Google Analytics 代替产品对比
虽然我把其他服务陆陆续续从 Google 迁移出来,但 Google Analytics 一直都运行良好所以也没有怎么管,但 Google Analytics 到今年年中的时候会强行升级 GA4,看了一下升级的过程和 Google Analytics 的操作实在太复杂,就诞生了迁移出 Google Analytics 的想法。简单地了解了一下目前的 Google Analytics 的代替品,收费的,自行架设的还很多选择。这篇文章就简单地对比一下。
主要还是分成两个部分来划分搜罗的产品,可以自行托管的,和商用的。看过我之前文章的小伙伴应该知道,我个人会偏向于开源,可自行托管的服务。即便这个服务还在初始阶段可能还比不上某个商业化的服务,但我依然会选择开源的那个,比如我会选择 [[Wallabag]] 更甚于 [[Pocket]] 和 [[Instapaper]],我会选择 [[miniflux]] 更甚于我过去常常推荐的 InoReader。如果实在找不到合适的开源的,我会优先选择数据归属权在于个人的服务(比如数据不联网,存在本地,可以使用纯文本或有格式的类型导出数据),比如 Obsidian 更甚于 [[Notion]] 和 [[Roam Research]] 以及一切基于网页的笔记应用。
可 Self-hosted:
- [[Matomo]] (PHP + MySQL)是一款 PHP 开发的流量监控工具,报表功能比较强大.
- [[Umami]] [[TypeScript]] + MySQL/PostgreSQL
- [[Plausible Analytics]] plausible analytics Elixir 开发的小巧的流量监控平台.
- [[Fathom Analytics]] Go + JavaScript
- [[shynet]] Python
- [[Ackee]] Node.js, JavaScript, SCSS
- [[uxwizz]] PHP+MySQL
- Posthog 可以自架
- GoatCounter 一个开源的统计应用
不可自架,闭源
- [[Microsoft Clarity]]
- [[Splitbee]] 被 Vercel 收购,即将关闭,过去调研的时候曾经用过一段时间,体验确实不错,界面非常简洁,但是被收购之后就被整合到了 Vercel
- [[Tiny Analytics]]
- [[Smatlook]]
- Simple Analytics
- [[Microsoft Clarity]]
下面就重点介绍一下我准备去试试的几个服务。
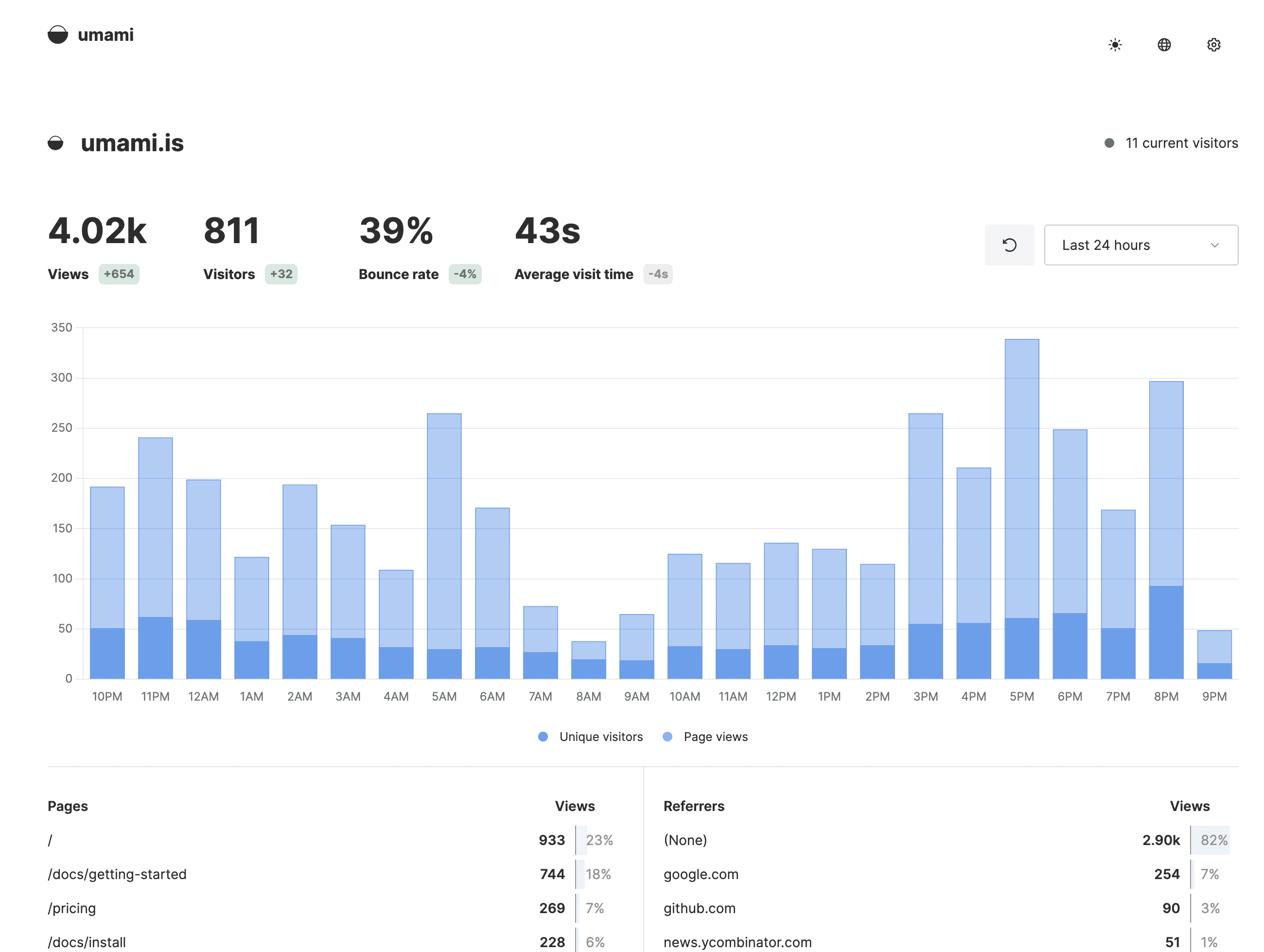
Umami
Umami 是一个可以自托管的数据统计服务,可以用来代替 [[Google Analytics]]。 “Umami”,源于 “Umai”,在日语里是“美味、鲜味”的意思。
Matomo
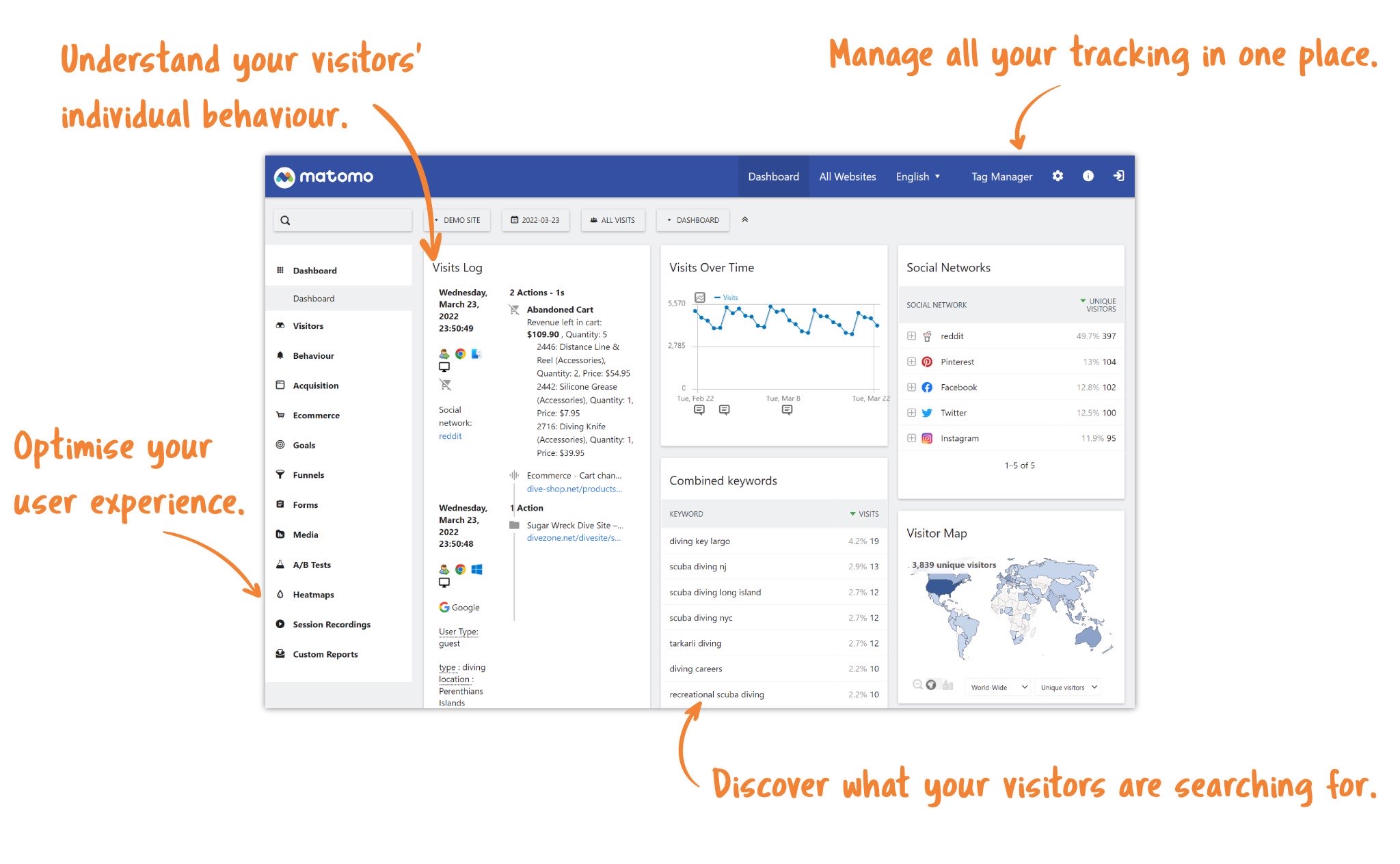
Matomo (原名 Piwik)是一款使用 PHP 编写的网站访问统计分析工具,开源,可自行架设,可以很好的代替 [[Google Analytics]] ,Matomo 使用 PHP 和 MySQL 实现,已经被超过 100 万网站所使用 。
Matomo 非常强大,并且只需要一来 PHP 和一个数据库,并且其报表分析非常强大。
- 支持根据用户访问的 IP 来查询地理位置
- 支持各种类型的表报
Fathom
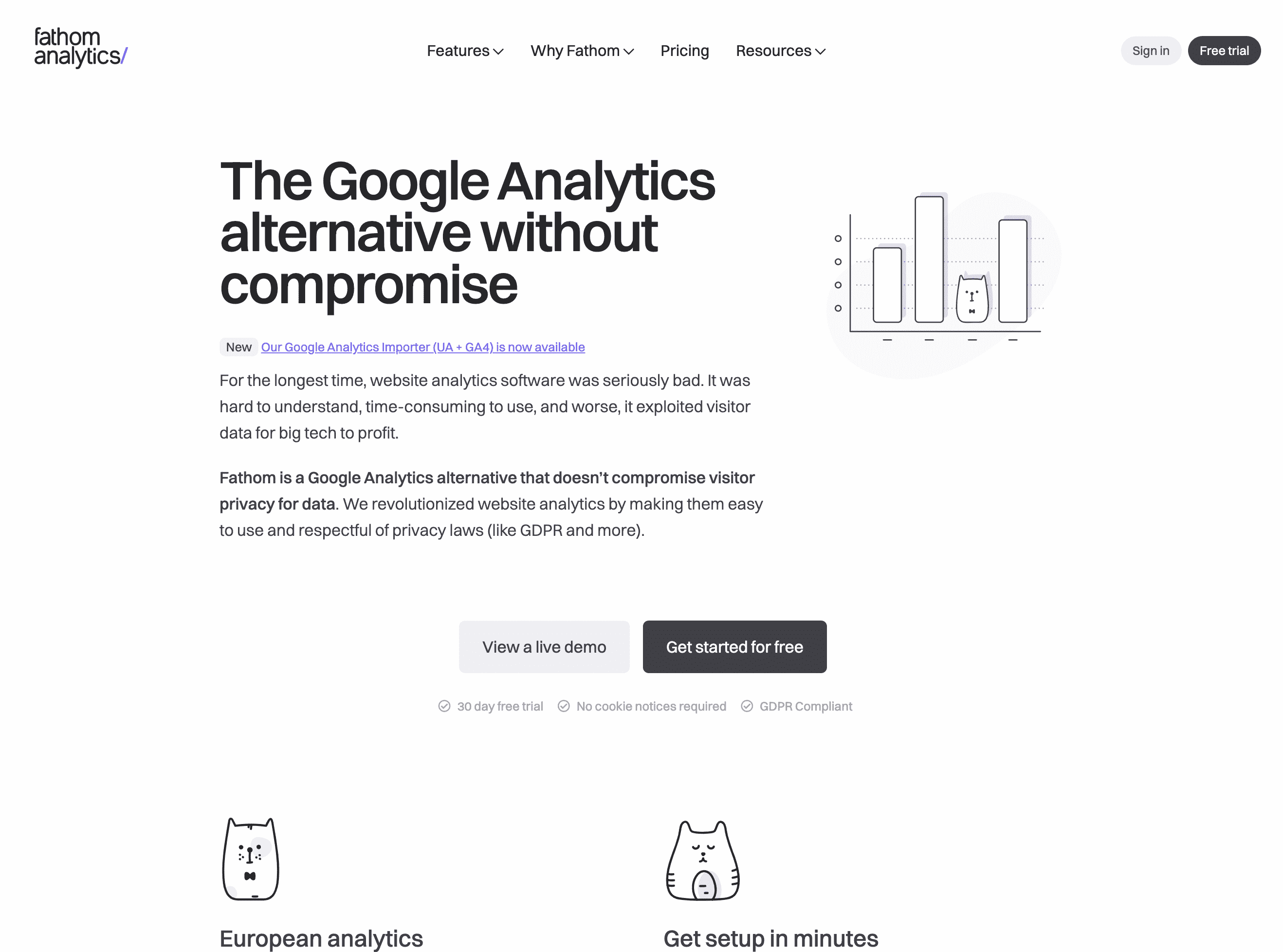
Fathom Analytics 是一个 [[Google Analytics]] 的代替。Fathom Analytics 是一个基于加拿大的团队推出的服务。
Fathom Analytics 是一个官方推出的 SaaS 平台,是一个收费的商业服务。如果不想使用官方的,也可以利用 Fathom Lite 自己搭建服务。
Fathom Lite 主要是使用 Go 语言 和 JavaScript 编写。Fathom Lite 和 Analytics 的区别可以参考这里。
Plausible
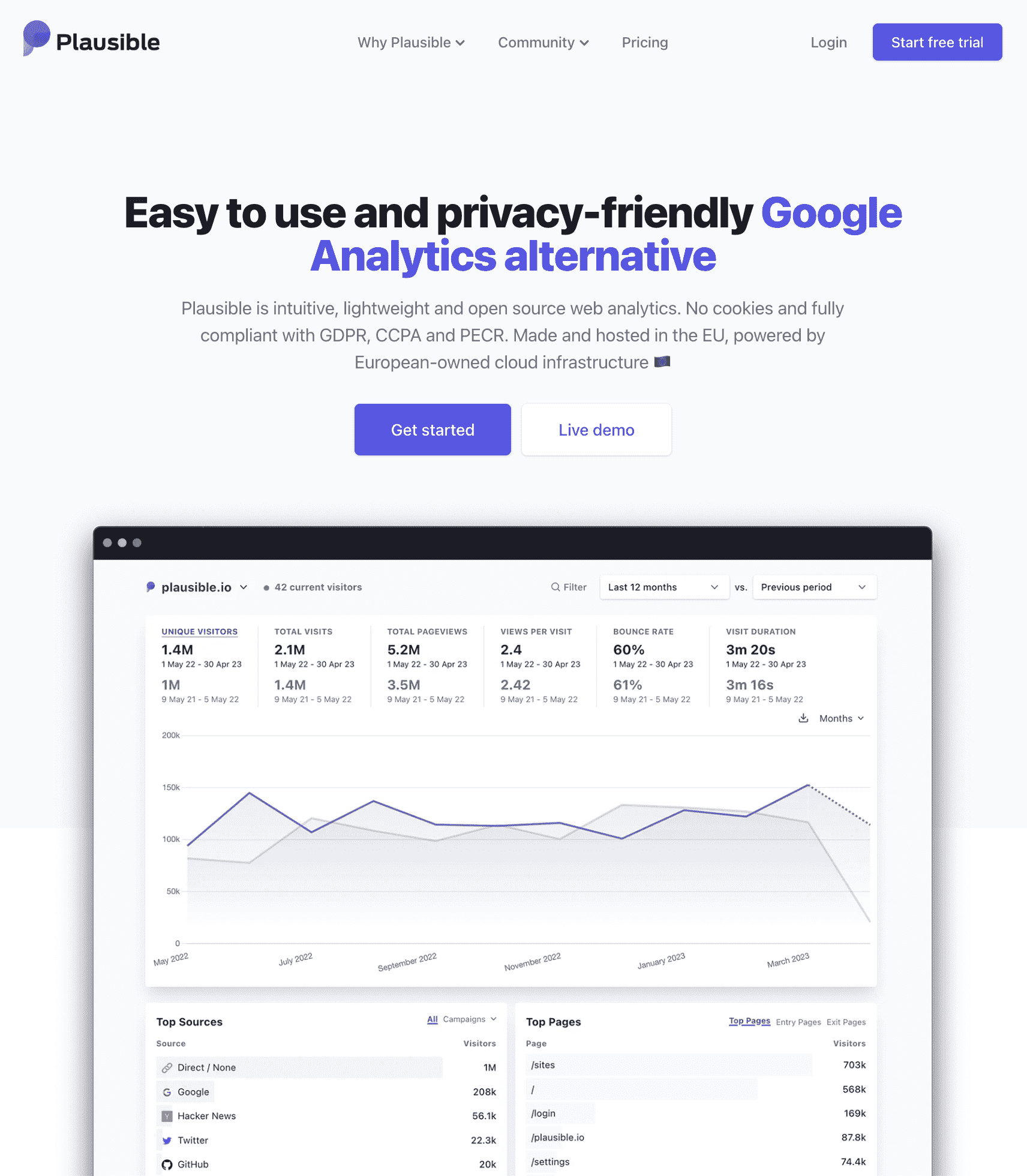
Plausible 是一个简单的 [[Google Analytics]] 代替。Plausible 是使用 [[Elixir]] 语言编写的,我最早知道这个服务是在 Twitter 上偶然之间看到了创始人分享如何想要找到一个 Google Analytics 代替,然后自己做,最后到如何打造成为一个 SaaS 产品,支撑自己的全部生活的成功故事。
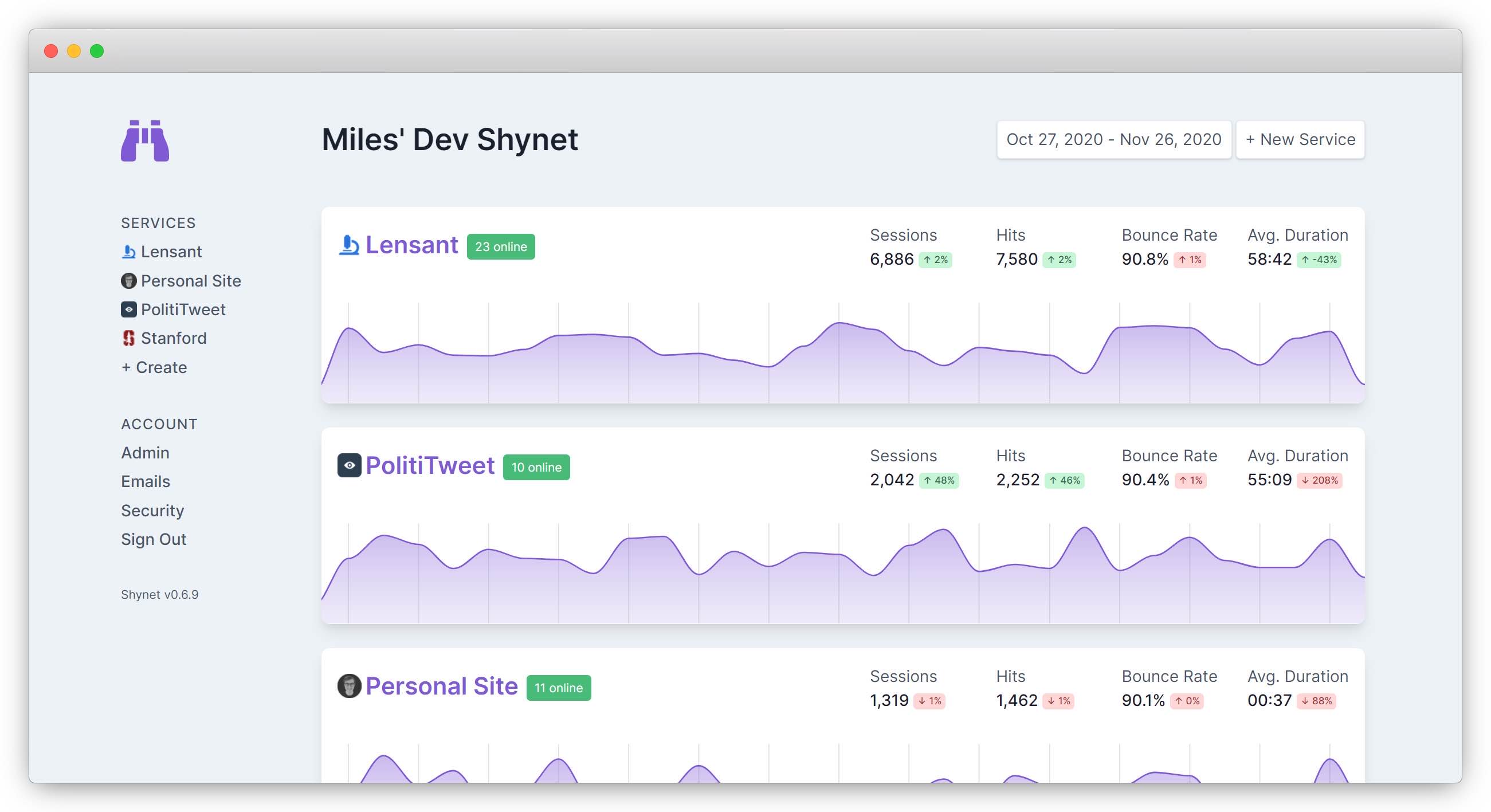
