorrent.rc 配置文件,所以想要找一个方法可以在不重启 rTorrent 的情况重新加载配置文件,网上调查了一下之后发现原来挺简单的。
- Go 语言编写的网络穿透工具 chisel chisel 是一个在 HTTP 协议上的 TCP/UDP 隧道,使用 Go 语言编写,10.9 K 星星。