shynet
shynet 是一款使用 Python 编写的网站流量分析工具。
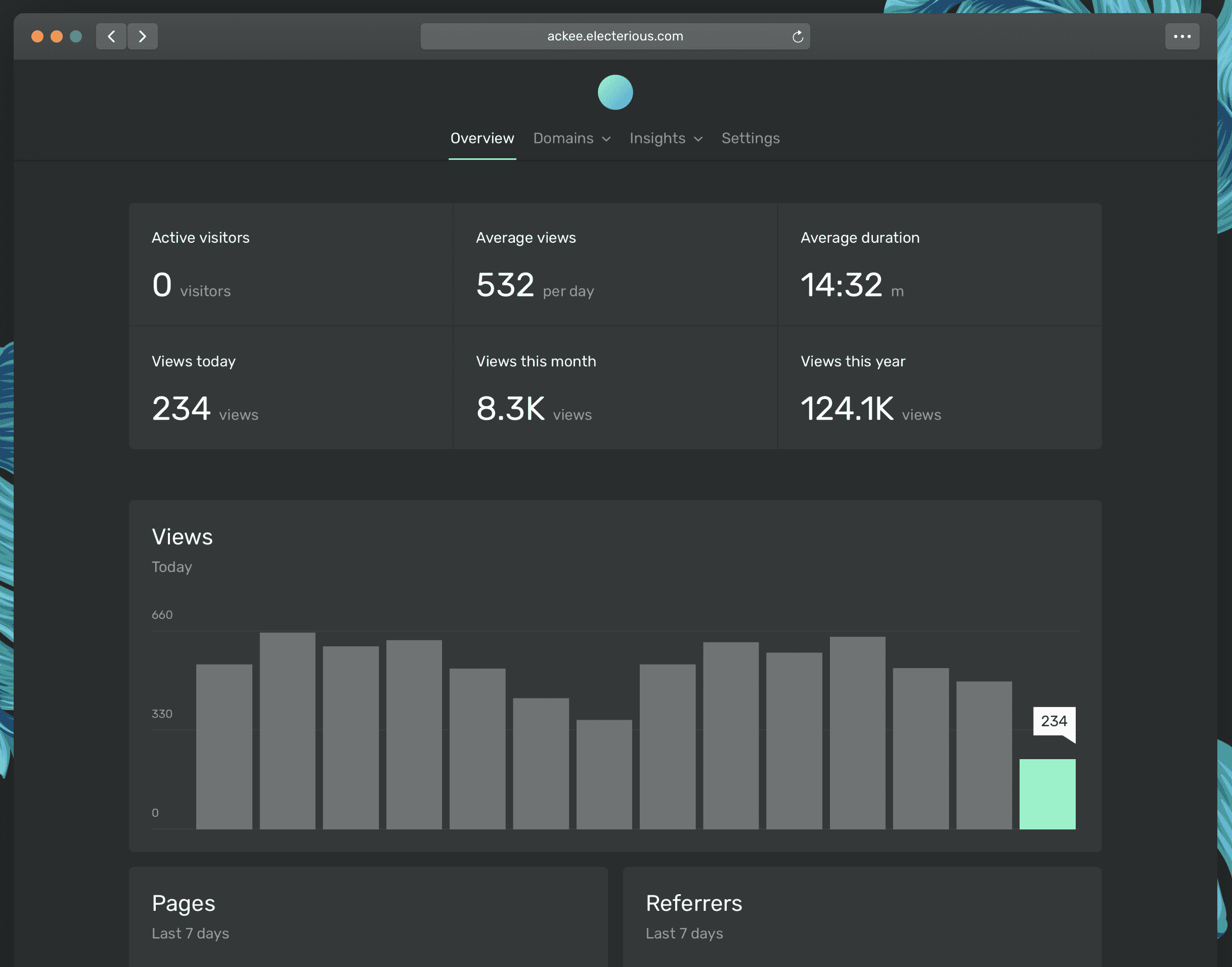
Ackee
Ackee 是一个关注隐私的开源(基于 MIT 协议)网页分析工具,采用轻量级的 Node.js 和 MongoDB 架构,接口使用 [[GraphQL]]。
Ackee 界面简洁美观,采用匿名数据采集的方式,分析你网站的流量并在最小的界面中提供有用的统计信息。对于不需要像 Google Analytics 或 Matomo 这样的全功能营销分析平台的个人来说,是一款非常不错的工具。
总结
除了浏览了一下官网和 GitHub 页面,没有对这些产品更进一步的了解了,但是我个人感觉 Umami 还不错,页面简洁,功能也满足我的使用。然后后端数据库支持 PostgreSQL 和常用的 MySQL,并且浏览了一下帮助文档,发现还支持 PlanetScale ,并且资源消耗也比较小,所以立马 Docker 搞起,创建数据库连接字符串,然后直接拉取镜像就能起来,配合 HestiaCP 申请一个 SSL 证书很快就搞定了。
自建 IT tools 一系列常用工具集
it-tools 是一个使用 [[Vue.js]] 和 TypeScript 编写的常用 IT 工具的集合。
集成工具
it-tools 项目中集成了如下的工具:
密码相关
- Token generator
- Hash text, 包括了 MD5,SHA256 在内的 8 种 Hash
- Bcrypt
- UUID
- Encrypt / decrypt text
- BIP39 passphrase generator
- Hmac generator
- RSA key pair generator
转换
- 日期时间转换
- 进制转换,二进制,八进制,十进制,十六进制
- 罗马数字转换
- Base64 转换
- Base64 文件转换
- 颜色表示转换,hex, rgb, hsl and css
- Case converter
- Text to NATO alphabet
- YAML to JSON
- JSON to YAML
- List converter
网页相关
- 编解码 URL
- Escape html entities
- URL parser
- Device Information
- Basic auth generator
- Open graph meta generator
- OTP code generator
- Mime types
- JWT parser
- keycode info
- Slugify string
- HTML WYSIWYG editor
- User-agent parser
- HTTP status codes
- JSON diff
图片和视频
- QR Code generator
- SVG placeholder
- Camera recorder
开发相关
- Git cheatsheet
- Random port generator
- Crontab generator
- 美化 GSON
- JSON 压缩
- 美化 SQL
- Chmod 计算
- Docker run 到 Docker Compose 转换
网络
- IPv4 子网计算
- IPv4 地址转换
- IPv4 地址范围
- Mac 地址查询
- IPv6 ULA 生成
数学相关
- Math evaluator
- ETA calculator
其他
- Chronometer
- Temperature converter
- Benchmark builder
- Lorem ipsum generator
- Text statistics
- Phone parser and formatter
安装
使用 Docker 镜像可以很快的安装上。更加具体的 docker-compose.yml 可以见这里
git clone https://github.com/einverne/dockerfile.git
cd dockerfile/it-tools
docker-compose up -d
学习
it-tools 也可以作为一个很好的学习 Vue 和 TypeScript 的项目,给这个项目贡献一个常用的工具库,用 Vue 绘制界面可以很好的上手 Vue 的使用。
EV Hosting 域名注册服务
EV Hosting 上线了域名注册服务,现在可以在 EV Hosting 选购超过 20 种的域名后缀,包括了常见的 .com, .org, .me, .info 等,还上线了 .fun, .life, .studio, .store 等等新的顶级域名。域名的价格在不同时期会略有不同。
在目前阶段,.fun, .pw, .life, .shop, pics, .studio, 等等域名只需要 20~30 元不等就可以购买一年。但是域名的续费一般会比较贵,可以酌情考虑不同的域名后缀。EV Hosting 也会在不同时间提供最优惠的域名注册服务。
注册域名
请注意购买域名之前,保证自己的注册邮箱是能够接收邮件的,在注册完成之后会受到一封验证邮件,域名注册局在第一次购买时需要验证该邮箱的使用。
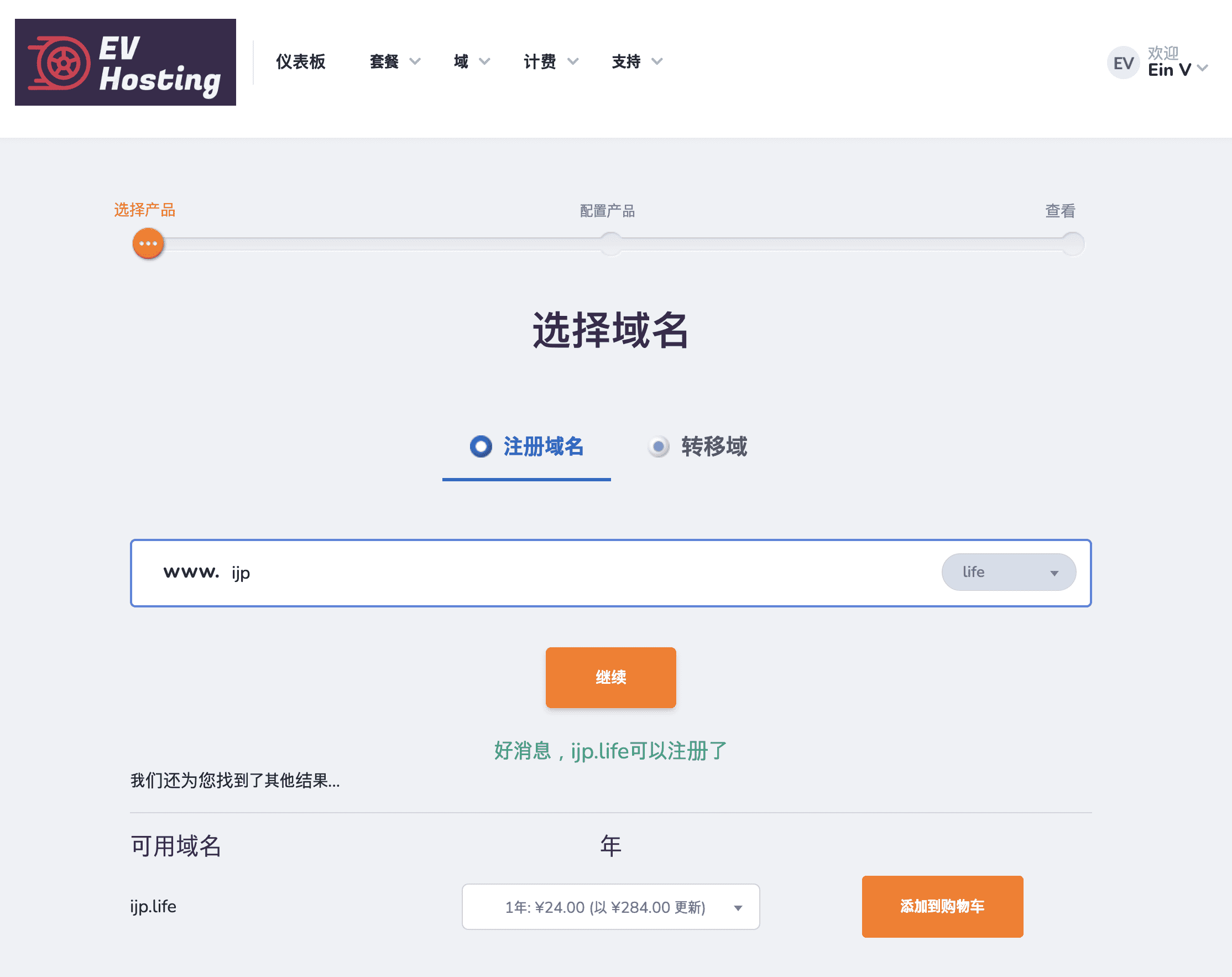
在下一个页面中进行支付。
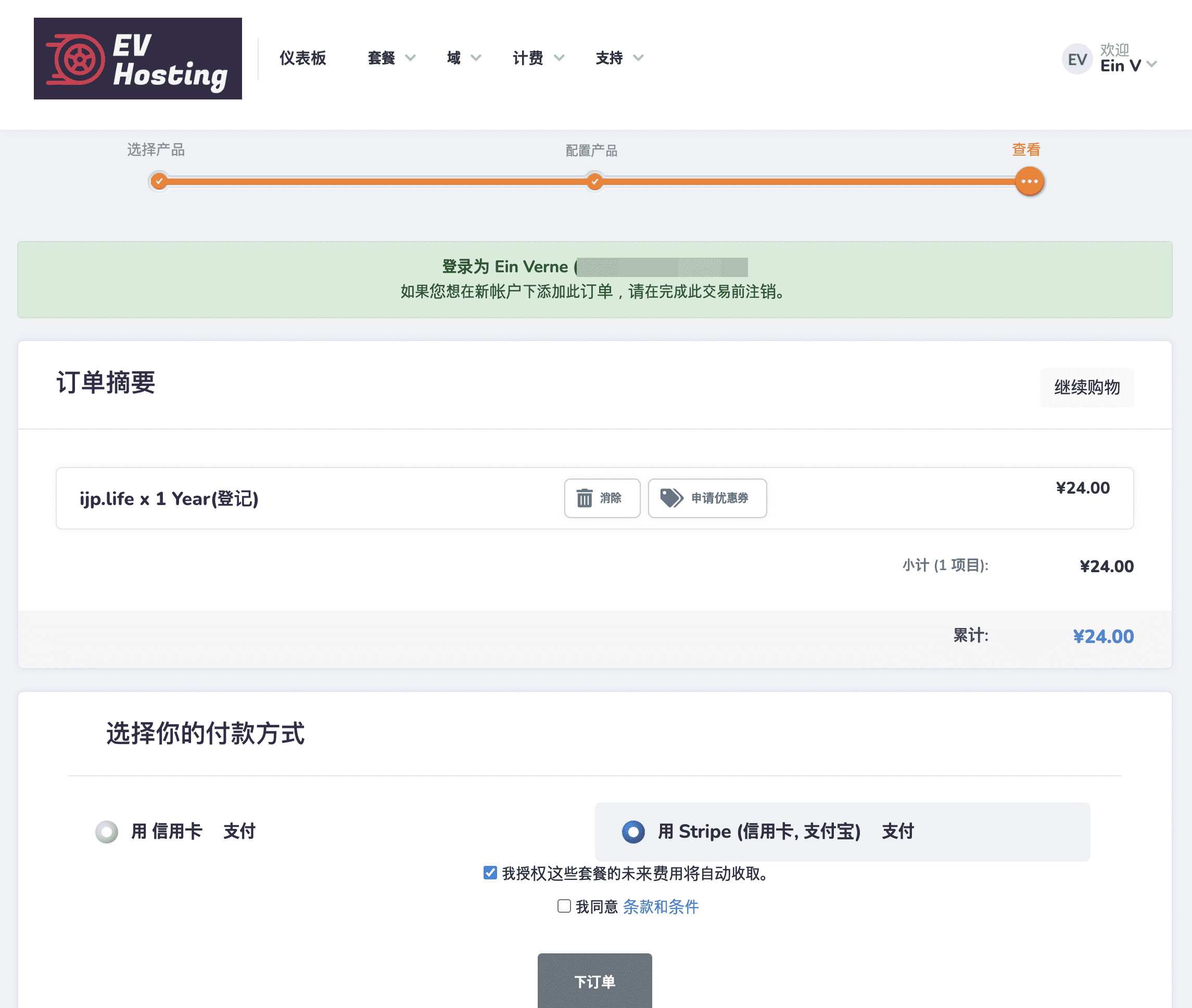
完成付款之后在「我的域名」中就能看到购买的域名。
在 EV Hosting 后台进行 DNS 记录管理
在 EV Hosting 中,点开对应的域名,可以在侧边栏中修改 NS 名称服务器(Name Server)。
本站提供的四个名称服务器可以在这里 查看(仅注册用户可见)。

将域名添加到 Cloudflare 管理
更推荐将域名添加到 Cloudflare 后台进行管理,访问 Cloudflare 后台,然后将域名添加到 Cloudflare。使用 Cloudflare 可以免费享受其提供的 CDN,还能隐藏背后服务器的 IP 地址。现在就介绍一下如何将 EV Hosting 购买的域名添加到 Cloudflare 。
首先要有一个 Cloudflare 的账号,进入账号之后,点击 「Add a site」,然后输入自己购买的域名。
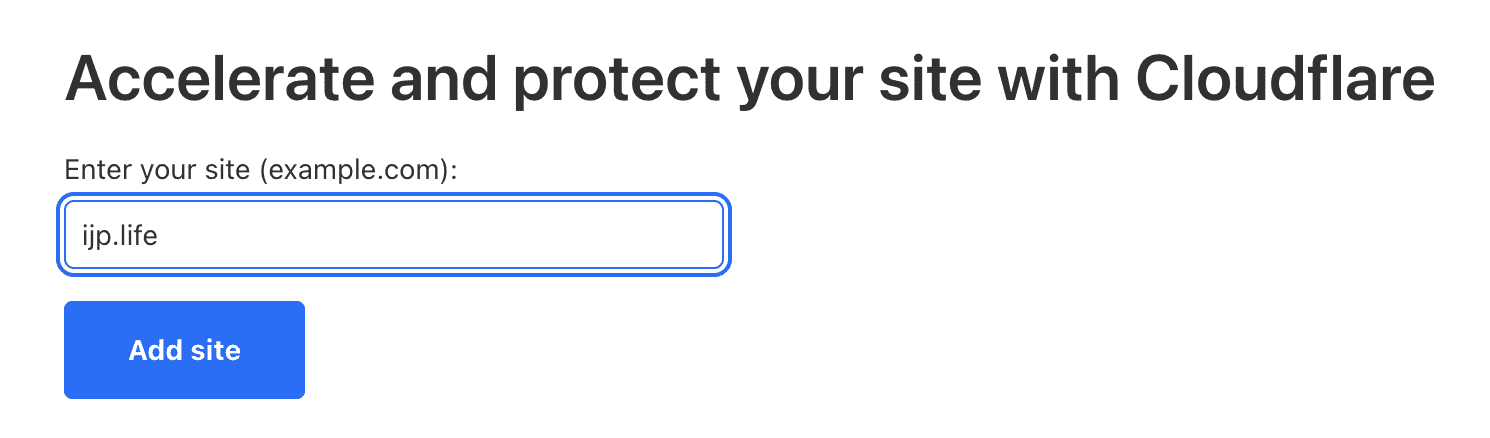
然后再下一步中选择 Free,使用免费套餐。然后 Cloudflare 会自动对域名进行扫描,自动找到域名的 DNS 记录,点击导入。然后 Cloudflare 会给出两个 Name server 的地址,将这两个服务器配置到 EV Hosting 域名管理后台的名称服务器中。
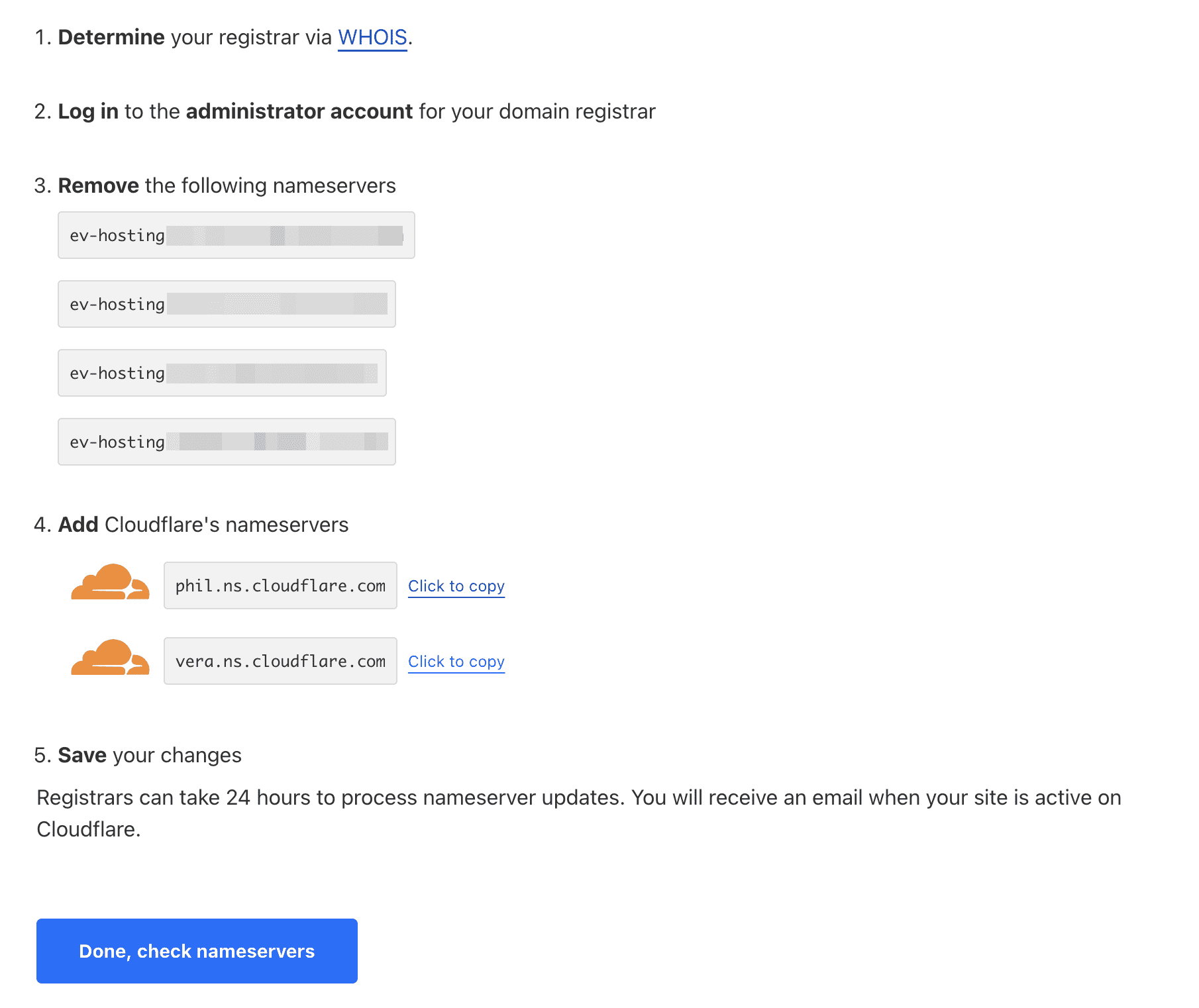
完成配置之后,等待一段时间 NameServer 生效,点击页面中的 「Done,check nameservers」。Cloudflare 会自动检查 DNS 是否生效,如果检查通过,会发一封邮件到 Cloudflare 的邮箱中。
添加到 Cloudflare 之后就可以使用 Cloudflare 的 DNS 管理,添加 [[A 记录]], [[TXT 记录]], [[CNAME 记录]] 等等了。
使用 Ansible 管理 Crontab
[[Ansible]] 是使用 Python 开发的自动化运维工具。它可以配置管理,部署软件并编排更高级的任务,例如持续部署或零停机滚动升级。Ansible 可以用来管理 crontab。[[Crontab]] 是一个用于在 Unix 和 Unix-like 操作系统上执行定期任务的工具,它允许用户在预定的时间间隔内自动运行命令或脚本。Crontab 是 Cron Table 的缩写,Cron 是一个用于定时执行任务的守护进程。
Crontab 使用一个称为 crontab 文件的特殊文件来定义定期任务的计划。每个用户都可以拥有自己的 crontab 文件,其中包含一系列命令或脚本以及与之关联的时间规则。更加详细的 cron 使用可以参考之前的文章
借助 Ansible,用户可以轻松地创建、修改和删除 crontab 条目,自动化 Crontab 任务的管理。
为什么需要用 Ansible 管理 crontab
在没用使用 Ansible 之前,都是通过 crontab -e 手动对 cron 任务进行管理,通常的任务就是备份与同步。但是随着要管理的机器和需要定义的脚本内容越来越复杂,手工编辑 crontab 就无法维护了。
另外在学习 Ansible 之后,了解了「Infrastructure as Code」概念,通过配置文件来定义所有的配置修改是一个不错的解决方案。这样一方面不用自己备份所有的脚本内容,也不用每一次都临时创建。在系统初始化的时候,直接通过 Ansible 就能纳入管理。
安装 Ansible
首先,确保你的系统上已经安装了 Ansible。你可以使用包管理器来安装它。例如,在 Ubuntu 上,你可以运行以下命令:
sudo apt update
sudo apt install ansible
下面是一些使用 Ansible 管理 crontab 的常见任务示例:
创建 crontab 条目:
使用 Ansible 创建 crontab 条目非常简单。你可以编写一个 Ansible playbook 文件,其中定义了你要创建的 crontab 条目。以下是一个示例 playbook 文件的内容:
---
- name: Manage crontab
hosts: your_target_hosts
tasks:
- name: Add crontab entry
cron:
name: "rsync backup"
minute: "0"
hour: "2"
job: "/path/to/your/backup_script.sh"
在这个示例中,your_target_hosts 是你要管理 crontab 的目标主机的列表。name 字段是 crontab 条目的名称,minute 和 hour 字段是定时任务的执行时间,job 字段是要执行的脚本或命令。
保存以上内容到一个 YAML 文件(比如 crontab.yml),然后运行以下命令来执行 playbook:
ansible-playbook crontab.yml
将在目标主机上创建一个新的 crontab 条目。
修改和删除 crontab 条目:
要修改或删除现有的 crontab 条目,你可以使用 Ansible 的 cron 模块的 state 参数。以下是一个示例 playbook 文件,演示如何修改和删除 crontab 条目:
---
- name: Manage crontab
hosts: your_target_hosts
tasks:
- name: Modify crontab entry
cron:
name: "My cron job"
minute: "30"
hour: "3"
job: "/path/to/your/updated_script.sh"
state: present
- name: Remove crontab entry
cron:
name: "My cron job"
state: absent
在这个示例中,state: present 表示修改 crontab 条目,state: absent 表示删除 crontab 条目。保存以上内容到一个 YAML 文件,然后运行 ansible-playbook 命令来执行 playbook。
Stock Event 应用使用体验
Stock Event 是一款投资组合追踪器,股票市场和股息追踪器,Stock Event 可以追踪的内容包括股票、ETF、加密货币、指数、外汇、大宗商品、各地交易所等等。Stock Event 最亮眼的一个功能就是可以追踪公司的分红日期,通过图表视觉化的追踪给用户提供了最详细的分红数据。另外加入 Pro ,就可以查看包括各地失业率在内的更多数据。同样使用 Pro 可以解锁无限制的关注数量,可以自定义收藏,并且连接个人日历,获取即将上市的 IPO 信息。
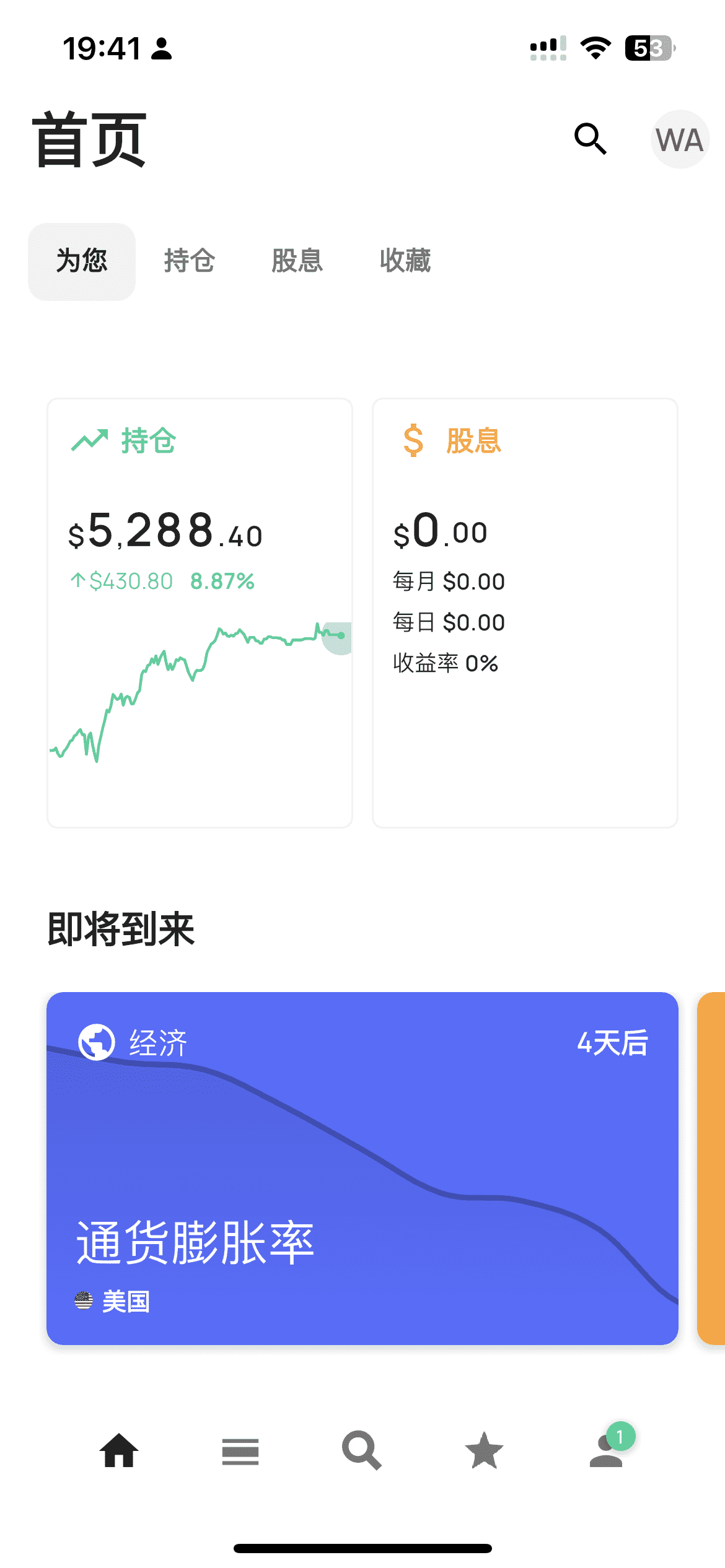
首页
在首页中非常清晰地绘制了当前持仓的涨跌幅,以及投资组合的股息。
在四个标签中的最后一个「收藏」中能看到 Stock Event 给出的一些组合,可以点进这些分类然后关注。
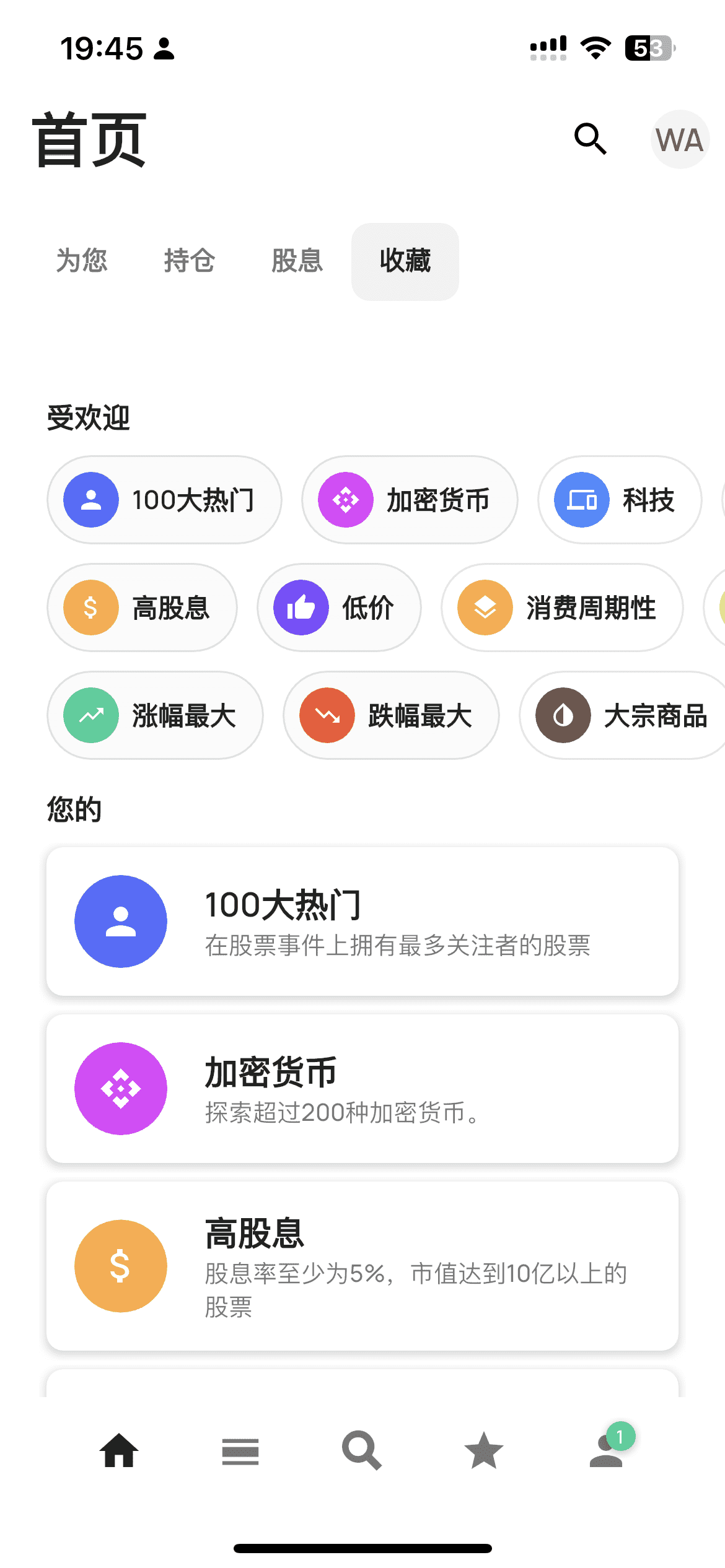
关注不同类型的股票
在首页的收藏中 Stock Event 提供了几种分类,包括:
- 100 大热门
- 加密货币
- 高股息,股息率 5%,市值 10 亿以上
- 低价
- 涨幅最大,今日涨幅最大的 30 只股票
- 跌幅最大,今日跌幅最大的 30 只股票
时间线
时间线界面中展示了当前用户关注列表中的公司(标的)的重大新闻时间线。
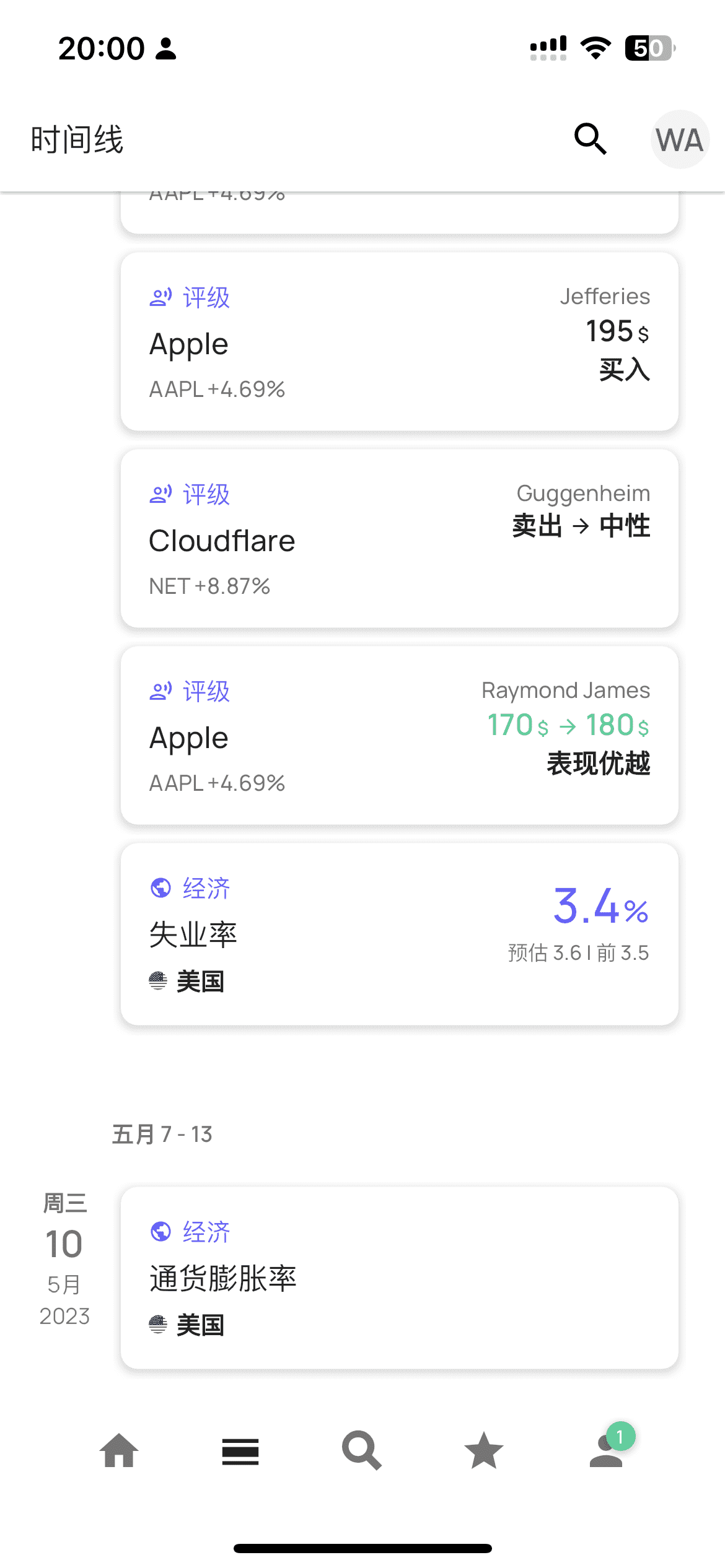
虽然我个人并不喜欢这样大面积留白的设计,我觉得信息展示的效率太低了,但至少也还能做一下参考。
搜索
第三个标签页是搜索和新闻的界面,可以在这个界面里面寻找自己关心的标的添加关注,也可以在这个界面中查看相关的新闻。
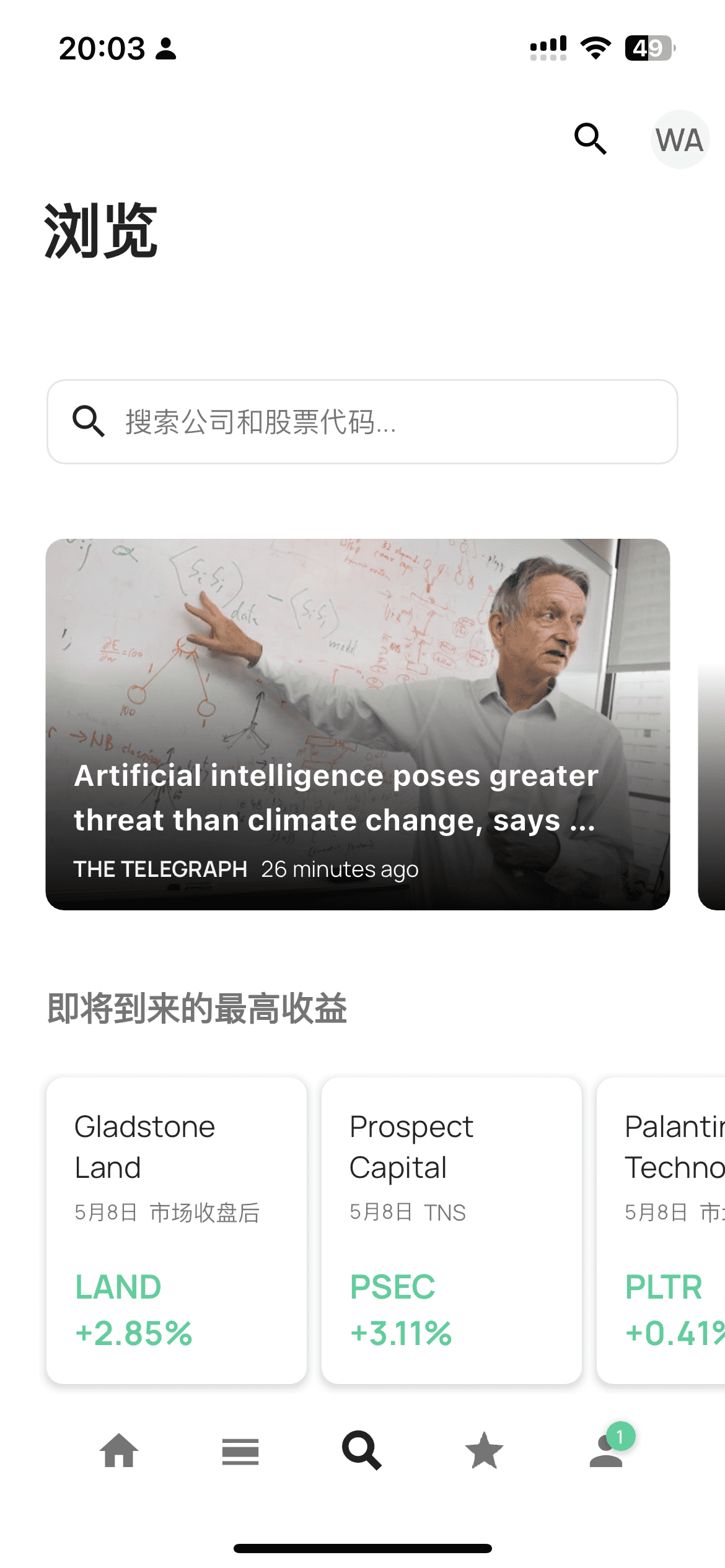
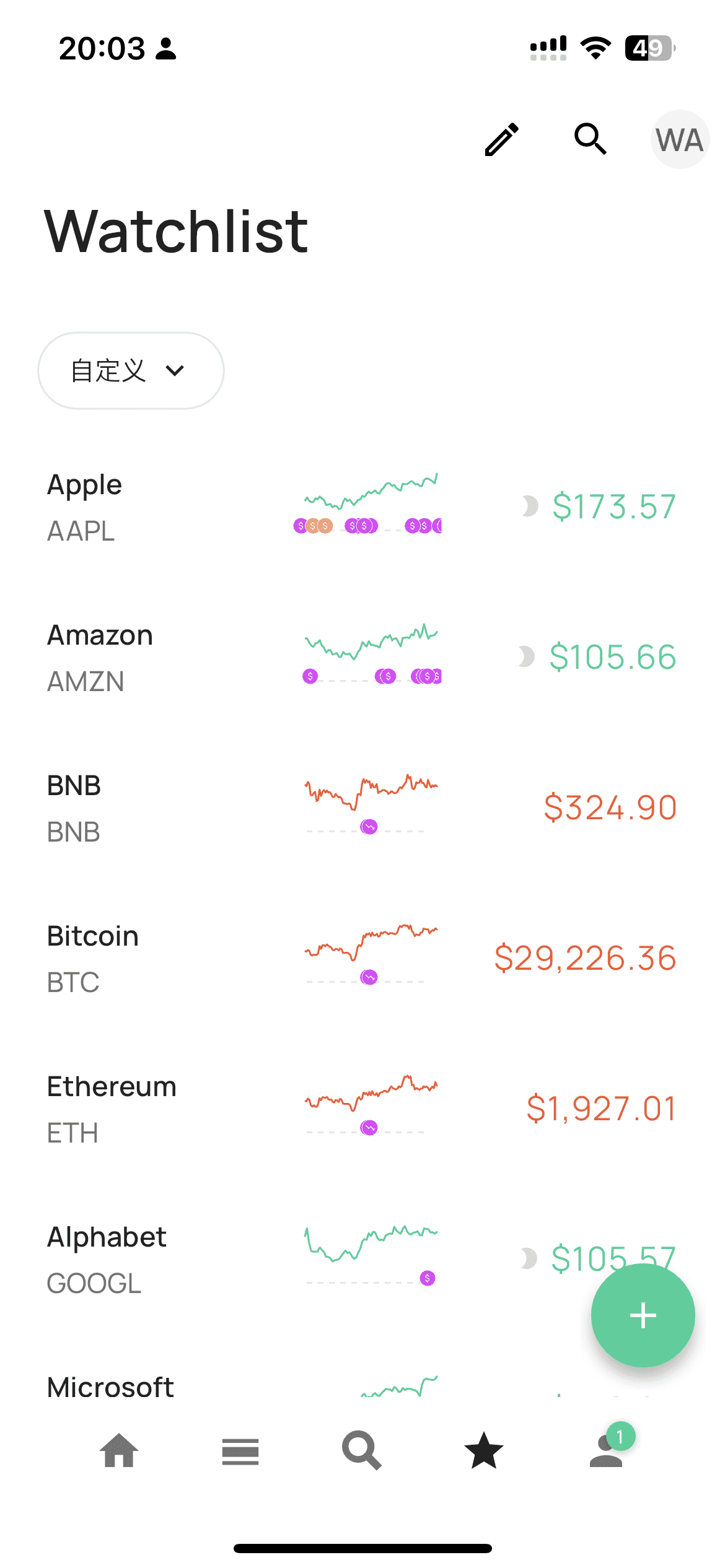
Watchlist
第四个标签页就是最基本的关注列表。基础账号最多可以添加 15 个关注,如果使用我的链接 注册,可以再永久获得 5 个关注位置。
总结
界面简洁,非常适合我这样不经常进行交易,只想快速在几秒钟的时间内了解一下当下行情的人。Stock Event 适合作为交易所软件的一个补充,交易软件比如 富途,老虎,华泰,长桥等,通常在交易软件中就会不自觉地进行操作(买卖),但是大部分的股票我是不会进行短期的买卖的,但如果常常打开股票交易软件就会控制不住自己的手。这个 Stock Event 就只是作为一个追踪器,并且可以在一个应用中查看股票,加密货币,就大大操作。Stock Event 操作起来也比交易所软件简单很多。
Stock Event 所提倡投资方法其实在其应用的设计中就能体现出来,Stock Event 将高股息,除息日都设计得非常直观,并且 Stock Event 还会推荐[[市盈率]]比较低的标的,让我们可以快速地获取价值投资中说的那样,找到高价值低价格的内容,然后长期持有。
如果看到这里了,那么可以使用我的邀请链接 注册,你我都可以在免费版的基础上增加 5 个关注列表。另外我还有一个专门写投资的博客,如果关注港股,美股和加密货币,也可以去看看。
在 HestiaCP 面板中禁用 open_basedir 配置
Hestia Control Panel ([[HestiaCP]]) 是一个免费开源的 Web 服务器控制面板,它提供了一个易于使用的 Web 界面来管理 Web 服务器和网站。Hestia CP 支持多种 Linux 发行版,包括 Ubuntu、Debian、CentOS 等,可以安装和配置 Apache 或 Nginx、PHP、MySQL 等常见的 Web 服务器和数据库软件。Hestia CP 还提供了一些额外的功能,如邮件服务器、防火墙、文件备份和恢复等。
open_basedir 是 PHP 的一个安全特性,用于限制 PHP 脚本能够访问的文件系统路径。它指定了一个或多个目录的列表,PHP 将只允许访问这些目录中的文件。这可以帮助防止恶意脚本访问系统中的敏感文件。
open_basedir 最主要的功能就是隔离站点能访问的内容,而从不至于让站点之间相互影响。
如果要禁用这个功能,需要修改 PHP 的配置,访问
cd /usr/local/hestia/data/templates/web/php-fpm/
文件夹下有安装的 PHP 版本不同的配置。比如说 PHP 8.0 的配置模板文件,就是 PHP-8_0.tpl
打开该文件,然后找到下面一行
php_admin_value[open_basedir]
然后在这一行前面加上 ; 注释。
;php_admin_value[open_basedir]
或者如果熟悉命令行的话,可以直接使用 sed -i 行内替换
sed -i 's/php_admin_value\[open_basedir\]/;php_admin_value\[open_basedir\]/g' /usr/local/hestia/data/templates/web/php-fpm/PHP-8_0.tpl
修改文件之后需要重启 PHP 8.0 的服务
/etc/init.d/php8.0-fpm restart
完成设置之后,就可以使用 phpinfo.php 来查看 open_basedir 的设置,应该会看到 no value 的字样。
CrossBox 使用记录
CrossBox 是一个 All-in-One 的,可自行架设的,的通信套件,包含了及时通信,邮件,文件存储等等组件。CrossBox 致力于为托管/电子邮件提供商提供一体化的、100%自托管的通信套件。它允许服务提供商利用现有的基础设施,为客户提供通常仅在 Gmail、Outlook 和其他大型 SaaS 平台上可用的通信功能(并且完全符合 GDPR 规定)。
服务提供商的特性
最值得注意的功能就是 CrossBox Cluster。它使服务提供商能够为不同服务器上的所有客户提供单一的入口点。其中包括统一的 Webmail URL,统一的 IMAP,SMTP,POP3 主机名以及统一的 MX。在更复杂的线上环境中,提供商还可以选择构建高可用性,负载均衡和地理分布式设置 - 使得它可以轻松实现 100%可用性,水平扩展以及来自世界不同地区的用户获得快速访问。
终端用户的特性
CrossBox 集成了超过 40 多个工具和功能,包括了邮件,即时通信,音频和视频通话,会议,屏幕分享,文件存储分享,等等。可以从官方页面的介绍中了解更多。或者直接试用线上版本 进行体验。
- Powerful Email Composer
- Email Attachment Previewer Built-in
- Email Scheduling
- Email Snoozing
- Send Large Email Attachments
- Canned Responses
- Email Reminders/Follow-ups
- Spam Learning
- Email Filters
- External Email Accounts
- Auto-purge/auto-sweep Old Emails
- Chat, Audio/Video Calls
- Screen-sharing
- Real-time File Sharing
- Private Files
- Team Folder
- Multi-account
- Multitasking
- 2FA, Access Recovery
- 100+ languages
- Android/iOS Apps
CrossBox 的 White-label Add-on 也可以让服务提供商自定义应用的名字,Logo,主题颜色,登录地址,[[webmail]] 域名,IMAP/SMTP/POP3 hostnames,MX 等等细节。更甚至服务提供商可以利用 在线的应用构建程序 直接生成 Android/iOS 的应用。
CrossBox 还提供了 [[DirectAdmin]],[[cPanel]],[[Plesk]] 控制面板的集成。服务提供商一键接入即可,无需任何的修改。1
现在 EV Hosting 也上线了自定义域名邮箱服务,如果你想要一个可以自己控制的域名邮箱,欢迎订购使用,现在使用 EV_MAIL_INIT 可以享受年付 5 折优惠。
reference
《How to Invest》 读书笔记
怎么知道的这一本书
很偶然的机会在 Twitter 上看到有人分享了读书笔记,于是就加入了待看书单。
关于作者
大卫-鲁宾斯坦 David Rubenstein 是彭博一个备受欢迎的财经访谈节目主持人。出于对历史的热爱,他还主持了一档历史节目。作为亿万富翁,他是著名的私募股权公司凯雷集团(The Carlyle Group)的联合创始人。他曾是职业律师,并担任过政府官员。
几句话总结书的内容
这是作者以主持人身份采访了一批当今大师级投资者后写的。试图总结出这批人的投资风格、思维模式、行为方式和人生态度等多方面共性。 而作者的经历也体现出富翁们的共性:高度的职业精神。
作者写作本书的目的是要向几十年前的《金钱大师》(The Money Masters)致敬。当年那本经典著作总结了 9 位大师的投资之道。而本书的重点并不是投资的干货,而是努力观察 23 位现在很活跃的投资家共同的特点。
- 他们大多数都来自普通家庭
- “这些人多来自蓝领和中产阶级家庭。 受过良好教育,有很好的数学能力,也有巨大的求知欲。 他们是获取信息的海绵。喜欢做最后决定,而不想把决定权交给别人。 犯了错以后也愿意承担后果,然后继续去干下一件事。”
- 大多数半路出家
- “很多人职场的起步不是投资,之前的教育也与金融无关。都是因缘际会进入投资领域。 所以投资大师不一定是顶尖商学院出身。 如吉姆•西蒙斯是数学家,他从没想过要做投资,但他发明了量化投资。 斯坦•德鲁肯米勒原本只是想拿一个经济学博士学位,然后投身到华尔街。”
- 大多数失败过,所以很低调谦虚
- “他们都亏过很多钱,但习以为常了。及时纠正错误是优秀投资者的标志。如果总是纠结于错误,永远不会有所成就。 他们都很谦虚,有些情况下可能是刻意的。 不喜欢吹嘘成绩。如果你遇到一个自吹自擂的人,那么这个人肯定不会成为大师级投资者。”
- 大多数酷爱读书的人
- “他们真的很热衷于阅读,阅读内容涉及各个领域,不仅仅局限在投资相关的资料上。所以他们对各种事物都有所了解也就不足为奇了。很多从事股票投资的年轻人不明白为什么要阅读书籍,他们只是跟着别人的潮流而已。他们没有发现真正的投资入门之道。优秀的投资者应当养成自己的阅读习惯,并且要清楚自己在做什么。
- 大多数天生不愿盲从
- “人生最容易的路是遵循传统智慧: 父母让你做,老师让你做,朋友让你做,跟着做就是了。 你可能会有不错的生活,但不会成为成功的投资者。 要获得巨大成功,你必须打破陈规,违背传统智慧。“
- 传统的智慧会说亚马逊、苹果这样的公司不可能成长为参天大树,会告诉约翰•保尔森(08 年大空头之一) 在抵押贷款市场上的空头肯定会输,会告诉吉姆·西蒙斯,量化投资不可能超过人类的头脑。 人们只是认为不能违背传统智慧。 但如果你很聪明,看到别人看不到的东西,作为投资者就会赚很多钱。”
- 大多数没有定见
- “斯坦·德鲁肯米勒对于投资从没有定见。他做宏观投资,有时做空有时做多。 他会做任何他认为值得的事。但也有可能第二天就改主意。 所以他不喜欢给别人建议,因为他也不知道第二天会不会改变主意。”
- 大多数很慷慨
- “他们把投资当作事业来做,不是因为钱赚不够,而是因为喜欢投资中对智慧的挑战。 但他们几乎都会最后将工作重心转向慈善,因为做慈善是一种乐趣,你必须在生活中找到真正喜欢的东西。这样当你每天做的时候,它是愉快的而不只是工作。”
- “有时人们看到华尔街赚了很多钱,就认为他们非常贪婪。 实际上作为投资者,你的职业就是赚钱。通过赚钱,把资金配置给需要的公司,让这些公司创造更大的价值。 美国经济过去 200 年取得的成功,很大程度上就是因为这些投资者在做着配置资金的高效工作,他们和其他职业一样应该得到肯定。”
启发或想法
在阅读的过程中,我脑海中一直会跳跃出 [[Naval Ravikant]] ,[[芒格]] 等等人的形象,好的投资人都有一些共同的技能和特点,我一直都认为好的投资一定是做对了什么,而这些投资家看待事情的角度,做对事情的过程,以及内在的思维模式,往往就隐藏着他自己的思考。他们所拥有的「技能」,「思想」,「习惯」,都是值得我们普通人去学习和借鉴的。在书中可以看到的是,这些投资家大多数来自于普通的家庭,往往并不是金融领域的,并且可能还遭遇过很多的失败。但是他们从来不因此而放弃,也从来不跟随市场,他们愿意承担自己的做出的选择所带来的后果,并且愿意承担错误的后果,能够及时地纠正自己的错误,谦虚低调。
最后我想说的是,投资是一门手艺,投资的经验是不可代替的,我们不应该期望通过阅读成功投资者的采访来成为更好的投资者,就像我们不应该期望通过阅读 NBA 球员的采访来成为更好的篮球运动员一样。但是我们要看到成功者身上独特的闪光点:
- 习惯失败
- 不愿盲从
- 没有定见
- 谦虚低调
- 乐于慈善
- 最重要的就是阅读,广泛的阅读,并形成自己独特的思考和判断能力。
谁应该看这本书
对投资感兴趣的人。
ChatGPT 打字机显示效果的背后:Server-sent Events 介绍
在使用 [[ChatGPT]] 的时候总是对它一个字一个字的出结果感到焦急,虽然也知道 AI 生成内容的时候确实是一个字一个字计算出来的。OpenAI 使用这样的一个打字机效果也确实符合这个使用场景。但是当我想要自己去实现这样的效果的时候就突然遇到了我的知识盲区,观察 Chrome DevTools,我原本还以为是用 Web Socket 实现的,但是观察了一番发现并没有 Web Socket 的连接。再观察 https://chat.openai.com/backend-api/conversation 接口,发现 content-type: text/event-stream; charset=utf-8,于是就有了这篇文章。
什么是 Server-sent Events
Server-sent Events (SSE) 是一种服务器推送技术,利用该技术可以让服务器通过 HTTP 连接向客户端推送通知,消息,事件。SSE 通常用于向浏览器客户端发送消息更新或连续数据流,通过称为 EventSource 的 JavaScript API 来增强本机跨浏览器流媒体,客户端通过请求特定 URL 来接收 Event Stream。 SSE 的 media type 为 text /event-stream。
服务器推送内容
当我们开发需要数据实时更新的项目时,通常有一个问题,就是「如何从服务端向客户端发送消息/更新」,通常情况下有三种处理方式:
- Client Polling
- Web Socket
- Sever-Sent Events(SSE)
Client Polling
客户端以固定间隔向服务端轮询查询更新。这个技术不是很新,实现比较简单。但这种技术只能算作准实时。
Web Socket
Websocket 是一个流行的技术,用来提供客户端和服务端的双向数据传输。
Websocket 不是基于 HTTP 协议的,所以需要额外的安装和集成,开发和实现难度稍微比 Client Polling 复杂一些。
Server-Sent Events
Server-Sent Events 是一个最新的技术,基于 HTTP,提供从服务端到客户端的异步消息通讯。几乎所有的浏览器都支持 SSE,除了 Internet Explorer。
SEE 使得服务器可以不依赖任何 polling 或 long-polling 的机制来发送消息给客户端。
GET /api/v1/live-stream
Accept: text/event-stream
Cache-Control: no-cache
Connection: keep-alive
text/event-stream 表示客户端会从服务端等待事件流。no-cache 表示禁止缓存。
这个请求会开启一个长连接,服务端可以将实时的内容发送给客户端。Events 发送的内容是 UTF-8 编码的文本内容。
优点
- 简单,EventSource API 非常简单
- 服务器推送,适用于服务器向客户端推送数据,客户端只能接收
- EventSource 会自动处理断开和重连
缺点
- Server-Sent Events 的一大缺点就是数据的格式只支持 UTF-8,二进制数据是不支持的。
- 当没有使用 HTTP/2 的时候,另一个限制就是同一个浏览器最多只能有 6 个并发连接。当使用多个标签页的时候可能成为瓶颈。

more
Microsoft 提供了 fetch-event-source 这个库来实现了 POST 请求的 EventSource。
reference
在 Hestia CP 的 VPS 上安装 ionCube Loader
Hestia Control Panel ([[HestiaCP]]) 是一个免费开源的 Web 服务器控制面板,它提供了一个易于使用的 Web 界面来管理 Web 服务器和网站。Hestia CP 支持多种 Linux 发行版,包括 Ubuntu、Debian、CentOS 等,可以安装和配置 Apache 或 Nginx、PHP、MySQL 等常见的 Web 服务器和数据库软件。Hestia CP 还提供了一些额外的功能,如邮件服务器、防火墙、文件备份和恢复等。
ionCube Loader 是一个 PHP 扩展程序,用于解密和执行使用 ionCube 编码技术加密的 PHP 脚本。它通常用于保护商业 PHP 应用程序的源代码,以防止未经授权的访问和复制。我之前在安装 Clientexec 的时候短暂地接触过。之前在 lnmp 和 [[aapanel]] 上都是手动安装的,基本步骤也相差不错,下载 ionCube,然后修改 PHP 配置,在配置里面将 ionCube 扩展的本地路径配置上。
首先访问 ionCube Loader 官网,然后根据自己的系统下载对应版本的二进制。
解压之后可以得到很多 .so 文件。
cp ioncube_loader_lin_7.4.so /usr/lib/php/20190902
echo zend_extension=ioncube_loader_lin_7.4.so > /etc/php/7.4/fpm/conf.d/00-ioncube.ini
echo zend_extension=ioncube_loader_lin_7.4.so > /etc/php/7.4/cli/conf.d/00-ioncube.ini
配置 8.1
echo zend_extension=ioncube_loader_lin_8.1.so > /etc/php/8.1/fpm/conf.d/00-ioncube.ini
echo zend_extension=ioncube_loader_lin_8.1.so > /etc/php/8.1/cli/conf.d/00-ioncube.ini
重启
service php7.4-fpm restart
验证
php7.4 -v

可以在 /usr/lib/php 目录下看到三个日期的目录,上面提到了一个 20190902 的目录。如果要配置其他 PHP 的版本,就需要用到其他的目录。
这三个数字分别代表 PHP 的版本号。20190902 代表 PHP 7.4,20200930 代表 PHP 8.0,而 20220829 代表 PHP 8.1。这些数字用于指定 PHP 扩展或应用程序所需的最低 PHP 版本。如果一个应用程序需要 PHP 7.4 或更高版本,则可以使用 20190902,如果需要 PHP 8.0 或更高版本,则可以使用 20200930,如果需要 PHP 8.1 或更高版本,则可以使用 20220829。
要注意的是 ionCube 是不提供 8.0 版本的,所以如果要求 8.0 以上,那么就需要配置 8.1 的。
文章分类
最近文章
- AI Shell 让 AI 在命令行下提供 Shell 命令 AI Shell 是一款在命令行下的 AI 自动补全工具,当你想要实现一个功能,敲一大段命令又记不住的时候,使用自然语言让 AI 给你生成一个可执行的命令,然后确认之后执行。
- 最棒的 Navidrome 音乐客户端 Sonixd(Feishin) Sonixd 是一款跨平台的音乐播放器,可以使用 [[Subsonic API]],兼容 Jellyfin,[[Navidrome]],Airsonic,Airsonic-Advanced,Gonic,Astiga 等等服务端。 Sonixd 是一款跨平台的音乐播放器,可以使用 [[Subsonic API]],兼容 Jellyfin,[[Navidrome]],Airsonic,Airsonic-Advanced,Gonic,Astiga 等等服务端。
- 中心化加密货币交易所 Gate 注册以及认证 Gate.io 是一个中心化的加密货币交易所。Gate 中文通常被称为「芝麻开门」,Gate 创立于 2013 年,前身是比特儿,是一家致力于安全、稳定的数字货币交易所,支持超过 1600 种数字货币的交易,提供超过 2700 个交易对。
- 不重启的情况下重新加载 rTorrent 配置文件 因为我在 Screen 下使用 rTorrent,最近经常调试修改 rtorrent.rc 配置文件,所以想要找一个方法可以在不重启 rTorrent 的情况重新加载配置文件,网上调查了一下之后发现原来挺简单的。
- Go 语言编写的网络穿透工具 chisel chisel 是一个在 HTTP 协议上的 TCP/UDP 隧道,使用 Go 语言编写,10.9 K 星星。